原文 Our Multi-tenancy Journey with Postgres Schemas and Apartment。这篇和之前发出的「如何使用 Postgres 对一个多租户应用分片」相呼应。

多租户 (Multip-tenancy) 是当下的热门话题。我对多租户应用程序的定义是一个能够服务于多个客户的软件系统,每个客户都能在该系统中拥有自己数据的独立视图。每个客户及其数据通常被称为一个租户,因此而有了多租户之名。
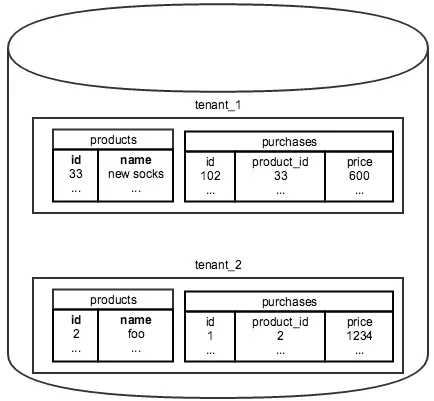
在早先关于分片多租户应用程序的博客文章中,Craig 深入探讨了任何需要支持多个客户账户的系统中自然发生的租户类型(或在他的例子中,是一家店)。在他的例子中,属于特定租户的所有记录都会获得一个外键 tenant_id,这个键逻辑上将其他表中的行与该租户关联起来。隔离发生在查询级别,比如所有产品(例如)都会使用 tenant_id 来限定范围,针对你感兴趣的特定商店。
当我加入 Influitive 时,他们已经采用了多租户路线,但是使用了PostgreSQL schema 来隔离。这使用了一种略有不同的多租户机制,其中表不再存储对其租户的引用。相反,当我们添加一个新租户时,我们会创建一个新的 Postgres schema,并在该 schema 内创建(复制)所有存储客户数据的表。为一个租户进行的查询设置了 schema search_path,以便所有为该请求获取的数据现在都隐式地限定在该租户范围内。
为此,我们将深入探讨我们使用 Postgres schema进行多租户管理的经验(以及我们编写的 gem,Apartment)以及从这次经验中学到的一些教训。
最初,在确定了 Apartment 接口后,这种策略为我们提供了巨大的好处。我们可以引入新的客户,同时添加新的功能,并且不用担心数据隔离。我听说过无数创业公司的故事,其中客户之间的数据发生了泄露,而这简直不是我们需要担心的问题。
直到我们业务开始扩张了。。。
Schema 迁移 (Schema Migrations)
随着我们的客户基础增长到 100 多个客户,以及我们的应用程序增长到 100 多个表,我们开始注意到事情变得缓慢。我没有确切的数字来支持这一点,但我们发现 Postgres schema 的数量、这些 Postgres 中的表在执行迁移时被修改的大小,以及完成迁移所需的时间之间存在直接相关性。schema/表越多/越大,迁移所需的时间就越长。
众所周知,大表的索引更改可能会耗时,甚至导致表锁定。理想情况下,对于列添加之类的操作,你会得到恒定的 O(1) 性能。采用单独 schema 方法来做租户,你现在得到的是 O(N) 性能,其中 N=租户数。现在,当你遇到像索引添加这样不可预测的更改时,情况会变得更糟。我不确切知道如何用大 O 表示,但我认为它可能看起来像 O(WTFxN)。
迁移开始成为我们生存的祸根,这意味着部署开始变成一种麻烦。没有人希望在他们的部署过程中遇到阻碍,尤其是当我们尝试每天或更频繁地部署时。
数据库资源
我不是 PostgreSQL 内部工作原理的专家,但我们在使用这种租户策略时,需要扩展我们主生产数据库的程度似乎远远超过了使用列范围进行租户的任何其他服务。我猜测有一个上限 —— 如果不是硬性的,至少也是一个软性的、推荐的上限 —— 关于你在一个 Postgres 数据库中存储的表/索引等的数量。我们正在运行一个 RDS r3.4xl,每月成本约为3000 美元,用来容纳一个本可以存在于更小实例上的数据库。我们还没有具体深入这个问题,但我相当确定我们拥有的表的数量是一个问题。
客户端内存膨胀
这一点与 Ruby 特别相关,更具体地说是与 ActiveRecord 相关(但可能与任何具有类似实现的库相关)虽然已经进行了一些修复,但根本原因大部分仍未解决。ActiveRecord 在连接到数据库时,会遍历所有表并存储有关列的元数据,以便正确映射 Postgre s数据类型到 Ruby 数据类型。不幸的是,这种操作是通过遍历所有 schema 中的所有表,然后缓存所找到的内容来完成的。这不必要地增加了运行中客户端的负担,因为所有租户的类型完全相同,但我们无法配置 ActiveRecord 仅通过单一 schema 进行映射。
目前,我们任何一个 ruby 进程连接到数据库的那一刻,它的内存立即增长到大约 500MB。其他拥有类似数据量但不使用基于 schema 的租户管理的服务并没有这个问题。而随着我们向系统中添加的每一个客户(租户/架构),这个问题将会继续恶化。
记录 ID 和识别
将 schema 作为租户的一个主要缺点是,你的序列生成器将在每个租户中独立存在。这意味着,如果你有一个带租户的用户表,你现在有 X 个以 id=1 标识的用户(假设均匀分布,对于每一个生成的序列 id 也是如此)。如果你试图跨这些表进行 join 或对所有这些数据进行全局报告,你将遇到一些冲突。此外,如果你将这些数据复制到其他系统而没有将记录限定在租户 id 内,实际上可能会遇到一些权限问题。
怎么办
上述问题的最终结果使我们基本上放弃了使用单独 schema 的方法来处理多租户问题。对于我们今后构建的所有服务,我们使用了更传统的列作用域方法,并编写了我们自己的包装器,有效地模仿了 Apartment 为我们提供的按请求租户的方法。我们没有开源任何东西,因为实现和我们的场景太耦合了,但关于如何使用您选择的 ORM 实现这种数据隔离,文档资源并不少。
我想以我们的一些建议来结束,这些建议可能会帮助那些已经走了我们走过的路线的人,基于我们所做的进行改变。
选择合适的工具
最初,我们盲目地将所有客户数据放入他们各自的 schema 表中,而没有考虑他们存储的数据类型。如果你发现自己在讨论诸如「事件」、「日志」、「交易」等(即任何暗示高容量写入的东西),考虑使用更合适的工具,如分布式数据库 Citus、Cassandra 等,或者是带有 projection 的事件日志如 Kafka。这可以解决你可能遇到的许多迁移/索引问题。
从一个可信的源头创建租户
当前,Apartment gem 使用 rails 的 schema.rb 来生成新的租户。这是一个错误。当运行 schema 迁移时,这个文件在本地会发生变化,但它确切地代表了那个开发者在其本地数据库中的内容。例如,如果一个功能分支添加了实验性数据库列,这些列可能会在你无意中将 schema.rb 的更改提交到你的主开发分支时悄悄地发布到生产环境中。(这种情况比我们愿意承认的还要多)。这会将那些实验性列添加到下一个被创建的租户中。这就使得不同租户的 schema 完全不同了!如果那个实验性列在你下一次部署时变成了真实存在的列,这将把 schema migration 搞破,因为对那些租户来说,add_column 调用会失败,因为该列已经存在。
使用 UUID
正如上面提到的,使用序列 ID 进行租户化意味着你的系统中的对象没有全局唯一标识符。如果你开始跨租户聚合数据(例如用于报告),或尝试跨租户连接并且只依靠序列ID来进行标识,这将特别麻烦。为此,我们在所有表中添加了 uuid 列,现在只使用序列 ID 进行基于游标的分页。
结论
我希望上述经验教训能为你设计下一个多租户应用程序提供一些洞察。考虑到我们上面看到的各种问题,我现在无法推荐采用 Postgres schema 方法。我希望这篇文章能帮助大家避免我们遇到的一些陷阱,并且还在努力摆脱这些问题。
作者一开始的多租户方案是物理隔离,通过给不同租户单独的 schema。只是后来随着租户的增多,太多的 schema 导致了各种问题。所以后来又回到了给每张表加一个 tenant_id 的路上。但在一些有强制数据合规的场景,比如存不同医院的医疗数据,存不同公司的 HR 数据,物理隔离是必须的,这时也不得不面对采用物理隔离的方案。从作者的复盘中,我们可以看到,如果是采用物理的隔离方案:
- 使用 schema 进行隔离会撞到各种表数量的限制,所以使用 database 进行隔离或许是更好的方案。
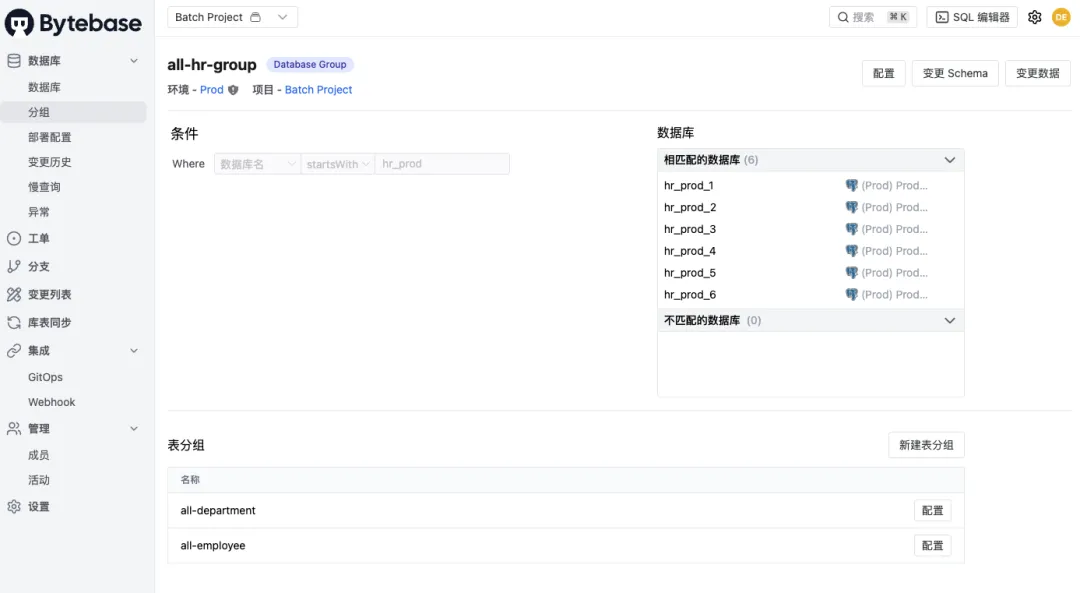
- 缺乏工具对隔离的 schema 进行批量变更。这个时候就可以考虑借助 Bytebase 的批量变更能力,把相同的数据库和数据库表归在一组里,进行批量操作,保证一致性。
💡 更多资讯,请关注 Bytebase 公号:Bytebase





![[DDD] ValueObject的一种设计落地及应用](https://img-blog.csdnimg.cn/direct/47abb37a392e4c64aa1e226af2bdb239.png)