文章目录
- 一、概念
- 二、线程不安全的原因
- 三、解决线程不安全问题--加锁(synchronized)
- synchronized的特性
- 四、死锁问题
- 五、内存可见性导致的线程安全问题
一、概念
想给出⼀个线程安全的确切定义是复杂的,但我们可以这样认为:
在多线程环境下程序能够按照预期的方式运行,并且不会出现数据竞争或不一致性的情况。因此,如果一个程序在单线程环境下能够正常运行,在多线程环境下也能够保持一致性和正确性,那么可以认为这个程序是线程安全的。反之,如果一个程序在多线程环境下出现了竞态条件、死锁、数据竞争等问题,那么可以认为这个程序是线程不安全的。
二、线程不安全的原因
首先观察一下下面的这段代码,判断他能否按预期输出10w?
package Thread;
//线程安全问题
public class ThreadDemo16 {
private static int count=0;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
Thread t2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
count++;
}
});
t1.start();
t2.start();
// 如果没有这俩 join, 肯定不⾏的. 线程还没⾃增完, 就开始打印了
//很可能打印出来的 count是初始值0,或者计算中间的值,总之是不确定的结果
t1.join();
t2.join();
// 预期结果应该是 10w
System.out.println("count: " + count);
}
}
运行之后我们发现打印的结果并不是10w,并且每一次运行的结果都是随机的,由此可见这个线程是不安全的,那么为什么会出现线程不安全这个问题呢?
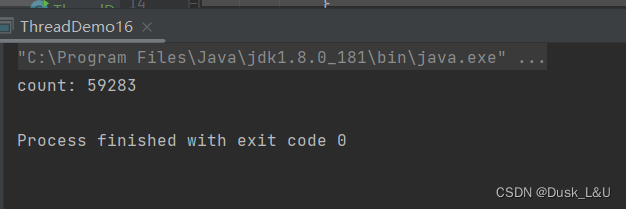
由此总结线程不安全的原因-----
- 【根本原因】==操作系统上的线程是“抢占式执行”的,线程调度是随机的,==这是线程不安全的一个主要原因。随机调度会导致在多线程环境下,程序的执行顺序不确定,程序员必须确保无论哪种执行顺序,代码都能正常运行。
- 【代码结构】共享资源:多个线程同时访问并修改共享的数据或资源。当多个线程同时访问和修改共享资源时容易引发竞态条件和数据不一致的问题。
①一个线程修改一个变量是安全的
②多个线程修改一个变量是不安全的
③多个线程修改不同变量是安全的- 【直接原因】多线程操作不是“原子的”。多线程操作中的原子性指的是一个操作是不可中断的,要么全部执行完成,要么都不执行,不能被其他线程干扰。这对于并发编程非常重要,因为如果一个操作在执行过程中被中断,可能导致数据不一致或者其他意外情况发生。(在上述多线程操作中,count++操作不是“原子的”,而是由多个CPU指令组成的,一个线程执行这些指令时,可能会在执行过程中被抢占,从而给其他线程“可乘之机”。要保证原子性操作,每个CPU指令都应该是“原子的”,即要么完全执行,要么完全不执行。)
- 内存可见性问题:在多线程环境下调用不可重入的函数(即不支持多线程调用的函数),可能导致数据混乱或程序崩溃。
- 指令重排序问题:在多线程环境下,由于编译器或处理器对指令进行重排序优化,可能导致预期之外的程序行为。
三、解决线程不安全问题–加锁(synchronized)
针对前述代码我们通过加锁解决线程安全问题
private static int count=0;
public static void main(String[] args) throws InterruptedException {
Object locker=new Object();
Thread t1=new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker){
count++;
}
}
});
Thread t2=new Thread(()->{
for (int i = 0; i < 50000; i++) {
synchronized (locker){
count++;
}
}
});
t1.start();
t2.start();
// 如果没有这俩 join, 肯定不⾏的. 线程还没⾃增完, 就开始打印了. 很可能打印出来的 cou
t1.join();
t2.join();
// 预期结果应该是 10w
System.out.println("count: " + count);
}
synchronized的特性
1)互斥
synchronized 会起到互斥效果, 某个线程执⾏到某个对象的 synchronized 中时, 其他线程如果也执⾏到同⼀个对象 synchronized 就会阻塞等待.
• 进⼊ synchronized 修饰的代码块, 相当于加锁
• 退出 synchronized 修饰的代码块, 相当于解锁
理解 “阻塞等待”.
针对每⼀把锁, 操作系统内部都维护了⼀个等待队列. 当这个锁被某个线程占有的时候, 其他线程尝试进⾏加锁, 就加不上了, 就会阻塞等待, ⼀直等到之前的线程解锁之后, 由操作系统唤醒⼀个新的线程,再来获取到这个锁.
注意:
• 上⼀个线程解锁之后, 下⼀个线程并不是⽴即就能获取到锁. ⽽是要靠操作系统来 “唤醒”. 这也就是操作系统线程调度的⼀部分⼯作.
• 假设有 A B C 三个线程, 线程 A 先获取到锁, 然后 B 尝试获取锁, 然后 C 再尝试获取锁, 此时 B 和 C
都在阻塞队列中排队等待. 但是当 A 释放锁之后, 虽然 B ⽐ C 先来的, 但是 B 不⼀定就能获取到锁,⽽是和 C 重新竞争, 并不遵守先来后到的规则.
synchronized的底层是使⽤操作系统的mutex lock实现的
2)可重入
我们来看一段代码
package Thread;
//下面这个代码能打印hello吗?
public class ThreadDemo17 {
public static void main(String[] args) {
Object lock=new Object();
Thread t=new Thread(()->{
synchronized (lock){//真正加锁,同时把计数器+1(初始为0,+1之后就说明当前这个对象被该线程加锁一次)同时记录线程是谁
synchronized (lock){//先判定当前加锁线程是否持有锁的线程,如果不是同一个线程,阻塞
//如果是同一个线程,就只是++计数器即可,没有其他操作
System.out.println("hello");
}//1 把计数器-1,由于计数器不为0,不会真的解锁
}//2---应该在2这里解锁,避免1和2之间的逻辑失去锁的保护,执行到这里,再次把计数器-1,此时计数器归零,真正解锁
//总之就是最外层的{进行加锁,最外层的}进行解锁
});
t.start();
}
}
能够打印hello
这段代码看起来有锁冲突,但是最终不会出现阻塞,关键在于,这两次加锁,其实是对同一个线程进行的;当前由于是同一个线程,此时锁对象就知道了第二次加锁的线程,就是持有锁的线程,第二次操作,就可以直接放行通过,不会线程阻塞,这个特性,称为“可重入”。可重入锁就是为了防止程序员在写代码时不小心写出来双重锁的效果而使代码出现问题,意思就是就算不小心写了那种双重锁代码,丰富的程序机制也不会让代码有问题。
对于可重入锁来说,内部会持有两个信息
1)当前这个锁是被哪个线程持有的
2)加锁次数的计数器
四、死锁问题
死锁是多线程中一类经典问题
加锁是能解决线程安全问题,但如果加锁方式不当,就可能产生死锁。
死锁的三种典型场景
- 一个线程一把锁
如果锁是不可重入锁,并且一个线程对这把锁加锁两次,就会出现死锁。(判定一个锁是可重入锁还是不可重入锁的关键在于是否允许同一个线程多次获取同一个锁。可重入锁允许同一个线程多次获取同一个锁,而不可重入锁则不允许。)
- 两个线程,两把锁 线程1获取到锁A,线程2获取到锁B,接下来,1尝试获取B,2尝试获取A,就同样出现死锁了。 一旦出现死锁,线程就”卡住“无法继续工作。
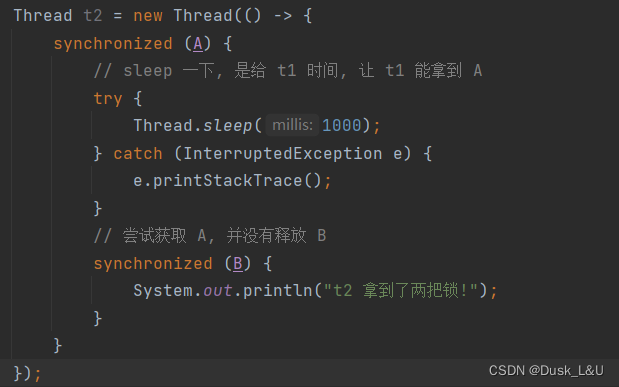
eg.//这是一个死锁代码,严重bug public class ThreadDemo18 { public static void main(String[] args) { Object A = new Object(); Object B = new Object(); Thread t1 = new Thread(() -> { synchronized (A) { // sleep 一下, 是给 t2 时间, 让 t2 也能拿到 B try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } // 尝试获取 B, 并没有释放 A synchronized (B) { System.out.println("t1 拿到了两把锁!"); } } }); Thread t2 = new Thread(() -> { synchronized (B) { // sleep 一下, 是给 t1 时间, 让 t1 能拿到 A try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } // 尝试获取 A, 并没有释放 B synchronized (A) { System.out.println("t2 拿到了两把锁!"); } } }); t1.start(); t2.start(); } }这个死锁问题也可以通过约定加锁顺序解决,先对A加锁,然后对B加锁
产生死锁的四个必要条件----
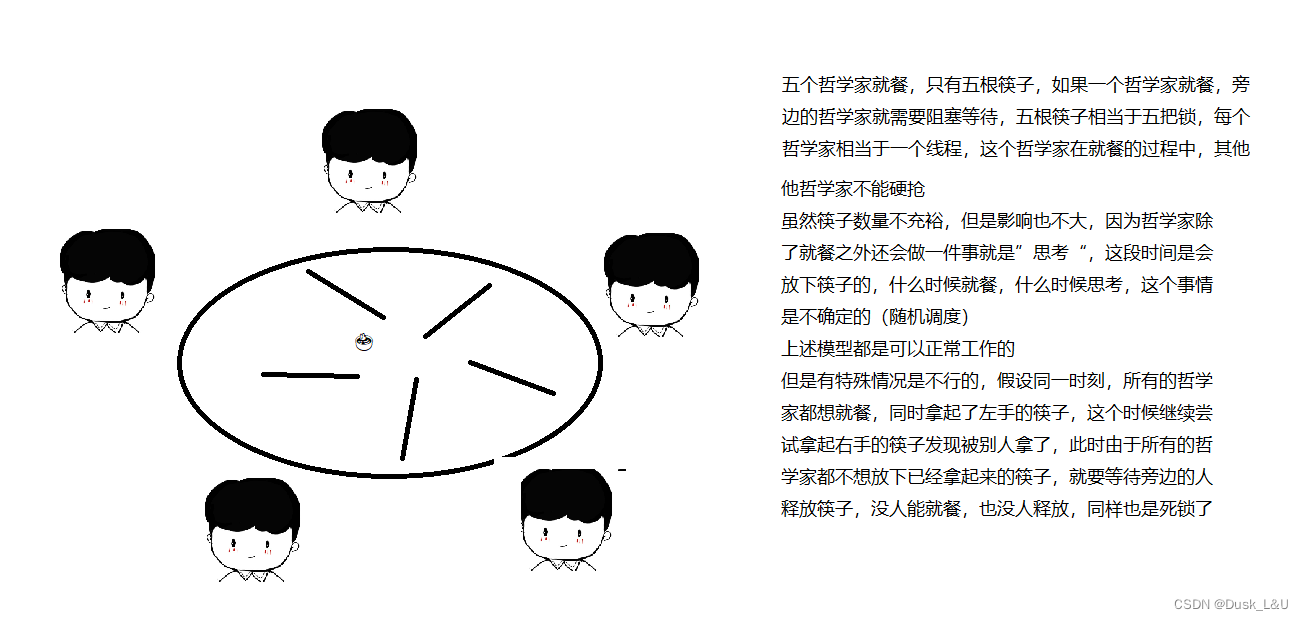
- N个线程M把锁(哲学家就餐问题)
- 互斥使用。获取锁的过程是互斥的,一个线程拿到这把锁,另一个线程也想获取,就需要阻塞等待。
- 不可抢占。一个线程拿到锁之后,只能主动解锁,不能让其他线程强行抢走锁。
- 请求保持。一个线程拿到锁A之后,在持有A的前提下,尝试获取B。
- 循环等待/环路等待。
想要解决死锁问题,核心思想是破坏上述的必要条件,只要破坏一个就好,前面2个条件是锁的基本特性,不好破坏,条件3需要看代码实际需求,也不太好破坏,只有循环等待最容易破坏。
只要指定一定的规则,就可以有效避免循环等待~
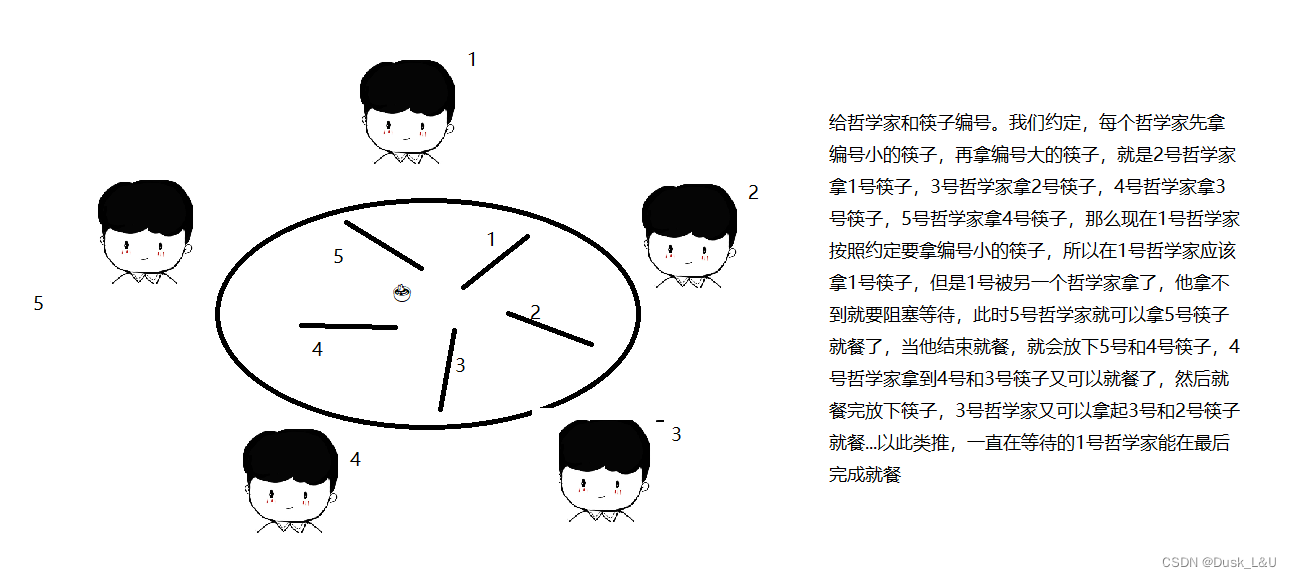
对上述哲学家就餐问题,指定加锁顺序,针对五把锁都进行编号,约定每个线程获取锁的时候,一定要先获取编号小的锁,后获取编号大的锁。

面试问题:谈谈你对死锁的理解?
前面四大点都是要点,需要逻辑严密,条理清楚的和面试官谈论
五、内存可见性导致的线程安全问题
如果一个线程写,一个线程读,是否会引起线程安全问题呢?我们来看下面这段代码
private static int flag=0;
public static void main(String[] args) {
Thread t1=new Thread(()->{
while(flag==0){
//循环里不做处理
}
System.out.println("让t线程结束");
});
Thread t2=new Thread(()->{
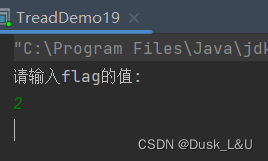
System.out.println("请输入flag的值:");
Scanner scanner=new Scanner(System.in);
flag=scanner.nextInt();
});
t1.start();
t2.start();//t2要等待用户输入,无论t1先启动还是t2先启动,等待用户输入的过程中,t1必然都是已经循环很多次了
}
当我们输入一个非0的值的时候会发现t1并没有真的结束,当下这个情况,也是bug
相当于t2修改了内存,但是t1没有看到这个内存的变化,就称为“内存可见性”问题
总的来说,一个线程循环,一个线程修改,在多线程的情况下,编译器对代码的优化做出了错误判断,本来期待编译器把读内存的操作优化掉,变成读寄存器中缓存的值,这样的优化,有助于提高我们循环的执行效率,并且编译器发现没有修改flag,编译器做了错误判断,那么在这样的情况下,t2通过用户输入进行修改flag会导致并未在t1中生效,就出现了不能让t1顺利结束的bug。
1)如果我们对循环里面做处理,让代码休眠10ms,会出现什么结果呢?
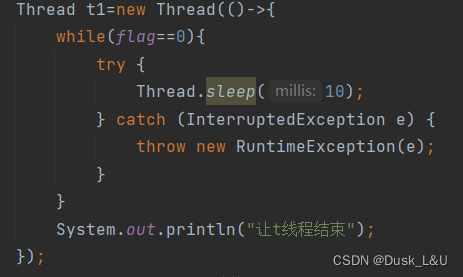
我们发现,输入一个非0的值的时候会发现t1线程结束
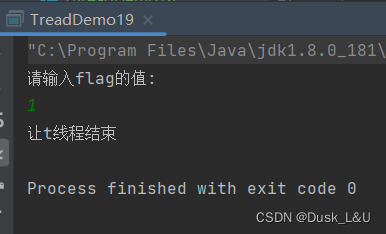
为什么会这样呢?
内存可见性高度依赖编译器的优化的具体实现,编译器啥时候触发优化是不确定的(尽量不要出现这种问题)意味着上述代码如果稍微改动可能结果截然不同,就如上述代码,不加sleep,一秒钟循环上百亿次,load操作的整体开销非常大,优化的迫切程度更多;加了sleep,load整体开销没那么大,优化的迫切程度就降低了。
2)给 flag 加上 volatile
private volatile static int flag=0;
// 执⾏效果
// 当⽤⼾输⼊⾮0值时, t1 线程循环能够⽴即结束.
java中提供了volatile就可以使上诉优化被强制关闭,可以确保每次循环条件都会重新从内存中读取数据;就是强制读取内存,开销是大了,效率是低了,数据正确性/逻辑正确性也提高了。
volatile关键字其中一个核心功能就是保证内存可见性,另一个功能,禁止指令重排序。
总结一下:volatile 和 synchronized 有着本质的区别. synchronized 能够保证原⼦性, volatile 保证的是内存可⻅性.
最后,码字不易,如果觉得对你有帮助的话请点个赞吧,关注我,一起学习,一起进步!