在C++里面有已经写好的标准模板库〈Standard Template Library),就是我们常说的STL库,实现了集合、映射表、栈、队列等数据结构和排序、查找等算法。我们可以很方便地调用标准库来减少我们的代码量。
size/empty 所有的STL容器都支持这两个方法,含义也相同
一、动态数组 vector
有些时候想开一个数组,但是却不知道应该开多大长度的数组合适,因为我们需要用到的数组可能会根据情况变动。这时候我们就需要用到动态数组。所谓动态数组,也就是不定长数组,数组的长度是可以根据我们的需要情况动态改变的。
C++中动态数组写作vector,C语言中没有标准库,这也是为什么参加比赛推荐用C++而不用C的原因。
1.vector基本用法
1.1引用库
#include <vector>
using namespace std;1.2构造一个动态数组
C++中直接构造一个vector的语句为: vector<T> vec。这样我们定义了一个名为vec的储存T类型数据的动态数组。其中T是我们数组要储存的数据类型,可以是int、float、double或者其他自定义的数据类型等等。初始的时候vec是空的。比如vector<int> a定义了一个储存整数的动态数组a。
1.3插入元素
C++中通过push_back()方法在数组最后面插入一个新的元素。
#include <vector>
using namespace std;
int main(){
vector<int> vec; // []初始为空
vec.push_back(1); // [1]
vec.push_back(2); // [1, 2]
vec.push_back(3); // [1, 2 ,3]
return 0;
}1.4获取长度、访问数组、修改数组
C++中通过size()方法获取vector的长度,通过[ ]操作直接访问vector中的元素,这一点和数组是一样的。
C++中修改vector中某个元素很简单,只需要用=给它赋值就好了,比如vec[1] = 3。
#include <vector>
#include <iostream>
using namespace std;
int main(){
vector<int> vec; // []初始为空
vec.push_back(1); // [1]
vec.push_back(2); // [1, 2]
vec.push_back(3); // [1, 2 ,3]
for (int i = 0; i < vec.size(); i++){
cout << vec[i] << " "; // 1 2 3
}
cout << endl;
vec[1] = 3; // [1, 3 ,2]
vec[2] = 2; // [1, 3 ,2]
for (int i = 0; i < vec.size(); i++){
cout << vec[i] << " "; // 1 3 2
}
return 0;
}1.5删除元素
和插入一样,删除元素也只能在动态数组的末端进行操作。C++中通过pop_back()方法删动态数组的最后一个元素。
#include <vector>
#include <iostream>
using namespace std;
int main(){
vector<int> vec; // []初始为空
vec.push_back(1); // [1]
vec.push_back(2); // [1, 2]
vec.push_back(3); // [1, 2 ,3]
for (int i = 0; i < vec.size(); i++){
cout << vec[i] << " "; // [1, 2 ,3]
}
cout << endl;
vec.pop_back(); // [1, 2]
vec.pop_back(); //[1]
for (int i = 0; i < vec.size(); i++){
cout << vec[i] << " "; // 1
}
return 0;
}1.6清空元素
C++中都只需要调用clear()方法就可清空vector 。
C++中vector的clear()只是清空vector,并不会清空开的内存。用一种方法可以清空vector的内存:
vector<int> vec;
vector<int>().swap(vec);1.7vector方法总结

2.vector的高级用法
2.1动态数组存储自定义结构类型

2.2使用构造函数快速构建vector
下面的代码,我们在定义一个vector的时候,调用构造函数,第一个参数表示初始的动态数组的长度,第二个参数表示初始的数组里面每个元素的值。如果不传入第二个参数,那么初始的值都是0。
int n = 10; //数组长度
vector<int> vec(n, 1); //初始值全赋为12.3二维动态数组
vector<vector<int > vec2,这样就定义了一个二维的动态数组。
注意:<int>中间有一个空格,这个空格一定要加上,否则在一些老版本的编译器上将不能通过编译。
#include <vector>
#include <iostream>
using namespace std;
int main(){
int n = 5;
vector<vector<int> > vec2;
for (int i = 0; i < n; i++){ //规定一维大小为n
vector<int> x(i+1, 1);
vec2.push_back(x); //一维一维的赋值
}
for (int i = 0; i < n; i++){
for (int j = 0; j < vec2[i].size(); j++){
cout << vec2[i][j] << " ";
}
cout << endl;
}
return 0;
}
2.4快速构建二维动态数组
二维动态数组的每一维的长度都可以不一样,可以是任意形状的。
借助构造函数,我们可以快速构造一个n行m列的动态数组,每个元素的初始值是0: vector<vector<int > vec2(n,vector<int>(m,0))。
3.vector习题
3.1打印锯齿矩阵
题目:
锯齿矩阵是指每一行包含的元素个数不相同的矩阵,比如:
1 3 5 2 6 12 2 3 4
3 1 6 2 7
读入若干对整数(, y),表示在第行的末尾加上一个元素g。输出最终的锯齿数组。初始时矩阵为空。
输入格式
第一行输入两个整数n, m(1 ≤n, m ≤ 10000),其中n表示锯齿数组的行数,m表示插入的元素总数。
接下来一共m行,每行两个整数x, y(1≤x≤n,0≤y≤10000),表示在第x行的末尾插入一个y元素输出格式
—共输出n行,每行若干个用空格分隔的整数。如果某行没有任何元素,则输出一个空行。样例输入:
3 121 3
2 2
2 3
2 4
3 1
3 6
1 5
1 2
1 6
3 2
3 7
1 1
样例输出3 5 2 6 1
2 3 4
1 6 2 7
#include <iostream>
#include <vector>
using namespace std;
vector<int> mat[10005]; //二维vector
int main(){
int n, m;
cin >> n >> m;
for (int i = 0; i < m; i++){
int x, y;
cin >> x >> y;
mat[x].push_back(y); //第x行插入元素y
}
for (int i = 1; i <= n; i++){
for (int j = 0; j < mat[i].size(); j++){
if (j != mat[i].size()-1){
cout << mat[i][j] << " ";
} else {
cout << mat[i][j];
}
}
cout << endl;
}
return 0;
}3.2堆积木
题目
蒜头君有n块积木,编号分别为1到n。一开始,蒜头把第i块积木放在位置i。
蒜头君进行m次操作,每次操作,蒜头把位置b上的积木整体移动到位置α上面。
比如1位置的积木是1,2位置的积木是2,那么把位置2的积木移动到位置1后,位置1上的积木从下到上依次为1,2。
输入格式
第一行输入2个整数 n, m(1 <n ≤ 10000,0 ≤ m ≤ 10000)。接下来m行,每行输入2个整数 a, b(1≤a,b≤n),如果a,b相等则本次不需要移动。
输出格式
输出n行,第i行输出位置主从下到上的积木编号,如果该行没有积木输出一行空行。样例输入1
2 2
1 2
1 2
样例输出1
1 2
样例输入24 4
3 14 3
2 4
2 2
样例输出2
2 4 3 1
#include <vector>
#include <iostream>
using namespace std;
vector<int> v[10005];
int main(){
int n, m, a, b;
cin >> n >> m;
//初始化,第i个积木的最底层积木是i
for (int i = 1; i <= n; i++){
v[i].push_back(i);
}
for (int i = 0; i < m; i++){
cin >> a >> b;
if (a == b){
continue;
}
for (int i = 0; i < v[b].size(); i++){
v[a].push_back(v[b][i]);//第a个积木加b
}
vector<int>().swap(v[b]); //清空b积木
}
for (int i = 1; i <= n; i++){
for (int j = 0; j < v[i].size(); j++){
if (j != v[i].size()-1){
cout << v[i][j] << " ";
} else {
cout << v[i][j];
}
}
cout << endl;
}
return 0;
}4.vector补充
1.二维数组
vector<int> b[233]; 相当于第一维长233,第二位长度动态变化的int数组
2.front/back
front函数返回vector的第一个元素,等价于*a.begin() 和 a[0]。
back函数返回vector的最后一个元素,等价于和 a[a.size() – 1]。
vector<int> v({1, 2, 3});
cout << v.front() << " " << *v.begin() << " " << v[0] << endl;
cout << v.back() << " " << v[v.size()-1] << endl;二、集合 set
集合是数学中的一个基本概念,通俗地理解,集合是由一些不重复的数据组成的。比如{1,2,3}就是一个有1,2,3三个元素的集合。
在C++中我们常用的集合是有序集合set 。
1.set基本用法
1.1引用库
#include <set>
using namespace std;1.2构造一个集合
C++中直接构造一个set的语句为: set<T> s。这样我们定义了一个名为s的、储存T类型数据的集合,其中T是集合要储存的数据类型。初始的时候s是空集合。比如set<int> aa,set<string> bbb等等。
1.3插入元素
C++中用insert()函数向集合中插入一个新的元素。注意如果集合中已经存在了某个元素,再次插入不会产生任何效果,集合中是不会出现重复元素的。
#include <set>
#include <string>
using namespace std;
int main(){
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("America"); // {"China", "America"}
country.insert("France");// {"China", "America", "France"}
return 0;
}1.4删除元素
C++中通过erase()函数删除集合中的一个元素,如果集合中不存在这个元素,不进行任何操作。
#include <set>
#include <string>
using namespace std;
int main(){
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
country.erase("America"); // {"China", "France"}
country.erase("England"); // {"China", "France"}
return 0;
}1.5判断元素是否存在
C++中如果你想知道某个元素是否在集合中出现,你可以直接用count()函数。如果集合中存在我们要查找的元素,返回1,否则会返回0。
#include <set>
#include <string>
#include <iostream>
using namespace std;
int main(){
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
if (country.count("China")){
cout << "China belong to country" << endl;
}
return 0;
}1.6遍历元素
C++通过迭代器可以访问集合中的每个元素,迭代器就好像一根手指指向set中的某个元素。通过操作这个手指,我们可以改变它指向的元素。通过 * (解引用运算符,不是乘号的意思)操作可以获取迭代器指向的元素。通过 ++ 操作让迭代器指向下一个元素,同理 -- 操作让迭代器指向上一个元素。
迭代器的写法比较固定, set<T>::iterator it 就定义了一个指向set<T>这种集合的迭代器it,T是任意的数据类型。其中::iterator是固定的写法。
begin函数返回容器中起始元素的迭代器,end函数返回容器的尾后迭代器(最后一位再往后一位)。
#include <set>
#include <string>
#include <iostream>
using namespace std;
int main(){
set<string> country; // {}
country.insert("China"); // {"China"}
country.insert("America"); // {"China", "America"}
country.insert("France"); // {"China", "America", "France"}
for (set<string>::iterator it = country.begin(); it != country.end(); it++){
cout << *it << endl; //set是从小到大遍历
}
return 0;
}注意,在C++中遍历set是从小到大遍历的,也就是说set会帮我们排序的。
1.7清空
C++中调用clear()函数就可清空set,同时会清空set占用的内存。
1.8C++ set函数总结
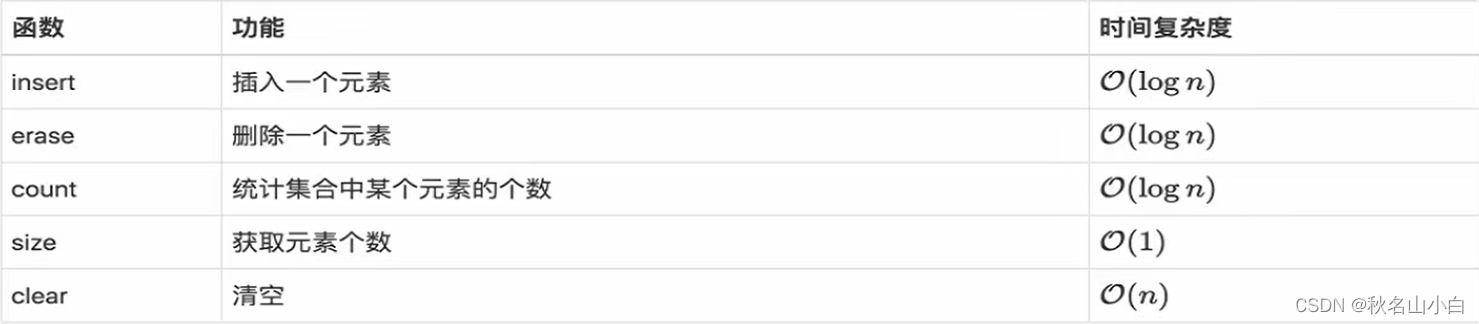
在set中插入、删除、查找某个元素的时间复杂度都是O(log n),并且内部元素是有序的,
2.set与结构体
set经常会配合结构体来使用,用 set 来储存结构体和 vector 有些区别。正如我们前面所说的那样, set是需要经过排序的。系统自带的数据类型有默认的比较大小的规则,而我们自定义的结构体,系统是不可能知道这个结构体比较大小的方式的。所以我们需要用一种方式来告诉系统怎么比较这个结构体的大小。其中一种方法叫做运算符重载,我们需要重新定义小于符号。
2.1重载<
struct Node {
int x, y;
bool operatro< (const Node &rhs) const {
if (x == rhs.x){
return y < rhs.y;
} else {
return x < rhs.x;
}
}
};- operator< 表示我们要重载运算符<,可以看成是一个函数名。
- rhs 是“right hand side”的简称,有右操作数的意思,这里我们定义为一个const引用。因为该运算符重载定义在结构体内部,左操作数就当前调用operator<的对象。
- 特别要注意,不要漏掉最后的const。const函数表示不能对其数据成员进行修改操作,并且const对象不能调用非const成员函数,只允许调用const成员函数。
- 上面重载规定了排序方式为,优先按照 ×从小到大排序,如果×相同,那么再按照 y从小到大排序。经过了<运算符重载的结构体,我们就可以比较两个Node对象的大小了,因此可以直接储存在set中了。
2.2set存储二维坐标上点的集合
#include <set>
#include <string>
#include <iostream>
using namespace std;
/**
6
5 6
1 2
2 1
3 4
1 2
1 1
**/
struct Point {
int x, y;
bool operator< (const Point &rhs) const {
if (x == rhs.x){
return y < rhs.y;
} else {
return x < rhs.x;
}
}
};
int main(){
int n;
set<Point> v;
cin >> n;
for (int i = 0; i < n; i++){
Point temp;
cin >> temp.x >> temp.y;
v.insert(temp);
}
for (set<Point>::iterator it = v.begin(); it != v.end(); it++){
cout << it->x << " " << it->y << endl;
}
return 0;
}3.set练习题
3.1破案
题目:
(如果本市有这个特征的人就视为是本市的)。但本市人口太多,又不能一个一个排查。警察又急需这条信息来缩小范围,所以警察特来找到聪明的你来帮忙解决这个棘手的问题。
输入格式
第一行将会输入两个数字n(1≤n≤2*10^5)和m(1 <m ≤ 10^4)。n代表本市的人口数目,m代表犯罪团伙的数量。
后面n行每行有3个数字代表本市每个人的身高、体重、年龄。然后会有m行每行有3个数字代表犯罪团伙每个人的身高、体重、年龄。
输出格式
输出m行,每行输出一个"yes"或"no”,"yes"代表这个罪犯是本市的,“no"代表这个罪犯不是本市的。
样例输入3 2
166 50 30178 60 23
132 40 15
167 50 30
178 60 23
样例输出
no
yes
#include <iostream>
#include <set>
using namespace std;
struct people{
int h;
int w;
int age;
people(int _h, int _w, int _age){
h = _h;
w = _w;
age = _age;
}
bool operator< (const people &rhs) const {
if (h != rhs.h){
return h < rhs.h;
}
if (w != rhs.w){
return w < rhs.w;
}
return age < rhs.age;
}
};
set<people> s;
int main(){
int n, m, h, w, age;;
cin >> n >> m;
for (int i = 0; i < n; i++){
cin >> h >> w >> age;
s.insert(people(h, w, age));
}
for (int i = 0; i < m; i++){
cin >> h >> w >> age;
if (s.count(people(h, w, age))){
cout << "yes" << endl;//有重复的,说明犯罪人在本市
} else {
cout << "no" << endl;
}
}
return 0;
}3.2集合的并
题目:
给你两个集合,计算其并集,即{A}+{B}。注:{A}+{B}中不允许出现重复元素,但是{A}与{B}之间可能存在相同元素。
输入格式
输入数据分为三行,第一行有两个数字n, m(0<n, m ≤10000),分别表示集合A和集合B的元素个数。后两行分别表示集合A和集合B。每个元素为不超出int范围的整数,每个元素之间用一个空格隔开。
输出格式
输出一行数据,表示合并后的集合,要求从小到大输出,每个元素之间用一个空格隔开。
样例输入11 2
1
2 3
样例输出11 2 3
样例输入21 2
1
1 2
样例输出21 2
#include <set>
#include <iostream>
using namespace std;
set<int> c;
int main(){
int n, m, x;
cin >> n >> m;
for (int i = 0; i < n+m; i++){
cin >> x;
c.insert(x);
}
int cnt = 0;
for (set<int>::iterator it = c.begin(); it != c.end(); it++){
if (cnt != c.size()-1){
cout << *it << " ";
cnt++;
} else {
cout << *it << endl;
}
}
return 0;
}3.3学英语
题目:
询问蒜头君一个单词,如果背过这个单词,告诉这个单词的意思,不然说还没有背过。
单词是由连续的大写或者小写字母组成。
注意单词中字母大小写是等价的。比如 You和 you是一个单词。
输入格式
首先输入一个n(1<n≤100000)表示事件数。
接下来n行,每行表示一个事件。
每个事件输入为一个整数d和一个单词word(单词长度不大于20),用空格隔开。
如果d=0,表示蒜头君记住了word这个单词,
如果d=1,表示这是个测试,测试蒜头君是否认识单词word
事件的输入是按照时间先后顺序输入的。
输出格式
对于花椰妹的每次测试,如果蒜头君认识这个单词,输出一行Yes,否则输出一行No。
样例输入1
5
0 we
0 are
1 family
0 Family
1 Family
样例输出1
No
Yes
样例输入2
4
1 jisuanke
0 Jisuanke
0 JISUANKE
1 JiSuanKe
样例输出2
No
Yes
#include <iostream>
#include <set>
#include <string>
using namespace std;
set<string> s;
string word;
int main(){
int n, test;
cin >> n;
for (int i = 0; i < n; i++){
cin >> test >> word;
for (int j = 0; j < word.size(); j++){
if (word[j] >= 'A' && word[j] <= 'Z'){
word[j] += 32;
}
}
if (!test){ //0 记住了单词
s.insert(word);
} else { //1 测试
if(s.count(word)){ //记住了
puts("Yes");
} else {
puts("No");
}
}
}
return 0;
}4.#include <set>补充
头文件set主要包括set和multiset两个容器,set不允许重复,multiset允许重复
4.1begin/end
返回集合的首、尾迭代器,时间复杂度均为O(1)。
s.begin() 是指向集合中最小元素的迭代器。
s.end() 是指向集合中最大元素的下一个位置的迭代器。换言之,就像vector一样,是一个“前闭后开”的形式。因此s.end()是指向集合中最大元素的迭代器。
4.2find
s.find(x) 在集合s中查找等于x的元素,并返回指向该元素的迭代器。若不存在,则返回s.end()。时间复杂度为O(logn)。
4.3lower_bound/upper_bound
这两个函数的用法与find类似,但查找的条件略有不同,时间复杂度为 O(logn)。
- s.lower_bound(x) 查找大于等于x的元素中最小的一个,并返回指向该元素的迭代器。
- s.upper_bound(x) 查找大于x的元素中最小的一个,并返回指向该元素的迭代器。
4.4count
s.count(x) 返回集合s中等于x的元素个数,时间复杂度为 O(k +logn),其中k为元素x的个数。
multiset<int> b; //元素可以重复
b.insert(1);
b.insert(2);
b.insert(1);
cout << b.count(1) << endl; // 2 返回集合中元素为1的元素个数 5.#include <unordered_set>
#include <iostream>
#include <unordered_set>
using namespace std;
/**
set 有序集合
unordered_set无序集合
**/
int main(){
unordered_set<int> a; //哈希表,不能存重复元素
unordered_multiset<int> b; //可以存重复
return 0;
}三、映射表 map
映射是指两个集合之间的元素的相互对应关系。通俗地说,就是一个元素对应另外一个元素。
比如有一个姓名的集合{"Tom""Jone", "Mary"},班级集合{1,2}。姓名与班级之间可以有如下的映射关系:class("Tom")=1,class("Jone")= 2,class("Mary")= 1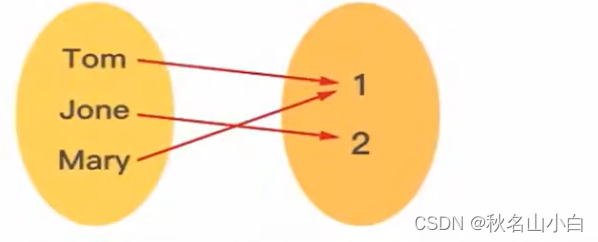
我们称其中的姓名集合为 关键字集合(key) ,班级集合为 值集合(value)。
在C++中我们常用的映射是 map 。
1.map基本用法
1.1引用库
#include <map>
using namespace std;1.2构造一个映射
在C++中,我们构造一个map 的语句为: map<T1,T2> m; 。这样我们定义了一个名为m的从T1类型到T2类型的映射。初始的时候m是空映射。比如 map<string,int> m 构建了一个字符串到整数的映射,这样我们可以把一个字符串和一个整数关联起来。
1.3插入一对映射 pair
在C++中通过insert()函数向集合中插入一个新的映射,参数是一个pair 。
pair是一个标准库类型,定义在头文件utility 中。可以看成是有两个成员变量first和second的结构体,并且重载了<运算符(先比较first大小,如果一样再比较second)。当我们创建一个pair时,必须提供两个类型。
我们可以像这样定义一个保存string和int的pair
pair<string, int> p;make_pair(v1,v2)函数返回由v1和v2初始化的pair,类型可以从v1和v2的类型推断出来。
我们向映射中加入新映射对的时候就是通过插入pair来实现的。如果插入的 key之前已经存在了,将不会用插入的新的value替代原来的value ,也就是这次插入是无效的。
#include <map>
#include <utility>
#include <string>
using namespace std;
int main(){
//dict是一个string到int的映射,存放每个名字对应的班级号,初始时为空
map<string, int> dict;
dict.insert(make_pair("Tom", 1)); // {"Tom"->1}
dict.insert(make_pair("Jone", 2)); // {"Tom"->1, "Jone"->2}
dict.insert(make_pair("Mary", 1)); // {"Tom"->1, "Jone"->2, "Mary"->1}
dict.insert(make_pair("Tom", 2)); // {"Tom"->1, "Jone"->2, "Mary"->1}
return 0;
}1.4访问映射
在C++中访问映射和数组一样,直接用[ ]就能访问。比如dict["Tom"]就可以获取"Tom"的班级了。而这里有一个比较神奇的地方,如果没有对"Tom"做过映射的话,此时你访问dict["Tom"],系统将会自动为"Tom"生成一个映射,其value为对应类型的默认值(比如int的默认值是0, string 的默认值是空字符串)。
并且我们可以之后再给映射赋予新的值,比如dict["Tom"]= 3,这样为我们提供了另一种方便的插入手段。实际上,我们常常通过下标访问的方式来插入映射,而不是通过用insert插入一个pair来实现。
#include <map>
#include <iostream>
#include <string>
using namespace std;
int main(){
//dict是一个string到int的映射,存放每个名字对应的班级号,初始时为空
map<string, int> dict;
dict["Tom"] = 1; // {"Tom"->1}
dict["Jone"] = 2; // {"Tom"->1, "Jone"->2}
dict["Mary"] = 1; // {"Tom"->1, "Jone"->2, "Mary"->1}
cout << "Mary的value:" << dict["Mary"] << endl;
return 0;
}1.5判断关键字是否存在
在C++中,如果你想知道某个关键字是否被映射过,你可以直接用count()函数。如果关键字存在,返回1,否则会返回0。
#include <map>
#include <iostream>
#include <string>
using namespace std;
int main(){
map<string, int> dict;
dict["Tom"] = 1; // {"Tom"->1}
dict["Jone"] = 2; // {"Tom"->1, "Jone"->2}
dict["Mary"] = 1; // {"Tom"->1, "Jone"->2, "Mary"->1}
if (dict.count("Mary")){
cout << "Mary的value:" << dict["Mary"] << endl;
} else {
cout << "Mary has no class" << endl;
}
return 0;
}1.6遍历映射
map的迭代器的定义和set差不多, map<T1,T2>::iterator it 就定义了一个迭代器,其中T1、T2分别是key和value的类型。
C++通过迭代器可以访问集合中的每个元素。这里迭代器指向的元素是一个pair,有first和second 两个成员变量,分别代表一个映射的key和value .
我们用 ->运算符来获取值, it->first和(*it).first的效果是一样的,就是获取迭代器it指向的pair里first成员的值。
#include <map>
#include <iostream>
#include <string>
using namespace std;
int main(){
map<string, int> dict;
dict["Tom"] = 1; // {"Tom"->1}
dict["Jone"] = 2; // {"Tom"->1, "Jone"->2}
dict["Mary"] = 1; // {"Tom"->1, "Jone"->2, "Mary"->1}
for (map<string, int>::iterator it = dict.begin(); it != dict.end(); it++){
// first是关键字,second是对应的值
cout << it->first << "->" << it->second << endl; //按关键字从小到大遍历
}
return 0;
}注意,在C++中遍历map是按照关键字从小到大遍历的,这一点和set有些共性。
1.7清空
C++中只需要调用clear()函数就可清空map和其占用的内存。
1.8C++ set函数总结

2.二维map
2.1map套用set
全校有很多班级,每个班级每个人都会有中文名。现在我们需要用一种方式来记录全校的同学的名字。如果直接用一个set记录,对于重名的同学,那么就没办法分辨了。
我们可以把全校的班级进行编号,对每一个班级建立一个set,也就是每个班级都映射成一个set,这样就能分辨不同班级的同名同学了。对于同班的同学来说,一般很少有重名的。
map<int,set<string> > s 就定义上面描述的数据结构,和二维vector 一样,两个> >中间的空格不能少了。
这样我们就可以进行插入和查询了。比如,
- 对2班的yuhaoran同学,s[2].insert("yuhaoran")。
- 查询yuhaoran是不是一个2班的人,s[2].count(" yuhaoran")
- 还可以把他从2班删除,s[2].erase("yuhaoran")
2.2map套用map
上面的结构没有办法解决同班同名的情况。实际上,如果同班同名,单单通过名字本身是无法分辨的,需要通过其他特征来分辨。所以为了简单起见,我们只需要记录每个班级同名的人的个数。
这时候,我们把里面的set改成map即可。
map<int,map<string,int > > s 。
2班有一个yuhaoran,s[2]["yuhaoran"]++。2班又转来了一个yuhaoran ,s[2]["yuhaoran"]++。
现在2班—共有多少个yuhaoran ?
cout << s[2]["yuhaoran"] << endl;
3.map练习题
3.1藏书
题目:
小明问这么多书籍,到底有多少本不一样的书,每样书的名字是什么?(因为有的书名是一样的,所以我们把它们视为同样的书)
输入格式
第—行是书籍总量n(1≤n ≤10^6)。
然后有n行书名(书名是一个英文字符串,字符串的长度小于100,中间没有空格)。
输出格式
第一行是不同书籍的数量,然后按照书名的字典序输出书名和数量。
样例输入4
EnglishMath
Chinese
Chinese
样例输出3
Chinese 2English 1
Math 1
#include <iostream>
#include <map>
#include <string>
using namespace std;
map<string, int> book;
int main(){
int n;
string name;
cin >> n;
for (int i = 0; i < n; i++){
cin >> name;
book[name]++;
}
cout << book.size() << endl;
for (map<string, int>::iterator it = book.begin(); it != book.end(); it++){
cout << it->first << " " << it->second << endl;
}
return 0;
}3.2最多重复数
题目:
这样一个面试题:
给定n个整数,求里面出现次数最多的数,如果有多个重复出现的数,求出值最大的一个。
输入格式
第一行输入一个整数n(1 ≤n ≤100000),接下来一行输入n个int范围内的整数。
输出格式
输出出现次数最多的数和出现的次数,中间用一个空格隔开,如果有多个重复出现的数,输出值最大的那个。
样例输入1
5
1 1 2 3 4
样例输出1
1 2
样例输入2
10
9 10 27 4 9 10 3 1 2 6
样例输出2
10 2
#include <iostream>
#include <map>
using namespace std;
map<int, int> m;
int main(){
int n, num, ans1, ans2;
cin >> n;
for (int i = 0; i < n; i++){
cin >> num;
m[num]++;
}
ans2 = 0; //最多重复次数
for (map<int, int>::iterator it = m.begin(); it != m.end(); it++){
if ((it->second >= ans2)){
ans2 = it->second;
ans1 = it->first;
}
}
cout << ans1 << " " << ans2 << endl;
return 0;
}3.3水果店
题目:
蒜头君告诉你每一笔销售记录的水果名称,产地和销售的数量,请你帮他生成明细表。
输入格式
第一行是一个整数N(0<N≤1000),表示工有N次成功的交易。其后有N行数据,每行表示—次交易,由水果名称(小写字母组成,长度不超过100),水果产地(小写字母组成,长度不超过100)和交易的水果数目(正整数,不超过1000)组成。
输出格式
请你输出一份排版格式正确(请分析样本输出)的水果销售情况明细表。这份明细表包括所有水果的产地、名称和销售数目的信息。
水果先按产地分类,产地按字母顺序排列;同一产地的水果按照名称排序,名称按字母顺序排序。
样例输入
5
apple shandong 3
pineapple guangdong 1sugarcane guangdong 1
pineapple guangdong 3
pineapple guangdong 1
样例输出
guangdong
|----pineapple(5)
|----sugarcane(1)
shandong
|----apple(3)
#include <iostream>
#include <string>
#include <map>
using namespace std;
//产地,名称->数目
map<string, map<string, int> > mp;
string name, area;
int num;
int main(){
int n;
cin >> n;
for (int i = 0; i < n; i++){
cin >> name >> area >> num;
mp[area][name] += num;
}
for (map<string, map<string, int> >::iterator it1 = mp.begin(); it1 != mp.end(); it1++){
cout << (it1->first) << endl;
for (map<string, int>::iterator it2 = (it1->second).begin(); it2 != (it1->second).end(); it2++){
cout << " |----" << (it2->first)<< "(" << (it2->second) << ")" << endl;
}
}
return 0;
} 4.map补充
4.1[]操作符
h[key] 返回key映射的value的引用,时间复杂度为O(logn)。我们可以很方便地通过h[key]来得到key对应的value,还可以对h[key]进行赋值操作,改变key对应的value。
#include <iostream>
#include <vector>
#include <map>
using namespace std;
int main(){
map<string, int> a;
a["lxy"] = 2;
cout << a["lxy"] << endl; //2
a.insert({"aa", 11});
map<string, vector<int>> b;
b["one"] = vector<int>({1, 2, 3, 4});
cout << b["one"][3] << endl; //4
return 0;
}四、队列和栈
1.#include <queue>
头文件queue主要包括循环队列queue和优先队列priority_queue两个容器
1.1循环队列 queue
先进先出
queue<int> q;
q.push(1); //队尾插入
q.pop(); //队头弹出
cout << q.front() << endl; //返回队头元素 0
cout << q.back() << endl; //返回队尾元素 1
queue<pair<int, int>> p; //pair类型,存二元组 1.2优先队列 priority_queue
无序,默认取大的
注意:优先队列类型为自定义结构体时,要重载运算符
- struct rec{…}; priority_queue<rec> q; //默认大根堆,结构体rec中必须定义小于号
- struct rec{...};priority_queue<rec, vector<rec>, greater<rec>> q; //小根堆,结构体rec中必须定义大于号
struct Rec{
int a, b;
bool operator< (const Rec& t) const {
return a < t.a;
}
};
priority_queue<Rec> d;
d.push({1, 2});
priority_queue<int> a; //默认大根堆
a.push(5); //插入元素
cout << a.top() << endl; //取最大值
a.pop(); //删除最大值
priority_queue<int, vector<int>, greater<int>> b; //小根堆 1.3除了队列和栈都有clear函数
队列通过重新初始化来清空
q = queue<int>();2.#include <deque>
双端队列deque是一个支持在两端高效插入或删除元素的连续线性存储空间。它就像是vector和queue的结合。
- 与vector相比,deque在头部增删元素仅需要O(1)的时间;
- 与queue相比,deque像数组一样支持随机访问。[] 随机访问
#include <iostream>
#include <deque>
using namespace std;
int main(){
deque<int> a;
a.push_back(1); //队尾插入
a.push_front(2); //队头插入
a.pop_back(); //队尾删除
a.pop_front(); //队首删除
a[0]; //随机访问一个元素
a.clear(); //清空元素
return 0;
}3.#include <stack>
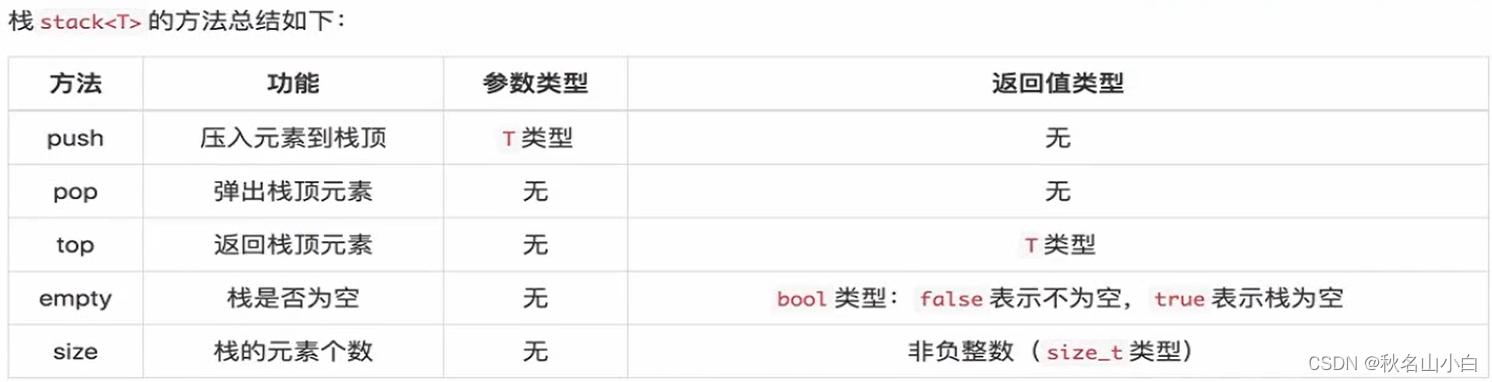
栈是先进后出
#include <iostream>
#include <stack>
using namespace std;
int main(){
stack<int> stk;
stk.push(1); //栈顶插入元素
cout << stk.top() << endl; //返回栈顶元素
stk.pop(); //弹出栈顶元素
return 0;
}
五、补充
1.pair
功能:pair将一对值(T1和T2)组合成一个值,
这一对值可以具有不同的数据类型(T1和T2),
两个值可以分别用pair的两个公有函数first和second访问。
#include <iostream>
using namespace std;
int main(){
pair<int, string> a;
a = {3, "lxy"};
cout << a.first << " " << a.second << endl;
a = make_pair(4, "abc");
cout << a.first << " " << a.second << endl;
return 0;
}
typedef pair<int,int> PII;//pair 是c++中的类型模板
//pair对象可以存储两个值,这两个值可以是不同数据类型
//存储的数据既可以是基本数据类型,也可以是自定义数据类型
PII a[11000];
//法二
pair <int, int> a[11000];