我默记这段路的酸楚,等来年春暖花开之时再赏心阅读
—— 24.3.24
python基础综合案例
数据可视化 — 折线图可视化
一、折线图案例
1.json数据格式
2.pyecharts模块介绍
3.pyecharts快速入门
4.数据处理
5.创建折线图
1.json数据格式
1.什么是json
2.掌握如何使用json进行数据转化
1.什么是json
JSON是一种轻量级的数据交互格式,可以按照JSON指定的格式去组织和封装数据
JSON本质上是一个带有特定格式的字符串
主要功能:json就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互,类似:
国际通用语言——英语
中国各民族各地区的通用语言——普通话
2.掌握如何使用json进行数据转化
①json格式的数据格式要求:(字典)
{“name”:"admin","age":18}
②也可以是:(字典列表)
[{"name":"admin","age":18},{"name":"root","age":16},{"name":"张三","age":20}]
JSON可以看作是把一个字典或者一个字典列表全部转换成字符串
正常定义为字典或字典列表导入包和方法后就可以进行自动转换
3.演示
''' 演示JSON数据和Python字典的相互转换 ''' import json # 准备列表,列表内每一个元素都是字典,将其转换为JSON data1 = [{"name":"张三","age":22},{"name":"李四","age":13},{"name":"王五","age":16}] json_str1 = json.dumps(data1,ensure_ascii=False) # 如果不写中文,则不需要参数ensure_ascii print(json_str1) print(type(json_str1)) # 准备字典,将字典转换为JSON data2 = {"name":"JayZhou","addr":"台北"} json_str2 = json.dumps(data2,ensure_ascii=False) print(json_str2) print(type(json_str2)) # 将JSON字符串转换为Python数据类型字典列表[{k:v,k:v},{k:v,k:v},{k:v,k:v}] str = '[{"name": "张三", "age": 22}, {"name": "李四", "age": 13}, {"name": "王五", "age": 16}]' json_str3 = json.loads(str) print(json_str3) print(type(json_str3)) # 将JSON字符串转换为Python数据类型列表{k:v,k:v} str2 = '{"name":"JayZhou","addr":"台北"}' json_str4 = json.loads(str2) print(json_str4) print(type(json_str4)) # 通过dumps和loads两个json包下的方法就可以将python中的字典或列表转换为json字符串通过dumps和loads两个json包下的方法就可以将python中的字典或列表转换为json字符串
总结
1.json:是一种轻量级的数据交互格式,采用完全独立于编程语言的格式来存储和表示数据(就是字符串)
python语言有很大的优势是因为JSON可以直接和Python的字典或者字典列表进行无缝转换
2.json格式数据转化
通过json.dumps(data)可以把python中的数据转化为json字符串
data = json.dumps(data)
如果其中有中文可以带上:ensure_ascii=False参数来确保中文正常转换
通过json.loads(data)方法把json数据转化为python中的列表或字典
data = json.loads(data)
2.pyecharts模块介绍
如果想要做出数据可视化效果图,可以借助pyecharts模块来完成
概况:
Echarts是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可,而Python是门富有表达力的语言,很适合用于数据处理,当数据分析遇上数据可视化时pyecharts诞生了
pyecharts模块安装
使用在前面学过的pip命令即可快速安装PyEcharts模块
pip install pyecharts
总结
1.开发可视化图表使用的技术栈是:
Echarts框架的Python版本:PyEcharts包
2.如何安装PyEcharts包:
pip install pyecharts
3.如何查看官方示例:
打开官方画廊:
https://gallery.pyecharts.org/#/README
3.pyecharts快速入门
1.构建一个基础的折线图
2.使用全局配置项设置属性
1.构建一个基础的折线图
基础折线图
①导包,导入Line功能构建折线图对象
from pyecharts.charts import Line
②得到折线图对象
line = Line()
③添加x轴数
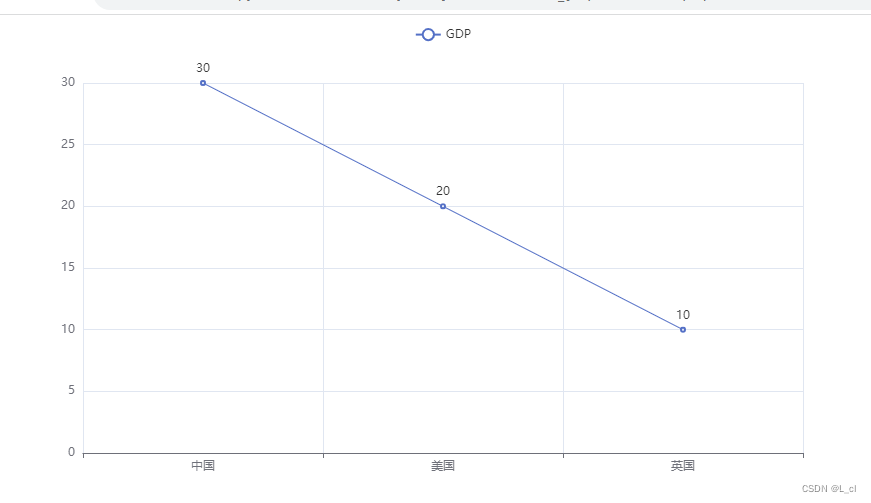
line.add_xaxis(["中国","美国","英国"])
⑤添加y轴数据
line.add_yaxis("GDP",[30,20,10])
⑥生成图表
line.render() # 生成图表后会在软件包内生成一个文件,运行这个文件就是生成的图表,可以运行文件也可以在文件右上角打开它
2.使用全局配置项设置属性
pyecharts有哪些配置选项
pyecharts模块中有很多的配置选项,常用到2个类别的选项
全局配置选项(表结构)
系列配置选项(数据)
全局配置选项 set_global_opts方法
这里全局配置选型可以通过set_global_opts方法来进行配置,相应的选项和选项的功能如下
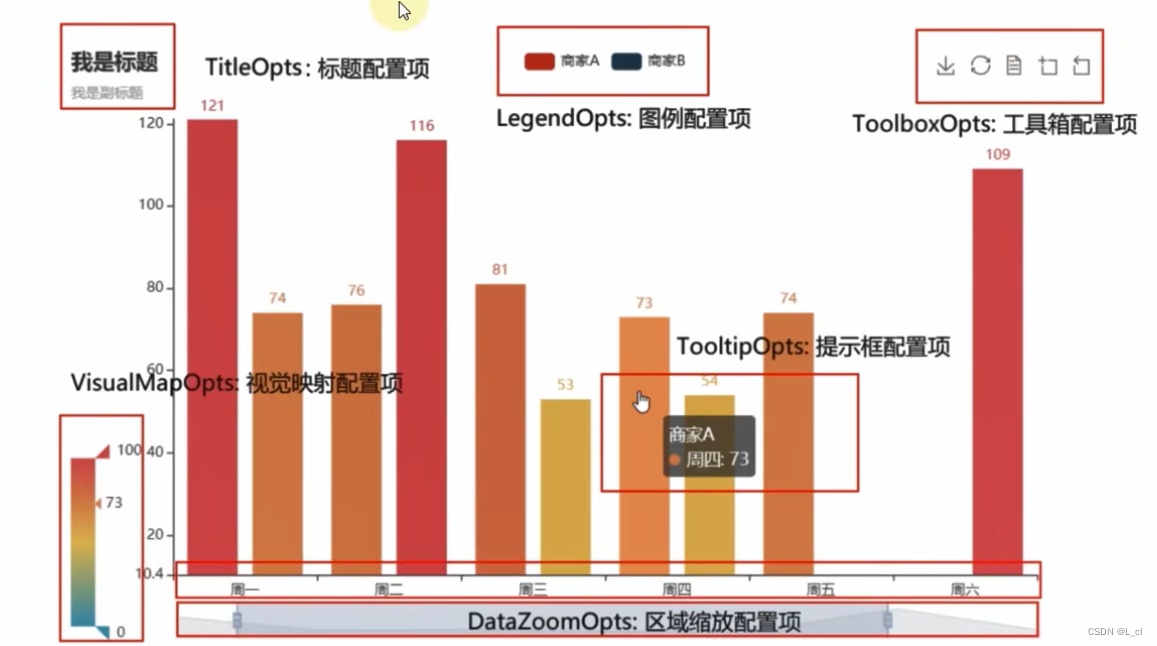
3.示例
# ①导包,导入Line功能构建折线图对象 from pyecharts.charts import Line # 导包,导入控制标题的包 from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts,VisualMapOpts # 得到折线图对象,Line对象 line = Line() # ③给折线图对象添加x轴数 line.add_xaxis(["中国","美国","英国"]) # ④给折线图对象添加y轴数据 line.add_yaxis("GDP",[30,20,10]) # ⑤设置全局变量配置项set_global_opts来设置 line.set_global_opts( # ctrl+p 可以查看方法中传递的参数 title_opts=TitleOpts(title = "GDP展示",pos_left="center",pos_bottom="1%"), # 控制标题及位置 legend_opts=LegendOpts(is_show=True), # 是否显示图例(默认显示) toolbox_opts=ToolboxOpts(is_show=True), # 工具箱是否显示 visualmap_opts=VisualMapOpts(is_show=True) # 视觉映射是否显示 ) # ⑥通过render方法,将代码生成为图像 line.render()运行成功后,会自动在包里生成一个文件
总结
1.pyecharts模块中有很多的配置选项,常用到三个类别的选项:
全局配置选项
系列配置选项
2.全局配置项能做什么?
配置图表的标题
配置图例
配置鼠标移动效果
配置工具栏
等整体配置项
4.数据处理
1.能够通过json模块对数据进行处理
json可视化
根据json可视化掌握数据的层级关系
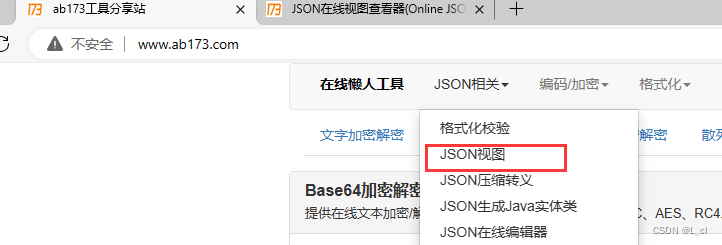
进入网站www.ab173.com
这是一个懒人软件,点击JSON相关、点击JSON视图
# 处理数据
# 美国疫情数据
f_us = open("D:/2LFE/Desktop/Python/资料/可视化案例数据/折线图数据/美国.txt","r",encoding="utf-8")
us_data = f_us.read() # 美国的全部内容
# 小日本疫情数据
f_jp = open("D:/2LFE/Desktop/Python/资料/可视化案例数据/折线图数据/日本.txt","r",encoding="utf-8")
jp_data = f_jp.read() # 日本的全部内容
# 印度疫情数据
f_in = open("D:/2LFE/Desktop/Python/资料/可视化案例数据/折线图数据/日本.txt","r",encoding="utf-8")
in_data = f_in.read() # 印度的全部内容
# 去掉不合JSON规范的开头,每个国家的数据不规范的内容不相同,需查看文档进行改变
us_data = us_data.replace("jsonp_1629344292311_69436(","")
jp_data = jp_data.replace("jsonp_1629350871167_29498(","")
in_data = in_data.replace("jsonp_1629350745930_63180(","")
# 去掉不合JSON规范的结尾,结尾不规范数据相同,注意变量名的修改
us_data = us_data[:-2] # 序列的切片
jp_data = jp_data[:-2] # 序列的切片
in_data = in_data[:-2] # 序列的切片
# JSON转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']
# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]
# 获取确诊数据,用于y轴,取2020年(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]5.生成图表
# 生成图表
line = Line() # 构建折线图对象,Line()的图表对象
# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是三个国家公用的,所以一个国家的就好
# 添加y轴数据,y轴数据不共用,label_opts功能:当前这个图表中标签属性是否显示
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据
6.设置全局选项
# 设置全局选项
line.set_global_opts(
# 标题设置
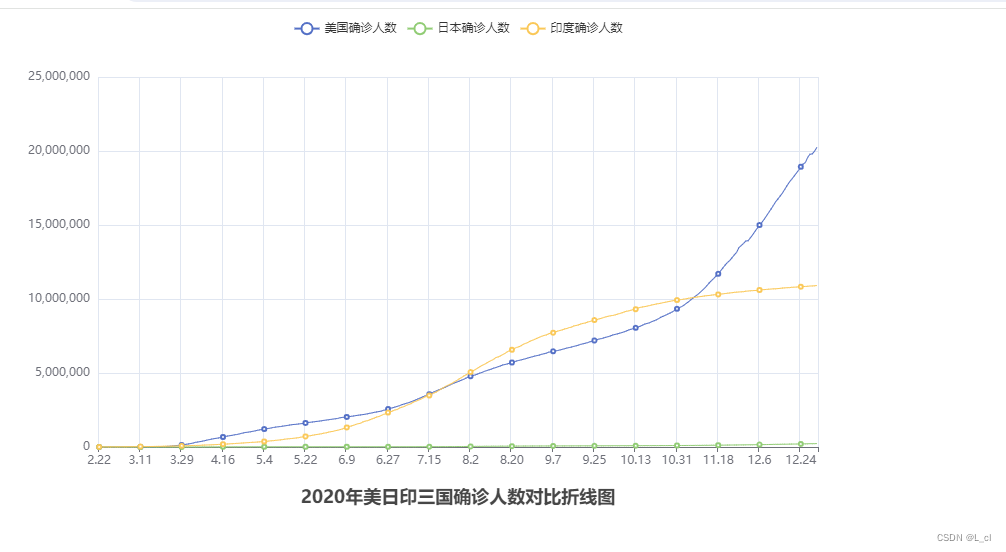
title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%")
)7.整体代码
# 演示可视化需求1:折线图开发
# 导入包
import json # josn可视化包
from pyecharts.charts import Line # 读取文件的函数,导入line功能
from pyecharts.options import TitleOpts, LabelOpts # 标题设置Title包,系列属性LabelOpts包
# 处理数据
# 美国疫情数据
f_us = open("E:\python.learning\折线图数据\美国.txt","r",encoding="utf-8")
us_data = f_us.read() # 美国的全部内容
# 小日本疫情数据
f_jp = open("E:\python.learning\折线图数据\日本.txt","r",encoding="utf-8")
jp_data = f_jp.read() # 日本的全部内容
# 印度疫情数据
f_in = open("E:\python.learning\折线图数据\印度.txt","r",encoding="utf-8")
in_data = f_in.read() # 印度的全部内容
# 去掉不合JSON规范的开头,每个国家的数据不规范的内容不相同,需查看文档进行改变
us_data = us_data.replace("jsonp_1629344292311_69436(","")
jp_data = jp_data.replace("jsonp_1629350871167_29498(","")
in_data = in_data.replace("jsonp_1629350745930_63180(","")
# 去掉不合JSON规范的结尾,结尾不规范数据相同,注意变量名的修改
us_data = us_data[:-2] # 序列的切片
jp_data = jp_data[:-2] # 序列的切片
in_data = in_data[:-2] # 序列的切片
# JSON转Python字典
us_dict = json.loads(us_data)
jp_dict = json.loads(jp_data)
in_dict = json.loads(in_data)
# 获取trend key
us_trend_data = us_dict['data'][0]['trend']
jp_trend_data = jp_dict['data'][0]['trend']
in_trend_data = in_dict['data'][0]['trend']
# 获取日期数据,用于x轴,取2020年(到314下标结束)
us_x_data = us_trend_data['updateDate'][:314]
jp_x_data = jp_trend_data['updateDate'][:314]
in_x_data = in_trend_data['updateDate'][:314]
# 获取确诊数据,用于y轴,取2020年(到314下标结束)
us_y_data = us_trend_data['list'][0]['data'][:314]
jp_y_data = jp_trend_data['list'][0]['data'][:314]
in_y_data = in_trend_data['list'][0]['data'][:314]
# 生成图表
line = Line() # 构建折线图对象,Line()的图表对象
# 添加x轴数据
line.add_xaxis(us_x_data) # x轴是三个国家公用的,所以一个国家的就好
# 添加y轴数据,y轴数据不共用,label_opts功能:当前这个图表中标签属性是否显示
line.add_yaxis("美国确诊人数", us_y_data, label_opts=LabelOpts(is_show=False)) # 添加美国的y轴数据
line.add_yaxis("日本确诊人数", jp_y_data, label_opts=LabelOpts(is_show=False)) # 添加日本的y轴数据
line.add_yaxis("印度确诊人数", in_y_data, label_opts=LabelOpts(is_show=False)) # 添加印度的y轴数据
# 设置全局选项
line.set_global_opts(
# 标题设置
title_opts=TitleOpts(title="2020年美日印三国确诊人数对比折线图", pos_left="center", pos_bottom="1%")
)
# 调用render方法,生成图表
line.render() # 折线图对象.render方法
# 关闭文件对象
f_us.close()
f_in.close()
f_jp.close()运行结果:


![[iOS]GCD(一)](https://img-blog.csdnimg.cn/direct/06108a8e4d07487a8ae5822647f1b3bb.png)