1、Dropout
Dropout是一种正则化技术,通过防止特征的协同适应,可用于减少神经网络中的过拟合。
Dropout的效果非常好,实现简单且不会降低网络速度,被广泛使用。
特征的协同适应指的是在训练模型时,共同训练的神经元为了相互弥补错误,而相互关联的现象,在神经网络中这种现象会变得尤其复杂。
协同适应会转而导致模型的过度拟合,因为协同适应的现象并不会泛化未曾见过的数据。
Dropout从解决特征间的协同适应入手,有效地控制了神经网络的过拟合。
Dropout在每次训练中,按照一定概率 p ,随机地抑制一些神经元的更新,相应地,按照概率 1-p 保留一些神经元的更新。
当神经元被抑制时,它的前向传播结果被置为0,而不管相应的权重和输入数据的数值大小。
被抑制的神经元在反向传播中,也不会更新相应权重,也就是说被抑制的神经元在前向传播和反向传播中都不起任何作用。
通过随机的抑制一部分神经元,可以有效防止特征的相互适应。
2、Dropout的实现方法
Dropout的实现方法非常简单,参考下面代码:
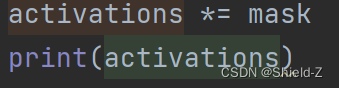
①生成一个随机数矩阵activations,表示神经网络中隐藏层的激活值。

②构建了一个参数 p=0.5 的伯努利分布,并从中采样一个由伯努利变量组成的掩码矩阵mask。
【伯努利变量是只有0和1两种取值可能性的离散变量】

③将mask和activations逐元素相乘,mask中数值为0的变量会将相应的激活值置为0,无论这一激活值本来的数值多大都不会参与到当前网络中更深层的计算,而mask中数值为1的变量则会保留相应的激活值。
输出为:

3、Dropout在训练模式和测试模式下的区别
因为Dropout对神经元的抑制是按照 p 的概率随机发生的,所以使用了Dropout的神经网络在每次训练中,学习的几乎都是一个新的网络。
另外的一种解释是Dropout在训练一个共享部分参数的集成模型。
为了模拟集成模型的方法,使用了Dropout的网络需要使用到所有的神经元。
所以在测试时,Dropout将激活值乘上一个尺度缩放系数 1-p 以恢复在训练时按概率p随机地丢弃神经元所造成的尺度变换,其中的 p 就是在训练时抑制神经元的概率。
在实践中(同时也是PyTorch的实现方式),通常采用Inverted Dropout 的方式。
在训练时对激活值乘上尺度缩放系数 1 / 1-p ,而在测试时则什么都不需要做。
Dropout会在训练和测试时做出不同的行为,PyTorch的torch.nn.Module 提供了 train 方法和 eval 方法,通过调用这两个方法可以将网络设置为训练模式或测试模式。
这两个方法只对Dropout这种训练和测试不一致的网络层起作用,而不影响其他的网络层,(后面介绍的 BatchNormalization也是训练和测试步骤不同的网络层。)
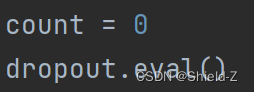
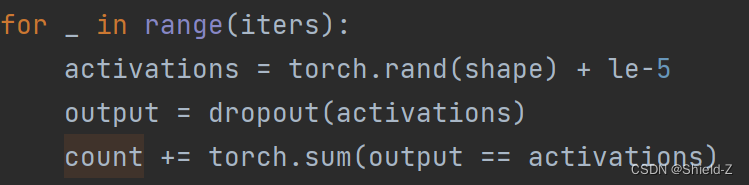
下面通过两个实验说明Dropout在训练模式和测试模式下的区别。

①执行了统计dropout影响到的神经元数量,注意因为PyTorch的Dropout采用了Inverted Dropout。所以在count += torch.sum(output == activations * (1/(1-p)))对activations乘上了 1 /(1-p),以应对Dropout的尺度变化。


结果发现它大约影响了50%的神经元,这一数值和我们设置的 p = 0.5基本一致。换句话说,p的数值越高,训练中的模型就越精简。
②统计了Dropout在测试时影响到的神经元数量,结果发现它并没有影响任何神经元,也就是说Dropout在测试时并不改变网络的结构。