二叉树
与链表类似,二叉树的基本单元是节点,每个节点包含值、左子节点引用和右子节点引用。
/* 二叉树节点结构体 */
struct TreeNode {
int val; // 节点值
TreeNode *left; // 左子节点指针
TreeNode *right; // 右子节点指针
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};
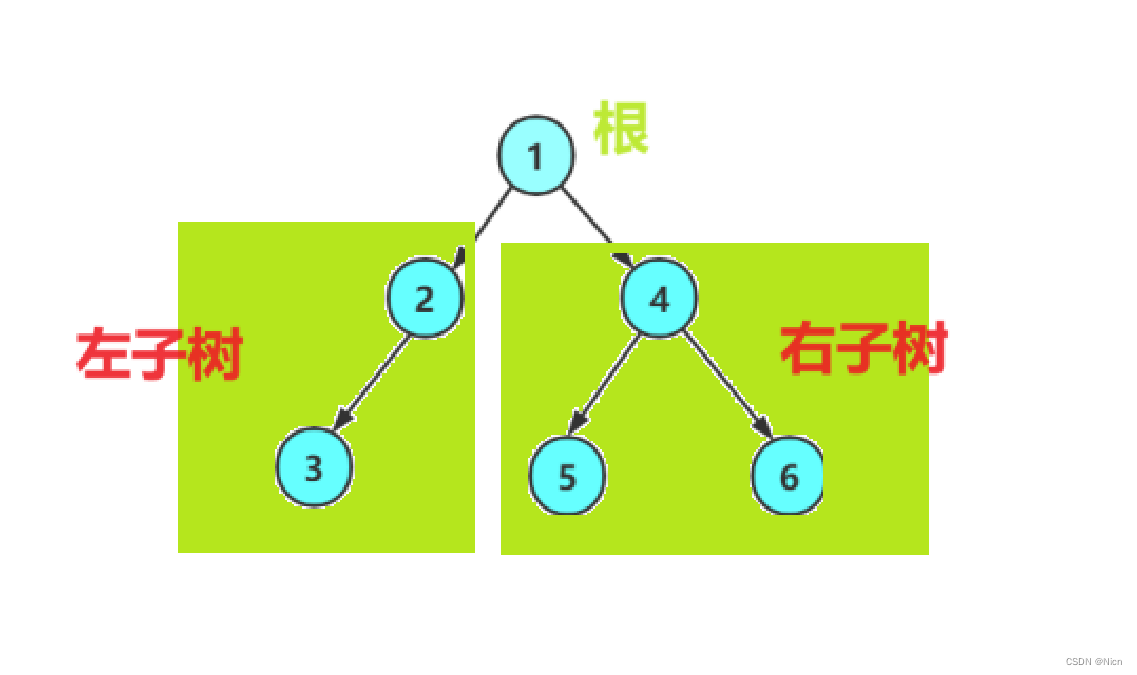
每个节点都有两个引用(指针),分别指向左子节点和右子节点,该节点被称为这两个子节点的父节点 。当给定一个二叉树的节点时,将该节点的左子节点及其以下节点形成的树称为该节点的左子树 ,同理可得右子树。
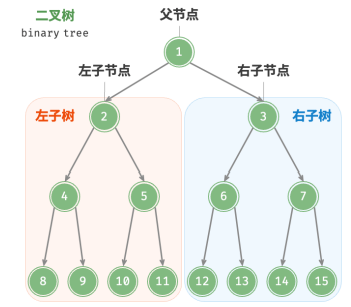
在二叉树中,除叶节点外,其他所有节点都包含子节点和非空子树。
如果将“节点 2”视为父节点,则其左子节点和右子节点分别是“节点 4”和“节点 5”,左子树是“节点 4 及其以下节点形成的树”,右子树是“节点 5 及其以下节点形成的树”。
二叉树常见术语
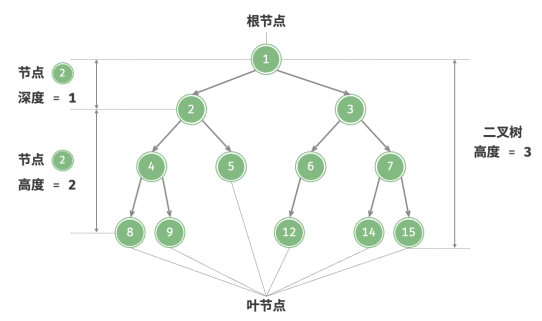
根节点:位于二叉树顶层的节点,没有父节点。
叶节点:没有子节点的节点,其两个指针均指向 None 。
边 edge:连接两个节点的线段,即节点引用(指针)。
节点所在的层:从顶至底递增,根节点所在层为 1 。
节点的度:节点的子节点的数量。在二叉树中,度的取值范围是 0、1、2 。
二叉树的高度:从根节点到最远叶节点所经过的边的数量。
节点的深度:从根节点到该节点所经过的边的数量。
节点的高度:从距离该节点最远的叶节点到该节点所经过的边的数量。
通常将“高度”和“深度”定义为“经过的边的数量”,但有些题目或教材可能会将其定义为“经过的节点的数量”。在这种情况下,高度和深度都需要加 1 。
二叉树基本操作
1.初始化二叉树
/* 初始化二叉树 */
// 初始化节点
TreeNode* n1 = new TreeNode(1);
TreeNode* n2 = new TreeNode(2);
TreeNode* n3 = new TreeNode(3);
TreeNode* n4 = new TreeNode(4);
TreeNode* n5 = new TreeNode(5);
// 构建节点之间的引用(指针)
n1->left = n2;
n1->right = n3;
n2->left = n4;
n2->right = n5;
2.插入与删除节点
与链表类似,在二叉树中插入与删除节点可以通过修改指针来实现。
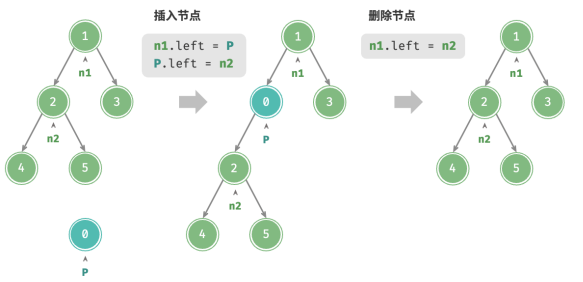
插入节点可能会改变二叉树的原有逻辑结构,而删除节点通常意味着删除该节点及其所有子树。因此,在二叉树中,插入与删除通常是由一套操作配合完成的,以实现有实际意义的操作。
常见二叉树类型
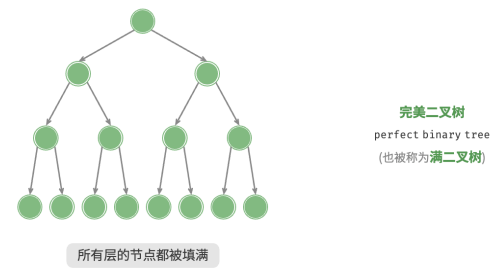
1.完美二叉树
所有层的节点都被完全填满。在完美二叉树中,叶节点的度为 0 ,其余所有节点的度都为 2 ;若树的高度为 ℎ ,则节点总数为 2^ℎ+1 − 1 ,呈现标准的指数级关系。
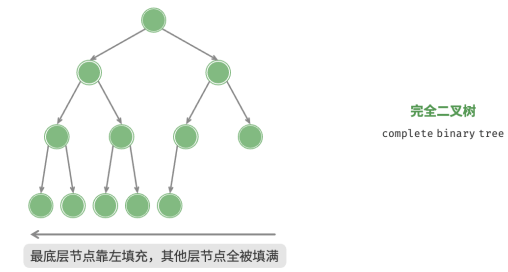
2.完全二叉树
只有最底层的节点未被填满,且最底层节点尽量靠左填充。
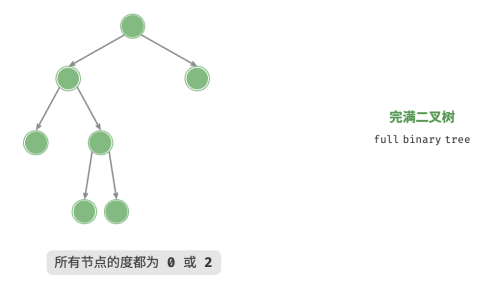
3.完满二叉树
除了叶节点之外,其余所有节点都有两个子节点。
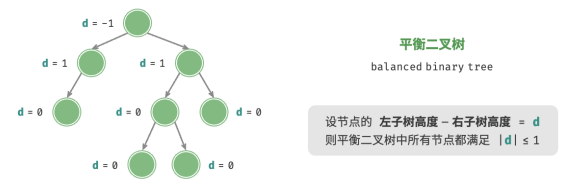
4. 平衡二叉树
任意节点的左子树和右子树的高度之差的绝对值不超过 1。
二叉树的退化
当二叉树的每层节点都被填满时,达到“完美二叉树”;而当所有节点都偏向一侧时,二叉树退化为“链表”。
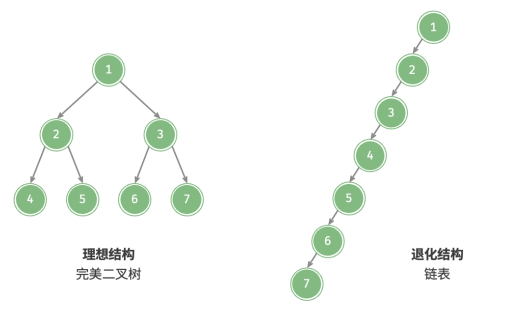
完美二叉树是理想情况,可以充分发挥二叉树“分治”的优势。
链表则是另一个极端,各项操作都变为线性操作,时间复杂度退化至 𝑂(𝑛) 。
在最佳结构和最差结构下,二叉树的叶节点数量、节点总数、高度等达到极大值或极小值:

二叉树遍历
从物理结构的角度来看,树是一种基于链表的数据结构,因此其遍历方式是通过指针逐个访问节点。然而,树是一种非线性数据结构,这使得遍历树比遍历链表更加复杂,需要借助搜索算法来实现。
二叉树常见的遍历方式包括层序遍历、前序遍历、中序遍历和后序遍历等。
层序遍历
层序遍历(level‑order traversal)从顶部到底部逐层遍历二叉树,并在每一层按照从左到右的顺序访问节点。
层序遍历本质上属于广度优先遍历(breadth‑first traversal),也称广度优先搜索(breadth‑first search, BFS),它体现了一种“一圈一圈向外扩展”的逐层遍历方式。
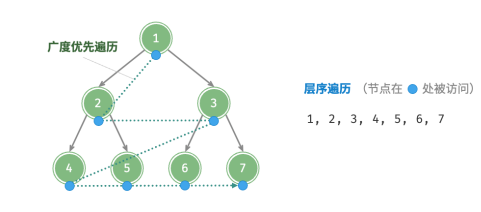
广度优先遍历通常借助“队列”来实现。
队列遵循“先进先出”的规则,而广度优先遍历则遵循“逐层推进”的规则,两者背后的思想是一致的。
/**
* File: binary_tree_bfs.cpp
* Created Time: 2022-11-25
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 层序遍历 */
vector<int> levelOrder(TreeNode *root) {
// 初始化队列,加入根节点
queue<TreeNode *> queue;
queue.push(root);
// 初始化一个列表,用于保存遍历序列
vector<int> vec;
while (!queue.empty()) {
TreeNode *node = queue.front();
queue.pop(); // 队列出队
vec.push_back(node->val); // 保存节点值
if (node->left != nullptr)
queue.push(node->left); // 左子节点入队
if (node->right != nullptr)
queue.push(node->right); // 右子节点入队
}
return vec;
}
/* Driver Code */
int main() {
/* 初始化二叉树 */
// 这里借助了一个从数组直接生成二叉树的函数
TreeNode *root = vectorToTree(vector<int>{1, 2, 3, 4, 5, 6, 7});
cout << endl << "初始化二叉树\n" << endl;
printTree(root);
/* 层序遍历 */
vector<int> vec = levelOrder(root);
cout << endl << "层序遍历的节点打印序列 = ";
printVector(vec);
return 0;
}

时间复杂度为 𝑂(𝑛) :所有节点被访问一次,使用 𝑂(𝑛) 时间,其中 𝑛 为节点数量;
空间复杂度为 𝑂(𝑛) :在最差情况下,即满二叉树时,遍历到最底层之前,队列中最多同时存在(𝑛 + 1)/2 个节点,占用 𝑂(𝑛) 空间。
前序、中序、后序遍历
相应地,前序、中序和后序遍历都属于深度优先遍历(depth‑first traversal),也称深度优先搜索 (depth‑first search, DFS),它体现了一种“先走到尽头,再回溯继续”的遍历方式。
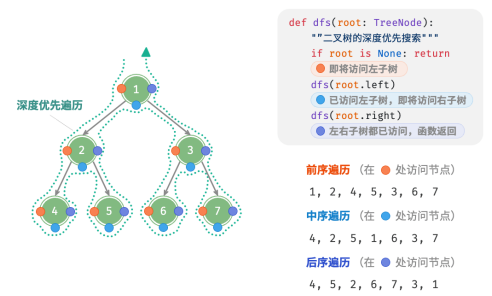
深度优先遍历就像是绕着整棵二叉树的外围“走”一圈,在每个节点都会遇到三个位置,分别对应前序遍历、中序遍历和后序遍历。
/**
* File: binary_tree_dfs.cpp
* Created Time: 2022-11-25
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
// 初始化列表,用于存储遍历序列
vector<int> vec;
/* 前序遍历 */
void preOrder(TreeNode *root) {
if (root == nullptr)
return;
// 访问优先级:根节点 -> 左子树 -> 右子树
vec.push_back(root->val);
preOrder(root->left);
preOrder(root->right);
}
/* 中序遍历 */
void inOrder(TreeNode *root) {
if (root == nullptr)
return;
// 访问优先级:左子树 -> 根节点 -> 右子树
inOrder(root->left);
vec.push_back(root->val);
inOrder(root->right);
}
/* 后序遍历 */
void postOrder(TreeNode *root) {
if (root == nullptr)
return;
// 访问优先级:左子树 -> 右子树 -> 根节点
postOrder(root->left);
postOrder(root->right);
vec.push_back(root->val);
}
/* Driver Code */
int main() {
/* 初始化二叉树 */
// 这里借助了一个从数组直接生成二叉树的函数
TreeNode *root = vectorToTree(vector<int>{1, 2, 3, 4, 5, 6, 7});
cout << endl << "初始化二叉树\n" << endl;
printTree(root);
/* 前序遍历 */
vec.clear();
preOrder(root);
cout << endl << "前序遍历的节点打印序列 = ";
printVector(vec);
/* 中序遍历 */
vec.clear();
inOrder(root);
cout << endl << "中序遍历的节点打印序列 = ";
printVector(vec);
/* 后序遍历 */
vec.clear();
postOrder(root);
cout << endl << "后序遍历的节点打印序列 = ";
printVector(vec);
return 0;
}

时间复杂度为 𝑂(𝑛) : 所有节点被访问一次,使用 𝑂(𝑛) 时间。
空间复杂度为 𝑂(𝑛) : 在最差情况下,即树退化为链表时,递归深度达到 𝑛 ,系统占用 𝑂(𝑛) 栈帧空间。
二叉树数组表示
在链表表示下,二叉树的存储单元为节点 TreeNode ,节点之间通过指针相连接。
可以用数组来表示二叉树。
表示完美二叉树
给定一棵完美二叉树,将所有节点按照层序遍历的顺序存储在一个数组中,则每个节点都对应唯一的数组索引。
根据层序遍历的特性,可以推导出父节点索引与子节点索引之间的“映射公式”:
若某节点的索引为 𝑖 ,则该节点的左子节点索引为 2𝑖 + 1 ,右子节点索引为 2𝑖 + 2 。
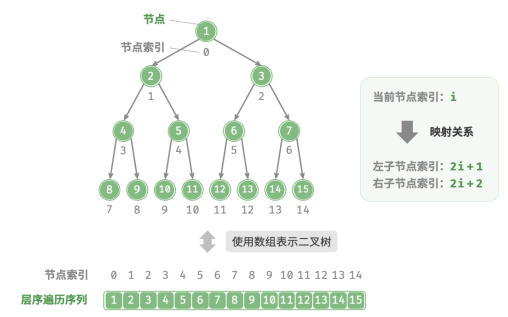
映射公式的角色相当于链表中的指针。 给定数组中的任意一个节点,都可以通过映射公式来访问它的左(右)子节点。
表示任意二叉树
完美二叉树是一个特例,在二叉树的中间层通常存在许多 None 。
由于层序遍历序列并不包含这些 None ,因此无法仅凭该序列来推测 None 的数量和分布位置。这意味着存在多种二叉树结构都符合该层序遍历序列。
可以考虑在层序遍历序列中显式地写出所有 None。,这样处理后,层序遍历序列就可以唯一表示二叉树了。
/* 二叉树的数组表示 */
// 使用 int 最大值 INT_MAX 标记空位
vector<int> tree = {1, 2, 3, 4, INT_MAX, 6, 7, 8, 9, INT_MAX, INT_MAX, 12, INT_MAX, INT_MAX, 15};
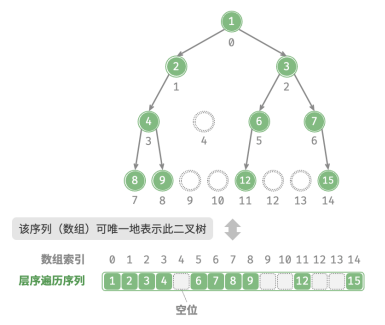
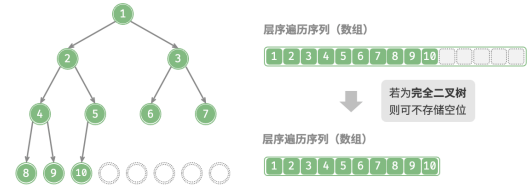
完全二叉树非常适合使用数组来表示。回顾完全二叉树的定义,None 只出现在最底层且靠右的位置,因此所有 None 一定出现在层序遍历序列的末尾。
因此,着使用数组表示完全二叉树时,可以省略存储所有 None。
完全二叉树的数组表示:
代码实现:
1.给定某节点,获取它的值、左(右)子节点、父节点;
2.获取前序遍历、中序遍历、后序遍历、层序遍历序列。
/**
* File: array_binary_tree.cpp
* Created Time: 2023-07-19
* Author: Krahets (krahets@163.com)
*/
#include "../utils/common.hpp"
/* 数组表示下的二叉树类 */
class ArrayBinaryTree {
public:
/* 构造方法 */
ArrayBinaryTree(vector<int> arr) {
tree = arr;
}
/* 列表容量 */
int size() {
return tree.size();
}
/* 获取索引为 i 节点的值 */
int val(int i) {
// 若索引越界,则返回 INT_MAX ,代表空位
if (i < 0 || i >= size())
return INT_MAX;
return tree[i];
}
/* 获取索引为 i 节点的左子节点的索引 */
int left(int i) {
return 2 * i + 1;
}
/* 获取索引为 i 节点的右子节点的索引 */
int right(int i) {
return 2 * i + 2;
}
/* 获取索引为 i 节点的父节点的索引 */
int parent(int i) {
return (i - 1) / 2;
}
/* 层序遍历 */
vector<int> levelOrder() {
vector<int> res;
// 直接遍历数组
for (int i = 0; i < size(); i++) {
if (val(i) != INT_MAX)
res.push_back(val(i));
}
return res;
}
/* 前序遍历 */
vector<int> preOrder() {
vector<int> res;
dfs(0, "pre", res);
return res;
}
/* 中序遍历 */
vector<int> inOrder() {
vector<int> res;
dfs(0, "in", res);
return res;
}
/* 后序遍历 */
vector<int> postOrder() {
vector<int> res;
dfs(0, "post", res);
return res;
}
private:
vector<int> tree;
/* 深度优先遍历 */
void dfs(int i, string order, vector<int> &res) {
// 若为空位,则返回
if (val(i) == INT_MAX)
return;
// 前序遍历
if (order == "pre")
res.push_back(val(i));
dfs(left(i), order, res);
// 中序遍历
if (order == "in")
res.push_back(val(i));
dfs(right(i), order, res);
// 后序遍历
if (order == "post")
res.push_back(val(i));
}
};
/* Driver Code */
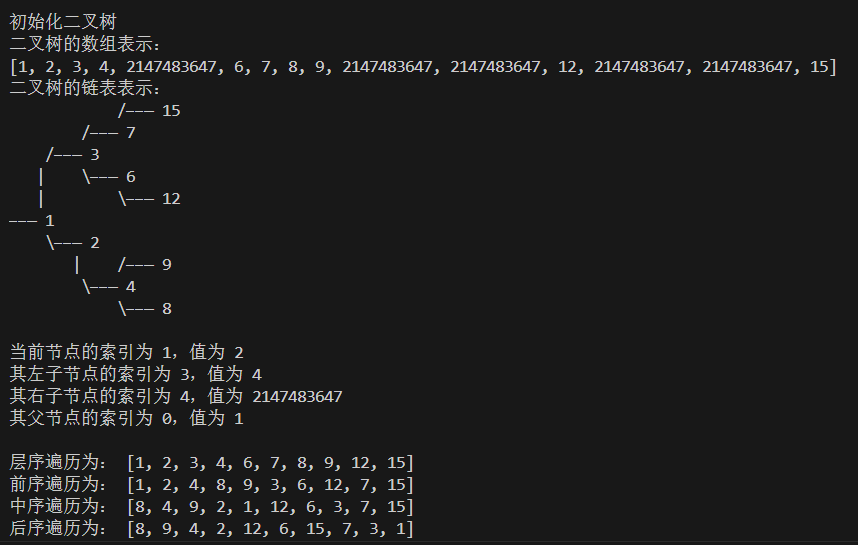
int main() {
// 初始化二叉树
// 使用 INT_MAX 代表空位 nullptr
vector<int> arr = {1, 2, 3, 4, INT_MAX, 6, 7, 8, 9, INT_MAX, INT_MAX, 12, INT_MAX, INT_MAX, 15};
TreeNode *root = vectorToTree(arr);
cout << "\n初始化二叉树\n";
cout << "二叉树的数组表示:\n";
printVector(arr);
cout << "二叉树的链表表示:\n";
printTree(root);
// 数组表示下的二叉树类
ArrayBinaryTree abt(arr);
// 访问节点
int i = 1;
int l = abt.left(i), r = abt.right(i), p = abt.parent(i);
cout << "\n当前节点的索引为 " << i << ",值为 " << abt.val(i) << "\n";
cout << "其左子节点的索引为 " << l << ",值为 " << (l != INT_MAX ? to_string(abt.val(l)) : "nullptr") << "\n";
cout << "其右子节点的索引为 " << r << ",值为 " << (r != INT_MAX ? to_string(abt.val(r)) : "nullptr") << "\n";
cout << "其父节点的索引为 " << p << ",值为 " << (p != INT_MAX ? to_string(abt.val(p)) : "nullptr") << "\n";
// 遍历树
vector<int> res = abt.levelOrder();
cout << "\n层序遍历为: ";
printVector(res);
res = abt.preOrder();
cout << "前序遍历为: ";
printVector(res);
res = abt.inOrder();
cout << "中序遍历为: ";
printVector(res);
res = abt.postOrder();
cout << "后序遍历为: ";
printVector(res);
return 0;
}
二叉树的数组表示的优点与局限性
优点:
1.数组存储在连续的内存空间中,对缓存友好,访问与遍历速度较快;
2.不需要存储指针,比较节省空间;
3.允许随机访问节点。
局限性:
1.数组存储需要连续内存空间,因此不适合存储数据量过大的树;
2.增删节点需要通过数组插入与删除操作实现,效率较低;
3.当二叉树中存在大量 None 时,数组中包含的节点数据比重较低,空间利用率较低;
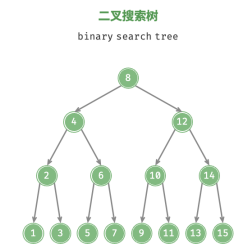
二叉搜索树
二叉搜索树 (binary search tree)满足以下条件:
1.对于根节点,左子树中所有节点的值 < 根节点的值 < 右子树中所有节点的值;
2.任意节点的左、右子树也是二叉搜索树,即同样满足条件 1。
二叉搜索树的操作
将二叉搜索树封装为一个类 BinarySearchTree ,并声明一个成员变量 root ,指向树的根节点。
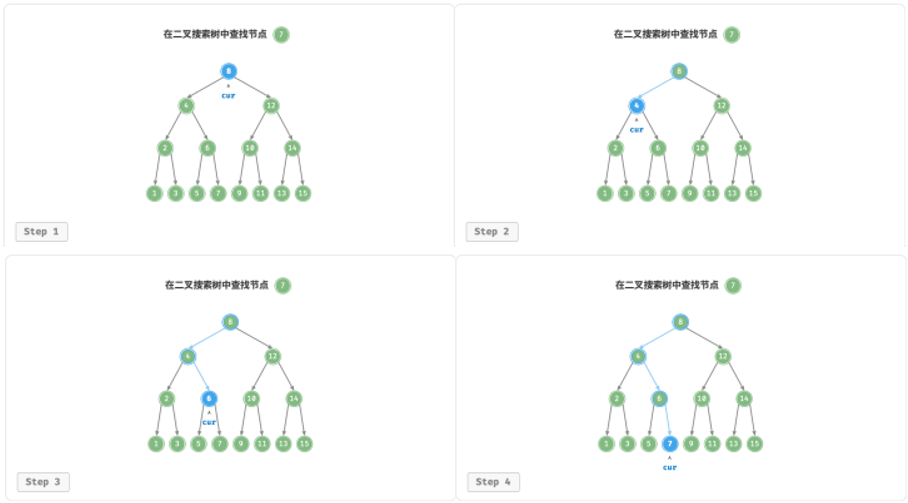
1.查找节点
给定目标节点值 num ,可以根据二叉搜索树的性质来查找。
声明一个节点 cur ,从二叉树的根节点 root 出发,循环比较节点值 cur.val 和 num 之间的大小关系。
若 cur.val < num ,说明目标节点在 cur 的右子树中,因此执行 cur = cur.right 。
若 cur.val > num ,说明目标节点在 cur 的左子树中,因此执行 cur = cur.left 。
若 cur.val = num ,说明找到目标节点,跳出循环并返回该节点。
二叉搜索树的查找操作与二分查找算法的工作原理一致,都是每轮排除一半情况。循环次数最多为二叉树的高度,当二叉树平衡时,使用 𝑂(log 𝑛) 时间。
/* 查找节点 */
TreeNode *search(int num) {
TreeNode *cur = root;
// 循环查找,越过叶节点后跳出
while (cur != nullptr) {
// 目标节点在 cur 的右子树中
if (cur->val < num)
cur = cur->right;
// 目标节点在 cur 的左子树中
else if (cur->val > num)
cur = cur->left;
// 找到目标节点,跳出循环
else
break;
}
// 返回目标节点
return cur;
}
2.插入节点
给定一个待插入元素 num ,为了保持二叉搜索树“左子树 < 根节点 < 右子树”的性质,操作流程如图:
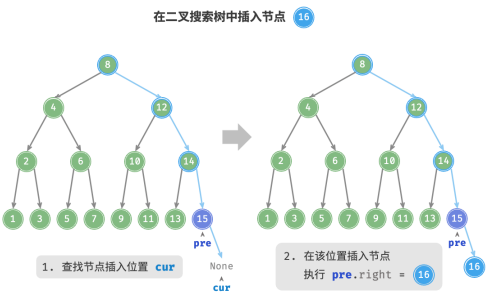
1.查找插入位置: 与查找操作相似,从根节点出发,根据当前节点值和 num 的大小关系循环向下搜索,直到越过叶节点(遍历至 None )时跳出循环;
2.在该位置插入节点: 初始化节点 num ,将该节点置于 None 的位置。
要点:
1.二叉搜索树不允许存在重复节点,否则将违反其定义。因此,若待插入节点在树中已存在,则不执行插入,直接返回。
2.为了实现插入节点,需要借助节点 pre 保存上一轮循环的节点。这样在遍历至 None 时,可以获取到其父节点,从而完成节点插入操作。
/* 插入节点 */
void insert(int num) {
// 若树为空,则初始化根节点
if (root == nullptr) {
root = new TreeNode(num);
return;
}
TreeNode *cur = root, *pre = nullptr;
// 循环查找,越过叶节点后跳出
while (cur != nullptr) {
// 找到重复节点,直接返回
if (cur->val == num)
return;
pre = cur;
// 插入位置在 cur 的右子树中
if (cur->val < num)
cur = cur->right;
// 插入位置在 cur 的左子树中
else
cur = cur->left;
}
// 插入节点
TreeNode *node = new TreeNode(num);
if (pre->val < num)
pre->right = node;
else
pre->left = node;
}
与查找节点相同,插入节点使用 𝑂(log 𝑛) 时间。
3.删除节点
先在二叉树中查找到目标节点,再将其删除。
与插入节点类似,需要保证在删除操作完成后,二叉搜索树的“左子树 < 根节点 < 右子树”的性质仍然满足。因此,根据目标节点的子节点数量,分 0、1 和 2 三种情况,执行对应的删除节点操作。
当待删除节点的度为 0 时,表示该节点是叶节点,可以直接删除。
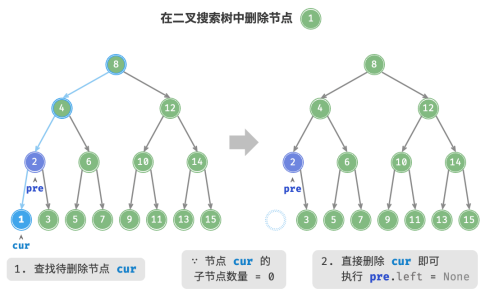
当待删除节点的度为 1 时,将待删除节点替换为其子节点即可。
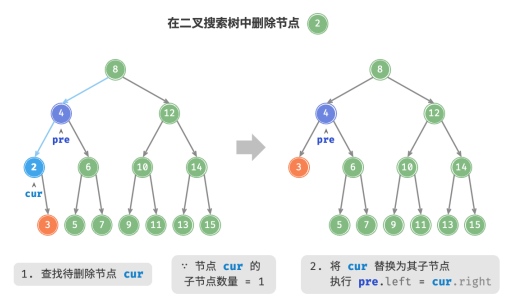
当待删除节点的度为 2 时,无法直接删除它,而需要使用一个节点替换该节点。
由于要保持二叉搜索树“左子树 < 根节点 < 右子树”的性质,因此这个节点可以是右子树的最小节点或左子树的最大节点。
假设选择右子树的最小节点(中序遍历的下一个节点),则删除操作流程如图:
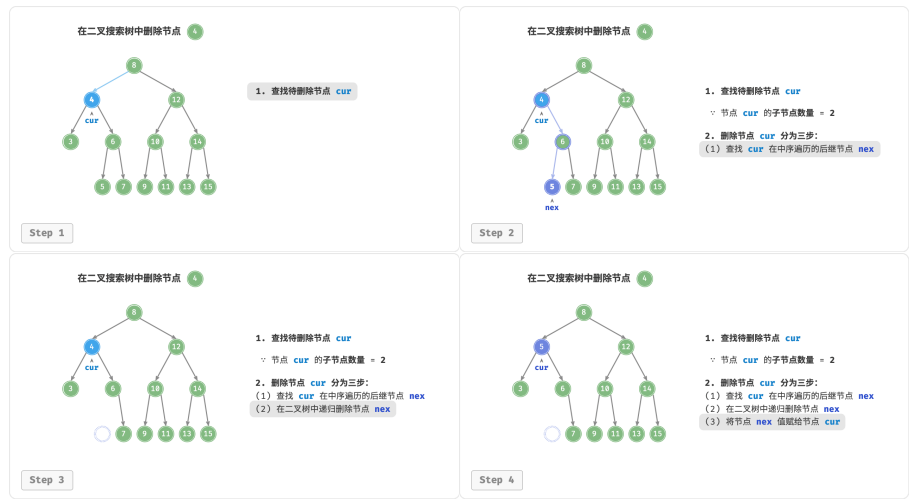
1.找到待删除节点在“中序遍历序列”中的下一个节点,记为 tmp 。
2.用 tmp 的值覆盖待删除节点的值,并在树中递归删除节点 tmp 。
删除节点操作同样使用 𝑂(log 𝑛) 时间,其中查找待删除节点需要 𝑂(log 𝑛) 时间,获取中序遍历后继节点
需要 𝑂(log 𝑛) 时间。
/* 删除节点 */
void remove(int num) {
// 若树为空,直接提前返回
if (root == nullptr)
return;
TreeNode *cur = root, *pre = nullptr;
// 循环查找,越过叶节点后跳出
while (cur != nullptr) {
// 找到待删除节点,跳出循环
if (cur->val == num)
break;
pre = cur;
// 待删除节点在 cur 的右子树中
if (cur->val < num)
cur = cur->right;
// 待删除节点在 cur 的左子树中
else
cur = cur->left;
}
// 若无待删除节点,则直接返回
if (cur == nullptr)
return;
// 子节点数量 = 0 or 1
if (cur->left == nullptr || cur->right == nullptr) {
// 当子节点数量 = 0 / 1 时, child = nullptr / 该子节点
TreeNode *child = cur->left != nullptr ? cur->left : cur->right;
// 删除节点 cur
if (cur != root) {
if (pre->left == cur)
pre->left = child;
else
pre->right = child;
} else {
// 若删除节点为根节点,则重新指定根节点
root = child;
}
// 释放内存
delete cur;
}
// 子节点数量 = 2
else {
// 获取中序遍历中 cur 的下一个节点
TreeNode *tmp = cur->right;
while (tmp->left != nullptr) {
tmp = tmp->left;
}
int tmpVal = tmp->val;
// 递归删除节点 tmp
remove(tmp->val);
// 用 tmp 覆盖 cur
cur->val = tmpVal;
}
}
4.中序遍历有序
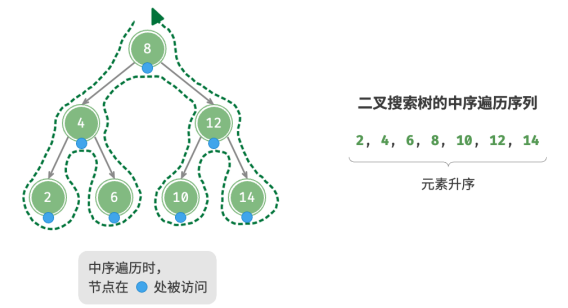
二叉树的中序遍历遵循“左 → 根 → 右”的遍历顺序,而二叉搜索树满足“左子节点 < 根节点 < 右子节点”的大小关系。
这意味着在二叉搜索树中进行中序遍历时,总是会优先遍历下一个最小节点,从而得出一个重要性质:二叉搜索树的中序遍历序列是升序的。
利用中序遍历升序的性质,在二叉搜索树中获取有序数据仅需 𝑂(𝑛) 时间,无须进行额外的排序操作,非常高效。
二叉搜索树的效率
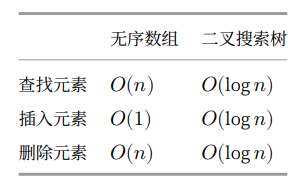
二叉搜索树的各项操作的时间复杂度都是对数阶,具有稳定且高效的性能。
只有在高频添加、低频查找删除数据的场景下,数组比二叉搜索树的效率更高。
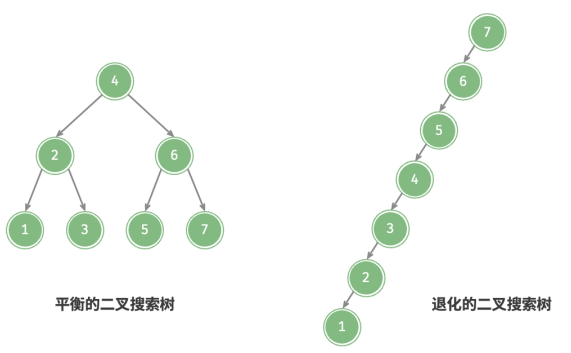
在理想情况下,二叉搜索树是“平衡”的,这样就可以在 log 𝑛 轮循环内查找任意节点。
然而,如果在二叉搜索树中不断地插入和删除节点,可能导致二叉树退化为链表,这时各种操作的时间复杂度也会退化为 𝑂(𝑛) 。
二叉搜索树常见应用
1.用作系统中的多级索引,实现高效的查找、插入、删除操作。
2.作为某些搜索算法的底层数据结构。
3.用于存储数据流,以保持其有序状态。
AVL 树
AVL 树既是二叉搜索树,也是平衡二叉树,同时满足这两类二叉树的所有性质,因此也被称为平衡二叉搜索树 (balanced binary search tree)。
AVL树常见术语
1.节点高度
由于 AVL 树的相关操作需要获取节点高度,因此需要为节点类添加 height 变量:
/* AVL 树节点类 */
struct TreeNode {
int val{}; // 节点值
int height = 0; // 节点高度
TreeNode *left{}; // 左子节点
TreeNode *right{}; // 右子节点
TreeNode() = default;
explicit TreeNode(int x) : val(x){}
};
“节点高度”是指从该节点到它的最远叶节点的距离,即所经过的“边”的数量。需要特别注意的是,叶节点
的高度为 0 ,而空节点的高度为 −1 。
创建两个工具函数,分别用于获取和更新节点的高度:
/* 获取节点高度 */
int height(TreeNode *node) {
// 空节点高度为 -1 ,叶节点高度为 0
return node == nullptr ? -1 : node->height;
}
/* 更新节点高度 */
void updateHeight(TreeNode *node) {
// 节点高度等于最高子树高度 + 1
node->height = max(height(node->left), height(node->right)) + 1;
}
2.节点平衡因子
节点的平衡因子(balance factor)定义为节点左子树的高度减去右子树的高度,同时规定空节点的平衡因
子为 0 。
/* 获取平衡因子 */
int balanceFactor(TreeNode *node) {
// 空节点平衡因子为 0
if (node == nullptr)
return 0;
// 节点平衡因子 = 左子树高度 - 右子树高度
return height(node->left) - height(node->right);
}
设平衡因子为 𝑓 ,则一棵 AVL 树的任意节点的平衡因子皆满足 −1 ≤ 𝑓 ≤ 1 。
AVL 树旋转
AVL 树的特点在于“旋转”操作,它能够在不影响二叉树的中序遍历序列的前提下,使失衡节点重新恢复平衡。换句话说,旋转操作既能保持“二叉搜索树”的性质,也能使树重新变为“平衡二叉树”。
将平衡因子绝对值 > 1 的节点称为“失衡节点”。根据节点失衡情况的不同,旋转操作分为四种:右旋、左旋、先右旋后左旋、先左旋后右旋。
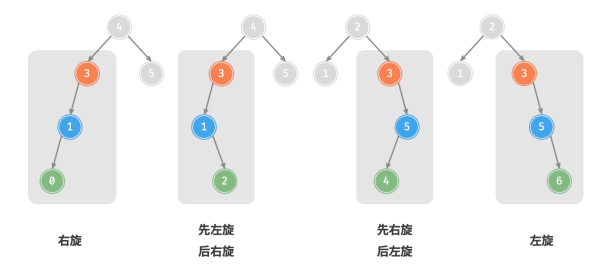
1.右旋
从底至顶看,二叉树中首个失衡节点是“节点 3”。我们关注以该失衡
节点为根节点的子树,将该节点记为 node ,其左子节点记为 child ,执行“右旋”操作。完成右旋后,子树恢复平衡,并且仍然保持二叉搜索树的性质。
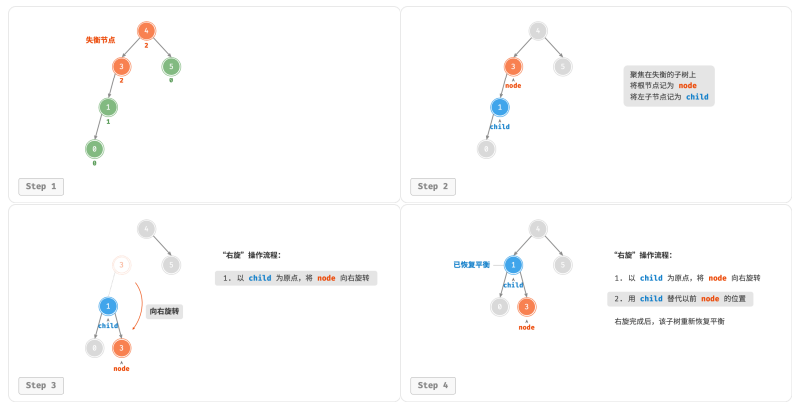
当节点 child 有右子节点(记为 grand_child )时,需要在右旋中添加一步:将 grand_child作为 node 的左子节点。
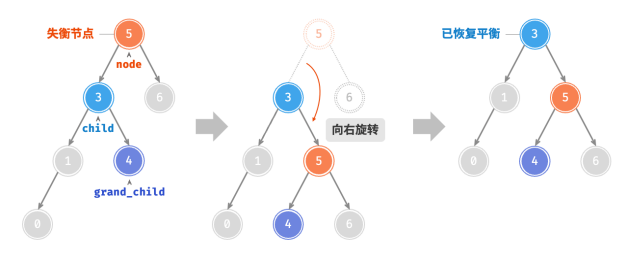
“向右旋转”是一种形象化的说法,实际上需要通过修改节点指针来实现,代码如下所示:
// === File: avl_tree.cpp ===
/* 右旋操作 */
TreeNode *rightRotate(TreeNode *node) {
TreeNode *child = node->left;
TreeNode *grandChild = child->right;
// 以 child 为原点,将 node 向右旋转
child->right = node;
node->left = grandChild;
// 更新节点高度
updateHeight(node);
updateHeight(child);
// 返回旋转后子树的根节点
return child;
}
2.左旋
如果考虑上述失衡二叉树的“镜像”,则需要“左旋”操作。
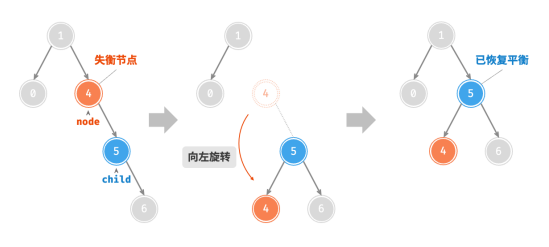
当节点 child 有左子节点(记为 grand_child )时,需要在左旋中添加一步:将grand_child 作为 node 的右子节点。
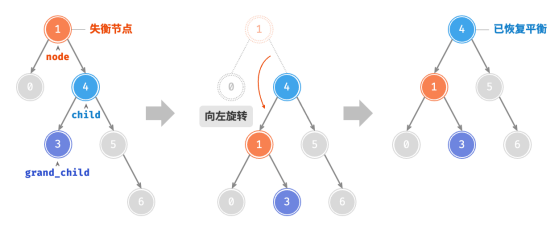
可以观察到,右旋和左旋操作在逻辑上是镜像对称的,它们分别解决的两种失衡情况也是对称的。基于对称性。只需将右旋的实现代码中的所有的 left 替换为 right ,将所有的 right 替换为 left ,即可得到左
旋的实现代码:
/* 左旋操作 */
TreeNode *leftRotate(TreeNode *node) {
TreeNode *child = node->right;
TreeNode *grandChild = child->left;
// 以 child 为原点,将 node 向左旋转
child->left = node;
node->right = grandChild;
// 更新节点高度
updateHeight(node);
updateHeight(child);
// 返回旋转后子树的根节点
return child;
}
3.先左旋后右旋
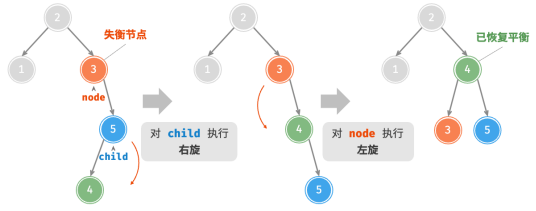
对于下图中的失衡节点 3 ,仅使用左旋或右旋都无法使子树恢复平衡。此时需要先对 child 执行“左旋”,再对 node 执行“右旋”。
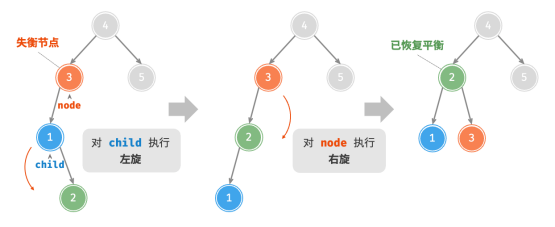
4.先右旋后左旋
如下图所示,对于上述失衡二叉树的镜像情况,需要先对 child 执行“右旋”,再对 node 执行“左旋”。
5. 旋转的选择
下图展示的四种失衡情况与上述案例逐个对应,分别需要采用右旋、先左旋后右旋、先右旋后左旋、左旋
的操作。
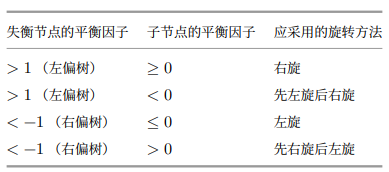
如下表所示,通过判断失衡节点的平衡因子以及较高一侧子节点的平衡因子的正负号,来确定失衡节点属于上图中的哪种情况。
为了便于使用,将旋转操作封装成一个函数。有了这个函数,就能对各种失衡情况进行旋转,使失衡节点重新恢复平衡。代码如下所示:
/* 执行旋转操作,使该子树重新恢复平衡 */
TreeNode *rotate(TreeNode *node) {
// 获取节点 node 的平衡因子
int _balanceFactor = balanceFactor(node);
// 左偏树
if (_balanceFactor > 1) {
if (balanceFactor(node->left) >= 0) {
// 右旋
return rightRotate(node);
} else {
// 先左旋后右旋
node->left = leftRotate(node->left);
return rightRotate(node);
}
}
// 右偏树
if (_balanceFactor < -1) {
if (balanceFactor(node->right) <= 0) {
// 左旋
return leftRotate(node);
} else {
// 先右旋后左旋
node->right = rightRotate(node->right);
return leftRotate(node);
}
}
// 平衡树,无须旋转,直接返回
return node;
}
AVL 树常用操作
1.插入节点
AVL 树的节点插入操作与二叉搜索树在主体上类似。
唯一的区别在于,在 AVL 树中插入节点后,从该节点到根节点的路径上可能会出现一系列失衡节点。
因此,需要从这个节点开始,自底向上执行旋转操作,使所有失衡节点恢复平衡。
/* 插入节点 */
void insert(int val) {
root = insertHelper(root, val);
}
/* 递归插入节点(辅助方法) */
TreeNode *insertHelper(TreeNode *node, int val) {
if (node == nullptr)
return new TreeNode(val);
/* 1. 查找插入位置并插入节点 */
if (val < node->val)
node->left = insertHelper(node->left, val);
else if (val > node->val)
node->right = insertHelper(node->right, val);
else
return node; // 重复节点不插入,直接返回
updateHeight(node); // 更新节点高度
/* 2. 执行旋转操作,使该子树重新恢复平衡 */
node = rotate(node);
// 返回子树的根节点
return node;
}
2.删除节点
类似地,在二叉搜索树的删除节点方法的基础上,需要从底至顶执行旋转操作,使所有失衡节点恢复平衡。
/* 删除节点 */
void remove(int val) {
root = removeHelper(root, val);
}
/* 递归删除节点(辅助方法) */
TreeNode *removeHelper(TreeNode *node, int val) {
if (node == nullptr)
return nullptr;
/* 1. 查找节点并删除 */
if (val < node->val)
node->left = removeHelper(node->left, val);
else if (val > node->val)
node->right = removeHelper(node->right, val);
else {
if (node->left == nullptr || node->right == nullptr) {
TreeNode *child = node->left != nullptr ? node->left : node->right;
// 子节点数量 = 0 ,直接删除 node 并返回
if (child == nullptr) {
delete node;
return nullptr;
}
// 子节点数量 = 1 ,直接删除 node
else {
delete node;
node = child;
}
} else {
// 子节点数量 = 2 ,则将中序遍历的下个节点删除,并用该节点替换当前节点
TreeNode *temp = node->right;
while (temp->left != nullptr) {
temp = temp->left;
}
int tempVal = temp->val;
node->right = removeHelper(node->right, temp->val);
node->val = tempVal;
}
}
updateHeight(node); // 更新节点高度
/* 2. 执行旋转操作,使该子树重新恢复平衡 */
node = rotate(node);
// 返回子树的根节点
return node;
}
3.查找节点
AVL 树的节点查找操作与二叉搜索树一致。
AVL 树典型应用
- 组织和存储大型数据,适用于高频查找、低频增删的场景。
- 用于构建数据库中的索引系统。
- 红黑树在许多应用中比 AVL 树更受欢迎。这是因为红黑树的平衡条件相对宽松,在红黑树中插入与删除节点所需的旋转操作相对较少,其节点增删操作的平均效率更高。
小结
学习地址
学习地址:https://github.com/krahets/hello-algo
重新复习数据结构,所有的内容都来自这里。

![每日一题 --- 反转链表[力扣][Go]](https://img-blog.csdnimg.cn/direct/34b6d71706c84ca1850d8e8bba09562c.png)

![[自研开源] MyData v0.7.5 更新日志](https://img-blog.csdnimg.cn/direct/06c362a0f8b34dfabd61d74038d81cb6.png)

![[数据结构]二叉树的建立与遍历(递归)](https://img-blog.csdnimg.cn/direct/aba4aff9ef104951b9a16205be1f4c94.png)





