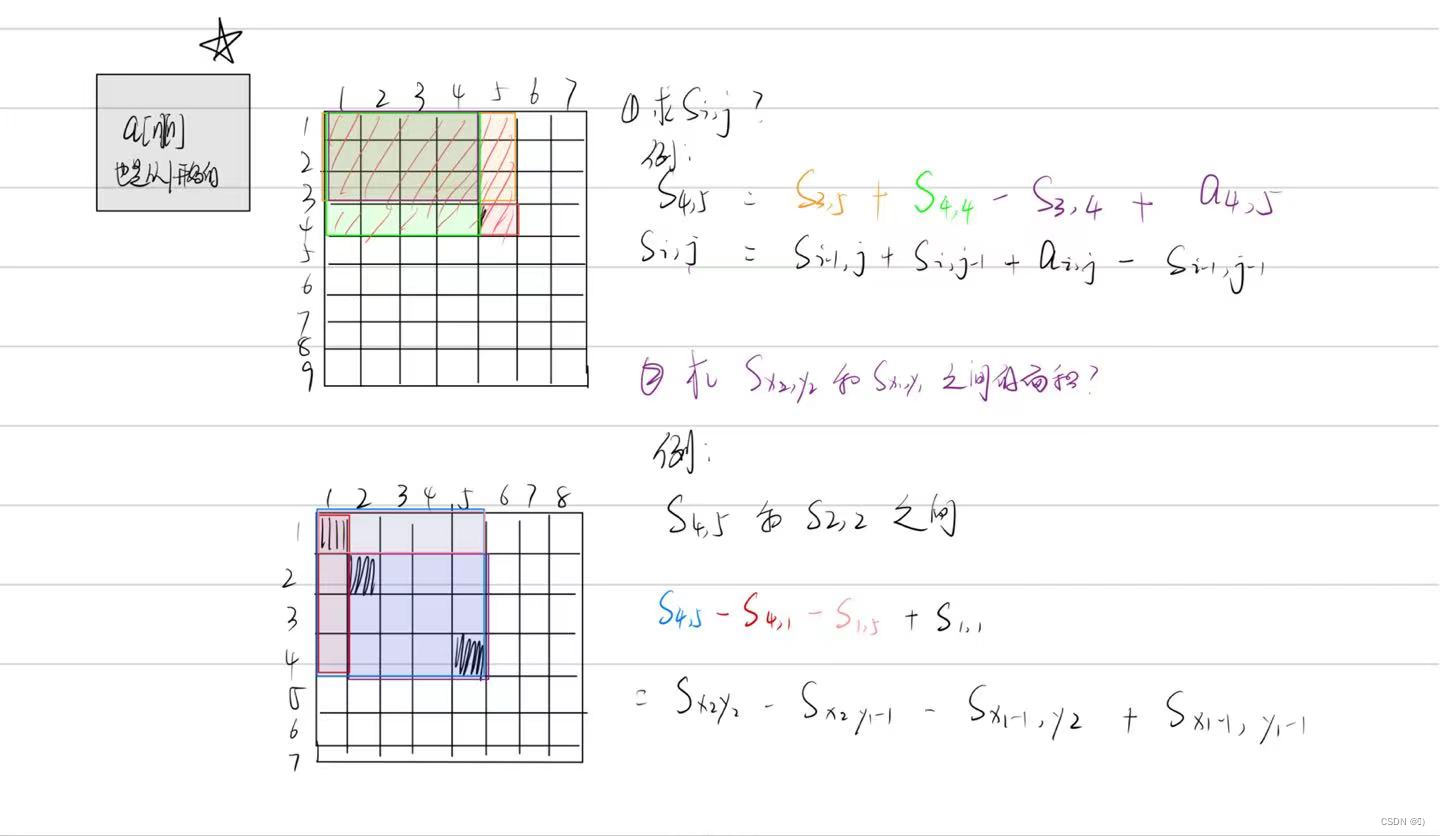
前面的文章,我们讲了什么Python的许多基础知识,现在我们开始对Python并发编程进行学习。我们将探讨 Python 中线程和多线程的使用。帮助大家更好地理解如何使用这种技术。
目录
1. 线程(Threads)
1.1 Python 中的线程工作原理
2. 创建和管理线程
2.1 创建线程
2.2 线程的生命周期和状态
2.3 线程同步和数据共享
3. 线程池(ThreadPool)
4. Python多线程编程
Python 多线程选择和注意事项
参考资料
总结
在编程中,并发编程允许程序同时执行多个独立的任务,这些任务可以在同一时间段内部分地重叠执行,从而提高程序的效率和响应性。在Python 中,并发编程可以通过多种方式实现,其中包括线程(Threads)和进程(Processes)。
1. 线程(Threads)
学过操作系统的同学都知道,线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。也即是说,一个进程可以拥有多个线程,这些线程共享进程的资源,但每个线程拥有自己的执行堆栈和局部变量。相对于进程而言,线程更加轻量级,创建和销毁的开销更小。
1.1 Python 中的线程工作原理
Python 的标准库提供了 threading 模块来进行多线程编程。线程是由操作系统的线程实现来管理的,这意味着 Python 的线程可以利用操作系统的多线程功能。
Python 的全局解释器锁(Global Interpreter Lock,GIL)是一个影响多线程执行的重要因素。GIL 实际上是一个互斥锁,它确保了在解释器级别上同一时刻只有一个线程在执行 Python 字节码。也就是说,在 CPU 密集型任务中,多线程并不能充分利用多核处理器。但在 I/O 密集型任务中,多线程可以提供更好的性能,因为线程在等待 I/O 操作完成时可以让出 GIL。
线程的优势和限制:
| 优势 | 限制 |
|---|---|
| 简单易用 | GIL 的影响 |
| 共享内存 | 线程安全 |
| 适用于 I/O 密集型任务 | 不适用于 CPU 密集型任务 |
2. 创建和管理线程
threading 模块,可以轻松地创建和管理线程。学习线程的知识,包括:创建线程、启动和停止线程,以及线程的生命周期和状态。下面我们一一介绍。
2.1 创建线程
首先,让我们看一下如何使用 threading 模块创建线程。
import threading
import time
def task(name, delay):
print(f"Thread {name} is starting...")
time.sleep(delay)
print(f"Thread {name} is done.")
# 创建线程
thread1 = threading.Thread(target=task, args=("Thread 1", 2))
thread2 = threading.Thread(target=task, args=("Thread 2", 1))
# 启动线程
thread1.start()
thread2.start()
# 等待线程结束
thread1.join()
thread2.join()
print("All threads are done.")
这里,我们定义了一个 task 函数作为线程的执行函数,接受线程的名称和延迟时间作为参数。然后我们创建了两个线程 thread1 和 thread2,分别执行 task 函数,并启动它们。最后,我们等待所有线程执行完毕,并输出 "All threads are done."。
输出如下:
Thread Thread 1 is starting...
Thread Thread 2 is starting...
Thread Thread 2 is done.
Thread Thread 1 is done.
All threads are done.
2.2 线程的生命周期和状态
线程的生命周期包括创建、就绪、运行、阻塞和终止几个阶段。如下所示:
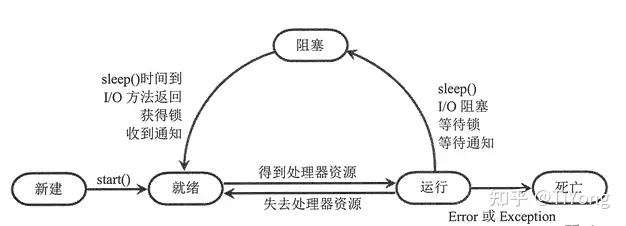
上面的例子中,我们通过 start() 方法启动了线程,使其进入就绪状态,然后线程调度器负责将其转换为运行状态,执行 task 函数。当 task 函数中的 time.sleep(delay) 被调用时,线程将进入阻塞状态,等待一定时间后再次进入就绪状态,直到任务完成。最后,通过 join() 方法等待线程结束,线程进入终止状态。
线程的状态可以通过 threading 模块中的常量来表示,如下所示:
| 状态 | 描述 | 相关常量 |
|---|---|---|
| 创建 | 创建线程对象,但尚未启动 | threading.Thread |
| 就绪 | 线程已启动,等待被调度执行 | threading.Thread.start() |
| 运行 | 线程正在执行代码 | threading.Thread.run() |
| 阻塞 | 线程因等待 I/O 操作或其他事件而暂停执行 | - |
| 等待 | 线程调用 wait() 方法进入等待状态 | - |
| 死亡 | 线程执行完毕或因异常终止 | threading.Thread.is_alive() |
| 守护线程 | 守护线程在主线程结束后自动退出 | threading.Thread.daemon |
2.3 线程同步和数据共享
由于线程共享同一进程的内存空间,可能会导致数据竞争和不确定的结果。为了确保线程安全,我们需要使用同步机制来控制线程的访问。
使用锁(Locks)确保线程安全
锁是最简单、最常用的同步机制,用于确保在任何时候只有一个线程可以访问共享资源。
import threading
# 创建一个安全的计数器类
class SafeCounter:
def __init__(self):
self._value = 0 # 初始化计数器值为0
self._lock = threading.Lock() # 创建一个线程锁对象
# 线程安全地增加计数器值
def increment(self):
with self._lock: # 使用线程锁确保原子操作
self._value += 1
# 线程安全地减少计数器值
def decrement(self):
with self._lock: # 使用线程锁确保原子操作
self._value -= 1
# 线程安全地获取当前计数器的值
def get_value(self):
with self._lock: # 使用线程锁确保原子操作
return self._value
# 创建一个SafeCounter的实例
counter = SafeCounter()
# 定义一个工作函数,每次增加计数器的值
def worker():
for _ in range(100000): # 每个线程执行10万次增加操作
counter.increment()
threads = []
# 创建10个线程来执行工作函数
for _ in range(10):
t = threading.Thread(target=worker) # 创建线程
threads.append(t) # 将线程添加到列表中
t.start() # 启动线程
# 等待所有线程执行完毕
for t in threads:
t.join()
# 打印最终计数器的值
print("Final counter value:", counter.get_value())
这里,创建了一个 SafeCounter 类来实现线程安全的计数器。在 increment 和 decrement 方法中,使用了 self._lock 来确保在修改计数器值时只有一个线程可以访问。get_value 方法也使用了同样的机制来获取计数器的值。
输出:
Final counter value: 1000000
3. 线程池(ThreadPool)
线程池是一种资源池,它预先创建了一组线程,并将其维护在一个池中。当需要执行任务时,可以从线程池中获取一个空闲线程来执行任务。任务完成后,线程会被释放回线程池,等待执行下一个任务。
Python 提供了 concurrent.futures 模块,其中的 ThreadPoolExecutor 类可以用来创建线程池,并方便地执行多个线程任务。
线程池有如下优点:
| 优点 | 描述 |
|---|---|
| 提高效率 | 可以避免频繁创建和销毁线程的开销,提高线程的利用率。 |
| 降低成本 | 可以减少线程的上下文切换,降低系统的开销。 |
| 提高可控性 | 可以方便地控制线程的数量和并发度,提高程序的稳定性。 |
使用 concurrent.futures.ThreadPoolExecutor 创建线程池:
从 Python 3.2 开始,标准库中提供了 concurrent.futures 模块,它提供了 ThreadPoolExecutor 类用于创建线程池。
from concurrent.futures import ThreadPoolExecutor
# 创建线程池,max_workers 参数指定线程池中最多可以同时运行的线程数
executor = ThreadPoolExecutor(max_workers=5)
控制并发任务的数量
通过 max_workers 参数来控制线程池中最多可以同时运行的线程数。
# 创建线程池,max_workers 参数设置为 2,表示最多同时运行 2 个线程
executor = ThreadPoolExecutor(max_workers=2)
示例:使用线程池进行网络请求(这里,我们虽然只是简单的输出,但后期我们将代码换成网络编程的代码,就可以衔接了。)
from concurrent.futures import ThreadPoolExecutor
# 定义要访问的 URL 列表
urls = ["https://www.baidu.com", "https://www.google.com", "https://www.bing.com"]
# 创建线程池
executor = ThreadPoolExecutor(max_workers=3)
# 定义要在线程中执行的函数
def print_message(message):
print(message)
# 提交任务到线程池
futures = [executor.submit(print_message,url) for url in urls]
# 等待所有任务完成
for future in futures:
# 获取任务的执行结果
response = future.result()
输出如下:
https://www.baidu.com
https://www.google.com
https://www.bing.com
4. Python多线程编程
多线程是指在一个程序中同时执行多个线程。线程是程序执行的基本单位,它是操作系统调度的最小单位。
注意:多线程可以提高程序的执行效率,但同时也带来了线程安全问题。
对于 CPU 密集型任务,可以考虑使用多线程,提高程序的执行效率。
import time
from concurrent.futures import ThreadPoolExecutor
# 任务函数,停止一秒,并返回n*n
def task(n):
time.sleep(1)
print("运算结果:", n*n)
return n * n
# 单线程执行
start_time = time.time()
for i in range(10):
result = task(i)
end_time = time.time()
print("单线程执行时间:", end_time - start_time)
# 多线程执行
start_time = time.time()
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(task, i) for i in range(10)]
results = [future.result() for future in futures]
end_time = time.time()
print("多线程执行时间:", end_time - start_time)
下面来看输出情况:
运算结果: 0
运算结果: 1
运算结果: 4
运算结果: 9
运算结果: 16
运算结果: 25
运算结果: 36
运算结果: 49
运算结果: 64
运算结果: 81
单线程执行时间: 10.105695724487305
运算结果: 16
运算结果: 4
运算结果: 9
运算结果: 1
运算结果: 0
运算结果: 81
运算结果: 64
运算结果: 49
运算结果: 36
运算结果: 25
多线程执行时间: 2.0349953174591064
可以看到,单线程执行时间远远高于多线程执行时间。这就是效率的极大提升。
Python 多线程选择和注意事项
| 问题 | 最佳实践 | 注意事项 |
|---|---|---|
| 避免常见的线程安全问题 | * 使用锁(Lock)来控制对共享数据的访问。 * 使用条件变量(Condition Variable)来实现线程之间的同步。 * 使用无锁数据结构,例如 concurrent.futures 模块中的 BoundedSemaphore。 | * 识别共享数据。 * 保护共享数据。 * 避免数据竞争。 * 测试线程安全性。 |
| 如何设计线程安全的程序 | * 识别共享数据。 * 保护共享数据。 * 避免数据竞争。 * 测试线程安全性。 | * 不要过度使用多线程。 * 使用合适的线程池。 * 监控程序性能。 |
| 在不同场景下选择合适的并发方案 | * CPU 密集型任务: 使用多线程可以提高程序的执行效率。 * I/O 密集型任务: 使用多线程可以提高程序的吞吐量。 * 混合型任务: 可以根据任务的不同特点,选择使用多线程、多进程或其他并发方案。 | * 选择合适的并发方案取决于任务的类型和特点。 * 需要权衡并发方案的利弊。 |
参考资料
- Python 官方文档 - threading: https://docs.python.org/3/library/threading.html
总结
关于线程和多线程的使用,这里也讲得差不多了,想必大家对线程和多线程的概念也有更深入的理解了。那么,大家可以试试敲敲代码,实际运行一番,相信你会有所收获。
欢迎大家和我一起继续学习、记录python的下一个知识点。
如果感觉阅读对您还有些作用,可以评论留言,关注我。谢谢您的阅读!
往期学习:
Python安装教程(版本3.8.10)windows10
Linux系统:安装Conda(miniconda)
Conda快速安装的解决方法(Mamba安装)
VSCode安装教程(版本:1.87.0)Windows10
Python基础语法:从入门到精通的必备指南
Python的基本数据类型
Python数据类型间的转换(隐式、显式)
Python基础知识:运算符详解
Python基础知识:数字类型及数学函数详解-
Python字符串操作及方法详解!一篇就搞定!
Python列表及其操作详解,从此不再迷茫!
Python元组(Tuple)深度解析!
Python字典的使用技巧(一篇详解)
Python条件控制深度解析,成为编程必备
Python循环语句全解析(附实战演练)
Python函数高效编程技巧,提升你的代码效率!
Python模块和包全解析,一篇文章就够!
Python lambda(匿名函数),一文详解
Python面向对象编程:合集篇(类、对象、封装、继承和多态)
Python命名空间和作用域,让你的代码逻辑更清晰!
Python正则表达式初学者指南,轻松上手!
Python深入理解迭代器和生成器