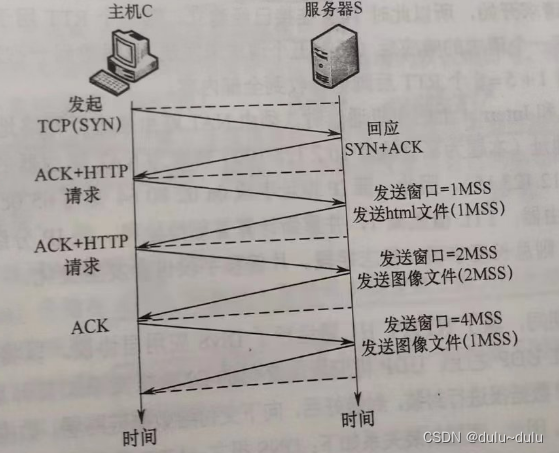
vLLM简介
vLLM 是一个快速且易于使用的 LLM(大型语言模型)推理和服务库。
vLLM 之所以快速,是因为:
-
最先进的服务吞吐量
-
通过 PagedAttention 高效管理注意力键和值内存
-
连续批处理传入请求
-
使用 CUDA/HIP 图快速模型执行
-
量化:GPTQ[1]、AWQ[2]、SqueezeLLM[3]、FP8 KV 缓存
-
优化的 CUDA 内核
vLLM 灵活且易于使用,因为它:
-
与流行的 HuggingFace 模型无缝集成
-
通过各种解码算法提供高吞吐量服务,包括并行采样、波束搜索等
-
支持分布式推理的张量并行性
-
支持流式输出
-
OpenAI 兼容的 API 服务器
-
支持 NVIDIA GPU 和 AMD GPU
-
(实验性) 前缀缓存支持
-
(实验性) 多洛拉支持
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了大模型算法岗技术与面试交流群, 想要进交流群、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:技术交流
实践案例合集:《大模型实战宝典》(2024版)正式发布!
用通俗易懂方式讲解系列
- 用通俗易懂的方式讲解:自然语言处理初学者指南(附1000页的PPT讲解)
- 用通俗易懂的方式讲解:1.6万字全面掌握 BERT
- 用通俗易懂的方式讲解:NLP 这样学习才是正确路线
- 用通俗易懂的方式讲解:28张图全解深度学习知识!
- 用通俗易懂的方式讲解:不用再找了,这就是 NLP 方向最全面试题库
- 用通俗易懂的方式讲解:实体关系抽取入门教程
- 用通俗易懂的方式讲解:灵魂 20 问帮你彻底搞定Transformer
- 用通俗易懂的方式讲解:图解 Transformer 架构
- 用通俗易懂的方式讲解:大模型算法面经指南(附答案)
- 用通俗易懂的方式讲解:十分钟部署清华 ChatGLM-6B,实测效果超预期
- 用通俗易懂的方式讲解:内容讲解+代码案例,轻松掌握大模型应用框架 LangChain
- 用通俗易懂的方式讲解:如何用大语言模型构建一个知识问答系统
- 用通俗易懂的方式讲解:最全的大模型 RAG 技术概览
- 用通俗易懂的方式讲解:利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
- 用通俗易懂的方式讲解:使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
- 用通俗易懂的方式讲解:面了 5 家知名企业的NLP算法岗(大模型方向),被考倒了。。。。。
- 用通俗易懂的方式讲解:NLP 算法实习岗,对我后续找工作太重要了!。
- 用通俗易懂的方式讲解:理想汽车大模型算法工程师面试,被问的瑟瑟发抖。。。。
- 用通俗易懂的方式讲解:基于 Langchain-Chatchat,我搭建了一个本地知识库问答系统
- 用通俗易懂的方式讲解:面试字节大模型算法岗(实习)
- 用通俗易懂的方式讲解:大模型算法岗(含实习)最走心的总结
- 用通俗易懂的方式讲解:大模型微调方法汇总
免费的Google Colab T4 GPU
Google Colab 的 T4 GPU 是一种高性能的计算资源,由 Google 提供,用于加速机器学习和深度学习任务。T4 GPU 是由 NVIDIA 生产的 Tensor Core GPU,专为提供高效的深度学习推理和训练性能而设计。
以下是关于 Google Colab 的 T4 GPU 的一些关键特性:
-
GPU 架构:T4 基于 NVIDIA 的 Ampere 架构,这是继 Turing 架构之后的新一代 GPU 架构,专为 AI 和机器学习工作负载优化。
-
Tensor Cores:T4 包含 Tensor Cores,这些是专门为深度学习矩阵运算设计的处理单元,能够提供更高的计算效率和性能。
-
内存:T4 GPU 拥有 16 GB 的 GDDR6 显存,这对于处理大型模型和数据集来说是非常充足的。
-
计算能力:T4 GPU 提供高达 318 GFLOPS 的单精度浮点运算能力,以及 60 GFLOPS 的半精度(FP16)运算能力,这使得它能够快速执行复杂的数学运算。
-
多精度计算:除了 FP32 和 FP16,T4 还支持 INT8 和 INT4 精度计算,这有助于在保持性能的同时减少模型的内存占用和提高推理速度。
-
软件兼容性:T4 GPU 支持广泛的深度学习框架和库,如 TensorFlow、PyTorch、Keras 等,这意味着用户可以在他们选择的工具上无缝地使用 T4 GPU。
-
易于访问:在 Google Colab 中,用户可以通过简单的配置更改来访问 T4 GPU,无需复杂的设置或额外的硬件投资。
-
成本效益:虽然 T4 GPU 是一种高端计算资源,但 Google Colab 提供的免费和付费版本都允许用户以合理的成本使用这些 GPU,这对于学生、研究人员和开发者来说是一个很大的优势。
选择免费的T4 GPU

免费的T4 GPU
查看GPU信息
- NVIDIA GPU 的详细信息
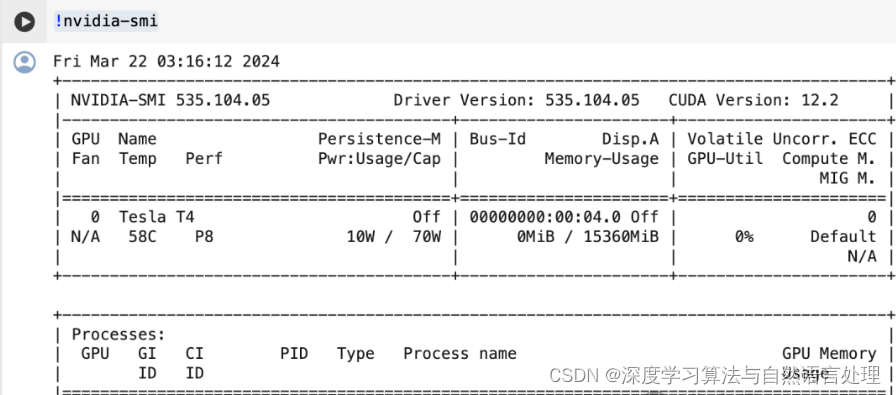
!nvidia-smi
GPU详细信息
nvidia-smi 是 NVIDIA 提供的一个命令行工具,用于监控和管理 NVIDIA GPU 设备。当你运行 nvidia-smi 命令时,它会返回一系列关于系统中所有 NVIDIA GPU 的详细信息
-
CUDA 版本:系统中安装的 CUDA 版本。
-
驱动版本:GPU 驱动的版本。
-
总显存:系统中所有 GPU 的总显存。
-
其他系统级别的信息,如 CPU 使用率、内存使用情况等。
-
显示每个进程对 GPU 显存的使用情况,包括进程 ID、已使用的显存量等。
-
GPU 编号:标识每个 GPU 的序号。
-
Name:显示 GPU 的型号。
-
Persistence-M:持续模式状态,显示是否开启,开启时 GPU 会保持唤醒状态以快速响应新任务。
-
Fan:风扇转速,显示为百分比,范围从 0 到 100%。
-
Temp:GPU 温度,单位是摄氏度。
-
Perf:性能状态,从 P0 到 P12,P0 表示最大性能,P12 表示最小性能。
-
Pwr:功耗,显示当前功耗和最大功耗。
-
Memory Usage:显存使用情况,包括总显存、已使用显存和剩余显存。
-
Bus-Id:GPU 总线的标识,格式为 domain🚌device.function。
-
Disp.A:显示 GPU 的显示输出是否激活。
-
Volatile GPU-Util:GPU 利用率,表示 GPU 正在执行的任务的负载百分比。
-
Uncorr. ECC:错误检查与纠正状态,与 GPU 的 ECC 内存相关。
-
Compute M:计算模式,显示 GPU 是处于默认模式还是特定计算模式。
# memory footprint support libraries/code
!ln -sf /opt/bin/nvidia-smi /usr/bin/nvidia-smi
!pip install -q gputil
import psutil
import humanize
import os
import GPUtil as GPU
GPUs = GPU.getGPUs()
# XXX: only one GPU on Colab and isn’t guaranteed
gpu = GPUs[0]
def printm():
process = psutil.Process(os.getpid())
virtual_memory = humanize.naturalsize( psutil.virtual_memory().available )
memory_info = humanize.naturalsize( process.memory_info().rss)
memoryFree =gpu.memoryFree
memoryUsed = gpu.memoryUsed
memoryUtil = gpu.memoryUtil*100
memoryTotal = gpu.memoryTotal
print(f"Gen RAM Free: {virtual_memory} | Proc size: {memory_info}" )
print("GPU RAM Free: {0:.0f}MB | Used: {1:.0f}MB | Util {2:3.0f}% | Total {3:.0f}MB".\
format(memoryFree, memoryUsed, memoryUtil*100, memoryTotal))
printm()
返回
Preparing metadata (setup.py) ... done
Building wheel for gputil (setup.py) ... done
Gen RAM Free: 12.4 GB | Proc size: 98.9 MB
GPU RAM Free: 15101MB | Used: 0MB | Util 0% | Total 15360MB
- 查看cuda版本信息
!nvcc -V
返回
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Aug_15_22:02:13_PDT_2023
Cuda compilation tools, release 12.2, V12.2.140
Build cuda_12.2.r12.2/compiler.33191640_0
根据版本信息,需要从源码安装
安装vLLM
%%bash
git clone https://github.com/vllm-project/vllm src
cd /content/src
pip install -e . # This may take 5-10 minutes.
检查torch版本
import torch
print(torch.version.cuda)
使用MODELSCOPE 镜像
%%bash
export VLLM_USE_MODELSCOPE=True
测试
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="Qwen/Qwen1.5-1.8B-Chat",dtype='half')
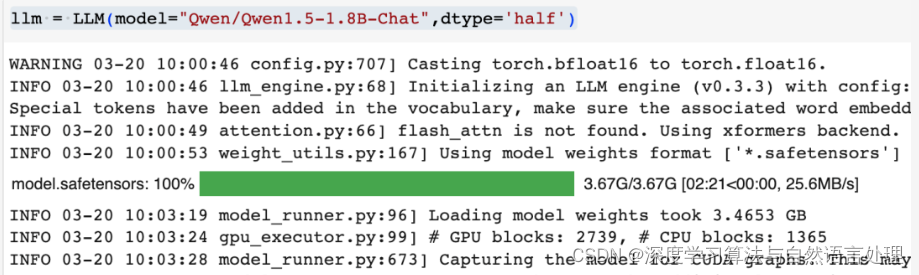
加载千问1.5-1.8B-Chat
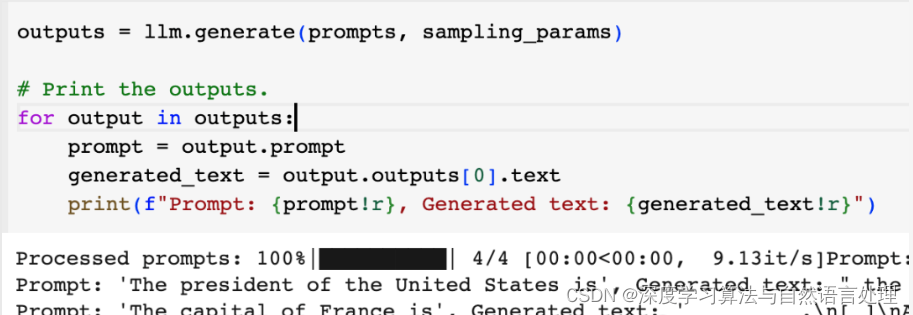
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
引用链接
[1] GPTQ: https://arxiv.org/abs/2210.17323
[2] AWQ: https://arxiv.org/abs/2306.00978
[3] SqueezeLLM: https://arxiv.org/abs/2306.07629