Flink实时计算引擎入门教程
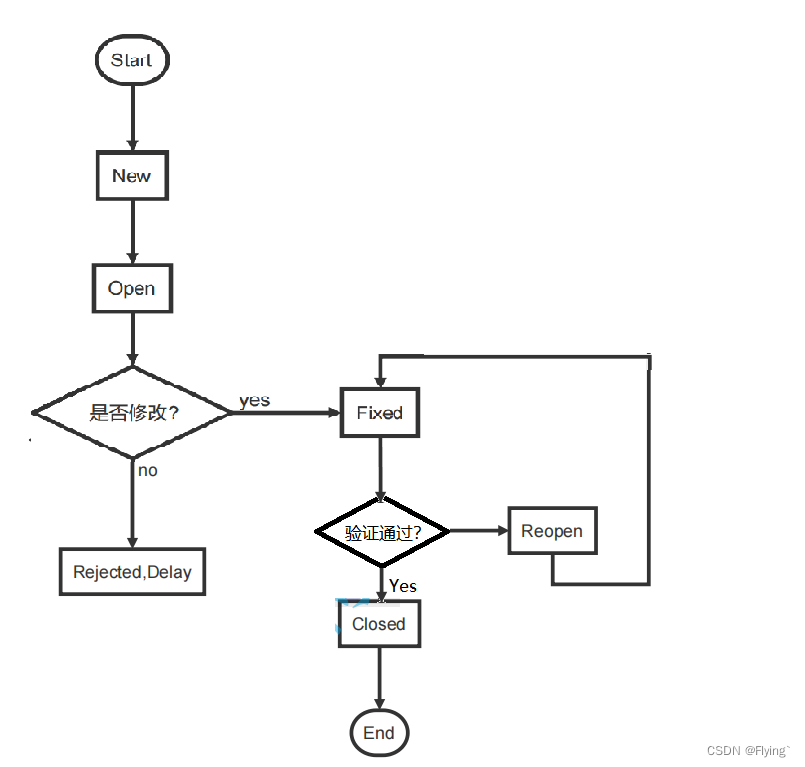
1.简介
Fink是一个开源的分布式,高性能,高可用,准确的实时数据计算框架,它主要优点如下:
流式计算: Fink可以连接处理流式(实时)数据。
容错: Fink提供了有状态的计算,会记录任务的中间状态,当执行失败时可以实现故障恢复。
可伸缩: Fink集群可以支持上千个节点。
高性能: Fink能提供高吞吐,低延迟的性能。
三大实时计算框架对比:
Spark Streaming: 可以处理秒级别延迟的实时数据计算,但是无法处理真正的实时数据计算,适合小型且独立的实时项目。
Storm: 可以处理真正的实时计算需求,但是它过于独立没有自己的生态圈,适合能够接受秒级别延迟不需要Hadoop生态圈的实时项目。
Fink: 新一代实时计算引擎,它包含了Strorm和Spark Streaming的优点,它即可以实现真正意义的实时计算需求,也融入了Hadoop生态圈,适合对性能要求高吞吐低延迟的实时项目。
2.执行流程

3.核心三大组件
](https://img-blog.csdnimg.cn/b2dcc5d962344a54bde9c4d149a3cdff.png)
DataSource: 数据源,主要用来接受数据。例如: readTextFile(),socketTextStream(),fromCollection(),以及一些第三方数据源组件。
Transformation: 计算逻辑,主要用于对数据进行计算。例如:map(),flatmap(),filter(),reduce()等类型的算子。
DataSink: 目的地,主要用来把计算的结果数据输出到其他存储介质。例如Kafka,Redis,Elasticsearch等。
4.应用场景
实时ETL: 集成实时数据计算系统现有的诸多数据通道和SQL灵活的加工能力,对实时数据进行清洗、归并和结构化处理。同时,为离线数仓进行有效的补充和优化,为数据实时传输计算通道。
实时报表: 实时采集、加工和存储,实时监控和展现业务指标数据,让数据化运营实时化。
监控预警: 对系统和用户行为进行实时检测和分析,实时检测和发现危险行为。
在线系统: 实时计算各类数据指标,并利用实时结果及时调整在线系统的相关策略。
5.架构原理
Fink常用的两种架构是: Standalone(独立集群)和ON YARN。
Standalone: 独立部署,不依赖Hadoop环境,但是需要使用Zookeeper实现服务的高可用。
ON YARN: 依赖Hadoop环境的YARN实现Flink任务的调度,需要Hadoop版本2.2以上。
Flink ON YARN架构图如下:
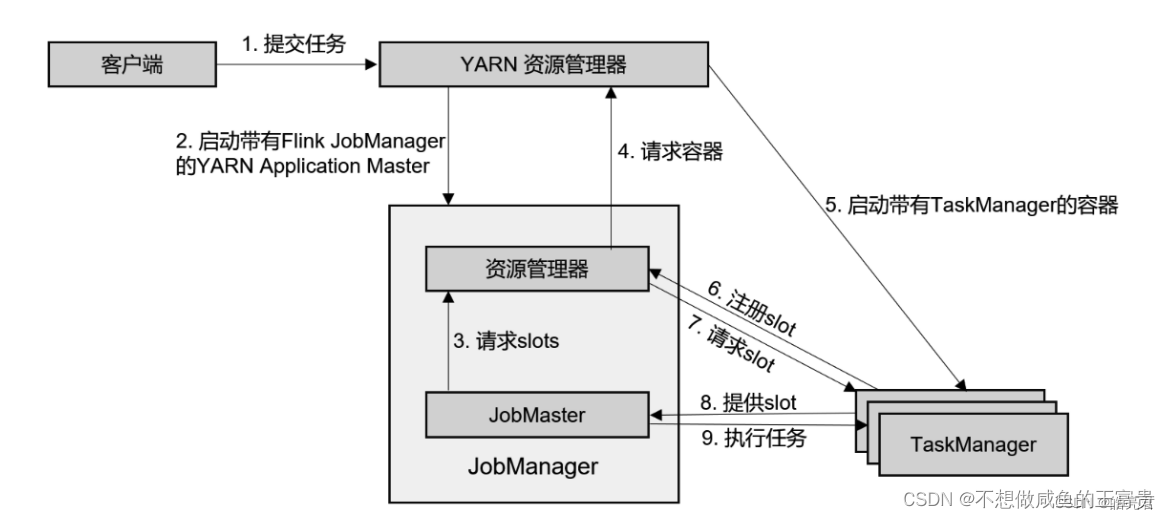
1.客户端将作业提交给 YARN 的资源管理器,这一步中会同时将 Flink 的 Jar 包和配置
上传到 HDFS,以便后续启动 Flink 相关组件的容器。
2.YARN 的资源管理器分配 Container 资源,启动 Flink JobManager,并将作业提交给
JobMaster。这里省略了 Dispatcher 组件。
3.JobMaster 向资源管理器请求资源(slots)。
4.资源管理器向 YARN 的资源管理器请求 container 资源。
5.YARN 启动新的 TaskManager 容器。
6.TaskManager 启动之后,向 Flink 的资源管理器注册自己的可用任务槽。
7.资源管理器通知 TaskManager 为新的作业提供 slots。
8.TaskManager 连接到对应的 JobMaster,提供 slots。
9.JobMaster 将需要执行的任务分发给 TaskManager,执行任务。
Flink ON YARN 在运行的时候可以细分为两种模式。
Session模式: 可以称为会话模式或多任务模式。这种模式会在YARN中初始化一个Flink集群,以后提交的任务都会提交到这个集群中,这个Flink集群会在YARN集群中,除非手动停止。
Per-Job模式: 可以称为单任务模式,这种模式每次提交Flink任务时任务都会创建一个集群,Flink任务之间都是互相独立,互不影响,执行任务资源会释放掉。
6.常用的API
Flink中提供了4种不同层次的API,每种都有对应的使用场景。
Sateful Stream Processing: 低级API,提供了对时间和状态的细粒度控制,简洁性和易用性较差,主要应用一些复杂事件处理逻辑上。
DataStream/DataSet API: 核心API,提供了针对实时数据和离线数据的处理,是对低级API进行的封装,提供了filter(),sum(),max(),min()等高级函数,简单易用。
Table API: 对DataStream/DataSet API做了进一步封装,提供了基于Table对象的一些关系型API。
SQL: 高级语言,Flink的SQL是基于Apache Calcite开发的,实现了标准SQL(类似于Hive的SQL),使用起来比其他API更加方便。Table API和SQL可以很容易结合使用,它们都返回Table对象。
在工作中能用SQL解决的优先使用SQL,复杂一些的考虑DataStream/DataSet API。
DataStreamAPI中常用的Transformation函数。

)
7.java编写flink程序
引入依赖,此文用的flink版本是1.15.2。
<properties>
<flink.version>1.15.2</flink.version>
<java.version>1.8</java.version>
<slf4j.version>1.7.30</slf4j.version>
<!--flink依赖的作用域 provided 表示表示该依赖包已经由目标容器提供,compile 标为默认值 -->
<flink.scope>compile</flink.scope>
</properties>
<dependencies>
<!-- core dependencies -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>${flink.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>${flink.version}</version>
<scope>${flink.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>${flink.version}</version>
<scope>${flink.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>${flink.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
<scope>${flink.scope}</scope>
</dependency>
<!-- test dependencies -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-test-utils</artifactId>
<version>${flink.version}</version>
<scope>test</scope>
</dependency>
<!-- 引入日志管理相关依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
<build>
<finalName>flink</finalName>
<plugins>
<!-- scala 编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>1.2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.ljm.hadoop.flink.Main</mainClass>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
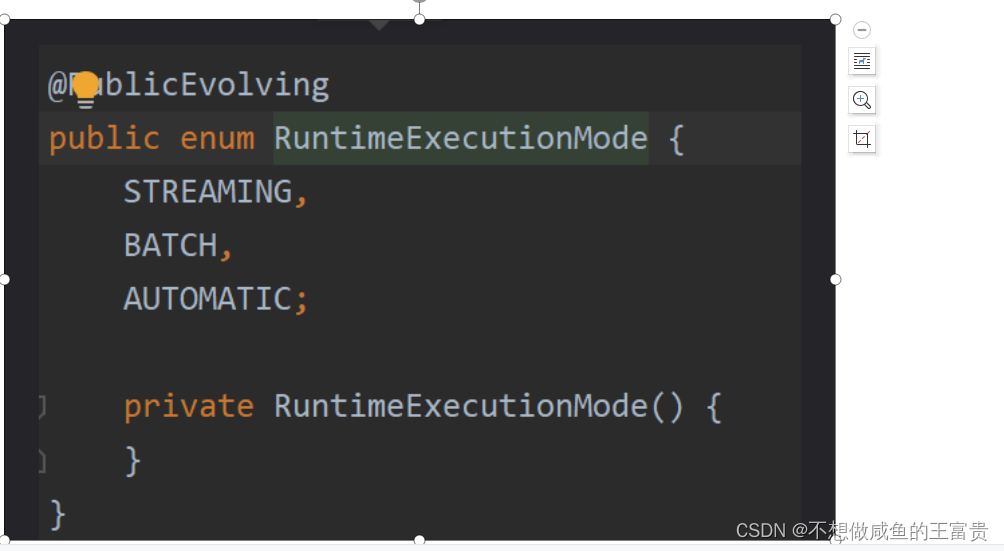
DataStream执行模式:
从1.12.0版本以后,flink实现了api的流批一体化处理。DataStream新增一个执行模式(execution mode),通过设置不同的执行模式,即可实现流处理与批处理之间的切换,这样一来,dataSet基本就被废弃了。
STREAMING: 流执行模式(默认)
BATCH: 批执行模式
AUTOMATIC: 在这种模式下,将由程序根据输入数据源是否有界,来自动选择执行模式。
以下为DataStream相关Api在Java中的简单应用
public class Main {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置执行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
map(env);
// flatMap(env);
// union(env);
// connect(env);
// socketTextStream(env);
env.execute("testJob");
}
/**
* 对数据处理
*/
private static void map(StreamExecutionEnvironment env) {
//在测试阶段,可以使用fromElements构造数据流
DataStreamSource<Integer> data = env.fromElements(1, 2, 3, 4, 5, 6, 7, 9, 11);
//处理数据
SingleOutputStreamOperator<Integer> numStream = data.map(new MapFunction<Integer, Integer>() {
@Override
public Integer map(Integer num) throws Exception {
return num - 1;
}
});
//使用一个线程打印数据
numStream.print().setParallelism(1);
//多线程输出(最大值=cpu总核数)
//numStream.print();
}
/**
* 将数据中的每行数据根据符号拆分为单词
*/
private static void flatMap(StreamExecutionEnvironment env) {
DataStreamSource<String> data = env.fromElements("hello,world", "hello,hadoop");
//读取文件内容,文件内容格式 hello,world
//DataStreamSource<String> data = env.readTextFile("D:\\java\\hadoop\\text.txt");
//处理数据
SingleOutputStreamOperator<String> wordStream = data.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] words = line.split(",");
for (String word : words) {
collector.collect(word);
}
}
});
wordStream.print().setParallelism(1);
}
/**
* 过滤数据中的奇数
*/
private static void filter(StreamExecutionEnvironment env) {
DataStreamSource<Integer> data1 = env.fromElements(1, 2, 3, 4, 5, 6, 7);
//处理数据
SingleOutputStreamOperator<Integer> numStream = data1.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer num) throws Exception {
return num % 2 == 1;
}
});
numStream.print().setParallelism(1);
}
/**
* 将两个流中的数字合并
*/
private static void union(StreamExecutionEnvironment env) {
//第1份数据流
DataStreamSource<Integer> data1 = env.fromElements(1, 2, 3, 4);
//第2份数据流
DataStreamSource<Integer> data2 = env.fromElements(3, 4, 5, 6);
//合并流
DataStream unionData = data1.union(data2);
unionData.print().setParallelism(1);
}
/**
* 将两个数据源中的数据关联到一起
*/
private static void connect(StreamExecutionEnvironment env) {
//第1份数据流
DataStreamSource<String> data1 = env.fromElements("user:tom,age:18");
//第2份数据流
DataStreamSource<String> data2 = env.fromElements("user:jack_age:18");
//连接两个流
ConnectedStreams<String, String> connectedStreams = data1.connect(data2);
//处理数据
SingleOutputStreamOperator<String> resStream = connectedStreams.map(new CoMapFunction<String, String, String>() {
@Override
public String map1(String s) throws Exception {
return s.replace(",", "-");
}
@Override
public String map2(String s) throws Exception {
return s.replace("_", "-");
}
});
resStream.print().setParallelism(1);
}
/**
* 每隔3秒重socket读取数据
*/
private static void socketTextStream(StreamExecutionEnvironment env) {
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//加载数据源
DataStreamSource<String> data = env.socketTextStream("127.0.0.1", 9001);
//数据处理
SingleOutputStreamOperator<String> wordStream = data.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] words = line.split(",");
for (String word : words) {
collector.collect(word);
}
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> wordCountStream = wordStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
});
//根据Tuple2中的第1列分组
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = wordCountStream.keyBy(0);
//窗口滑动设置,对指定时间窗口(例如3s内)内的数据聚合统计,并且把时间窗口内的结果打印出来
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> windowedStream = keyedStream.timeWindow(Time.seconds(3));
//根据Tuple2中的第2列进行合并数据
SingleOutputStreamOperator<Tuple2<String, Integer>> sumRes = windowedStream.sum(1);
//数据输出
sumRes.print();
}
}
上面示例的socketTextStream方法中用到了socketTextStream函数需要通过netnat工具发送数据
netnat工具下载
在netnat目录下执行 nc -L -p 9001 -v

运行socketTextStream方法,可以发现控制台打印了数据

上图中的3和5表示线程Id,如果只需要单线程打印则需要在print()后面追加setParallelism(1);
sumRes.print().setParallelism(1);
8.把flink程序部署到hadoop环境上面运行
8.1.安装flink程序
flink下载地址,下载1.15.2版本然后上传到服务器 /home/soft/目录下解压
tar -zxvf flink-1.15.2-bin-scala_2.12.tgz
flink客户端节点上需要设置HADOOP_HOME和HADOOP_CLASSPATH环境变量
vi /etc/profile
export HADOOP_HOME=/home/soft/hadoop-3.2.4
export HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
8.2.编译java开发的flink应用
使用socketTextStream接受socket传输的数据
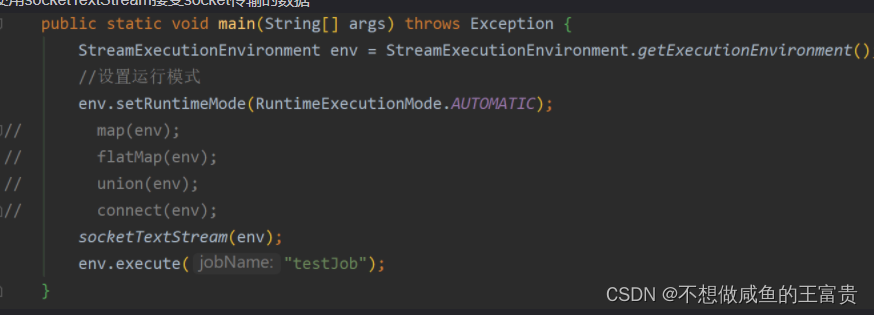
修改socketTextStream方法里面的代码,把127.0.0.1改成netcat工具部署机器ip地址
DataStreamSource<String> data = env.socketTextStream("192.168.239.128", 9001);
需要把pom.xml文件中flink.scope属性值设置为provided,这些依赖不需要打进Jar包中。
<properties>
<flink.scope>provided</flink.scope>
</properties>
执行命令打包
mvn clean package
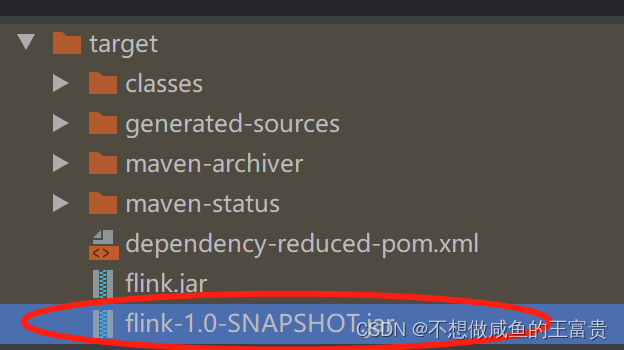
把flink-1.0-SNAPSHOT.jar上传至/home/soft/flink-1.15.2目录下然后提交任务
8.3.提交Flink任务到YARN集群中
cd /home/soft/flink-1.15.2
bin/flink run -m yarn-cluster -yjm 1024 -ytm 1024 flink-1.0-SNAPSHOT.jar
参数说明
bin/flink: 这个脚本启动的是Per-Job,bin/yarn-session.sh 则启动的是Session模式的
-m: 指定模式,yarn-cluster=集群模式,yarn-client=客户端模式
-yjm:每个JobManager内存 (default: MB)
-ytm:每个TaskManager内存 (default: MB)

8.4.测试任务并查看结果
在服务器上面安装netcat工具,然后发送数据,这台机器的ip必须和Java编写的Flink程序一致。
yum install nc
nc -l 9001
使用浏览器访问: http://hadoop集群主节点ip:8088/cluster可以看到已提交的Flink任务,然后下图的点击顺序可以看到任务的执行结果
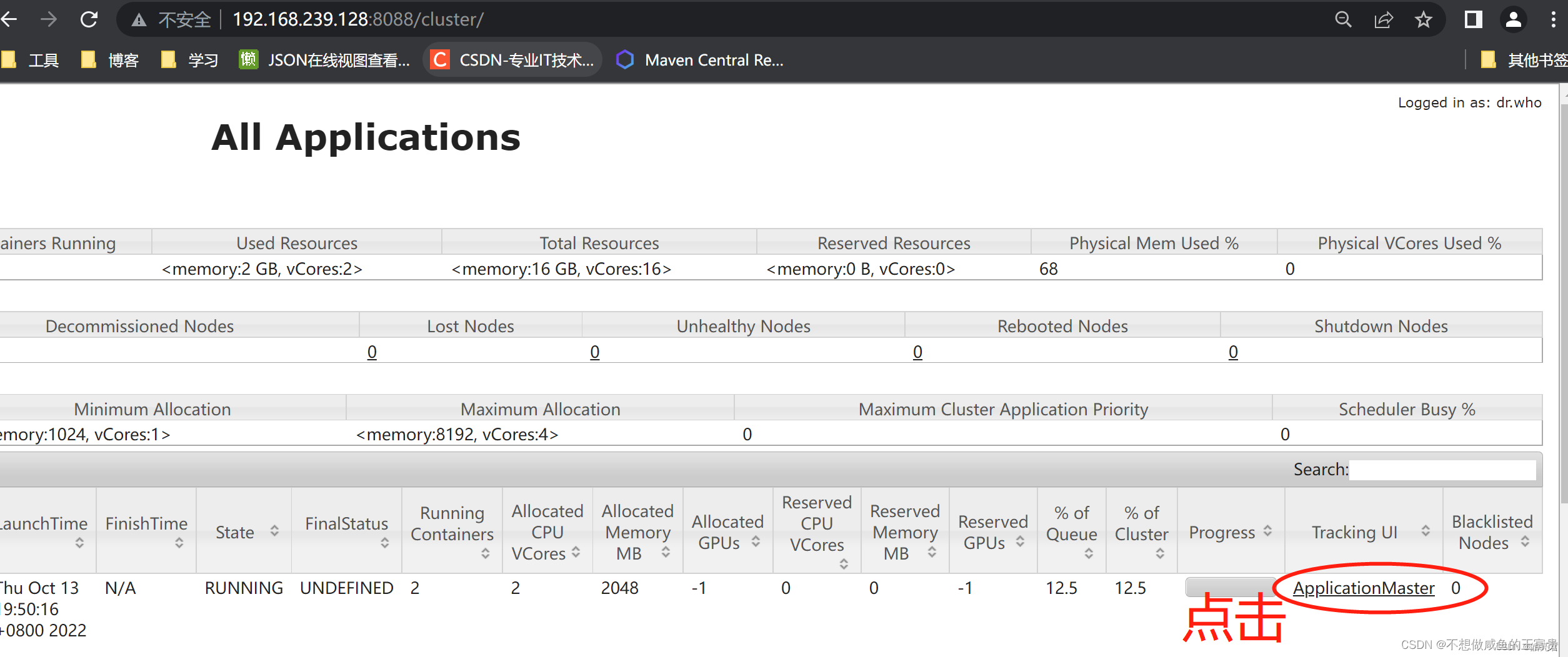
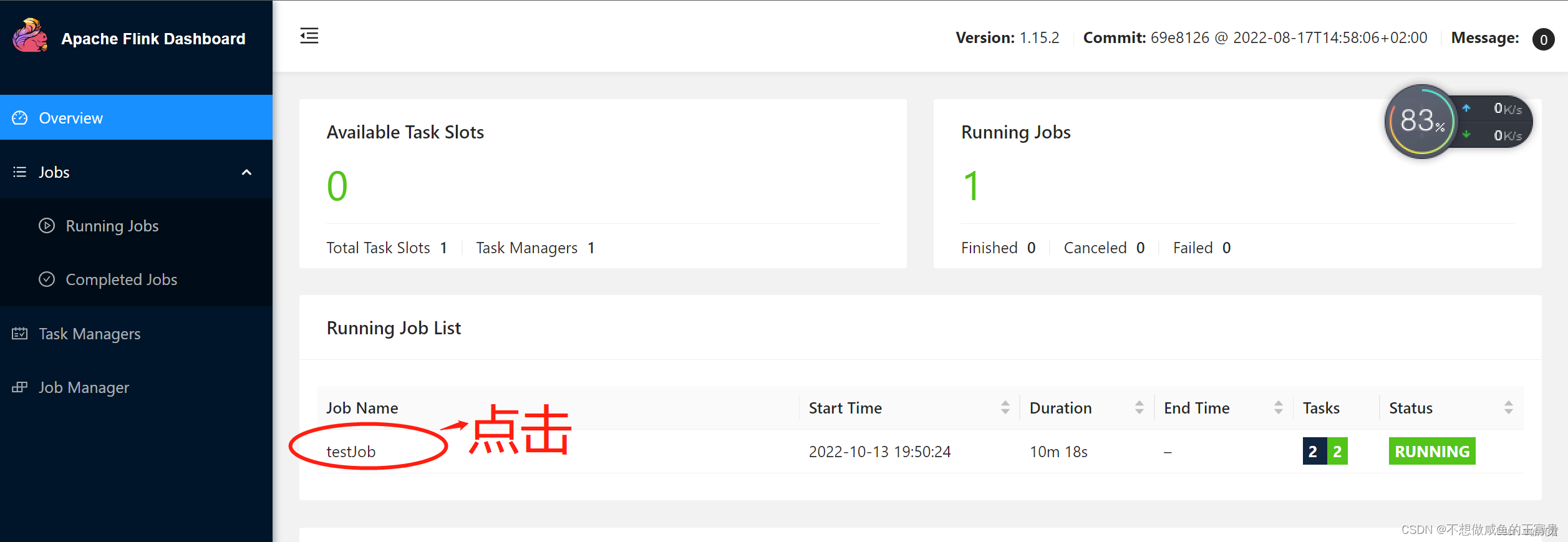
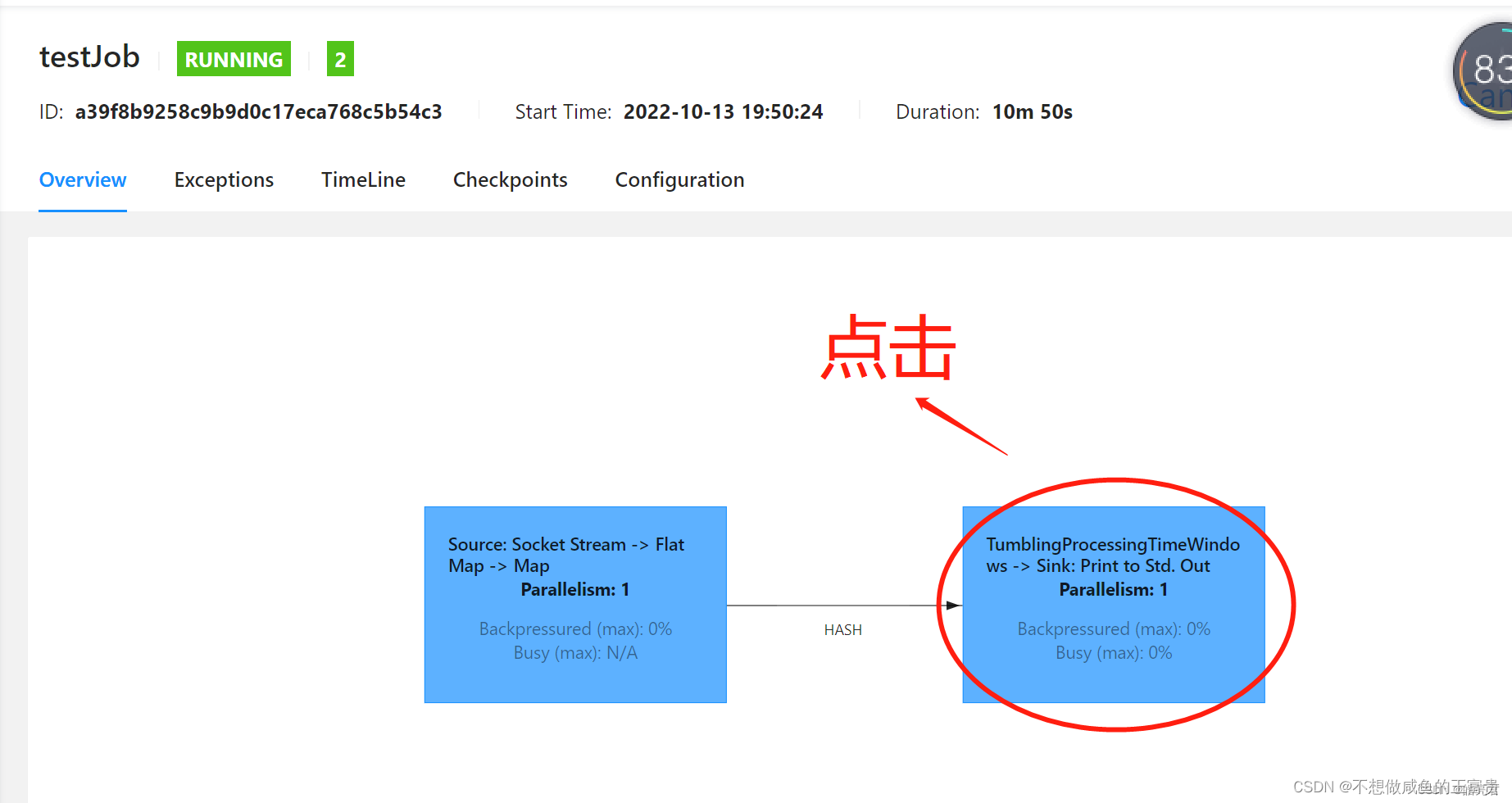
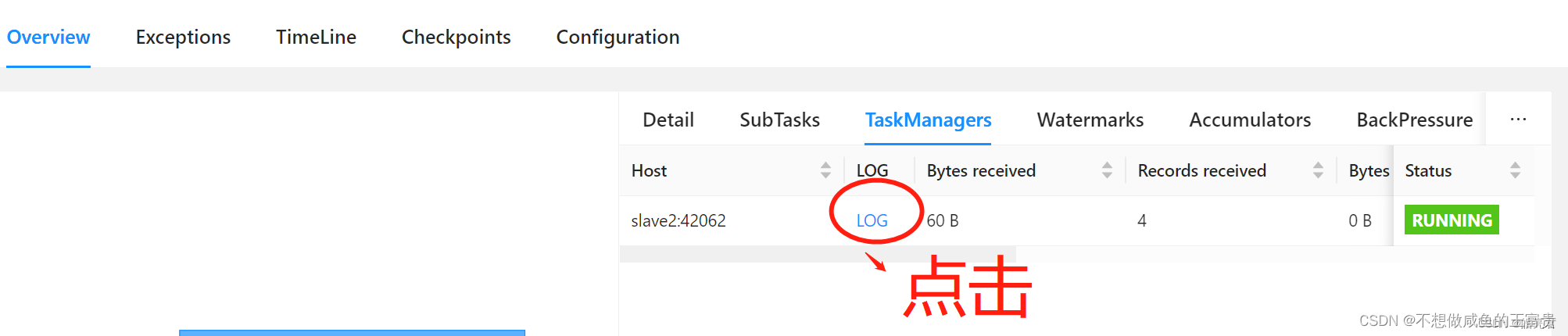
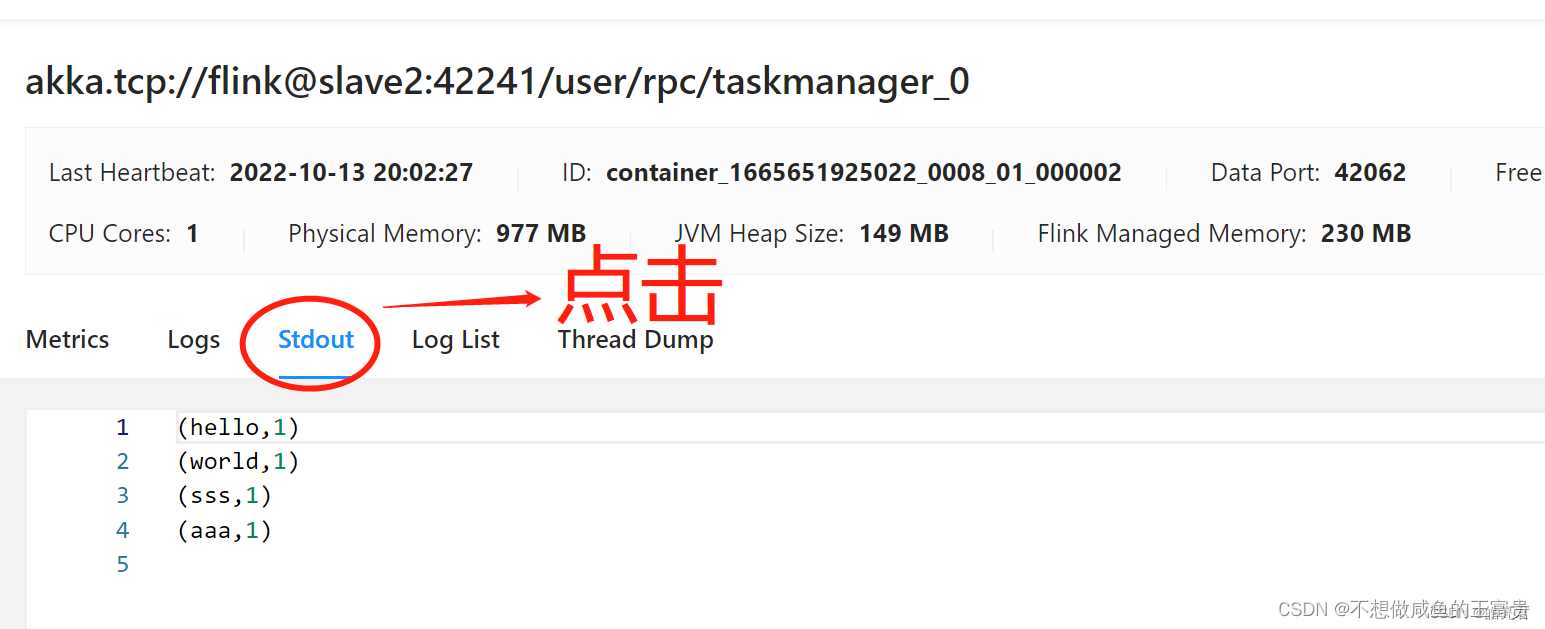
8.5.停止任务
通过YARN命令停止
yarn application -kill application_1665651925022_0008
或通过Flink命令停止
bin/flink cancel -yid application_1665651925022_0008 a39f8b9258c9b9d0c17eca768c5b54c3