every blog every motto: You can do more than you think.
0. 前言
transformer注解
在过去的一年里,《Attention is all you need》中的transformer一直萦绕在很多人的脑海里。除了在翻译质量上产生重大改进之外,它还为许多其他NLP任务提供了一种新的架构。论文本身写得很清楚,但传统观点认为很难正确执行。
在这篇文章中,我将以逐行实现的形式呈现论文的注释版本。我重新整理并删除了原论文中的一些章节,并在全文中添加了注释。这个文档本身就是一个工作笔记本,应该是一个完全可用的实现(可以在jupyter notebook中运行)。总共有400行库代码,可以在4个gpu上每秒处理27,000个token。
要继续学习,首先需要安装PyTorch。完整的笔记本也可以在github或谷歌Colab上使用免费的gpu。
请注意,这仅仅是研究人员和感兴趣的开发人员的起点。这里的代码主要基于我们的OpenNMT包。(如果有帮助,请随意引用。)对于模型的其他全服务实现,请检查Tensor2Tensor (tensorflow)和Sockeye (mxnet)
0.1 准备
# !pip install http://download.pytorch.org/whl/cu80/torch-0.3.0.post4-cp36-cp36m-linux_x86_64.whl numpy matplotlib spacy torchtext seaborn
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy, time
from torch.autograd import Variable
import matplotlib.pyplot as plt
import seaborn
seaborn.set_context(context="talk")
%matplotlib inline
1. 背景
减少sequential计算的目标也构成了Extended Neural GPU、ByteNet和ConvS2S的基础,它们都使用卷积神经网络作为基本构建块,并行计算所有输入和输出位置的隐藏表示。在这些模型中,将两个任意输入或输出位置的信号关联起来所需的操作数量随着位置之间的距离而增长,ConvS2S为线性增长,ByteNet为对数增长。这使得学习远距离位置之间的依赖关系变得更加困难。在Transformer中,这被减少到一个恒定的操作数量,尽管其代价是由于平均注意加权位置而降低了有效分辨率,我们使用多头注意抵消了这一影响
之前计算两个数据之间的关联,计算量随着位置增加而增加,而Transformer将其减少到了一个恒定操作数量,具体是怎么减少的?
self-attention,有时被称为内间注意力,是一种将单向(single)序列的不同位置联系起来以计算该序列的表示的注意机制。self-attention在阅读理解、抽象总结、文本蕴涵和学习任务无关的句子表征等任务中得到了成功的应用。端到端记忆网络基于循环注意机制,而不是基于sequence-aligned recurrence,并已被证明在简单语言问答和语言建模任务中表现良好。
然而,据我们所知,Transformer是第一个完全依赖于self-attention来计算其输入和输出表示的转换模型,而不使用sequence-aligned RNNs或卷积
2. 模型结构
Most competitive neural sequence transduction models have an encoder-decoder structure. 这里,编码器将符号表示 的输入序列 ( x 1 , … , x n ) (x_1,…,x_n) (x1,…,xn)映射到连续表示的序列 z = ( z 1 , … , z n ) \mathbf{z} = (z_1,…,z_n) z=(z1,…,zn)。给定 z \mathbf{z} z,解码器每次生成一个输出序列 ( y 1 , … , y m ) (y_1,…,y_m) (y1,…,ym)。在每个步骤中,模型都是自回归(auto-regressive),使用先前生成的符号作为额外的输入,再进行下一步。
整体结构如下:
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask,
tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
标准的全连接层+softmax
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)
Transformer整体架构如下,使用堆叠的self-attention和point-wise,编码器和解码器的完全连接层,分别如图1的左半部分和右半部分所示
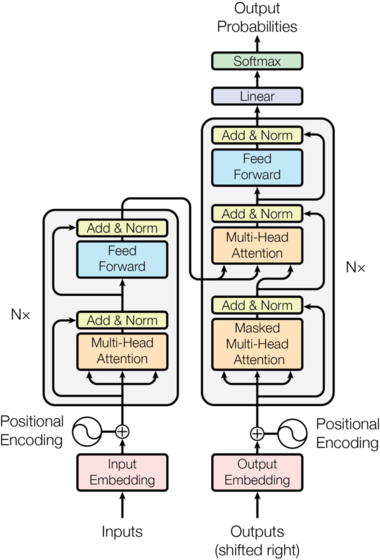
2.1 Encoder and Decoder
2.1.1 Encoder
编码器由 N = 6 N=6 N=6相同层的堆栈组成
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
编码器的整体结构,生成6个相同的层
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size) # 这里的是层的标准化
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
我们在两个子层之间使用了一个残差连接,然后是layer normalization
如下是layer normalization
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2 # 标准化
也就是说,每个子层的输出是 L a y e r N o r m ( x + S u b l a y e r ( x ) ) \mathrm{LayerNorm}(x + \mathrm{Sublayer}(x)) LayerNorm(x+Sublayer(x)),其中 S u b l a y e r ( x ) \mathrm{Sublayer}(x) Sublayer(x)是子层本身实现的函数。我们将dropout应用于每个子层的输出,然后将其添加到子层输入并归一化
为了利用这些残差连接,模型中的所有子层以及嵌入层产生维度 d model = 512 d_{\text{model}}=512 dmodel=512的输出
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
# return x + self.dropout(sublayer(self.norm(x))) # 残差连接,
# 换种写法,和上面相同
temp = self.norm(x)
temp = sublayer(temp)
temp = self.dropout(temp)
return x + temp
每一层有两个子层。第一个是多头自注意机制,第二个是一个简单的、position-wise全连接前馈网络
EncoderLayer中有两层,第一层是一个多头注意力,第二层是一个前馈网络
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2) # 有两层
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # 第一层是一个多头
return self.sublayer[1](x, self.feed_forward) # 第二层是一个简单的前馈网络
2.1.2 Decoder
解码器也由 N = 6 N=6 N=6相同层的堆栈组成
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N) # 初始化时,这里是6
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
除了每个编码器层中的两个子层之外,解码器插入第三个子层,该子层对编码器堆栈的输出执行多头注意力。与编码器类似,我们在每个子层周围使用残差连接,然后进行层规范化
decoder由多层组成,每层中又含有三层
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask)) # 第一层
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask)) # 第二层
return self.sublayer[2](x, self.feed_forward) # 第三层
我们还修改了解码器堆栈中的自注意子层,以防止位置关注后续位置。这种掩蔽,再加上输出embeddings偏移一个位置的事实,确保了位置 i i i的预测只能依赖于小于 i i i位置的已知输出
将后面的位置进行掩码(遮住)
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8') # 左下角和对象线为0,
return torch.from_numpy(subsequent_mask) == 0
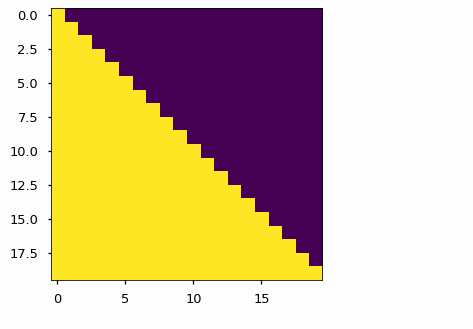
attenion 掩码如下,每个tgt单词(行)被允许查看的位置(列)。在训练过程中,单词会被屏蔽,以便关注将来的单词
plt.figure(figsize=(5,5))
plt.imshow(subsequent_mask(20)[0])
None
说明: 黄色是能看到的,黑色是看不到的
2.1.3 attention
attenion函数可以描述为将查询(query)和一组键值(key-value)对映射到输出,其中查询、键、值和输出都是向量。输出是作为值的加权和计算的,其中分配给每个值的==权重是由查询(query)与相应键(key)==计算得到。
我们称这种特殊的attention为“Scaled Dot-Product Attention”。输入包括维度为 d k d_k dk的查询和键,维度为 d v d_v dv的值。我们计算查询与所有键的点积,每个点积除以 d k \sqrt{d_k} dk,并应用softmax函数来获得值的权重。
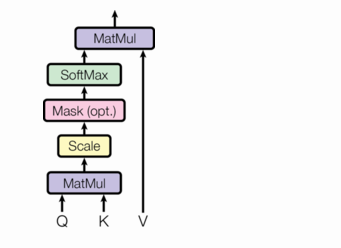
在实践中,我们同时计算一组查询的注意力函数,它们被打包成一个矩阵Q。键和值也打包成矩阵
K
K
K和
V
V
V。我们计算输出矩阵为
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
\mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
两个最常用的注意力函数是加法注意力(additive attention)和点积(dot-product)注意力(乘法)。除了缩放因子 1 d k \frac{1}{\sqrt{d_k}} dk1之外,点积注意力与我们的算法相同。加性注意使用一个具有单个隐藏层的前馈网络来计算兼容性函数。虽然两者在理论复杂性上相似,但在实践中,点积注意力更快,更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
虽然对于较小的 d k d_k dk值,这两种机制的表现相似,,但在不缩放较大的 d k d_k dk值的情况下,加法注意力优于点积注意力。我们怀疑对于 d k d_k dk的大值,点积的大小会变大,将softmax函数推到具有极小梯度的区域(为了说明点积变大的原因,假设 q q q和 k k k的分量是具有平均值 0 0 0和方差 1 1 1的独立随机变量。然后它们的点积 q ⋅ k = ∑ i = 1 d k q i k i q \cdot k = \sum_{i=1}^{d_k} q_ik_i q⋅k=∑i=1dkqiki有均值 0 0 0和方差 d k d_k dk)。 为了抵消这个影响,我们将点积乘以 1 d k \frac{1}{\sqrt{d_k}} dk1 。
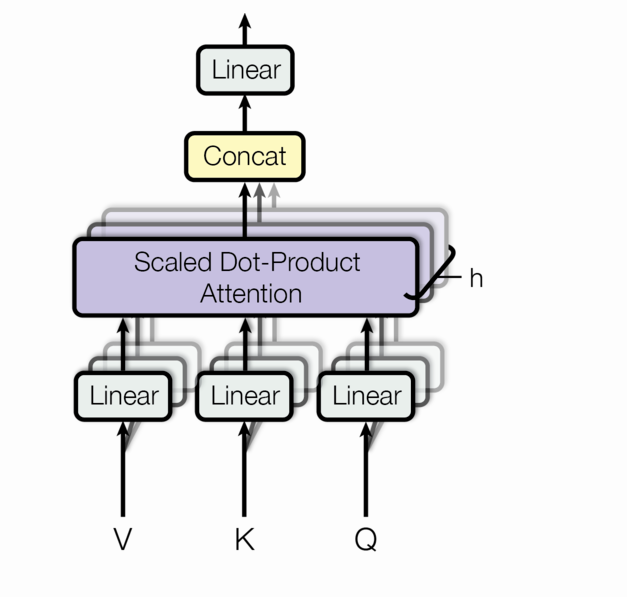
多头注意允许模型在不同位置共同注意来自不同表示子空间的信息。对于单一注意力头,平均会抑制这一点。
( M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O where h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) ) (\mathrm{MultiHead}(Q, K, V) = \mathrm{Concat}(\mathrm{head_1}, ..., \mathrm{head_h})W^O \\ \text{where}~\mathrm{head_i} = \mathrm{Attention}(QW^Q_i, KW^K_i, VW^V_i)) (MultiHead(Q,K,V)=Concat(head1,...,headh)WOwhere headi=Attention(QWiQ,KWiK,VWiV))
其中投影是参数矩阵 W i Q ∈ R d model × d k W^Q_i \in \mathbb{R}^{d_{\text{model}} \times d_k} WiQ∈Rdmodel×dk, W i K ∈ R d model × d k W^K_i \in \mathbb{R}^{d_{\text{model}} \times d_k} WiK∈Rdmodel×dk, W i V ∈ R d model × d v W^V_i \in \mathbb{R}^{d_{\text{model}} \times d_v} WiV∈Rdmodel×dv and W O ∈ R h d v × d model W^O \in \mathbb{R}^{hd_v \times d_{\text{model}}} WO∈Rhdv×dmodel.。在这项工作中,我们使用 h = 8 h=8 h=8平行注意层,或头。对于这些,我们使用 d k = d v = d model / h = 64 d_k=d_v=d_{\text{model}}/h=64 dk=dv=dmodel/h=64。由于每个头部的维数降低,因此总计算成本与全维的单头部关注相似。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)
2.1.4 Applications of Attention in our Model
Transformer以三种不同的方式使用多头注意:
1)在“编码器-解码器注意”层中,查询来自前一个解码器层,而记忆键和值来自编码器的输出。这允许解码器中的每个位置都参与输入序列中的所有位置。这模仿了序列到序列模型中典型的编码器-解码器注意机制,例如(引用)。
2)编码器包含自关注层。在自关注层中,所有的键、值和查询都来自同一个地方,在这种情况下,是编码器中前一层的输出。编码器中的每个位置都可以处理编码器前一层中的所有位置。
3)类似地,解码器中的自注意层允许解码器中的每个位置注意到解码器中的所有位置直至并包括该位置。我们需要防止解码器中的向左信息流以保持自回归特性。我们通过屏蔽(设置为 − ∞ -\infty −∞) softmax输入中对应于非法连接的所有值来实现缩放点积注意。
2.1.5 Position-wise Feed-Forward Networks
除了注意子层之外,编码器和解码器中的每一层都包含一个完全连接的前馈网络,该网络分别相同地应用于每个位置。这包括两个线性转换,中间有一个ReLU激活。
[ F F N ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 ] [\mathrm{FFN}(x)=\max(0, xW_1 + b_1) W_2 + b_2] [FFN(x)=max(0,xW1+b1)W2+b2]
虽然线性变换在不同位置上是相同的,但它们在每一层之间使用不同的参数。另一种描述它的方式是两个核大小为1的卷积。输入输出维度为 d model = 512 d_{\text{model}}=512 dmodel=512,内层维度为 d f f = 2048 d_{ff}=2048 dff=2048。
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
2.1.6 Embeddings and Softmax
与其他序列转导模型类似,我们使用学习的嵌入将输入标记和输出标记转换为维度 d model d_{\text{model}} dmodel的向量。我们还使用通常学习的线性变换和softmax函数将解码器输出转换为预测的下一个令牌概率。在我们的模型中,我们在两个嵌入层和pre-softmax线性变换之间共享相同的权重矩阵,类似于(引用)。在嵌入层中,我们将这些权重乘以 d model \sqrt{d_{\text{model}}} dmodel。
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
2.1.7 Positional Encoding
由于我们的模型不包含递归和卷积,为了使模型利用序列的顺序,我们必须注入一些关于序列中标记的相对或绝对位置的信息。为此,我们在编码器和解码器堆栈底部的输入嵌入中添加了“位置编码”。位置编码与嵌入具有相同的维数 d model d_{\text{model}} dmodel,因此两者可以相加。有许多位置编码的选择,学习和固定(引用)
在这项工作中,我们使用了不同频率的正弦和余弦函数: ( P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d model ) ) (PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{\text{model}}})) (PE(pos,2i)=sin(pos/100002i/dmodel))
$(PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{\text{model}}})) 其中 其中 其中pos 为位置, 为位置, 为位置,i$为尺寸。也就是说,位置编码的每一个维度对应于一个正弦波。波长形成从 2 π 2\pi 2π到 10000 ⋅ 2 π 10000 \cdot 2\pi 10000⋅2π的几何级数。我们选择这个函数是因为我们假设它可以让模型很容易地学习相对位置,因为对于任何固定的偏移 k k k, P E p o s + k PE_{pos+k} PEpos+k可以表示为 P E p o s PE_{pos} PEpos的线性函数。
此外,我们将dropout应用于编码器和解码器堆栈中的嵌入和位置编码之和。对于基本模型,我们使用 P d r o p = 0.1 P_{drop}=0.1 Pdrop=0.1的比率
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)],
requires_grad=False)
return self.dropout(x)
下面的位置编码将根据位置添加正弦波。波的频率和偏移量在每个维度上都是不同的。
plt.figure(figsize=(15, 5))
pe = PositionalEncoding(20, 0)
y = pe.forward(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d"%p for p in [4,5,6,7]])
None

我们还尝试使用学习位置嵌入(引用),并发现这两个版本产生了几乎相同的结果。我们选择正弦版本是因为它可以允许模型外推到比训练期间遇到的序列长度更长的序列。
3.模型
这里我们定义了一个函数,它接受超参数并产生一个完整的模型
def make_model(src_vocab, tgt_vocab, N=6,
d_model=512, d_ff=2048, h=8, dropout=0.1):
"Helper: Construct a model from hyperparameters."
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
position = PositionalEncoding(d_model, dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn),
c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
# This was important from their code.
# Initialize parameters with Glorot / fan_avg.
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform(p)
return model
# Small example model.
tmp_model = make_model(10, 10, 2)
None
3.1 训练
本节描述了我们模型的训练机制。
我们停下来休息一下,介绍一些训练标准编码器和解码器模型所需的工具。首先,我们定义一个批处理对象,其中包含用于训练的src和目标句子,以及构造掩码
3.1.1 batches and masking
class Batch:
"Object for holding a batch of data with mask during training."
def __init__(self, src, trg=None, pad=0):
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
self.trg_mask = \
self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
tgt_mask = (tgt != pad).unsqueeze(-2)
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask
接下来,我们创建一个通用的训练和评分函数来跟踪损失。我们传入一个泛型损失计算函数,该函数也处理参数更新
3.1.2 training loop
def run_epoch(data_iter, model, loss_compute):
"Standard Training and Logging Function"
start = time.time()
total_tokens = 0
total_loss = 0
tokens = 0
for i, batch in enumerate(data_iter):
out = model.forward(batch.src, batch.trg,
batch.src_mask, batch.trg_mask)
loss = loss_compute(out, batch.trg_y, batch.ntokens)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed = time.time() - start
print("Epoch Step: %d Loss: %f Tokens per Sec: %f" %
(i, loss / batch.ntokens, tokens / elapsed))
start = time.time()
tokens = 0
return total_loss / total_tokens
3.1.3 training data and batching
我们在标准的WMT 2014英语-德语数据集上进行训练,该数据集由大约450万句对组成。句子使用字节对编码进行编码,这种编码具有大约37000个标记的共享源-目标词汇表。对于英语-法语,我们使用了更大的WMT 2014英语-法语数据集,该数据集由36M个句子组成,并将标记拆分为32000个单词片词汇
句子对按近似序列长度进行批处理。每个训练批包含一组句子对,其中包含大约25000个源标记和25000个目标标记
我们将使用火炬文本进行批处理。下面将对此进行更详细的讨论。这里,我们在torchtext函数中创建批,以确保我们的批大小填充到最大批大小不超过阈值(如果我们有8个gpu,则为25000)
global max_src_in_batch, max_tgt_in_batch
def batch_size_fn(new, count, sofar):
"Keep augmenting batch and calculate total number of tokens + padding."
global max_src_in_batch, max_tgt_in_batch
if count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max(max_src_in_batch, len(new.src))
max_tgt_in_batch = max(max_tgt_in_batch, len(new.trg) + 2)
src_elements = count * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max(src_elements, tgt_elements)
3.1.4 Hardware and Schedule
我们在一台带有8个NVIDIA P100 gpu的机器上训练我们的模型。对于使用本文中描述的超参数的基本模型,每个训练步骤大约需要0.4秒。我们对基本模型进行了总共10万步或12小时的训练。对于我们的大型模型,步长是1.0秒。大模特训练了30万步(3.5天)
3.1.5 Optimizer
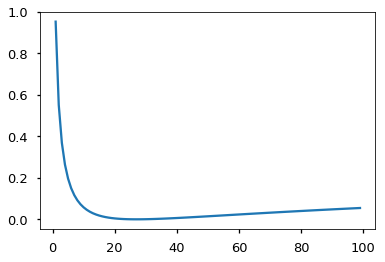
我们使用了Adam优化器(引用) β 1 = 0.9 \beta_1=0.9 β1=0.9, β 2 = 0.98 \beta_2=0.98 β2=0.98和 ϵ = 1 0 − 9 \epsilon=10^{-9} ϵ=10−9。我们根据公式在训练过程中改变学习率:(lrate = d_{\text{model}}^{-0.5} \cdot \min({step_num}^{-0.5}, {step_num} \cdot {warmup_steps}^{-1.5}))这对应于在第一个 w a r m u p s t e p s warmup_steps warmupsteps训练步骤中线性增加学习率,然后按步数的平方根的倒数成比例地降低学习率。我们使用 w a r m u p s t e p s = 4000 warmup_steps=4000 warmupsteps=4000。
这部分非常重要。需要用这个模型的设置进行训练
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step is None:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
该模型在不同模型尺寸和优化超参数下的曲线示例
# Three settings of the lrate hyperparameters.
opts = [NoamOpt(512, 1, 4000, None),
NoamOpt(512, 1, 8000, None),
NoamOpt(256, 1, 4000, None)]
plt.plot(np.arange(1, 20000), [[opt.rate(i) for opt in opts] for i in range(1, 20000)])
plt.legend(["512:4000", "512:8000", "256:4000"])
None

3.1.6 regularization
label smoothing
在训练过程中,我们使用值 ϵ l s = 0.1 \epsilon {ls}=0.1 ϵls=0.1 (cite)的标签平滑。这损害了困惑,因为模型学会了更不确定,但提高了准确性和BLEU分数
我们使用KL div损失来实现标签平滑。我们没有使用单一目标分布,而是创建了一个对正确单词和整个词汇表中分布的其余平滑质量具有置信度的分布
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(size_average=False)
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, Variable(true_dist, requires_grad=False))
在这里,我们可以看到一个基于置信度的质量如何分布到单词上的例子
# Example of label smoothing.
crit = LabelSmoothing(5, 0, 0.4)
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0]])
v = crit(Variable(predict.log()),
Variable(torch.LongTensor([2, 1, 0])))
# Show the target distributions expected by the system.
plt.imshow(crit.true_dist)
None

标签平滑实际上开始惩罚模型,如果它对给定的选择非常有信心
crit = LabelSmoothing(5, 0, 0.1)
def loss(x):
d = x + 3 * 1
predict = torch.FloatTensor([[0, x / d, 1 / d, 1 / d, 1 / d],
])
#print(predict)
return crit(Variable(predict.log()),
Variable(torch.LongTensor([1]))).data[0]
plt.plot(np.arange(1, 100), [loss(x) for x in range(1, 100)])
None
3.2 example
我们可以从一个简单的复制任务开始。给定一个小词汇表中的随机输入符号集,目标是生成这些相同的符号
3.2.1 Synthetic Data
def data_gen(V, batch, nbatches):
"Generate random data for a src-tgt copy task."
for i in range(nbatches):
data = torch.from_numpy(np.random.randint(1, V, size=(batch, 10)))
data[:, 0] = 1
src = Variable(data, requires_grad=False)
tgt = Variable(data, requires_grad=False)
yield Batch(src, tgt, 0)
3.2.2 Loss Computation
class SimpleLossCompute:
"A simple loss compute and train function."
def __init__(self, generator, criterion, opt=None):
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self, x, y, norm):
x = self.generator(x)
loss = self.criterion(x.contiguous().view(-1, x.size(-1)),
y.contiguous().view(-1)) / norm
loss.backward()
if self.opt is not None:
self.opt.step()
self.opt.optimizer.zero_grad()
return loss.data[0] * norm
3.2.3 Greedy Decoding
# Train the simple copy task.
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 400,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
for epoch in range(10):
model.train()
run_epoch(data_gen(V, 30, 20), model,
SimpleLossCompute(model.generator, criterion, model_opt))
model.eval()
print(run_epoch(data_gen(V, 30, 5), model,
SimpleLossCompute(model.generator, criterion, None)))
Epoch Step: 1 Loss: 3.023465 Tokens per Sec: 403.074173
Epoch Step: 1 Loss: 1.920030 Tokens per Sec: 641.689380
1.9274832487106324
Epoch Step: 1 Loss: 1.940011 Tokens per Sec: 432.003378
Epoch Step: 1 Loss: 1.699767 Tokens per Sec: 641.979665
1.657595729827881
Epoch Step: 1 Loss: 1.860276 Tokens per Sec: 433.320240
Epoch Step: 1 Loss: 1.546011 Tokens per Sec: 640.537198
1.4888023376464843
Epoch Step: 1 Loss: 1.682198 Tokens per Sec: 432.092305
Epoch Step: 1 Loss: 1.313169 Tokens per Sec: 639.441857
1.3485562801361084
Epoch Step: 1 Loss: 1.278768 Tokens per Sec: 433.568756
Epoch Step: 1 Loss: 1.062384 Tokens per Sec: 642.542067
0.9853351473808288
Epoch Step: 1 Loss: 1.269471 Tokens per Sec: 433.388727
Epoch Step: 1 Loss: 0.590709 Tokens per Sec: 642.862135
0.5686767101287842
Epoch Step: 1 Loss: 0.997076 Tokens per Sec: 433.009746
Epoch Step: 1 Loss: 0.343118 Tokens per Sec: 642.288427
0.34273059368133546
Epoch Step: 1 Loss: 0.459483 Tokens per Sec: 434.594030
Epoch Step: 1 Loss: 0.290385 Tokens per Sec: 642.519464
0.2612409472465515
Epoch Step: 1 Loss: 1.031042 Tokens per Sec: 434.557008
Epoch Step: 1 Loss: 0.437069 Tokens per Sec: 643.630322
0.4323212027549744
Epoch Step: 1 Loss: 0.617165 Tokens per Sec: 436.652626
Epoch Step: 1 Loss: 0.258793 Tokens per Sec: 644.372296
0.27331129014492034
为了简单起见,此代码使用贪婪解码预测翻译
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len-1):
out = model.decode(memory, src_mask,
Variable(ys),
Variable(subsequent_mask(ys.size(1))
.type_as(src.data)))
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.data[0]
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
model.eval()
src = Variable(torch.LongTensor([[1,2,3,4,5,6,7,8,9,10]]) )
src_mask = Variable(torch.ones(1, 1, 10) )
print(greedy_decode(model, src, src_mask, max_len=10, start_symbol=1))
1 2 3 4 5 6 7 8 9 10
[torch.LongTensor of size 1x10]
3.3 real world example
现在我们考虑一个使用IWSLT德语-英语翻译任务的真实示例。这个任务比本文中考虑的WMT任务小得多,但它说明了整个系统。我们还展示了如何使用多gpu处理使其非常快
#!pip install torchtext spacy
#!python -m spacy download en
#!python -m spacy download de
3.3.1 data loading
我们将使用火炬文本和空间加载数据集进行标记化
# For data loading.
from torchtext import data, datasets
if True:
import spacy
spacy_de = spacy.load('de')
spacy_en = spacy.load('en')
def tokenize_de(text):
return [tok.text for tok in spacy_de.tokenizer(text)]
def tokenize_en(text):
return [tok.text for tok in spacy_en.tokenizer(text)]
BOS_WORD = '<s>'
EOS_WORD = '</s>'
BLANK_WORD = "<blank>"
SRC = data.Field(tokenize=tokenize_de, pad_token=BLANK_WORD)
TGT = data.Field(tokenize=tokenize_en, init_token = BOS_WORD,
eos_token = EOS_WORD, pad_token=BLANK_WORD)
MAX_LEN = 100
train, val, test = datasets.IWSLT.splits(
exts=('.de', '.en'), fields=(SRC, TGT),
filter_pred=lambda x: len(vars(x)['src']) <= MAX_LEN and
len(vars(x)['trg']) <= MAX_LEN)
MIN_FREQ = 2
SRC.build_vocab(train.src, min_freq=MIN_FREQ)
TGT.build_vocab(train.trg, min_freq=MIN_FREQ)
批处理对速度至关重要。我们希望有非常均匀的分批,用绝对最小的填充。要做到这一点,我们必须破解一些默认的火炬文本批处理。这段代码修补了它们的默认批处理,以确保我们搜索足够多的句子来找到紧密的批处理。
3.3.2 Iterators
class MyIterator(data.Iterator):
def create_batches(self):
if self.train:
def pool(d, random_shuffler):
for p in data.batch(d, self.batch_size * 100):
p_batch = data.batch(
sorted(p, key=self.sort_key),
self.batch_size, self.batch_size_fn)
for b in random_shuffler(list(p_batch)):
yield b
self.batches = pool(self.data(), self.random_shuffler)
else:
self.batches = []
for b in data.batch(self.data(), self.batch_size,
self.batch_size_fn):
self.batches.append(sorted(b, key=self.sort_key))
def rebatch(pad_idx, batch):
"Fix order in torchtext to match ours"
src, trg = batch.src.transpose(0, 1), batch.trg.transpose(0, 1)
return Batch(src, trg, pad_idx)
3.3.3 Multi-GPU Training
最后要真正针对快速训练,我们将使用多gpu。此代码实现了多gpu字生成。它不是特定于变压器,所以我不会进入太多的细节。这个想法是在训练时将单词生成分解成块,以便在许多不同的gpu上并行处理。我们使用pytorch并行原语来实现这一点:
- 复制-分裂模块到不同的gpu。
- 分散-将批次分散到不同的gpu上
- Parallel_apply -在不同的gpu上批量应用模块
- 收集-将分散的数据拉回到一个gpu上。
- 神经网络。dataparliel——一个特殊的模块包装器,在求值之前调用所有这些。
# Skip if not interested in multigpu.
class MultiGPULossCompute:
"A multi-gpu loss compute and train function."
def __init__(self, generator, criterion, devices, opt=None, chunk_size=5):
# Send out to different gpus.
self.generator = generator
self.criterion = nn.parallel.replicate(criterion,
devices=devices)
self.opt = opt
self.devices = devices
self.chunk_size = chunk_size
def __call__(self, out, targets, normalize):
total = 0.0
generator = nn.parallel.replicate(self.generator,
devices=self.devices)
out_scatter = nn.parallel.scatter(out,
target_gpus=self.devices)
out_grad = [[] for _ in out_scatter]
targets = nn.parallel.scatter(targets,
target_gpus=self.devices)
# Divide generating into chunks.
chunk_size = self.chunk_size
for i in range(0, out_scatter[0].size(1), chunk_size):
# Predict distributions
out_column = [[Variable(o[:, i:i+chunk_size].data,
requires_grad=self.opt is not None)]
for o in out_scatter]
gen = nn.parallel.parallel_apply(generator, out_column)
# Compute loss.
y = [(g.contiguous().view(-1, g.size(-1)),
t[:, i:i+chunk_size].contiguous().view(-1))
for g, t in zip(gen, targets)]
loss = nn.parallel.parallel_apply(self.criterion, y)
# Sum and normalize loss
l = nn.parallel.gather(loss,
target_device=self.devices[0])
l = l.sum()[0] / normalize
total += l.data[0]
# Backprop loss to output of transformer
if self.opt is not None:
l.backward()
for j, l in enumerate(loss):
out_grad[j].append(out_column[j][0].grad.data.clone())
# Backprop all loss through transformer.
if self.opt is not None:
out_grad = [Variable(torch.cat(og, dim=1)) for og in out_grad]
o1 = out
o2 = nn.parallel.gather(out_grad,
target_device=self.devices[0])
o1.backward(gradient=o2)
self.opt.step()
self.opt.optimizer.zero_grad()
return total * normalize
现在我们创建模型、标准、优化器、数据迭代器和并行化
# GPUs to use
devices = [0, 1, 2, 3]
if True:
pad_idx = TGT.vocab.stoi["<blank>"]
model = make_model(len(SRC.vocab), len(TGT.vocab), N=6)
model.cuda()
criterion = LabelSmoothing(size=len(TGT.vocab), padding_idx=pad_idx, smoothing=0.1)
criterion.cuda()
BATCH_SIZE = 12000
train_iter = MyIterator(train, batch_size=BATCH_SIZE, device=0,
repeat=False, sort_key=lambda x: (len(x.src), len(x.trg)),
batch_size_fn=batch_size_fn, train=True)
valid_iter = MyIterator(val, batch_size=BATCH_SIZE, device=0,
repeat=False, sort_key=lambda x: (len(x.src), len(x.trg)),
batch_size_fn=batch_size_fn, train=False)
model_par = nn.DataParallel(model, device_ids=devices)
None
现在我们训练模型。我将稍微使用一下热身步骤,但其他一切都使用默认参数。在具有4个Tesla v100的AWS p3.8xlarge上,这以每秒约27,000个令牌的速度运行,批量大小为12,000个
3.3.4 training the system
#!wget https://s3.amazonaws.com/opennmt-models/iwslt.pt
if False:
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 2000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
for epoch in range(10):
model_par.train()
run_epoch((rebatch(pad_idx, b) for b in train_iter),
model_par,
MultiGPULossCompute(model.generator, criterion,
devices=devices, opt=model_opt))
model_par.eval()
loss = run_epoch((rebatch(pad_idx, b) for b in valid_iter),
model_par,
MultiGPULossCompute(model.generator, criterion,
devices=devices, opt=None))
print(loss)
else:
model = torch.load("iwslt.pt")
经过训练后,我们可以解码模型以生成一组翻译。这里我们简单地翻译验证集中的第一个句子。这个数据集非常小,所以贪婪搜索的翻译是相当准确的
for i, batch in enumerate(valid_iter):
src = batch.src.transpose(0, 1)[:1]
src_mask = (src != SRC.vocab.stoi["<blank>"]).unsqueeze(-2)
out = greedy_decode(model, src, src_mask,
max_len=60, start_symbol=TGT.vocab.stoi["<s>"])
print("Translation:", end="\t")
for i in range(1, out.size(1)):
sym = TGT.vocab.itos[out[0, i]]
if sym == "</s>": break
print(sym, end =" ")
print()
print("Target:", end="\t")
for i in range(1, batch.trg.size(0)):
sym = TGT.vocab.itos[batch.trg.data[i, 0]]
if sym == "</s>": break
print(sym, end =" ")
print()
break
Translation: <unk> <unk> . In my language , that means , thank you very much .
Gold: <unk> <unk> . It means in my language , thank you very much .
3.3.5 Additional Components: BPE, Search, Averaging
这主要涵盖了变压器模型本身。有四个方面我们没有明确讨论。我们还在OpenNMT-py中实现了所有这些附加功能
\1) BPE/ Word-piece:我们可以使用一个库先将数据预处理成子词单元。参见Rico Sennrich的subword- nmt实现。这些模型会将训练数据转换成这样
▁Die ▁Protokoll datei ▁kann ▁ heimlich ▁per ▁E - Mail ▁oder ▁FTP ▁an ▁einen ▁bestimmte n ▁Empfänger ▁gesendet ▁werden .
2)共享嵌入:当使用具有共享词汇表的BPE时,我们可以在源/目标/生成器之间共享相同的权重向量。详情请参阅(引用)。要将其添加到模型中,只需执行以下操作
if False:
model.src_embed[0].lut.weight = model.tgt_embeddings[0].lut.weight
model.generator.lut.weight = model.tgt_embed[0].lut.weight
3)光束搜索:这有点太复杂了。有关pytorch的实现,请参阅OpenNMT- py
4)模型平均:本文对最后k个检查点进行平均,以创建集成效果。如果我们有很多模型,我们可以事后再做
def average(model, models):
"Average models into model"
for ps in zip(*[m.params() for m in [model] + models]):
p[0].copy_(torch.sum(*ps[1:]) / len(ps[1:]))
3.4 Results
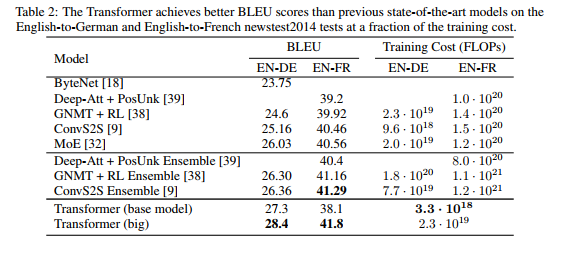
在WMT 2014英德翻译任务中,大型变压器模型(表2中的transformer (big))比之前报道的最佳模型(包括集成)高出2.0 BLEU以上,建立了新的最先进的BLEU分数28.4。该模型的配置列在表3的底线。训练时间为3.5天,使用的是8个P100图形处理器。甚至我们的基本模型也超过了所有以前发表的模型和集合,而训练成本只是任何竞争模型的一小部分。
在WMT 2014英法翻译任务上,我们的大模型获得了41.0的BLEU分数,优于之前发布的所有单一模型,而训练成本不到之前最先进模型的1/4。训练为英语到法语的Transformer(大)模型使用的辍学率Pdrop = 0.1,而不是0.3。
我们在这里编写的代码是基本模型的一个版本。这里有这个系统的完整训练版本(示例模型)
通过上一节中的附加扩展,OpenNMT-py复制在EN-DE WMT上达到了26.9。这里我已经将这些参数加载到我们的重新实现中
!wget https://s3.amazonaws.com/opennmt-models/en-de-model.pt
model, SRC, TGT = torch.load("en-de-model.pt")
model.eval()
sent = "▁The ▁log ▁file ▁can ▁be ▁sent ▁secret ly ▁with ▁email ▁or ▁FTP ▁to ▁a ▁specified ▁receiver".split()
src = torch.LongTensor([[SRC.stoi[w] for w in sent]])
src = Variable(src)
src_mask = (src != SRC.stoi["<blank>"]).unsqueeze(-2)
out = greedy_decode(model, src, src_mask,
max_len=60, start_symbol=TGT.stoi["<s>"])
print("Translation:", end="\t")
trans = "<s> "
for i in range(1, out.size(1)):
sym = TGT.itos[out[0, i]]
if sym == "</s>": break
trans += sym + " "
print(trans)
Translation: <s> ▁Die ▁Protokoll datei ▁kann ▁ heimlich ▁per ▁E - Mail ▁oder ▁FTP ▁an ▁einen ▁bestimmte n ▁Empfänger ▁gesendet ▁werden .
3.4.1 Attention Visualization
即使有一个贪婪的解码器,翻译看起来也很好。我们可以进一步可视化它,看看在每一层注意力上发生了什么
tgt_sent = trans.split()
def draw(data, x, y, ax):
seaborn.heatmap(data,
xticklabels=x, square=True, yticklabels=y, vmin=0.0, vmax=1.0,
cbar=False, ax=ax)
for layer in range(1, 6, 2):
fig, axs = plt.subplots(1,4, figsize=(20, 10))
print("Encoder Layer", layer+1)
for h in range(4):
draw(model.encoder.layers[layer].self_attn.attn[0, h].data,
sent, sent if h ==0 else [], ax=axs[h])
plt.show()
for layer in range(1, 6, 2):
fig, axs = plt.subplots(1,4, figsize=(20, 10))
print("Decoder Self Layer", layer+1)
for h in range(4):
draw(model.decoder.layers[layer].self_attn.attn[0, h].data[:len(tgt_sent), :len(tgt_sent)],
tgt_sent, tgt_sent if h ==0 else [], ax=axs[h])
plt.show()
print("Decoder Src Layer", layer+1)
fig, axs = plt.subplots(1,4, figsize=(20, 10))
for h in range(4):
draw(model.decoder.layers[layer].self_attn.attn[0, h].data[:len(tgt_sent), :len(sent)],
sent, tgt_sent if h ==0 else [], ax=axs[h])
plt.show()
Encoder Layer 2
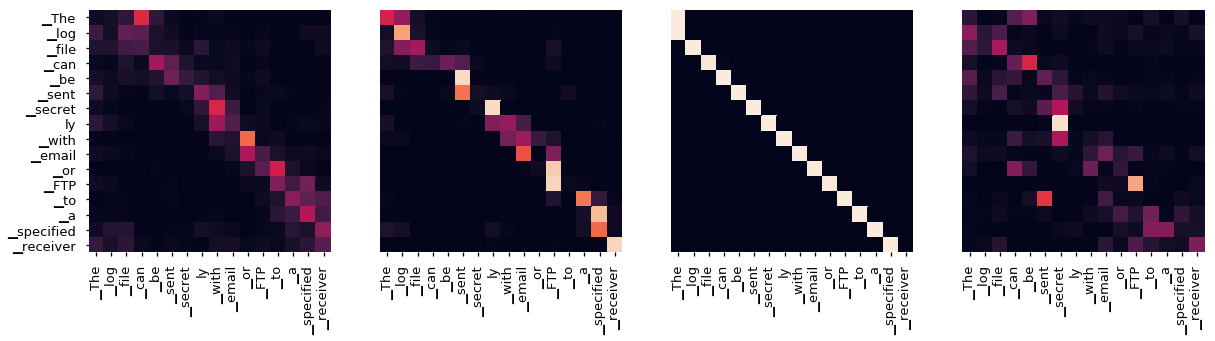
Encoder Layer 4
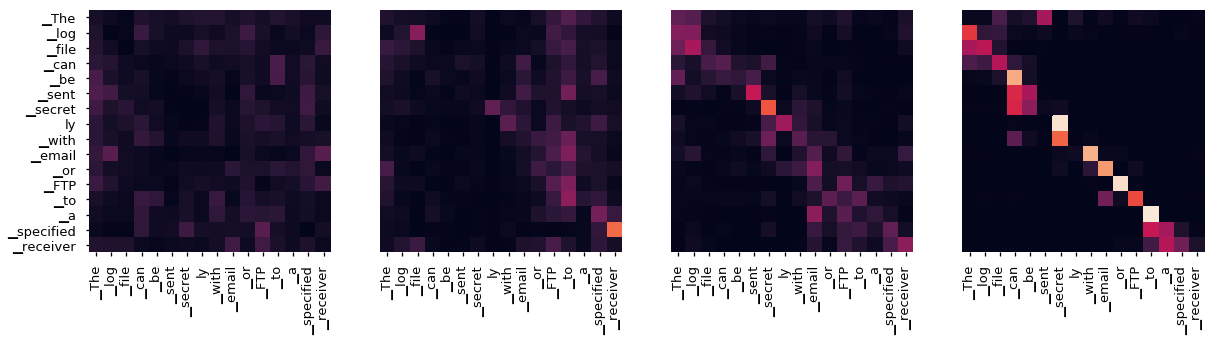
Encoder Layer 6

Decoder Self Layer 2
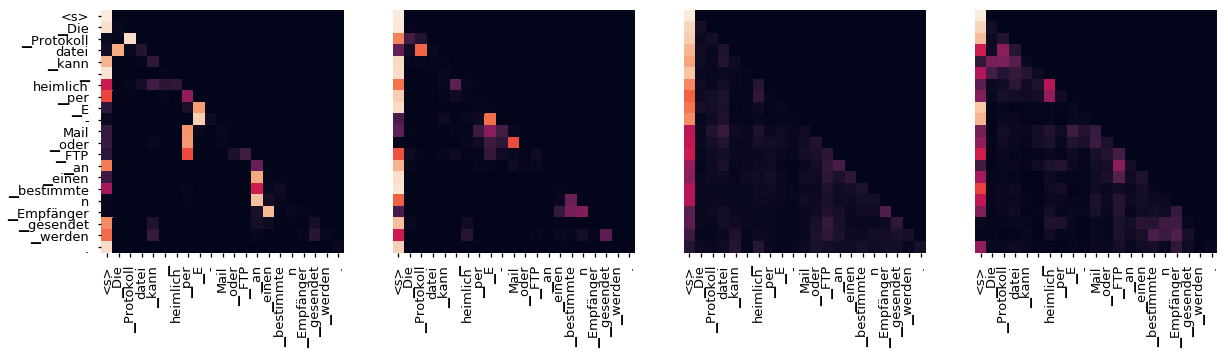
Decoder Src Layer 2
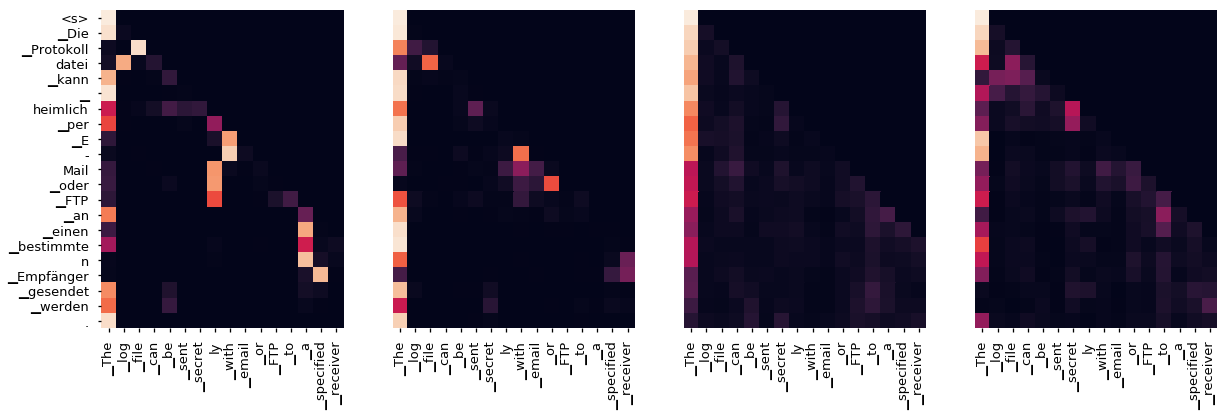
Decoder Self Layer 4
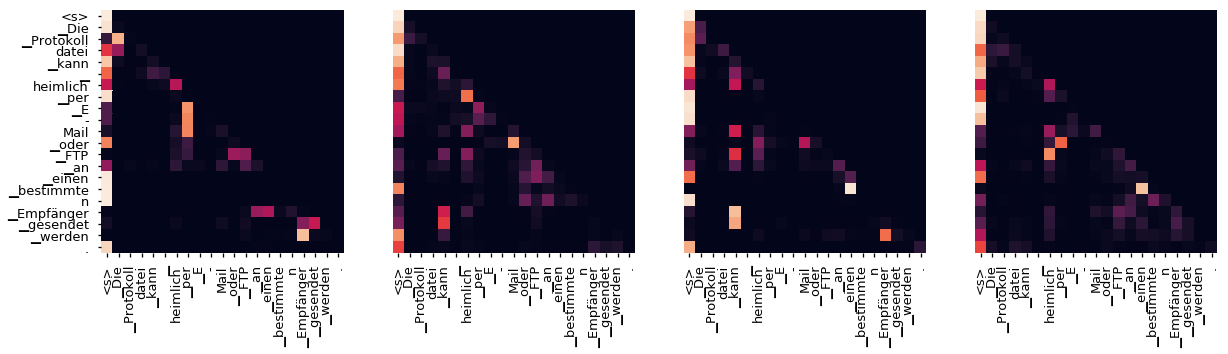
Decoder Src Layer 4
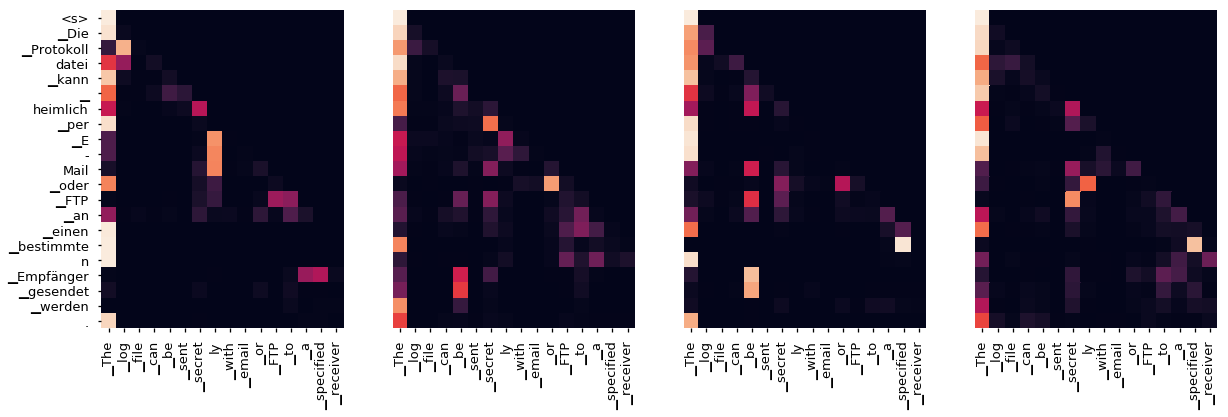
Decoder Self Layer 6
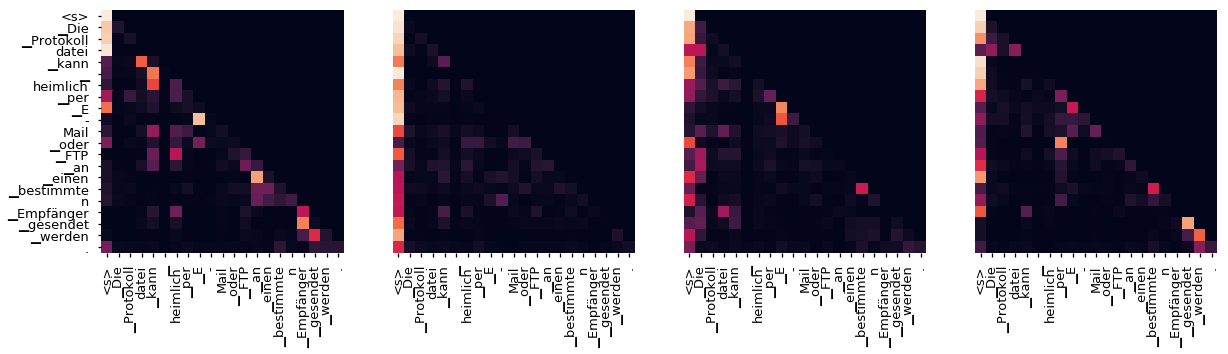
Decoder Src Layer 6
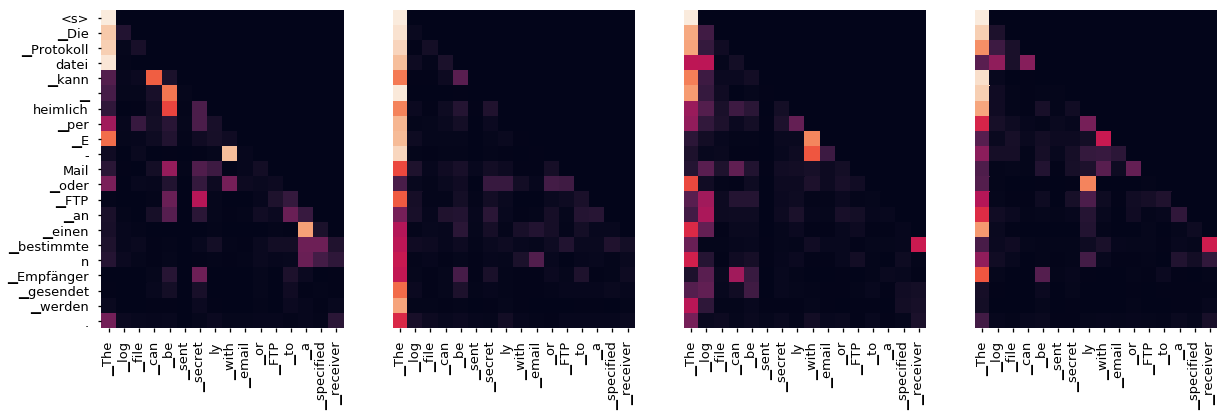
3.5 conclusion
希望这段代码对未来的研究有用。如果你有任何问题,请联系我们。如果您觉得这段代码有帮助,也可以查看我们的其他OpenNMT工具