本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:数据算法工程师必须掌握的5个Python库
如果你是一名初学者或中级机器学习工程师或数据科学家,这篇文章非常适合你。你已经选择了自己喜欢的机器学习库,比如PyTorch或TensorFlow,并且掌握了选择模型正确架构的技巧。你还能够训练模型并解决现实世界的问题。但接下来呢?
在本文中,我将介绍五个我认为每个机器学习工程师和数据科学家都应该熟悉的库。这些将成为你技能集中宝贵的补充,让你成为一个更具竞争力的候选人,并简化机器学习开发过程。
在这篇文章中,我将介绍五个我认为每位机器学习工程师和数据科学家都应该熟悉的库。这些库将成为你技能集的宝贵补充,使你成为一个更具竞争力的候选人,并简化机器学习开发过程。
1.MLFlow---模型实验和跟踪

想象你是一个机器学习开发者,正在从事一个预测客户流失的模型项目。你开始使用Jupyter笔记本探索你的数据,尝试不同的算法和超参数。随着你的进步,你的笔记本变得越来越杂乱,充满了代码、结果和可视化内容。跟踪你的进展、识别哪些方法有效、哪些无效,以及复制你的最佳成果变得困难。
这就是MLflow发挥作用的地方。MLflow是一个平台,帮助你从头到尾管理你的机器学习实验,确保可追溯性和可重复性。它提供了一个集中的存储库,用于存储你的代码、数据和模型工件,以及一个跟踪系统,记录你所有的实验,包括超参数、指标和输出。
以下是MLflow如何帮助你避免单独使用Jupyter笔记本的陷阱:
-
集中存储库:MLflow保持你的代码、数据和模型工件组织有序且易于获取。你可以快速找到你需要的资源,而不会迷失在笔记本的迷宫中。
-
实验跟踪:MLflow记录每一次实验,包括使用的确切代码、数据和超参数。这使你能够轻松比较不同的实验,并识别导致最佳结果的原因。
-
可重复性:MLflow使你能以完全相同的代码、数据和环境重现你的最佳模型。这对于确保结果的一致性和可靠性至关重要。
因此,如果你认真对待构建有效的机器学习模型,就抛弃Jupyter笔记本的混乱,拥抱MLflow的力量吧。
链接:https://mlflow.org/
2. Streamlit---快速且漂亮的网页应用程序

Streamlit是数据科学领域最受欢迎的前端框架。它是一个开源的Python框架,允许用户快速轻松地创建交互式数据应用程序,这对于可能没有广泛网页开发知识的数据科学家和机器学习工程师特别有益。
通过使用Streamlit,开发人员可以构建和分享吸引人的用户界面,并在不需要深入的前端经验或知识的情况下部署模型。该框架是免费的、全Python的、开源的,能够在短时间内创建可分享的网页应用程序。
如果你有一些涉及机器学习的个人项目,那么使用Streamlit为其添加一个界面是一个不错的主意。开始使用它几乎不需要时间,有许多现成的模板可供选择,你可以在短时间内完成前端部分的开发。分享它也极为简单,这意味着在你的简历中,它肯定会显得非常出色。
链接:https://streamlit.io
3. FastAPI---轻便和快速部署你的模型、

一旦你训练并验证了你的模型,你需要部署它,以便其他应用程序可以使用。这就是FastAPI发挥作用的地方。
FastAPI是一个高性能的web框架,用于构建RESTful API。它以其简单性、易用性和速度而闻名。这使它成为将机器学习模型部署到生产环境的理想选择。
以下是为什么机器学习工程师和数据科学家应该学习FastAPI的一些原因:
速度:FastAPI非常快。它使用现代异步编程模型,使其能够高效地同时处理多个请求。这对于需要处理大量数据的机器学习模型部署至关重要。
简单性:FastAPI易于学习和使用。它具有清晰简洁的语法,使得编写干净且可维护的代码变得容易。对于不一定是经验丰富的web开发人员的机器学习工程师和数据科学家来说,这一点很重要。
易用性:FastAPI提供了许多功能,使构建和部署API变得容易。例如,它内置了自动文档、数据验证和错误处理的支持。这节省了时间和精力,允许机器学习工程师专注于他们的核心工作——构建和部署模型。
生产就绪:FastAPI是为生产环境设计的。它具有像支持多后端、安全性和部署工具等特性。这使得它成为部署关键机器学习模型的可靠选择。
总之,FastAPI是一个强大且多功能的工具,可用于将机器学习模型部署到生产环境。其易用性、速度和生产就绪性使其成为希望使他人能够访问其模型的机器学习工程师和数据科学家的理想选择。
链接:https://fastapi.tiangolo.com
4.XGBoost---更快更好地预测表格数据

XGBoost是一种强大的机器学习算法,以其准确性、速度和可扩展性而闻名。它基于梯度提升框架,将多个弱学习器组合成一个强学习器。简单来说,你使用多个小模型(如随机森林),将它们组合成一个大模型,最终你会得到一个更快的模型(与例如神经网络相比),同时它是可扩展的,且不太容易过拟合。
以下是为什么机器学习工程师和数据科学家应该学习XGBoost的一些原因:
准确性:XGBoost是现有最准确的机器学习算法之一。它已经被用于赢得许多机器学习竞赛,并且在不同的任务中一直名列前茅。
速度:XGBoost也非常快。它能够快速高效地在大型数据集上进行训练和预测。这使它成为速度重要应用的好选择,如实时欺诈检测或金融建模。
可扩展性:XGBoost具有很高的可扩展性。它可以处理大型数据集和复杂模型,而不会牺牲准确性。这使它成为数据量或模型复杂度是一个关注点的应用的好选择。
如果你有一个表格数据的任务(如基于房间数量预测房价,或根据最后购买/账户数据计算客户购买产品的可能性),在转向使用Keras或PyTorch的神经网络之前,你应该始终首先尝试XGBoost。
5. ELI5---模型更具有解释性和透明性
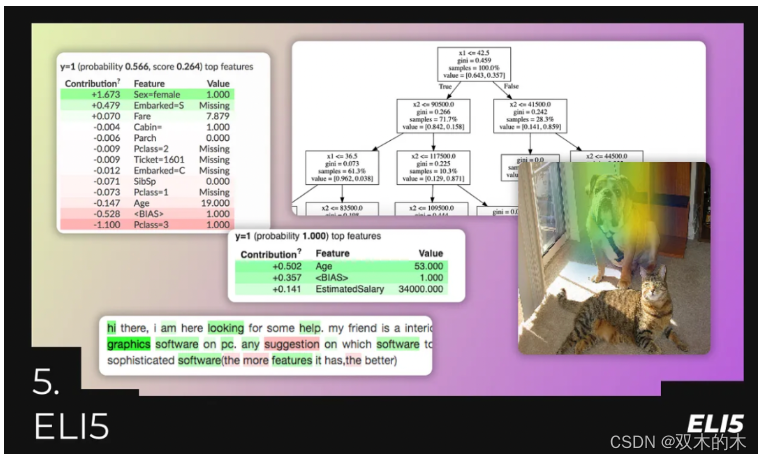
在你训练了你的模型之后,你可以部署它并使用它。但此时,模型更像是一个“黑盒子”——你输入数据,你得到输出结果。它是如何工作的?没人知道。数字从这里进去,从那里出来,最后你得到了一个答案。
那么,如果你的客户/老板问你的模型是如何得出某个特定答案的呢?同样,你不知道。或者你可能想知道在训练过程中哪些参数最重要,以及哪些只是增加了噪声?
所有这些问题都可以通过ELI5来回答。这个库将帮助你使你的模型变得透明、可解释且更易于理解。但你可能会获得更多关于模型的信息,还有数据、训练过程、权重分布和输入参数。除此之外,你可以“调试”你的模型,获得更多关于哪种架构可能更有效,以及当前模型存在什么问题的见解。
ELI5已经支持了像Scikit-Learn、Keras、XGBoost等许多其他库。你可以针对图像、文本和表格数据的分类调试你的模型。
开源库:https://github.com/TeamHG-Memex/eli5
结论
我们已经探讨了五个领先的数据科学框架。如果你至少对每个库都有所了解,你将获得多重优势:
与其他数据科学家相比,你将有更多机会找到工作,因为你在机器学习的不同方面获得了多种技能。你将能够从事全栈项目,因为你不仅可以开发模型,还可以使用FastAPI后端部署它,并让用户在Streamlit前端与之交互。你不会迷失在“Jupyter Notebook地狱”中,因为你的所有机器学习实验都将是可追踪和可复现的,用MLFlow进行管理,所有模型都会被正确版本化。表格数据对你来说不是问题,因为你知道如何使用XGBoost快速训练一个可扩展、快速且准确的模型。而且,大多数模型对你来说不再是“黑盒子”,因为你可以更深入地理解它们,使用ELI5调试它们的思考过程并解释它们的预测。所有这些库都会让生活变得更轻松,为你增添许多有用且重要的技能。编码快乐!!!
参考链接
-
https://mlflow.org
-
https://streamlit.io
-
https://blog.streamlit.io/building-a-streamlit-and-scikit-learn-app-with-chatgpt/
-
https://fastapi.tiangolo.com
-
https://www.geeksforgeeks.org/xgboost/
-
https://xgboost.readthedocs.io/en/stable/
-
https://github.com/TeamHG-Memex/eli5
-
https://eli5.readthedocs.io/en/latest/overview.html#basic-usage
-
https://www.analyticsvidhya.com/blog/2020/11/demystifying-model-interpretation-using-eli5/
THE END!
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
![[SAP ABAP] SE11查询数据库表中的数据](https://img-blog.csdnimg.cn/direct/740f6d8e5f90499ca3b38fcef9a9c41f.png)