希尔排序
- 前言
- 一、希尔排序( 缩小增量排序 )
- 二、希尔排序的特性总结
- 三、希尔排序动画演示
- 四、希尔排序具体代码实现
- test.c
前言
希尔排序是一种基于插入排序的算法,通过比较相距一定间隔的元素来工作,各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。这种算法交换操作结合了直接插入排序和分组交换的思想,交换操作和移动操作相结合,相比于直接插入排序,希尔排序交换操作和移动操作相结合,效率更高。希尔排序是非稳定排序算法。
一、希尔排序( 缩小增量排序 )
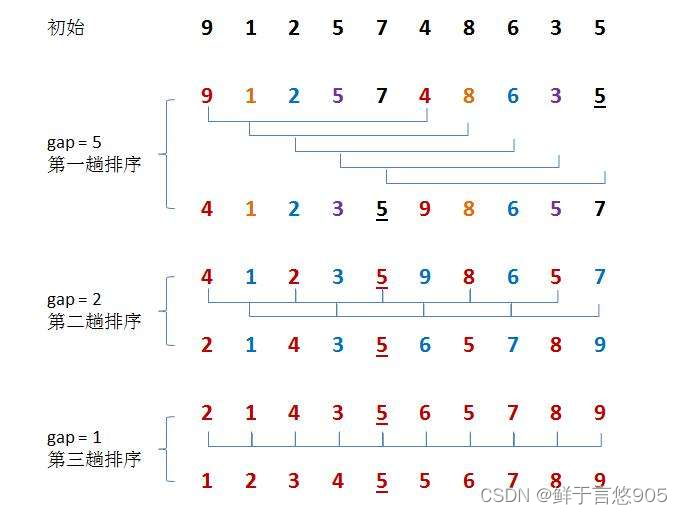
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数,把待排序文件中所有记录分成个组,所有距离为的记录分在同一组内,并对每一组内的记录进行排序。然后,取,重复上述分组和排序的工作。当到达=1时,所有记录在统一组内排好序。
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列(由相隔某个“增量”的记录组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
二、希尔排序的特性总结
- 希尔排序是对直接插入排序的优化。
- 当
gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。 - 希尔排序的时间复杂度不好计算,因为
gap的取值方法很多,导致很难去计算,因此在不同的书中给出的希尔排序的时间复杂度都不固定:
《数据结构(C语言版)》— 严蔚敏

《数据结构-用面相对象方法与C++描述》— 殷人昆

因为我们的gap是按照Knuth提出的方式取值的,而且Knuth进行了大量的试验统计,我们暂时就按照: O(n1.25)到O(1.6*n1.25) 来算
- 稳定性:不稳定
希尔排序的特性总结起来主要有三点:交换性、移动性和跳跃性。这些特性使得希尔排序在处理大量数据时,相较于直接插入排序,效率有了显著的提升。
希尔排序的交换性体现在算法过程中,元素之间的比较和交换是基于它们之间的相对大小,而不是它们的物理位置。这一点与直接插入排序相似,但是希尔排序通过引入一个增量因子,使得交换操作可以在更大的范围内进行,从而减少了不必要的比较和移动。
移动性是指希尔排序在每一次迭代过程中,都会将待排序序列中的一部分元素移动到它们最终的位置。这个过程是通过增量因子的逐渐减小来实现的,每次迭代都会使得更多的元素达到它们正确的位置。这种特性使得希尔排序在处理大规模数据时,相较于直接插入排序,具有更好的时间和空间效率。
希尔排序的跳跃性是其最显著的特性之一。由于增量因子的存在,元素之间的比较和交换可以在不同的子序列之间进行,从而实现了跳跃式的移动。这种跳跃式的移动使得算法在初期就能够对元素进行较大范围的调整,从而快速接近有序状态。随着增量因子的逐渐减小,跳跃性逐渐减弱,算法逐渐过渡到局部调整阶段,直至最终完成排序。
综上所述,希尔排序的特性使得它在处理大量数据时具有较高的效率。通过交换性、移动性和跳跃性的结合,希尔排序在保持算法简单易懂的同时,实现了比直接插入排序更优的性能。这使得希尔排序在实际应用中具有广泛的应用价值,特别是在处理大规模数据集时,能够有效地提高排序效率。
三、希尔排序动画演示
希尔排序
希尔排序是一种基于插入排序的算法,通过比较相距一定间隔的元素来工作,各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。动画演示可以直观地展示希尔排序的每一趟排序过程,包括元素的移动和位置变化,帮助人们更好地理解和掌握希尔排序的原理和实现方法。
四、希尔排序具体代码实现
test.c
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap /= 2;
//gap = gap/3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
void PrintArray(int* a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n");
}
void TestOP()
{
srand((unsigned int)time(0));
const int N = 100000;
int* a = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; i++)
{
a[i] = rand();
}
int begin1 = clock();
ShellSort(a, N);
int end1 = clock();
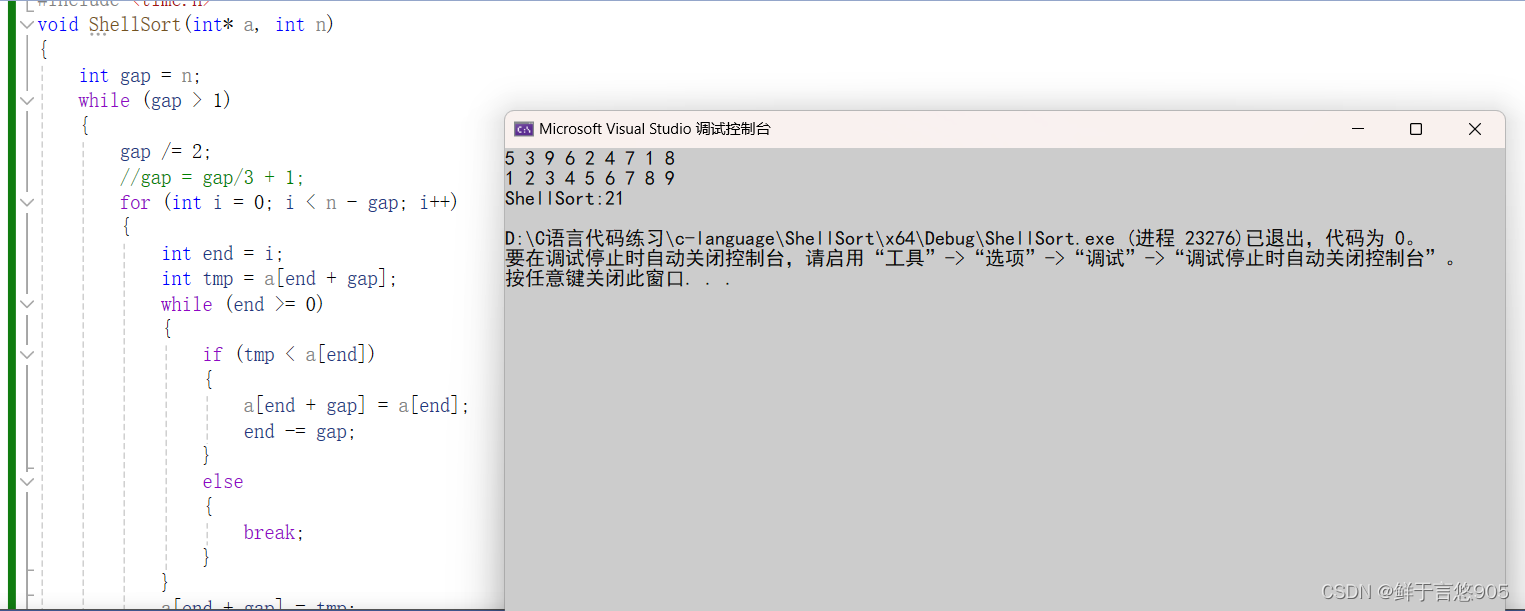
printf("ShellSort:%d\n", end1 - begin1);
free(a);
}
void TestShellSort()
{
int a[] = { 5, 3, 9, 6, 2, 4, 7, 1, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
ShellSort(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
int main()
{
TestShellSort();
TestOP();
return 0;
}
这段代码实现的是希尔排序(Shell Sort)算法,这是一种基于插入排序的算法,通过比较相距一定间隔的元素来工作,各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。
下面是这段代码的详细解释:
- 函数定义:
void ShellSort(int* a, int n)
这个函数接受一个整数数组 a 和一个整数 n 作为参数,其中 n 是数组 a 的长度。
- 初始化间隔:
int gap = n;
这里初始化间隔 gap 为数组的长度 n。希尔排序的关键是选择合适的间隔序列。这个例子中选择了每次除以2的间隔,但也可以尝试其他的间隔序列,比如除以3再加1(被注释掉的那行)。
- 主循环:
while (gap > 1)
只要间隔 gap 大于1,就继续排序。
- 更新间隔:
gap /= 2;
每次循环后,间隔 gap 都除以2,这意味着每次迭代时,比较的元素之间的距离都会减半。
- 插入排序变种:
内部的两个嵌套循环实现了一个插入排序的变种。外部循环遍历数组,而内部循环则负责将当前元素(加上间隔gap)插入到已排序的序列中。
int end = i;:初始化end为当前外部循环的索引i。int tmp = a[end + gap];:保存当前要插入的元素。while (end >= 0):这个循环用于将tmp插入到正确的位置。如果tmp小于a[end],则将a[end]向右移动gap个位置,并继续向前比较。如果tmp大于或等于a[end],则停止循环。a[end + gap] = tmp;:将tmp插入到正确的位置。
- 结束:
当gap减少到1时,内部循环实际上就变成了标准的插入排序,因为每次只比较相邻的元素。
总的来说,希尔排序是插入排序的一个改进版本,通过允许非相邻元素的交换,它可以更快地移动数据。但需要注意的是,选择合适的间隔序列对于希尔排序的性能至关重要。