栈
1.栈的定义
栈:栈是仅限与在表尾进行插入或者删除的线性表
我们把允许一端插入和删除的一端叫做栈顶,另一端叫栈底,不含任何元素的栈叫做空栈,栈又叫做后进先出的线性表,简称LIFO结构
2.栈的理解
对于定义里面的在表尾进行插入和删除,这里的表尾就是栈顶,而不是栈底,(这个理解会在用单链表实现栈的时候会着重说明一下),栈的插入叫做入栈,栈的删除叫做出栈。
这里为了更加形象的去理解栈,你可以把他当作一个装弹夹的过程,因为装弹的时候就是第一颗装进去是在最下面的,最后一颗装进去是在最上面的,所以非常符合后进先出的特点。

再者就是我们进入网页的时候,想回到上一个页面,会点击返回页面,这个操作也是栈的应用,因为返回的是最新点开的,所以可以理解为出栈的操作。
因为栈是线性表所以可以分为顺序存储结构和链式存储结构
3.栈的顺序存储结构及实现
栈的顺序存储也就是用顺序表去实现,所以我们称为顺序栈,这里用顺序表,完美契合了栈的特点,所以非常合适。
顺序栈的实现有以下几步
1.栈的初始化
2.栈的销毁
3.栈的入栈
4.栈的出栈
首先栈的初始化,和顺序表一样,但是我们需要一个坐标去表示栈顶,在栈满的时候去判断是否会溢出,这个坐标我们设置为top,初始化的时候我们有两个选择一种是初始化为-1,一种是初始化为0,两种各有好处,前者是可以用top表示当前元素,后者更加符合更多人的认知,这里我采用的是后者




栈的结构定义
typedef int STDataType;//这里有可能是其他元素所以采用取别名的方式
typedef struct Stack
{
STDataType* a;
int top;//栈顶元素
int capacity;//容量大小
}ST;栈的初始化
void STInit(ST* pst)
{
assert(pst);
pst->a = NULL;
pst->capacity = 0;
pst->top = 0;//这里我们采用第二种方式
}栈的入栈操作
void STPush(ST* pst, STDataType x)
{
assert(pst);
if (pst->top == pst->capacity)//这里无论是满还是空都成立,所以写在一起
//如果top开始是-1那么这里应该top+1
{
int newcapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;//如果是空就给一个初值
//否则直接扩容到2倍
STDataType* tmp = (STDataType*)realloc(pst->a,newcapacity*sizeof(STDataType));//申 请一片空间
if (tmp == NULL)
{
perror("realloc fail");
return;
}
else
{
pst->a = tmp;
pst->capacity = newcapacity;
}
}
pst->a[pst->top] = x;//申请成功,那么直接赋值,top再++
pst->top++;
}栈的出栈操作
void STPop(ST* pst)
{
assert(pst);
assert(!STEmpty(pst));//如果是空就不能出栈了
pst->top--;//直接--就行
}栈的销毁操作
void STDestory(ST* pst)
{
assert(pst);
free(pst->a);
pst->a = NULL;
pst->capacity = 0;
pst->top = 0;
}栈的判空
bool STEmpty(ST* pst)
{
assert(pst);
return pst->top == 0;
}由于栈用顺序结构有点弊端,所以我们可以用两个栈去优化它,也就是两个相同的栈相对,这样可以让顺序栈进一步优化
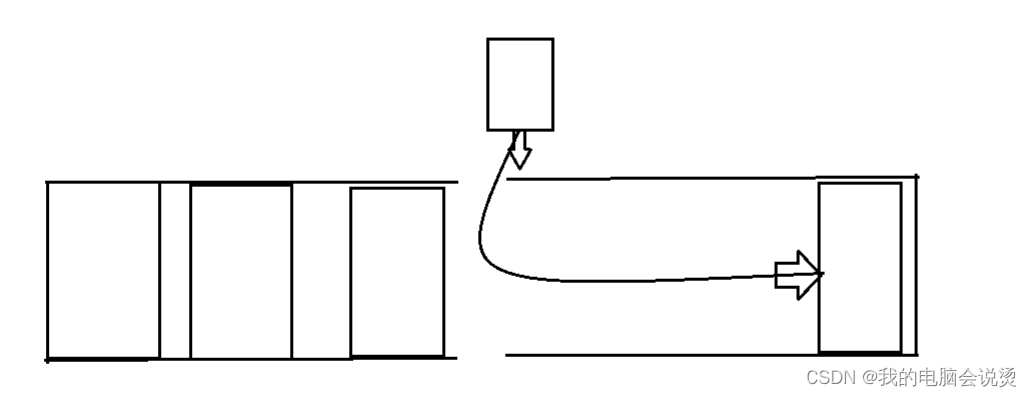
但是如果两个栈都增加那么也是没效果的,这种结构适用于一个整加,一个减少,就比如买股票
有人买就有人卖出
4.栈的链式存储结构及实现
栈的链式存储结构简称为链栈,用链表来实现其实有很多方法,但这里还是推荐用单链表,其他的都有点不对劲,首先我们肯定需要一个栈顶指针, 这里我们有两种选择,一种是把尾结点当作栈顶,每次插入或删除都在尾结点,或者是把头节点做栈顶,每次插入或者删除在头节点,如果用尾结点做栈顶,那么我需要把指针放在尾结点的前一个,所以为了避免混淆,我们使用头插头删的方法去实现
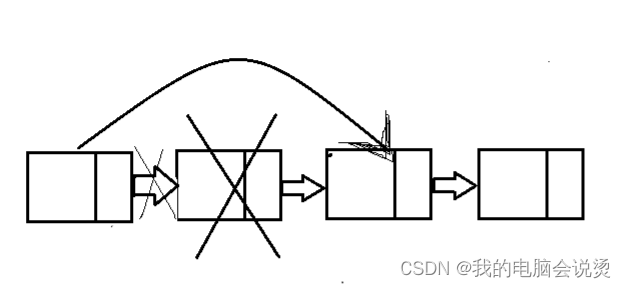

链栈的优势是不存在栈满的情况,如果真的发生了那说明计算机已经面临奔溃了
链栈的结构定义
typedef int STDataType;
typedef struct StackNode
{
struct StackNode* next;
STDataType data;
}ST;
typedef struct Stack
{
ST* top;
int size;
}Stack;//这里多定义一个结构体,用top指针去指向第一个结点链栈的初始化
void StackInit(Stack* st)
{
assert(st);
st->top = NULL;
st->size = 0;
}链栈的销毁
void StackDestory(Stack* st)
{
assert(st);
ST* cur = st->top;
while (cur)
{
ST* next = cur->next;
free(cur);
cur = next;
}
st->top = NULL;
st->size = 0;
}链栈的入栈
void StackPush(Stack* st, STDataType x)
{
assert(st);
ST* newnode = (ST*)malloc(sizeof(ST));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
else {
newnode->data = x;
newnode->next = NULL;
if (st->top == NULL)
{
st->top = newnode;
}
else
{
newnode->next = st->top;
st->top = newnode;
}
}
st->size++;
}链栈的出栈
void StackPop(Stack* st)
{
assert(st);
assert(!StackEmpty(st));
ST* cur = st->top;
st->top = st->top->next;
free(cur);
st->size--;
}链栈的判空
bool StackEmpty(Stack* st)
{
assert(st);
return st->top == NULL;
}链栈的返回栈顶元素
STDataType StackTop(Stack* st)
{
assert(st);
assert(!StackEmpty(st));
return st->top->data;
}队列
1.队列的定义:
队列:队列是只允许在一端进行插入操作,在另一端进行删除操作的线性表
队列是一种先进先出的线性表,运行插入一段的叫队尾,允许出队列的叫队头
没有元素的队列叫空队列
2.队列的理解
对于队列的理解我们可以理解为一条河流或者是排队取餐,他们都是有顺序的,先来的先吃饭,后来的后吃饭,这是不是很想一些餐厅一样,他们那个系统也就是队列的应用。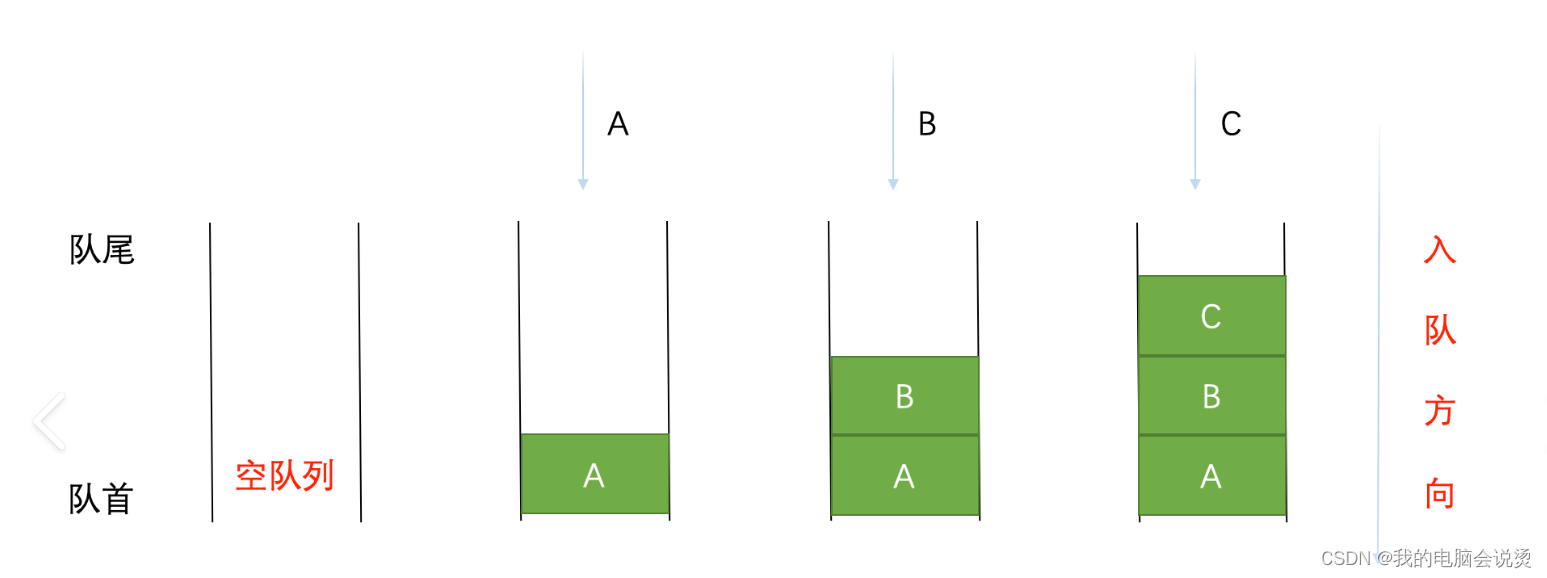
队列存储方式和栈是一样的有两种方式
1.顺序队列:顺序表实现队列
2.链队列:用链表实现队列
这两者的选择上其实用链表更加合适,顺序表不是很适合,因为用顺序表需要挪动数据非常麻烦,所以下面用链表实现,顺序表的实现就不展示了
3.队列的链式存储结构
因为队列是一个先进先出的数据结构,所以我们用链表的时候也就是头删和尾插
队列的结构定义
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType data;
}QNode;
typedef struct Queue
{
QNode* phead;//一个指向头
QNode* ptail;//一个指向尾
int size;
}Queue;//这里和栈的链表实现有些类似,都有两个结构体,
//一个结构体表示结点,一个结构体表示位置指针队列初始化
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}队列的销毁
void QueueDestory(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}队列的入列
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
else
{
newnode->data = x;
newnode->next = NULL;
if (pq->phead == NULL)
{
pq->phead = pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;
pq->ptail = newnode;
}
}
pq->size++;
}队列的出列
void QueuePop(Queue* pq)
{
//头删
assert(pq);
assert(!QueueEmpty(pq));
//一个结点
//多个结点
if (pq->phead->next == NULL)
{
free(pq->phead);
pq->phead = pq->ptail = NULL;
}
else
{
QNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
}队列的获取第一个元素
QDataType QueueTop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->phead->data;
}队列的判空
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->phead == NULL && pq->ptail==NULL;//两个指针都有
//或者写成pq->size==0
}队列的获取尾元素
这个很多人感觉没用,但他在做一些题目的时候会有很大作用
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->ptail->data;
}说完链队列,我们来看看顺序队列,上面其实说了顺序队列的不好,但是如果我们把它改成循环队列那就会很好,如果是普通队列那么它出队的时间复杂度为O(N),循环队列为O(1),而且,普通队列会浪费很多空间,具体看下面的动图
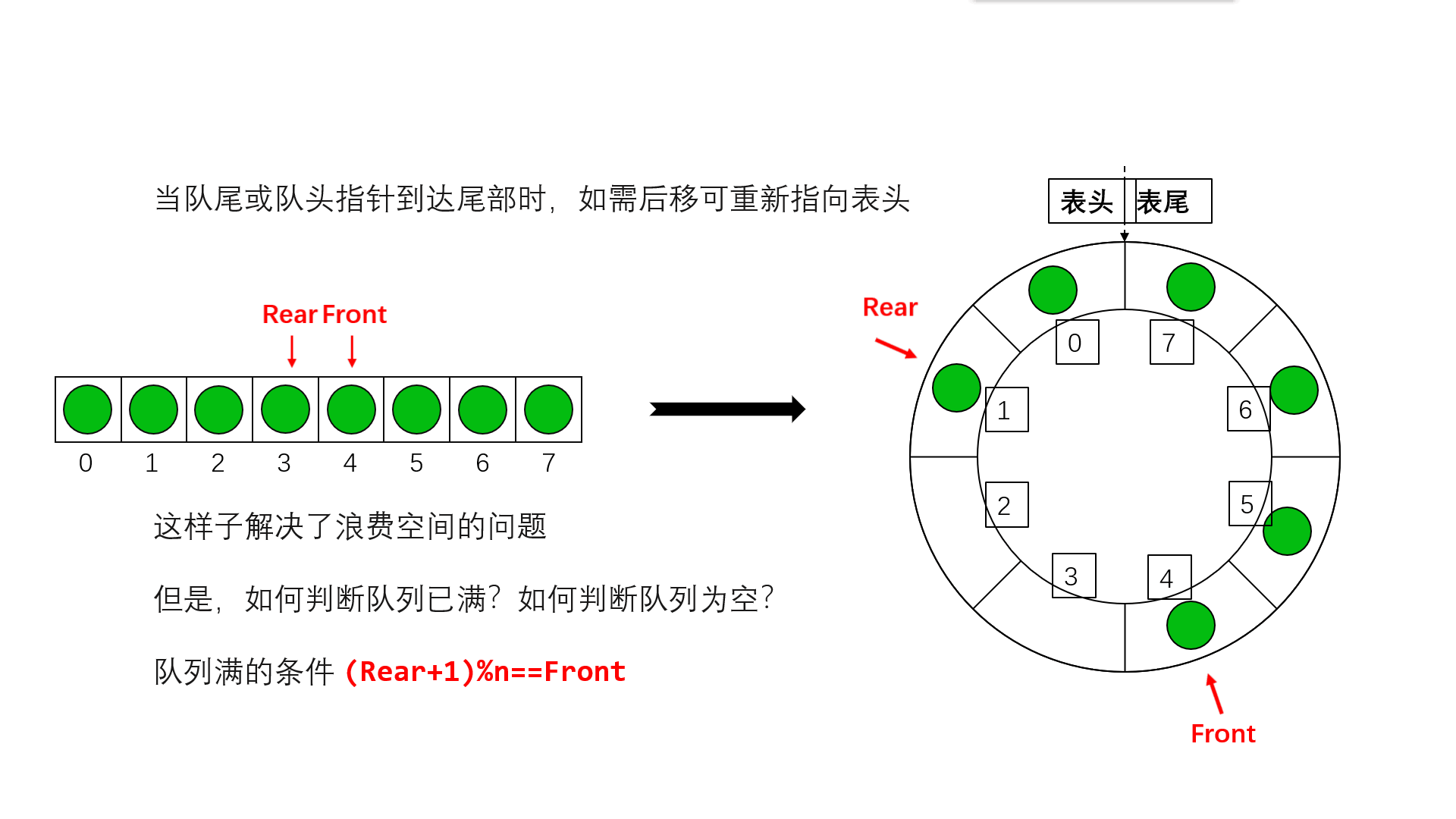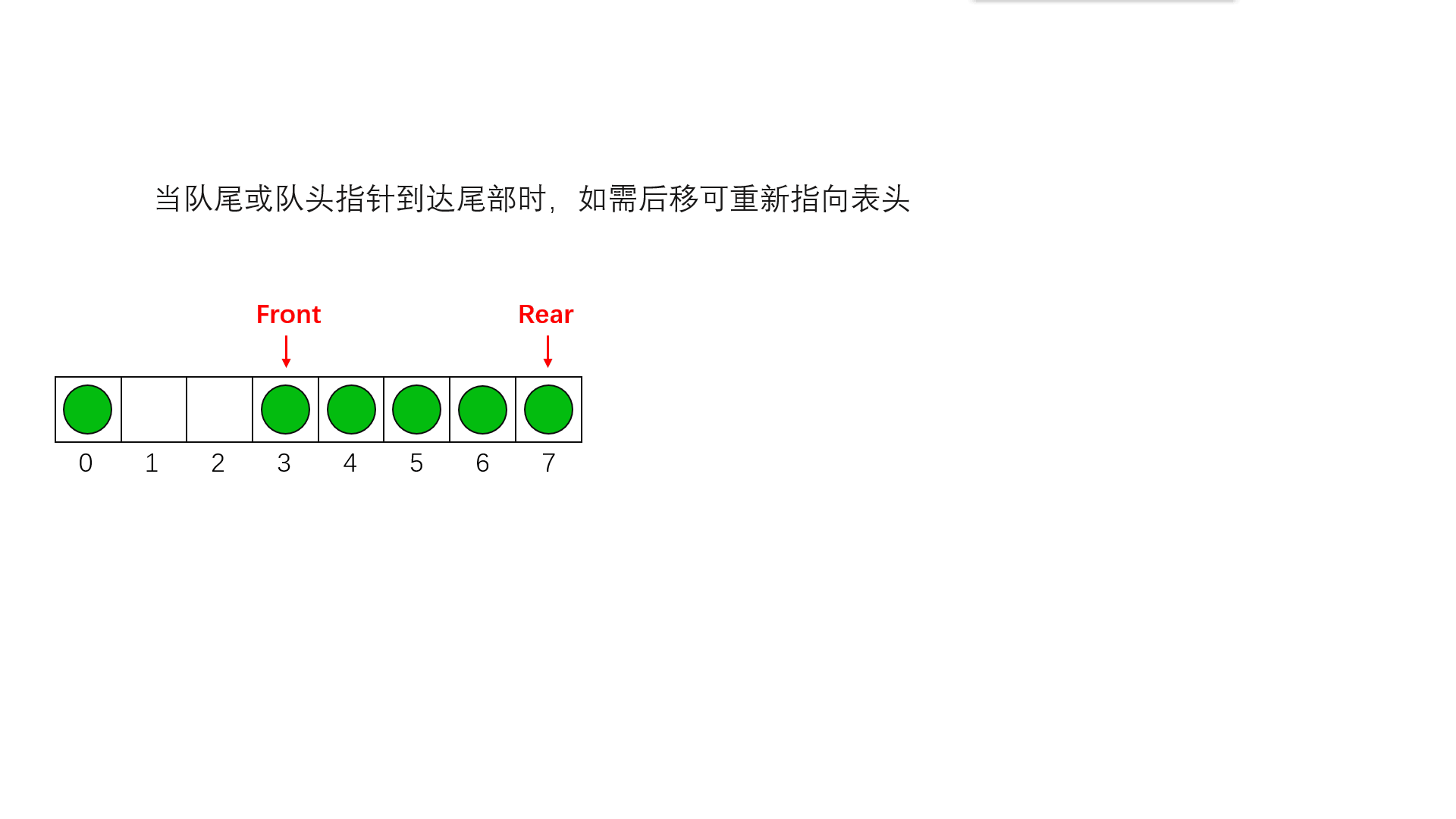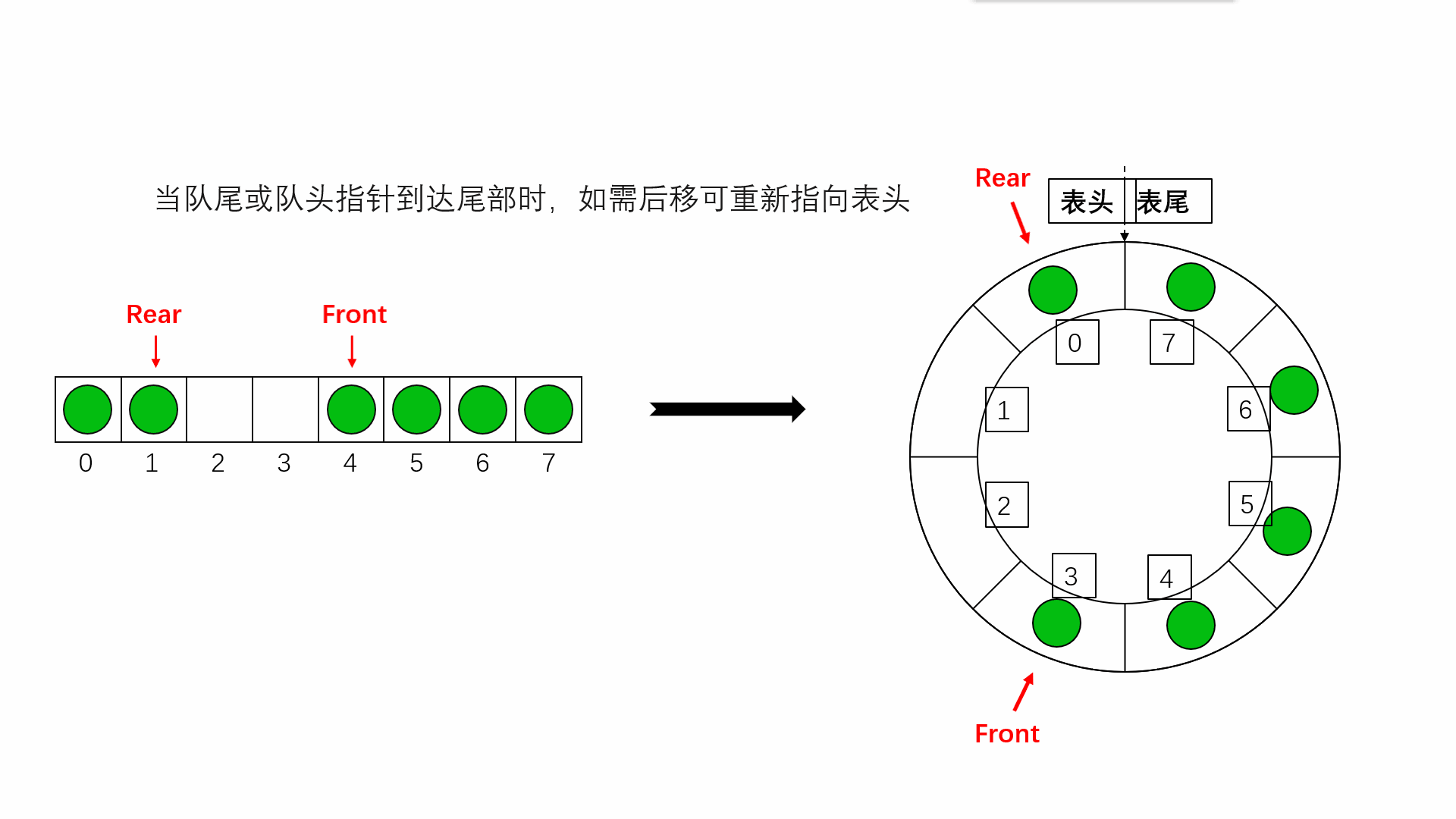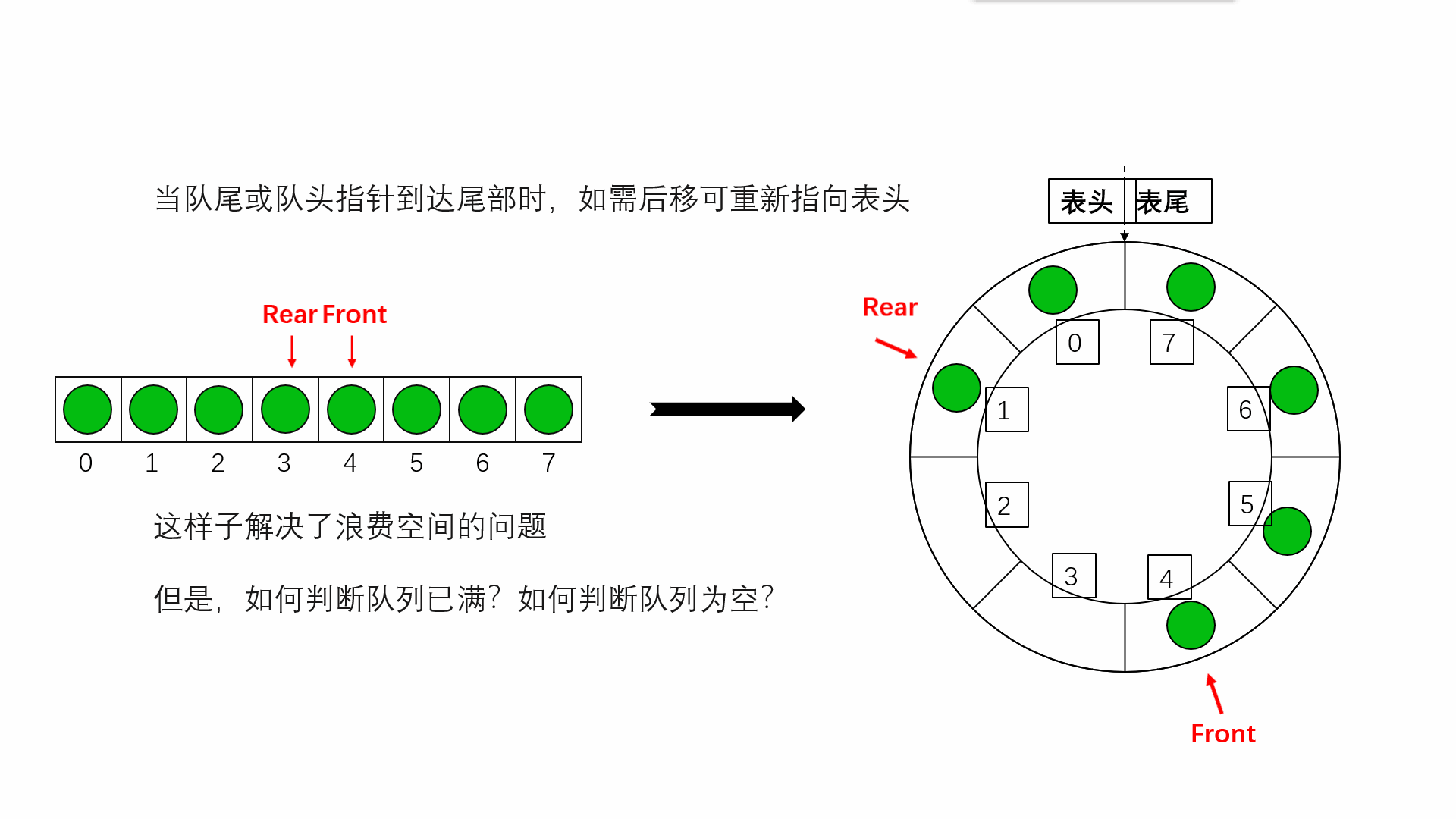
队空的条件就是front==rear,那满就不能用这个了 ,所以我们可以多开一个空间,rear指向最后一个元素的下一个位置,这个位置没有元素是空的,当rear再走一步也就和front相等了,用这个来判断是否是满的,由于是循环的所以我们用(rear+1)%MAXSIZE==front来判断
所以我们这样做就可以把顺序队列给优化
循环队列的结构定义
typedef int QDataType;
#define MAXSIZE 50
typedef struct QueueSL
{
QDataType a[MAXSIZE];//数组表示
int front;//一个头
int rear;//一个尾
}QL;循环队列的初始化
void QLInit(QL* pq)
{
assert(pq);
pq->front = 0;
pq->rear = 0;
}循环队列的销毁
void QLDestory(QL* pq)
{
assert(pq);
free(pq->a);
pq->front = 0;
pq->rear = 0;
}循环队列的入队列
void QLPush(QL* pq, QDataType x)
{
assert(pq);
if ((pq->rear + 1) % MAXSIZE == pq->front)
{
return;
}
else
{
pq->a[pq->rear] = x;
pq->rear = (pq->rear + 1) % MAXSIZE;//这里可以看看上面的动态图,然后自己画图
//不能直接写rear++,但跑到最后一个元素的时候还要回来
}
}
循环队列的出列
void QLPop(QL* pq)
{
assert(pq);
assert(!QLEmpty(pq));//这里判断是否为空,空了就不能删了
pq->front = (pq->front + 1) % MAXSIZE;//和上面一样
}循环队列判空
bool QLEmpty(QL* pq)
{
assert(pq);
return (pq->rear == pq->front);
}
以上就是栈和队列的基本操作和基础知识,其实还有很多知识点,这些放在后面的文章说(需要用到c++)
有了以上的基础,下面我们写几个题目去巩固一下
oj题
用栈实现队列
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(
push、pop、peek、empty):实现
MyQueue类:
void push(int x)将元素 x 推到队列的末尾int pop()从队列的开头移除并返回元素int peek()返回队列开头的元素boolean empty()如果队列为空,返回true;否则,返回false说明:
- 你 只能 使用标准的栈操作 —— 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。- 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
示例 1:
输入: ["MyQueue", "push", "push", "peek", "pop", "empty"] [[], [1], [2], [], [], []] 输出: [null, null, null, 1, 1, false] 解释: MyQueue myQueue = new MyQueue(); myQueue.push(1); // queue is: [1] myQueue.push(2); // queue is: [1, 2] (leftmost is front of the queue) myQueue.peek(); // return 1 myQueue.pop(); // return 1, queue is [2] myQueue.empty(); // return false提示:
1 <= x <= 9- 最多调用
100次push、pop、peek和empty- 假设所有操作都是有效的 (例如,一个空的队列不会调用
pop或者peek操作)进阶:
- 你能否实现每个操作均摊时间复杂度为
O(1)的队列?换句话说,执行n个操作的总时间复杂度为O(n),即使其中一个操作可能花费较长时间。
这道题思路就是一个栈出数据,一个栈进数据,就可以实现队列,因为队列是先进先出,栈是后进先出,所以把栈倒过来,就变成了先进先出
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void STInit(ST* pst);
void STDestroy(ST* pst);
void STPush(ST* pst, STDataType x);
void STPop(ST* pst);
STDataType STTop(ST* pst);
bool STEmpty(ST* pst);
int STSize(ST* pst);
void STInit(ST* pst)
{
assert(pst);
pst->a = NULL;
//pst->top = -1; // top 指向栈顶数据
pst->top = 0; // top 指向栈顶数据的下一个位置
pst->capacity = 0;
}
void STDestroy(ST* pst)
{
assert(pst);
free(pst->a);
pst->a = NULL;
pst->top = pst->capacity = 0;
}
void STPush(ST* pst, STDataType x)
{
if (pst->top == pst->capacity)
{
int newCapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;
STDataType* tmp = (STDataType*)realloc(pst->a, newCapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
pst->a = tmp;
pst->capacity = newCapacity;
}
pst->a[pst->top] = x;
pst->top++;
}
void STPop(ST* pst)
{
assert(pst);
assert(!STEmpty(pst));
pst->top--;
}
STDataType STTop(ST* pst)
{
assert(pst);
assert(!STEmpty(pst));
return pst->a[pst->top - 1];
}
bool STEmpty(ST* pst)
{
assert(pst);
/*if (pst->top == 0)
{
return true;
}
else
{
return false;
}*/
return pst->top == 0;
}
int STSize(ST* pst)
{
assert(pst);
return pst->top;
}
//以上是栈的实现,可以自己写一个,因为我们用的c所以不是太方便
typedef struct {
ST pushst;
ST popst;//用结构体去存两个栈
} MyQueue;
MyQueue* myQueueCreate() {//开辟一片空间去存,也就是创造
MyQueue*obj=(MyQueue*)malloc(sizeof(MyQueue));
if(obj==NULL)
{
perror("malloc fail");
return NULL;
}
STInit(&obj->pushst);//记得初始化
STInit(&obj->popst);
return obj;
}
void myQueuePush(MyQueue* obj, int x) {
STPush(&obj->pushst,x);//把数据全部丢进进数据的那个栈
}
int myQueuePeek(MyQueue* obj) {
if(STEmpty(&obj->popst))//判断是不是空,如果不是空,直接返回第一个元素就行
//如果不是就需要把元素全部导进来
{
while(!STEmpty(&obj->pushst))
{
STPush(&obj->popst,STTop(&obj->pushst));
STPop(&obj->pushst);//导一个元素就删一个
}
}
return STTop(&obj->popst);
}
int myQueuePop(MyQueue* obj) {//和上面的思路很想,所以直接套过来就行,多了一个删除
int front=myQueuePeek(obj);
STPop(&obj->popst);
return front;
}
bool myQueueEmpty(MyQueue* obj) {
return STEmpty(&obj->pushst)&&
STEmpty(&obj->popst);
}
void myQueueFree(MyQueue* obj) {
STDestroy(&obj->pushst);
STDestroy(&obj->popst);
free(obj);
}用队列实现栈
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(
push、top、pop和empty)。实现
MyStack类:
void push(int x)将元素 x 压入栈顶。int pop()移除并返回栈顶元素。int top()返回栈顶元素。boolean empty()如果栈是空的,返回true;否则,返回false。注意:
- 你只能使用队列的标准操作 —— 也就是
push to back、peek/pop from front、size和is empty这些操作。- 你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
示例:
输入: ["MyStack", "push", "push", "top", "pop", "empty"] [[], [1], [2], [], [], []] 输出: [null, null, null, 2, 2, false] 解释: MyStack myStack = new MyStack(); myStack.push(1); myStack.push(2); myStack.top(); // 返回 2 myStack.pop(); // 返回 2 myStack.empty(); // 返回 False提示:
1 <= x <= 9- 最多调用
100次push、pop、top和empty- 每次调用
pop和top都保证栈不为空进阶:你能否仅用一个队列来实现栈。
这道题的思路和上一个题有点像,但是不能完全套用,因为我们队列是先进先出,我们要实现后进先出,我们得把有数据的队列里面的前n-1个数据放到没有数据的地方,然后把最后那个元素弹出,也就是实现了后进先出,后面的没个元素操作都是这样。
typedef int QDataType;
typedef struct QueueNode
{
QDataType data;
struct QueueNode* next;
}QNode;
typedef struct Queue
{
QNode* phead;
QNode* ptail;
int size;
}Queue;
void QueueInit(Queue* pq);
void QueueDestory(Queue* pq);
void QueuePush(Queue* pq, QDataType x);
void QueuePop(Queue* pq);
QDataType QueueFront(Queue* pq);
QDataType QueueBack(Queue* pq);
bool QueueEmpty(Queue* pq);
int QueueSize(Queue* pq);
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}
void QueueDestory(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
newnode->data = x;
newnode->next = NULL;
if (pq->ptail == NULL)
{
assert(pq->phead == NULL);
pq->phead = newnode;
pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;
pq->ptail = newnode;
}
pq->size++;
}
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
if (pq->phead->next == NULL)
{
free(pq->phead);
pq->ptail=pq->phead = NULL;
}
else
{
QNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
pq->size--;
}
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
return pq->phead->data;
}
QDataType QueueBack(Queue* pq)
{
assert(pq);
return pq->ptail->data;
}
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->phead == NULL && pq->ptail == NULL;
}
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}//队列的实现
typedef struct {
Queue q1;
Queue q2;
} MyStack;//和上个题一样的思路
MyStack* myStackCreate() {
MyStack *obj=(MyStack*)malloc(sizeof(MyStack));
QueueInit(&obj->q1);
QueueInit(&obj->q2);
return obj;
}
void myStackPush(MyStack* obj, int x) {
if(!QueueEmpty(&obj->q1))//往没有数据的地方放数据
{
QueuePush(&obj->q1,x);
}
else
{
QueuePush(&obj->q2,x);
}
}
//导数据
int myStackPop(MyStack* obj) {
Queue*pEmptyQ=&obj->q1;//因为我们不知道哪个是空,所以要把它找出来
Queue*pNoEmptyQ=&obj->q2;
if(!QueueEmpty(&obj->q1))
{
pEmptyQ=&obj->q2;
pNoEmptyQ=&obj->q1;
}
while(QueueSize(pNoEmptyQ)>1)//找到以后就开始导数据,把最后一个留下
{
QueuePush(pEmptyQ,QueueFront(pNoEmptyQ));
QueuePop(pNoEmptyQ);
}
int top=QueueFront(pNoEmptyQ);然后返回最后一个元素,这也是要导出的元素
QueuePop(pNoEmptyQ);
return top;
}
int myStackTop(MyStack* obj) {
Queue*pEmptyQ=&obj->q1;
Queue*pNoEmptyQ=&obj->q2;
if(!QueueEmpty(&obj->q1))//找哪个不是空
{
pEmptyQ=&obj->q2;
pNoEmptyQ=&obj->q1;
}
return QueueBack(pNoEmptyQ);//这里队列的尾指针起到了作用,是不是很妙,也就不用遍历了
}
bool myStackEmpty(MyStack* obj) {
return QueueEmpty(&obj->q1)&&QueueEmpty(&obj->q2);
}
void myStackFree(MyStack* obj) {
free(obj);
}总结
希望本文章对你有帮助,大概就是栈和队列的实现以及为什么要这样实现都在里面了,可能还有很多知识点,因为牵扯到c++所以准备往后更,里面的oj题可能很好的打磨,希望你能认真看完,👍👍