文章目录
- 一、安装
- pycharm
- 二、输入输出
- 输出 print()
- 文件输出:
- 格式化输出:
- 输入input
- 注释
- 三、编码规范
- 四、变量
- 保留字
- 变量
- 五、数据类型
- 数字类型
- 整数
- 浮点数
- 复数
- 字符串类型
- 布尔类型
- 序列结构
- 序列属性
- 列表list ,有序
- 多维列表
- 列表推导式
- 元组tuple
- 元素推导式
- 字典 ,无序
- 通过映射函数创建字典
- 通过关键字参数创建字典
- 访问字典
- 字典推导式
- 解包操作符
- 集合,无序可变,去重
- 创建集合
- 添加和删除
- 交集 并集 差集
- 字符串
- 检索字符串
- 格式化字符串
- 六、运算符
- 算术运算符
- 用于字符串
- 赋值运算符
- 比较运算符
- 逻辑运算符
- 位运算符
- 七、条件if else
- 八、循环
- for
- while
- conitue break
- 九、RegEx正则表达(Regular Expression)
- 十、函数
- def函数
- 形参 实参
- 可变参数
- 匿名函数/ lambda 函数
- 十一、全局变量 局部变量
- 十二、模块
- 导入模块
- 标准模块
- 外部模块安装
- __main\_\_
- 模块导入
- __name__的理解
- 包
- 第三方包
- 十、文件与IO
- 文件操作
- 打开文件
- 写入文件
- 关闭文件
- 读取文件
- 文件指针
- os.rename(src, dst):重命名文件或目录。
- os.remove(file):删除文件。
- os.rmdir(directory):删除空目录。
- os.removedirs(directory):递归删除目录及其所有子目录中的所有空目录。
- shutil模块中,存在一个rmtree()函数用于递归删除目录以及目录中的所有文件和子目录。
- os.chmod(path, mode):更改文件或目录的权限模式。
- 目录操作
- 路径
- 目录
- 使用os.path.exists() 来检查目录是否存在。
- 使用 os.mkdir() 来创建单个目录。
- 使用 os.makedirs() 来创建多级目录。如果上级目录不存在,会一并创建所需的上级目录。
- 使用 os.rmdir() 来删除目录。
- 使用 os.walk() 来遍历目录中的子目录和文件。
- 十一、类 对象
- 类
- __init\_\_()
- 访问限制
- 十二、 装饰器
- 将类方法转换为属性的装饰器
- 函数装饰器
- 类装饰器
- 十三、继承
- super()
- 十二、input
- 十五、错误处理 try except finally
- raise抛出异常
- assert
- 十六、zip lambda map
- 十七、深拷贝deepcopy 浅拷贝copy
- 十九、多核运算
- 二十、tkinter
- 二十一、python gui界面
- 二十二、pickle存放数据
- 二十六、datetime time
- datetime.datetime.strptime()
- datetime.datetime.strftime()
一、安装
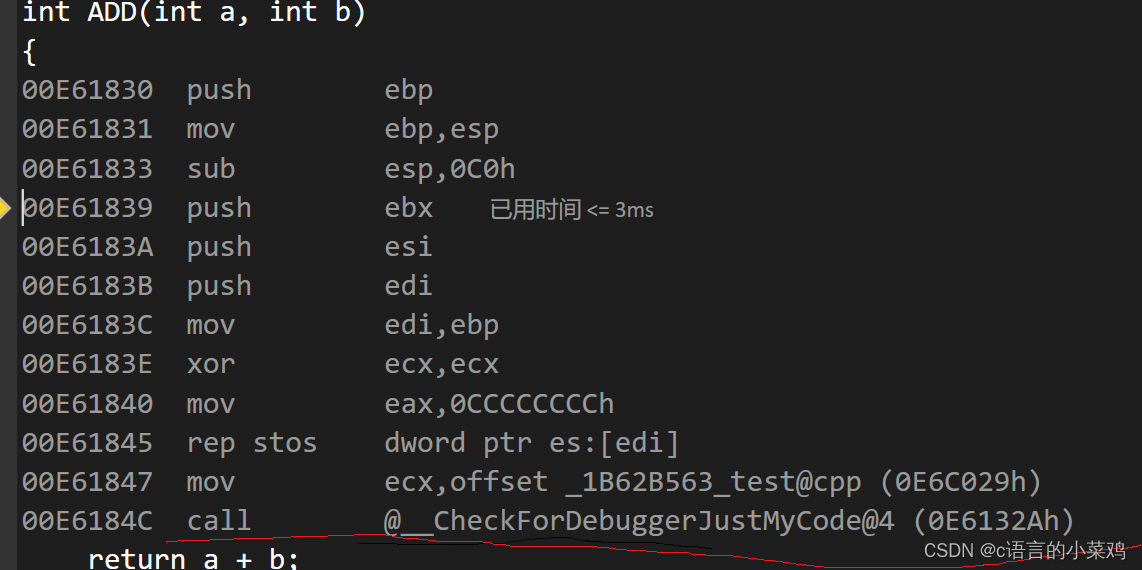
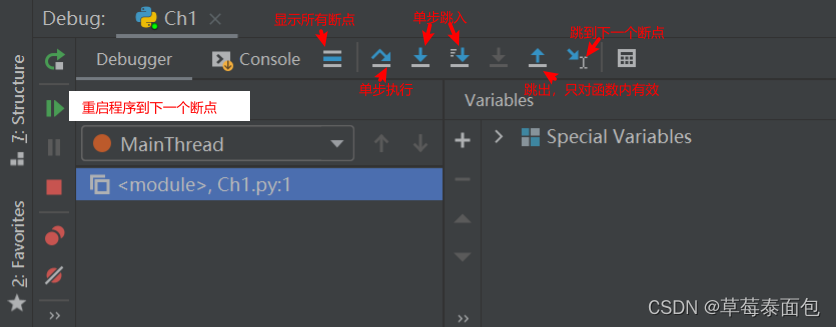
pycharm
debug工具栏
二、输入输出
输出 print()
2.7版本之前不用括号()
2.7之后需要括号
print(1)
print('hello world')
print("hello world")
print('apple'+'car')
#打印'需要加\
print("I\'m m")
#int转换str
print('apple'+str(4))
print(1+3)
#转换小数用float
print(float('1.2')+2)
print('a=',1)
默认情况下,每次调用print()函数都会在输出内容后添加换行符,如果不希望换行,可以使用end参数。
print("Hello,", end=" ")
print("World!")
ASCII码转换为字符使用ch()
字符转换为ASCII码的数字使用ord()
print(chr(97))
文件输出:
可以将输出内容写入到文件中,通过file参数指定文件对象。
with open("output.txt", "w") as f:
print("Hello, File!", file=f)
格式化输出:
使用 % 格式化字符串:
name = "Alice"
age = 30
print("Name: %s, Age: %d" % (name, age))
使用 format 方法:
name = "Bob"
age = 25
print("Name: {}, Age: {}".format(name, age))
使用 f-string(Python 3.6+):
name = "Charlie"
age = 20
print(f"Name: {name}, Age: {age}")
指定宽度和对齐方式:
name = "David"
age = 35
print("{:<10} {:>5}".format(name, age))
格式化数字:
num = 3.14159
print("{:.2f}".format(num)) # 保留两位小数
日期格式化输出:
import datetime
now = datetime.datetime.now()
print(now.strftime("Today is %Y-%m-%d %H:%M:%S"))
格式化字典:用了解包操作符**,将字典 person 中的键值对作为参数传递给format()方法,然后在字符串模板中通过键名来引用对应的值,
person = {"name": "Eve", "age": 28}
print("Name: {name}, Age: {age}".format(**person))
多个值格式化:
name = "Frank"
age = 22
height = 175.5
print("{0}'s age is {1}, and his height is {2:.1f}".format(name, age, height))
输入input
python 3.x中,无论输入的是数字还是字符都是作为字符串读取
注释
单行注释:
# 1
多行注释:
'''
...
'''
"""
sdcc
"""
中文编码声明注释:
# coding:utf-8
# coding=utf-8
三、编码规范
- import一次导入一个模块
- 不写分号
- 每行不超过80字符
- 避免在循环中使用+或者+=连接字符串,推荐将每个子字符串加入列表,在循环结束后用join()连接列表
list = []
for i in range(10):
list.append(str(i % 16))
result = ''.join(list)
print(type(result),type(list))
- 命名规范:
– 模块名使用小写字母,使用下划线分割字母。
– 类名采用首字母大写的形式
– 模块内部的类采用下划线+首字母大写的形式
– 函数、类的属性和方法命名使用小写字母,使用下划线分割字母
– 常量命名采用全部大写字母
– 使用下划线_开头的模块名和函数名是受保护的,import时不能导入
– 使用双下划线__开头的实例变量(实例变量是指属于类的实例的变量)或方法是类私有的
– 以双下划线__开头和结尾的是Python里专用的标识
– 区分大小写
四、变量
保留字
保留字区分大小写。if是保留字,IF不是
#查看python的保留字
import keyword
print(keyword.kwlist)
变量
type()获取变量的类型
id()获取变量的内存地址
五、数据类型
数字类型
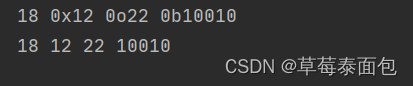
整数
正整数、负整数、0
| 类型 | 开头 |
|---|---|
| 八进制 | 0o或0O开头 |
| 十六进制 | 0x或0X开头 |
| 二进制 | 只有0、1,无开头 |
a = 18
print(a, hex(a), oct(a),bin(a))
print(a, hex(a)[2:], oct(a)[2:],bin(a)[2:])
浮点数
复数
使用j或J表示虚部
3+4j
字符串类型
字符型前加上r,将原样输出字符串
print(r"30x4好好好")
30x4好好好
布尔类型
序列结构
元组、字典、列表对比
1、
元组和列表的区别:
1、元组是不可变序列,不能单独修改元素
2、元组比列表处理和访问的速度快
3、列表不能作为字典的键,元组可以
4、列表元组有序,字典集合无序
2、
元组用(),或者不加()
列表用[ ]
字典{key:value}
集合{}
3、推导式
r1 = [random.randint(10, 100) for i in range(10)]
print("列表推导式:", r1)
r2 = (random.randint(10, 100) for i in range(10))
print("元组推导式:", r2)
r2 = tuple(r2)
print("元组推导式:", r2)
r3 = {i: random.randint(10, 100) for i in range(10)}
print("字典推导式:", r3)
输出:
列表推导式: [32, 72, 80, 10, 66, 25, 52, 23, 11, 12]
元组推导式: <generator object <genexpr> at 0x039B6030>
元组推导式: (21, 45, 86, 65, 63, 43, 34, 74, 44, 83)
字典推导式: {0: 50, 1: 38, 2: 29, 3: 75, 4: 12, 5: 87, 6: 65, 7: 59, 8: 64, 9: 42}
序列属性
索引可以是负数,从右向左计数
倒数第一个元素是-1,倒数第2个元素是-2,以此类推
切片
a[start: end :step] 默认step是1
a[:]复制整个序列
序列连接,用+
a+b
乘法,重复序列
empty =[None] * 5
用in检查某个元素是否在序列中
not in检查不在序列中
len()
max()
min()
list():序列转换为列表
enumerate():序列组合为一个索引序列。它用于将一个可迭代对象(如列表、元组、字符串等)转换为一个枚举对象,同时返回索引和对应的值。还可以接收一个可选的 start 参数,用于指定索引的起始值,默认为 0。
my_list = ['apple', 'banana', 'orange']
for index, value in enumerate(my_list, start=1):
print(f'Index: {index}, Value: {value}')
列表list ,有序
| 函数 | 作用 |
|---|---|
| list() | 将range()循环的结果转换为列表 |
| del | del list删除列表 del a[2]删除元素 |
| append() | 添加 a.append(1) |
| insert() | 向指定位置插入元素 |
| extend() | a.extend(b)将序列b追加到a序列后面 |
| count() | 元素出现的次数 |
| index() | 元素首次出现的下标 |
| sum() | 元素的和,sum(list, start=0) start:可选参数,表示计算总和的初始值,默认为0。 |
| sort() | 原列表改变 sort(key=,reverse= ) key 参数允许你指定一个用于排序的自定义函数,例如可以按照元素的某个属性来排序。 reverse 参数用于指定是否按降序进行排序。默认是升序。True降序,false升序 |
| sorted() | 原列表元素顺序不变 |
a = [1,2,3,4]
#追加
a.append(0)
print(a)
#添加 inset(坐标,数值)
a.insert(1,0)#a[1]=0
a.remove(2)#移除第一个出现的2
print(a[-1])#列表最后一位的坐标用-1
print(a[-2],a[-3])#列表倒数第二个值,倒数第三个值
print(a[0:3])#:表示从哪到哪
print(a[:3])
print(a[1:])
print(a.index(2))#列表中第一次出现的2的索引值
print(a.count(2))#列表中出现2的次数
#默认从小到大排序,并覆盖掉原来的数据
print(a.sort())
#排序顺序为从大到小
a.sort(revers=True)
print(a)
# 定义一个包含学生信息的列表
students = [
{'name': 'Alice', 'age': 25},
{'name': 'Bob', 'age': 22},
{'name': 'Eve', 'age': 28}
]
# 按照年龄从大到小进行排序
students.sort(key=lambda x: x['age'], reverse=True)
print(students) # 输出结果为 [{'name': 'Eve', 'age': 28}, {'name': 'Alice', 'age': 25}, {'name': 'Bob', 'age': 22}]
多维列表
用模块numpy pandas
a_multi = [[1.2.3],
[2,3,4],
[3,4,5]]
print(a[0][1])
列表推导式
用于根据现有可迭代对象创建新的列表。
original_list = [1, 2, 3, 4, 5]
squared_list = [x**2 for x in original_list]
print(squared_list) # 输出结果为 [1, 4, 9, 16, 25]
original_list = [1, 2, 3, 4, 5]
filtered_list = [x**2 for x in original_list if x % 2 == 0]
print(filtered_list) # 输出结果为 [4, 16]
元组tuple
元组用(),或者不加()
列表用[ ]
a_tuple = (1,2,3,4)
b_tuple = 1,2,3,4
c = (1,) 单独的元素要加,
a_list = [1,2,3,4]
for content in a_list:
print(content)
for i range(len(a_list)):
print(i, a_list[1])
元组的连接必须是元组,使用+
元素推导式
可以使用生成器表达式来模拟类似于元组推导式的行为,使用 tuple() 函数将生成器对象转换为元组
# 使用生成器表达式来生成包含平方数的元组
squared_tuple = tuple(x**2 for x in range(1, 5)) # 生成器对象
print(squared_tuple) # 输出结果为 (1, 4, 9, 16)
在 Python 中生成器是一种迭代器,它只能被遍历一次。
# 使用生成器表达式创建生成器对象
generator = (x**2 for x in range(1, 5))
# 打印生成器对象的内容
for item in generator:
print(item)
print(tuple(generator)) # 输出是() 为空
# 将生成器对象转换为列表
result_list = list((x**2 for x in range(1, 5)))
# 将列表转换为元组
result_tuple = tuple(result_list)
print(result_tuple) # 输出结果为 (1, 4, 9, 16)
字典 ,无序
- 由key value组成
- 键必须唯一
- 键必须不可变,只能是数字、字符串、元组
# 空字典
dic = {}
dic = dict()
d = {'apple':1,'pear':2,'orange':3,1:'a','b':'c'}
print(d['apple'])
del d['pear']#删除元素
print(d)
d[2]=20 #添加元素
print(d)
d = {'apple':1,'pear':{1:3,3:'a'}}#字典中包含字典
print(d['pear'][3])
# 删除字典
del dict
# 清空字典
dict.clear()
通过映射函数创建字典
zip()将列表或元组合成字典
keys = ['a', 'b', 'c']
values = [1, 2, 3]
# 使用 zip() 函数将两个列表合并为一个字典
result_dict = dict(zip(keys, values))
print(result_dict)
{'a': 1, 'b': 2, 'c': 3}
通过关键字参数创建字典
# 使用 fromkeys() 创建字典
keys = ['a', 'b', 'c']
my_dict = dict.fromkeys(keys)
print(my_dict)
{'a': None, 'b': None, 'c': None}
# 使用 fromkeys() 创建字典
keys = ['a', 'b', 'c']
default_value = 0 # 默认值
my_dict = dict.fromkeys(keys, default_value)
print(my_dict)
{'a': 0, 'b': 0, 'c': 0}
keys = ('a', 'b', 'c')
value = ['a', 'b', 'c']
dict = {keys:value}
print(dict)
{('a', 'b', 'c'): ['a', 'b', 'c']}
访问字典
dic.get(key,[default])
如果key不在字典,则返回default
dic.items()获取键值对列表
keys = ('a', 'b', 'c')
value = ['a', 'b', 'c']
dic = dict(zip(keys,value))
print(dic)
print(dic.items())
print(dic.keys())
print(dic.values())
for items in dic.items():
print(items)
for key in dic.keys():
print(key)
输出:
{'a': 'a', 'b': 'b', 'c': 'c'}
dict_items([('a', 'a'), ('b', 'b'), ('c', 'c')])
dict_keys(['a', 'b', 'c'])
dict_values(['a', 'b', 'c'])
('a', 'a')
('b', 'b')
('c', 'c')
a
b
c
字典推导式
解包操作符
解包操作符**通常用于将字典中的键值对解包为关键字参数传递给函数或方法。
解包字典传递参数:
def greet(name, age):
print("Hello, {}! You are {} years old.".format(name, age))
person = {"name": "Alice", "age": 30}
greet(**person)
输出结果为:
Hello, Alice! You are 30 years old.
与其他参数结合使用:
def greet(prefix, name, suffix):
print("{} {} {}".format(prefix, name, suffix))
person = {"name": "Bob"}
greet("Hello,", **person, suffix="!")
输出结果为:
Hello, Bob !
字典合并:
dict1 = {"a": 1, "b": 2}
dict2 = {"c": 3, "d": 4}
merged_dict = {**dict1, **dict2}
print(merged_dict)
输出结果为:
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
集合,无序可变,去重
创建集合
-
使用大括号 {} 和逗号 , 将元素括起来:可以直接使用大括号和逗号来定义集合。例如:my_set = {1, 2, 3, 4, 5}
-
使用 set() 函数:可以使用 set() 函数来创建集合,可以传入一个可迭代对象作为参数,例如列表、元组、字符串等。例如:
my_list = [6, 3, 9, 0, 1, 2, 3, 4, 5, 4]#列表
my_set = set(my_list)
print(my_set) # {0, 1, 2, 3, 4, 5, 6, 9} 默认都是升序排列
my_list = "[6, 3, 9, 0, 1, 2, 3, 4, 5, 4]" #字符串
my_set = set(my_list)
print(my_set)
- 创建空集合:要创建空集合,不能使用 {},因为这样会创建一个空字典,而是要使用 set() 函数来创建空集合。例如:empty_set = set()
添加和删除
添加 set.add(element)
删除集合 del set
删除元素 set.remove(element) set.pop()
清空集合 set,clear()
pop()随机移除,返回这个被移除的元素。但是实际运行移除的都是第一个元素
my_list = [0, 1, 2, 3, 4, 5]
my_set = set(my_list)
a = my_set.pop()
print(my_set, a)
交集 并集 差集
set1 = {1, 2, 3, 4, 5}
set2 = {3, 4, 5, 6, 7}
intersection = set1 & set2 或者使用 intersection = set1.intersection(set2)
union = set1 | set2 或者使用 union = set1.union(set2)
difference = set1 - set2 或者使用 difference = set1.difference(set2)
a = ['a','b','b','c','c']
print(set(a))
print(type(set(a)))
s = 'Welcome to my world'
print(set(s))
unique = set(s)
unique.add('a')
#unique.add(['b','x'])#不能加列表!
unique.clear()
unique.remove('x')#函数返回值不是set,是None;如果remove的元素不存在会报错
unique.discard('y')#如果remove的元素不存在,不会报错,会返回原有的set
print(unique)
print(a.difference(unique))#不同的地方,set=a-unique
print(a.intersection(unique))#相同的元素
字符串
| 功能 | 方法 |
|---|---|
| 拼接 | + 不允许和其他类型拼接 |
| 长度 | len() ,所有字符均默认为1个长度 utf-8中1个汉字3个字节,len(str.encode())得到字节数 |
| 切片 | str[start : end: step] |
| 分割 | str.split(sep, maxsplit)把字符串分割为列表 如果不指定sep分隔符,那么也不能指定maxsplit |
| 大写字母转小写字母 | str.lower() 如果没有字符转化,返回原字符串,否则返回新字符串 |
| 小写字母转大写字母 | str.upper() |
| 去除字符串中的空格和特殊字符\t \r \n | str.strip([chars]) str.lstrip([chars]) str.rstrip([chars]) |
| 判断字符串中是否只包含数字字符。 如果字符串中的每个字符都是数字,则返回 True;否则返回 False。 | str.isdigit() |
检索字符串
str.count(sub[,start[,end]])
str.find(sub[,start[,end]])
str.rfind(sub[,start[,end]]) 从右查找
str.index(sub[,start[,end]])
str.rindex(sub[,start[,end]]) 从右查找
str.startwith(sub[,start[,end]]):是否以什么开头
str.endwith(sub[,start[,end]]):以什么结尾
格式化字符串
使用了大括号{}来表示我们想要插入值的位置。在大括号内部,:后面的部分表示了格式化的方式。在这个例子中,{:0>9s}表示将值格式化为长度为9的字符串,若不够9位则在左边用0进行填充。{😒}表示将值格式化为字符串类型。
我们将实际要插入的值作为参数传入。在这里,'7’插入了第一个位置,'百度’插入了第二个位置,'baidu’插入了第三个位置。然后,str.format()方法会将这些值插入到模板字符串中,并返回格式化后的结果,存储在变量content中。
template = '编号:{:0>9s}\t公司名称: {:s} \t官网: http://www.{:s}.com'
content = template.format('7', '百度', 'baidu')
print(content) # 编号:000000007 公司名称: 百度 官网: http://www.baidu.com
六、运算符
算术运算符
- 加法:+
- 减法:-
- 乘法:*
- 除法:/ (总是返回浮点数)
- 取整除法:// (返回不大于结果的最大整数)
- 求余数:%【第二个被除数是负数,结果也是负数】
- 指数运算:**
# 加法
result1 = 5 + 3 # 结果为 8
# 减法
result2 = 7 - 2 # 结果为 5
# 乘法
result3 = 4 * 6 # 结果为 24
# 除法
result4 = 10 / 5 # 结果为 2.0 (总是返回浮点数)
# 取整除法
result5 = 17 // 3 # 结果为 5 (返回不大于结果的最大整数)
# 求余数
result6 = 10 % 3 # 结果为 1 (10 除以 3 的余数)
# 指数运算
result7 = 2 ** 5 # 结果为 32 (2 的 5 次方)
用于字符串
指定重复次数
print(3*"*")
赋值运算符
- 等号:=
- 加法赋值:+=
- 减法赋值:-=
- 乘法赋值:*=
- 除法赋值:/=
- 取整除法赋值://=
- 求余数赋值:%=
- 指数赋值:**=
# 等号
x = 10 # 将值 10 赋给变量 x
# 加法赋值
x += 5 # 等同于 x = x + 5
# 减法赋值
x -= 3 # 等同于 x = x - 3
# 乘法赋值
x *= 2 # 等同于 x = x * 2
# 除法赋值
x /= 4 # 等同于 x = x / 4
# 取整除法赋值
x //= 3 # 等同于 x = x // 3
# 求余数赋值
x %= 2 # 等同于 x = x % 2
# 指数赋值
x **= 3 # 等同于 x = x ** 3
比较运算符
- 相等:==
- 不相等:!=
- 大于:>
- 小于:<
- 大于等于:>=
- 小于等于:<=
# 相等
result1 = 5 == 5 # 结果为 True
# 不相等
result2 = 8 != 3 # 结果为 True
# 大于
result3 = 10 > 7 # 结果为 True
# 小于
result4 = 4 < 2 # 结果为 False
# 大于等于
result5 = 6 >= 6 # 结果为 True
# 小于等于
result6 = 9 <= 3 # 结果为 False
逻辑运算符
- and与
- or 或
- not 非
位运算符
- 按位与:&
- 按位或:|
- 按位异或:^
- 按位取反:~
- 左移:<<
- 右移:>>
# 按位与
result1 = 5 & 3 # 结果为 1
# 按位或
result2 = 5 | 3 # 结果为 7
# 按位异或
result3 = 5 ^ 3 # 结果为 6
# 按位取反
result4 = ~5 # 结果为 -6
# 左移
result5 = 5 << 1 # 结果为 10
# 右移
result6 = 5 >> 1 # 结果为 2
七、条件if else
if not 代表后面的表达式为false,执行下面的语句
if x is not None是最好的写法【为啥??】
可以多变量连续比较!
x=1
y=2
z=3
if x<y<z:
print('x<y<z')
x=1
y=2
z=0
if x<y>z:
print('x<y>z')
if x>y:
print('x>y')
elif x==y:
print('x==y')
else:
print('x<y')
简写
b =a if a>0 else -a
八、循环
for
【注意】for条件后需要加冒号:
改变结构的快捷键:ctrl+[
range是左闭右开,range(1,3)是【1,2】
example_list = [1,2,3,4,5,6,7,12]
for i in example_list:
print(i)
for i in range(1,3):
print(i)
for i in range(1,10,2):
print(i)
while
【注意】while 条件后需要加冒号:
condition = 1
while condition<10:
print(conditon)
conditon = condition+1
conitue break
break跳出循环
continue跳到下一次循环
while True:
a=input('input int:')
if a =='1':
break
else:
pass
while True:
a=input('input int:')
if a =='1':
continue
else:
pass
九、RegEx正则表达(Regular Expression)
主要用于网页爬虫
- ():用于创建一个捕获组
- 可以用来对一个子模式进行分组,以便后续可以对这个组内的内容进行匹配或提取;
- 可以用于指定一组模式中的选择项。例如 (a|b) 表示匹配 a 或 b。
- []:用于创建一个字符集
- 可以指定一个字符集中允许的字符,例如 [abc] 表示匹配字符 a、b、c 中的任意一个。
- 可以使用范围表示,比如 [0-9] 表示匹配任意一个数字字符。
- 可以指定字符集的取反,用 ^,例如 [^abc] 表示匹配除了 a、b、c 之外的任意字符。
- {}:用于指定匹配重复次数。
- 可以用来指定一个模式重复出现的次数,比如 {3} 表示匹配 3 次,{2,4} 表示匹配 2 到 4 次。
- 可以指定具体的次数,也可以指定范围。
- 一般与 *、+、? 等修饰符一起使用,用来控制重复匹配的次数。
import re
#简单python匹配
pattern1="cat"
pattern2="bird"
strting = "a cat"
print(pattern1 in string)
print(pattern2 in string)
#正则寻找配对
pattern1="cat"
pattern2="bird"
strting = "a cat"
print(re.search(pattern1,string))
print(re.search(pattern2,string))
#匹配run or ran
ptn = "r[au]n"#没有r只是普通的表达式
ptn = r"r[au]n"#有r表示是一个表达式
ptn2 = r"r[0-9a-z]n"#中间的数可能是0-9的数字或者a-z的小写
print(re.search(ptn,'a cat runs'))
特殊种类匹配
#数字 \d:所有数字形式
print(re.search(r"r\dn",'a cat r4ns'))
#\D:不是数字的形式
print(re.search(r"r\Dn",'a cat runs'))
#空白
#\s:任意空白符的键\t \n \r \f \v
print(re.search(r"r\sn",'r\nn r4ns'))
#\S:不是空白符的形式
print(re.search(r"r\Sn",'r\nn r4ns'))
#所有字母、数字、“_”
#\w:a-z 0-9 _
print(re.search(r"r\wn",'r\nn r4ns'))
#\W:相反意义
print(re.search(r"r\Wn",'r\nn r4ns'))
#空白字符
#\b:字符的前后空白符才匹配
print(re.search(r"\bruns\b",'dog runs to cat'))
print(re.search(r"\bruns\b",'dog runs to cat'))
#\B:字符前后的空白符不限量
print(re.search(r"\B runs \B",'dog runs to cat'))
#特殊字符 任意字符
#\\:匹配\
print(re.search(r"runs\\",'dog runs\ to cat'))
#.:匹配任意字符,除了\n
print(re.search(r"r.n",'dog r[uns to cat'))
#句尾句首
^:匹配句首
print(re.search(r"^dog",'dog runs to cat'))
$:匹配句尾
print(re.search(r"cat$",'dog runs to cat'))
?:匹配前面的子表达式零次或一次。
print(re.search(r"Mon(day)?",'Monday'))
print(re.search(r"Mon(day)?",'Mon'))
多行匹配
string = """
dog runs to cat.
I run to dog.
"""
print(re.search(r"^I",string))
print(re.search(r"^I",string,flags=re.M))
*:0次或多次匹配
print(re.search(r"ab*","a"))
print(re.search(r"ab*","abbb"))
+:1次或多次
print(re.search(r"ab+","a"))
print(re.search(r"ab+","abbb"))
{n,m}:指定次数匹配
print(re.search(r"ab{2,10}","a"))
print(re.search(r"ab{2,10}","abbb"))
group数组
match = re.search(r"(\d+).Date:(.+)","ID:1,Date:28/02/2024")
print(match.group()) #打印所有的匹配的句子
print(match.group(1)) #打印所有的匹配的第一个()
print(match.group(2)) #打印所有的匹配的第二个()
match = re.search(r"(?P<id>\d+).Date:(?P<date>.+)","ID:1,Date:28/02/2024")
print(match.group('id')) #打印命名为id的部分
print(match.group('date')) #打印命名为date的部分
寻找所有匹配findall
print(re.findall(r"r[au]n","run ran ren"))
|:或
print(re.findall(r"ran|run","run ran ren"))
print(re.findall(r"r(a|u)n","run ran ren"))
替换
print(re.sub(r"ran|run","catches","run ran ren"))
分裂
print(re.split(r"[,;\.]","a,b;c.d"))#以, ; .分割元素,由于.表示任意字符,所以需要加转义\
编译compile
com = re.compile(r"r[au]n")
print(com.research("dog runs to cat"))
?=、?<=、?!、?<!
exp1(?=exp2):查找 exp2 前面的 exp1。
(?<=exp2)exp1:查找 exp2 后面的 exp1。
exp1(?!exp2):查找后面不是 exp2 的 exp1。
(?<!exp2)exp1:查找前面不是 exp2 的 exp1。
所以pattern匹配的是后面的exp1,matches匹配的是a_后面跟的数字

举例:
match[0]是正则表达式匹配的结果,是一个包含年、月、日信息的元组,例如(2024, 02, 28)。
year, month, day = match[0]中的year、month和day是左侧的目标变量,它们会按照元组中元素的顺序依次接收对应的值。
import re
# 定义包含日期信息的字符串
date_string = "2024-02-28"
# 定义匹配日期信息的正则表达式模式,利用()创建捕获组来分别匹配年、月、日
pattern = r"(\d{4})-(\d{2})-(\d{2})"
# 使用 re 模块的 findall() 方法匹配字符串中的模式
match = re.findall(pattern, date_string)
# 输出匹配结果
if match:
year, month, day = match[0]
print("Year:", year)
print("Month:", month)
print("Day:", day)
else:
print("No match")
十、函数
def函数
def func(b):
a=1+2+b
print(a)
#调用函数
func()
def sale_car(price,color,brand):
print('price',price,'color',color,'brand',brand)
sale_car(100,'red','bmw')
#默认值定义好的参数统一放在后面
def sale_car(price,color,brand='bmw'):
print('price',price,'color',color,'brand',brand)
sale_car(100,'red')
形参 实参
如果传递的是可变对象(如列表、字典等),函数内部的修改会影响原始对象;
如果传递的是不可变对象(如整数、字符串等),函数内部的修改不会影响原始对象。
值传递:字符串,不可变对象
引用传递:列表,可变对象
可变参数
可变参数指的是函数在定义时可以接受任意数量的参数。有两种类型的可变参数:
- *args
*args 允许函数接受任意数量的位置参数,这些参数会被收集到一个元组中传递给函数。
def my_func(*args):
for arg in args:
print(arg)
my_func(1, 2, 3) # 输出 1 2 3
list = [1,2,3]
my_func(*list)
- kwargs
kwargs 允许函数接受任意数量的关键字参数,这些参数会被收集到一个字典中传递给函数。
def my_func(**kwargs):
for key, value in kwargs.items():
print(key, value)
my_func(a=1, b=2, c=3) # 输出 a 1, b 2, c 3
def my_func(*args, **kwargs):
for arg in args:
print(arg)
for key, value in kwargs.items():
print(key, value)
my_func(1, 2, 3, a=4, b=5) # 输出 1 2 3, a 4, b 5
匿名函数/ lambda 函数
lambda arguments: expression
add = lambda x, y: x + y
print(add(3, 5)) # 输出 8
filter() 函数用于过滤序列,返回一个由使得函数返回值为 True 的元素所组成的迭代器。
语法:filter(function, iterable)
numbers = [1, 2, 3, 4, 5]
filtered_nums = filter(lambda x: x % 2 == 0, numbers)
print(list(filtered_nums)) # 输出 [2, 4]
map() 函数用于对序列中的每个元素应用函数,返回一个由应用函数后的结果组成的迭代器。
语法:map(function, iterable)
示例:
numbers = [1, 2, 3, 4, 5]
squared_nums = map(lambda x: x ** 2, numbers)
print(list(squared_nums)) # 输出 [1, 4, 9, 16, 25]
十一、全局变量 局部变量
全局通常以全部大写定义变量名
A = 1
app = None
def func():
global app
app=10
return app
print(app)
print(func())
print(app)
十二、模块
模块文件的扩展名必须是.py
使用模块可以避免函数名和变量名冲突的问题
使用包避免模块名冲突的问题
导入模块
import time
import time as t
print(time.localtime())
from time import localtime#只需要特定的功能
print(localtime())
from time imprt *#添加所有的功能
检索模块,查找的目录
import sys
print(sys.path)
标准模块
- os 模块:提供了与操作系统进行交互的功能,例如文件操作、目录操作、进程管理等。
- datetime 模块:提供了处理日期和时间的功能,包括日期时间对象的创建、格式化、计算以及时区相关操作等。
- time模块:
- calendar模块:
- math 模块:提供了数学运算相关的函数,例如数学常量、数学函数、对数函数等。
- random 模块:提供了生成随机数的功能,包括伪随机数生成器、随机数种子相关等。
- json 模块:提供了处理 JSON 格式数据的功能,包括解析 JSON 数据、序列化 Python 对象为 JSON 字符串等。
- re 模块:提供了对正则表达式的支持,可以进行模式匹配、文本搜索、替换等操作。
- sys 模块:提供了与 Python 解释器进行交互的功能,可以访问解释器的变量和函数。
- collections 模块:提供了额外的数据结构,例如 OrderedDict、defaultdict、Counter 等,用于扩展 Python 原生数据结构的功能
- itertools 模块:提供了用于迭代操作的函数,例如生成排列、组合、循环迭代等。
- urllib 模块:提供了用于读取网上的数据、操作 URL 的功能,例如发送 HTTP 请求、处理 URL 编码解码等。
- math模块:提供了标准算数运算函数
- decimal模块:
外部模块安装
sudo pip3 install numpy
sudo pip3 install numpy-1.9.2
#upgrade
sudo pip3 install -U numpy
sudo pip3 uninstall numpy
__main__
if __name__ == '__main__'
在 Python 中,if name == ‘main’: 是一个常见的语句,用于检查当前脚本是否被直接执行。这个语句的含义是:如果当前脚本被直接执行(而不是被导入为模块),那么执行紧随其后的代码块。
这种结构通常被用于使一个 Python 文件既可以被作为脚本直接运行,又可以被其他脚本导入并调用其中的函数或类。这种做法很常见,因为在 Python 中,模块和脚本之间的区别很模糊,同一个文件既可以是独立的脚本,也可以是可重用的模块。
当 Python 解释器读取一个文件时,它会将其中的代码执行一遍。如果一个文件被作为主程序直接运行,name 的值会被设置为 ‘main’,这样通过 if name == ‘main’: 就可以执行特定于主程序的代码块。如果一个文件被导入为模块,name 的值会被设置为该模块的名称,而不是 ‘main’,因此 if name == ‘main’: 下面的代码块就不会执行。
模块导入
Python是一种解释型脚本语言,在执行之前不同要将所有代码先编译成中间代码,Python程序运行时是从模块顶行开始,逐行进行翻译执行,所以,最顶层(没有被缩进)的代码都会被执行,所以Python中并不需要一个统一的main()作为程序的入口。在某种意义上讲,“if name’main:”也像是一个标志,象征着Java等语言中的程序主入口,告诉其他程序员,代码入口在此——这是“if name’main:”这条代码的意义之一。
当我们把模块A中的代码在模块B中进行import A时,只要B模块代码运行到该import语句,模块A的代码会被执行。
# 模块A
a = 100
print('你好,我是模块A……')
print(a)
# 模块B
from package01 import A
b = 200
print('你好,我是模块B……')
print(b)
运行模块B时,输出结果如下:
你好,我是模块A……
100
你好,我是模块B……
200
如果在模块A中,我们有部分的代码不想在被导入到B时直接被运行,但在直接运行A时可直接运行,那该怎么做呢?那就可以用到“if name==’main:”这行代码了,我们队上面用到的A模块代码进行修改:
A模块代码修改为:
# 模块A
a = 100
print('你好,我是模块A……')
if __name__=='__main__':
print(a)
B模块不做修改,直接执行B模块,输出结果如下:
你好,我是模块A……
你好,我是模块B……
200
A模块中的a的值就没有再被输出了。所以,当你要导入某个模块,但又不想改模块的部分代码被直接执行,那就可以这一部分代码放在“if name==‘main’:”内部。
__name__的理解
__name__属性是Python的一个内置属性,记录了一个字符串。
若是在当前文件,name 是__main__。
在hello文件中打印本文件的__name__属性值,显示的是__main__
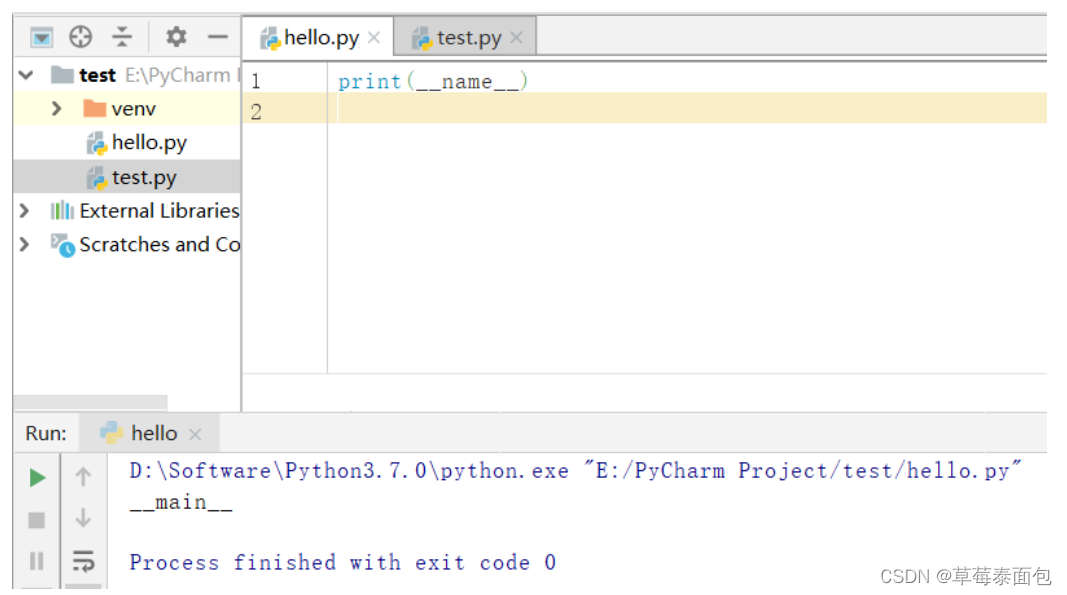
若是导入的文件,__name__是模块名。
test文件导入hello模块,在test文件中打印出hello模块的__name__属性值,显示的是hello模块的模块名。
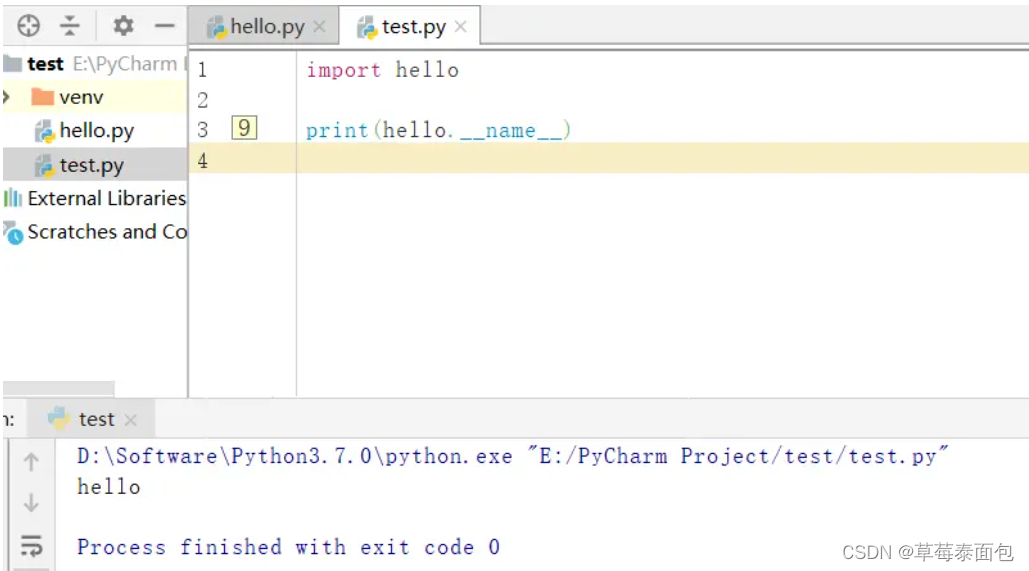
因此__name__ == ‘main’ 就表示在当前文件中,可以在if name == ‘main’:条件下写入测试代码,如此可以避免测试代码在模块被导入后执行。
包
包(Package)是一种模块的组织方式,可以将多个功能相近的模块组织在一起,方便管理和引用。包内部可以包含多个模块文件,通常还包括一个__init__.py 文件作为包的初始化文件。
包的结构:
包是一个包含 init.py 文件的目录,该目录下可以包含多个模块文件和子包(子目录),形成层级结构。
init.py 文件可以是空文件,也可以包含初始化代码,用于在导入包时执行一些初始化操作。
当导入包时,init.py 文件会被执行,其中可以定义包的属性、函数等内容。
Python 包的命名应该是小写字母和下划线的组合
如果你开发了一个功能强大的包,可以考虑将其发布到 Python Package Index(PyPI)
第三方包
- NumPy:提供了强大的多维数组对象和对应的操作函数,是进行科学计算的基础包之一。
- Pandas:提供了数据分析和数据处理的功能,包括数据结构、数据清洗、数据分析等,是处理结构化数据的重要工具。
- Matplotlib:用于绘制图表和可视化数据,支持各种类型的图形和绘图风格。
- Scikit-learn:提供了各种机器学习算法和工具,用于建模、数据预处理、模型评估等,是机器学习领域的重要库之一。
- TensorFlow / PyTorch:这两个包分别提供了深度学习框架,支持构建神经网络模型、训练、推理等一系列深度学习相关操作。
- Django / Flask:这两个是常用的 Web 框架,用于快速搭建 Web 应用和 API。
- Requests:提供了发送 HTTP 请求的简洁而友好的 API,用于进行网络请求操作。
- Beautiful Soup:用于解析 HTML 和 XML 文档,提取信息的库,常用于网页爬虫和数据抓取。
- PyQt / Tkinter:这两个提供了创建图形用户界面(GUI)的工具包,用于构建桌面应用程序。
- pytest:提供了对 Python 代码进行单元测试的功能,支持编写测试用例、执行测试、生成测试报告等。
十、文件与IO
文件操作
文件对象file
print(type(myfile))
将输出:<class '_io.TextIOWrapper'>代表着一个文本文件的 I/O 包装器对象
打开文件
a:append追加
a+:读写
w:write只写,w和a相关的参数,文件存在则将其覆盖,否则创建新文件
r:read只读,r相关的参数,文件必须存在
rb:以二进制形式打开文件,多用于图片、声音
text = 'first line. \n second line.'
myfile=open('myfile.txt','w')
appendtext = 'append file'
myfile=open('myfile.txt','a')
with open('myfile.txt','w') as file:
pass
写入文件
myfile.write(text)
关闭文件
close()先刷新缓冲区还没有写入的信息,然后再关闭文件,这样可以将还没有写入文件的内容写入到文件
myfile.close()#记得关上
读取文件
read(),打开模式必须是r/r+
file = open('myfile.txt','r')
content = file.read()
#逐行读取
first_line = file.readline()
#逐行读取并保存为list数据类型
content_list = file.readlines()
print(content)
文件指针
file.seek() 是 Python 中用于移动文件指针(读写位置)的方法,以字节数为单位。文件指针指示了即将被读取或写入的位置。file.seek(offset, whence) 方法接受两个参数:
- offset:表示偏移量,可以为正数或负数,表示相对于 whence 参数的偏移量。
- whence:可选参数,表示基准位置,可选值为 0(文件开头)、1(当前位置)、2(文件末尾),默认为 0。
例如:
如果你想从文件开头偏移10个字节,可以使用 file.seek(10, 0)。
如果你想从当前位置向后偏移5个字节,可以使用 file.seek(5, 1)。
如果你想从文件末尾向前偏移20个字节,可以使用 file.seek(-20, 2)。
file.tell() 方法来获取当前文件指针的位置。
with open("example.txt", "r") as file:
file.seek(5) # 移动文件指针到第6个字符的位置(索引从0开始)
data = file.read(10) # 读取10个字符
print(data)
os.rename(src, dst):重命名文件或目录。
将目录或文件从 src 参数指定的路径重命名为 dst 参数指定的路径。
当 倒数第二级目录不同时,会创建新文件夹
import os
os.rename("old_file.txt", "new_file.txt")
os.remove(file):删除文件。
import os
os.remove("file_to_delete.txt")
os.rmdir(directory):删除空目录。
import os
os.rmdir("empty_directory")
os.removedirs(directory):递归删除目录及其所有子目录中的所有空目录。
import os
os.removedirs("parent_directory/child_directory/grandchild_directory")
shutil模块中,存在一个rmtree()函数用于递归删除目录以及目录中的所有文件和子目录。
使用rmtree()函数需要小心,因为它会永久删除指定的目录及其中的所有内容,无法恢复。
import shutil
shutil.rmtree("path/to/directory_to_delete")
os.chmod(path, mode):更改文件或目录的权限模式。
import os
os.chmod("file.txt", 0o777) # 设置文件权限为所有者可读写执行
目录操作
模块os和os.path
变量:
- os.name操作系统的类型
='nt’是windows
=’posix’是linux、unix、macos - os,linesep当前操作系统的换行符
- os.sep当前操作系统的路径分隔符
路径
import os
# 获取当前工作目录
current_dir = os.getcwd()
print("当前工作目录:", current_dir)
# 组合当前目录下的相对路径为绝对路径
relative_path = "myfolder/myfile.txt"
absolute_path = os.path.abspath(relative_path)
print("相对路径", relative_path, "的绝对路径是:", absolute_path)
输出
当前工作目录: /home/user
相对路径 myfolder/myfile.txt 的绝对路径是: /home/user/myfolder/myfile.txt
使用 os.path.join() 函数来拼接路径。这个函数可以帮助我们安全地创建跨平台兼容的文件路径,无需担心不同操作系统的路径分隔符差异。
函数不会验证拼接的路径是否存在
import os
# 定义要拼接的路径部分
folder = "myfolder"
filename = "myfile.txt"
# 使用os.path.join()拼接路径
full_path = os.path.join(folder, filename)
# 打印拼接后的完整路径
print("完整路径:", full_path)
假设在 Unix/Linux 系统上运行以上代码,将输出拼接后的完整路径:
完整路径: myfolder/myfile.txt
在 Windows 系统上运行,输出将会是:
完整路径: myfolder\myfile.txt
目录
使用os.path.exists() 来检查目录是否存在。
使用 os.mkdir() 来创建单个目录。
使用 os.makedirs() 来创建多级目录。如果上级目录不存在,会一并创建所需的上级目录。
使用 os.rmdir() 来删除目录。
import os
directory = "myfolder"
if os.path.exists(directory):
print(f"目录 '{directory}' 存在")
else:
print(f"目录 '{directory}' 不存在")
os.makedirs(directory) # 创建目录,包括必要的父目录
os.makedirs("path/to/new_directory", exist_ok=True)
os.rmdir(directory) # 删除指定的目录
使用 os.walk() 来遍历目录中的子目录和文件。
返回一个生成器,每次迭代产生一个包含目录路径、子目录列表和文件列表的元组 (root, dirs, files)
root 是当前目录的路径。字符串
dirs 是当前目录下的子目录列表。列表
files 是当前目录下的文件列表。列表
import os
directory = "my_folder"
for root, dirs, files in os.walk(directory):
print(f"当前目录: {root}")
print(f"子目录: {dirs}")
print(f"文件: {files}")
print()
十一、类 对象
在python中一切都是对象,函数等也是对象
对象是类的实例
面向对象的三大特征:封装、继承、多态(将父类对象应用于子类特征)
类
具有相同的属性和方法的对象的集合
类名通常以大写字母开头
类的成员由实例方法和数据成员(属性)组成
class Calculator:
name = 'calculator'
def __init__(self,name):
self.name = name
def add(self,x,y):
recult=x+y
print(self.name)
属性:1、类属性:定义在类中,在函数体外的属性
2、实例属性:定义在类的方法中的属性,只作用于当前实例,类名不能访问实例属性
class Test:
a = "a"
def __init__(self):
self.b = "b"
t1 = Test.a
t2 = Test.b 无法访问!
t3 = Test().a
t4 = Test().b
t = Test()
t.a
t.b
类属性是属于类本身的属性,它被所有类的实例所共享。在类的内部定义的属性属于类属性。当类属性的值被修改时,所有实例都会受到影响。
class Person:
species = "Homo sapiens" # 类属性
person1 = Person()
person2 = Person()
print(person1.species) # 输出 "Homo sapiens"
print(person2.species) # 输出 "Homo sapiens"
Person.species = "Homo erectus" # 修改类属性的值
print(person1.species) # 输出 "Homo erectus"
print(person2.species) # 输出 "Homo erectus"
实例属性是属于类实例的属性,它只在特定的实例中存在,不会被其他实例共享。实例属性通常在 __init__() 方法中初始化,并且每个类的实例都可以拥有独特的实例属性值。
class Person:
def __init__(self, name):
self.name = name # 实例属性
person1 = Person("Alice")
person2 = Person("Bob")
print(person1.name) # 输出 "Alice"
print(person2.name) # 输出 "Bob"
__init__()
init() 是一个特殊方法(也称为构造方法),用于在创建一个类的实例时进行初始化操作。当实例化一个类时,会自动调用该类的 init() 方法。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def introduce(self):
print(f"My name is {self.name} and I am {self.age} years old.")
# 创建一个 Person 类的实例
person1 = Person("Alice", 30)
# 调用实例的方法,使用.访问
person1.introduce()
访问限制
- 首尾双下划线:系统定义的
- 单下划线开头:protected类型,只允许类本身和子类访问,不能import
- 双下划线开头:private类型,只允许定义该方法的类本身进行访问
class MyClass:
def __init__(self):
self.public_var = 10 # 公开的实例属性
self._protected_var = 20 # 受保护的实例属性
self.__private_var = 30 # 私有的实例属性,会触发名称修饰
def public_method(self):
print("This is a public method")
def _protected_method(self):
print("This is a protected method")
def __private_method(self): # 私有的方法,会触发名称修饰
print("This is a private method")
obj = MyClass()
print(obj.public_var) # 可以访问公开的实例属性
print(obj._protected_var) # 也可以访问受保护的实例属性
# 以下访问会触发 AttributeError
print(obj.__private_var)
obj.__private_method()
通过类名+双下划线+属性名的形式来访问私有属性。
# 使用名称修饰来访问私有属性
class MyClass:
def __init__(self):
self.__private_var = 30
obj = MyClass()
print(obj._MyClass__private_var)
# 通过公共方法来访问私有属性
class MyClass:
def __init__(self):
self.__private_var = 30
def get_private_var(self):
return self.__private_var
obj = MyClass()
print(obj.get_private_var())
十二、 装饰器
他们是修改其他函数的功能的函数。
将类方法转换为属性的装饰器
@property 是 Python 中用来将类方法转换为属性的装饰器,它可以让我们通过访问属性的方式调用方法,从而实现对属性的访问和计算逻辑的封装。
class Circle:
def __init__(self, radius):
self._radius = radius
@property
def radius(self):
return self._radius
@property
def area(self):
return 3.14 * self._radius ** 2
@radius.setter
def radius(self, value):
if value <= 0:
raise ValueError("Radius must be positive")
self._radius = value
@radius.deleter
def radius(self):
del self._radius
# 创建 Circle 实例
my_circle = Circle(5)
# 访问属性方法
print(my_circle.radius) # 输出半径
print(my_circle.area) # 输出面积
# 修改属性值
my_circle.radius = 10
print(my_circle.radius)
# 删除属性
del my_circle.radius
可以实现只读属性
class Circle:
def __init__(self, radius):
self._radius = radius
@property
def radius(self):
return self._radius
# 创建 Circle 实例
my_circle = Circle(5)
# 访问只读属性
print(my_circle.radius) # 输出半径
# 尝试修改只读属性(将会引发 AttributeError 异常)
try:
my_circle.radius = 10
except AttributeError as e:
print("Error:", e)
函数装饰器
def my_decorator(func):
def wrapper():
print("Before calling the function")
func()
print("After calling the function")
return wrapper
@my_decorator
def say_hello():
print("Hello!")
say_hello()
类装饰器
类装饰器是那些实现 call 方法的类,它们可以像函数装饰器一样使用。
class MyClassDecorator:
def __init__(self, func):
self.func = func
def __call__(self):
print("Before calling the function")
self.func()
print("After calling the function")
@MyClassDecorator
def say_hi():
print("Hi!")
say_hi()
十三、继承
通过 class 子类(父类): 声明继承关系。
派生类中定义__init__()时不会自动调用基类的init方法,必须进行初始化,使用super()调用基类的init()
# 定义父类
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
print(f"{self.name} makes a sound")
# 定义子类,继承自 Animal
class Dog(Animal):
def __init__(self, name, breed):
# 调用父类的初始化方法
super().__init__(name)
self.breed = breed
def speak(self):
print(f"{self.name} barks")
def fetch(self):
print(f"{self.name} fetches the ball")
# 创建子类实例
dog = Dog("Buddy", "Golden Retriever")
print(dog.name) # 继承自父类
dog.speak() # 重写了父类方法
dog.fetch() # 子类新增的方法
super()
super() 是一个内置函数,用于调用父类的方法。通常在子类中使用 super() 函数来调用父类的方法,这样可以避免显式地提及父类的名称
super() 可以在两种不同的情况下使用:经典类(不继承自 object 的类)中和新式类(继承自 object 的类)中。
在 Python 3.x 中,所有的类都默认继承自 object。
class ParentClass(object):
def some_method(self):
# 方法实现
class ChildClass(ParentClass):
def some_method(self):
super().some_method()
# 子类方法的实现
十二、input
input 返回的字符串
a = input('input:')
print('a=',a)
十五、错误处理 try except finally
try:
file = open('1','r+')#r+只读加写入的方式打开
except Exception as e:#try执行失败
print(e)
response = input('do you want to create a new file')
if respone=='y':
file = open('1','w')
else:#try执行成功
file.write('sss')
file.close()
finally 是 Python 中的一个关键字,通常用于定义在try语句块结束之后,无论是否发生异常,都要执行的代码块。finally 语句块通常用于清理资源、确保某些操作一定会被执行,或者在try语句块结束时执行一些必要的收尾工作。
try:
# 可能会发生异常的代码块
# 这里会尝试执行一些操作
except SomeException:
# 异常处理代码
finally:
# 无论try代码块中是否发生异常,都会执行的代码块
# 这里放一些清理资源或必要的收尾工作
try:
file = open('example.txt', 'r')
# 读取文件内容
# 可能会引发异常
except FileNotFoundError:
print('File not found')
finally:
if 'file' in locals():
file.close() # 确保文件关闭
print('Finally block executed') # 最终执行的代码
raise抛出异常
raise 关键字用于手动触发异常,即抛出一个异常。
x = -1
if x < 0:
raise ValueError("x不能为负数")
assert
assert 是一个关键字,用于在代码中检查某个条件是否为真。当某个条件为假时,assert 将引发一个 AssertionError 异常。
- condition 是要检查的条件,如果条件为 False,则 assert 语句将引发异常。
- message 是可选的,用于在引发异常时指定错误信息。
assert condition, message
def divide(x, y):
assert y != 0, "除数不能为 0"
return x / y
assert只在调试阶段有用,可以通过-O参数来关闭assert语句,就会触发优化模式。在优化模式下,所有 assert 语句都会被忽略
python -O your_program.py
十六、zip lambda map
zip
a=[1,2,3]
b=[4,5,6]
zip(a,b) #zip后是一个object
list(zip(a,b))
for i,j in zip(a,b):
print(i/2,j*2)
list(zip(a,a,b))
lambda
def fun(x,y):
return x+y
fun(1+2)
fun2 = lambda x,y:x+y
fun2(1,2)
map
map(fun,[1],[2]) #map后是一个object对象
list(map(fun,[1],[2]))
list(map(fun,[1,2],[2,5]))
十七、深拷贝deepcopy 浅拷贝copy
copy:
对于复杂对象(比如嵌套列表、字典等),copy() 只会复制对象本身和其内部的引用,而不会递归地复制内部的子对象
deepcopy:
对于复杂对象,deepcopy() 会递归地复制所有子对象,从而生成一个完全独立的副本,原对象和复制对象之间没有任何关联。
import copy
a=[1,2,3]
b=a #a,b指向同样的内容
id(a)#id是看a在内存中的地址
id(b)
print(id(a)==id(b))
c = copy.copy(a)
print(id(a)==id(c))
import copy
original_list = [1, [2, 3], 4]
shallow_copy_list = copy.copy(original_list)
deep_copy_list = copy.deepcopy(original_list)
original_list[1][0] = 5
print(original_list) # [1, [5, 3], 4]
print(shallow_copy_list) # [1, [5, 3], 4],共享引用
print(deep_copy_list) # [1, [2, 3], 4],独立副本
十九、多核运算
在这里插入代码片
二十、tkinter
二十一、python gui界面
wxpython
二十二、pickle存放数据
import pickle
a = {1:'da',2:[1,2,3]}
file = open('1','wb')#b表示二进制
pickle.dump(a,file)
file.close()
file = open('1','rb')
a1 = pickle.load(file)
file.close()
print(a1)
with open('1','rb') as file:#with 会自动关闭file
a1 = pickle.load(file)
print(a1)
二十六、datetime time
计算两个日期间的倒计时
import datetime
import time
count_time = datetime.datetime(2024, 11, 11, 0, 0, 0, 0)
while True:
now_time = datetime.datetime.now()
countdown = count_time - now_time
print(f'距离结束:{countdown.days}天,{countdown.seconds//3600}时,{(countdown.seconds % 3600)//60}分,{(countdown.seconds % 3600) % 60}秒')
time.sleep(1)
datetime.datetime.strptime()
用于将一个字符串解析为一个 datetime 对象。其语法如下:
datetime.datetime.strptime(date_string, format)
date_string 是待解析的日期时间字符串。
format 是日期时间字符串的格式,指定了解析字符串的结构。
from datetime import datetime
date_string = "2024-03-22 12:00:00"
date_obj = datetime.strptime(date_string, "%Y-%m-%d %H:%M:%S")
print(date_obj) # 输出:2024-03-22 12:00:00
print(type(date_obj)) <class 'datetime.datetime'>
datetime.datetime.strftime()
用于将一个 datetime 对象格式化为一个字符串。其语法如下:
datetime_obj.strftime(format)
datetime_obj 是一个 datetime 对象,表示待格式化的日期时间。
format 是格式化字符串,指定了输出字符串的结构。
from datetime import datetime
date_obj = datetime(2024, 3, 22, 12, 0, 0)
date_string = date_obj.strftime("%Y-%m-%d %H:%M:%S")
print(date_string) # 输出:2024-03-22 12:00:00