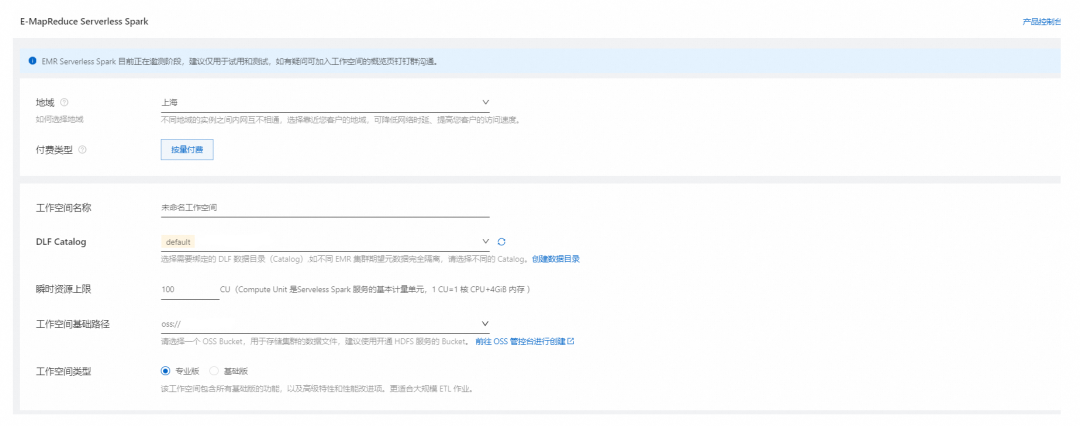
随着大数据应用的广泛推广,企业对于数据处理的需求日益增长。为了进一步优化大数据开发流程,减少企业的运维成本,并提升数据处理的灵活性和效率,阿里云开源大数据平台 E-MapReduce (简称“EMR”)正式推出 EMR Serverless Spark 版,并已开启邀测!
以强大的 Spark Native Engine 为基础,阿里云 EMR Serverless Spark 版旨在提供一个全托管、一站式的数据开发平台。它为用户提供任务开发、调试、发布、调度和运维等全方位的产品化服务,显著简化了大数据计算的工作流程,使用户能更专注于数据分析和价值提炼,轻松应对海量数据分析和处理的挑战。

产品优势
云原生极速计算引擎
-
内置 Spark Native Engine,相对开源版本性能提升200%;
-
内置 Celeborn,支持 PB 级 Shuffle 数据,计算资源总成本最高下降 30% 。
开放化的数据湖架构
-
支持计算存储分离,计算可弹性伸缩、存储可按量付费;
-
对接 OSS-HDFS,完全兼容 HDFS 的云上存储,无缝平滑迁移上云;
-
中心化的 DLF 元数据,全面打通湖仓元数据。
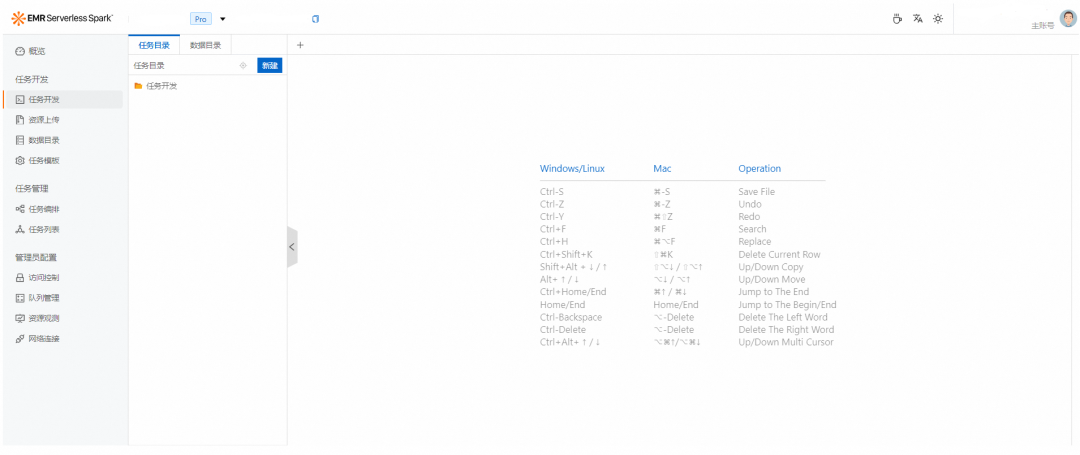
一站式的开发体验:
-
提供作业开发、调试、发布、调度等一站式数据开发体验;
-
内置版本管理、开发与生产隔离,满足企业级开发与发布标准。
Serverless 的资源平台:
-
开箱即用,无需手动管理和运维云基础设施;
-
弹性伸缩,秒级资源弹性与供给;
-
按量付费,按实际计算资源量付费,进一步降低计算总成本。
应用场景
基于 EMR Serverless Spark 版建立数据平台
得益于其开放的产品架构,EMR Serverless Spark 版使得在数据湖中对结构化和非结构化数据进行分析与处理变得简单高效。此外,其还内置了任务调度系统,允许用户轻松构建和管理数据 ETL 任务,实现数据管道的自动化和周期性数据处理。
EMR Serverless Spark 版还内嵌了先进的版本管理系统,并提供了开发与生产环境的完全隔离,确保符合企业级用户在研发和发布流程方面的严格要求。这些特性共同保障了数据处理的可靠性和效率,同时满足企业级应用的高标准要求。

邀测信息
诚挚邀请您参与 EMR Serverless Spark 版免费测试,体验 100% 兼容 Spark 的 Serverless 服务。
您将收获:
● 开发、调试、运行、调度,运维一体化的开发体验;
● 直接对产品提出意见和建议,影响产品方向;
● 邀测期间免费测试并提供一对一技术支持。
如何申请:
扫描下方二维码即可提交申请!