写在前面
本文看下es数据建模相关的内容。
1:什么是数据建模
数据建模是对真实数据的一种抽象,最终映射为计算机形式的表现。其包括如下三个阶段:
1:概念模型
2:逻辑模型
3:数据模型
2:es数据建模的过程
es的数据建模其实就是确定各个字段都需要如何进行设置,什么类型?是否需要搜索?等,具体需要考虑的问题如下:

注意以上四个要素没有先后的顺序,而只是需要综合考虑的因素。
2.1:数据类型
为了选择合适的数据类型,我们来看下每种数据类型的特点。
2.1.1:text
默认会被分词器分词,可以搜索,但是不支持聚合和排序,如果想要支持的话需要显式将fielddata设置为true。
2.1.2:keyword
不会被分词,所以一般用在不需要分词时使用,如主键id,邮箱,手机号,身份证号等。支持聚合,搜索和排序,以及用于查询时精确匹配方式的过滤。
2.1.3:多字段类型
当希望一个数据按照多种的数据类型来存储,从而满足诸如按照不同的分词器进行分词,按照不同的查询条件进行查询(如存储为int则可以按照range来查询),但又不希望设置多个字段时使用。默认的在es中如果时字段时text类型的,则会默认添加一个名称为keyword的keyword类型的字段,当然实际工作中我们我们不需要这个默认行为则可以通过显式mapping来自己定义。
2.1.4:数值类型
数值类型是一种结构化数据,数值类型应该尽量设置能够满足存储要求的最小类型,如可以设置为byte,就不要设置为long。
2.1.5:枚举类型
枚举类型是一种结构化数据,建议设置为keyword,以获得更好的性能。
2.1.6:日期,布尔,地理信息等
设置为对应的类型即可。
2.2:搜索,聚合,排序
- 搜索
是否需要被搜索,也是对字段进行建模时要考虑的一个重要因素,因为搜索功能需要分词,以及创建对应的倒排索引数据结构,所以需要额外的存储消耗,以及构建对应数据结构的性能消耗。 - 聚合,排序
聚合和排序功能需要依赖于doc_values,和fielddata,需要简历对应的数据结构来满足聚合和排序功能,因此也会有对应的存储成本,和对应数据结构的维护成本。
对于这三个因素可从以下方面进行考虑:
1:如果是同时不需要搜索,聚合和排序,则可考虑设置enable=false,不存储_source(还需要注意不存储_source的话将无法reindex和更新)
2:如果是不需要搜索,则可以设置index:false
3:如果不需要聚合和排序,则可以设置doc_values和fielddata为false
4:如果是更新频繁,聚合频繁,则可考虑设置keyword类型的eager_global_ordinals为true,可以利用缓存来提高性能。
2.3:额外存储字段值
如果希望额外存储字段值,则可以设置store:true,一般结合enbled:false使用。
enabled:false一般应用在一些指标数据的存储上,这些数据不需要reindex,更新。此时如果还希望查看某些字段的话则可以设置store为true。
但是实际的应用中不建议直接设置enabled:false,而是考虑使用高压缩的存储方式来减少存储的开销。
2.4:数据建模优化实例
假定我们要对如下的数据进行建模:

如下是默认生成的mapping:

其中cover_url被自动映射为text类型,并增加keyword类型的子字段,如下:
# Index 一本书的信息
PUT books/_doc/1
{
"title": "Mastering ElasticSearch 5.0",
"description": "Master the searching, indexing, and aggregation features in ElasticSearch Improve users’ search experience with Elasticsearch’s functionalities and develop your own Elasticsearch plugins",
"author": "Bharvi Dixit",
"public_date": "2017",
"cover_url": "https://images-na.ssl-images-amazon.com/images/I/51OeaMFxcML.jpg"
}
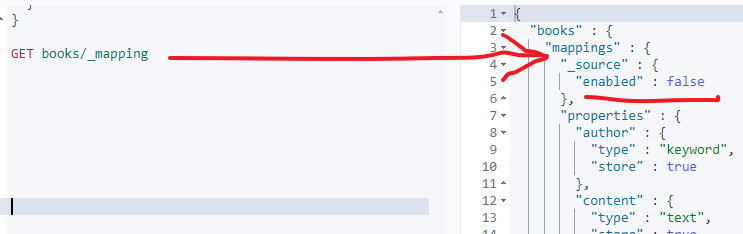
#查询自动创建的Mapping
GET books/_mapping
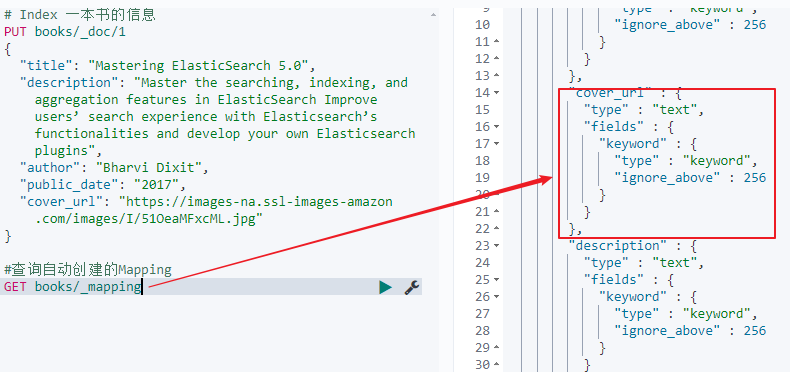
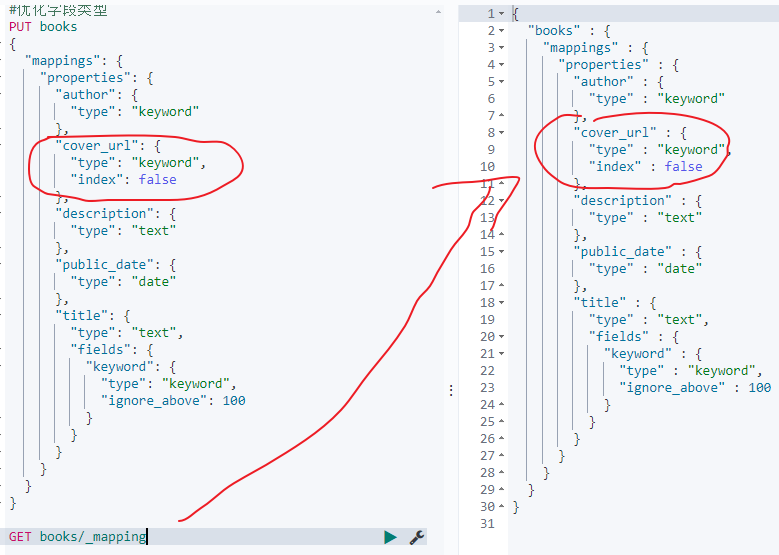
假定根据实际的业务需求,cover url不需要支持搜索,只需要支持聚合即可,此时我们就可以将其显式的设置为keyword,并将index设置为false,如下:
DELETE books
#优化字段类型
PUT books
{
"mappings": {
"properties": {
"author": {
"type": "keyword"
},
"cover_url": {
"type": "keyword",
"index": false
},
"description": {
"type": "text"
},
"public_date": {
"type": "date"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 100
}
}
}
}
}
}
GET books/_mapping
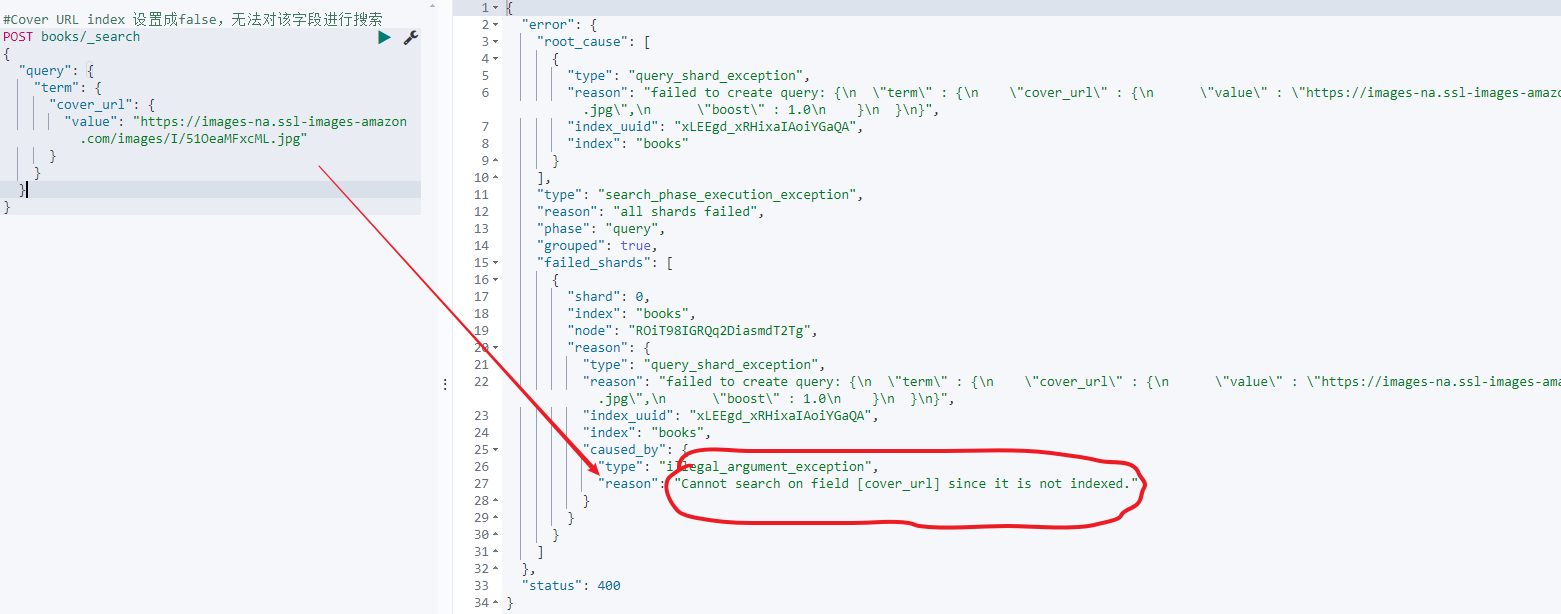
此时cover_url因为设置了index:false就不支持搜索了:
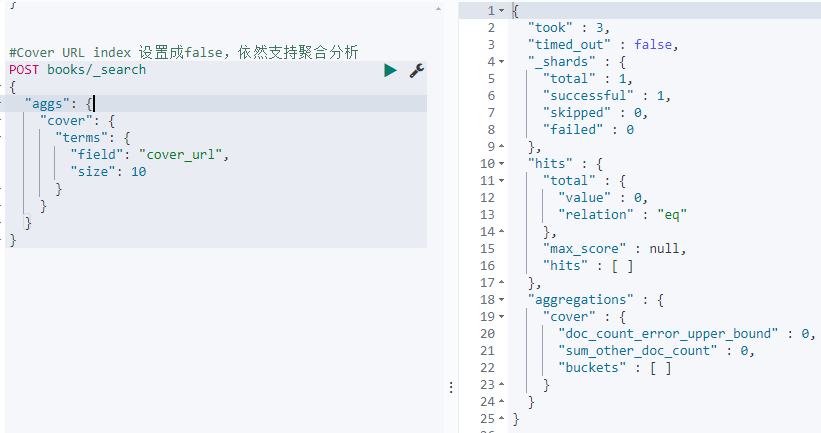
#Cover URL index 设置成false,无法对该字段进行搜索
POST books/_search
{
"query": {
"term": {
"cover_url": {
"value": "https://images-na.ssl-images-amazon.com/images/I/51OeaMFxcML.jpg"
}
}
}
}
但依然是支持聚合的:
#Cover URL index 设置成false,依然支持聚合分析
POST books/_search
{
"aggs": {
"cover": {
"terms": {
"field": "cover_url",
"size": 10
}
}
}
}
假定需求发生变更,要求将文章的内容存储在content字段中,并且不需要做更新和reindex。
考虑到content内容比较大,所以如果放在_source中返回的话会占用比较多的网络带宽资源,并且数据查询到额速度也会降低,所以为了解决这个问题,我们可以考虑如下的两种方案:
1:source filtering不返回数据,特别是content
2:设置enabled:false,并设置字段store:true
其中对于1:source_fitering 只是在返回给客户端时不返回,在汇总数据时还是返回的,如下图:
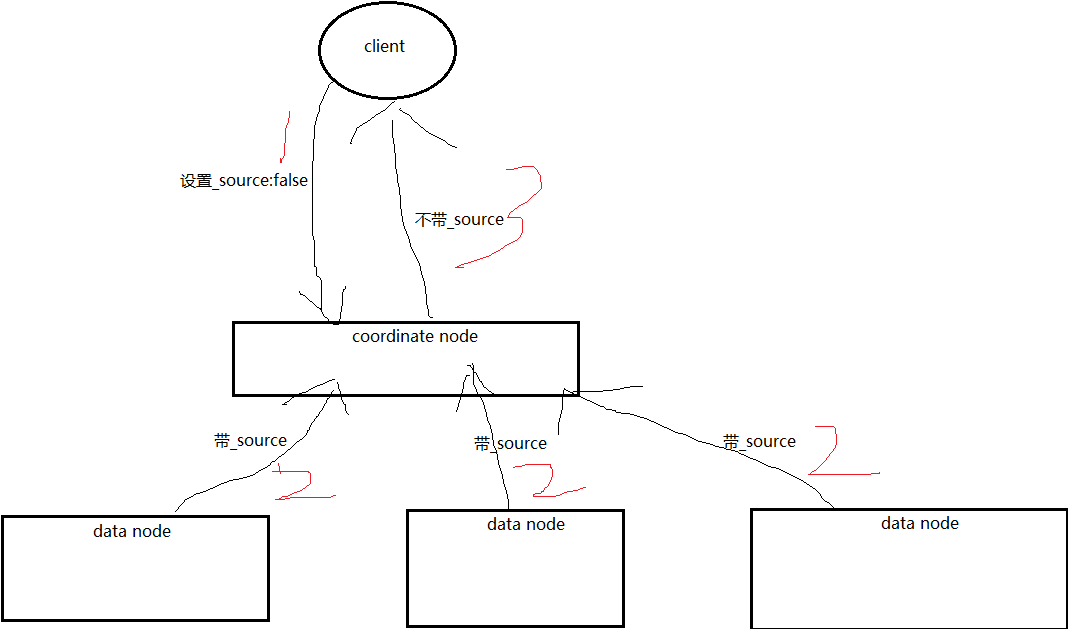
所以对于这个需求我们需要通过2设置enabled:false来解决。
如下在mapping中显式设置enabled:false:
DELETE books
#新增 Content字段。数据量很大。选择将Source 关闭
PUT books
{
"mappings": {
"_source": {
"enabled": false
},
"properties": {
"author": {
"type": "keyword",
"store": true
},
"cover_url": {
"type": "keyword",
"index": false,
"store": true
},
"description": {
"type": "text",
"store": true
},
"content": {
"type": "text",
"store": true
},
"public_date": {
"type": "date",
"store": true
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 100
}
},
"store": true
}
}
}
}
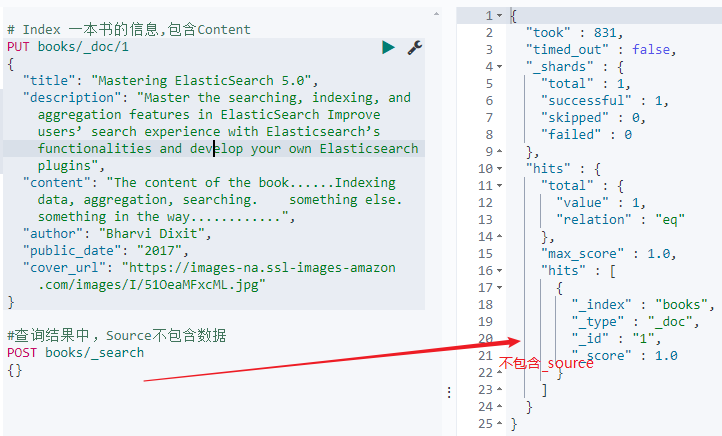
插入数据:
# Index 一本书的信息,包含Content
PUT books/_doc/1
{
"title": "Mastering ElasticSearch 5.0",
"description": "Master the searching, indexing, and aggregation features in ElasticSearch Improve users’ search experience with Elasticsearch’s functionalities and develop your own Elasticsearch plugins",
"content": "The content of the book......Indexing data, aggregation, searching. something else. something in the way............",
"author": "Bharvi Dixit",
"public_date": "2017",
"cover_url": "https://images-na.ssl-images-amazon.com/images/I/51OeaMFxcML.jpg"
}
#查询结果中,Source不包含数据
POST books/_search
{}
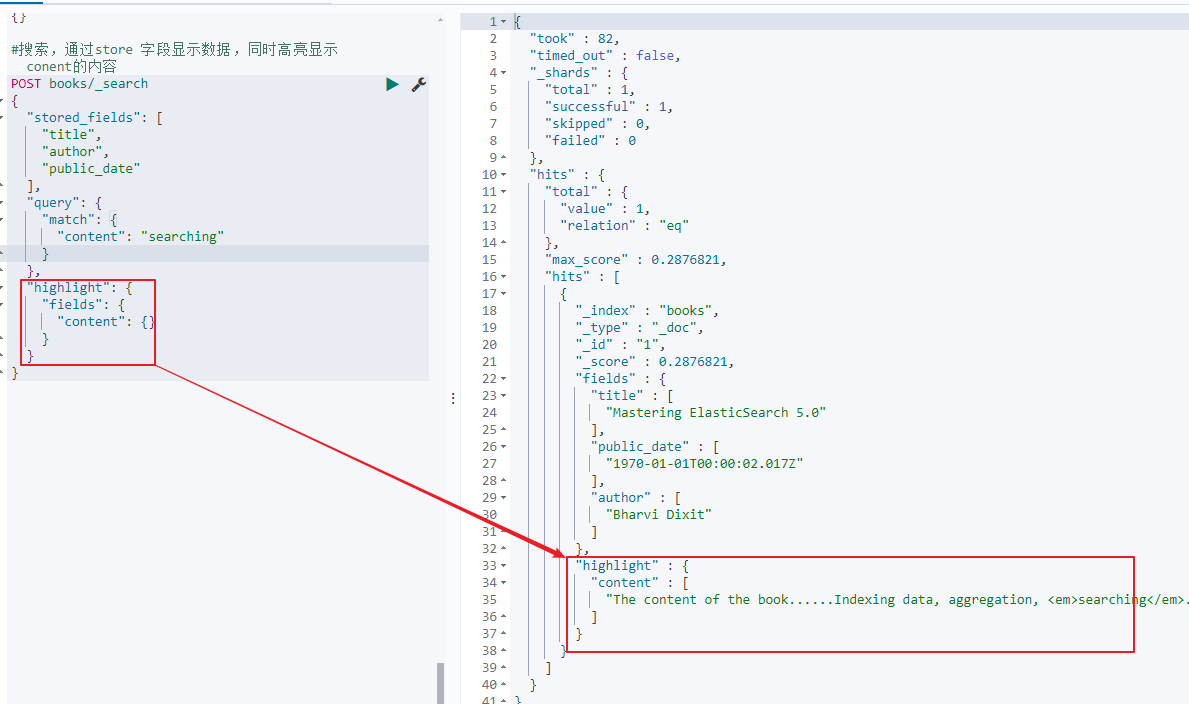
但依然可以查询和高亮,因为store:true所以会存储字段的原始值(但是enabled:false所以原始文档是不存储的,即_source是没有信息的):
#搜索,通过store 字段显示数据,同时高亮显示 conent的内容
POST books/_search
{
"stored_fields": [
"title",
"author",
"public_date"
],
"query": {
"match": {
"content": "searching"
}
},
"highlight": {
"fields": {
"content": {}
}
}
}
写在后面
参考文章列表
source filtering 。