于高山之巅,方见大河奔涌;于群峰之上,便觉长风浩荡
—— 24.3.22
一、数据挖掘和机器学习的定义
1.数据挖掘的狭义定义
背景:大数据时代——知识贫乏
数据挖掘的狭义定义:
数据挖掘就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但是又潜在有用的信息或知识的过程
数据源必须是真实的、大量的、含噪声的
发现的是用户感兴趣的知识
发现的知识要可接受、可理解、可运用
并不要求发现放之四海而皆准地知识,仅支持特定的发现问题即可
从知识发现过程来看:可以把数据挖掘视为知识发现过程中的一个基本步骤,也就是数据分析环节
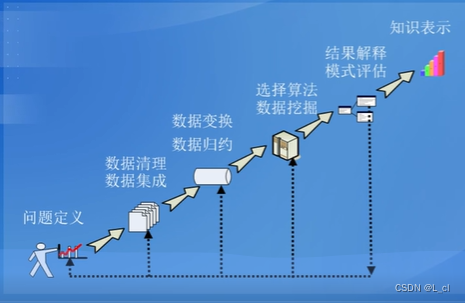
2.⭐Fayyad数据挖掘过程主要包含七个阶段:
①数据清理
②数据集成
③数据选择
④数据变换
⑤数据挖掘
⑥模式评估
⑦知识表示
3.数据挖掘和机器学习的定义
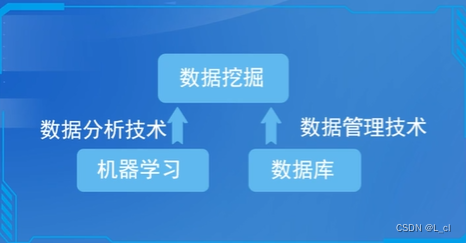
数据挖掘是一种深层次地数据分析方法,需要对涉及到地海量数据进行管理与分析
数据库领域的研究为数据挖掘提供数据管理技术,对于利用计算机对历史数据的分析,就是误码通常所说的机器学习
机器学习的定义:
机器学习是利用经验来改善计算机系统自身的性能,机器学习需要:
①通过数据分析建立模型
②利用算法对模型进行优化
③使计算机不断模拟人的学习行为来获取新的知识和技能,不断改善性能从而实现自我完善
机器学习方法构成地三元素:
①模型 ②策略 ③算法
可简单表示为:机器学习 = 模型+策略 + 算法
模型是从数据中抽象用来描述客观世界的数学模型
机器学习的根本目的是构建一个模型来描述历史的数据规律,通过这个模型对未来进行预测
策略是选择模型的标准
假设空间往往包括多个模型,策略来确定哪一个模型是最好的
算法是指学习模型的具体计算方法,即在确定寻找最优模型的策略后,机器学习的问题归结于最优化问题,其优化算法是指求解模型参数最优解的算法
4.数据挖掘和机器学习、数据库的关系:
利用数据库提供的技术来管理海量数据,利用机器学习方法来分析挖掘数据背后的知识
数据挖掘注重运用算法或其他某种模式解决实际问题,偏实践和应用
机器学习注重相关机器学习算法的理论研究和算法优化,为数据挖掘提供了理论方法,偏理论和学术
数据挖掘技术是机器学习技术的一个实际应用
广义上来看,同属于知识发现的范畴,只是侧重点不同
相关术语:
①人工智能AI是一个大的领域概念
②机器学习是人工智能的一个重要领域
③统计学主要是利用机器学习来对数据挖掘产生影响
④机器学习和数据库是数据挖掘两大支撑技术
⑤模式识别是机器学习的一个工程应用
⑥机器学习可以从数据中实现系统的构建,而模式识别是对数据中模式和规律性的识别
⑦神经网络是机器学习中一个重要的方法,深度学习就是多层次的神经网络,是神经网络的高级阶段

5.习题
1.

2.

3.

4.

5.

6.

二、机器学习过程及其发展历程
1.机器学习基本过程
①第一步 数据集准备:机器学习是数据贪婪的,数据采集是最基础、最重要的一步,从不同的数据源收集数据,数据集是构建机器学习模型的起点。
②第二步 数据预处理:数据预处理是指对数据进行清洗、归约或转换等。通过对数据进行各种检查和校正以纠正缺失值、异常、标准化等问题。通过预处理将数据结构化以便满足模型训练的需要。第一和第二步属于机器学习初级阶段
③第三步模型选择:根据具体任务特定问题的要求,选择合适的模型,根据机器学习模型对于训练数据处理方式的不同,机器学习算法可以大致可分为:监督学习、无监督学习和强化学习等。④第四步模型训练:机器学习过程的核心是模型训练通过训练历史经验数据,对选择的模型的参数进行不断优化,最小化模型预测带来的误差。
第三和第四部属于机器学习中级阶段。
⑤第五步模型评估优化:在训练好模型之后,利用在数据预处理中准备好的测试数据集对模型进行测试。对模型评估结束后,还可以通过调参对训练过程进行优化。
⑥第六步应用预测:使用完全训练好的模型在新数据上做预测,这是机器学习过程的最后一步,在此阶段默认该模型已准备就绪,可以用于实际应用。
第五和第六步属于机器学习高级阶段,实现智能的目标。
2.机器学习的发展历程
数据挖掘与机器学习的本质是一样的
区别:
①数据挖掘更接近于数据端
②机器学习更接近于智能端
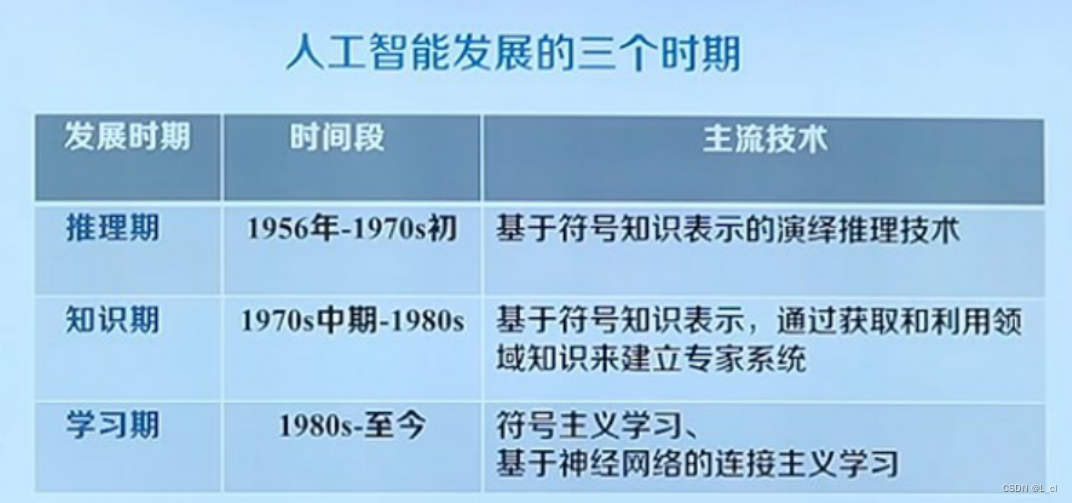
人工智能发展的三个时期:

3.习题
1.

2.

3.

4.
5.

6.
三、机器学习算法及数据隐私权
1.机器学习算法分类
我们通过系统的反馈方法的不同,将机器学习算法分为:无监督学习、有监督学习、强化学习
数据集的相关定义:
训练集、验证集、测试集
①训练集
训练集也称为样本数据集,是用于训练构造模型的数据集,通过设置模型参数、训练模型、建立机器学习模型
训练集由数据对象组成,每个对象所属类别已知,在构造模型时,需要输入一定数量的训练集,选取的训练集是否合适直接影响到分类器性能的好坏
②验证集
训练集训练出的多个模型对验证集数据进行预测,并记录模型准确率,从而选出效果最佳的模型所对应的参数,也就是说验证集用来调整模型参数。当模型无需人为设定超参数,所有参数都通过学习得到时就不需要验证集
③测试集
用于测试基于训练集构造的模型的性能。在模型产生后,由模型判定测试集对象的所属类别与测试集已知的所属类别进行比较,得出分类器的正确率等一系列评价性能指标。


2.机器学习的三类方法
①无监督学习:
无监督学习也叫无导师学习,实际应用中,在无法预先知道样本标签的情况下,训练数据类别未知,需要根据样本间的相似性对样本集进行划分,使类内的距离最小化,类间的距离最大化。无监督学习常见包括聚类、降维和关联规则等。
聚类是基于样本间的相似性来对样本进行划分,常见的聚类算法有:
习题
1.