Elasticsearch从入门到精通-06ES统计分析语法
bucket和metric概念简介
bucket就是一个聚合搜索时的数据分组。如:销售部门有员工张三和李四,开发部门有员工王五和赵六。那么根据部门分组聚合得到结果就是两个bucket。销售部门bucket中有张三和李四,开发部门 bucket中有王五和赵六。metric就是对一个bucket数据执行的统计分析。如上述案例中,开发部门有2个员工,销售部门有2个员工,这就是metric。metric有多种统计,如:求和,最大值,最小值,平均值等。
用一个大家容易理解的SQL语法来解释,如:select count() from table group by column。那么group by column分组后的每组数据就是bucket。对每个分组执行的count()就是metric。
数据准备:
PUT /cars
{
"mappings": {
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"model": {
"type": "keyword"
},
"sold_date": {
"type": "date"
},
"remark": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
POST /cars/_bulk
{"index":{}}
{"price":258000,"color":"金色","brand":"大众","model":"大众迈腾","sold_date":"2021-10-28","remark":"大众中档车"}
{"index":{}}
{"price":123000,"color":"金色","brand":"大众","model":"大众速腾","sold_date":"2021-11-05","remark":"大众神车"}
{"index":{}}
{"price":239800,"color":"白色","brand":"标志","model":"标志508","sold_date":"2021-05-18","remark":"标志品牌全球上市车型"}
{"index":{}}
{"price":148800,"color":"白色","brand":"标志","model":"标志408","sold_date":"2021-07-02","remark":"比较大的紧凑型车"}
{"index":{}}
{"price":1998000,"color":"黑色","brand":"大众","model":"大众辉腾","sold_date":"2021-08-19","remark":"大众最让人肝疼的车"}
{"index":{}}
{"price":218000,"color":"红色","brand":"奥迪","model":"奥迪A4","sold_date":"2021-11-05","remark":"小资车型"}
{"index":{}}
{"price":489000,"color":"黑色","brand":"奥迪","model":"奥迪A6","sold_date":"2022-01-01","remark":"政府专用?"}
{"index":{}}
{"price":1899000,"color":"黑色","brand":"奥迪","model":"奥迪A 8","sold_date":"2022-02-12","remark":"很贵的大A6。。。"}
案例1:根据color分组统计销售数量
只执行聚合分组,不做复杂的聚合统计。在ES中最基础的聚合为terms,相当于SQL中的count。在ES中默认为分组数据做排序,使用的是doc_count数据执行降序排列。可以使用_key元数据,根据分组后的字段数据执行不同的排序方案,也可以根据_count元数据,根据分组后的统计值执行不同的排序方案。
size:0 代表不显示元数据,只显示聚合结果
GET /cars/_search
{
"size":0, //只显示聚合结果
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"_count": "desc"
}
}
}
}
}
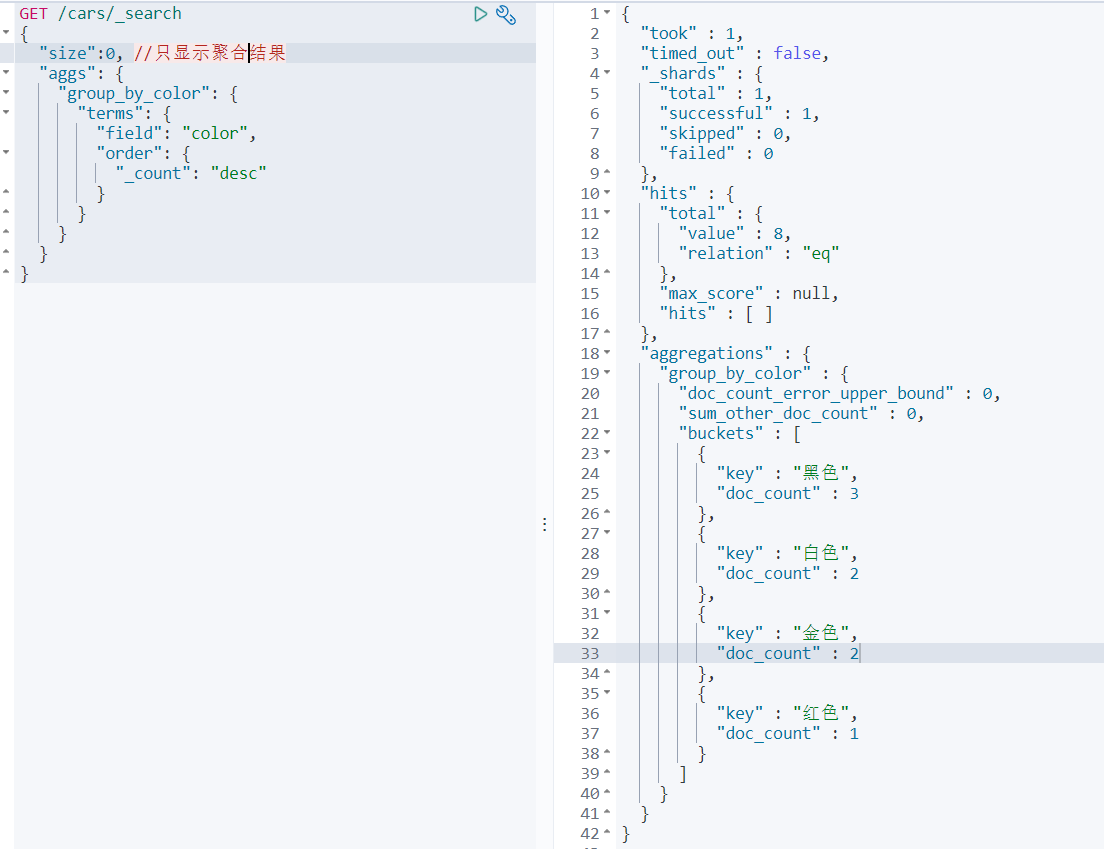
案例2:统计不同颜色车辆的平均价格
本案例先根据color执行聚合分组,在此分组的基础上,对组内数据执行聚合统计,这个组内数据的聚合统计就是metric。同样可以执行排序,因为组内有聚合统计,且对统计数据给予了命名avg_by_price,所以可以根据这个聚合统计数据字段名执行排序逻辑。
GET /cars/_search
{
"size":0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price": "asc"
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}

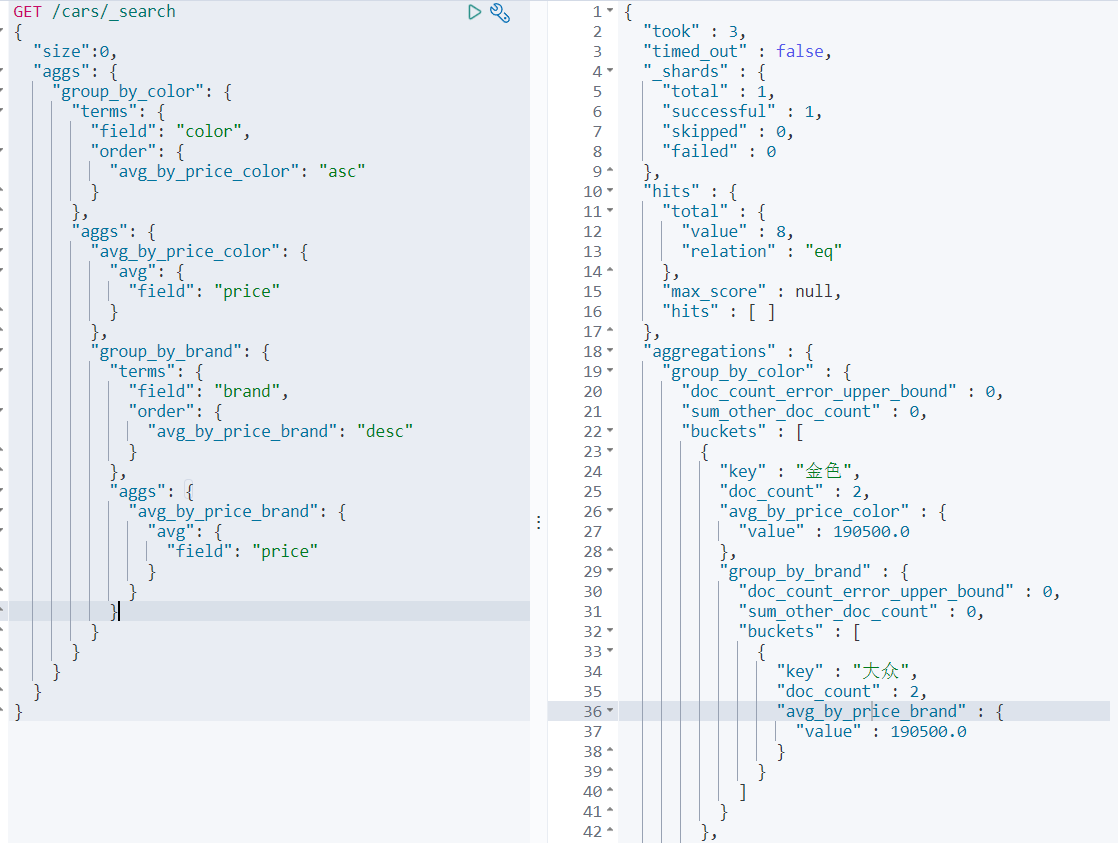
案例3:统计不同color不同brand中车辆的平均价格
先根据color聚合分组,在组内根据brand再次聚合分组,这种操作可以称为下钻分析。Aggs如果定义比较多,则会感觉语法格式混乱,aggs语法格式,有一个相对固定的结构,简单定义:aggs可以嵌套定义,可以水平定义。嵌套定义称为下钻分析。水平定义就是平铺多个分组方式。
GET /cars/_search
{
"size":0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"avg_by_price_color": "asc"
}
},
"aggs": {
"avg_by_price_color": {
"avg": {
"field": "price"
}
},
"group_by_brand": {
"terms": {
"field": "brand",
"order": {
"avg_by_price_brand": "desc"
}
},
"aggs": {
"avg_by_price_brand": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
案例4:统计不同color中的最大和最小价格、总价
GET /cars/_search
{
"size":0,
"aggs": {
"group_by_color": {
"terms": {
"field": "color"
},
"aggs": {
"max_price": {
"max": {
"field": "price"
}
},
"min_price": {
"min": {
"field": "price"
}
},
"sum_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
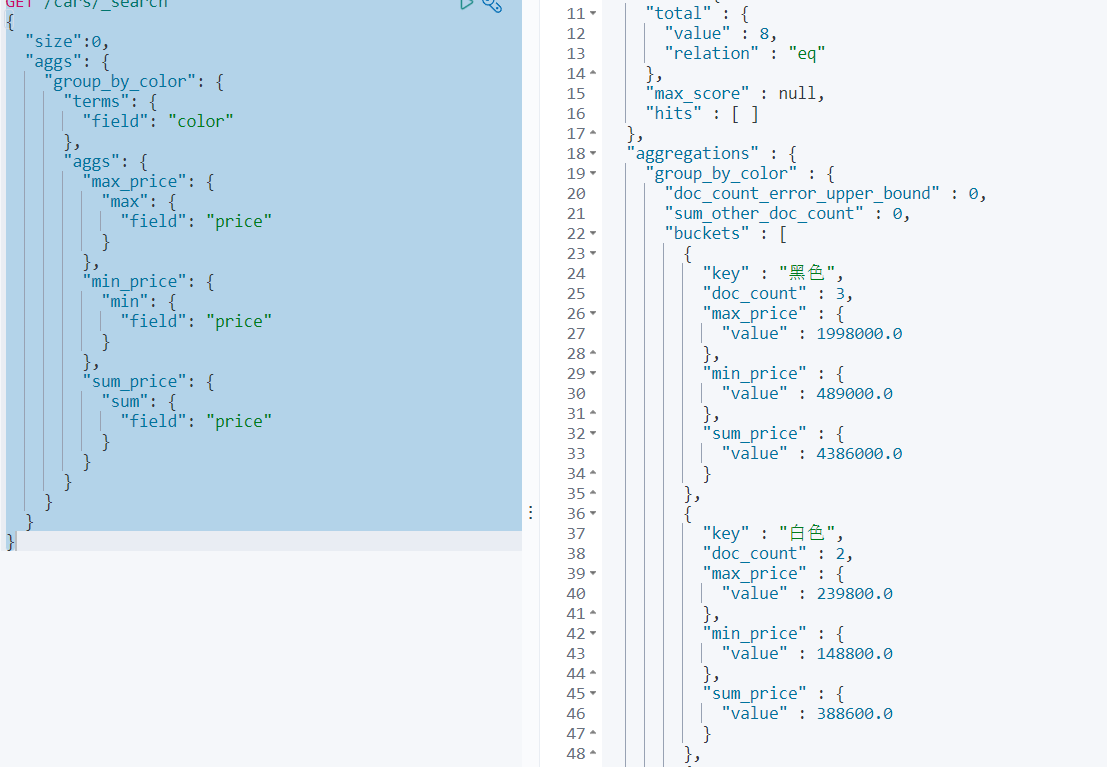
在常见的业务常见中,聚合分析,最常用的种类就是统计数量,最大,最小,平均,总计等。通常占有聚合业务中的60%以上的比例,小型项目中,甚至占比85%以上。
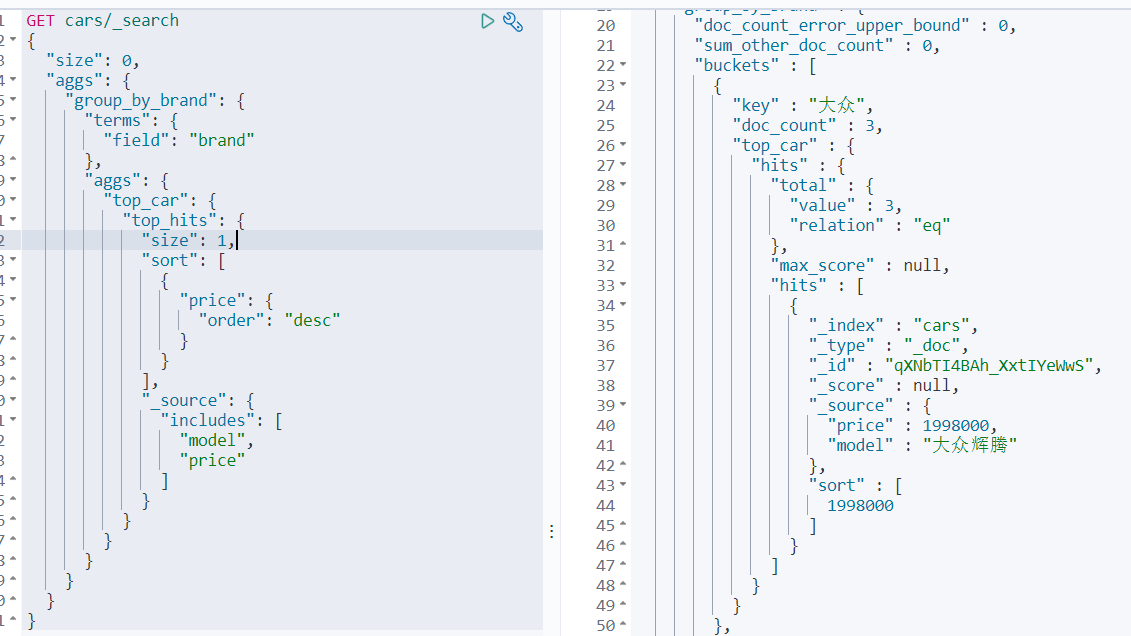
案例5:统计不同品牌汽车中价格排名最高的车型
在分组后,可能需要对组内的数据进行排序,并选择其中排名高的数据。那么可以使用size来实现:top_hits中的属性size代表取组内多少条数据(默认为10);sort代表组内使用什么字段什么规则排序(默认使用_doc的asc规则排序);_source代表结果中包含document中的那些字段(默认包含全部字段)。
GET cars/_search
{
"size": 0,
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"top_car": {
"top_hits": {
"size": 1,
"sort": [
{
"price": {
"order": "desc"
}
}
],
"_source": {
"includes": [
"model",
"price"
]
}
}
}
}
}
}
}
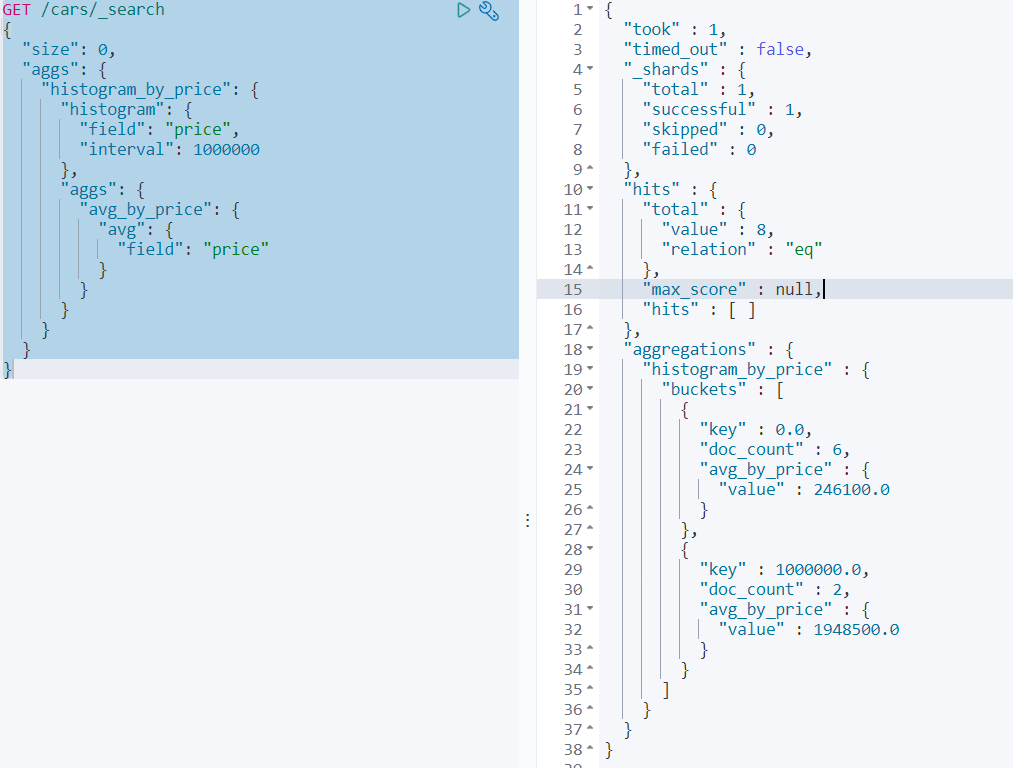
案例6:histogram区间统计
histogram类似terms,也是进行bucket分组操作的,是根据一个field,实现数据区间分组。如:以100万为一个范围,统计不同范围内车辆的销售量和平均价格。那么使用histogram的聚合的时候,field指定价格字段price。区间范围是100万,这个时候ES会将price价格区间划分为: [0, 1000000), [1000000, 2000000), [2000000, 3000000)等,依次类推。在划分区间的同时,histogram会类似terms进行数据数量的统计(count),可以通过嵌套aggs对聚合分组后的组内数据做再次聚合分析。
GET /cars/_search
{
"size": 0,
"aggs": {
"histogram_by_price": {
"histogram": {
"field": "price",
"interval": 1000000
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
案例7:date_histogram区间分组
date_histogram可以对date类型的field执行区间聚合分组,如每月销量,每年销量等。如:以月为单位,统计不同月份汽车的销售数量及销售总金额。这个时候可以使用date_histogram实现聚合分组,其中field来指定用于聚合分组的字段,interval指定区间范围(可选值有:year、quarter、month、week、day、hour、minute、second),format指定日期格式化,min_doc_count指定每个区间的最少document(如果不指定,默认为0,当区间范围内没有document时,也会显示bucket分组),extended_bounds指定起始时间和结束时间(如果不指定,默认使用字段中日期最小值所在范围和最大值所在范围为起始和结束时间)。
GET /cars/_search
{
"size": 0,
"aggs": {
"histogram_by_date": {
"date_histogram": {
"field": "sold_date",
"calendar_interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count": 1,
"extended_bounds": {
"min": "2021-01-01",
"max": "2022-12-31"
}
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}

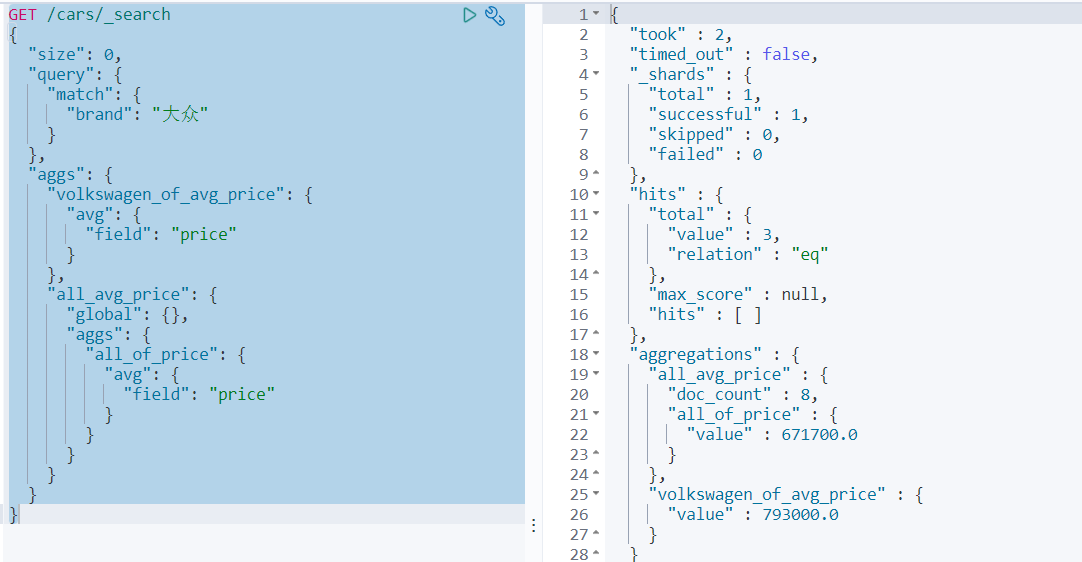
案例8:_global bucket
在聚合统计数据的时候,有些时候需要对比部分数据和总体数据。如:统计某品牌车辆平均价格和所有车辆平均价格。global是用于定义一个全局bucket,这个bucket会忽略query的条件,检索所有document进行对应的聚合统计。
GET /cars/_search
{
"size": 0,
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"volkswagen_of_avg_price": {
"avg": {
"field": "price"
}
},
"all_avg_price": {
"global": {},
"aggs": {
"all_of_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
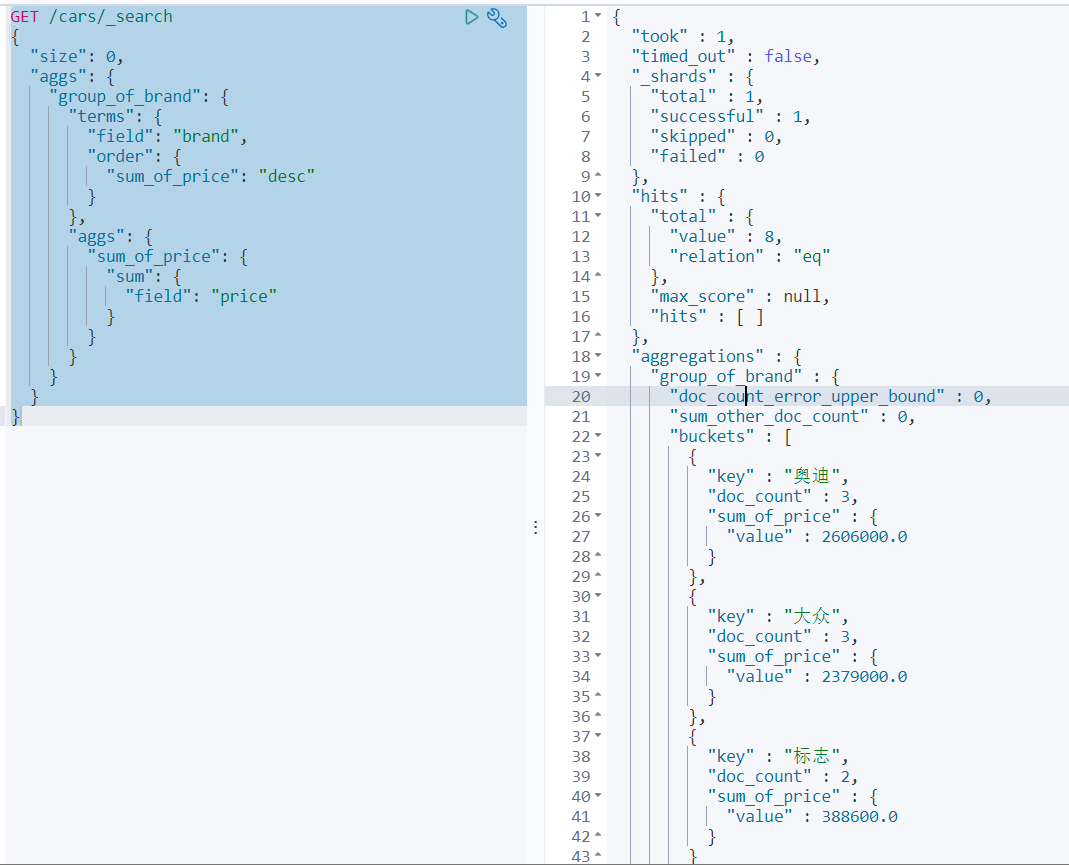
案例9:aggs+order
对聚合统计数据进行排序。如:统计每个品牌的汽车销量和销售总额,按照销售总额的降序排列。
GET /cars/_search
{
"size": 0,
"aggs": {
"group_of_brand": {
"terms": {
"field": "brand",
"order": {
"sum_of_price": "desc"
}
},
"aggs": {
"sum_of_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
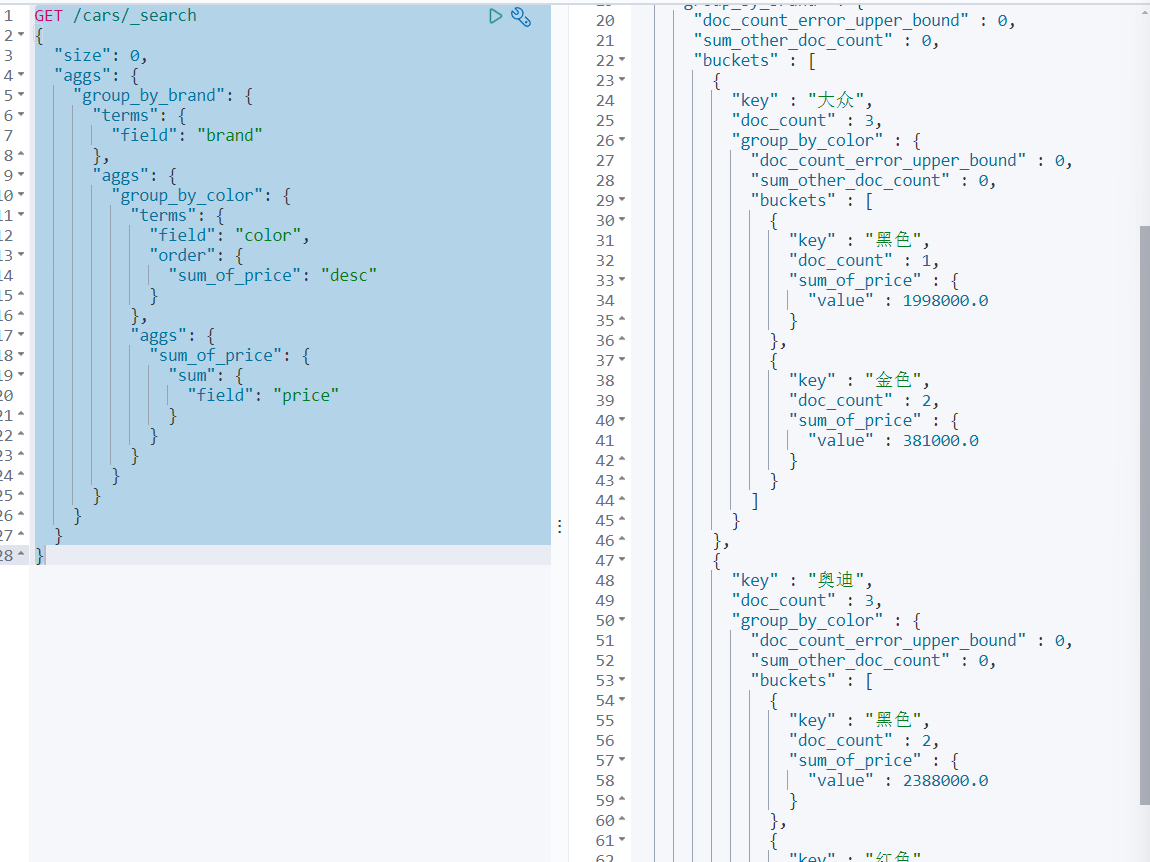
如果有多层aggs,执行下钻聚合的时候,也可以根据最内层聚合数据执行排序。如:统计每个品牌中每种颜色车辆的销售总额,并根据销售总额降序排列。这就像SQL中的分组排序一样,只能组内数据排序,而不能跨组实现排序。
GET /cars/_search
{
"size": 0,
"aggs": {
"group_by_brand": {
"terms": {
"field": "brand"
},
"aggs": {
"group_by_color": {
"terms": {
"field": "color",
"order": {
"sum_of_price": "desc"
}
},
"aggs": {
"sum_of_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
}
}
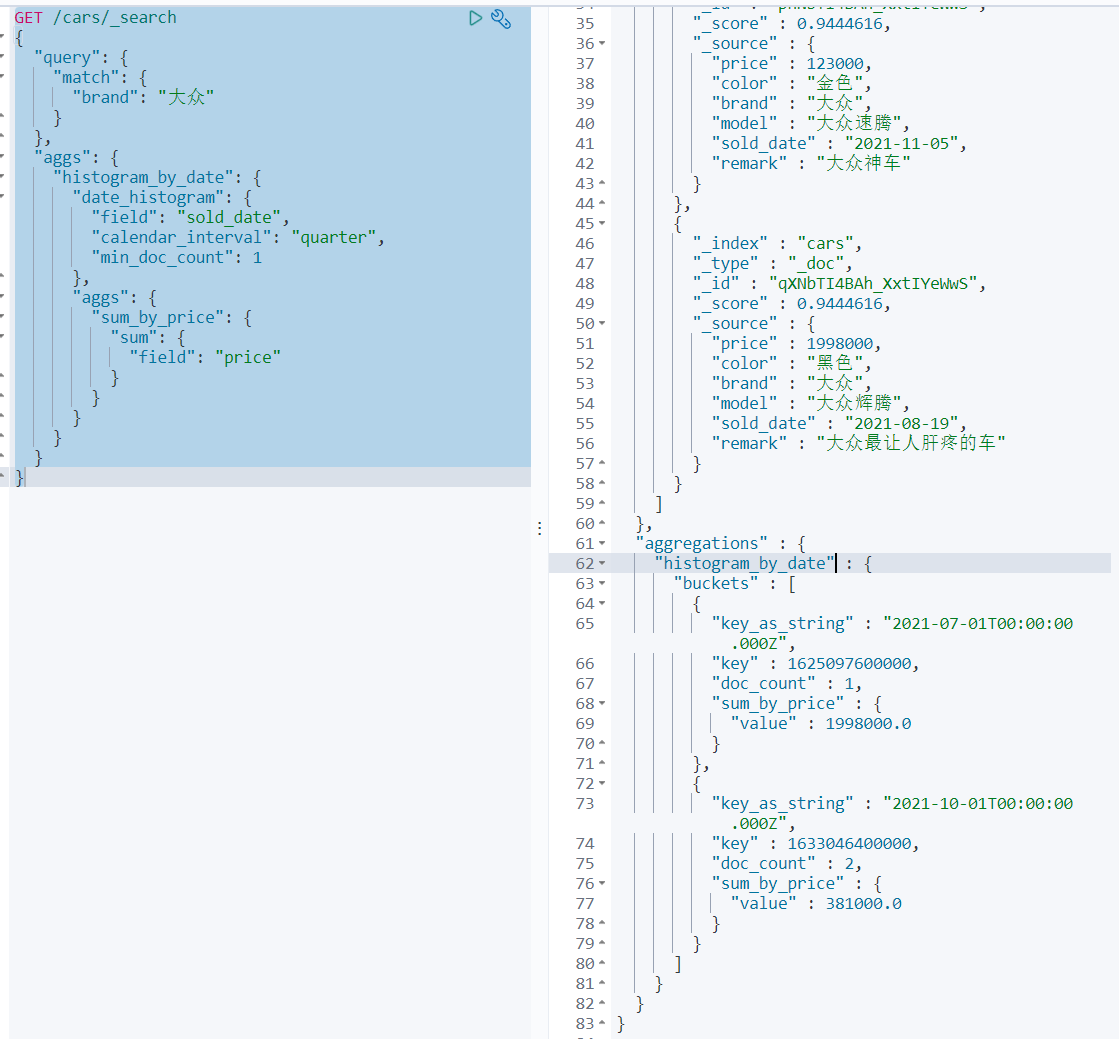
案例10:search+aggs
聚合类似SQL中的group by子句,search类似SQL中的where子句。在ES中是完全可以将search和aggregations整合起来,执行相对更复杂的搜索统计。如:统计某品牌车辆每个季度的销量和销售额。
GET /cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"histogram_by_date": {
"date_histogram": {
"field": "sold_date",
"calendar_interval": "quarter",
"min_doc_count": 1
},
"aggs": {
"sum_by_price": {
"sum": {
"field": "price"
}
}
}
}
}
}
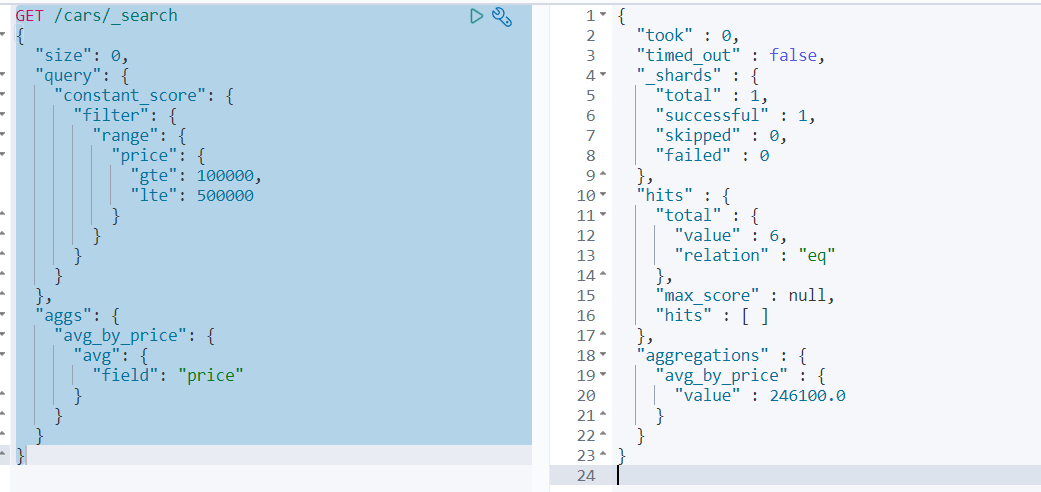
案例11:filter+aggs
在ES中,filter也可以和aggs组合使用,实现相对复杂的过滤聚合分析。如:统计10万~50万之间的车辆的平均价格。
GET /cars/_search
{
"size": 0,
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 100000,
"lte": 500000
}
}
}
}
},
"aggs": {
"avg_by_price": {
"avg": {
"field": "price"
}
}
}
}
案例12:聚合中使用filter
filter也可以使用在aggs句法中,filter的范围决定了其过滤的范围。如:统计某品牌汽车最近一年的销售总额。将filter放在aggs内部,代表这个过滤器只对query搜索得到的结果执行filter过滤。如果filter放在aggs外部,过滤器则会过滤所有的数据。
GET /cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"count_last_year": {
"filter": {
"range": {
"sold_date": {
"gte": "now-12y"
}
}
},
"aggs": {
"sum_of_price_last_year": {
"sum": {
"field": "price"
}
}
}
}
}
}
ggs内部,代表这个过滤器只对query搜索得到的结果执行filter过滤。如果filter放在aggs外部,过滤器则会过滤所有的数据。
GET /cars/_search
{
"query": {
"match": {
"brand": "大众"
}
},
"aggs": {
"count_last_year": {
"filter": {
"range": {
"sold_date": {
"gte": "now-12y"
}
}
},
"aggs": {
"sum_of_price_last_year": {
"sum": {
"field": "price"
}
}
}
}
}
}