Transformer
- 1、引言
- 2、Transformer
- 2.1 定义
- 2.2 原理
- 2.3 算法公式
- 2.3.1 自注意力机制
- 2.3.1 多头自注意力机制
- 2.3.1 位置编码
- 2.4 代码示例
- 3、总结
1、引言
小屌丝:鱼哥, 你说transformer是个啥?
小鱼:嗯… 啊… 嗯…就是…
小屌丝:你倒是说啊,是个啥?
小鱼:你不知道?
小屌丝:我知道啊,
小鱼:你知道,你还问我?
小屌丝:考考你
小鱼:kao…kao… wo??
小屌丝:对
小鱼:看你你很懂 transformer
小屌丝: 必须的
小鱼:那你来跟我说一说?
小屌丝:可以。
小鱼:秃头顶上点灯
小屌丝:啥意思? 你说的是啥意思?你说清楚,啥意思???

小鱼:唉~ ~没文化,真可怕。
2、Transformer
2.1 定义
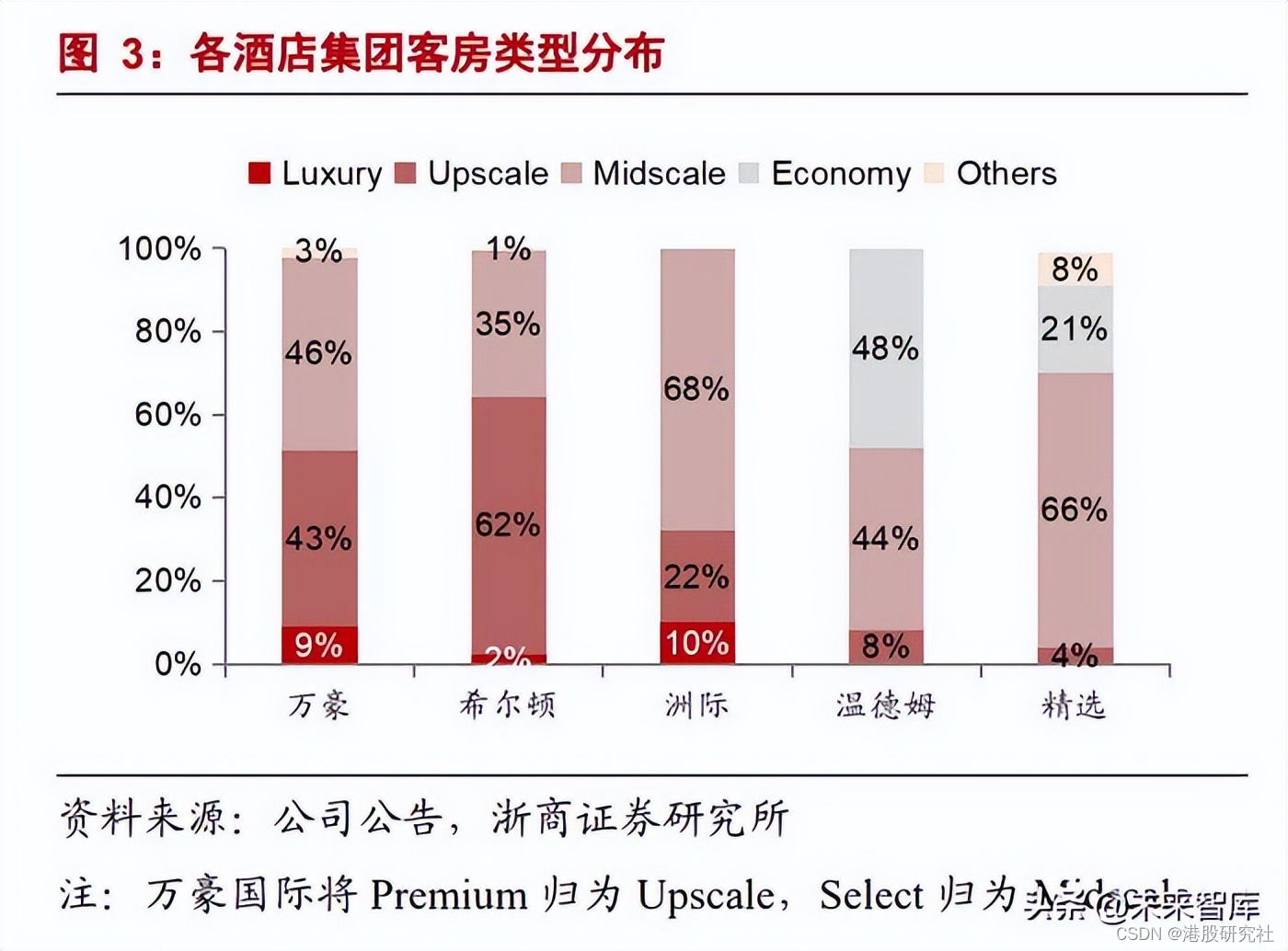
Transformer是一种基于自注意力机制的深度学习模型,它完全摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构,转而通过自注意力机制来计算输入序列中不同位置之间的依赖关系。
Transformer模型由谷歌在2017年提出,并在自然语言处理领域取得了显著的成绩,如机器翻译、文本生成、问答系统等。
2.2 原理
Transformer的核心思想是利用自注意力机制来捕捉输入序列中的上下文信息。
它采用Encoder-Decoder架构,其中Encoder负责将输入序列编码为一系列的隐藏状态,而Decoder则根据这些隐藏状态生成输出序列。
在Transformer中,自注意力机制是通过计算输入序列中每个位置与其他位置之间的相似度来实现的。
具体来说,对于输入序列中的每个位置,Transformer会生成一个查询向量、一个键向量和一个值向量。然后,它会计算查询向量与所有键向量之间的相似度,得到一个相似度分数矩阵。
最后,根据这个相似度分数矩阵对值向量进行加权求和,得到每个位置的输出表示。
2.3 算法公式
2.3.1 自注意力机制
自注意力机制
- 输入:查询矩阵Q、键矩阵K、值矩阵V
- 输出:自注意力输出Z
- 公式: Z = s o f t m a x ( Q K T / √ d k ) V Z = softmax(QK^T/√d_k)V Z=softmax(QKT/√dk)V
其中,d_k是键向量的维度,用于缩放点积结果以防止梯度消失。
2.3.1 多头自注意力机制
多头自注意力机制
- 输入:查询矩阵Q、键矩阵K、值矩阵V、头数h
- 输出:多头自注意力输出MultiHead(Q, K, V)
- 公式: M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中,每个头head_i都执行一次自注意力机制,W^O是输出线性变换的权重矩阵。
2.3.1 位置编码
位置编码
为了捕捉序列中的位置信息,Transformer使用位置编码将位置信息嵌入到输入向量中。
公式: P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 ( 2 i / D ) ) P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 ( 2 i / D ) ) PE(pos, 2i) = sin(pos / 10000^(2i / D)) PE(pos, 2i+1) = cos(pos / 10000^(2i / D)) PE(pos,2i)=sin(pos/10000(2i/D))PE(pos,2i+1)=cos(pos/10000(2i/D))
其中, p o s pos pos是位置索引, i i i是维度索引, D D D是输入向量的维度。
2.4 代码示例
# -*- coding:utf-8 -*-
# @Time : 2024-03-17
# @Author : Carl_DJ
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义位置编码类
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 计算位置编码
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
-(np.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
# 定义Transformer编码器层
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1):
super(TransformerEncoderLayer, self).__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, src, src_mask=None, src_key_padding_mask=None):
# 自注意力机制
src2, attn = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)
src = src + self.dropout1(src2)
src = self.norm1(src)
# 前馈神经网络
src2 = self.linear2(self.dropout(F.relu(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src, attn
# 定义Transformer编码器
class TransformerEncoder(nn.Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layers = nn.ModuleList([encoder_layer for _ in range(num_layers)])
self.num_layers = num_layers
self.norm = norm
def forward(self, src, mask=None, src_key_padding_mask=None):
output = src
# 堆叠多个编码器层
for mod in self.layers:
output, attn = mod(output, mask, src_key_padding_mask)
if self.norm:
output = self.norm(output)
return output
# 定义完整的Transformer模型
class TransformerModel(nn.Module):
def __init__(self, src_vocab_size, d_model, nhead, num_encoder_layers, dim_feedforward, max_position_embeddings):
super(TransformerModel, self).__init__()
self.src_mask = None
self.position_enc = PositionalEncoding(d_model, max_position_embeddings)
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout=0.1)
encoder_norm = nn.LayerNorm(d_model)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers, norm=encoder_norm)
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.d_model = d_model
def generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def forward(self, src, src_mask=None):
if src_mask is None:
device = src.device
bsz, seq_len = src.size()
src_mask = self.generate_square_subsequent_mask(seq_len).to(device)
src = self.src_embedding(src) * math.sqrt(self.d_model)
src = self.position_enc(src)
output = self.encoder(src, src_mask)
output = self.decoder(output)
return output
代码解析:
-
PositionalEncoding:定义位置编码类,用于给输入序列添加位置信息。Transformer模型是位置无关的,因此需要通过位置编码来提供序列中每个位置的信息。
-
TransformerEncoderLayer:定义Transformer编码器层,包含自注意力机制和前馈神经网络。每个编码器层都会接收输入序列,经过自注意力机制和前馈神经网络处理,输出新的序列表示。
-
TransformerEncoder:定义Transformer编码器,通过堆叠多个编码器层来构建更深的模型。
-
TransformerModel:定义完整的Transformer模型,包括嵌入层、位置编码、编码器和解码器。模型将源语言序列作为输入,经过一系列变换后,输出每个位置的目标语言词汇的预测概率。
-
generate_square_subsequent_mask:生成一个上三角矩阵的掩码,用于在自注意力机制中防止模型看到未来的信息。
-
forward:模型的前向传播函数。首先,将源语言序列通过嵌入层转换为向量表示,并乘以模型维度的平方根进行缩放。然后,将位置编码加到嵌入向量上。接下来,将结果输入到编码器中。最后,将编码器的输出传递给解码器,得到每个位置的预测概率。

3、总结
Transformer模型通过自注意力机制打破了传统RNN和CNN的局限性,能够更好地捕捉序列中的长期依赖关系,因此在自然语言处理任务中取得了显著的效果。
Transformer的Encoder-Decoder架构和多头自注意力机制使得模型能够同时处理输入序列中的多个位置,提高了模型的并行性和效率。通过位置编码,Transformer还能够处理序列中的位置信息,使得模型在处理自然语言等序列数据时更加灵活和准确。
虽然Transformer模型具有强大的能力,但它也需要大量的数据和计算资源来进行训练。
因此,在实际应用中,我们通常使用预训练的Transformer模型(如BERT、GPT等)作为基础,通过微调来适应特定的任务需求。
我是小鱼:
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)测评一、二等奖获得者;
关注小鱼,一起学习机器学习&深度学习领域的知识。