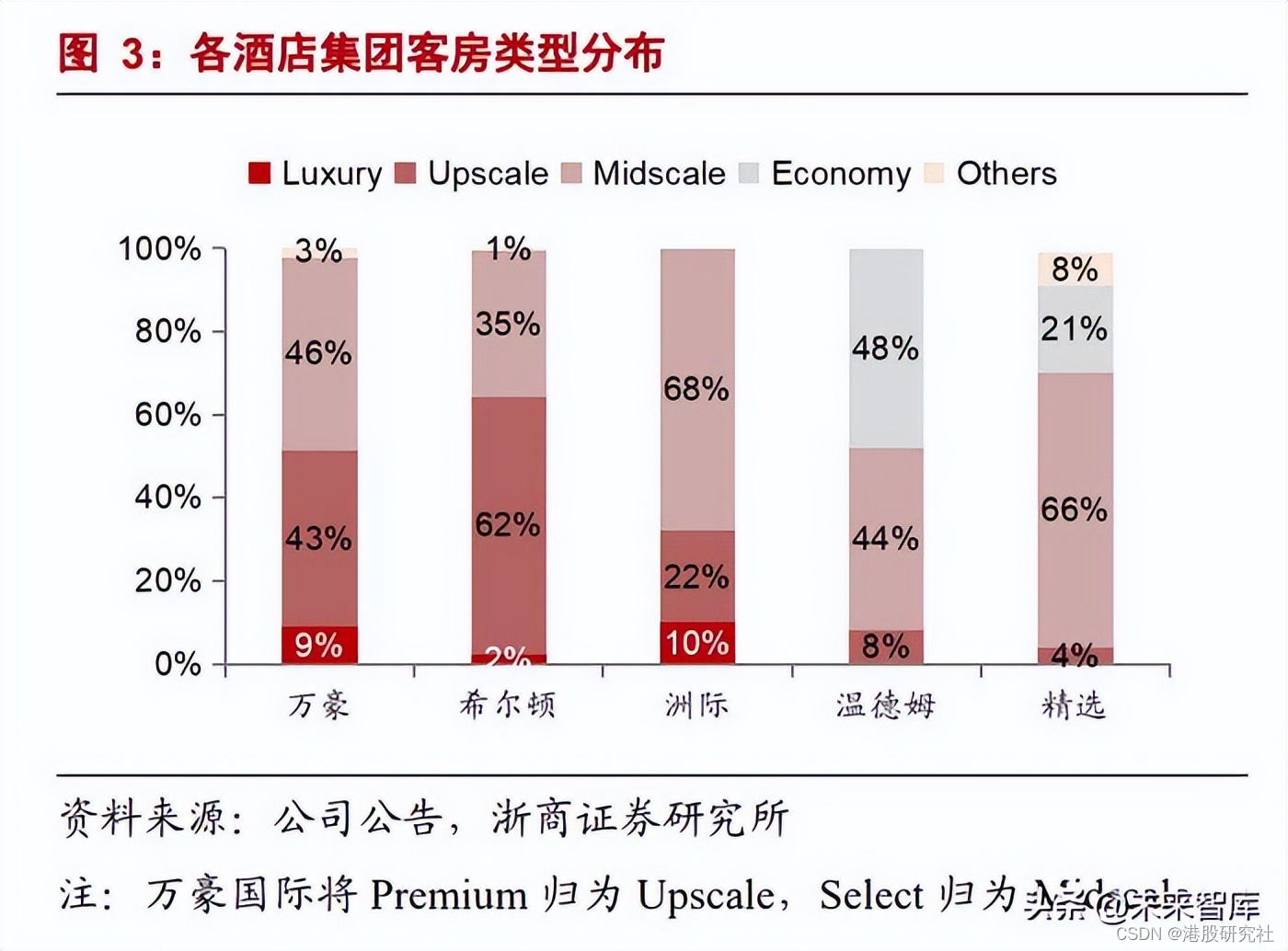
我本身有四台机器做WAS集群,挂载nfs,其中随机一台客户端计算机端口关闭释放将进入不良状态,对 NFSv4 挂载的任何访问都将挂起(例如“ls,cd 或者df均挂起”)。这意味着没有人并且所有需要访问共享的用户进程都会被卡住。
现象如下,df -h挂起,mount没反应,超时,

起初以为网络问题,开发所有网络和防火墙策略后,问题依旧,只有重启操作系统才能挂载,
通过抓包发现,这是正常数据包,正常握手通信,
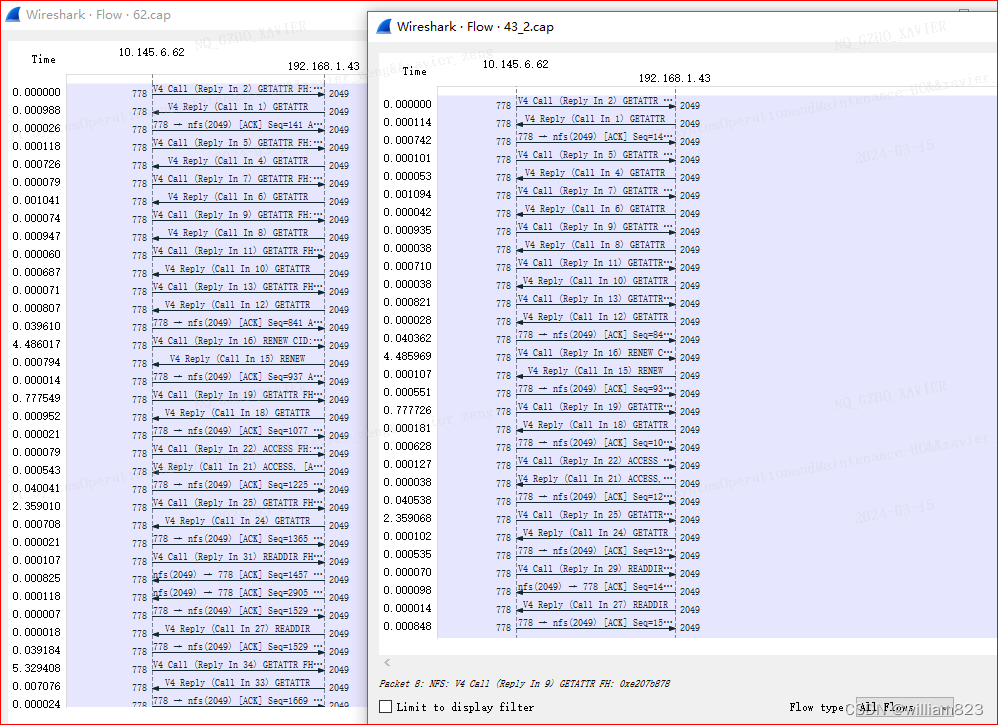
这是异常数据包,发现nfs server端响应数据包后客户端后,客户端显示没收到数据包,需要服务端重传,但是服务端已经发送了数据包,双方处于等待状态,
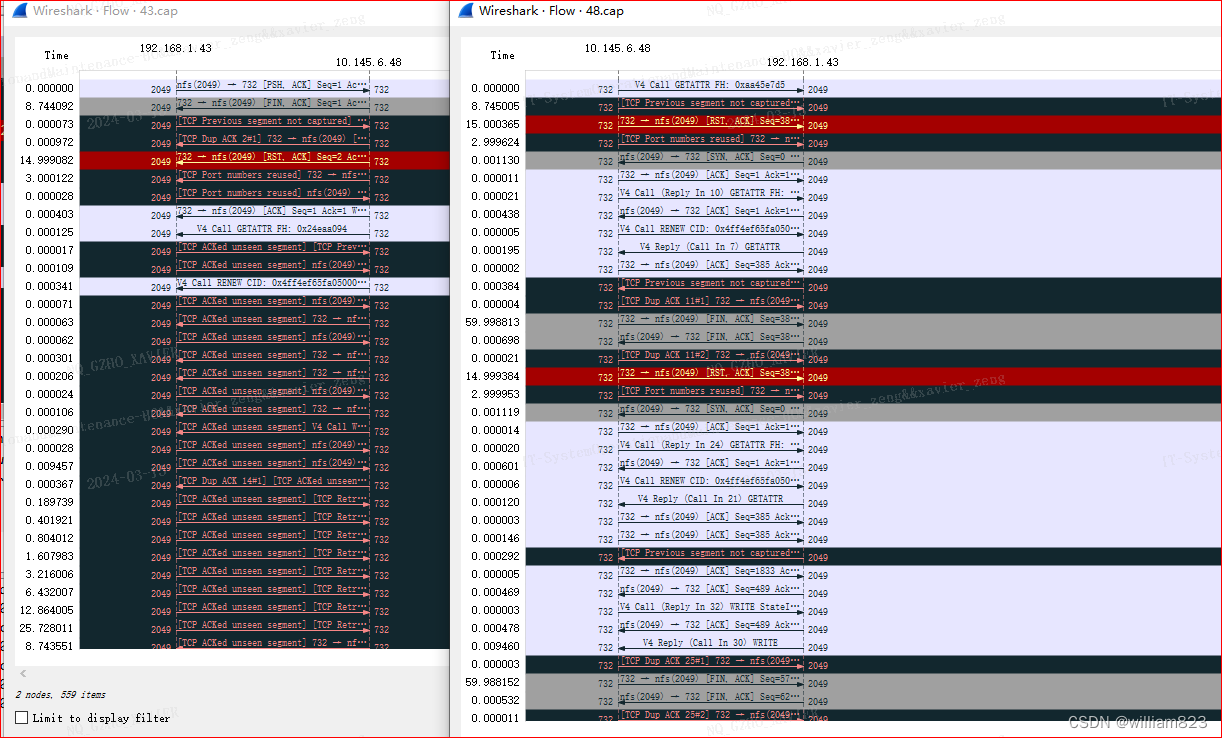
直到超时,挂载返回,如下超时,
mount -t nfs 192.168.1.43:/home/evolist/grandysImport/muzai/upload /mnt/muzai
mount.nfs: Connection timed out
在客户端和服务器中都启用了非常冗长的 NFS 日志记录,但从未出现任何错误。但是,当触发此状态时,我确实在客户端计算机上收到以下内核跟踪错误:
查看内核日志 dmesg
Mar 25 00:49:48 servername kernel: INFO: task ProcessName:8230 blocked for more than 120 seconds.
Mar 25 00:49:48 servername kernel: Not tainted 2.6.32-431.el6.x86_64 #1
Mar 25 00:49:48 servername kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Mar 25 00:49:48 servername kernel: ProcessName D 0000000000000000 0 8230 8229 0x00000000
Mar 25 00:49:48 servername kernel: ffff8804792cdb68 0000000000000046 ffff8804792cdae8 ffffffffa0251940
Mar 25 00:49:48 servername kernel: ffff88010cdc8080 ffff8804792cdb18 ffff88010cdc8130 ffff88010ea5c208
Mar 25 00:49:48 servername kernel: ffff88047b011058 ffff8804792cdfd8 000000000000fbc8 ffff88047b011058
Mar 25 00:49:48 servername kernel: Call Trace:
Mar 25 00:49:48 servername kernel: [<ffffffffa0251940>] ? rpc_execute+0x50/0xa0 [sunrpc]
Mar 25 00:49:48 servername kernel: [<ffffffff810a70a1>] ? ktime_get_ts+0xb1/0xf0
Mar 25 00:49:48 servername kernel: [<ffffffff8111f930>] ? sync_page+0x0/0x50
Mar 25 00:49:48 servername kernel: [<ffffffff815280a3>] io_schedule+0x73/0xc0
Mar 25 00:49:48 servername kernel: [<ffffffff8111f96d>] sync_page+0x3d/0x50
Mar 25 00:49:48 servername kernel: [<ffffffff81528b6f>] __wait_on_bit+0x5f/0x90
Mar 25 00:49:48 servername kernel: [<ffffffff8111fba3>] wait_on_page_bit+0x73/0x80
Mar 25 00:49:48 servername kernel: [<ffffffff8109b320>] ? wake_bit_function+0x0/0x50
Mar 25 00:49:48 servername kernel: [<ffffffff81135bf5>] ? pagevec_lookup_tag+0x25/0x40
Mar 25 00:49:48 servername kernel: [<ffffffff8111ffcb>] wait_on_page_writeback_range+0xfb/0x190
Mar 25 00:49:48 servername kernel: [<ffffffff81120198>] filemap_write_and_wait_range+0x78/0x90
Mar 25 00:49:48 servername kernel: [<ffffffff811baa3e>] vfs_fsync_range+0x7e/0x100
Mar 25 00:49:48 servername kernel: [<ffffffff811bab2d>] vfs_fsync+0x1d/0x20
Mar 25 00:49:48 servername kernel: [<ffffffffa02cf8b0>] nfs_file_flush+0x70/0xa0 [nfs]
Mar 25 00:49:48 servername kernel: [<ffffffff81185b6c>] filp_close+0x3c/0x90
Mar 25 00:49:48 servername kernel: [<ffffffff81074e0f>] put_files_struct+0x7f/0xf0
Mar 25 00:49:48 servername kernel: [<ffffffff81074ed3>] exit_files+0x53/0x70
Mar 25 00:49:48 servername kernel: [<ffffffff81076f4d>] do_exit+0x18d/0x870
Mar 25 00:49:48 servername kernel: [<ffffffff81077688>] do_group_exit+0x58/0xd0
Mar 25 00:49:48 servername kernel: [<ffffffff81077717>] sys_exit_group+0x17/0x20
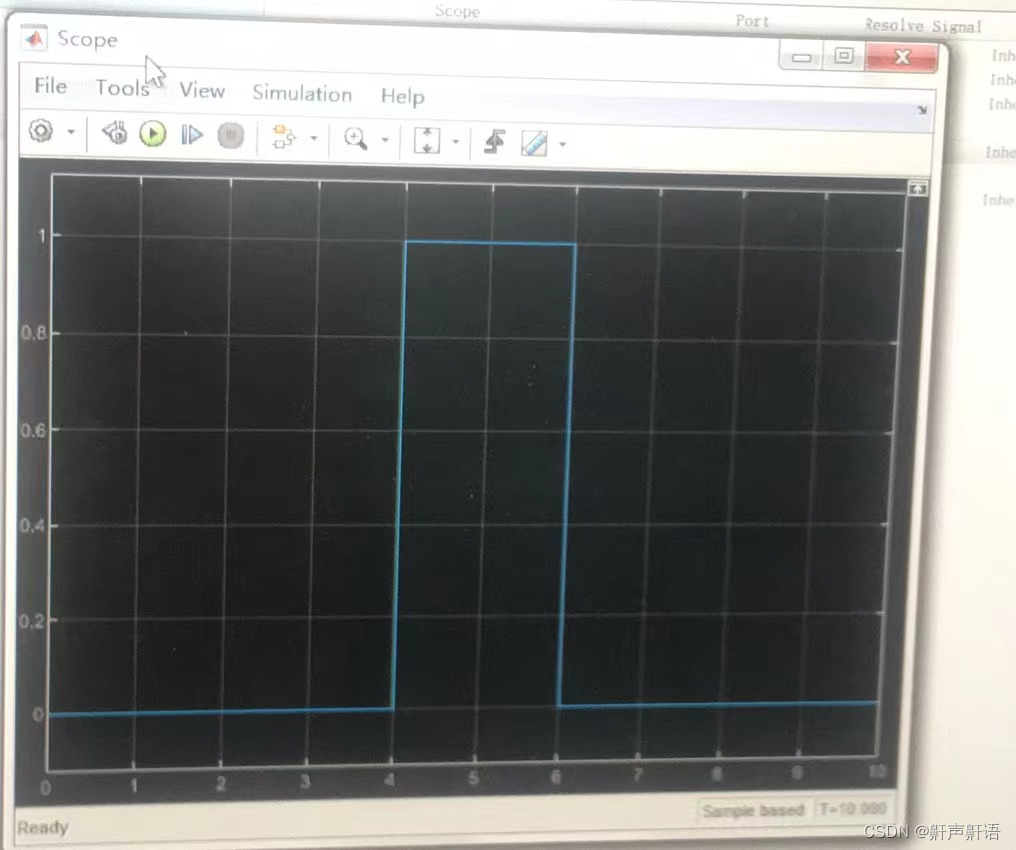
Mar 25 00:49:48 servername kernel: [<ffffffff8100b072>] system_call_fastpath+0x16/0x1b分析系统message日志发现,该问题与WAS出现内存溢出等故障有关,出现故障并开始疯狂写入数据的过程有关。例如,生成巨大核心文件的段错误,或具有紧密打印循环的错误。(例如伴随如下错误情况),会出现nfs不响应和超时情况(下图)
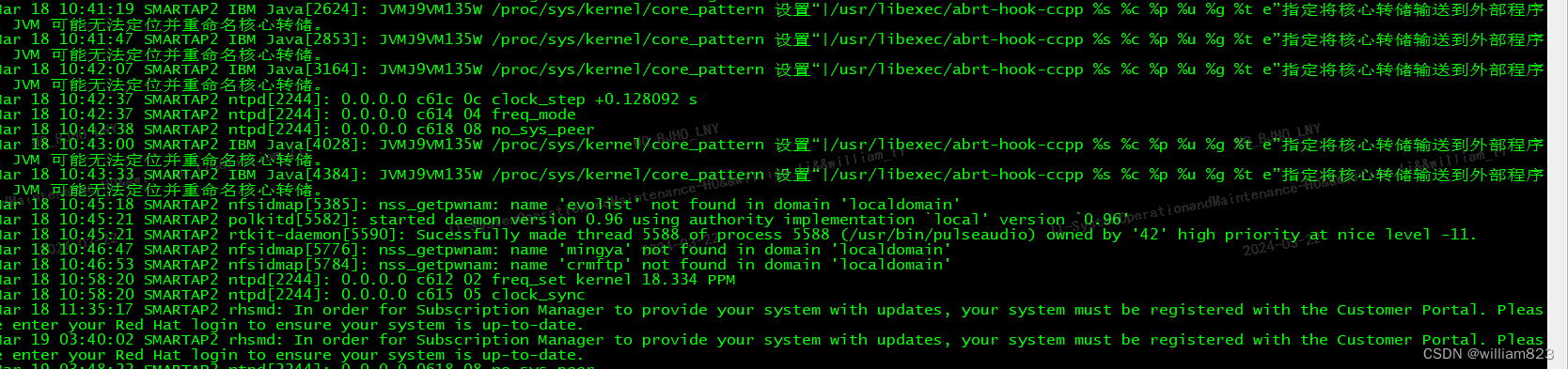

我曾试图在测试环境中重现此问题,其中多个“dd”进程在 NFS 服务器上敲击,但并没有重现nfs挂起问题,一切运行正常。
经过查询相关资料,参考链接:nfs - Random machine hangs with NFSv4 on CentOS/RHEL 6.5 - Server Fault
查看我系统内核刚好为,kernel-2.6.32-431.el6.x86_64

找到解决方案,如下,
CentOS 6.5 的内核 2.6.32-431.el6 存在问题。在提出这个问题的时候,这是一个相当古老的内核。我们查看了 RHEL/CentOS 内核的更新日志,发现了许多与 NFS 相关的活动。因此,我们升级到最新的 CentOS 内核 3.10.5-3.el6.x86_64 ,运行观察一段时间,没有再有遇到过这个问题。
3.10.5-3.el6.x86_64 我下载链接,供参考
https://download.csdn.net/download/cqrf2006/80015808?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-download-2%7Edefault%7EOPENSEARCH%7EPaid-1-80015808-blog-70904150.235%5Ev43%5Epc_blog_bottom_relevance_base3&depth_1-utm_source=distribute.pc_relevant_t0.none-task-download-2%7Edefault%7EOPENSEARCH%7EPaid-1-80015808-blog-70904150.235%5Ev43%5Epc_blog_bottom_relevance_base3&utm_relevant_index=1