文章目录
- doccano 数据集导入
- 简介
- 代码实现
- 代码运行结果
- 代码公开
doccano 数据集导入
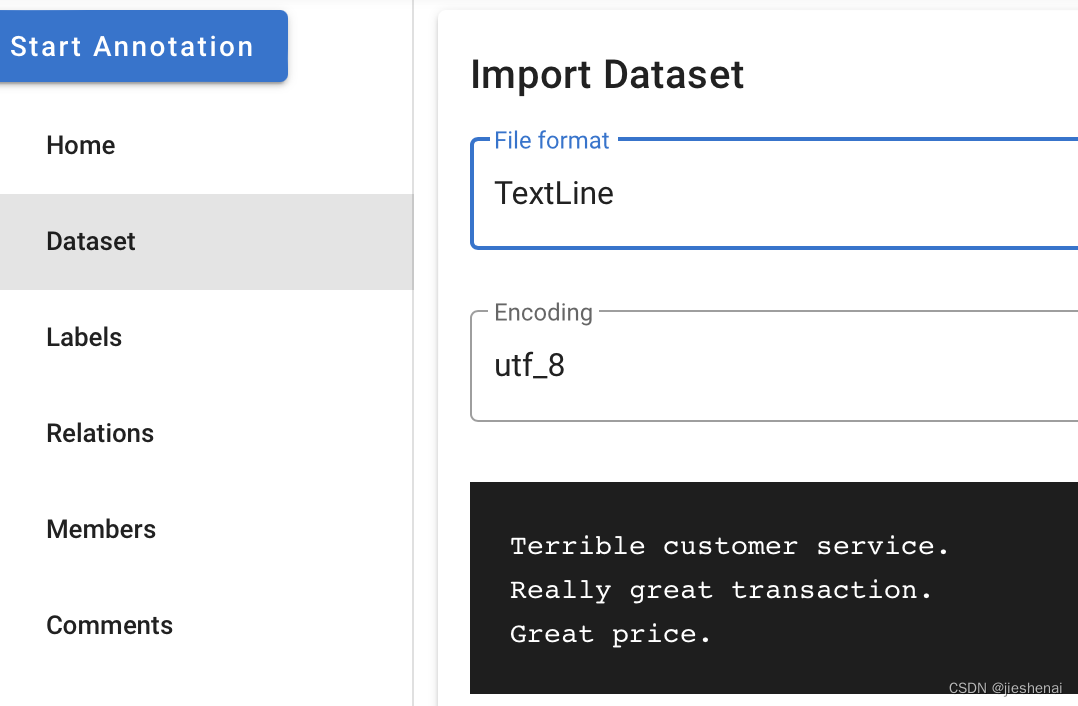
在Doccano 导入数据集时,使用TextLine的文件格式,导入的文件需要为一行一行文本的数据格式,每一行文本在导入Doccano后就是一条数据。
简介
主要工作说明:把pdf转成txt文件,在txt文件中,根据句号把文本分隔成一行一行文本,从而实现把pdf转换成doccano标注格式。
提供了两个文件转换功能:
- pdf转txt;
- txt转doccano的TextLine的文件格式;
下述是具体的函数说明:
trans_pdf_text: 实现把pdf转成txt文件,is_delete_page=True删除PDF的页码;
trans_folder_pdf2txt(prov, output_folder='pdf2txt'): 实现把prov文件夹下的所有pdf转成txt文件,存储到output_folder文件夹下;
cut_txt2sents(input_file, output_file, *args):
使用split('。')把文本切分成列表,args使用filters.py中的过滤函数进行过滤。
主要使用get_length_filter
代码实现
filters.py的代码如下:
def contains_digit_filters(sentence):
"""
判断句子中是否包含数字
"""
for char in sentence:
if char.isdigit():
return True
return False
def get_length_filter(bottom_len=8, top_len=1e3):
"""
文本长度过滤器,返回一个过滤器,
用于筛选出文本长度在bottom_len与top_len之间的句子
"""
def _length_filter(text):
if bottom_len <= len(text) <= top_len:
return True
return False
return _length_filter
def catalog_filter(text):
"""
过滤章节,识别到章节则返回False,删除掉
:param text:
:return:
"""
text = text.strip()
head = text[:5]
if '第' == head[0]:
if '章' in head or '节' in head or '篇' in head:
return False
return True
def title_filter(text):
if len(text) <= 45:
if '国民经济和社会发展' in text and '五年规划' in text:
return False
return True
过滤器说明:
get_length_filter(bottom_len=8, top_len=1e3):
筛选长度在bottom_len与top_len之间的文本,bottom_len筛选掉长度太短的文本,top_len可筛选掉文本的目录。
下面是主要代码:
import os
import re
from filters import get_length_filter, title_filter
"""
pdf -> txt
txt -> doccano
"""
def delete_page_num(text):
"""
删除页码
:param text:
:return:
"""
page_nums = [
r'\n- \d+ -( *?)\n',
r'\n— \d+ —( *?)+\n',
r'\n\d+( *?)\n',
r'\nI+( *?)\n',
]
patterns = [re.compile(pattern) for pattern in page_nums]
for pattern in patterns:
text = pattern.sub('', text)
return text
def trans_pdf_text(input_file, output_file, is_delete_page=True):
"""
把pdf文件转为txt,删除页码,保存到output_file
:param input_file:
:param output_file:
:param is_delete_page:
:return:
"""
import fitz
pdf_file = fitz.open(input_file) # pdf_path是PDF文件的路径
res = []
for i in range(len(pdf_file)):
page = pdf_file.load_page(i)
res.append(page.get_text())
text = ''.join(res)
if is_delete_page:
text = delete_page_num(text)
with open(output_file, 'w') as f:
f.write(text)
def trans_folder_pdf2txt(prov, output_folder='pdf2txt'):
"""
把某目录下pdf文件转为txt,方便预览和手动修改
:return:
"""
filenames = list(filter(
lambda x: x.endswith('.pdf'),
os.listdir(prov)
))
if not os.path.exists(p := os.path.join(output_folder, prov)):
os.mkdir(p)
for filename in filenames:
filename = os.path.join(prov, filename)
output_file = os.path.join(output_folder, filename.replace('.pdf', '.txt'))
trans_pdf_text(
filename,
output_file
)
def cut_txt2sents(input_file, output_file, *args):
"""
这部分处理由pdf转的txt文件,再将txt文本按照句号。切分
由于pdf转的txt文件,其文件内容很乱,需要进行一些处理
* args: 过滤器
针对句子的过滤器
"""
# 删除
delete_list = [
'\xa0', '\t', '\u3000',
' ', '', ' ', ' ', '',
'目\n录\n', '\n'
]
if input_file.endswith('.txt'):
with open(input_file, 'r', encoding='utf-8') as f:
text = f.read()
for char in delete_list:
text = text.replace(char, '')
text = text.replace(';', '。')
text = text.replace(';', '。')
## 本来按照\n切分最好,但是pdf转txt后,其中包含很多的\n,所以无法使用\n提前切分
# texts = text.split('\n')
# for text in texts:
# data.extend(text.split('。'))
data = text.split('。')
# 过滤器
for arg in args:
data = filter(arg, data)
with open(output_file, 'w') as f:
f.write('\n'.join(data))
def trans_folder_txt2doccano(input_folder, output_folder, *filter_funcs):
"""
把某目录下的txt文件转为doccano格式
针对一整个文件夹内的文件,批量操作)
:return:
"""
filenames = list(filter(
lambda x: x.endswith('.txt'),
os.listdir(input_folder)
))
if not os.path.exists(output_folder):
os.mkdir(output_folder)
for filename in filenames:
cut_txt2sents(
os.path.join(input_folder, filename),
os.path.join(output_folder, filename),
*filter_funcs
)
trans_folder_txt2doccano(
os.path.join(pdf_txt_folder, prov),
os.path.join('doccano', prov),
get_length_filter(8, 200),
title_filter
)
trans_folder_txt2doccano(
prov, f'doccano/{prov}',
get_length_filter(8, 200)
)
代码运行结果
原始文件夹介绍:
湖北省: 存放原始文件,里面有一些pdf文件和txt文件;
pdf2txt: 存放pdf转txt的结果,若希望修改可以手动修改;
doccano: 最终的doccano TextLine 输入格式的文件;

pdf_txt_folder = 'pdf2txt'
prov = '湖北省'
trans_folder_pdf2txt(prov, pdf_txt_folder)
上述代码实现把湖北省文件夹下的pdf文件转成txt文件,并保存到pdf2txt文件夹下,程序运行结果如下:

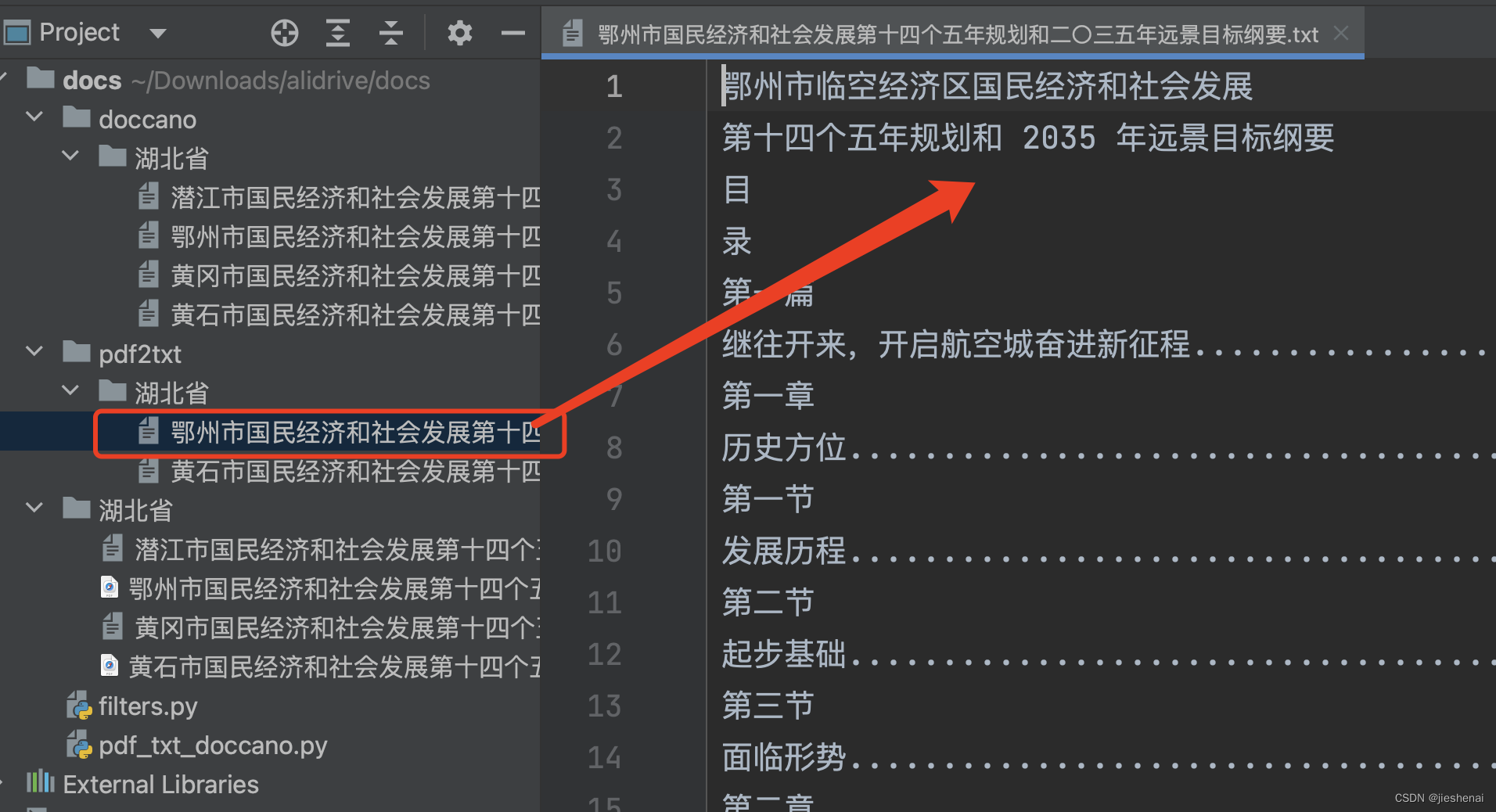
pdf2txt/湖北省/鄂州市国民经济和社会发展第十四个五年规划和二〇三五年远景目标纲要.txt:
在pdf转txt后的文件中,包含有目录信息。
下述代码实现把pdf2txt/湖北省和湖北省文件夹下的txt文件,转换为doccano输入格式,转换结果存储在doccano文件夹下
trans_folder_txt2doccano(
os.path.join(pdf_txt_folder, prov),
os.path.join('doccano', prov),
get_length_filter(8, 200),
title_filter
)
trans_folder_txt2doccano(
prov, f'doccano/{prov}',
get_length_filter(8, 200)
)
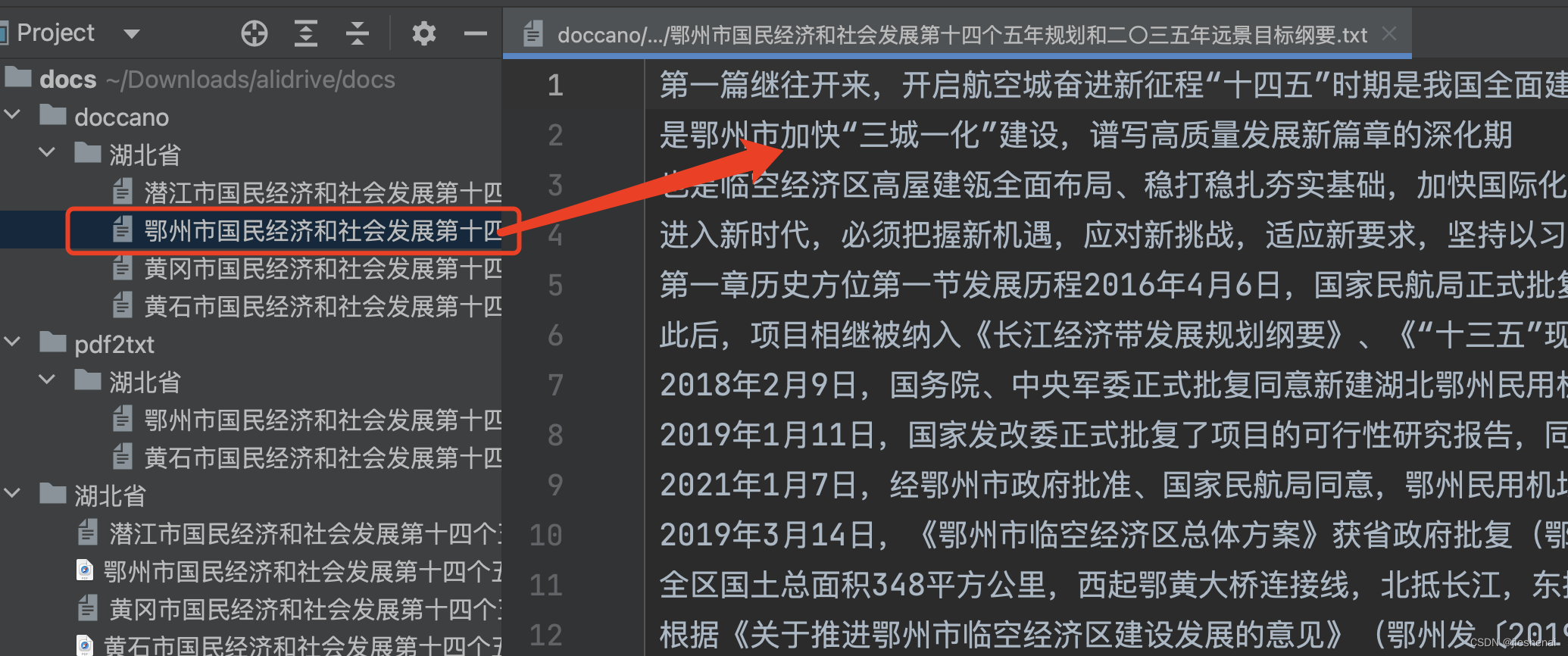
在txt转为doccano标注格式的过程中:
get_length_filter(8, 200):使用文件长度过滤器,只保留文本长度在8到200之间的文本;如下图所示,对比上图,利用长度过滤器删除掉了目录。
代码公开
- 链接: https://pan.baidu.com/s/1x_o70B9VJVg07VPxyMdubQ?pwd=ryku 提取码: ryku
在百度网盘中,包含了湖北省文件夹下的pdf和txt文件。 - https://github.com/JieShenAI/csdn/tree/main/24/03/pdf_txt_doccano
只有代码,不包括pdf和txt文件;