大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
2022年11月30日,ChatGPT正式发布,它的影响力迅速扩散至各个领域。2022年12月5日,也就是ChatGPT发布五天后,OpenAI的CEO Sam Altman宣布ChatGPT的用户数量已达到100万,这意味着ChatGPT成为了历史上增长最快的消费软件应用之一。截至目前(2024年3月),ChatGPT 的用户已超过1.805亿,ChatGPT app在iOS和Android应用商店的下载量超过1.1亿次,ChatGPT网站在2024年1月的访问量达到16亿次。
在ChatGPT的众多用户和高访问量中,学术界占据了显著的一席之地。早在去年9月,学术界就有研究者注意到并披露在一些知名学术期刊上发表的文章中识别出了明显的生成式人工智能,如ChatGPT等工具的使用迹象,比如把Regenerate response这个ChatGPT“重新生成”按钮也复制到了论文里;更为离谱的,直接把As an AI language model, there is no access to the specific database details of any particular research study - 作为人工智能语言模型,我…复制到了论文里。


以上都是学术界用ChatGPT来写论文的例子,在近期发表的一篇标题为“Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews”的论文里,研究者表示在几个AI顶级会议(ICLR 2024、NeurIPS 2023、CoRL 2023和EMNLP 2023)的同行评审文本中,有6.5%至16.9%可能已经被LLM大量修改,超出了拼写检查或轻微写作更新的范围。也就是,不仅仅是写论文的在用ChatGPT,同行评审也在用ChatGPT!很多网友表示:还有什么是ChatGPT不能做的吗!

今天就来聊一聊这篇很有意思的论文。
关键词
-
大型语言模型 (LLM)
-
ChatGPT
-
同行评审 (Peer Review)
-
人工智能会议 (AI Conferences)
-
文本修改 (Text Modification)
-
最大似然估计 (Maximum Likelihood Estimation, MLE)
-
信息生态系统 (Information Ecosystem)
-
文本分布 (Text Distribution)
-
语料库 (Corpus)
研究背景和目的
在学术领域,类似ChatGPT的大型语言模型(LLM)已经开始被大量用于辅助教学、作业辅导、甚至参与到考试和论文写作中。这种技术的应用引发了关于学术诚信和学生学习成效的广泛讨论。在科学研究领域,LLM被用来协助文献综述、数据分析和研究假设的生成,这不仅提高了研究效率,也引发了对科学发现原创性的担忧。全球媒体行业也在利用LLM进行内容创作,包括新闻撰写和社交媒体帖子的生成,这改变了信息传播的方式和速度。然而,随着LLM生成的文本越来越难以与人类写作区分开来,如何识别和验证文本的来源成为了一个紧迫的问题。这种难以区分的现象可能导致信息的误导和知识的混淆,对教育、科研和媒体的质量和公信力构成挑战。
为了应对这一挑战,该论文提出了一种新的框架,旨在高效地监测信息生态系统中AI修改的内容。这个框架被称为分布GPT量化方法(Distributional GPT Quantification),它通过分析已知由人类或AI生成的参考文本来估计一个给定语料库中AI生成或显著修改内容的比例。这种方法的核心在于使用最大似然估计(Maximum Likelihood Estimation, MLE)来计算文本分布,从而对文本的来源进行准确估计。通过这种方式,研究者可以评估LLM在大规模文本中的影响,识别出可能由AI生成或修改的文本部分,进而对信息生态系统中AI的使用情况进行量化分析。这一框架的提出,不仅有助于学术界更好地理解和管理LLM的使用,也为制定相关政策和指导原则提供了科学依据。
方法论和案例研究
在论文中,研究者们采用了最大似然估计(Maximum Likelihood Estimation, MLE)来解决不确定来源文本的分布估计问题。这种方法的核心在于构建一个统计模型,该模型假设文本是由两种已知分布生成的:一种是人类专家撰写的文本分布(P),另一种是AI生成的文本分布(Q)。通过比较这两种分布,研究者能够估计出给定文本是由人类撰写还是由AI生成的概率。
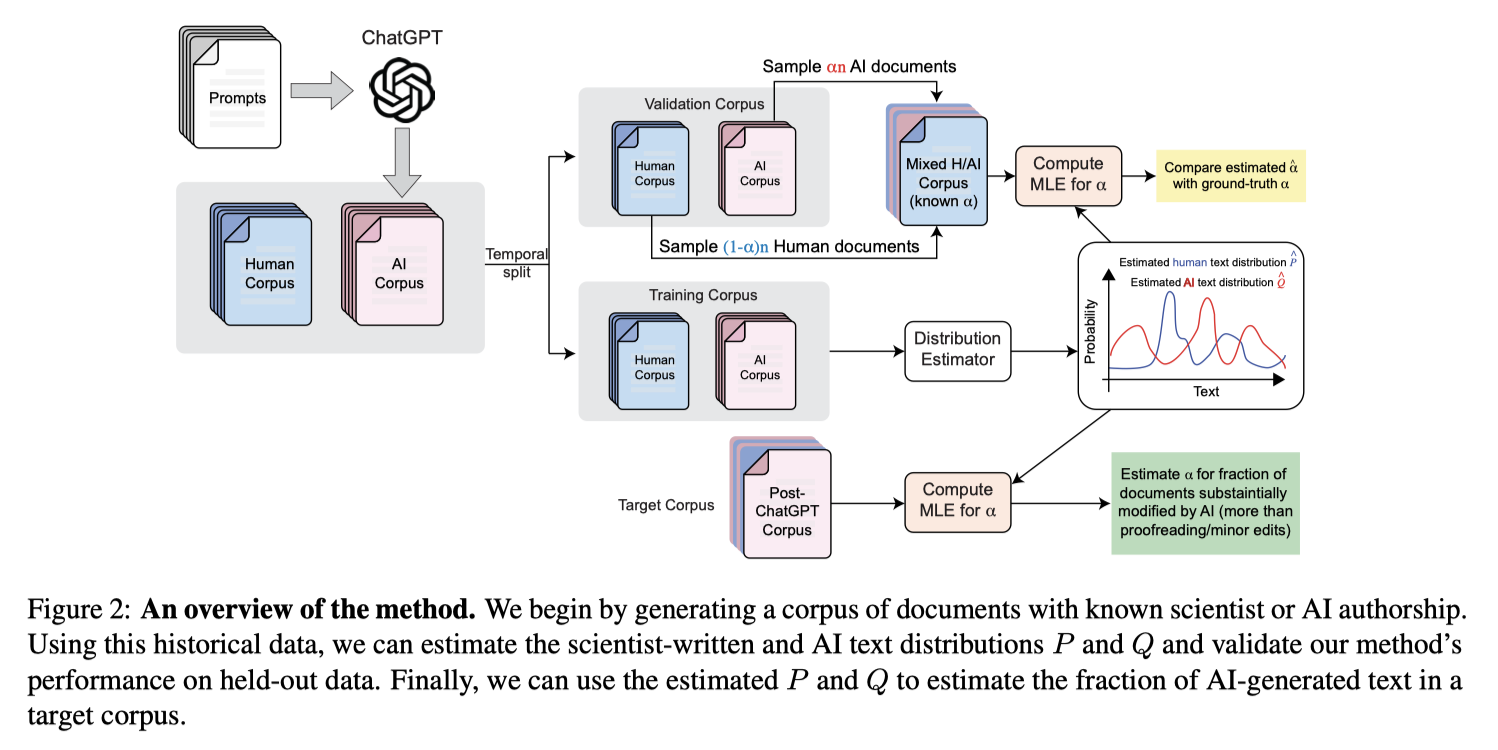
为了实现这一目标,研究者首先收集了两组参考文本:一组是人类专家撰写的文本,另一组是已知由AI生成的文本。这些文本被用来训练模型,以便能够准确地区分人类和AI的写作风格。然后,研究者将这种方法应用于未知来源的文本,通过计算这些文本在人类和AI文本分布下的概率,来估计文本是由人类撰写的概率(α)。这个过程涉及到对文本中的词汇使用频率和分布进行统计分析,以及对这些统计数据进行最大似然估计。
在方法论的基础上,研究者们进行了一项案例研究,他们选择了几个AI领域的顶级会议,包括国际学习表示会议(ICLR 2024)、神经信息处理系统会议(NeurIPS 2023)、机器人学:科学与系统会议(CoRL 2023)和自然语言处理实证方法会议(EMNLP 2023)。这些会议的同行评审文本被用作案例研究的数据集,以评估LLM在学术评审中的使用情况。
研究者们首先分析了这些会议在ChatGPT发布前后的评审文本,以观察是否有显著的变化。他们发现,在ChatGPT发布后,这些会议的评审文本中由LLM生成或显著修改的比例有所增加。此外,他们还对Nature系列期刊的评审文本进行了类似的分析,但发现在这些期刊中并没有观察到类似的趋势,这可能反映了不同学科领域对LLM工具的接受程度和使用模式的差异。
主要发现

-
ChatGPT发布后的文本修改比例:
-
研究者们通过应用他们提出的分布GPT量化方法,对ChatGPT发布后的AI会议同行评审文本进行了分析。他们发现,在ICLR 2024、NeurIPS 2023和CoRL 2023等会议的评审文本中,有显著比例的文本可能经过了LLM的大量修改。具体来说,ICLR 2024的评审文本中有**10.6%,EMNLP 2023的评审文本中有约16.9%**的文本被认为受到了ChatGPT的显著影响。这一发现表明,ChatGPT等LLM工具在学术评审过程中的使用已经变得相当普遍,且可能对评审质量产生影响。
-
-
生成文本使用的相关因素:
-
论文中提到的生成文本使用与评审自信程度的负相关性表明,那些对自己评审内容不够自信的评审者更倾向于使用LLM进行文本生成或修改。这可能是因为LLM提供了一种快速生成内容的方式,帮助评审者在不确定时构建更有说服力的评审意见。
-
提交截止日期的临近程度与LLM使用率的正相关性揭示了一个有趣的现象:在截止日期临近时提交的评审文本中,LLM的使用更为频繁。这可能是因为评审者在时间压力下寻求快速完成评审的方法,而LLM提供了一种有效的时间管理工具。
-
评审者对作者反驳的回应可能性与LLM使用率的关系表明,那些不太可能回应作者反驳的评审者更可能依赖LLM。这可能意味着这些评审者更倾向于一次性完成评审,而不是参与到与作者的互动和讨论中。
-
-
语料库级趋势的观察:
-
研究者们通过分析发现,某些特定的形容词在LLM生成的文本中出现的频率异常高,如“commendable”、“meticulous”和“intricate”等。这种在LLM文本中特定词汇使用频率的显著增加,可能反映了LLM在生成文本时的某些固有倾向或模式。这些模式在单独的文本中可能不易被察觉,但在大规模的语料库分析中则变得明显,为识别和理解LLM生成内容提供了线索。
-

讨论与影响
研究指出,LLM的使用可能导致评审内容的同质化,减弱了评审的多样性和深度,因为LLM可能倾向于生成具有特定模式和风格的内容。此外,LLM生成的文本可能缺乏对学术文献的引用和批判性分析,从而影响评审的权威性和可信度。
论文还讨论了LLM使用对信息和知识实践的更广泛影响。LLM可能会改变研究者和学者之间的交流方式,影响知识的创造和传播。例如,如果LLM生成的内容未经适当审查就被接受为权威信息,可能会导致错误信息的传播和科学理解的混淆。
此外,论文还提出了LLM使用可能带来的伦理和责任问题。例如,评审者使用LLM生成的文本时,如何确保他们对所提供反馈的真实性和准确性负责?LLM的使用是否应该在评审报告中明确披露?这些问题都需要学术界和出版界共同面对和解决。
未来工作
论文呼吁未来的研究应该采取跨学科的方法,结合计算机科学、社会学、教育学和传播学等领域的专业知识,以全面理解LLM在信息生态系统中的使用及其对人类行为和知识传播的影响。具体来说,未来的工作可以包括:
-
开发更精确的工具和技术来检测和区分LLM生成的文本与人类写作。
-
研究LLM使用对学术诚信和研究质量的长期影响。
-
探索如何制定有效的政策和指导原则,以规范LLM在学术评审和其他领域的使用。
-
分析LLM在不同学科和文化背景下的使用模式和接受度。
-
评估LLM在促进知识传播和教育普及方面的潜力和挑战。
论文原文链接
最后,附上该论文的链接:
https://arxiv.org/abs/2403.07183
精选推荐
-
完全免费白嫖GPT4的三个方法,都给你整理好了!
-
AI领域的国产之光,ChatGPT的免费平替:Kimi Chat!
-
Kimi Chat,不仅仅是聊天!深度剖析Kimi Chat 5大使用场景!
-
我用AI工具5分钟制作一个动画微电影!这个AI现在免费!
-
当全网都在疯转OpenAI的Sora时,我们普通人能做哪些准备?——关于Sora,你需要了解这些!
-
文心一言4.0 VS ChatGPT4.0哪家强?!每月60块的文心一言4.0值得开吗?
-
ChatGPT和文心一言哪个更好用?一道题告诉你答案!
-
字节推出了“扣子”,国内版的Coze,但是我不推荐你用!
-
白嫖GPT4,Dalle3和GPT4V - 字节开发的Coze初体验!附教程及提示词Prompt
-
2024年了你还在用百度翻译?手把手教会你使用AI翻译!一键翻译网页和PDF文件!
都读到这里了,点个赞鼓励一下吧,小手一赞,年薪百万!😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。