2. 问题定义
时间序列关系数据(Time Series Relation Data)
这个数据是存放在关系型数据库中,每一条记录都是泰永时间搓的行为。
更具体地,每条记录表示为 x = ( v , t , x 1 , x 2 , … , x m − 2 ) x = (v,t,x_1,x_2,\dots,x_{m-2}) x=(v,t,x1,x2,…,xm−2),其中 v v v代表带时间戳的行为, t t t是时间戳,𝑥𝑖代表其他属性,例如设备ID和会话持续时间。
针对时间序列关系数据的欺诈检测(Fraud Detection over Time Series Relation Data)
每一个用户 u ∈ U u \in U u∈U都会有一些列的行为 V = { v 0 , v 1 , … , v n − 1 } V = \{v_0, v_1, \dots, v_{n-1}\} V={v0,v1,…,vn−1}其中 v i ∈ V v_{i} \in V vi∈V代表的是用户的行为, n n n是序列的长度。用户的行为数据,也就是 V V V通常是按照时间顺序进行呈现的,目的是根据用户的历史顺序行为数据确定用户是否有可以行为,这个任务可以被构建为一个二分类任务。
时间感知行为图
给定一个具有带时间戳的行为序列 V = { v 0 , v 1 , … , v n − 1 } V = \{v_0, v_1, \dots, v_{n-1}\} V={v0,v1,…,vn−1}及相应的属性的用户,其时间感知行为图定义为 G = { V , E , A } G = \{V, E, A\} G={V,E,A}, 其中 V V V代表行动节点, E E E是边, A ∈ R n ∗ n ( 0 ≤ A i , j ≤ 1 ) A \in R^{n*n}(0 \leq A_{i,j} \leq 1) A∈Rn∗n(0≤Ai,j≤1)是图卷积矩阵(graph convolutional matrix)。图中的每个节点 V i V_i Vi代表一条记录,每条边< v i , v j v_i, v_j vi,vj>的权重与 v i v_i vi代表一条记录,每条边< v i v_i vi, v j v_j vj>的权重与 v i v_i vi和 v j v_j vj之间的时间差成反比。
图卷积矩阵(Graph Convolutional Matrix)
GCN计算所有邻近节点(包含节点本身)的节点特征的胶圈平均值。权重矩阵被称为图卷积矩阵。在时间感知行为图中,构建了一个时间感知的图卷积矩阵来模拟行动之间的相互依赖性。更具体地说,第
i
i
i个节点和第
j
j
j个节点之间的归一化边权重是
A
~
i
,
j
=
ρ
∣
t
i
−
t
j
∣
∑
k
=
0
n
−
1
ρ
∣
t
i
−
t
k
∣
\widetilde{A}_{i,j}=\frac{\rho^{|t_i-t_j|}}{\sum_{k=0}^{n-1}\rho^{|t_i-t_k|}}
A
i,j=∑k=0n−1ρ∣ti−tk∣ρ∣ti−tj∣
,其中
0
<
ρ
<
1
0 < \rho <1
0<ρ<1 是控制每个目标节点接受场的范围的超参数。
3. MINT框架
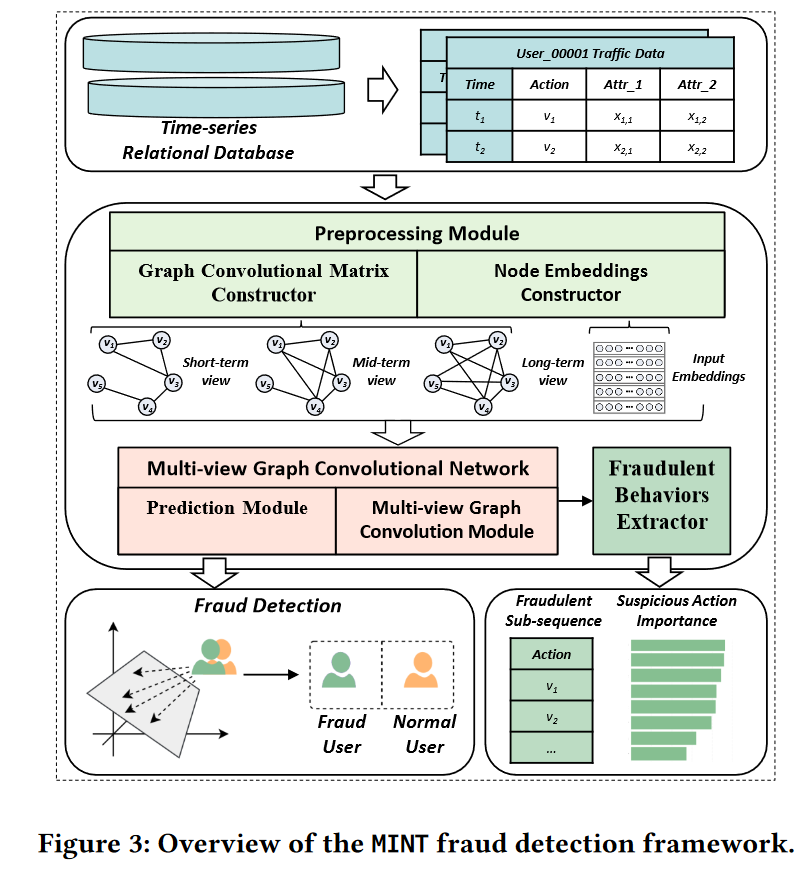
3.1 提取用户的时间信息,构建具有三个不同视角的时间感知行为图。
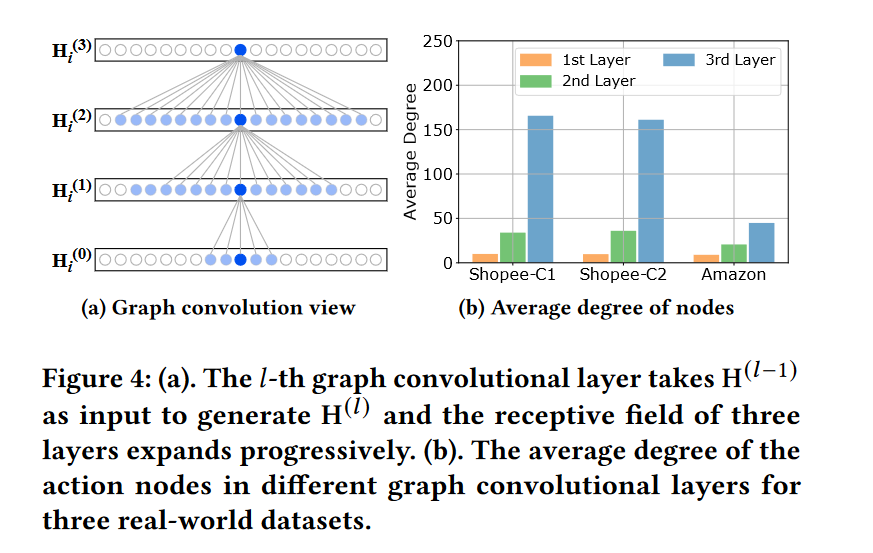
MINT的数据预处理模块由图卷积矩阵构造器和节点嵌入构造器组成。
- 将每一个行为表示为一个带有相应属性的节点特征
- 根据算法1构建三个具有不同接收计算的图卷积助阵,这个主要是 ρ \rho ρ的数值不相同。
- 更深的图卷积层会聚合更多的邻域信息(图四中的蓝色节点)到目的节点。
- 每一层中表示的是某一个用户的所有行为,按照的是时间段进行排序,然后,每一个节点的中的属性,例如时间,设备等等,会放入MLP中,输入的维度为 d d d,表示的是一个节点(也就是一个行为)的特征。
- 初始的行为嵌入表示为 H ( 0 ) ∈ R n ∗ d H^{(0)} \in R^{n*d} H(0)∈Rn∗d,其中 n n n是节点的数量, d d d表示输入嵌入的维度。
3.2 多视图卷积网络
3.2.1 多视图图卷积
在每一层图卷积中,特征聚合如下执行:
h
N
(
v
i
)
(
l
)
=
∑
v
j
∈
N
(
v
i
)
A
v
i
,
v
j
(
l
)
∗
h
v
j
(
l
−
1
)
\mathbf{h}_{\mathcal{N}(v_i)}^{(l)}=\sum_{v_j\in\mathcal{N}(v_i)}\mathbf{A}_{v_i,v_j}^{(l)}*\mathbf{h}_{v_j}^{(l-1)}
hN(vi)(l)=vj∈N(vi)∑Avi,vj(l)∗hvj(l−1)
我们现在知道,
H
(
0
)
=
[
h
v
0
(
0
)
,
h
v
1
(
0
)
,
…
,
h
v
n
−
1
(
0
)
]
H^{(0)} = [h_{v_0}^{(0)},h_{v_1}^{(0)},\dots,h_{v_{n-1}}^{(0)}]
H(0)=[hv0(0),hv1(0),…,hvn−1(0)],这个是初始化的特征,通过节点的属性经过
M
L
P
MLP
MLP获取的,
h N ( v i ) ( l ) \mathbf{h}_{\mathcal{N}(v_i)}^{(l)} hN(vi)(l)表示的是第 l l l层中行动节点 v i v_i vi的聚合邻居表示, A v i , v j ( l ) \mathbf{A}_{v_i,v_j}^{(l)} Avi,vj(l)表示的是在第 l l l层中行动节点 v j v_j vj到节点 v i v_i vi的归一化聚合系数。粗俗一点说也就是第 l l l层的节点特征是通过第 l − 1 l-1 l−1层的节点特征*第 l l l层中的图卷积矩阵
然后,对于他自己聚合邻居节点候得特征计算方式如下:
h
v
i
(
l
)
=
L
e
a
k
y
R
e
L
U
(
W
(
l
)
h
N
(
v
i
)
(
l
)
)
\mathbf{h}_{v_i}^{(l)}=LeakyReLU(\mathbf{W}^{(l)}\mathbf{h}_{\mathcal{N}(v_i)}^{(l)})
hvi(l)=LeakyReLU(W(l)hN(vi)(l))
L
e
a
k
y
R
e
L
U
LeakyReLU
LeakyReLU的激活函数公式如下所示,一般的
R
e
L
U
ReLU
ReLU函数会将小于0的数值变成0,但是
L
e
a
k
y
R
e
L
U
LeakyReLU
LeakyReLU会将小于0的数值变成极小值
f
(
x
)
=
{
x
i
f
x
>
0
α
x
i
f
x
≤
0
f(x)=\begin{cases}x&\mathrm{~if~}x>0\\\alpha x&\mathrm{~if~}x\leq0&\end{cases}
f(x)={xαx if x>0 if x≤0
可以看见其中的
W
(
l
)
∈
R
d
∗
d
\mathbf{W}^{(l)} \in R^{d*d}
W(l)∈Rd∗d是第
l
l
l层转换函数中的可训练参数矩阵。
3.2.2 门控邻居交互
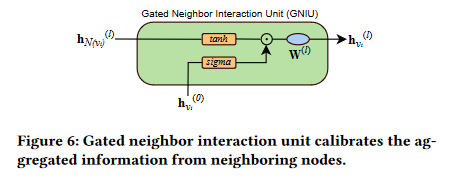
在这一节中,作者推翻了上一小节讲述的东西,现在说的是上一小节的做法会存在过平滑问题。
仅仅依赖时间间隔信息的信息聚合方法会导致严重的过平滑问题。也就是说,一些常见的行为,如‘访问主页’,在用户的行为数据中出现的频率远高于其他行为。导致用户的表示会被常见的行为信息所主导,从而降低欺诈检测的性能。我们将这个问题称为是过平滑问题。为了解决这个问题,我们尝试从邻居节点中尝试去聚合更有用的信息,作者设计了一个门控邻居交互机制。
首先对于第
l
l
l层中行动节点
v
i
v_i
vi的聚合邻居表示
h
N
(
v
i
)
(
l
)
\mathbf{h}_{\mathcal{N}(v_i)}^{(l)}
hN(vi)(l),变成了如下公式进行解决:
h
^
N
(
v
i
)
(
l
)
=
LayerNorm
(
σ
(
h
v
i
(
0
)
)
⊙
t
a
n
h
(
h
N
(
v
i
)
(
l
)
)
)
\widehat{\mathrm{h}}_{\mathcal{N}(v_i)}^{(l)}=\text{LayerNorm}(\sigma(\mathrm{h}_{v_i}^{(0)})\odot tanh(\mathrm{h}_{\mathcal{N}(v_i)}^{(l)}))
h
N(vi)(l)=LayerNorm(σ(hvi(0))⊙tanh(hN(vi)(l)))
其中,他把初始化的通过节点属性输入进
M
L
P
MLP
MLP中的特征的输出结果,输出进了
σ
\sigma
σ函数中,其中
σ
\sigma
σ函数的公式如下:
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)=\frac1{1+e^{-x}}
σ(x)=1+e−x1
他是把输入的
x
x
x输出为一个[0-1]的数值,这样做的目的可能是引入非线性函数去捕获更加复杂的信息。
然后
t
a
n
h
(
x
)
tanh(x)
tanh(x)的结构如下所示:
tanh
(
x
)
=
e
x
−
e
−
x
e
x
+
e
−
x
\tanh(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}
tanh(x)=ex+e−xex−e−x
他的输出范围在[-1,1],通过这样的方式去保持中心化,也可以改善梯度流
采用 L a y e r N o r m LayerNorm LayerNorm也是为了缓解梯度爆炸或者梯度消失的问题。
最后,在第
l
l
l层中的节点特征
h
v
i
(
l
)
\mathbf{h}_{v_i}^{(l)}
hvi(l)被表示为:
h
v
i
(
l
)
=
L
e
a
k
y
R
e
L
U
(
W
(
l
)
h
^
N
(
v
i
)
(
l
)
)
\mathbf{h}_{v_i}^{(l)}=LeakyReLU(\mathbf{W}^{(l)}\widehat{\mathbf{h}}_{\mathcal{N}(v_i)}^{(l)})
hvi(l)=LeakyReLU(W(l)h
N(vi)(l))
读出层
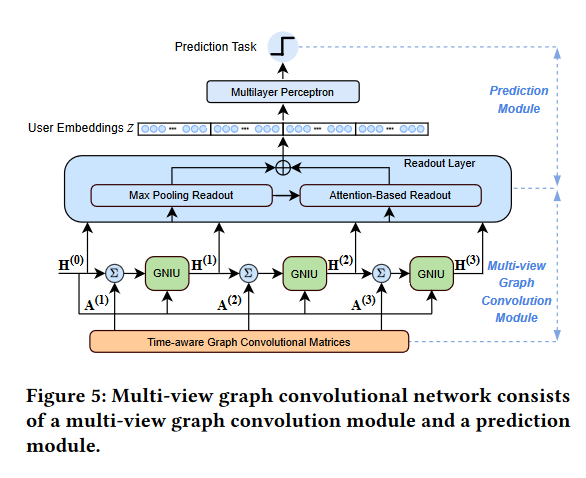
我们为了从行为嵌入矩阵中【 H ( l ) = [ h v 0 ( l ) , h v 1 ( l ) , … , h v n − 1 ( l ) ] H^{(l)} = [h_{v_0}^{(l)},h_{v_1}^{(l)},\dots,h_{v_{n-1}}^{(l)}] H(l)=[hv0(l),hv1(l),…,hvn−1(l)],】生成意图嵌入向量,设计了一个最大池化层和基于注意力机制的读出层,如图5所示。我们通过最大池化层去获取最显著的特征,我们称为嵌入相关的意图表示: h e ( 0 ) , h e ( 1 ) , h e ( 2 ) , h e ( 3 ) h_e^{(0)}, h_e^{(1)}, h_e^{(2)},h_e^{(3)} he(0),he(1),he(2),he(3),然后再运用注意力机制去融合在嵌入维度上保持最显著的行为。
对于每个试图,与行为相关的意图表示如下获得:
α
(
l
)
=
ϕ
a
t
t
(
h
e
(
l
)
,
H
(
l
)
)
=
h
e
(
l
)
⊺
W
a
t
t
H
(
l
)
\alpha^{(l)}=\phi_{att}(\mathbf{h}_{e}^{(l)},\mathbf{H}^{(l)})=\mathbf{h}_{e}^{(l)^{\intercal}}\mathbf{W}^{att}\mathbf{H}^{(l)}
α(l)=ϕatt(he(l),H(l))=he(l)⊺WattH(l)
h
e
(
l
)
⊺
∈
R
d
∗
n
\mathbf{h}_{e}^{(l)^{\intercal}} \in R^{d*n}
he(l)⊺∈Rd∗n|
W
a
t
t
∈
R
d
∗
d
\mathbf{W}^{att} \in R^{d*d}
Watt∈Rd∗d|
H
(
l
)
∈
R
n
∗
d
H^{(l)} \in R^{n*d}
H(l)∈Rn∗d =>
α
(
l
)
∈
R
n
∗
n
\alpha^{(l)} \in R^{n*n}
α(l)∈Rn∗n
注意力机制计算后的结果:
h
a
(
l
)
=
∑
i
=
0
n
−
1
α
i
(
l
)
⋅
h
i
(
l
)
,
α
i
(
l
)
∈
α
(
l
)
,
h
i
(
l
)
∈
H
(
l
)
\mathbf{h}_{a}^{(l)}=\sum_{i=0}^{n-1}\alpha_{i}^{(l)}\cdot\mathbf{h}_{i}^{(l)},\alpha_{i}^{(l)}\in\boldsymbol{\alpha}^{(l)},\mathbf{h}_{i}^{(l)}\in\mathbf{H}^{(l)}
ha(l)=i=0∑n−1αi(l)⋅hi(l),αi(l)∈α(l),hi(l)∈H(l)
α
(
l
)
∈
R
n
∗
n
\alpha^{(l)} \in R^{n*n}
α(l)∈Rn∗n|
h
(
l
)
∈
R
n
∗
d
\mathbf{h}^{(l)} \in R^{n*d}
h(l)∈Rn∗d =>
h
a
(
l
)
∈
R
n
∗
d
\mathbf{h}_{a}^{(l)} \in R^{n*d}
ha(l)∈Rn∗d
最后,该层的每个节点特征为: h ( l ) = h e ( l ) + h a ( l ) . \mathbf{h}^{(l)}=\mathbf{h}_{e}^{(l)}+\mathbf{h}_{a}^{(l)}. h(l)=he(l)+ha(l). 最后 h ( l ) ∈ R n ∗ d \mathbf{h}^{(l)} \in R^{n*d} h(l)∈Rn∗d
3.2.3 预测模块 (Prediction Module)
z = C O N C A T E ( [ h ( 0 ) , h ( 1 ) , h ( 2 ) , h ( 3 ) ] ) p = ϕ M L P ( z ) , ϕ M L P : R 4 ∗ d ↦ R \begin{aligned}\mathbf{z}&=CONCATE([\mathbf{h}^{(0)},\mathbf{h}^{(1)},\mathbf{h}^{(2)},\mathbf{h}^{(3)}])\\\\p&=\phi_{MLP}(z),\phi_{MLP}:\mathbb{R}^{4*d}\mapsto\mathbb{R}\end{aligned} zp=CONCATE([h(0),h(1),h(2),h(3)])=ϕMLP(z),ϕMLP:R4∗d↦R