🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
嘿,朋友们!今天咱们要来搞个大事情——自己动手实现逻辑回归!为啥要这么干呢?因为有时候,用现成的工具就像吃别人嚼过的糖,没劲!自己动手,那才叫真本事,不仅能搞懂背后的原理,还能在朋友面前炫耀一番:“看我这代码,多牛!”所以,咱们这就开始,一起踏上这个充满挑战和乐趣的旅程吧!🚀
逻辑回归
逻辑回归是一种算法,能帮咱们预测一个变量的两个类别。现实生活里头,这玩意儿能干不少事儿,比如:
- 检测垃圾邮件
- 预测客户会不会流失
- 预测客户会不会拖欠贷款
这些用例有个共同点:它们的结果都只有两种。当然啦,逻辑回归也有能预测多个结果的类型,不过这篇文章就只讲二分类的逻辑。
逻辑回归的假设(二分类)
你会发现逻辑回归模型的假设和线性回归模型很像,因为逻辑回归也是线性的。
- 二元因变量:目标变量必须只有两种可能的结果。
- 没有多重共线性:自变量之间应该没啥相关性,不然模型的效果会大打折扣。
- 自变量与对数几率的线性关系:对数几率是另一种表示概率的方式,形式上就是 log ( p / ( 1 − p ) ) \log(p/(1-p)) log(p/(1−p))。
还有一些对其他模型也很关键的假设,比如没有异常值(如果有,记得处理一下),样本量要足够大。虽然没有明确的样本量阈值,但记住:样本越多越好。
搭建我们的逻辑回归对象
咱们先从创建初始化函数和对象里要用到的属性开始。你会看到初始化函数里有三个属性:学习率(learning_rate)、迭代次数(iterations)和测试集比例(test_size)。
在用梯度下降找到模型最优权重的时候,fit 方法会用到学习率和迭代次数这两个属性。等咱们讲到这一步的时候,还会详细说说。咱们还加了一个训练集和测试集划分的方法,能将特征和目标变量的数据分成训练集和测试集。
自己动手搭建这些对象的时候,我喜欢把能用的功能都塞进去,这样后面写代码的时候就能更省事儿。
大部分属性一看就懂,除了 min_ 和 max_。咱们会在这些属性里存归一化缩放器的信息。对数据进行归一化处理,能让咱们在模型拟合的时候更快地找到解决方案。
import numpy as np
import pandas as pd
class DIYLogisticRegression:
def __init__(self, learning_rate=0.01, iterations=1000, test_size=0.2):
# 学习率,用于控制梯度下降的步长
self.learning_rate = learning_rate
# 迭代次数,决定了训练过程的循环次数
self.iterations = iterations
# 测试集占总数据集的比例
self.test_size = test_size
# 权重,初始值为 None,稍后会初始化
self.W = None
# 偏置项,初始值为 None,稍后会初始化
self.b = None
# 训练集特征数据
self.X_train = None
# 测试集特征数据
self.X_test = None
# 训练集目标数据
self.y_train = None
# 测试集目标数据
self.y_test = None
# 用于归一化处理的最小值
self.min_ = None
# 用于归一化处理的最大值
self.max_ = None
训练集/测试集划分与归一化
要正确地训练机器学习模型,必须用一个数据集来训练,另一个数据集来验证。机器学习生命周期里的另一个关键步骤是数据清洗,这可能包括归一化处理。咱们会创建一个方法,把特征和目标数据分成训练集和测试集,同时填充相应的属性。这个方法还会用最大最小值归一化方法对训练数据进行缩放,并把同样的逻辑应用到测试数据上。这就是 min_ 和 max_ 属性的用武之地啦。
注意,这些最小值和最大值是从训练集中得到的,然后应用到测试集上。为啥要这么做呢?假设咱们训练好了一个模型,把它放到生产环境中,那咱们根本不知道新数据的上下限是多少,所以只能依赖从训练集中提取出来的逻辑。
def train_test_split_scale(self, X, y):
## 训练集和测试集划分
n_samples = X.shape[0]
test_size = int(n_samples * self.test_size)
indices = np.arange(n_samples)
np.random.shuffle(indices)
test_indices = indices[:test_size]
train_indices = indices[test_size:]
self.X_train, self.X_test = X.iloc[train_indices], X.iloc[test_indices]
self.y_train, self.y_test = y.iloc[train_indices], y.iloc[test_indices]
# 最大最小值归一化
self.min_ = self.X_train.min()
self.max_ = self.X_train.max()
self.X_train = (self.X_train - self.min_) / (self.max_ - self.min_)
self.X_test = (self.X_test - self.min_) / (self.max_ - self.min_)
Sigmoid 函数
文章前面提到,咱们要搭建的是一个预测二元结果的逻辑回归模型,背后的原理其实是线性模型:
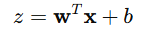
图由作者提供
和线性回归一样,咱们把线性模型设为等于 (z)。这个变量会被代入 Sigmoid 函数。Sigmoid 函数是逻辑回归模型做出预测之前的最后一步。这个函数的关键特性是,它的输出值会被限制在 0 和 1 之间。现在知道为啥逻辑回归要用它了吧?有了 Sigmoid 函数的输出,通常情况下,如果值大于或等于 0.5,咱们就预测二元变量的结果为 1,否则就是 0。当然啦,这个 0.5 的决策边界也可以根据具体需求调整。咱们这就把这个函数作为对象的一个方法加进去。
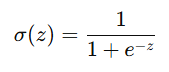
图由作者提供
def sigmoid(self, z):
# Sigmoid 函数,将输入值映射到 0 和 1 之间
return 1 / (1 + np.exp(-z))
最大似然估计和二元交叉熵损失
要理解逻辑回归,有一个最基本的概念必须得搞清楚,那就是怎么找到特征数据的权重 (W)。这个是通过最大似然估计(MLE)来实现的。MLE 的过程就是找到最能契合咱们数据的权重。一开始我琢磨这个概念的时候,总是在想,找到最优权重是不是就能得到最高的预测准确率呢?其实不是这么回事。最大似然估计函数(咱们要最大化这个函数)的目标是找到最能契合数据内在模式的权重。举个例子,假设咱们有一条观测数据,它的特征并没有明显显示出目标变量是 1 还是 0 的模式。那找到的最优权重和偏置就应该预测这个结果接近 0.5。再假设咱们有另一条观测数据,它的特征明显和预测结果为 1 的模式强相关,那咱们找到的权重和偏置就应该预测这个观测的结果接近 1。
所以,知道最大化 MLE 函数能找到最优权重,但它是怎么做到的呢?这就要通过梯度下降这个迭代过程来实现。梯度下降更适合最小化问题,所以咱们会用 MLE 函数的负值,也就是二元交叉熵损失。
在梯度下降的每一步迭代中,咱们都要计算这个损失函数。接下来的部分,咱们会详细讲讲怎么做到这一点。
先看看计算这个损失函数的方法。你会注意到,咱们在这个损失函数里加了一个额外的步骤,用到了 np.clip() 函数。这个损失函数很容易得到极小值。
一旦出现这种情况,Python 可能会直接四舍五入到 0,那就会出现对数为 0 的情况,这是未定义的。np.clip() 函数会设置一个极小值下限,这样咱们就不会得到 0 了。
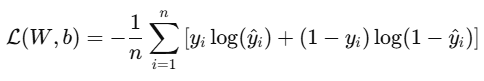
图由作者提供
def compute_loss(self, y, y_hat):
# 计算二元交叉熵损失
epsilon = 1e-10
y_hat = np.clip(y_hat, epsilon, 1 - epsilon)
return -np.mean(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))
找到最优权重和偏置
这一步就是咱们要把模型拟合到数据上了。正如前面提到的,这是一个叫梯度下降的迭代过程。一开始,咱们会随机初始化权重和偏置的值,然后用它们通过线性函数和 Sigmoid 激活函数来预测每一个 (y) 值。这些预测值就叫 (y_{\text{hat}})。有了 (y_{\text{hat}}) 之后,咱们就能通过二元交叉熵损失函数对权重和偏置进行调整,朝着更优的解靠近。具体来说,咱们要对二元交叉熵损失函数分别对权重和偏置求偏导数。
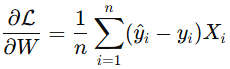
图由作者提供
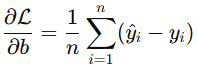
图由作者提供
接下来,咱们把这两个导数值乘以学习率 (\alpha),然后从当前的权重和偏置中减去。这个过程会不断重复,直到损失函数的值不再下降。
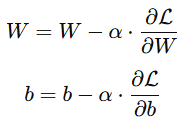
图由作者提供
在咱们的 fit 方法里,每迭代 100 次就输出一次损失函数的值,看看它是不是正确收敛了。如果学习率太高,损失值可能会一直越过最小值,那咱们就永远也“撞”不到最优权重和偏置了。反过来,如果学习率太小,那可能要经过很多次迭代才能“撞”到最小值。
def fit(self):
n_samples, n_features = self.X_train.shape
# 随机初始化权重
self.W = np.random.randn(n_features) * 0.01
# 初始化偏置为 0
self.b = 0
for i in range(self.iterations):
linear_model = np.dot(self.X_train, self.W) + self.b
y_hat = self.sigmoid(linear_model)
dW = (1 / n_samples) * np.dot(self.X_train.T, (y_hat - self.y_train))
db = (1 / n_samples) * np.sum(y_hat - self.y_train)
self.W -= self.learning_rate * dW
self.b -= self.learning_rate * db
if i % 100 == 0:
loss = self.compute_loss(self.y_train, y_hat)
print(f"Iteration {i}, Loss: {loss:.4f}")
预测和评估
重头戏已经搞定了!接下来只要再加几个方法就行啦。一切都已经准备就绪,咱们可以开始添加预测和评估方法了。首先,咱们会创建一个方法,用拟合过程中找到的最优权重,代入线性函数,再通过 Sigmoid 方法,预测结果的概率。这个方法最终会输出一个介于 0 和 1 之间的值,也就是咱们对预测结果的概率估计。
接下来,我会再加一个预测方法,它会根据一个阈值,把概率转换成 1 或者 0。默认的阈值就设为 0.5 吧。
最后,我还会加一个综合评估方法,打印出混淆矩阵、精确率、召回率,还有咱们模型的整体准确率。注意,这些都是基于咱们的测试集来评估模型性能的。
def predict_proba(self, X):
"""预测给定输入 X 的概率"""
linear_model = np.dot(X, self.W) + self.b
return self.sigmoid(linear_model)
def predict(self, X, threshold=0.5):
"""根据阈值预测类别标签(0 或 1)"""
probabilities = self.predict_proba(X)
return (probabilities >= threshold).astype(int)
def evaluate(self):
"""使用精确率、召回率、准确率和混淆矩阵评估模型"""
y_pred = self.predict(self.X_test)
tp = np.sum((self.y_test == 1) & (y_pred == 1))
fp = np.sum((self.y_test == 0) & (y_pred == 1))
fn = np.sum((self.y_test == 1) & (y_pred == 0))
tn = np.sum((self.y_test == 0) & (y_pred == 0))
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
accuracy = (tp + tn) / (tp + tn + fp + fn)
print("混淆矩阵:")
print(f"TP: {tp}, FP: {fp}")
print(f"FN: {fn}, TN: {tn}\n")
print(f"精确率(预测为正的样本中实际为正的比例): {precision:.4f}")
print(f"召回率(所有实际为正的样本中预测正确的比例): {recall:.4f}")
print(f"准确率(所有样本预测正确的比例): {accuracy:.4f}")
测试我们的对象
咱们来看看这个逻辑回归对象在实际中的表现吧。为了测试它,咱们用的是 Kaggle 上的 心脏病发作预测数据集。这个数据集有 13 列,其中 12 列是特征,最后一列是目标变量 DEATH_EVENT。幸好,咱们的对象已经具备了处理数据、训练模型和评估模型的所有功能。
df = pd.read_csv("heart_failure_clinical_records_dataset.csv") # 加载数据集
X = df.drop('DEATH_EVENT', axis=1)
y = df['DEATH_EVENT']
model = DIYLogisticRegression(learning_rate=0.1, iterations=1000, test_size=0.25)
model.train_test_split_scale(X, y)
model.fit()
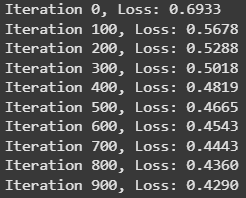
图由作者提供
model.evaluate()

还不错嘛,咱们的模型准确率达到了大约 80%。而且损失函数也收敛得很好,每次迭代的损失值都在下降。咱们来好好聊聊数据和模型吧。这个模型能帮咱们告诉患者他们是否有心脏病发作的风险,所以可别小瞧了它的表现哦。我列出了三个评估指标:精确率、召回率和准确率。你觉得哪个最重要呢?要是咱们告诉某人他有心脏病发作的风险,但实际上他没有,这算不算坏事呢?我觉得不算,但如果咱们没告诉某人他有风险,而他其实有,那可就太糟糕了。所以,咱们应该尽量提高召回率,它能告诉我们所有实际为正的样本中有多少被正确预测了。
和 Sklearn 的逻辑回归对象对比
咱们成功地从零搭建了一个逻辑回归对象,现在来看看它和 sklearn 的逻辑回归类比起来怎么样吧。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score
X = df.drop('DEATH_EVENT', axis=1)
y = df['DEATH_EVENT']
# 训练集和测试集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
# 最大最小值归一化
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 初始化并训练逻辑回归模型
model = LogisticRegression()
model.fit(X_train, y_train)
# 在测试数据上进行预测
y_pred = model.predict(X_test)
# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
# 显示结果
print("混淆矩阵:")
print(f"TP: {cm[1,1]}, FP: {cm[0,1]}")
print(f"FN: {cm[1,0]}, TN: {cm[0,0]}")
print(f"精确率: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"准确率: {accuracy:.4f}")
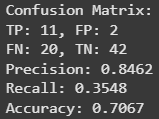
总的来说,评估指标都很接近!感谢您阅读这篇文章!希望您通过这篇文章对逻辑回归模型有了更深入的理解。