具体内容请看b站尚硅谷课程! 32_Flink运行时架构_提交流程_Yarn应用模式_哔哩哔哩_bilibili
- Flink本身有状态机制,状态都存储在Flink内部结构中,无需集成Mysql等
- 对于精确一次Exactly-once,Flink进行了相关的配置,无需像Spark Streaming一样去进行复杂的自定义来实现精准一次

- Spark Streaming不区分时间语义!不考虑数据本身产生的时间;且窗口必须是批次的整数倍(只有滚动/滑动的Time Window),支持小
- Flink有一个重要的点就是支持流式SQL!(SparkSQL不支持流数据的管理哦!)
- 分层API:SQL(最好用)-->TABLE API(当成表对象处理)-->DATASTREAM/DATASET API-->有状态流处理(低级语言,底层APIs)
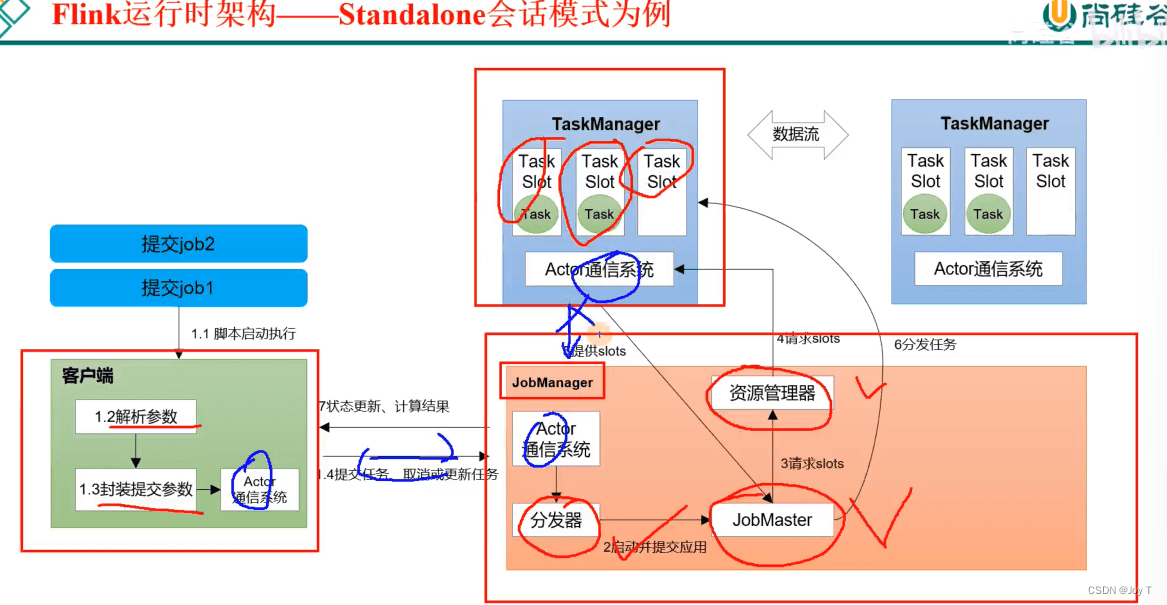
- 三大核心角色:Client JobManager TaskManager。一旦提交一个flink程序,本地就会启动一个Client进程,读取解析参数、封装提交参数,通过Actor通信系统提交给JobM。
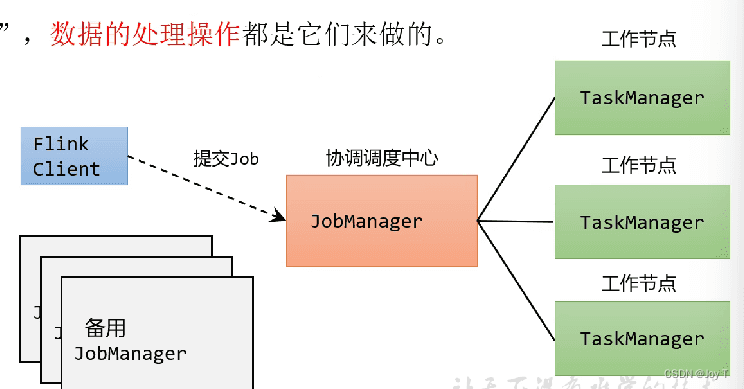
JobManager是Flink的进程,它是 Flink 集群的“大脑”,处理作业的提交、计划和监控等,JobMaster、ResouceManager、Dispatcher以线程的形式存在于 JobManager 进程中(JobMaster与Job一一对应,多个Job就有多个JobMaster);Master是Spark的进程, Driver 是运行用户应用程序的进程。
以Source为例,Source算子有两个子任务(Source算子有两个并行度)
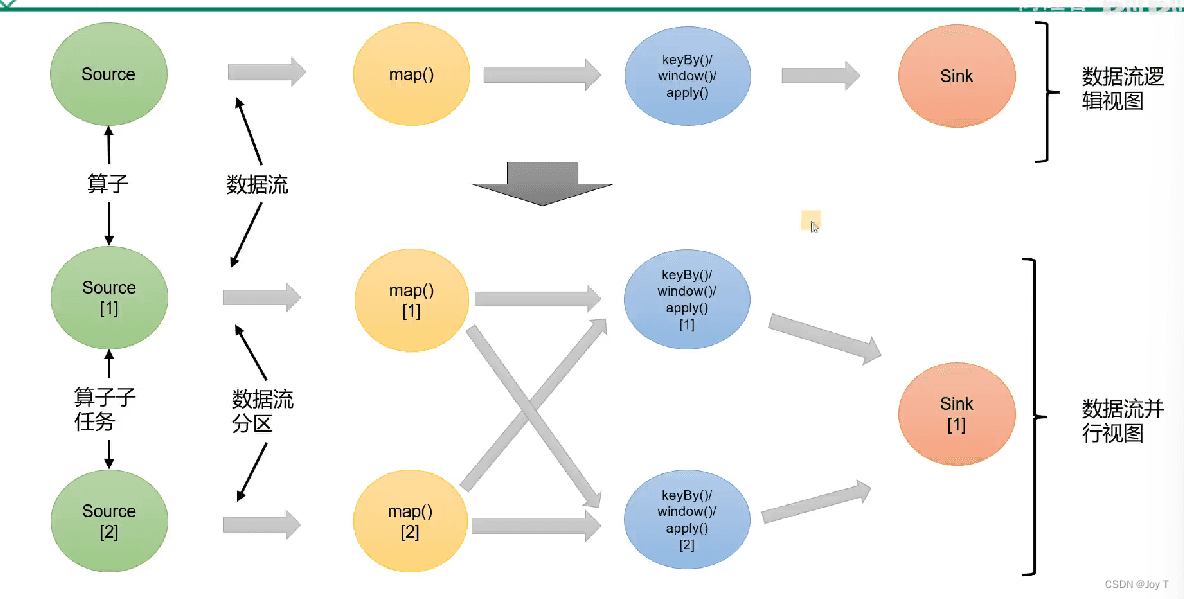
- 在Flink中,作业Job的并行度等于所有步骤并行度的最大值,以上图为例则并行度为2(Flink并行度更加灵活)
- 算子链(Operator Chaining)是 Flink 用来优化数据处理性能的一种技术。它允许将多个操作符(算子)合并成一个任务链,这样在执行过程中就可以减少数据在操作符之间的传输和序列化/反序列化开销。在 Flink 中,算子链默认是开启的,但可以通过配置进行调整;Spark采用了类似的优化机制,通常被称为“管道化”(pipelining)
分为one-to-one和Redistributing重分区,分别类似于Spark的窄依赖和宽依赖。(上图中间是Redistributing)

减少原本算子之间的跨线程次数,减少时延的同时提升吞吐量。
- 任务槽:在TaskManager小弟上固定给你两碗饭(内存资源,每个 Slot 能够运行一个并行实例的任务)!槽数最好和CPU核数保持一致,也是默认策略,防止TaskManager之间抢夺CPU资源。
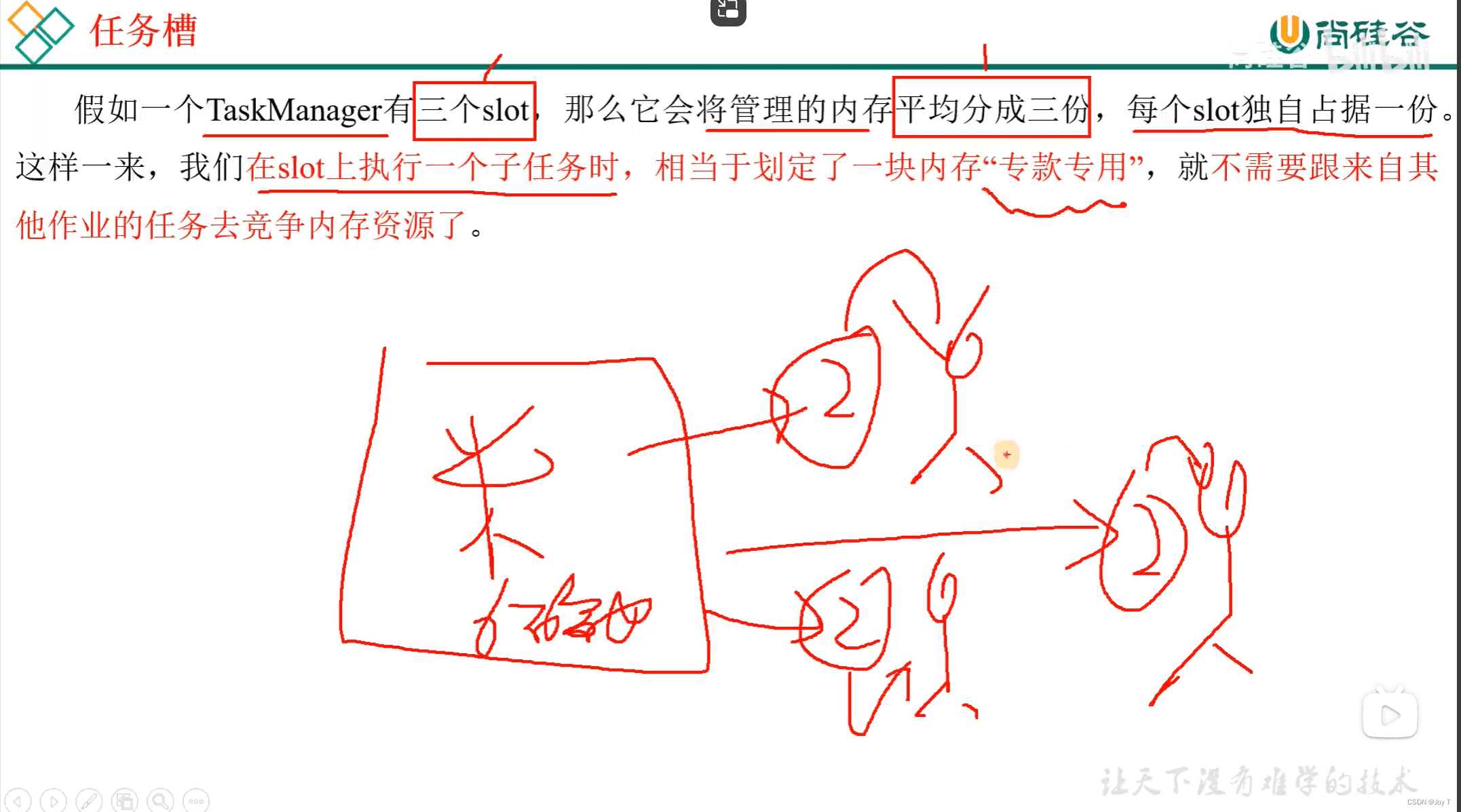
在一个 Flink 集群中,通常会有多个 TaskManager 实例,每个 TaskManager 可以运行在不同的机器上,故可以配置每个 TaskManager 的 Slot 数量为其所在机器的 CPU 核心数(每台机器通常运行一个 TaskManager 实例,和Hadoop的DataNode一样)
- Spark没有分槽但有分区(partitioner分区器)
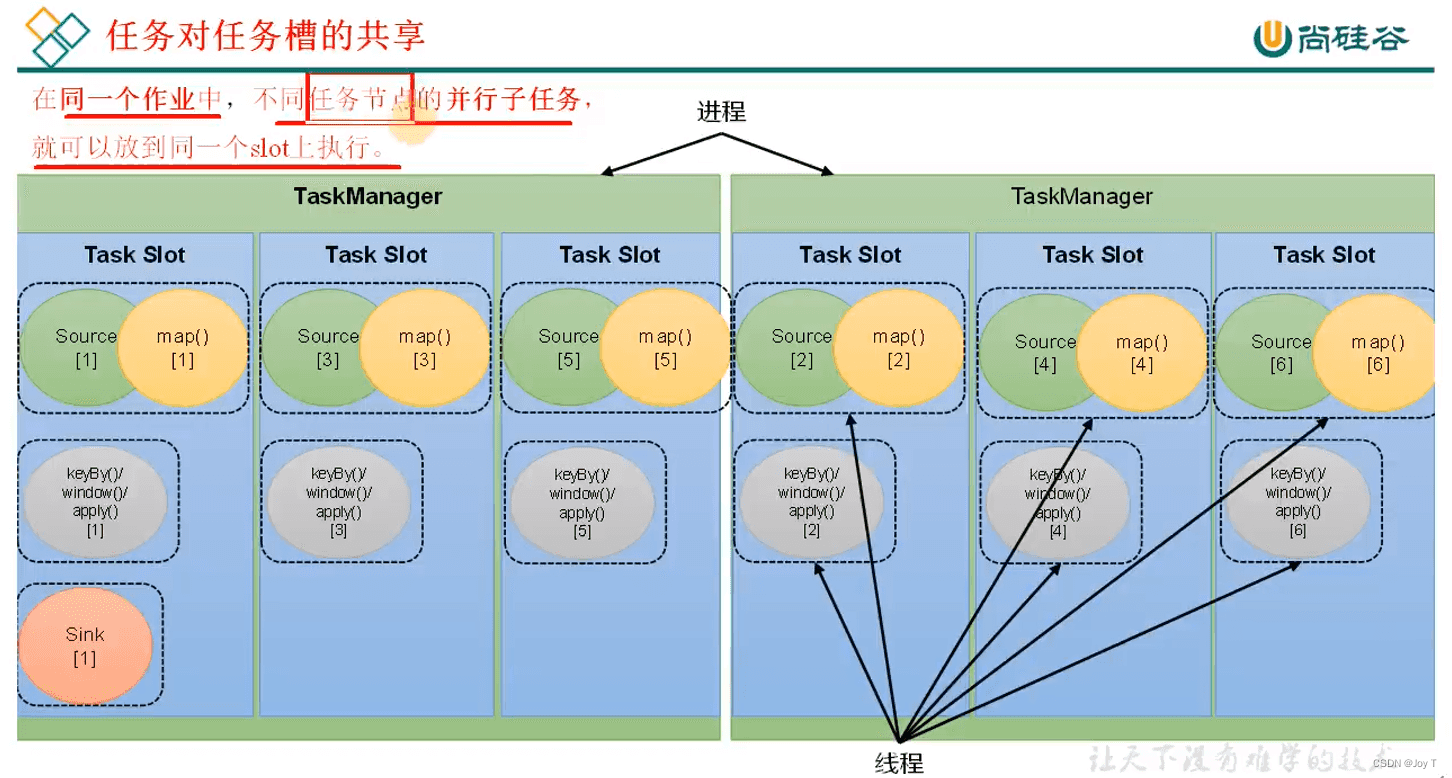
每个slot内部是不间断地并行运行同一个作业中的不同算子链的任务,不是内部串行,每一个算子链的进度都是时刻在变且相互之间没有联系。
- slot是一种静态定义,它是整个TaskManager理论上能够支持并行的上限;而并行度是动态的定义,并行度的数量如果大于slot,那么整个Flink程序就拒绝运行。