目录
安装
语音识别
补全标点
语音合成
参考
PaddleSpeech是百度飞桨开发的语音工具
安装
注意,PaddleSpeech不支持过高版本的Python,因为在高版本的Python中,飞桨不再提供paddle.fluid API。这里面我用的是Python3.7
需要通过3个pip命令安装PaddleSpeech:
pip install paddlepaddle==2.4.2
pip install pytest-runner
pip install paddlespeech在使用的时候,urllib3库可能会报错,因此需要对它进行降级:
pip uninstall urllib3
pip install urllib3==1.26.18语音识别
PaddleSpeech的语音识别非常简单:
from paddlespeech.cli.asr.infer import ASRExecutor
asr = ASRExecutor()
result = asr(audio_file="zh.wav")
print(result)输出:
我们说四十二号混凝土不能与引力场相互搅拌不然会因为爱因斯坦的相对论而引发炸串的食品安全问题这是严重的金融危机可以看到,这里面没有标点符号。我们可以通过TextExecutor()补全标点
补全标点
在补全标点之前,需要在C:\Users\<你的用户名>\AppData\Roaming下创建一个nltk_data文件夹,然后将这个链接里面的文件夹都复制进去:
项目目录预览 - nltk_data - GitCode
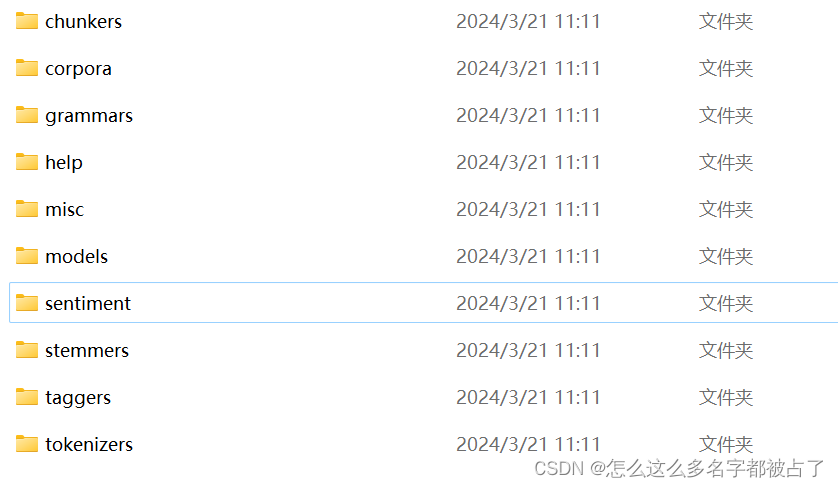
接下来从tokenizers文件夹下找到punkt.zip文件,然后将这个zip文件里的punkt文件夹复制到nltk_data文件夹里。
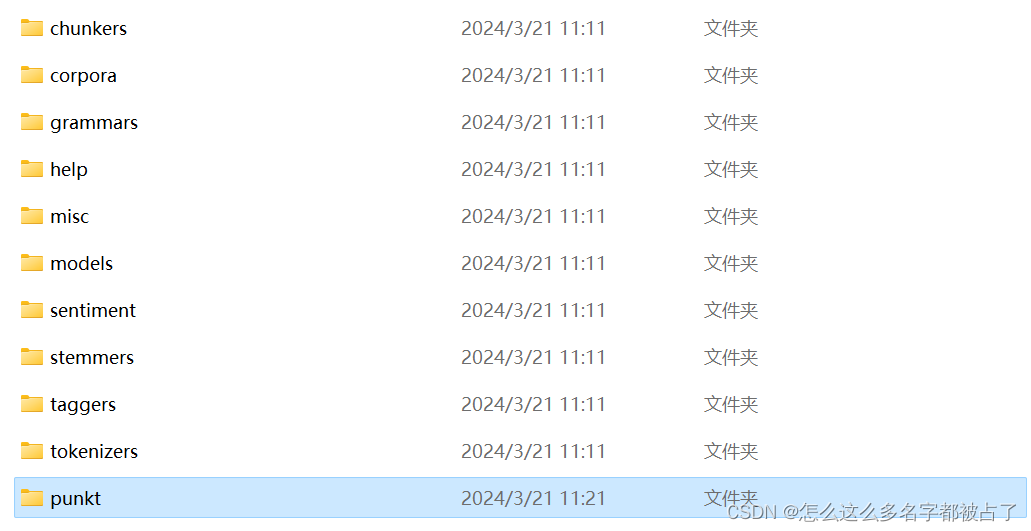
这样我们就做好了补全标点前的准备。
补全标点也很简单,它的基础用法如下:
from paddlespeech.cli.text.infer import TextExecutor
text_punc = TextExecutor()
result = text_punc(text=u"今天的天气真不错啊你下午有空吗我想约你一起去吃饭")
print(result)
输出:
今天的天气真不错啊!你下午有空吗?我想约你一起去吃饭。我们可以将补全标点和语音识别结合起来:
from paddlespeech.cli.asr.infer import ASRExecutor
from paddlespeech.cli.text.infer import TextExecutor
text_punc = TextExecutor()
asr = ASRExecutor()
asr_result = asr(audio_file="zh.wav")
result = text_punc(text=asr_result)
print(result)
输出:
我们说,四十二号混凝土不能与引力场相互搅拌,不然,会因为爱因斯坦的相对论,而引发炸串的食品安全问题,这是严重的金融危机。语音合成
语音合成可以使用TTSExecutor:
from paddlespeech.cli.tts.infer import TTSExecutor
tts = TTSExecutor()
tts(text="今天天气十分不错。", output="output.wav")最后会在当前目录下生成一个output.wav音频
参考
PaddleSpeech: Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation. (gitee.com)
[TTS]我运行语音专文本的示例代码报错 · Issue #3488 · PaddlePaddle/PaddleSpeech · GitHub
nltk包下载慢的解决方案(总结)_nltk download太慢-CSDN博客




![[Semi-笔记] 2023_TIP](https://img-blog.csdnimg.cn/direct/25f09a020f354e9d805a916d9df88b54.png)