目录
- 概要
- 一:Conservative-Progressive Collaborative Learning(保守渐进式协作学习)
- 挑战:
- 解决:
- 二:Pseudo Label Determination for Disagreement(伪标签分歧判定)
- 挑战:
- 解决:
- 三:Confidence-based Dynamic Loss(基于置信度的动态损失)
- 挑战:
- 解决:
- 实验结果
- 消融实验
- 小结
- 论文地址
- 代码地址
分享一篇2023年TIP的文章。
概要
伪标签在仅利用高质量伪标签和利用所有伪标签之间始终存在权衡。针对这个问题,这篇文章提出了一种新颖的学习方法,称为保守渐进协作学习(CPCL),其中两个预测网络并行训练,并根据两个预测的一致和不一致来实现伪监督。一个网络通过交集监督寻求共同点,并接受高质量标签的监督,以确保监督更可靠;而另一个网络通过联合监督保留差异,并接受所有伪标签的监督,从而实现保守进化与渐进探索的协同。为了减少可疑伪标签的影响,根据预测置信度对损失进行动态重新加权。
一:Conservative-Progressive Collaborative Learning(保守渐进式协作学习)
挑战:
尽管半监督学习仍处于起步阶段,但已经完成了一些开创性的工作。熵最小化和一致性正则化是近年来提出的两种典型方法。熵最小化方法首先在标记图像上训练的模型,之后在未标记图像上预测生成伪标签,并使用扩展训练数据重新训练模型。一致性正则化方法旨在强制预测在各种扰动下的不变性,包括对输入图像、特征和网络的扰动。
在伪监督过程中,这两种方法都存在确认偏差,这是由伪标签的错误引起的。为了解决这个问题,有一些工作采用预测置信度作为选择可靠伪标签的指标。虽然设置置信度阈值可以避免性能下降,但是很大一部分未标记的数据被浪费了。
解决:
在这项工作中,提出了保守渐进协作学习(CPCL),它分别通过仅使用高质量伪标签的交叉监督和使用大量伪标签的并集监督来训练两个并行网络,并实现保守的协作进化和渐进探索。两个网络具有相同的结构,但初始化不同。伪标签是根据两个网络对未标记图像的预测生成的。
具体来说,一个网络是保守的,由更可靠的“交叉”部分监督,而另一个网络是进步的,在“并集”部分的伪监督下探索不一致的预测。因此,两个网络在异构知识下进行训练,可以在一定程度上减少模型耦合问题。此外,预测置信度用于损失重新加权,以处理不可避免的噪声伪标签。具体框架如下:
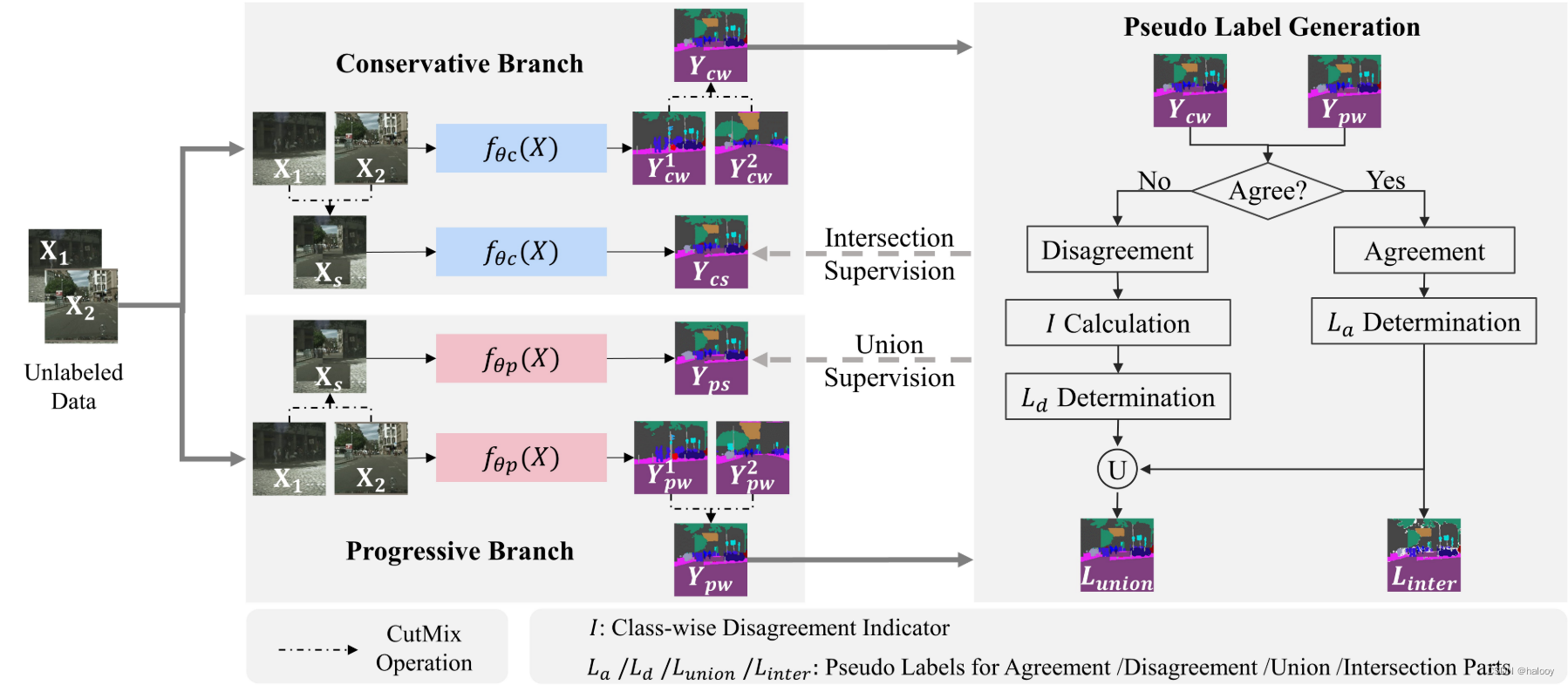
其由两个平行的分支组成,一个是保守分支,另一个是进步分支。
保守分支在交集伪标签的监督下,利用高质量的标签来确保更可靠的监督,而进步分支则在并集伪标签的监督下,实现对分歧部分的探索。每个分支中的分割网络共享相同的结构并具有不同的初始化。
通过输入两个未标记的图像 X1 和 X2,并利用强增强方法(例如 CutMix、CutOut 和 CowMix)生成增强图像 Xs。这篇文章采用CutMix,需要两个输入图像并基于随机掩模选择输出像素。
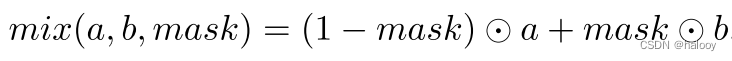
这就是CutMix的过程,a,b为两个输入图像,mask为随机生成的掩码。
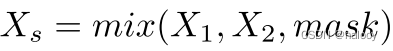
通过将两个输入图像X1和X2进行CutMix后生成增强后的图像Xs
以保守分支为例:
第一步:将三幅图像输入网络fθc(X),分割预测为Y1 cw、Y2 cw和Ycs。
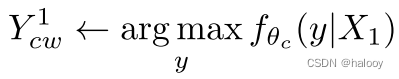
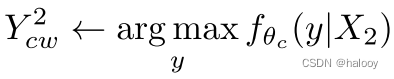
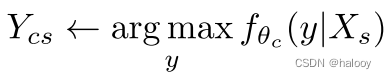
第二步:使用与输入相同的混合掩码进一步混合输出 Y1 cw 和 Y2 cw,结果为 Ycw。
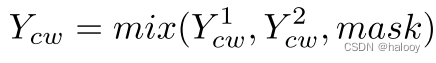
这一步相当于对两个输入图像X1和X2的伪标签进行相同的CutMix操作,其中的混合掩码相同,便于和数据增强后的输入图像Xs生成的伪标签进行后续对比。
类似地,我们可以得到另一个分支的相应输出,分别记为Y1 pw、Y2 pw、Yps,以及混合输出Ypw。
伪标签的生成是基于一致和不一致的,并且都是像素级的。对于像素pi,如果Ycw的预测与Ypw的预测相同,则两个网络在pi处达成一致,否则彼此不一致。
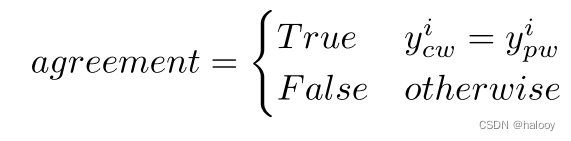
其中 yi cw 是 Ycw 在 pi 处的预测,yi pw 是 Ypw 的相应预测。
如果网络的两个预测彼此一致,则特定像素的伪标签很容易确定。它被确定为该像素处的预测。
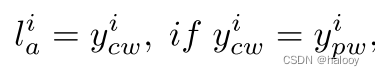
其中 li a 是像素 pi 处一致部分 La 的伪标签。然而,确定不一致部分 Ld 的逐像素伪标签要复杂得多,因为两个网络的预测不同。我们没有选择具有更高置信度的预测,而是根据类别分歧指标来确定伪标签,获得一致部分和不一致部分的伪标签(这将在下面详细阐述)。利用 La 和 Ld 混合Union Lunion 的伪标签
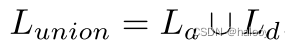
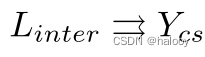
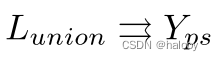
交集 Linter 的伪标签直接使用 La 生成。最后,将交集和并集伪监督分别应用于保守分支和渐进分支。
最后仅将网络保留在保守分支中以在推理模式下生成分割预测。
二:Pseudo Label Determination for Disagreement(伪标签分歧判定)
挑战:
典型且可行的方法是选择置信度较高的预测作为伪标签。然而,这种方法只关注精确像素的信息,这是有限的。
解决:
为了处理同一像素上两个预测之间的不一致,引入了一种基于类不一致指标的不一致部分的伪标签确定方法。转向整个预测的类别分歧指标,从宏观角度来看待。具体来说,构造一致性矩阵 M ∈ RC×C,如下图所示,并据此计算类别不一致指标 I。 I 较高的语义类别是困难类别,更容易引起混乱。像素pi处的伪标签,其中yi cw 不等于 yi pw,被确定为具有较高分歧指标的预测,以实现对具有强烈好奇心的分歧部分的渐进式探索。

协议矩阵的图示。 mj,k 是 yi cw 为 cj 且 yi pw 为 ck (j, k ∈ [1, C]) 的像素数,C 是类别数。当 j = k 时,两个预测一致,否则不一致。
基于类不一致指标的伪标签确定算法如算法1所示。

算法流程:
基于类分歧指标的伪标签判定算法
输入:保守分支Ycw的预测输出和进步分支Ypw的输出
输出:不一致部分 Ld 的伪标签
1.计算一致性矩阵M ∈ RC×C
2.计算类间分歧指标 I
3.确定像素pi处的伪标签
返回:Ld
这里针对第2步计算类间分歧指标作出自己的理解:
首先计算的一致性矩阵,mj,k 是保守分支预测 yi cw 为 j 类并且 进步分支预测yi pw 为 k 类的像素数量
根据类间分歧第一个公式 Ij 为例:
分子为mj,j 表示保守分支和进步分支预测相同的类的像素数量,分母则是总和,如果两个分支预测相同的数量占比大的话,则Ij 最终较小;举例:二分类问题,预测相同的数量为10预测不同的数量为1,则10/(10+1),接近于1。最后计算的I j 值小。
如果预测相同的数量为1,预测不同的数量为10,则1/(1+10),接近于0,最后计算的I j 值大。
因此I 较高的语义类别是困难类别
在第3步确定像素pi处的伪标签时,如果Ij大于Ik 则选择I j 。因为这里需要的是不一致部分的伪标签。
三:Confidence-based Dynamic Loss(基于置信度的动态损失)
挑战:
前面方法获得了未标记数据的伪标签。然而,噪声标签是不可避免的,并且生成的伪标签总是存在一些错误,因为它是由算法而不是人类自动注释的。许多研究探索了图像去噪算法,与图像噪声不同,伪标签噪声难以建模或去噪。
解决:
为了解决这个问题,提出了基于置信度的动态损失来处理不可靠的伪标签。与置信阈值相反,置信阈值需要预定义阈值并且无法充分利用所有未标记的数据,我们利用置信度来重新加权损失。逐像素预测置信度定义为最大 softmax 概率。令bi c 表示保守分支在第i个像素处的预测置信度,类似地,进步分支的预测置信度表示为bi p 。因此,基于置信度的动态权重定义为:
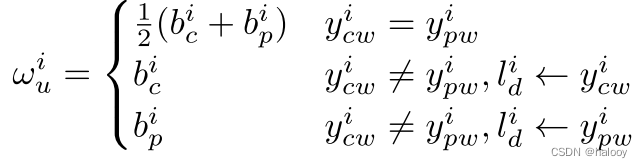
理解:第二行最后的Yi cw 逼近Li d,证明保守分支的预测趋近于不一致部分,代表bi c在该像素的预测置信度较低,则给这个像素的权重置为bi c,降低低置信度伪标签的影响。
因此,降低了低置信度的可疑伪标签的影响。未标记数据 LU 的重新加权损失定义为
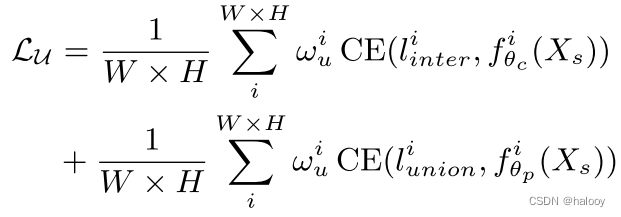
其中li inter和li union是Linter和Lunion在第i个像素处的伪标签,fi θ(Xs)是分割网络在第i个像素处对未标记图像Xs的输出,CE(· ) 是交叉熵损失函数。根据动态的基于置信度的权重,对每个像素的损失进行重新加权。
也就是保守分支只使用高置信度的像素进行CE损失学习,进步分支则对高低置信度的像素都进行学习。其权重也是用的动态基于置信度的权重,对每个像素的损失进行重新加权。
利用标记数据的训练是采用传统的监督方式。
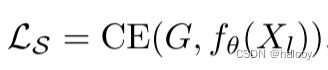
总损失:将监督训练和无监督训练的分离损失合并到整个训练目标中
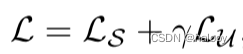
实验结果
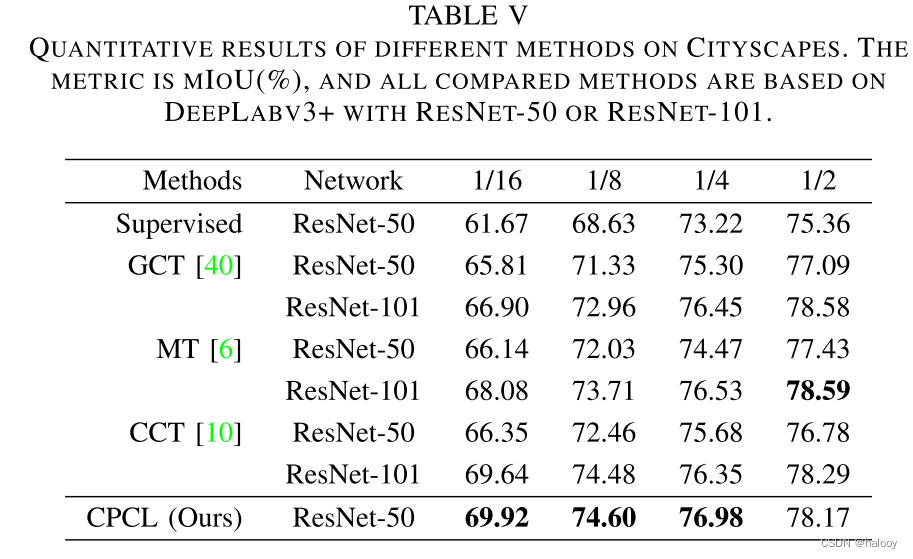
消融实验
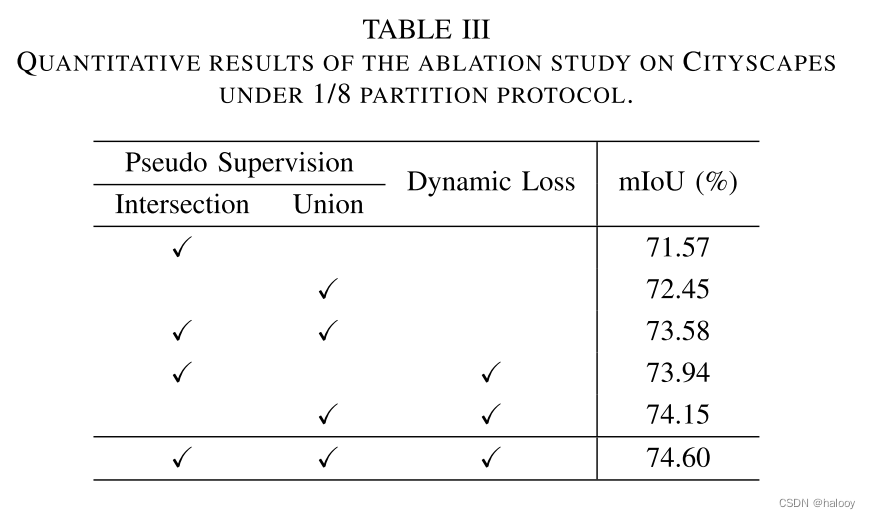
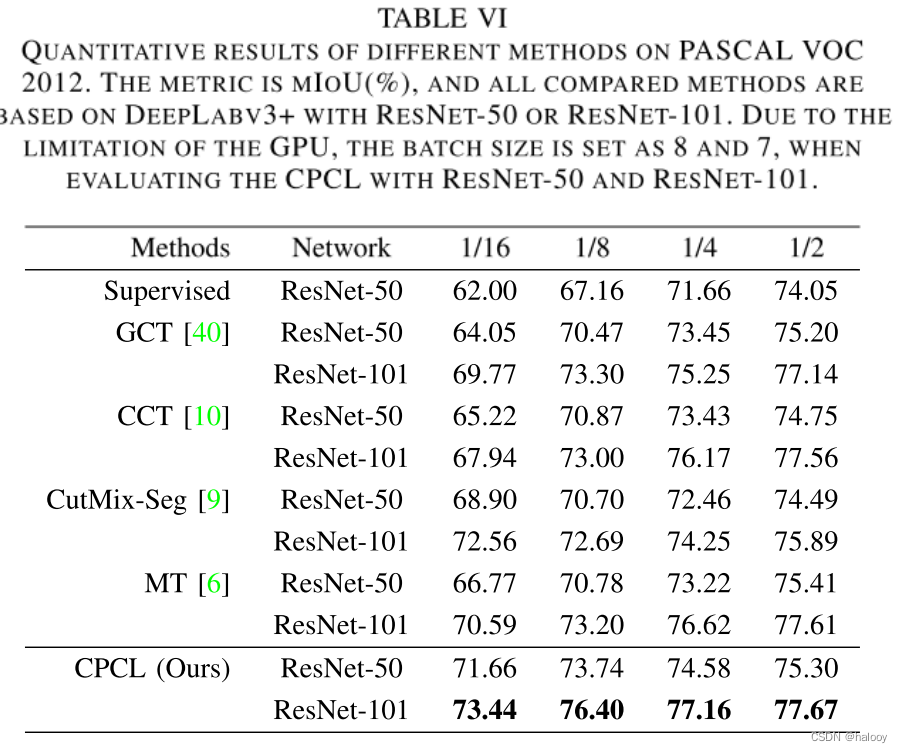
当不采用基于置信度的动态损失时,使用不重新加权的交叉熵损失函数。可以看出,所提出的三个模块都是有效的。针对噪声标签,提出了基于置信度的动态损失。由于引入动态损失,mIoU
分别增加了 2.37% 和 1.70%。交叉监督的改进更加明显,因为一致部分的伪标签的确定是像素级的,更容易受到噪声标签的影响。
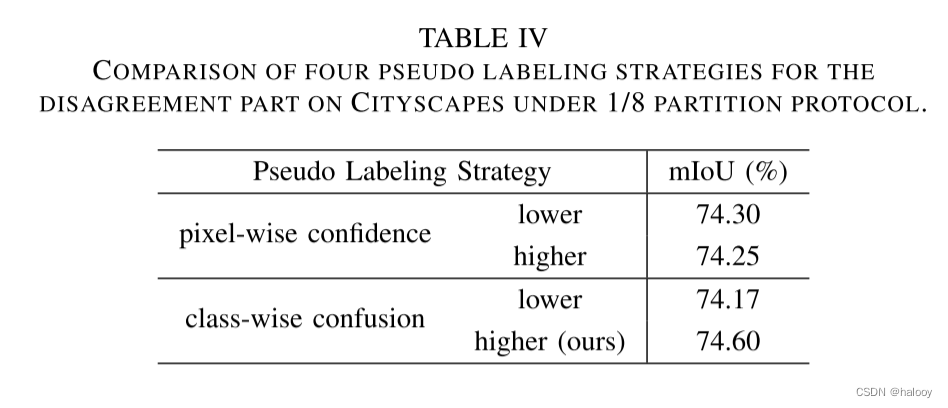
同时研究了针对分歧部分的不同伪标记策略并分析了定量结果。比较了四种相关策略,包括基于像素置信度(较高和较低)和类混淆(较高和较低)的伪标记,逐像素置信度表示确切像素的不确定性。
1.具有较高置信度的伪标记是常见的保守策略。然而,当与交叉口伪监督合作时,改进不太明显,因为两者都表现得保守。
2.基于较低置信度的探索是渐进的,但它更可能受到逐像素噪声的影响。所提出的动态损失可以在一定程度上减少影响,其mIoU达到74.30%。
3.与像素级置信度不同,类级混淆可以从宏观角度衡量语义歧义。混淆度较低的伪标记与基于较高置信度的伪标记类似,但在类别级别,四种比较策略中性能最差(74.17 mIoU)。
4.由于以强烈的好奇心探索困难的语义类,即混淆度较高的伪标签可能有助于模型进行局部优化,因此在 CPCL 中使用的所提出的策略取得了更好的性能。
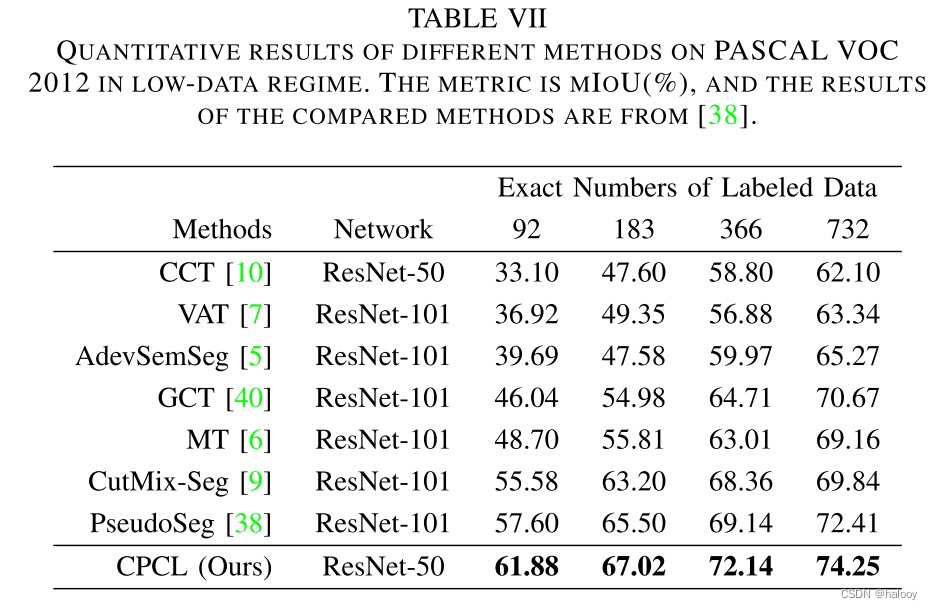
该方法在低数据情况下的性能优势是显而易见的。可以有效减少对标记数据的需求。
小结
这篇文章提出保守渐进协作学习(CPCL),不仅可以利用高质量标签的优势,还可以充分利用大量低质量的未标记的数据。在低数据量情况下也同时表现突出。
论文地址
pdf地址
代码地址
https://github.com