文章目录
- 一、线程的概念
- 1. 什么是线程
- Linux下并不存在真正的多线程,而是用进程模拟的!
- Linux没有真正意义上的线程相关的系统调用!
- 原生线程库pthread
- 2. 线程和进程的联系和区别
- 3. 线程的优点
- 4. 线程的缺点
- 5. 线程异常
- 6. 线程用途
- 二、二级页表
- 三、进程vs线程
- 四、Linux线程控制
- 1. POSIX线程库
- 2. 线程创建
- 让主线程创建一批新线程
- 获取线程ID
- 3. 线程等待
- 等待线程的函数叫做pthread_join
- 4. 线程终止
- 5. 线程分离
- 6. 线程ID的本质和进程地址空间布局
Linux多线程重点:
- 1.了解线程概念,理解线程与进程区别与联系。
- 2.学会线程控制,线程创建,线程终止,线程等待。
- 3.了解线程分离与线程安全概念。
- 4.学会线程同步。
- 5.学会使用互斥量,条件变量,posix信号量,以及读写锁。
- 6.理解基于读写锁的读者写者问题。
一、线程的概念
1. 什么是线程
课本观点:线程是比进程更加轻量化的一种执行流 / 线程是在进程内部执行的一种执行流
我们的观点:线程是CPU调度的基本单位 / 进程是承担系统资源的基本实体。
换言之,当我们创建进程时是创建一个task_struct、创建地址空间、维护页表,然后在物理内存当中开辟空间、构建映射,打开进程默认打开的相关文件、注册信号对应的处理方案等等。
- 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”。
- 一切进程至少都有一个执行线程。
- 线程在进程内部运行,本质是在进程地址空间内运行。
- 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更轻量化,从今天开始,我们把pcb称为轻量级进程(Light-weight process)。
- 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流。
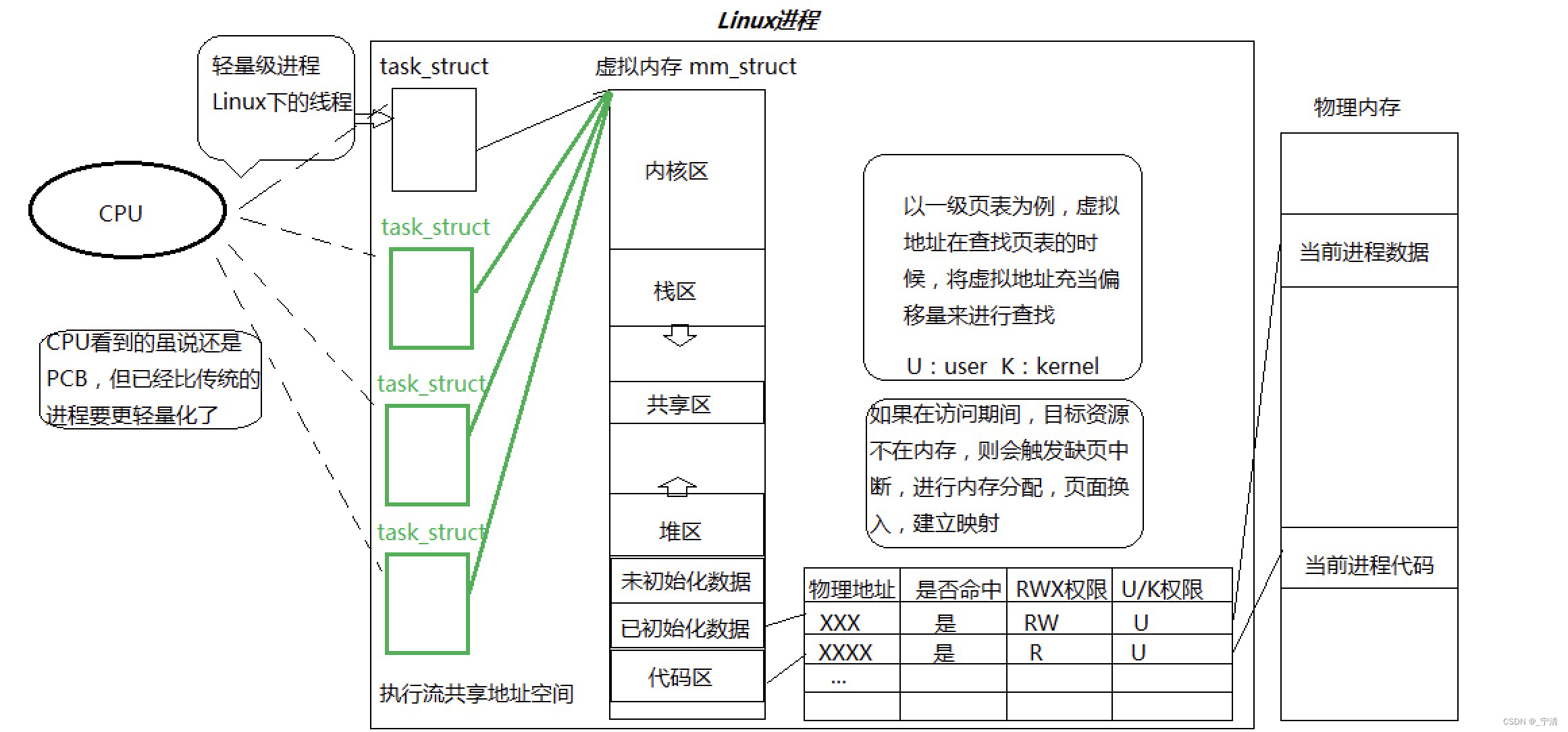
在Linux看来,描述线程的控制块和描述进程的控制块是类似的,因此Linux并没有重新为线程设计数据结构,而是直接复用了进程控制块,所以我们说Linux中的所有执行流都叫做轻量级进程。
但也有支持真的线程的操作系统,比如Windows操作系统,因此Windows操作系统系统的实现逻辑一定比Linux操作系统的实现逻辑要复杂得多。
Linux下并不存在真正的多线程,而是用进程模拟的!
操作系统中存在大量的进程,一个进程内又存在一个或多个线程,因此线程的数量一定比进程的数量多,当线程的数量足够多的时候,很明显线程的执行粒度要比进程更细。
如果一款操作系统要支持真的线程,那么就需要对这些线程进行管理。比如说创建线程、终止线程、调度线程、切换线程、给线程分配资源、释放资源以及回收资源等等,所有的这一套相比较进程都需要另起炉灶,搭建一套与进程平行的线程管理模块。
因此,如果要支持真的线程一定会提高设计操作系统的复杂程度。在Linux看来,描述线程的控制块和描述进程的控制块是类似的,因此Linux并没有重新为线程设计数据结构,而是直接复用了进程控制块,所以我们说Linux中的所有执行流都叫做轻量级进程。
但也有支持真的线程的操作系统,比如Windows操作系统,因此Windows操作系统系统的实现逻辑一定比Linux操作系统的实现逻辑要复杂得多。
Linux没有真正意义上的线程相关的系统调用!
既然在Linux中都没有真正意义上的线程了,那么自然也没有真正意义上的线程相关的系统调用了。但是Linux可以提供创建轻量级进程的接口,也就是创建进程,共享空间,其中最典型的代表就是vfork函数。
pid_t vfork(void);
vfork函数的返回值与fork函数的返回值相同:
- 给父进程返回子进程的PID。
- 给子进程返回0。
vfork的主要作用是为了在创建新进程时减少资源的开销,尤其是在子进程很快就会调用exec的情况下。它在性能上优于fork,但由于其特殊的语义,要小心使用以避免潜在的问题。在vfork中,父进程会被阻塞,直到子进程调用exec或者exit。这是因为子进程共享父进程的地址空间,如果父进程在子进程修改了这个地址空间之前继续执行,可能导致未定义的行为。
只不过vfork函数创建出来的子进程与其父进程共享地址空间,例如在下面的代码中,父进程使用vfork函数创建子进程,子进程将全局变量g_val由100改为了200,父进程休眠3秒后再读取到全局变量g_val的值。
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <unistd.h>
int g_val = 100;
int main()
{
pid_t id = vfork();
if (id == 0){
//child
g_val = 200;
printf("child:PID:%d, PPID:%d, g_val:%d\n", getpid(), getppid(), g_val);
exit(0);
}
//father
sleep(3);
printf("father:PID:%d, PPID:%d, g_val:%d\n", getpid(), getppid(), g_val);
return 0;
}
原生线程库pthread
在Linux中,站在内核角度没有真正意义上线程相关的接口,但是站在用户角度,当用户想创建一个线程时更期望使用thread_create这样类似的接口,而不是vfork函数,因此系统为用户层提供了原生线程库pthread。
原生线程库实际就是对轻量级进程的系统调用进行了封装,在用户层模拟实现了一套线程相关的接口。
因此对于我们来讲,在Linux下学习线程实际上就是学习在用户层模拟实现的这一套接口,而并非操作系统的接口。
pthread库并不是基于vfork来创建线程的。pthread库通常使用底层的系统调用,如clone。
2. 线程和进程的联系和区别
线程的特点:
- 线程创建更简单
- 线程是在进程内部执行的本质是:线程在进程的地址空间中运行
- Linux下的线程是用进程的pcb模拟的,所以Linux下的线程是轻量级进程。
- OS如果要支持线程,也像进程一样必须先管理进程,先描述再组织:TCB (T是thread)
进程的特点:
- 进程 = 内核数据结构 + 代码和数据
以前我们讲的进程:内部只有一个执行流的进程
今天我们讲的进程:内部可以有多个执行流的进程
3. 线程的优点
- 创建一个新线程的代价要比创建一个新进程小得多。
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多。
- 线程占用的资源要比进程少很多。
- 能充分利用多处理器的可并行数量。
- 在等待慢速IO操作结束的同时,程序可执行其他的计算任务。
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现。
- IO密集型应用,为了提高性能,将IO操作重叠,线程可以同时等待不同的IO操作。
[!info] 为什么线程切换效率高?
- 要换的寄存器少
- 不需要重新更新cache
4. 线程的缺点
- 性能损失: 一个很少被外部事件阻塞的计算密集型线程往往无法与其他线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
- 健壮性降低: 编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说,线程之间是缺乏保护的。
- 缺乏访问控制: 进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
- 编程难度提高: 编写与调试一个多线程程序比单线程程序困难得多。
5. 线程异常
- 单个线程如果出现除零、野指针等问题导致线程崩溃,进程也会随着崩溃。
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出。
6. 线程用途
- 合理的使用多线程,能提高CPU密集型程序的执行效率。
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)。
二、二级页表
在Linux下,虚拟内存管理使用页表来实现虚拟地址到物理地址的映射。对于32位的机器,虚拟地址空间是4GB(232),即这张表一共有232个映射表项: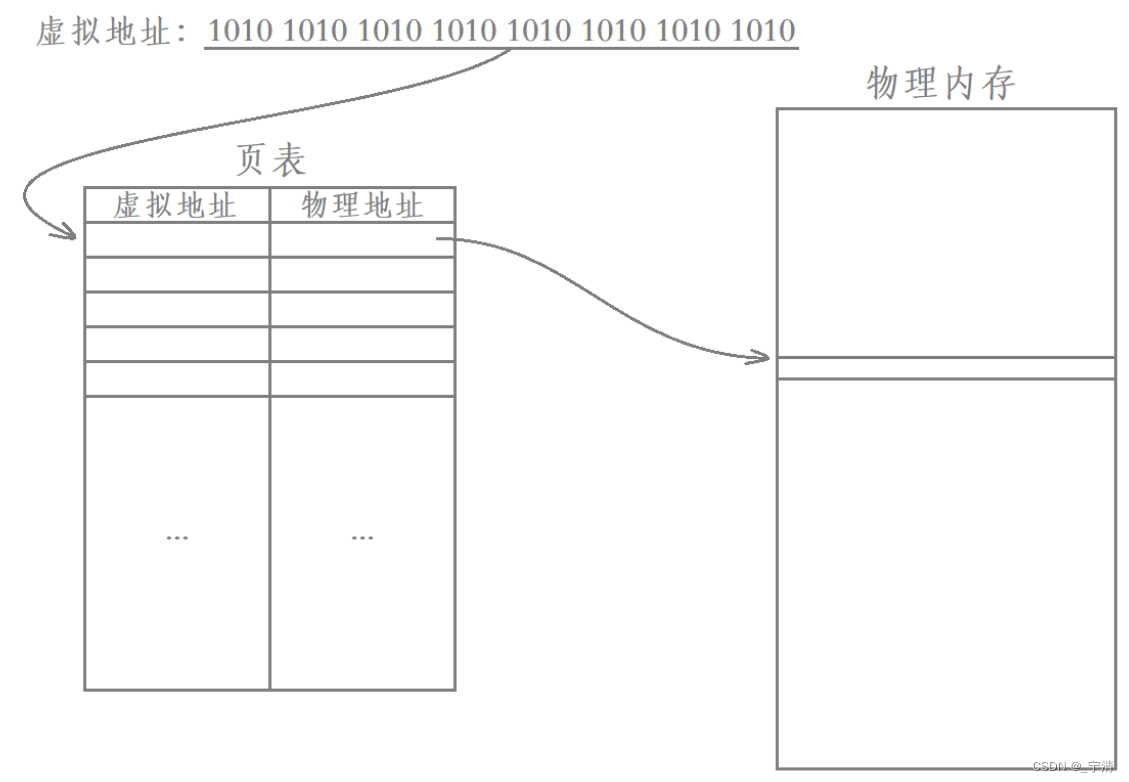
每一个表项中除了要有虚拟地址和与其映射的物理地址以外,实际还需要有一些权限相关的信息,比如我们所说的用户级页表和内核级页表,实际就是通过权限进行区分的:
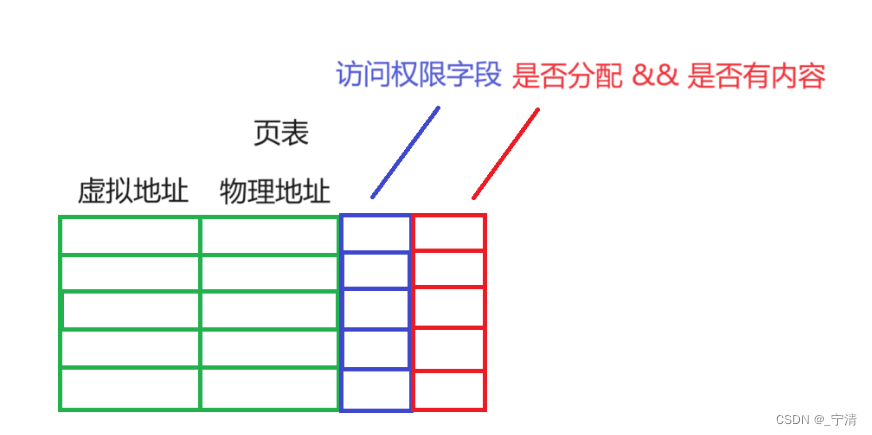
每个应表项中存储一个物理地址和一个虚拟地址就需要8个字节,考虑到还需要包含权限相关的各种信息,这里每一个表项就按10个字节计算。
这里一共有232个表项,也就意味着存储这张页表我们需要用232 * 10个字节,也就是40GB。而在32位平台下我们的内存可能一共就只有4GB,也就是说我们根本无法存储这样的一张页表。
因此所谓的页表并不是单纯的一张表!
在32位Linux系统中,最常见的是使用两级页表(也称为二级页表),即页目录表和页表:
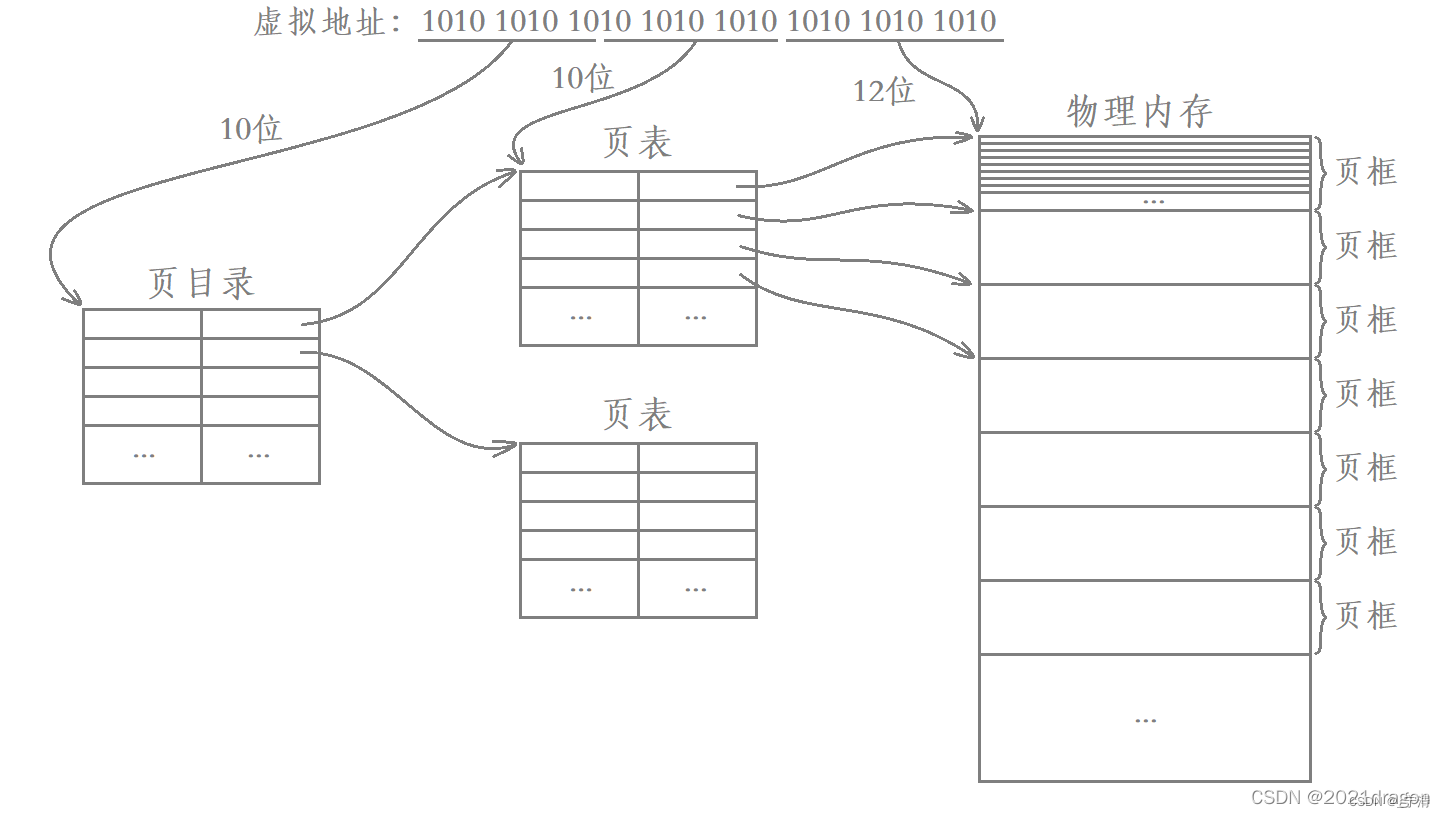
这实际上就是我们所谓的二级页表,其中页目录项是一级页表,页表项是二级页表。
32位系统下因为地址空间大小限制,虚拟地址空间大小为4GB。即使使用最小的页面大小(通常是4KB),也需要232个页面来覆盖整个地址空间。如果使用单层页表,那么需要232个页表项来进行映射,每个页表项占用4字节(32位系统),因此单个页表需要大约2^32 * 10个字节的空间。而这只是一个页表,如果是单层映射,需要存储整个地址空间的映射,这将需要非常大的空间,这在32位系统下是不切实际的。
因此,为了在32位Linux系统中实现有效的内存管理,需要使用二级页表来平衡地址空间大小的限制和内存管理的效率要求。划分页表的本质是划分进程地址空间!
三、进程vs线程
进程是承担分配系统资源的基本实体,线程是CPU调度的基本单位。
线程与进程共享的内容:
-
因为是在同一个地址空间,因此所谓的代码段(Text Segment)、数据段(Data Segment)都是共享的:
- 如果定义一个函数,在各线程中都可以调用。
- 如果定义一个全局变量,在各线程中都可以访问到。
-
进程资源和环境:
- 文件描述符表。(进程打开一个文件后,其他线程也能够看到)
- 每种信号的处理方式。(
SIG_IGN、SIG_DFL或者自定义的信号处理函数) - 当前工作目录。(cwd)
- 用户ID和组ID。
每个线程独有的数据:
- 线程ID。
- 一组寄存器。(存储每个线程的上下文信息)
- 栈。(每个线程都有临时的数据,需要压栈出栈)
- errno。(C语言提供的全局变量,每个线程都有自己的)
- 信号屏蔽字。
- 调度优先级。
四、Linux线程控制
1. POSIX线程库
pthread(POSIX Threads)是一种跨平台的线程库标准。POSIX Threads定义了一套线程API规范,可以在多个操作系统上使用,包括Linux。在Linux系统中,pthread库是一种实现这个规范的库,用于创建和管理线程。因此,pthread常常被称为Linux下的原生线程库,指的是它是Linux上支持POSIX线程规范的一种库。
pthread线程库是应用层的原生线程库:
- 应用层指的是这个线程库并不是系统接口直接提供的,而是由第三方帮我们提供的。
- “原生”指的是大部分Linux系统都会默认带上该线程库。
- 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的。
- 要使用这些函数库,要通过引入头文件<pthreaad.h>。
- 链接这些线程函数库时,要使用编译器命令的“-lpthread”选项。
错误检查:
- 传统的一些函数是,成功返回0,失败返回-1,并且对全局变量errno赋值以指示错误。
- pthreads函数出错时不会设置全局变量errno(而大部分POSIX函数会这样做),而是将错误代码通过返回值返回。
- pthreads同样也提供了线程内的errno变量,以支持其他使用errno的代码。对于pthreads函数的错误,建议通过返回值来判定,因为读取返回值要比读取线程内的errno变量的开销更小。
2. 线程创建
创建线程的函数叫做pthread_create
pthread_create - create a new thread
SYNOPSIS
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
Compile and link with -pthread.
参数说明:
- thread:获取创建成功的线程ID,该参数是一个输出型参数。
- attr:用于设置创建线程的属性,传入nullptr表示使用默认属性。
- start_routine:该参数是一个函数地址,表示线程例程,即线程启动后要执行的函数。
- arg:传给线程例程的参数。
线程创建成功返回0,失败返回错误码。
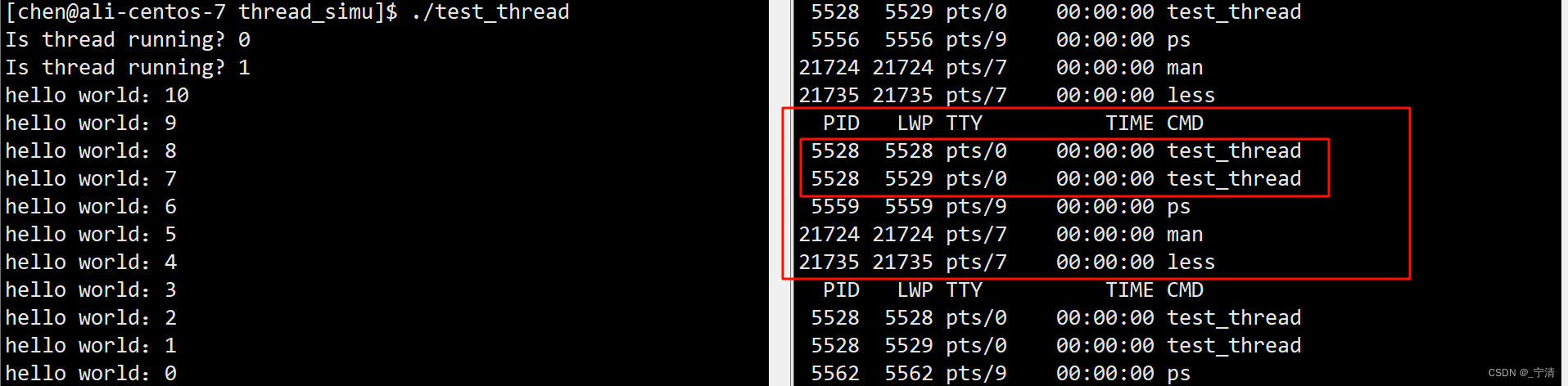
使用ps -aL命令,可以显示当前的轻量级进程。
- 默认情况下,不带
-L,看到的就是一个个的进程。 - 带
-L就可以查看到每个进程内的多个轻量级进程。
while :; do ps -aL; sleep 1; done
让主线程创建一批新线程
#include <iostream>
#include <unistd.h>
#include <pthread.h>
#include <functional>
#include <vector>
using namespace std;
using func_t = std::function<void()>;
const int threadnum = 5;
class ThreadData
{
public:
ThreadData(const std::string& name, const uint64_t& ctime, func_t f)
:threadname(name)
, createtime(ctime)
, func(f)
{}
public:
std::string threadname;
uint64_t createtime;
func_t func;
};
void Print()
{
std::cout << "我是线程执行的大任务的一部分" << std::endl;
}
// 新线程
void* ThreadRoutine(void* args)
{
int a = 10;
ThreadData* td = static_cast<ThreadData*>(args);
while (true)
{
std::cout << "new thread"
<< " thread name: " << td->threadname << " create time: " << td->createtime << std::endl;
td->func();
// if(td->threadname == "thread-4")
// {
// std::cout << td->threadname << " 触发了异常!!!" << std::endl;
// a /= 0; // 故意制造异常
// }
sleep(1);
}
}
int main()
{
std::vector<pthread_t> pthreads;
for (size_t i = 0; i < threadnum; i++)
{
char threadname[64];
snprintf(threadname, sizeof(threadname), "%s-%d", "thread", i + 1);
pthread_t tid; // 线程id typedef unsigned long int pthread_t;
ThreadData* td = new ThreadData(threadname, (uint64_t)time(nullptr), Print);
pthread_create(&tid, nullptr, ThreadRoutine, td);
pthreads.push_back(tid);
sleep(1);
}
std::cout << "thread id: ";
for (const auto& tid : pthreads)
{
std::cout << tid << ",";
}
std::cout << std::endl;
while (true)
{
std::cout << "main thread" << std::endl;
sleep(3);
}
return 0;
}
LWP(Light Weight Process)就是轻量级进程的ID,可以看到显示的两个轻量级进程的PID是相同的,因为它们属于同一个进程:
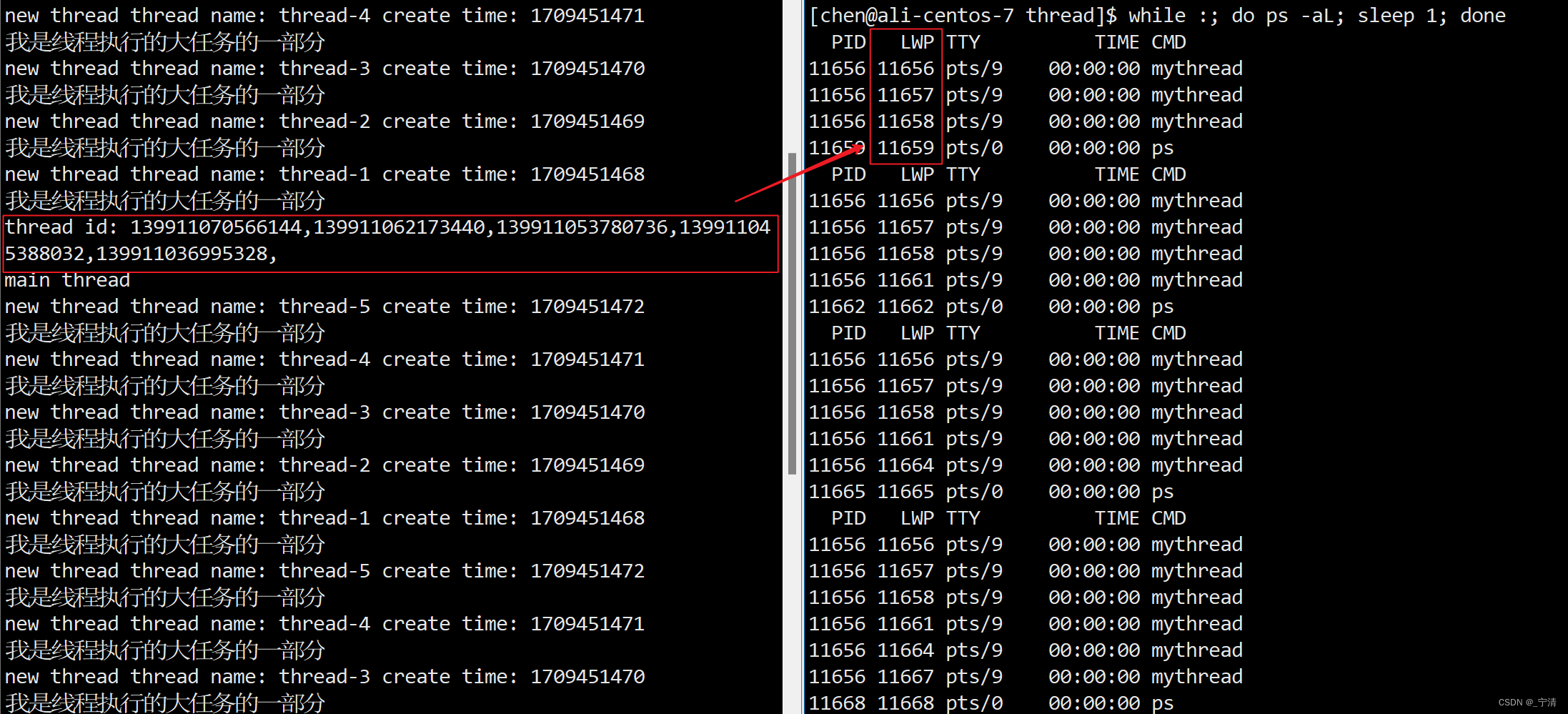
注意: 用pthread_self函数获得的线程ID与内核的LWP的值是不相等的,pthread_self函数获得的是用户级原生线程库的线程ID,而LWP是内核的轻量级进程ID,它们之间是一对一的关系。
获取线程ID
常见获取线程ID的方式有两种:
- 创建线程时通过输出型参数获得。
- 通过调用pthread_self函数获得。
pthread_t pthread_self(void);
示例:
using namespace std;
const int threadnum = 5;
// 新线程
void* ThreadRoutine(void* args)
{
std::cout << "我是新线程,通过pthread_self获得的线程id是:" << pthread_self() << std::endl;
}
int main()
{
std::vector<pthread_t> pthreads;
for (size_t i = 0; i < threadnum; i++)
{
pthread_t tid; // 线程id typedef unsigned long int pthread_t;
pthread_create(&tid, nullptr, ThreadRoutine, nullptr);
pthreads.push_back(tid);
sleep(1);
}
std::cout << "直接打印pthread_t线程id:" << std::endl;
for (const auto& tid : pthreads)
{
std::cout << tid << std::endl;
}
// 线程等待
for (const auto& tid : pthreads)
{
pthread_join(tid, nullptr);
}
return 0;
}
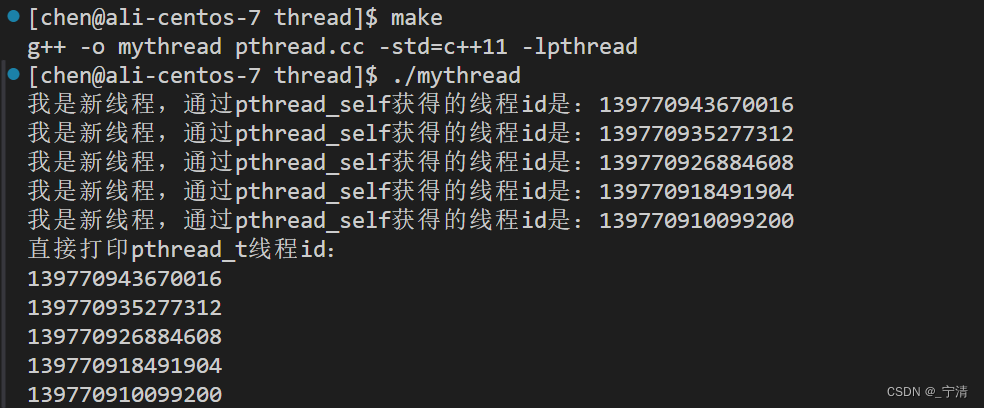
线程ID与内核的LWP的值是不相等的:
- pthread_self函数获得的是用户级的POSIX程库的线程ID
- LWP是内核的轻量级进程ID
- 它们之间是一对一的关系
3. 线程等待
等待线程的函数叫做pthread_join
int pthread_join(pthread_t thread, void **retval);
- thread:被等待线程的ID。
- retval:线程退出时的退出码信息,这是一个输出型参数
总结如下:
-
如果thread线程通过return返回,retval所指向的是thread线程函数的返回值。
-
如果thread线程被别的线程调用pthread_cancel异常终止掉,retval所指向的单元里存放的是常数
PTHREAD_CANCELED,用grep命令查询它:
grep -ER "PTHREAD_CANCELED" /usr/include/ -
如果thread线程是自己调用pthread_exit终止的,retval所指向的单元存放的是传给pthread_exit的参数。
-
如果对thread线程的终止状态不感兴趣,可以传
nullptr给retval参数。
[!Question] 为什么线程退出时只能拿到线程的退出码?
如果我们等待的是一个进程,那么当这个进程退出时,我们可以通过wait函数或是waitpid函数的输出型参数status,获取到退出进程的退出码、退出信号以及core dump标志。
那为什么等待线程时我们只能拿到退出线程的退出码?难道线程不会出现异常吗?
线程在运行过程中当然也会出现异常,线程和进程一样,线程退出的情况也有三种:
- 代码运行完毕,结果正确。
- 代码运行完毕,结果不正确。
- 代码异常终止。
因此我们也需要考虑线程异常终止的情况,但是pthread_join函数无法获取到线程异常退出时的信息。因为线程是进程内的一个执行分支,如果进程中的某个线程崩溃了,那么整个进程也会因此而崩溃,此时我们根本没办法执行pthread_join函数,因为整个进程已经退出了。
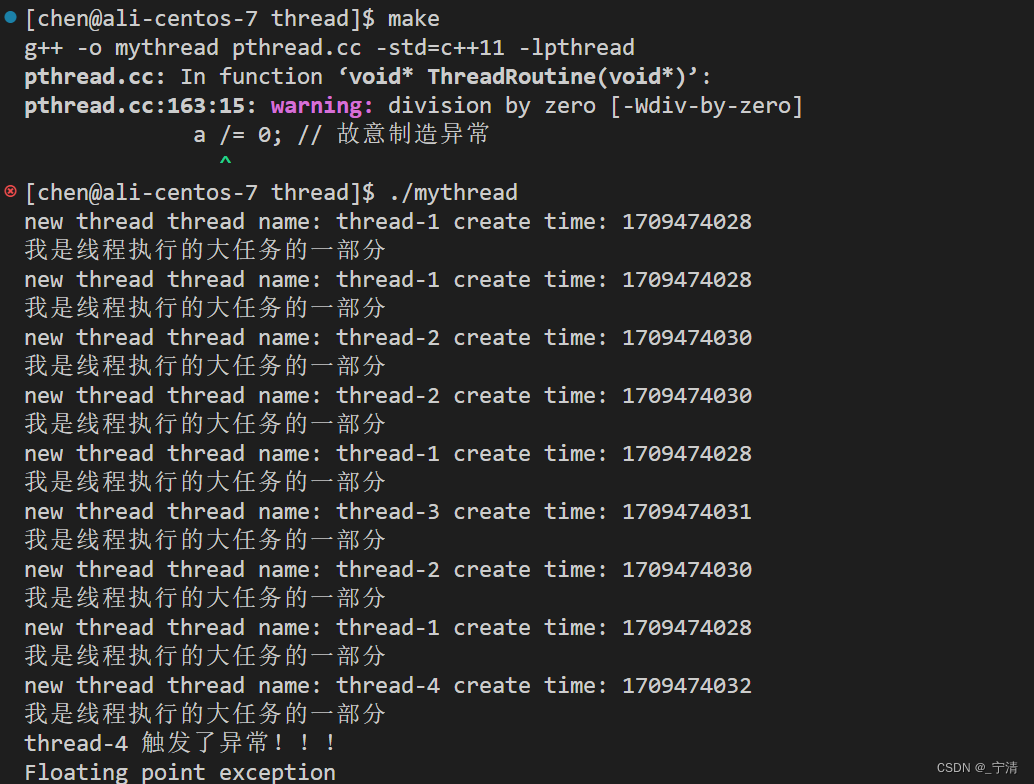
例如,我们在线程的执行例程当中制造一个除零错误,当某一个线程执行到此处时就会崩溃,进而导致整个进程崩溃。
// 新线程 void* ThreadRoutine(void* args) { int a = 10; ThreadData* td = static_cast<ThreadData*>(args); while (true) { std::cout << "new thread" << " thread name: " << td->threadname << " create time: " << td->createtime << std::endl; td->func(); if(td->threadname == "thread-4") { std::cout << td->threadname << " 触发了异常!!!" << std::endl; a /= 0; // 故意制造异常 } sleep(1); } }
4. 线程终止
如果需要只终止某个线程而不是终止整个进程,可以有三种方法:
- 从线程函数return。
- 线程可以自己调用pthread_exit函数终止自己。
- 一个线程可以调用pthread_cancel函数终止同一进程中的另一个线程。
5. 线程分离
- 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成内存泄漏。
- 但如果我们不关心线程的返回值,join也是一种负担,此时我们可以将该线程进行分离,后续当线程退出时就会自动释放线程资源。
- 一个线程如果被分离了,这个线程依旧要使用该进程的资源,依旧在该进程内运行,甚至这个线程崩溃了一定会影响其他线程,只不过这个线程退出时不再需要主线程去join了,当这个线程退出时系统会自动回收该线程所对应的资源。
- 可以是线程组内其他线程对目标线程进行分离,也可以是线程自己分离。
- joinable和分离是冲突的,一个线程不能既是joinable又是分离的。
分离线程的函数叫做pthread_detach
int pthread_detach(pthread_t thread);
参数说明:
- thread:被分离线程的ID。
返回值说明:
- 线程分离成功返回0,失败返回错误码。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
void* Routine(void* arg)
{
pthread_detach(pthread_self());
char* msg = (char*)arg;
int count = 0;
while (count < 5)
{
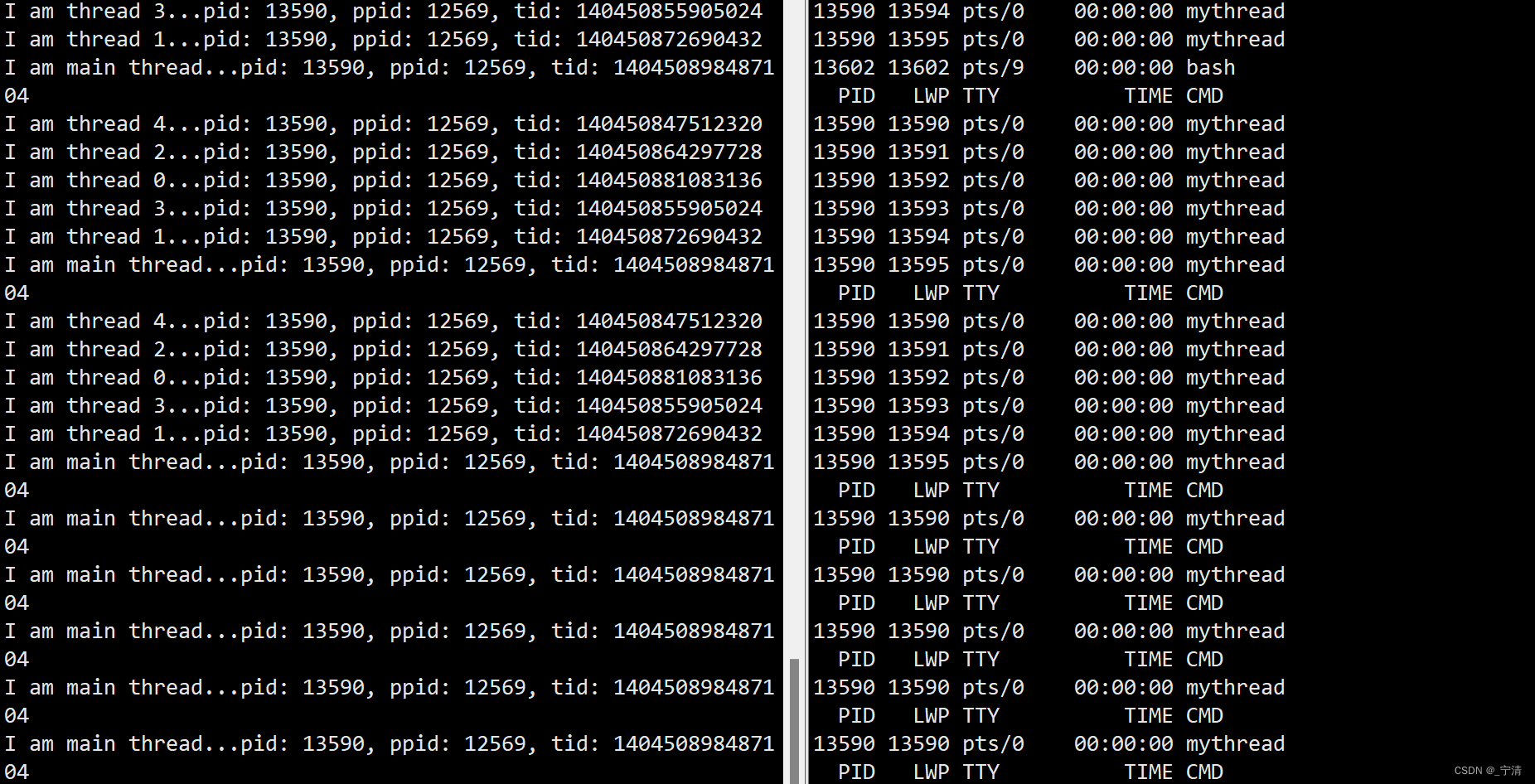
printf("I am %s...pid: %d, ppid: %d, tid: %lu\n", msg, getpid(), getppid(), pthread_self());
sleep(1);
count++;
}
pthread_exit((void*)6666);
}
int main()
{
pthread_t tid[5];
for (int i = 0; i < 5; i++)
{
char* buffer = (char*)malloc(64);
sprintf(buffer, "thread %d", i);
pthread_create(&tid[i], NULL, Routine, buffer);
printf("%s tid is %lu\n", buffer, tid[i]);
}
while (1)
{
printf("I am main thread...pid: %d, ppid: %d, tid: %lu\n", getpid(), getppid(), pthread_self());
sleep(1);
}
return 0;
}
6. 线程ID的本质和进程地址空间布局
- pthread_create函数会产生一个线程ID,存放在第一个参数指向的地址中,该线程ID和内核中的LWP不是一回事。
- 内核中的LWP属于进程调度的范畴,因为线程是轻量级进程,是操作系统调度器的最小单位,所以需要一个数值来唯一表示该线程。
- pthread_create函数第一个参数指向一个虚拟内存单元,该内存单元的地址即为新创建线程的线程ID,这个ID属于NPTL线程库的范畴,线程库的后续操作就是根据该线程ID来操作线程的。
- 线程库NPTL提供的pthread_self函数,获取的线程ID和pthread_create函数第一个参数获取的线程ID是一样的。
pthread_t到底是什么类型呢?
首先,Linux不提供真正的线程,只提供LWP,也就意味着操作系统只需要对内核执行流LWP进行管理,而供用户使用的线程接口等其他数据,应该由线程库自己来管理,因此管理线程时的“先描述,再组织”就应该在线程库里进行。
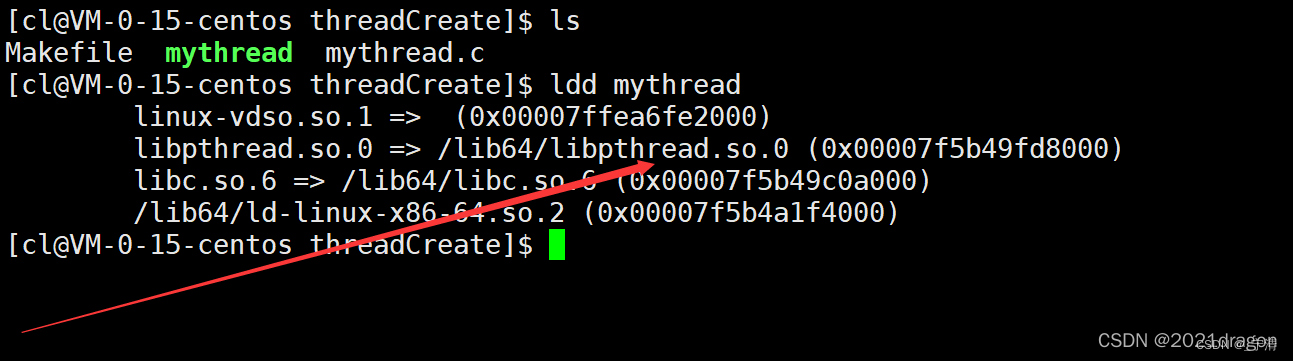
通过
ldd命令可以看到,我们采用的线程库实际上是一个动态库。
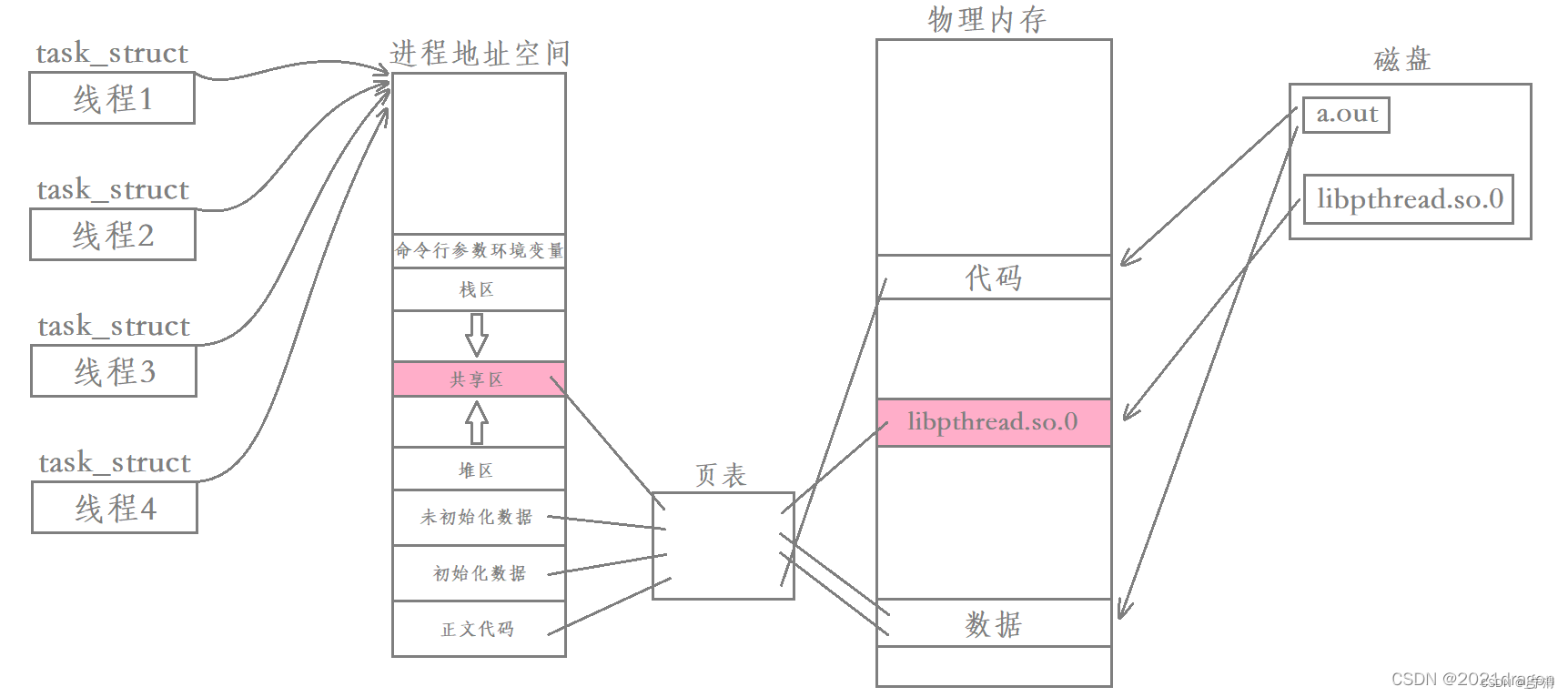
进程运行时动态库被加载到内存,然后通过页表映射到进程地址空间中的共享区,此时该进程内的所有线程都是能看到这个动态库的。
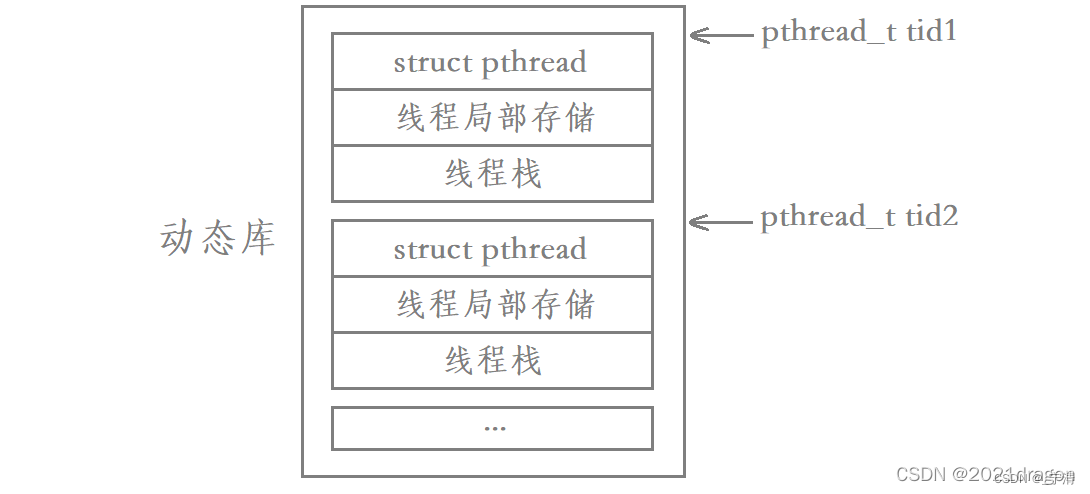
我们说每个线程都有自己私有的栈,其中主线程采用的栈是进程地址空间中原生的栈,而其余线程采用的栈就是在共享区中开辟的。除此之外,每个线程都有自己的struct pthread,当中包含了对应线程的各种属性;每个线程还有自己的线程局部存储,当中包含了对应线程被切换时的上下文数据。
每一个新线程在共享区都有这样一块区域对其进行描述,因此我们要找到一个用户级线程只需要找到该线程内存块的起始地址,然后就可以获取到该线程的各种信息。
上面我们所用的各种线程函数,本质都是在库内部对线程属性进行的各种操作,最后将要执行的代码交给对应的内核级LWP去执行就行了,也就是说线程数据的管理本质是在共享区的。
pthread_t到底是什么类型取决于实现,但是对于Linux目前实现的NPTL线程库来说,线程ID本质就是进程地址空间共享区上的一个虚拟地址,同一个进程中所有的虚拟地址都是不同的,因此可以用它来唯一区分每一个线程。
例如,我们也可以尝试按地址的形式对获取到的线程ID进行打印。