基于课堂上学到的以及书上的看到的,总结出的数据库复习资料
一、数据库概述
- 基本概念
1.数据
数据(Data)是事物的符号表示,可以是声音、图像、文字、数字,也可以是计算机代码。
2.数据库
数据库(DataBase,DB)是一个长期存储在计算机内的,有组织的、共享的、统一管理的数据集合。具有较小的冗余、较高的数据独立性和易扩展性,并可以为各种用户共享。
3.数据库管理系统
数据库管理系统(DataBase Management System,DBMS)是位于用户和操作系统之间的一个数据管理软件,用于建立、使用和维护数据库,可以理解为用户与数据库的接口。
DBMS的主要功能有:
① 数据定义功能:提供数据定义语言,定义数据库和数据库对象
②数据操纵功能:提供数据操纵语言,对数据进行增删改查等操作
③数据控制功能:提供数据控制语言,提供数据的安全性、完整性、并发控制等功能
④数据库建立维护功能
4.数据库管理员
数据库管理员(DataBase Administrator,DBA)是一个负责管理和维护数据库服务器的人。
5.数据库系统
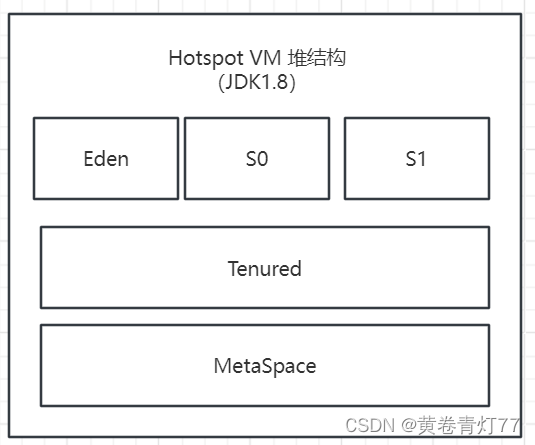
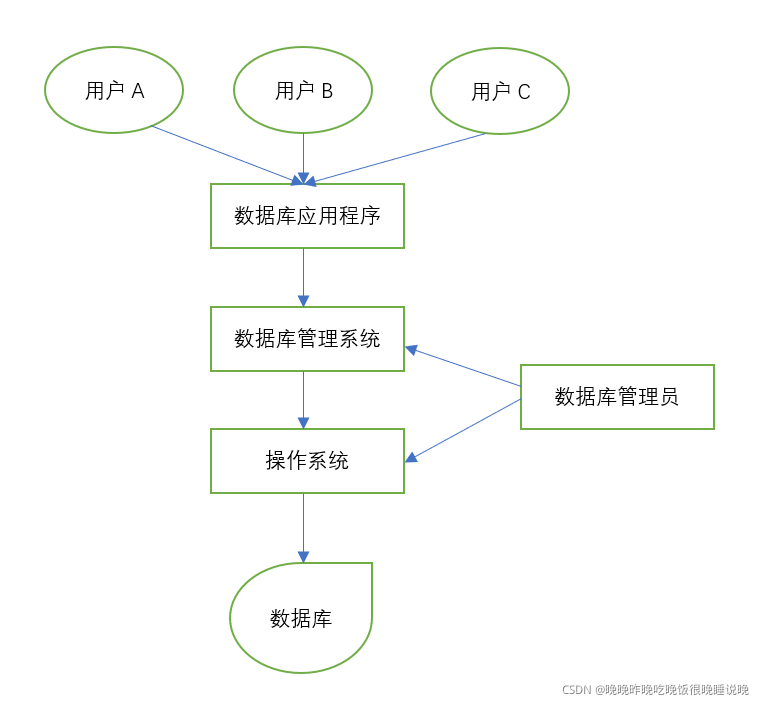
数据库系统(DataBase System,DBS),又称数据库应用系统,是由数据库(DB)、操作系统、数据库管理系统(DBMS)、数据库应用程序、用户、数据库管理员组成的用于存储、管理、处理和维护数据的系统。
这就是数据库系统的结构:
- 数据管理技术的发展
数据管理技术的发展经历了人工管理阶段、文件系统阶段、数据库系统阶段。
- 三级模式结构
模式是指对数据的逻辑结构或物理结构、数据特征、数据约束的定义和描述。模式是对数据的一种抽象,模式反映数据的本质、核心或类型等方面。
数据库系统是三级模式结构,分别是外模式、模式、内模式。
①外模式又称子模式或用户模式,是三级模式的最外层,一个数据库可以有多个外模式,但一个应用程序只能使用一个外模式。
②模式又称概念模式或逻辑模式,位于中间层,一个数据库只有一个模式。
③内模式又称存储模式,位于底层,一个数据库只有一个内模式。
- 二级映射
数据库管理系统在这三级模式之间提供了两级映射:外模式/模式映射、模式/内模式映射。
- 数据模型
在开发设计数据库应用系统时需要使用不同的数据模型,分别是概念数据模型、逻辑数据模型、物理数据模型。
1.概念数据模型
面向现实世界建模,通过各种概念来描述现实世界的事物以及事物之间的联系,主要用于数据库设计。最常用的概念模型是E-R模型(实体-联系模型)。
2.逻辑数据模型
面向用户建模,是事物及事物之间联系的数据描述,提供了表示和组织数据的方法。主要的逻辑模型有层次模型、网状模型、关系模型、面向对象数据模型、对象关系数据模型和半结构化数据模型等。
3.物理数据模型
面向计算机系统的,是对数据底层的抽象,它描述数据在系统内部的表示方法和存取方法。
- 概念模型
概念模型又称信息模型,是现实世界到机器世界的一个中间层次。
有以下概念:
1.实体
客观存在并可以相互区别的事物称为实体。实体可以是具体的人、事、物或抽象的概念,实体用矩形框表示。
2.属性
实体所具有的某一特性称为属性。属性采用椭圆框表示。
3.码
能唯一标识实体的最小属性集,又称为键或关键字。
4.实体型
用实体名及其属性集合来抽象和刻画同类实体。如学生(姓名,学号,性别)。
5.实体集
同类型的实体的集合称为实体集。如全体学生记录就是一个实体集。
6.域
属性的取值范围称为该属性的域。
7.联系
两个实体集之间的联系包括一对一联系、一对多联系、多对多联系。
联系由菱形框表示。
- 关系数据库
1.概念
数据模型是严格定义的一组概念的集合,一般由数据结构(静态)、数据操作(动态)、数据完整性约束三部分组成。
通常数据库的类型是按照数据所存储的结构的类型来命名的数据模型,常见的数据模型有层次模型、网状模型、关系模型和面向对象模型。最常用的是关系模型。关系模型是指用二维表的形式表示实体以及实体间联系的数据模型,一个关系就是一张二维表。
关系数据库系统是支持关系模型的数据库系统。
2.基本名词
①元组:关系表中每一横行称作一个元组,也称为记录。
②属性:每一列称为一个属性,也称为字段。
③候选码、主码、全码
- 数据库设计
数据库系统设计基本步骤分为:
①需求分析阶段
②概念设计阶段
③逻辑设计阶段
④物理设计阶段
⑤数据库实施阶段
⑥运行和维护阶段
二、数据库管理
- SQL Server数据库概述
SQL(Structured Query Language)语言,即结构化查询语言,是关系数据库的标准语言,是一种高级的非过程化编程语言。
SQL语言分为四类:
①数据定义语言(Data Definition Language,DDL),用于定义数据库对象,如表、视图、索引等数据库对象,包括create、alter、drop等语句。
②数据操纵语言(Data Manipulation Language,DML),包括insert、update、delete等语句。
③数据查询语言(Data Query Language,DQL),select语句。
④数据控制语言(Data Control Language,DCL),用于控制用户对数据库的操作权限,包括grant、revoke等语句。
1.逻辑数据库
组成数据库的逻辑成分称为数据库对象,常用的数据库对象包括表、视图、索引、存储过程、触发器等。
SQL Server的数据库有两类:系统数据库、用户数据库。
SQL Server在安装时自动创建5个系统数据库:master、model、msdb、tempdb、resource(不可见)。
2.物理数据库
SQL Server的物理数据库架构包括页和区、数据库文件、数据库文件组等。
(1)页和区是SQL Server数据库的两个主要数据存储单位。
页:用于数据存储的最基本单位。每个页的大小是8KB,每1MB的数据文件可以容纳128页。(1MB=1024KB)
区:用于控制表和索引的存储。每8个连接的页组成一个区,区的大小是64KB,1MB的数据库有16个区。
(2)SQL Server采用操作系统文件来存放数据库,使用的文件有主数据文件、辅助数据文件、日志文件。
主数据文件:用于存储数据,一个数据库只能有一个主文件,默认扩展名为.mdf。
辅助/次要数据文件:用于存储数据,可以创建多个或不创建,默认扩展名为.ndf。
日志文件:用于保存恢复数据库所需的事务日志信息,一个数据库至少有一个或多个日志文件,默认扩展名为.ldf。
(3)SQL Server提供了两类文件组,主文件组和用户定义文件组。
主文件组(PRIMARY 文件组):由系统定义,里面包含主要数据文件和次要数据文件。每个数据库有一个主文件组,主文件组也是默认文件组。
用户定义文件组:由用户定义,用于将多个次要数据文件集合起来。
一个数据文件只能属于一个文件组,事务日志文件不能属于任何文件组。
- 创建数据库
create database 数据库名
on [ primary ]
( name='逻辑名',
filename='物理名'
[ ,size=自定义容量 ]
[ ,maxsize=最大容量 / unlimited ]
[ ,filegrowth=增长量 [KB/MB/GB/TB/%] ] )
,filegroup 自定义文件组名
( name='逻辑名',
filename='物理名.ndf'
[ ,size=自定义容量 ]
[ ,maxsize=最大容量 / unlimited ]
[ ,filegrowth=增长量 [KB/MB/GB/TB/%] ] )
log on
( name='逻辑名',
filename='物理名.ldf'
[ ,size=自定义容量 ]
[ ,maxsize=最大容量 / unlimited ]
[ ,filegrowth=增长量 [KB/MB/GB/TB/%] ] )
- 选择数据库
use 数据库名
- 查看数据库
sp_helpdb 数据库名
> 或者
> 查看所有数据库信息
sp_helpdb
- 修改数据库
alter database 数据库名
> 增加数据文件到数据库
add file (数据文件信息...)
[ to filegroup 文件组名 ]
> 增加事务日志文件到数据库
add log file (数据文件信息...)
> 删除文件
remove file 逻辑名
> 增加文件组
add filegroup 文件组名
> 删除文件组(且文件组为空)
remove filegroup 文件组名
> 更改文件属性(且一次只能改一个)
modify file (数据文件信息...)
> 更改数据库名称
modify name=新数据库名
eg:
--********** create student database **********--
--********** Begin **********--
create database student
on primary
(
name='studentdata1',
filename='/home/studentdata1.mdf',
size=5mb,
maxsize=10mb,
filegrowth=1mb
),
filegroup fg1
(
name='studentdata2',
filename='/home/studentdata2.ndf',
size=5mb,
maxsize=10mb,
filegrowth=1mb
)
log on(
name='studentlog1',
filename='/home/studentlog1.ldf',
size=5mb,
maxsize=10mb,
filegrowth=1mb
)
--********** End **********--
go
--********** add database file **********--
--********** Begin **********--
alter database student
add file
(
name='studentdata3',
filename='/home/studentlog3.ndf',
size=6mb,
maxsize=20mb,
filegrowth=1mb
)
--********** End **********--
go
--********** add database log file **********--
--********** Begin **********--
alter database student
add log file
(
name='studentlog2',
filename='/home/studentlog2.ldf',
size=6mb,
maxsize=20mb,
filegrowth=1mb
)
--********** End **********--
go
--********** alter database file **********--
--********** Begin **********--
alter database student
modify file
(
name='studentdata3',
size=8mb,
maxsize=30mb
)
--********** End **********--
go
- 收缩数据库
> 自动收缩数据库
alter database 数据库名 set auto_shrink on
> 自定义收缩数据库( 使其还剩百分之n可用 )
dbcc shrinkdatabase ( 数据库名,收缩的百分比 )
> 自定义收缩文件
dbcc shrinkfile ( 逻辑名,文件大小 )
- 删除数据库
drop database 数据库名
- 分离和附加数据库
> 分离数据库
exec sp_detach_db [@dbname=] '数据库名'
> 附加数据库
exec sp_attach_db [@dbname=] '数据库名',
[@filename1=]'物理名.mdf'
三、表的管理
- 相关概念
(1)数据完整性
①实体完整性 / 行完整性:用来保证表中每一行数据在表中是唯一的。措施:primary key约束,unique约束,identity列。
②域完整性 / 列完整性:用来保证数据表特定列输入的有效性与正确性,指数据库中的数据列必须满足某种特定的数据类型和数据约束。措施:限制数据的类型或格式,check约束,default约束,not null约束或规则。
③参照完整性 / 引用完整性:建立在外键与主键或外键与唯一键之间的一种引用规则,确保主表的数据与从表的数据的一致性。措施:foreign key约束。
④用户定义完整性
(2)主键和外键
一个表中只能有一个主键,且定义表时先定义主键再定义外键。
(3)数据类型
整型、浮点型、字符型、日期和时间型、货币型、二进制型、其他数据类型。
- 约束
①check约束
用于限制一列或多列输入的值的范围。(and or in)
②default约束
没有指定数据时自动赋默认值。
③primary key约束
将表中的一列或多列的组合设置为主键。一个表只能有一个主键,且主键列不能为空不能重复。
④foreign key约束
将表中的一列或多列的组合设置为表的外键,一个表的外键必须是另一个表的主键。外键所在的表为从表,主键所在的表为主表,从表的外键列只能插入所参照的主表的主键列存在的值。
⑤unique约束
用于确保表中的两个数据行在非主键列中没有相同的列值,保证数据唯一性,可为空。一个表中可以定义多个unique约束。
- 创建表
create table 表名
( 列名 类型 [ not null / null ] [ 约束 ],
列名 类型 [ not null / null ] [ 约束 ] )
例如:
create table 选课
( 课程号 tinyint primary key,
学号 char(8) [ foreign key ]references
学生(学号),
成绩 int check(成绩>=0 and 成绩<=100),
课程名 char(10) unique,
学分 decimal(3,1) default 4.0 )
(只是举个栗子,表明约束的用法及格式,逻辑上并不一定正确,课程名和学分本应该在课程表里)
> 设置多个主键
,primary key( 列名1,列名2 )
> 表级约束(多个列一起检查)
eg: ,订购日期<=发货日期
- 修改表
alter table 表名
> 修改列的定义
alter column 列名 数据类型 [ null/not null ]
> 增加列
add 列名 数据类型 [ null/not null ] [ 约束 ]
[,列名 数据类型...]
> 删除列
drop column 列名 [,...]
> 增加约束
add constraint 约束名 约束 [,...]
> 删除约束
drop constraint 约束名 [,...]
- 数据的插入
> 插入一条数据
insert (into) 表名 values('值','值','值')
> 插入多条数据
insert (into) 表名 values('值','值','值') ,('值','值','值')
> 指定列名
insert (into) 表名 (列名,列名,列名) values('值','值','值')
- 数据的删除
> 删除所有记录
delete from 表名
> 删除指定记录
delete from 表名 where 列名='值'
- 数据的修改
> 修改某一条数据
update 表名
set 要修改的列的名='新的值'
where 另一条列名='值'
四、查询
- 基本查询
> 查询全部信息
select * from 表名
> 带限制条件的查询
select top 行数 列名 from 表名
> 表达式查询
select 包含列名的表达式 as 新列名 from 表名
> 使用where语句进行检索
where 列名 between 数字1 and 数字2
(检索列在数字1~数字2里的内容)
where 列名 <> '值'
(检索列除了'值'里的内容)
> 检索表 Products 中所有不以 B 为起始字符的产品的所有内容。
select * from Products
where prod_name like '[^B]%'
- 多表连接
自连接
自连接可以将一个表与它自身连接,若要在一个表中查找具有相同列值的行,可以使用自连接。使用自连接时需要为表指定两个别名,且对所有列的引用均要用别名限定。
select a.学号,a.课程号,b.课程号,a.成绩
from 成绩表 join 成绩表
on a.学号 = b.学号 and a.课程号 != b.课程号
自然连接和等值连接的区别
1.自然连接一定是等值连接,但等值连接不一定是自然连接
2.等值连接要求相等的分量不一定是公共属性;而自然连接要求相等的分量必须是公共属性
3.等值连接不会去除重复的属性;而自然连接去除重复的属性
五、索引
按照存储结构的不同,可以将索引分为两类:聚集索引、非聚集索引。
每个表只能有一个聚集索引,每个表中最多可以创建249个非聚集索引。
1.创建索引
> 创建非聚集索引
create (nonclustered) index index_name
on table_name(字段名)
> 创建唯一聚集索引
create unique clustered index index_name
on table_name(字段名)
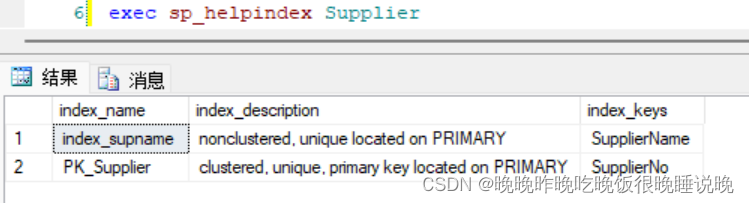
2.查看索引
exec sp_helpindex 表名
3.删除索引
drop index table_name.index_name(,table_name.index_name)
六、T-SQL程序设计
1.系统函数
- 字符串函数
(“表达式”用~符号代替省略了)
| 字符串函数 | 功能 |
|---|---|
| ascii(字符表达式) | 返回最左边字符的ASCII码 eg:select ASCII('A') |
| char(整型表达式) | 返回ASCII码对应的字符eg:select CHAR(66) |
| space(整型表达式) | 返回n个空格,n为整型表达式的值eg:print SPACE(3)+'嗨' |
| len(字符表达式) | 返回字符的个数eg:print len('T-SQL语言') |
| right(字符~ ,整型~) | 返回字符~ 中最右边的n个字符,n为整型~的值 |
| left(字符~ ,整型~) | 返回字符~ 中最左边的n个字符,n为整型~的值 |
流程控制语句
- waitfor语句
可使用waitfor语句延迟或暂停程序的执行
waitfor delay 'time' / time 'time'
> 修改SQL身份验证的用户sa的登录密码
begin
waitfor time '22:44'
exec sp_password '123456','12345','sa'
end
sp_password为系统存储过程,后面的参数分别为:‘旧密码’,‘新密码’,‘用户名’
亲测程序会一直显示正在执行查询,直到自己指定的时间点。
> 五秒后,执行SQL语句
waitfor delay '00:00:05'
select * from Student
delay指等待指定的时间间隔,最高可达24小时。
七、存储过程
存储过程案例:
USE studentdb
go
SET NOCOUNT ON
go
--********** create proc_student_info **********--
--********** Begin **********--
create procedure proc_student_info
as
Begin
select * from student
End
--********** End **********--
go
exec proc_student_info
go
--********** create proc_sno **********--
--********** Begin **********--
create proc proc_sno
@xuehao varchar(20)
as
Begin
select * from student where sno=@xuehao
End
--********** End **********--
go
exec proc_sno '1001'
go
--********** create proc_add **********--
--********** Begin **********--
create proc proc_add
@no varchar(20),@name varchar(20),@sex1 varchar(20),@birth date,
@dis varchar(50),@sch varchar(50)
as
insert into student(sno,sname,sex,birthday,discipline,school)
values(@no,@name,@sex1,@birth,@dis,@sch)
--********** End **********--
go
exec proc_add '1004','HMM','female','2019-6-2','English','national school'
go
exec proc_student_info
go
--********** create student_del **********--
--********** Begin **********--
create proc student_del
@no varchar(20)
as
begin
if exists(select @no from student where sno=@no)
begin
delete from student where sno=@no
print'sucessfully deleted'
end
else
begin
print'No such student'
end
end
--********** End **********--
go
exec student_del '1001'
go
exec proc_student_info
go
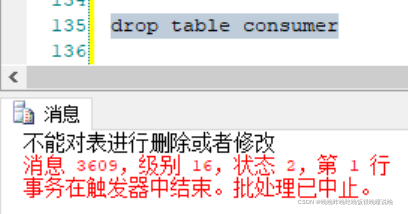
八、触发器
- 使用DDL触发器
create trigger table_1 on database
after alter_table,drop_table
as
begin
print'不能对表进行删除或者修改'
rollback transaction
end
go
drop table consumer