Kubeadm
kubeadm 是 Kubernetes 社区提供的集群构建工具,它能够以最佳实践的方式部署一个最小化的可用 Kubernetes 集群。
但是 kubeadm 在设计上并未安装网络解决方案,所以需要用户自行安装第三方符合 CNI 的网络解决方案,如 flanal,calico,canal 等。
常见的 Kubernetes 集群的运行模式有三种:
- 独立组件模式:各组件直接以守护进程方式运行,如二进制部署。
- 静态 Pod 模式:各组件以静态 Pod 运行在 Master 节点,kubelet 和容器运行时以守护进程运行所有节点,kube-proxy 以 DaemonSet 形式托管在集群。
- 自托管(self-hosted)模式:和第二种类似,但各组件都运行为 Pod 对象(非静态),且这些 Pod 对象都以 DaemonSet 形式托管在集群。
kubeadm 能够部署第二种和第三种运行方式。一般用于测试环境部署使用,生产环境更推荐二进制安装,更容易排查问题。
安装 Kubeadm(YUM 源安装方式)
在安装之前,所有节点需要新增 kubeadm 的 yum 源。
执行机器:所有 master 和 worker 节点
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF此时查看支持的 kubeadm 版本:
yum list kubeadm.x86_64 --showduplicates在写本文的时候最新版本支持到了 1.26.1-0。
所有节点安装 kubeadm:
yum -y install kubeadm-1.26.0-0 kubelet-1.26.0-0 kubectl-1.26.0-0但是可能会因为网络问题,下载可能会很慢,可以使用第二种方式。
安装 Kubeadm(rpm 包安装方式)
通过下载过程可以看到一共需要 6 个 rpm 包,可以直接去阿里云仓库里面下载:
http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/Packages
也可以通过下面的链接进行下载:
| 包名 | 版本 | 下载地址 |
| kubeadm | 1.26.0-0 | 点击下载 |
| kubectl | 1.26.0-0 | 点击下载 |
| kubelet | 1.26.0-0 | 点击下载 |
| cri-tools(依赖) | 1.26.0-0 | 点击下载 |
| kubernetes-cni(依赖) | 1.2.0-0 | 点击下载 |
将下载好的安装包改名之后,上传到 /opt/package 目录,执行安装。
执行机器:所有 master 和 worker 节点
cd /opt/package
yum -y localinstall kube* cri*配置 Kubelet
由于本文使用 Containerd 作为容器运行时,所以需要对 kubelet 进行配置,如果不是则不需要执行。
执行机器:所有 master 和 worker 节点
cat >/etc/sysconfig/kubelet<<EOF
KUBELET_KUBEADM_ARGS="--container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock"
EOF设置 Kubelet 开机启动:
systemctl daemon-reload
systemctl enable --now kubelet
systemctl status kubelet集群还未初始化,此时 Kunelet 还没有配置文件,是无法启动的,暂时不用管它。
集群初始化
创建初始化配置文件目录,该目录下面的文件只有在集群初始化的时候有用。
执行机器:所有 master 节点
mkdir -p /opt/service/kubeadm
cd /opt/service/kubeadm集群初始化后续的操作只需要在任意一个 Master 节点上执行即可,后面通过同步到其他节点完成配置,这里选择 master-01 执行。
master-01 新增配置文件:
cat > kubeadm-config-old.yaml << EOF
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
# 加入集群的 Token
token: 7t2weq.bjbawausm0jaxury
# 加入集群的 Token 有效期
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
# 本机地址,这里只支持 IP
advertiseAddress: 192.168.2.21
# API Server 监听端口
bindPort: 6443
nodeRegistration:
# Containerd socket 文件地址
criSocket: unix:///var/run/containerd/containerd.sock
# 本机名称,需要能够解析通信
name: master-01
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/control-plane
---
apiServer:
certSANs:
# VIP 地址,如果只有一个节点就写 IP 地址即可
- 192.168.2.100
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
# 证书存放目录
certificatesDir: /etc/kubernetes/pki
# 集群名称
clusterName: kubernetes
# 配置高可用集群,使用可 Nginx SLB 代理了 API Server 端口
controlPlaneEndpoint: 192.168.2.100:6443
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
# 指定国内的镜像仓库
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
# 该版本需要和 kubeadm 一致
kubernetesVersion: v1.26.0
networking:
dnsDomain: cluster.local
# Pod 网段(可用IP个数 65534,172.16.0.1 - 172.16.255.254)
podSubnet: 172.16.0.0/16
# Service 网段,注意不能和自己的网络冲突(可用IP个数 65534,10.10.0.1 - 10.10.255.254)
serviceSubnet: 10.10.0.0/16
scheduler: {}
EOF注意上面有注释的配置需要根据自己实际情况进行修改。如果 Pod 网段和 Service 网段不知道怎么划分,可以使用 IP 计算器:
http://tools.jb51.net/aideddesign/ip_net_calc/
更新配置文件:
kubeadm config migrate --old-config kubeadm-config-old.yaml --new-config kubeadm-config-new.yaml此时配置文件就会生成新版本,将新版本的配置文件传输给其他 Master 节点。
scp kubeadm-config-new.yaml root@192.168.2.22:/opt/service/kubeadm/通过刚生成的配置文件拉取镜像,这样的好处在于之后集群初始化的时候更快。
执行机器:所有 master 节点
kubeadm config images pull --config /opt/service/kubeadm/kubeadm-config-new.yaml该命令会自动从阿里云镜像仓库中下载以下镜像:
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.26.0
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.26.0
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.26.0
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.26.0
- registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9
- registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.6-0
- registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.9.3
拉取完成之后可以通过 nerdctl 命令查看拉取的镜像,但是需要指定名称空间:
nerdctl -n k8s.io image ls初始化集群,此时可以先注释掉 Nginx 中反向代理配置的除 master-01 之外的其它节点,等到集群 Master 节点都添加完成再将它们放开。
执行机器:master-01
kubeadm init --config /opt/service/kubeadm/kubeadm-config-new.yaml --upload-certs初始化完成之后会生成一系列的指令,需要将提示的内容记录下来,后面会用到:
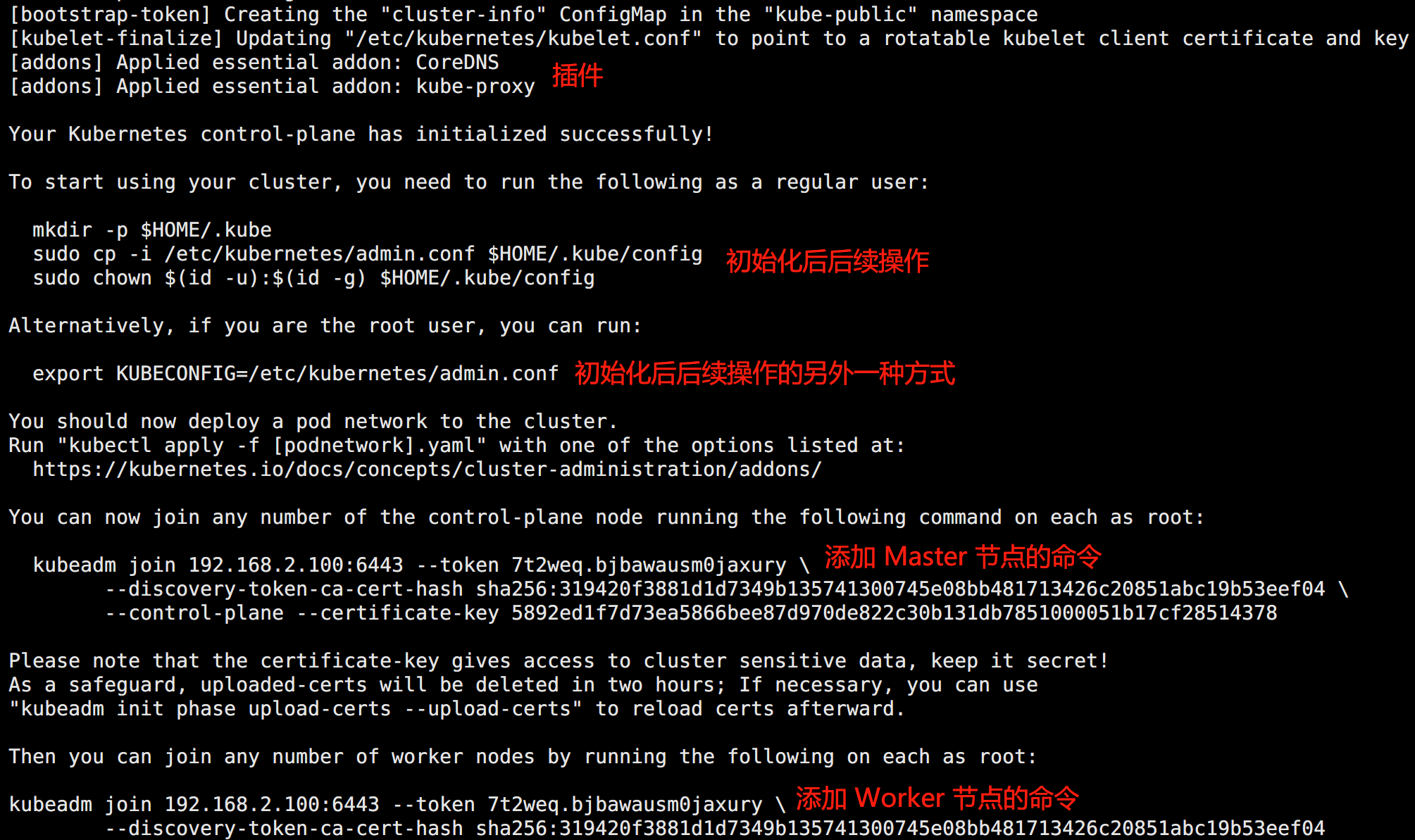
此时会涉及到几个重要的目录:
- Kubelet 配置文件目录:/var/lib/kubelet
- Kubernetes 配置文件目录:/etc/kubernetes
- Kubernetes master 组件配置文件目录:/etc/kubernetes/manifests
- Kubernetes 证书目录:/etc/kubernetes/pki
如果初始化失败,可以通过本机的 /var/log/messages 排错。
比如出现错误:
failed to get sandbox image "registry.k8s.io/pause:3.6":
这可能是在安装配置 Containerd 的时候没有修改它默认配置里面的 pause 镜像地址,导致一致访问 k8s.io 这个国内无法访问的域名导致。
找到错误之后可以执行下面命令进行清理初始化内容,清理完成后修复错误重新初始化:
kubeadm reset -f
ipvsadm --clear
rm -rf ~/.kube添加完成后后续操作:
cat >> /etc/profile << EOF
# Kubeadm 配置
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
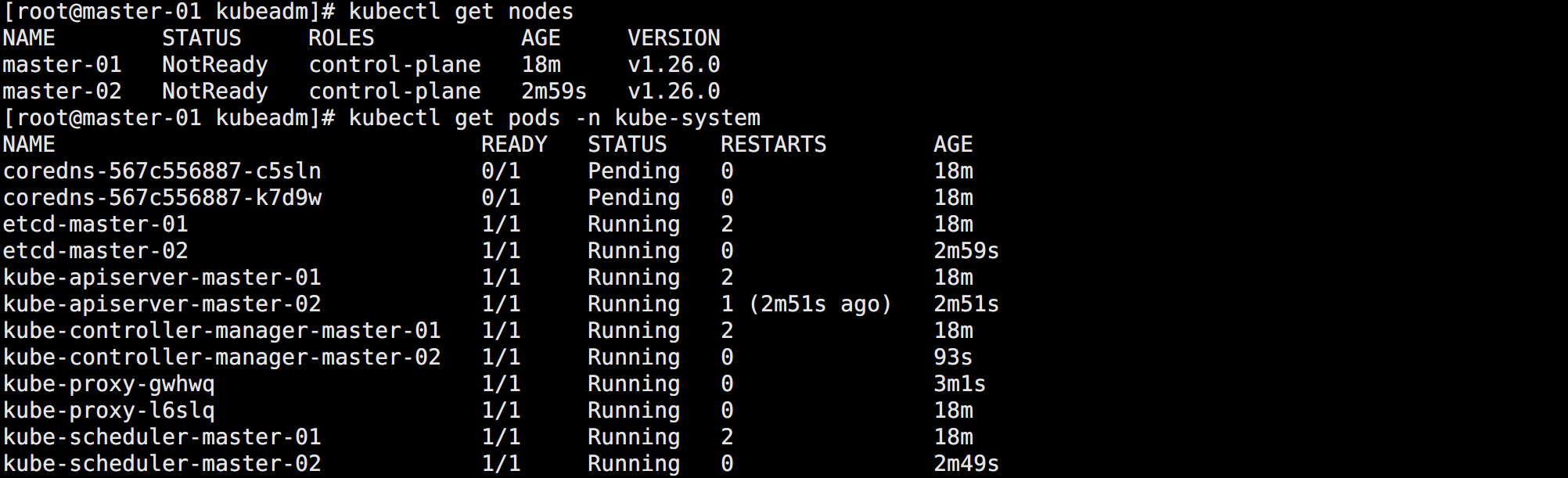
source /etc/profile查看当前 Kubernetes 集群的状态:
# 查看节点信息
kubectl get nodes
# 查看 pod 信息
kubectl get pods -n kube-system如图所示:

此时的 NotReady 和 CoreDNS 的状态都属于正常现象,因为缺少网络插件。
加入 Master 节点
其他 Master 节点加入集群,只需要将 master-01 初始化的时候生成的加入命令在对应的节点上面执行即可。
执行机器:master-02
kubeadm join 192.168.2.100:6443 --token 7t2weq.bjbawausm0jaxury --discovery-token-ca-cert-hash sha256:319420f3881d1d7349b135741300745e08bb481713426c20851abc19b53eef04 --control-plane --certificate-key 5892ed1f7d73ea5866bee87d970de822c30b131db7851000051b17cf28514378注意,拷贝命令的时候需要删除换行符 \,否则会报错:
accepts at most 1 arg(s), received 3
To see the stack trace of this error execute with --v=5 or higher
Master 节点加入集群之后,也会让执行相关的命令:

可以继续执行 master-01 的那个后续配置:
cat >> /etc/profile << EOF
# Kubeadm 配置
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
source /etc/profile再度查看集群信息:
# 查看节点信息
kubectl get nodes
# 查看 pod 信息
kubectl get pods -n kube-system如图所示:
Master 节点都添加完成之后就可以去 SLB 的 Nginx 里面将之前注释掉的节点都放开了。
加入 Worker 节点
和加入 Master 节点类似,执行初始化时候生成的命令即可。
执行机器:所有 Worker 节点
kubeadm join 192.168.2.100:6443 --token 7t2weq.bjbawausm0jaxury --discovery-token-ca-cert-hash sha256:319420f3881d1d7349b135741300745e08bb481713426c20851abc19b53eef04再度查看集群信息:
# 查看节点信息
kubectl get nodes
# 查看 pod 信息
kubectl get pods -n kube-system -o wide如图所示:
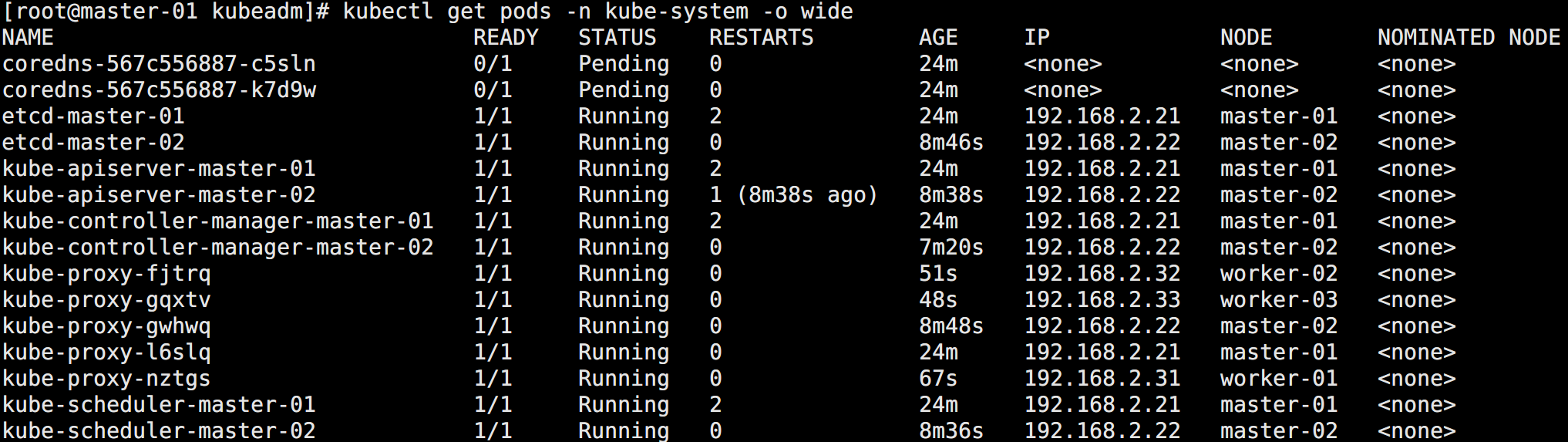
此时在 Worker 节点都启动了 kube-proxy。
安装 Calico
在介绍 kubeadm 的时候说过,kubeadm 需要用户自己安装网络插件,比如 flanal,calico,canal 等。目前业内比较推荐 calico。
Calico 是一个纯三层的数据中心网络方案(不需要 Overlay),并且与 OpenStack、Kubernetes、AWS、GCE 等 IaaS 和容器平台都有良好的集成。
Calico 通过在每一个计算节点利用 Linux Kernel 实现了一个高效的 vRouter 来负责数据转发,每个 vRouter 再通过 BGP 协议负责把自己上运行的 workload 的路由信息向整个 Calico 网络内传播。小规模部署可以直接互联,大规模下可通过指定的 BGP route reflector 来完成。这样的做法保证了最终所有的 workload 之间的数据流量都是通过 IP 路由的方式完成互联的。
Calico 节点组网可以直接利用数据中心的网络结构(无论是 L2 或者 L3),不需要额外的 NAT,隧道或者 Overlay Network。
此外,Calico 基于 iptables 还提供了丰富而灵活的网络 Policy,保证通过各个节点上的 ACLs 来提供 Workload 的多租户隔离、安全组以及其他可达性限制等功能。
https://projectcalico.docs.tigera.io/about/about-calico
本文编写的时候目前 Calico 最新版本为 3.25,通过官方文档可以看到其对 Kubernetes 版本的支持情况,如果版本不对可能会出现问题:
https://projectcalico.docs.tigera.io/getting-started/kubernetes/requirements
官方文档有这样的说明:
由于 Kubernetes API 的变化,Calico v3.25 将无法在 Kubernetes v1.15 或更低版本上运行。v1.16-v1.18 可能有效,但不再进行测试。较新的版本也可能有效,但我们建议升级到针对较新的 Kubernetes 版本测试过的 Calico 版本。
Calico 的安装只需要在任意 Master 节点执行即可,这里选择在 master-01 上面执行。
执行机器:master-01
cd /opt/service/kubeadm/
wget https://projectcalico.docs.tigera.io/archive/v3.25/manifests/calico.yaml
kubectl apply -f calico.yaml由于网络问题,这个过程会很慢,集群也可能变卡,过程中 Master 节点的组件还可能会被重启,等待安装完成即可。
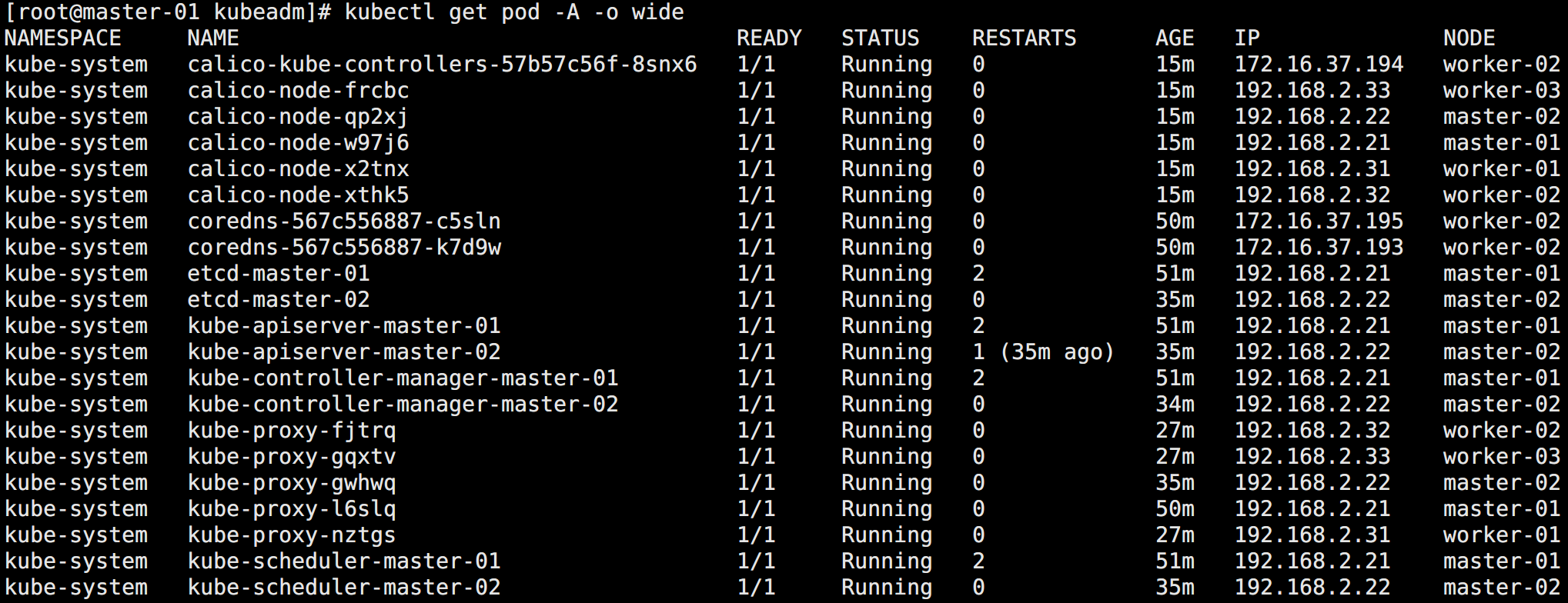
安装完成后可以查看集群节点状态:
kubectl get nodes如图所示:

开启自动生成 Token
从 v1.24.0 开始,ServiceAccount 不再自动生成 Secret。如果你还想要自动生成 Secret,那么可以给 kube-controller-manager 配置特性 LegacyServiceAccountTokenNoAutoGeneration=false。
https://kubernetes.feisky.xyz/concepts/objects/serviceaccount
修改所有 Master 节点的 kube-controller-manager 资源清单:
vim /etc/kubernetes/manifests/kube-controller-manager.yaml在 command 下面新增配置:--feature-gates=LegacyServiceAccountTokenNoAutoGeneration=false
- command:
- kube-controller-manager
- --feature-gates=LegacyServiceAccountTokenNoAutoGeneration=false修改完成后 K8S 集群会自动滚动更新 kube-controller-manager,不需要重启。
修改 Kube-proxy 模式
通过命令查看 kube-proxy 的模式:
curl 127.0.0.1:10249/proxyMode可以看到其模式为:iptables,需要将其改为 ipvs。
执行机器:master-01
kubectl edit cm kube-proxy -n kube-system找到 mode 配置,修改:
mode: ipvs更新配置:
kubectl patch daemonset kube-proxy -p "{\"spec\":{\"template\":{\"metadata\":{\"annotations\":{\"date\":\"`date +'%s'`\"}}}}}" -n kube-system再次使用 curl 命令查看就能发现 mode 已经变成 ipvs 了。
到此,Kubeadm 集群安装完成!
证书有效期
通过 kubeadm 安装的 Kubernetes 集群的证书有效期为 1 年,可以使用相关命令查看证书的有效期:
kubeadm certs check-expiration如图所示:
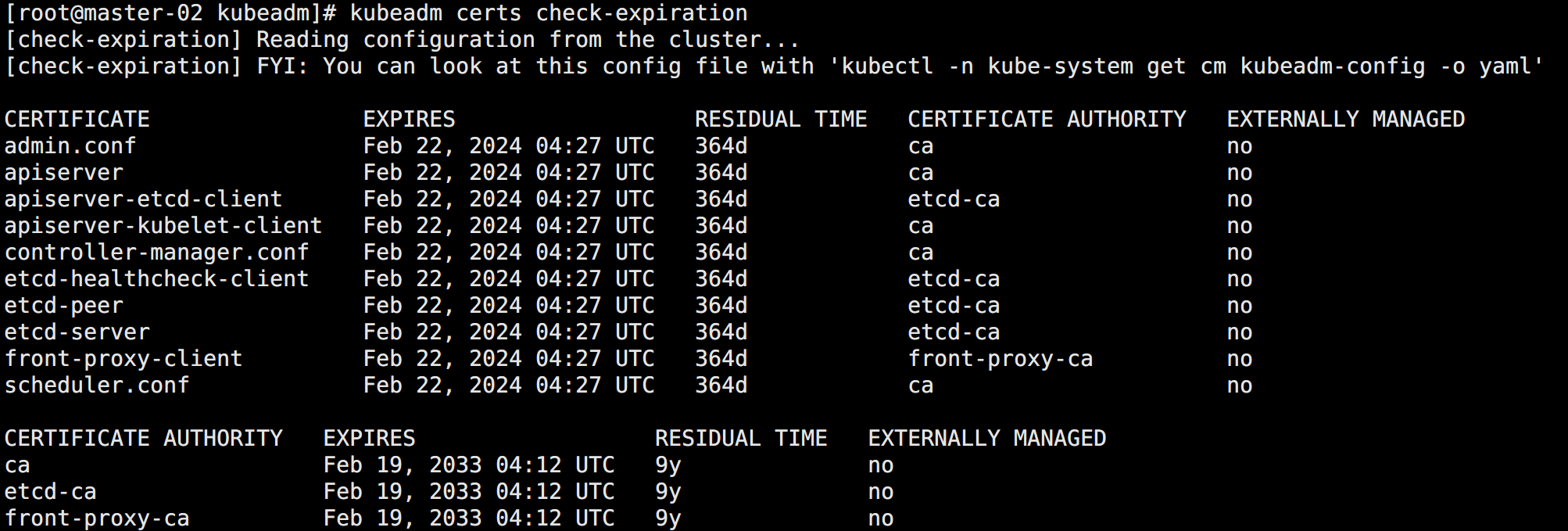
可以看到除了 ca 证书,其他证书的有效期都是一年。如果证书到期,则整个集群都会挂掉。
解决这个问题的办法一般有两种:
- 如果还没有安装集群,可以通过修改源码设置证书有效期。
- 如果集群已经运行,可以通过重新签发有效期更长的证书。
证书更新(直接更新)
为了更新的安全性,更新之前可以将所有 Master 节点的配置目录做一个备份:
cp -r /etc/kubernetes /etc/kubernetes_$(date +%F)
cp -r /var/lib/etcd /var/lib/etcd_$(date +%F)通过执行证书更新命令查看:
kubeadm certs renew --help可以看到证书更新是支持更新指定服务的证书,也可以更新单个服务的证书,但都是集群服务的证书。
# 所有 Master 节点更新所有证书
kubeadm certs renew all
systemctl restart kubelet如图所示:

可以看到提示让重启 kube-apiserver, kube-controller-manager, kube-scheduler 和 etcd 服务证书才能生效。
# 重启组件
for i in $(kubectl get pods -A | grep -E "etcd|kube-apiserver|kube-controller-manager|kube-scheduler" | awk '{print $2}');do
kubectl delete pod $i -n kube-system
sleep 3
done再度查看证书有效期,如图所示:

可以看到证书有效期已经更新。,也可以通过命令查看:
echo | openssl s_client -showcerts -connect 127.0.0.1:6443 -servername api 2>/dev/null | openssl x509 -noout -enddate同时,由于在初始化 Master 集群的时候采用的是设置环境变量 export KUBECONFIG=/etc/kubernetes/admin.conf 的方法,不需要再更新该文件。
如果不是该方法,还需要使用新的 admin.conf 替换掉复制的 /root/.kube/config 配置文件。
证书更新(修改源码)
上面的方法更新的证书有效期还是 1 年,生产还不是太建议。可以通过修改源码调整 kubeadm 的证书时间。
执行机器:ops
下载源码,切换到安装版本的分支:
# 下载 Kubernetes 源码
yum install git
cd /opt
git clone https://github.com/kubernetes/kubernetes.git
cd kubernetes
# 查看所有分支
git branch -a
# 切换分支
git checkout -b remotes/origin/release-1.26
# 查看当前分支
git branch修改文件:staging/src/k8s.io/client-go/util/cert/cert.go
vim staging/src/k8s.io/client-go/util/cert/cert.go搜索关键字 NewSelfSignedCACert 找到方法,里面有定义 now.Add(duration365d * 10).UTC(), 10 年,改成 100 年:
# 改成 100 年
NotAfter: now.Add(duration365d * 100).UTC(),修改文件:cmd/kubeadm/app/constants/constants.go
vim cmd/kubeadm/app/constants/constants.go搜索关键字 CertificateValidity,可以找到定义的常量 CertificateValidity = time.Hour * 24 * 365 1 年,改为 100 年。
CertificateValidity = time.Hour * 24 * 365 * 100安装 Go 环境:
# 查看所需要的 go 版本
cat build/build-image/cross/VERSION
# 下载 go
wget https://golang.google.cn/dl/go1.20.1.linux-amd64.tar.gz
mv go1.20.1.linux-amd64.tar.gz /opt/package
cd /opt/package
tar -zxf go1.20.1.linux-amd64.tar.gz
mv go /opt/
mkdir /opt/gopath
# 配置环境变量
cat >> /etc/profile << EOF
# go 配置
export GOROOT=/opt/go
export GOPATH=/opt/gopath
export PATH=\$PATH:\$GOROOT/bin
EOF
#生效
source /etc/profile
# 查看安装结果
go version编译 Kubeadm:
cd /opt/kubernetes/
# 指定只编译 Kubeadm
make all WHAT=cmd/kubeadm GOFLAGS=-v编译完成后会在 _output/local/bin/linux/amd64/kubeadm 目录下生成 kubeadm 的二进制文件。将该二进制文件替换掉 Master 节点的二进制文件即可。
替换 Kubeadm 文件。
执行服务器:所有 Master 节点
mv /usr/bin/kubeadm /usr/bin/kubeadm_$(date +%F)执行服务器:ops
cd _output/local/bin/linux/amd64/
# 发送文件
scp kubeadm root@192.168.2.21:/usr/bin/
# 发送文件
scp kubeadm root@192.168.2.22:/usr/bin/执行服务器:所有 Master 节点
# 修改权限
chmod 755 /usr/bin/kubeadm通过上面更新证书的方式再次更新证书,结果如图所示:
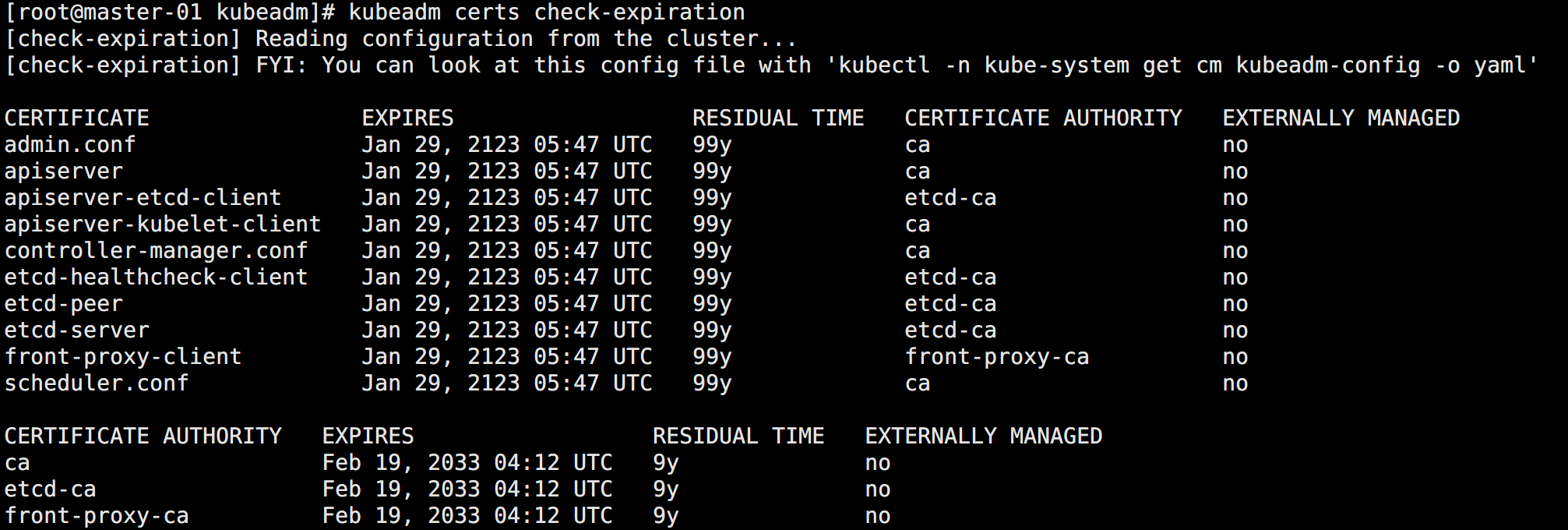
可以看到除了 CA 证书以外,其它证书都是 100 年有效期了。
如果想要更新 CA 证书,则需要重新初始化集群。但是没必要,10 年完全够了。
删除节点
有些时候某些机器出现问题可能需要将其下掉,或者在初始化节点的时候信息初始化的有问题需要重新加入,这时候就涉及到删除节点的问题。
具体删除办法如下,Master 节点和 Worker 节点都一样。
# 先将节点标记为不可调度的维护模式
kubectl drain master-02 --delete-local-data --ignore-daemonsets --force查看标记效果:

可以看到 master-02 节点已经属于不可调度状态。
如果标记标记节点写错了可以恢复调度:
kubectl uncordon master-02从集群中删除标记节点:
# 删除节点
kubectl delete nodes master-02在被删除的节点上清空数据:
# 重置节点
kubeadm reset -f
# 清除数据
ipvsadm --clear
rm -rf ~/.kube
rm -rf /var/lib/etcd
rm -rf /etc/kubernetes
# 关闭 kubelet
systemctl stop kubelet加集群 Token 过期 / 忘记
在集群初始化的时候有生成加入集群的命令,但是这个命令是有有效期的。如果过期或者忘记就需要重新生成。
查看现有的 Token:
kubeadm token list如果列出的 Token 都过期了,就需要重新生成 Token:
kubeadm token create此时查看 Token:

这样创建的 Token 有效期为 24 小时。
有了 Token 还不够,Worker 节点加入命令中还需要 --discovery-token-ca-cert-hash CA 证书 Hash 值:
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'此时就可以生成 Woker 节点加入集群的命令:
kubeadm join 192.168.2.100:6443 --token Token地址 --discovery-token-ca-cert-hash sha256:生成的Hash值当然这样分两次生成比较麻烦,可以在创建 Token 的时候就直接生成整个 Worker 加入集群命令:
kubeadm token create --print-join-command如图所示:

对于 Master 节点加入集群,除了 Worker 节点加入集群的参数,还需要 --certificate-key 新生成的证书 Key:
kubeadm init --config /opt/service/kubeadm/kubeadm-config-new.yaml phase upload-certs --upload-certs此时还会用到初始化集群时候的配置文件,如图所示:

将命令进行拼接:
kubeadm join 192.168.2.100:6443 --token Token地址 --discovery-token-ca-cert-hash sha256:生成的Hash值 --control-plane --certificate-key 生成的Key对于全新的 Master 节点,使用上面命令加入集群是没问题的,但是如果那个节点是前面踢掉的,就会有问题。
踢掉的 Master 节点加入集群
踢掉的 Master 节点加入集群会出现报错:
[control-plane] Creating static Pod manifest for "kube-scheduler"
[check-etcd] Checking that the etcd cluster is healthy
error execution phase check-etcd: etcd cluster is not healthy: failed to dial endpoint https://192.168.2.21:2379 with maintenance client: context deadline exceeded
To see the stack trace of this error execute with --v=5 or higher
原因在于集群的 ETCD 中还有存储它的相关信息,需要先清理掉。
# 登录集群的任意 ETCD Pod
kubectl exec -it etcd-master-01 sh -n kube-system
# Pod 中设置登录 ETCD 的命令
export ETCDCTL_API=3
alias etcdctl='etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key'
# 查看集群节点列表
etcdctl member list
# 删除节点
etcdctl member remove 50d272e8d4c41a8e此时再次清空新的 Master 节点数据,然后加入 Mater 节点则没问题了。
kubeadm reset -f
# 清除数据
ipvsadm --clear
rm -rf ~/.kube
rm -rf /var/lib/etcd
rm -rf /etc/kubernetes
# 关闭 kubelet
systemctl stop kubelet