前言
本文不讲述如泛化,前向后向传播,过拟合等基础概念。
本文图片来源于网络,图片所有者可以随时联系笔者删除。
本文提供代码不代表该神经网络的全部实现,只是为了方便展示此模型的关键结构。
CNN,常用于计算机视觉,是计算机视觉方面常见的基础模型,后面发展的有很多其他变种,也被用于文字处理等非计算机视觉领域。概念是由AI领域著名大佬LeCun等人在上世纪90年代提出。CNN之所以在计算机视觉领域(CNN、)表现出色,是因为它们能够自动并有效地捕捉到图像中的空间层次结构,这一点对于理解像素组成的图像至关重要。通过利用这种层次结构,CNN能够识别和分类从简单到复杂的对象和场景,无论它们的大小、位置或者是姿态如何变化。CNN的变种和改进模型层出不穷:AlexNet、VGG、GoogLeNet到ResNet和DenseNet等等等等。
正文
引
前文提到AlexNet,其在LeNet的基础上增加了3个卷积层,同时AlexNet作者对它们的卷积窗口、输出通道数和构造顺序均做了大量的调整,使其在图像分类效果反超机器学习方式,意义重大,但是为什么AlexNet行之有效,其实还是偏于黑盒,本文继续介绍几个CNN方面经典的模型
VGG - by Visual Geometry Group实验室
VGG网络是深度学习领域一个非常重要的里程碑,VGG网络由牛津大学的视觉几何组(Visual Geometry Group)提出,并且在2014年的ImageNet挑战赛中取得了优异的成绩。
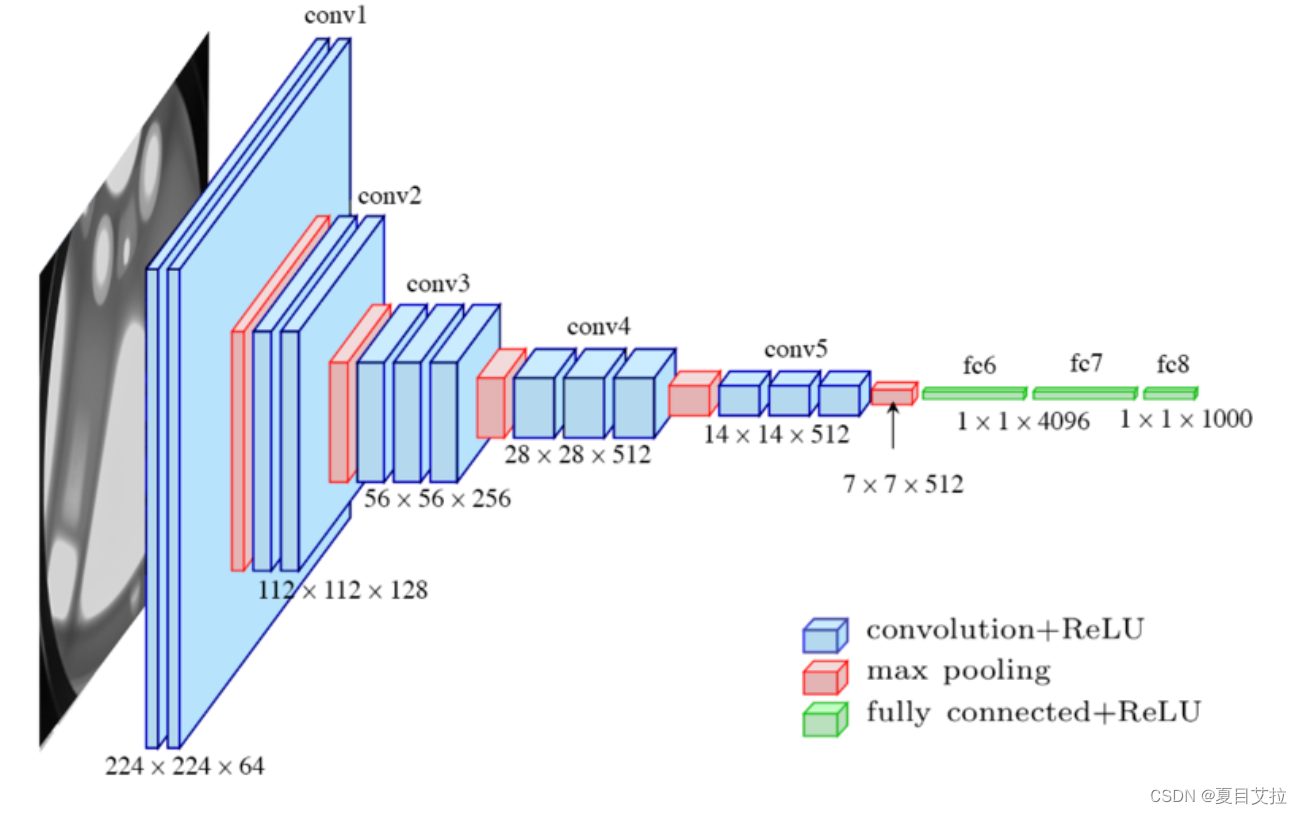
结构
VGG网络的关键贡献是展示了通过增加网络深度可以显著提高模型的性能。它通过重复使用小的卷积核(3x3)和最大池化层(2x2)来构建深度网络。VGG有几个版本,最著名的是VGG-16和VGG-19,数字代表网络中的层数(包括卷积层和全连接层)。
VGG-16的结构如下:
- 输入层:224x224 RGB图像
- 卷积层:多个卷积层,使用3x3的卷积核,步长为1
- 池化层:几个最大池化层,使用2x2的池化窗口,步长为2
- 全连接层:三个全连接层,最后一层为1000类输出,使用softmax激活函数
- 激活函数:所有隐藏层使用ReLU激活函数
关键变化
与AlexNet相比,VGG网络的几个关键变化如下:
-
更小的卷积核:VGG网络使用了3x3的卷积核,可以捕获到像素间最基本的特征。虽然小,但通过叠加多个卷积层,能够覆盖更大的感受野。
-
增加深度:VGG网络明显增加了网络的深度,这有助于学习更加复杂的特征表示。
-
统一卷积核大小:VGG网络中所有的卷积层都使用3x3的卷积核,简化了模型结构。
同时,这也使得VGG比AlexNet计算更慢
更深的网络结构:VGG网络比AlexNet有更多的层(例如,VGG-16有16个可训练层,而AlexNet只有8个)。这种增加的深度意味着网络在前向传播和反向传播过程中需要进行更多的计算。此外,梯度更新和权重更新的计算量也随之增加。
更高的存储需求:在VGG网络中,由于有更多的中间层,因此在训练过程中需要存储更多的中间特征图(feature maps)。这些特征图需要大量的内存或显存来存储,尤其是在网络的前几层,特征图的尺寸较大,消耗的存储资源更多。
示例代码
import torch
import torch.nn as nn
class VGG16(nn.Module):
def __init__(self, num_classes=1000):
super(VGG16, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 重复上述模式构建更深的网络层...
)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
GoogleNet - by Google(强大的谷歌)
GoogleNet(也称为Inception v1)是另一种深度学习架构,它在2014年赢得了ImageNet图像识别挑战赛。GoogleNet的主要贡献是它的Inception模块,这种模块设计使得网络能够在保持计算资源可控的同时,大幅增加深度和宽度。
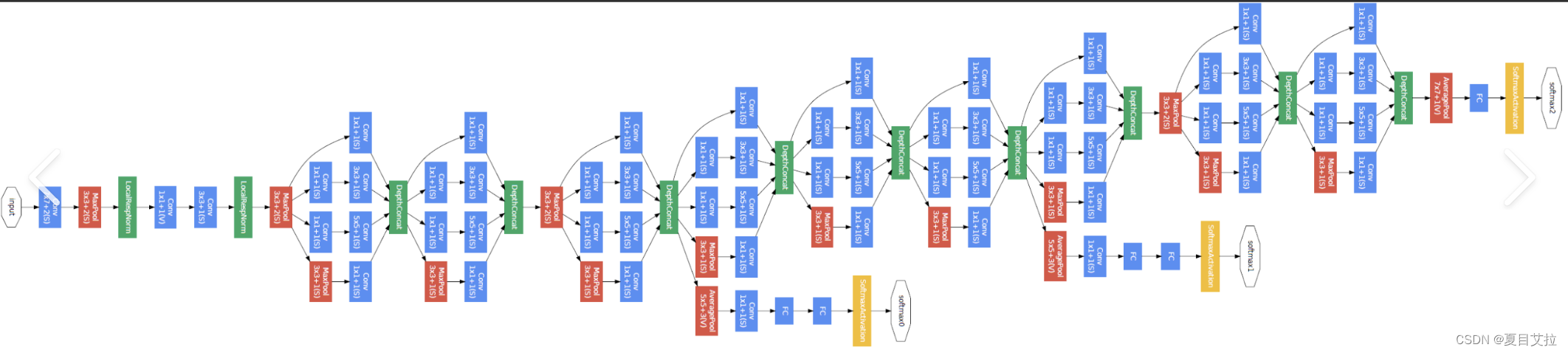
Inception模块:Inception模块的核心思想是在同一层内并行使用不同尺寸的卷积核(1x1, 3x3, 5x5)和最大池化(3x3),然后将这些操作的输出沿深度方向拼接起来。这种设计允许网络自动学习决定在每一层应该使用何种尺寸的卷积核,从而更有效地捕获图像特征。

1x1卷积核:GoogleNet通过1x1卷积核来进行降维,这样做可以显著减少参数数量和计算量,同时保持特征的有效性。1x1卷积在这里充当了降维和增维的作用,既减少了计算量,又保留了重要的特征信息。
深度和宽度的增加:通过Inception模块,GoogleNet能够在不显著增加计算负担的情况下,增加网络的深度和宽度。这使得模型能够学习到更加复杂和抽象的特征表示。
辅助分类器:在网络的中间层,GoogleNet引入了辅助分类器,以在训练过程中提供额外的梯度信号,帮助缓解深层网络训练中的梯度消失问题。在最终的模型中,这些辅助分类器不会被用于预测,仅在训练阶段使用。
无全连接层:与AlexNet和VGG不同,GoogleNet在网络顶部没有使用全连接层,而是使用平均池化层来减少每个特征图的维度,这样做显著降低了模型的参数数量。
示例代码
Inception模块
import torch
import torch.nn as nn
import torch.nn.functional as F
class InceptionModule(nn.Module):
def __init__(self, in_channels):
super(InceptionModule, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 64, kernel_size=1)
self.branch3x3 = nn.Sequential(
nn.Conv2d(in_channels, 48, kernel_size=1),
nn.Conv2d(48, 64, kernel_size=3, padding=1)
)
self.branch5x5 = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=1),
nn.Conv2d(64, 96, kernel_size=5, padding=2)
)
self.branch_pool = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels, 32, kernel_size=1)
)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3(x)
branch5x5 = self.branch5x5(x)
branch_pool = self.branch_pool(x)
# Concatenate the outputs of the branches
outputs = [branch1x1, branch3x3, branch5x5, branch_pool]
return torch.cat(outputs, 1) 简化的GoogleNet
class SimpleGoogleNet(nn.Module):
def __init__(self, num_classes=1000):
super(SimpleGoogleNet, self).__init__()
self.conv1 = nn.Conv2d(3, 192, kernel_size=3, padding=1)
self.inception1 = InceptionModule(192)
self.inception2 = InceptionModule(256)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.inception1(x)
x = self.inception2(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x