第十三章:接口、协议和 ABCs
针对接口编程,而不是实现。
Gamma、Helm、Johnson、Vlissides,《面向对象设计的第一原则》¹
面向对象编程关乎接口。在 Python 中理解类型的最佳方法是了解它提供的方法——即其接口——如 “类型由支持的操作定义”(第八章)中所讨论的。
根据编程语言的不同,我们有一种或多种定义和使用接口的方式。自 Python 3.8 起,我们有四种方式。它们在 类型映射(图 13-1)中有所描述。我们可以总结如下:
鸭子类型
Python 从一开始就采用的类型化方法。我们从 第一章 开始学习鸭子类型。
鹅式类型
自 Python 2.6 起由抽象基类(ABCs)支持的方法,依赖于对象与 ABCs 的运行时检查。鹅式类型 是本章的一个重要主题。
静态类型
类似 C 和 Java 这样的静态类型语言的传统方法;自 Python 3.5 起由 typing 模块支持,并由符合 PEP 484—类型提示 的外部类型检查器强制执行。这不是本章的主题。第八章的大部分内容以及即将到来的 第十五章 关于静态类型。
静态鸭子类型
由 Go 语言推广的一种方法;由 typing.Protocol 的子类支持——Python 3.8 中新增——也由外部类型检查器强制执行。我们首次在 “静态协议”(第八章)中看到这一点。
类型映射
图 13-1 中描述的四种类型化方法是互补的:它们各有优缺点。不应该否定其中任何一种。
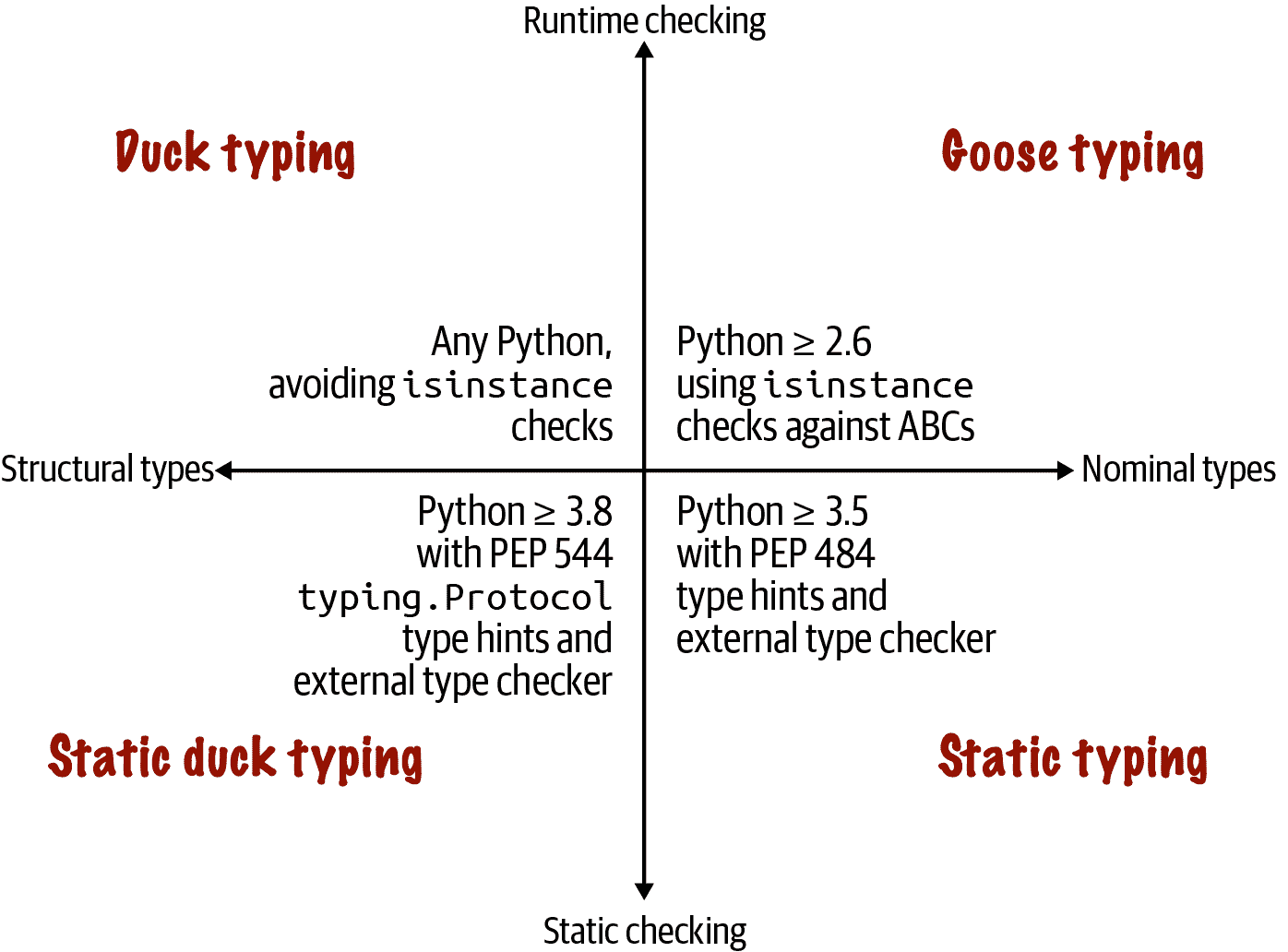
图 13-1。上半部分描述了仅使用 Python 解释器进行运行时类型检查的方法;下半部分需要外部静态类型检查器,如 MyPy 或 PyCharm 这样的 IDE。左侧象限涵盖基于对象结构的类型化——即对象提供的方法,而不考虑其类或超类的名称;右侧象限依赖于对象具有明确定义的类型:对象的类名或其超类的名称。
这四种方法都依赖于接口来工作,但静态类型可以通过仅使用具体类型而不是接口抽象,如协议和抽象基类,来实现——这样做效果不佳。本章讨论了鸭子类型、鹅式类型和静态鸭子类型——围绕接口展开的类型学科。
本章分为四个主要部分,涵盖了类型映射中四个象限中的三个:图 13-1。
-
“两种类型协议” 比较了两种结构类型与协议的形式——即类型映射的左侧。
-
“编程鸭子” 深入探讨了 Python 的常规鸭子类型,包括如何使其更安全,同时保持其主要优势:灵活性。
-
“鹅式类型” 解释了使用 ABCs 进行更严格的运行时类型检查。这是最长的部分,不是因为它更重要,而是因为书中其他地方有更多关于鸭子类型、静态鸭子类型和静态类型的部分。
-
“静态协议” 涵盖了
typing.Protocol子类的用法、实现和设计——对于静态和运行时类型检查很有用。
本章的新内容
本章经过大幅编辑,比第一版《流畅的 Python》中对应的第十一章长约 24%。虽然有些部分和许多段落是相同的,但也有很多新内容。以下是亮点:
-
本章的介绍和类型映射(图 13-1)是新内容。这是本章和所有涉及 Python ≥ 3.8 中类型的其他章节中大部分新内容的关键。
-
“两种类型的协议”解释了动态协议和静态协议之间的相似之处和不同之处。
-
“防御性编程和‘快速失败’” 主要复制了第一版的内容,但进行了更新,现在有一个部分标题以突出其重要性。
-
“静态协议”是全新的。它在“静态协议”(第八章)的初始介绍基础上进行了扩展。
-
在图 13-2、13-3 和 13-4 中更新了
collections.abc的类图,包括 Python 3.6 中的CollectionABC。
《流畅的 Python》第一版中有一节鼓励使用numbers ABCs 进行鹅式类型化。在“数字 ABC 和数值协议”中,我解释了为什么如果您计划同时使用静态类型检查器和鹅式类型检查器的运行时检查,应该使用typing模块中的数值静态协议。
两种类型的协议
根据上下文,计算机科学中的“协议”一词有不同的含义。诸如 HTTP 之类的网络协议指定了客户端可以发送给服务器的命令,例如GET、PUT和HEAD。我们在“协议和鸭子类型”中看到,对象协议指定了对象必须提供的方法以履行某种角色。第一章中的FrenchDeck示例演示了一个对象协议,即序列协议:允许 Python 对象表现为序列的方法。
实现完整的协议可能需要多个方法,但通常只实现部分也是可以的。考虑一下示例 13-1 中的Vowels类。
示例 13-1。使用__getitem__部分实现序列协议
>>> class Vowels:
... def __getitem__(self, i):
... return 'AEIOU'[i]
...
>>> v = Vowels()
>>> v[0]
'A'
>>> v[-1]
'U'
>>> for c in v: print(c)
...
A
E
I
O
U
>>> 'E' in v
True
>>> 'Z' in v
False
实现__getitem__足以允许按索引检索项目,并支持迭代和in运算符。__getitem__特殊方法实际上是序列协议的关键。查看Python/C API 参考手册中的这篇文章,“序列协议”部分。
int PySequence_Check(PyObject *o)
如果对象提供序列协议,则返回1,否则返回0。请注意,对于具有__getitem__()方法的 Python 类,除非它们是dict子类[…],否则它将返回1。
我们期望序列还支持len(),通过实现__len__来实现。Vowels没有__len__方法,但在某些情况下仍然表现为序列。这对我们的目的可能已经足够了。这就是为什么我喜欢说协议是一种“非正式接口”。这也是 Smalltalk 中对协议的理解方式,这是第一个使用该术语的面向对象编程环境。
除了关于网络编程的页面外,Python 文档中“协议”一词的大多数用法指的是这些非正式接口。
现在,随着 Python 3.8 中采纳了PEP 544—协议:结构子类型(静态鸭子类型),在 Python 中,“协议”一词有了另一层含义——与之密切相关,但又不同。正如我们在“静态协议”(第八章)中看到的,PEP 544 允许我们创建typing.Protocol的子类来定义一个或多个类必须实现(或继承)以满足静态类型检查器的方法。
当我需要具体说明时,我会采用这些术语:
动态协议
Python 一直拥有的非正式协议。动态协议是隐式的,按照约定定义,并在文档中描述。Python 最重要的动态协议由解释器本身支持,并在《Python 语言参考》的“数据模型”章节中有详细说明。
静态协议
由 PEP 544—协议:结构子类型(静态鸭子类型) 定义的协议,自 Python 3.8 起。静态协议有明确的定义:typing.Protocol 的子类。
它们之间有两个关键区别:
-
一个对象可能只实现动态协议的一部分仍然是有用的;但为了满足静态协议,对象必须提供协议类中声明的每个方法,即使你的程序并不需要它们。
-
静态协议可以被静态类型检查器验证,但动态协议不能。
这两种协议共享一个重要特征,即类永远不需要声明支持某个协议,即通过继承来支持。
除了静态协议,Python 还提供了另一种在代码中定义显式接口的方式:抽象基类(ABC)。
本章的其余部分涵盖了动态和静态协议,以及 ABC。
编程鸭
让我们从 Python 中两个最重要的动态协议开始讨论:序列和可迭代协议。解释器会尽最大努力处理提供了即使是最简单实现的对象,下一节将解释这一点。
Python 探究序列
Python 数据模型的哲学是尽可能与基本的动态协议合作。在处理序列时,Python 会尽最大努力与即使是最简单的实现一起工作。
图 13-2 显示了 Sequence 接口如何被正式化为一个 ABC。Python 解释器和内置序列如 list、str 等根本不依赖于该 ABC。我只是用它来描述一个完整的 Sequence 预期支持的内容。

图 13-2. Sequence ABC 和 collections.abc 中相关抽象类的 UML 类图。继承箭头从子类指向其超类。斜体字体的名称是抽象方法。在 Python 3.6 之前,没有 Collection ABC——Sequence 是 Container、Iterable 和 Sized 的直接子类。
提示
collections.abc 模块中的大多数 ABC 存在的目的是为了正式化由内置对象实现并被解释器隐式支持的接口——这两者都早于 ABC 本身。这些 ABC 对于新类是有用的起点,并支持运行时的显式类型检查(又称为 鹅式类型化)以及静态类型检查器的类型提示。
研究 图 13-2,我们看到 Sequence 的正确子类必须实现 __getitem__ 和 __len__(来自 Sized)。Sequence 中的所有其他方法都是具体的,因此子类可以继承它们的实现——或提供更好的实现。
现在回想一下 示例 13-1 中的 Vowels 类。它没有继承自 abc.Sequence,只实现了 __getitem__。
没有 __iter__ 方法,但 Vowels 实例是可迭代的,因为——作为后备——如果 Python 发现 __getitem__ 方法,它会尝试通过调用从 0 开始的整数索引的方法来迭代对象。因为 Python 足够聪明以迭代 Vowels 实例,所以即使缺少 __contains__ 方法,它也可以使 in 运算符正常工作:它会进行顺序扫描以检查项目是否存在。
总结一下,鉴于类似序列的数据结构的重要性,Python 通过在 __iter__ 和 __contains__ 不可用时调用 __getitem__ 来使迭代和 in 运算符正常工作。
第一章中的原始FrenchDeck也没有继承abc.Sequence,但它实现了序列协议的两种方法:__getitem__和__len__。参见示例 13-2。
示例 13-2。一叠卡片的序列(与示例 1-1 相同)
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
第一章中的几个示例之所以有效,是因为 Python 对任何类似序列的东西都给予了特殊处理。Python 中的可迭代协议代表了鸭子类型的极端形式:解释器尝试两种不同的方法来迭代对象。
为了明确起见,我在本节中描述的行为是在解释器本身中实现的,主要是用 C 语言编写的。它们不依赖于Sequence ABC 中的方法。例如,Sequence类中的具体方法__iter__和__contains__模拟了 Python 解释器的内置行为。如果你感兴趣,请查看Lib/_collections_abc.py中这些方法的源代码。
现在让我们研究另一个例子,强调协议的动态性,以及为什么静态类型检查器无法处理它们。
Monkey Patching:在运行时实现协议
Monkey patching 是在运行时动态更改模块、类或函数,以添加功能或修复错误。例如,gevent 网络库对 Python 的标准库的部分进行了 monkey patching,以允许轻量级并发而无需线程或async/await。²
来自示例 13-2 的FrenchDeck类缺少一个重要特性:它无法被洗牌。几年前,当我第一次编写FrenchDeck示例时,我确实实现了一个shuffle方法。后来我有了一个 Pythonic 的想法:如果FrenchDeck像一个序列一样工作,那么它就不需要自己的shuffle方法,因为已经有了random.shuffle,文档中描述为“原地洗牌序列x”。
标准的random.shuffle函数的使用方式如下:
>>> from random import shuffle
>>> l = list(range(10))
>>> shuffle(l)
>>> l
[5, 2, 9, 7, 8, 3, 1, 4, 0, 6]
提示
当遵循已建立的协议时,你提高了利用现有标准库和第三方代码的机会,这要归功于鸭子类型。
然而,如果我们尝试对FrenchDeck实例进行洗牌,就会出现异常,就像示例 13-3 中一样。
示例 13-3。random.shuffle无法处理FrenchDeck
>>> from random import shuffle
>>> from frenchdeck import FrenchDeck
>>> deck = FrenchDeck()
>>> shuffle(deck)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../random.py", line 265, in shuffle
x[i], x[j] = x[j], x[i]
TypeError: 'FrenchDeck' object does not support item assignment
错误消息很明确:'FrenchDeck'对象不支持项目赋值。问题在于shuffle是原地操作,通过在集合内部交换项目,而FrenchDeck只实现了不可变序列协议。可变序列还必须提供__setitem__方法。
因为 Python 是动态的,我们可以在运行时修复这个问题,甚至在交互式控制台中也可以。示例 13-4 展示了如何做到这一点。
示例 13-4。Monkey patching FrenchDeck使其可变并与random.shuffle兼容(继续自示例 13-3)
>>> def set_card(deck, position, card): # ①
... deck._cards[position] = card
...
>>> FrenchDeck.__setitem__ = set_card # ②
>>> shuffle(deck) # ③
>>> deck[:5]
[Card(rank='3', suit='hearts'), Card(rank='4', suit='diamonds'), Card(rank='4', suit='clubs'), Card(rank='7', suit='hearts'), Card(rank='9', suit='spades')]
①
创建一个以deck, position, 和card为参数的函数。
②
将该函数分配给FrenchDeck类中名为__setitem__的属性。
③
现在deck可以被洗牌了,因为我添加了可变序列协议的必要方法。
__setitem__特殊方法的签名在Python 语言参考中的“3.3.6. 模拟容器类型”中定义。这里我将参数命名为deck, position, card,而不是语言参考中的self, key, value,以显示每个 Python 方法都是作为普通函数开始的,将第一个参数命名为self只是一种约定。在控制台会话中这样做没问题,但在 Python 源文件中最好使用文档中记录的self, key, 和value。
诀窍在于set_card知道deck对象有一个名为_cards的属性,而_cards必须是一个可变序列。然后,set_card函数被附加到FrenchDeck类作为__setitem__特殊方法。这是猴子补丁的一个例子:在运行时更改类或模块,而不触及源代码。猴子补丁很强大,但实际打补丁的代码与要打补丁的程序非常紧密耦合,通常处理私有和未记录的属性。
除了是猴子补丁的一个例子,示例 13-4 突显了动态鸭子类型协议的动态性:random.shuffle不关心参数的类,它只需要对象实现可变序列协议的方法。甚至不用在意对象是否“出生”时就具有必要的方法,或者后来某种方式获得了这些方法。
鸭子类型不需要非常不安全或难以调试。下一节将展示一些有用的代码模式,以检测动态协议,而不需要显式检查。
防御性编程和“快速失败”
防御性编程就像防御性驾驶:一套增强安全性的实践,即使面对粗心的程序员或驾驶员。
许多错误只能在运行时捕获——即使在主流的静态类型语言中也是如此。³在动态类型语言中,“快速失败”是更安全、更易于维护的程序的极好建议。快速失败意味着尽快引发运行时错误,例如,在函数体的开头立即拒绝无效参数。
这里有一个例子:当你编写接受要在内部处理的项目序列的代码时,不要通过类型检查强制要求一个list参数。相反,接受参数并立即从中构建一个list。这种代码模式的一个例子是本章后面的示例 13-10 中的__init__方法:
def __init__(self, iterable):
self._balls = list(iterable)
这样可以使你的代码更灵活,因为list()构造函数处理任何适合内存的可迭代对象。如果参数不可迭代,调用将立即失败,并显示一个非常清晰的TypeError异常,就在对象初始化时。如果想更明确,可以用try/except包装list()调用以自定义错误消息——但我只会在外部 API 上使用这些额外的代码,因为问题对于代码库的维护者来说很容易看到。无论哪种方式,有问题的调用将出现在回溯的最后,使得修复问题变得直截了当。如果在类构造函数中没有捕获无效参数,程序将在稍后的某个时刻崩溃,当类的其他方法需要操作self._balls时,而它不是一个list。那么根本原因将更难找到。
当数据不应该被复制时,例如因为数据太大或者函数设计需要在原地更改数据以使调用者受益时,调用list()会很糟糕。在这种情况下,像isinstance(x, abc.MutableSequence)这样的运行时检查将是一个好方法。
如果你担心得到一个无限生成器——这不是一个常见问题——你可以先调用len()来检查参数。这将拒绝迭代器,同时安全地处理元组、数组和其他现有或将来完全实现Sequence接口的类。调用len()通常非常便宜,而无效的参数将立即引发错误。
另一方面,如果任何可迭代对象都可以接受,那么尽快调用iter(x)以获得一个迭代器,正如我们将在“为什么序列可迭代:iter 函数”中看到的。同样,如果x不可迭代,这将快速失败,并显示一个易于调试的异常。
在我刚刚描述的情况下,类型提示可以更早地捕捉一些问题,但并非所有问题。请记住,类型Any与其他任何类型都是一致的。类型推断可能导致变量被标记为Any类型。当发生这种情况时,类型检查器就会一头雾水。此外,类型提示在运行时不会被强制执行。快速失败是最后的防线。
利用鸭子类型的防御性代码也可以包含处理不同类型的逻辑,而无需使用isinstance()或hasattr()测试。
一个例子是我们如何模拟collections.namedtuple中的field_names参数处理:field_names接受一个由空格或逗号分隔的标识符组成的单个字符串,或者一组标识符。示例 13-5 展示了我如何使用鸭子类型来实现它。
示例 13-5. 鸭子类型处理字符串或字符串可迭代对象
try: # ①
field_names = field_names.replace(',', ' ').split() # ②
except AttributeError: # ③
pass # ④
field_names = tuple(field_names) # ⑤
if not all(s.isidentifier() for s in field_names): # ⑥
raise ValueError('field_names must all be valid identifiers')
①
假设它是一个字符串(EAFP = 宁愿请求原谅,也不要事先获准)。
②
将逗号转换为空格并将结果拆分为名称列表。
③
抱歉,field_names不像一个str那样嘎嘎叫:它没有.replace,或者返回我们无法.split的东西。
④
如果引发了AttributeError,那么field_names不是一个str,我们假设它已经是一个名称的可迭代对象。
⑤
为了确保它是可迭代的并保留我们自己的副本,将我们拥有的内容创建为一个元组。tuple比list更紧凑,还可以防止我的代码误改名称。
⑥
使用str.isidentifier来确保每个名称都是有效的。
示例 13-5 展示了一种情况,鸭子类型比静态类型提示更具表现力。没有办法拼写一个类型提示,说“field_names必须是由空格或逗号分隔的标识符字符串”。这是namedtuple在 typeshed 上的签名的相关部分(请查看stdlib/3/collections/init.pyi的完整源代码):
def namedtuple(
typename: str,
field_names: Union[str, Iterable[str]],
*,
# rest of signature omitted
如您所见,field_names被注释为Union[str, Iterable[str]],就目前而言是可以的,但不足以捕捉所有可能的问题。
在审查动态协议后,我们转向更明确的运行时类型检查形式:鹅式类型检查。
鹅式类型检查
抽象类代表一个接口。
C++的创始人 Bjarne Stroustrup⁴
Python 没有interface关键字。我们使用抽象基类(ABCs)来定义接口,以便在运行时进行显式类型检查,同时也受到静态类型检查器的支持。
Python 术语表中关于抽象基类的条目对它们为鸭子类型语言带来的价值有很好的解释:
抽象基类通过提供一种定义接口的方式来补充鸭子类型,当其他技术(如
hasattr())显得笨拙或微妙错误时(例如,使用魔术方法)。ABCs 引入虚拟子类,这些子类不继承自一个类,但仍然被isinstance()和issubclass()所识别;请参阅abc模块文档。⁵
鹅式类型检查是一种利用 ABCs 的运行时类型检查方法。我将让 Alex Martelli 在“水禽和 ABCs”中解释。
注
我非常感谢我的朋友 Alex Martelli 和 Anna Ravenscroft。我在 2013 年的 OSCON 上向他们展示了Fluent Python的第一个大纲,他们鼓励我将其提交给 O’Reilly 出版。两人后来进行了彻底的技术审查。Alex 已经是本书中被引用最多的人,然后他提出要写这篇文章。请开始,Alex!
总结一下,鹅打字包括:
-
从 ABC 继承以明确表明你正在实现先前定义的接口。
-
运行时使用 ABC 而不是具体类作为
isinstance和issubclass的第二个参数进行类型检查。
Alex 指出,从 ABC 继承不仅仅是实现所需的方法:开发人员的意图也是明确声明的。这种意图也可以通过注册虚拟子类来明确表示。
注意
使用register的详细信息在“ABC 的虚拟子类”中有介绍,本章后面会详细介绍。现在,这里是一个简短的示例:给定FrenchDeck类,如果我希望它通过类似issubclass(FrenchDeck, Sequence)的检查,我可以通过以下代码将其作为Sequence ABC 的虚拟子类:
from collections.abc import Sequence
Sequence.register(FrenchDeck)
如果你检查 ABC 而不是具体类,那么使用isinstance和issubclass会更加可接受。如果与具体类一起使用,类型检查会限制多态性——这是面向对象编程的一个重要特征。但是对于 ABCs,这些测试更加灵活。毕竟,如果一个组件没有通过子类化实现 ABC,但确实实现了所需的方法,那么它总是可以在事后注册,以便通过这些显式类型检查。
然而,即使使用 ABCs,你也应该注意,过度使用isinstance检查可能是代码异味的表现——这是 OO 设计不佳的症状。
通常情况下,使用isinstance检查的if/elif/elif链执行不同操作取决于对象类型通常是不可以的:你应该使用多态性来实现这一点——即,设计你的类使解释器分派调用到正确的方法,而不是在if/elif/elif块中硬编码分派逻辑。
另一方面,如果必须强制执行 API 契约,则对 ABC 执行isinstance检查是可以的:“伙计,如果你想调用我,你必须实现这个”,正如技术审查员 Lennart Regebro 所说。这在具有插件架构的系统中特别有用。在框架之外,鸭子类型通常比类型检查更简单、更灵活。
最后,在他的文章中,Alex 多次强调了在创建 ABCs 时需要克制的必要性。过度使用 ABCs 会在一门因其实用性和实用性而流行的语言中引入仪式感。在流畅的 Python审查过程中,Alex 在一封电子邮件中写道:
ABCs 旨在封装由框架引入的非常一般的概念、抽象概念——诸如“一个序列”和“一个确切的数字”。[读者]很可能不需要编写任何新的 ABCs,只需正确使用现有的 ABCs,就可以获得 99.9%的好处,而不会严重风险设计错误。
现在让我们看看鹅打字的实践。
从 ABC 继承
遵循 Martelli 的建议,在大胆发明自己之前,我们将利用现有的 ABC,collections.MutableSequence。在示例 13-6 中,FrenchDeck2明确声明为collections.MutableSequence的子类。
示例 13-6. frenchdeck2.py:FrenchDeck2,collections.MutableSequence的子类
from collections import namedtuple, abc
Card = namedtuple('Card', ['rank', 'suit'])
class FrenchDeck2(abc.MutableSequence):
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
def __setitem__(self, position, value): # ①
self._cards[position] = value
def __delitem__(self, position): # ②
del self._cards[position]
def insert(self, position, value): # ③
self._cards.insert(position, value)
①
__setitem__是我们启用洗牌所需的全部…
②
…但是从MutableSequence继承会强制我们实现__delitem__,该 ABC 的一个抽象方法。
③
我们还需要实现insert,MutableSequence的第三个抽象方法。
Python 在导入时不会检查抽象方法的实现(当加载和编译 frenchdeck2.py 模块时),而是在运行时当我们尝试实例化 FrenchDeck2 时才会检查。然后,如果我们未实现任何抽象方法,我们将收到一个 TypeError 异常,其中包含类似于 "Can't instantiate`` abstract class FrenchDeck2 with abstract methods __delitem__, insert" 的消息。这就是为什么我们必须实现 __delitem__ 和 insert,即使我们的 FrenchDeck2 示例不需要这些行为:因为 MutableSequence ABC 要求它们。
如 图 13-3 所示,Sequence 和 MutableSequence ABCs 中并非所有方法都是抽象的。
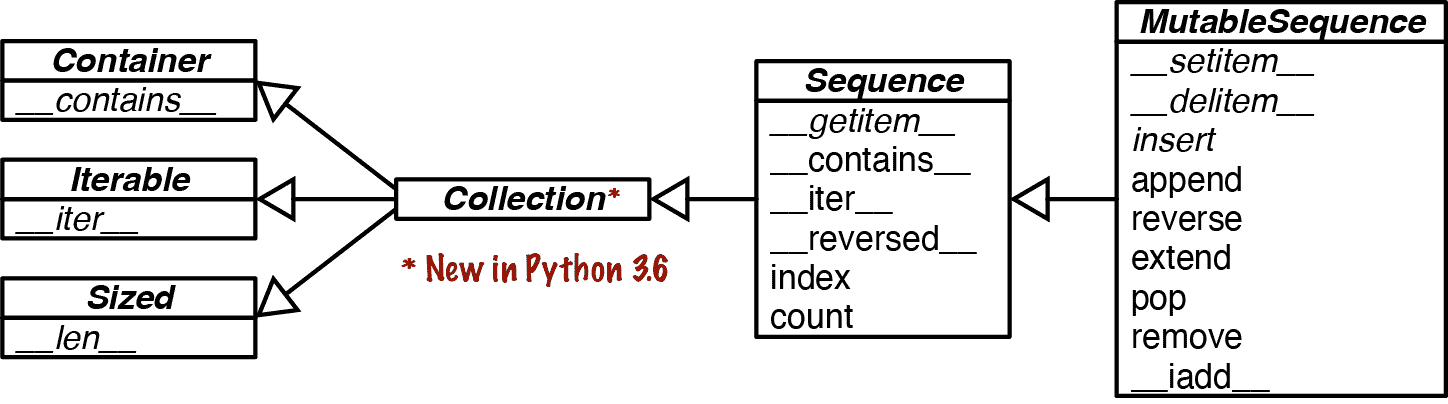
图 13-3. MutableSequence ABC 及其来自 collections.abc 的超类的 UML 类图(继承箭头从子类指向祖先类;斜体名称是抽象类和抽象方法)。
要将 FrenchDeck2 写为 MutableSequence 的子类,我必须付出实现 __delitem__ 和 insert 的代价,而我的示例并不需要这些。作为回报,FrenchDeck2 从 Sequence 继承了五个具体方法:__contains__, __iter__, __reversed__, index, 和 count。从 MutableSequence 中,它还获得了另外六个方法:append, reverse, extend, pop, remove, 和 __iadd__—它支持用于原地连接的 += 运算符。
每个 collections.abc ABC 中的具体方法都是根据类的公共接口实现的,因此它们可以在不了解实例内部结构的情况下工作。
提示
作为具体子类的编码者,您可能能够用更高效的实现覆盖从 ABCs 继承的方法。例如,__contains__ 通过对序列进行顺序扫描来工作,但如果您的具体序列保持其项目排序,您可以编写一个更快的 __contains__,它使用标准库中的 bisect 函数进行二分搜索。请查看 fluentpython.com 上的 “使用 Bisect 管理有序序列” 了解更多信息。
要很好地使用 ABCs,您需要了解可用的内容。接下来我们将回顾 collections 中的 ABCs。
标准库中的 ABCs
自 Python 2.6 起,标准库提供了几个 ABCs。大多数在 collections.abc 模块中定义,但也有其他的。例如,您可以在 io 和 numbers 包中找到 ABCs。但最常用的在 collections.abc 中。
提示
标准库中有两个名为 abc 的模块。这里我们谈论的是 collections.abc。为了减少加载时间,自 Python 3.4 起,该模块是在 collections 包之外实现的—在 Lib/_collections_abc.py—因此它是单独从 collections 导入的。另一个 abc 模块只是 abc(即 Lib/abc.py),其中定义了 abc.ABC 类。每个 ABC 都依赖于 abc 模块,但我们不需要自己导入它,除非要创建全新的 ABC。
图 13-4 是在 collections.abc 中定义的 17 个 ABCs 的摘要 UML 类图(不包括属性名称)。collections.abc 的文档中有一个很好的表格总结了这些 ABCs,它们之间的关系以及它们的抽象和具体方法(称为“mixin 方法”)。在 图 13-4 中有大量的多重继承。我们将在 第十四章 中专门讨论多重继承,但现在只需说当涉及到 ABCs 时,通常不是问题。⁷
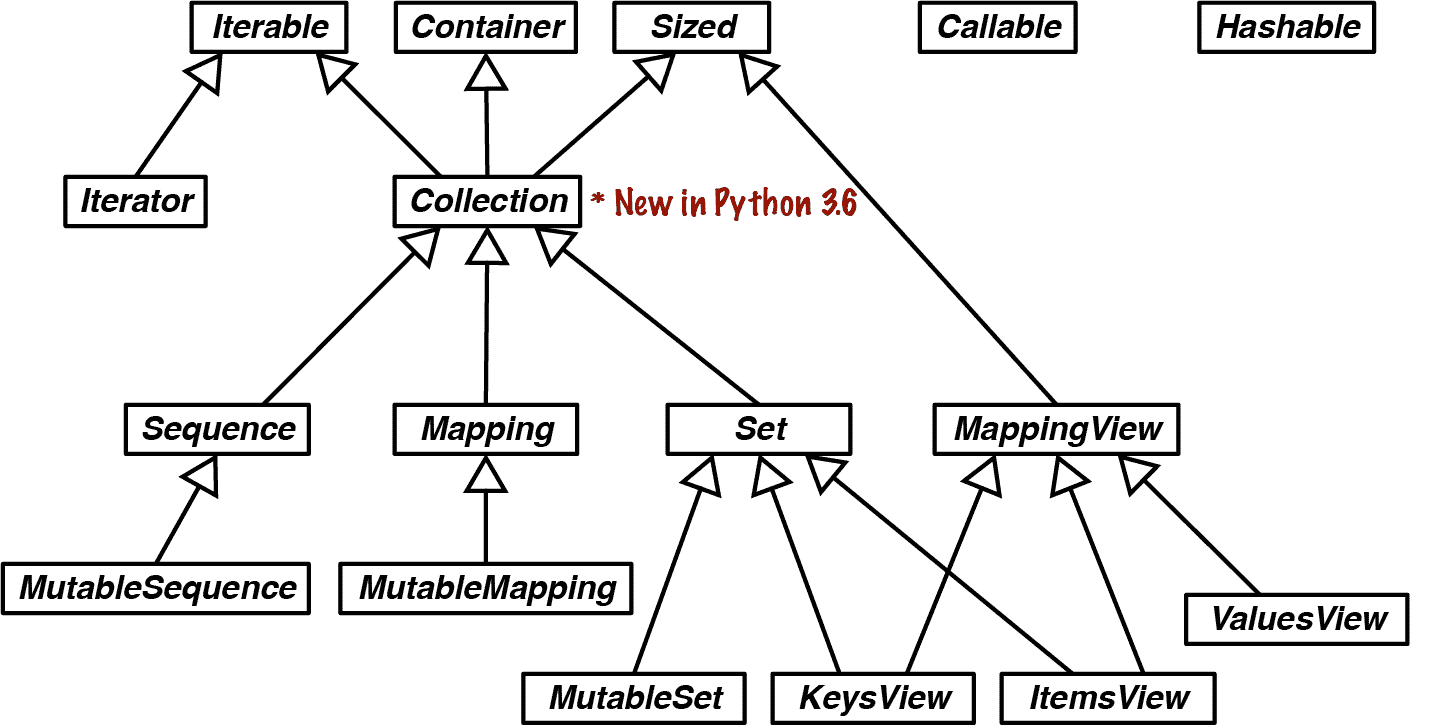
图 13-4. collections.abc 中 ABCs 的 UML 类图。
让我们回顾一下 图 13-4 中的聚类:
Iterable, Container, Sized
每个集合应该继承这些 ABC 或实现兼容的协议。Iterable 支持 __iter__ 迭代,Container 支持 __contains__ 中的 in 运算符,Sized 支持 __len__ 中的 len()。
Collection
这个 ABC 没有自己的方法,但在 Python 3.6 中添加了它,以便更容易从 Iterable、Container 和 Sized 继承。
Sequence、Mapping、Set
这些是主要的不可变集合类型,每种类型都有一个可变的子类。MutableSequence 的详细图表在 图 13-3 中;对于 MutableMapping 和 MutableSet,请参见 第三章 中的图 3-1 和 3-2。
MappingView
在 Python 3 中,从映射方法 .items()、.keys() 和 .values() 返回的对象分别实现了 ItemsView、KeysView 和 ValuesView 中定义的接口。前两者还实现了 Set 的丰富接口,其中包含我们在 “集合操作” 中看到的所有运算符。
Iterator
请注意,迭代器子类 Iterable。我们在 第十七章 中进一步讨论这一点。
Callable、Hashable
这些不是集合,但 collections.abc 是第一个在标准库中定义 ABC 的包,这两个被认为是足够重要以被包含在内。它们支持对必须是可调用或可哈希的对象进行类型检查。
对于可调用检测,内置函数 callable(obj) 比 insinstance(obj, Callable) 更方便。
如果 insinstance(obj, Hashable) 返回 False,则可以确定 obj 不可哈希。但如果返回值为 True,可能是一个误报。下一个框解释了这一点。
在查看一些现有的 ABC 后,让我们通过从头开始实现一个 ABC 并将其投入使用来练习鹅子打字。这里的目标不是鼓励每个人开始左右创建 ABC,而是学习如何阅读标准库和其他包中找到的 ABC 的源代码。
定义和使用 ABC
这个警告出现在第一版 Fluent Python 的“接口”章节中:
ABC,就像描述符和元类一样,是构建框架的工具。因此,只有少数 Python 开发人员可以创建 ABC,而不会对其他程序员施加不合理的限制和不必要的工作。
现在 ABC 在类型提示中有更多潜在用途,以支持静态类型。如 “抽象基类” 中所讨论的,使用 ABC 而不是具体类型在函数参数类型提示中给调用者更多的灵活性。
为了证明创建一个 ABC 的合理性,我们需要为在框架中使用它作为扩展点提供一个上下文。因此,这是我们的背景:想象一下你需要在网站或移动应用程序上以随机顺序显示广告,但在显示完整广告库之前不重复显示广告。现在让我们假设我们正在构建一个名为 ADAM 的广告管理框架。其要求之一是支持用户提供的非重复随机选择类。⁸ 为了让 ADAM 用户清楚地知道“非重复随机选择”组件的期望,我们将定义一个 ABC。
在关于数据结构的文献中,“栈”和“队列”描述了抽象接口,以物理对象的实际排列为基础。我将效仿并使用一个现实世界的隐喻来命名我们的 ABC:宾果笼和彩票吹风机是设计用来从有限集合中随机挑选项目,直到集合耗尽而不重复的机器。
ABC 将被命名为 Tombola,以宾果的意大利名称和混合数字的翻转容器命名。
Tombola ABC 有四个方法。两个抽象方法是:
.load(…)
将项目放入容器中。
.pick()
从容器中随机移除一个项目,并返回它。
具体方法是:
.loaded()
如果容器中至少有一个项目,则返回True。
.inspect()
返回一个从容器中当前项目构建的tuple,而不更改其内容(内部排序不保留)。
图 13-5 展示了Tombola ABC 和三个具体实现。
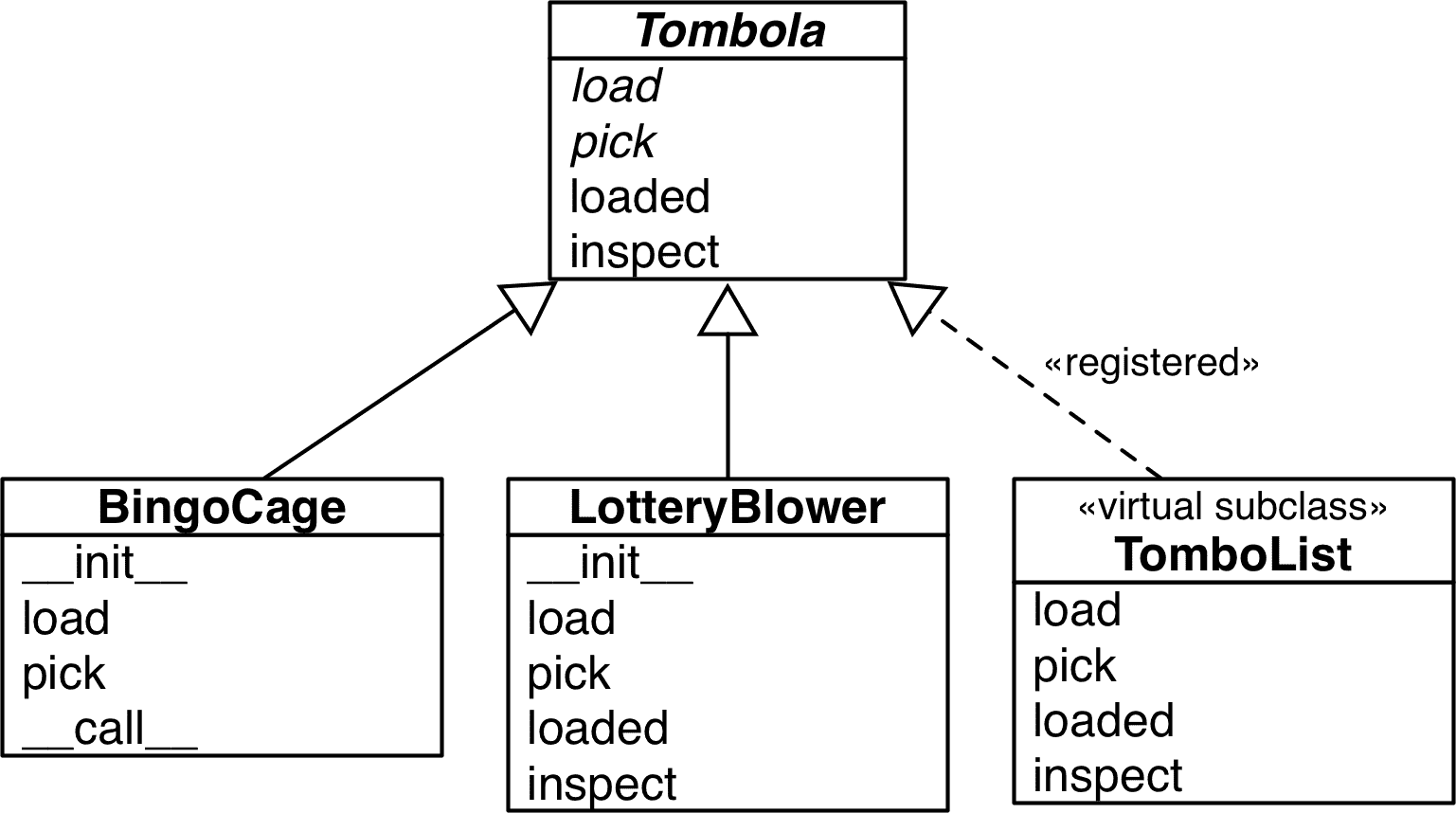
图 13-5. ABC 和三个子类的 UML 图。Tombola ABC 的名称和其抽象方法以斜体书写,符合 UML 约定。虚线箭头用于接口实现——这里我用它来显示TomboList不仅实现了Tombola接口,而且还注册为Tombola的虚拟子类—正如我们将在本章后面看到的。⁹
示例 13-7 展示了Tombola ABC 的定义。
示例 13-7. tombola.py:Tombola是一个具有两个抽象方法和两个具体方法的 ABC
import abc
class Tombola(abc.ABC): # ①
@abc.abstractmethod
def load(self, iterable): # ②
"""Add items from an iterable."""
@abc.abstractmethod
def pick(self): # ③
"""Remove item at random, returning it.
This method should raise `LookupError` when the instance is empty.
"""
def loaded(self): # ④
"""Return `True` if there's at least 1 item, `False` otherwise."""
return bool(self.inspect()) # ⑤
def inspect(self):
"""Return a sorted tuple with the items currently inside."""
items = []
while True: # ⑥
try:
items.append(self.pick())
except LookupError:
break
self.load(items) # ⑦
return tuple(items)
①
要定义一个 ABC,需要继承abc.ABC。
②
抽象方法使用@abstractmethod装饰器标记,通常其主体除了文档字符串外是空的。¹⁰
③
文档字符串指示实现者在没有项目可挑选时引发LookupError。
④
一个 ABC 可以包含具体方法。
⑤
ABC 中的具体方法必须仅依赖于 ABC 定义的接口(即 ABC 的其他具体或抽象方法或属性)。
⑥
我们无法知道具体子类将如何存储项目,但我们可以通过连续调用.pick()来构建inspect结果来清空Tombola…
⑦
…然后使用.load(…)将所有东西放回去。
提示
抽象方法实际上可以有一个实现。即使有,子类仍将被强制重写它,但他们可以使用super()调用抽象方法,为其添加功能而不是从头开始实现。有关@abstractmethod用法的详细信息,请参阅abc模块文档。
.inspect() 方法的代码在示例 13-7 中有些愚蠢,但它表明我们可以依赖.pick()和.load(…)来检查Tombola中的内容——通过挑选所有项目并将它们加载回去,而不知道项目实际上是如何存储的。这个示例的重点是强调在抽象基类(ABCs)中提供具体方法是可以的,只要它们仅依赖于接口中的其他方法。了解它们的内部数据结构后,Tombola的具体子类可以始终用更智能的实现覆盖.inspect(),但他们不必这样做。
示例 13-7 中的.loaded()方法只有一行,但很昂贵:它调用.inspect()来构建tuple,然后对其应用bool()。这样做是有效的,但具体子类可以做得更好,我们将看到。
注意,我们对.inspect()的绕道实现要求我们捕获self.pick()抛出的LookupError。self.pick()可能引发LookupError也是其接口的一部分,但在 Python 中无法明确表示这一点,除非在文档中(参见示例 13-7 中抽象pick方法的文档字符串)。
我选择了LookupError异常,因为它在 Python 异常层次结构中与IndexError和KeyError的关系,这是实现具体Tombola时最有可能引发的异常。因此,实现可以引发LookupError、IndexError、KeyError或LookupError的自定义子类以符合要求。参见图 13-6。

图 13-6。Exception类层次结构的一部分。¹¹
①
LookupError是我们在Tombola.inspect中处理的异常。
②
IndexError是我们尝试从序列中获取超出最后位置的索引时引发的LookupError子类。
③
当我们使用不存在的键从映射中获取项时,会引发KeyError。
现在我们有了自己的Tombola ABC。为了见证 ABC 执行的接口检查,让我们尝试用一个有缺陷的实现来愚弄Tombola,参见示例 13-8。
示例 13-8。一个虚假的Tombola不会被发现
>>> from tombola import Tombola
>>> class Fake(Tombola): # ①
... def pick(self):
... return 13
...
>>> Fake # ②
<class '__main__.Fake'> >>> f = Fake() # ③
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't instantiate abstract class Fake with abstract method load
①
将Fake声明为Tombola的子类。
②
类已创建,目前没有错误。
③
当我们尝试实例化Fake时,会引发TypeError。消息非常清楚:Fake被视为抽象,因为它未能实现Tombola ABC 中声明的抽象方法之一load。
所以我们定义了我们的第一个 ABC,并让它验证一个类的工作。我们很快将子类化Tombola ABC,但首先我们必须了解一些 ABC 编码规则。
ABC 语法细节
声明 ABC 的标准方式是继承abc.ABC或任何其他 ABC。
除了ABC基类和@abstractmethod装饰器外,abc模块还定义了@abstractclassmethod、@abstractstaticmethod和@abstractproperty装饰器。然而,在 Python 3.3 中,这三个装饰器已被弃用,因为现在可以在@abstractmethod之上堆叠装饰器,使其他装饰器变得多余。例如,声明抽象类方法的首选方式是:
class MyABC(abc.ABC):
@classmethod
@abc.abstractmethod
def an_abstract_classmethod(cls, ...):
pass
警告
堆叠函数装饰器的顺序很重要,在@abstractmethod的情况下,文档是明确的:
当
abstractmethod()与其他方法描述符结合使用时,应将其应用为最内层的装饰器…¹²
换句话说,在@abstractmethod和def语句之间不得出现其他装饰器。
现在我们已经解决了这些 ABC 语法问题,让我们通过实现两个具体的子类来使用Tombola。
ABC 的子类化
鉴于Tombola ABC,我们现在将开发两个满足其接口的具体子类。这些类在图 13-5 中有所描述,以及下一节将讨论的虚拟子类。
示例 13-9 中的BingoCage类是示例 7-8 的变体,使用了更好的随机化程序。这个BingoCage实现了所需的抽象方法load和pick。
示例 13-9。bingo.py:BingoCage是Tombola的具体子类
import random
from tombola import Tombola
class BingoCage(Tombola): # ①
def __init__(self, items):
self._randomizer = random.SystemRandom() # ②
self._items = []
self.load(items) # ③
def load(self, items):
self._items.extend(items)
self._randomizer.shuffle(self._items) # ④
def pick(self): # ⑤
try:
return self._items.pop()
except IndexError:
raise LookupError('pick from empty BingoCage')
def __call__(self): # ⑥
self.pick()
①
这个BingoCage类明确扩展了Tombola。
②
假设我们将用于在线游戏。random.SystemRandom在os.urandom(…)函数之上实现了random API,该函数提供了“适用于加密用途”的随机字节,根据os模块文档。
③
将初始加载委托给.load(…)方法。
④
我们使用我们的SystemRandom实例的.shuffle()方法,而不是普通的random.shuffle()函数。
⑤
pick的实现如示例 7-8 中所示。
⑥
__call__也来自示例 7-8。虽然不需要满足Tombola接口,但添加额外的方法也没有坏处。
BingoCage继承了Tombola的昂贵loaded和愚蠢的inspect方法。都可以用快得多的一行代码重写,就像示例 13-10 中那样。关键是:我们可以懒惰并只继承来自 ABC 的次优具体方法。从Tombola继承的方法对于BingoCage来说并不像它们本应该的那样快,但对于任何正确实现pick和load的Tombola子类,它们确实提供了正确的结果。
示例 13-10 展示了Tombola接口的一个非常不同但同样有效的实现。LottoBlower不是洗“球”并弹出最后一个,而是从随机位置弹出。
示例 13-10。lotto.py:LottoBlower是一个具体子类,覆盖了Tombola的inspect和loaded方法。
import random
from tombola import Tombola
class LottoBlower(Tombola):
def __init__(self, iterable):
self._balls = list(iterable) # ①
def load(self, iterable):
self._balls.extend(iterable)
def pick(self):
try:
position = random.randrange(len(self._balls)) # ②
except ValueError:
raise LookupError('pick from empty LottoBlower')
return self._balls.pop(position) # ③
def loaded(self): # ④
return bool(self._balls)
def inspect(self): # ⑤
return tuple(self._balls)
①
初始化程序接受任何可迭代对象:该参数用于构建一个列表。
②
random.randrange(…)函数在范围为空时会引发ValueError,因此我们捕获并抛出LookupError,以便与Tombola兼容。
③
否则,随机选择的项目将从self._balls中弹出。
④
重写loaded以避免调用inspect(就像示例 13-7 中的Tombola.loaded一样)。通过直接使用self._balls来工作,我们可以使其更快—不需要构建一个全新的tuple。
⑤
用一行代码重写inspect。
示例 13-10 展示了一个值得一提的习惯用法:在__init__中,self._balls存储list(iterable)而不仅仅是iterable的引用(即,我们并没有简单地赋值self._balls = iterable,从而给参数起了个别名)。正如在“防御性编程和‘快速失败’”中提到的,这使得我们的LottoBlower灵活,因为iterable参数可以是任何可迭代类型。同时,我们确保将其项存储在list中,这样我们就可以pop项。即使我们总是得到列表作为iterable参数,list(iterable)也会产生参数的副本,这是一个很好的做法,考虑到我们将从中删除项目,而客户端可能不希望提供的列表被更改。¹³
现在我们来到鹅类型的关键动态特性:使用register方法声明虚拟子类。
一个 ABC 的虚拟子类
鹅类型的一个重要特征——也是为什么它值得一个水禽名字的原因之一——是能够将一个类注册为 ABC 的虚拟子类,即使它没有继承自它。这样做时,我们承诺该类忠实地实现了 ABC 中定义的接口——Python 会相信我们而不进行检查。如果我们撒谎,我们将被通常的运行时异常捕获。
这是通过在 ABC 上调用register类方法来完成的。注册的类然后成为 ABC 的虚拟子类,并且将被issubclass识别为这样,但它不会继承 ABC 的任何方法或属性。
警告
虚拟子类不会从其注册的 ABC 继承,并且在任何时候都不会检查其是否符合 ABC 接口,即使在实例化时也是如此。此外,静态类型检查器目前无法处理虚拟子类。详情请参阅Mypy issue 2922—ABCMeta.register support。
register方法通常作为一个普通函数调用(参见“实践中的 register 用法”),但也可以用作装饰器。在示例 13-11 中,我们使用装饰器语法并实现TomboList,Tombola的虚拟子类,如图 13-7 所示。
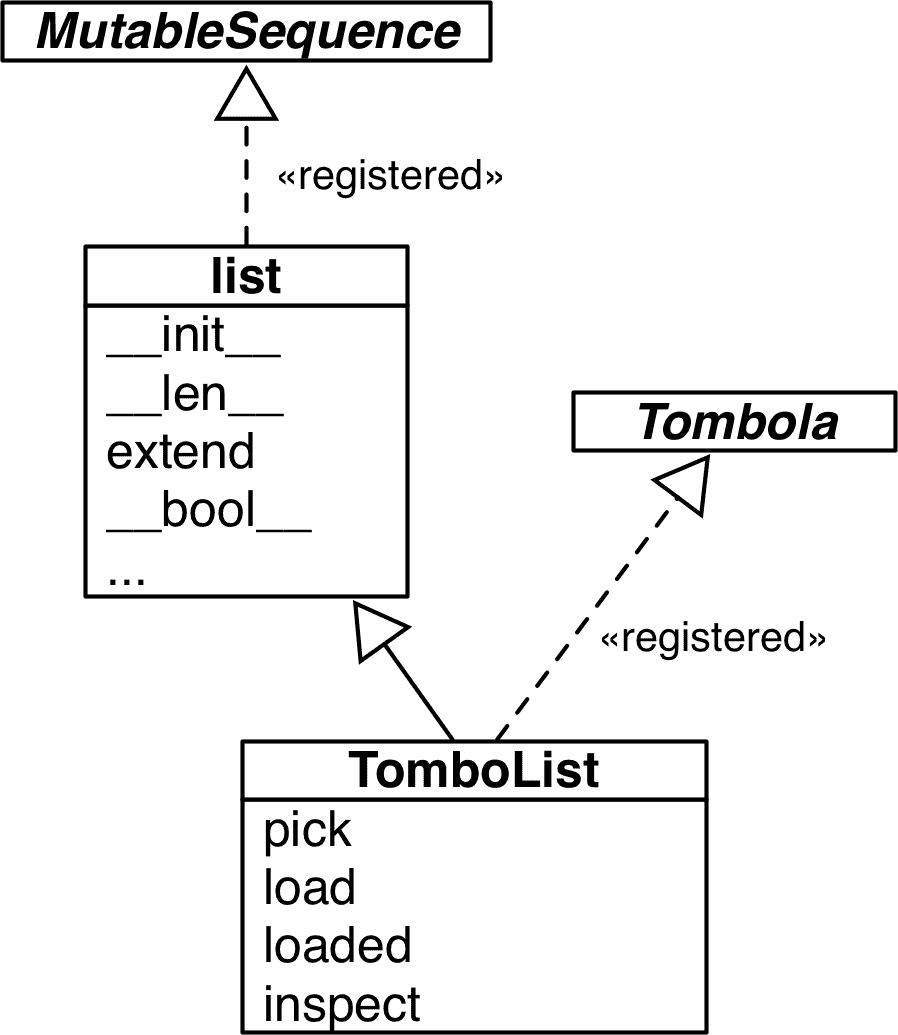
图 13-7. TomboList的 UML 类图,list的真实子类和Tombola的虚拟子类。
示例 13-11. tombolist.py:类TomboList是Tombola的虚拟子类
from random import randrange
from tombola import Tombola
@Tombola.register # ①
class TomboList(list): # ②
def pick(self):
if self: # ③
position = randrange(len(self))
return self.pop(position) # ④
else:
raise LookupError('pop from empty TomboList')
load = list.extend # ⑤
def loaded(self):
return bool(self) # ⑥
def inspect(self):
return tuple(self)
# Tombola.register(TomboList) # ⑦
①
Tombolist被注册为Tombola的虚拟子类。
②
Tombolist扩展了list。
③
Tombolist从list继承其布尔行为,如果列表不为空则返回True。
④
我们的pick调用self.pop,从list继承,传递一个随机的项目索引。
⑤
Tombolist.load与list.extend相同。
⑥
loaded委托给bool。¹⁴
⑦
总是可以以这种方式调用register,当你需要注册一个你不维护但符合接口的类时,这样做是很有用的。
请注意,由于注册,函数issubclass和isinstance的行为就好像TomboList是Tombola的子类一样:
>>> from tombola import Tombola
>>> from tombolist import TomboList
>>> issubclass(TomboList, Tombola)
True
>>> t = TomboList(range(100))
>>> isinstance(t, Tombola)
True
然而,继承受到一个特殊的类属性__mro__的指导——方法解析顺序。它基本上按照 Python 用于搜索方法的顺序列出了类及其超类。¹⁵ 如果你检查TomboList的__mro__,你会看到它只列出了“真正”的超类——list和object:
>>> TomboList.__mro__
(<class 'tombolist.TomboList'>, <class 'list'>, <class 'object'>)
Tombola不在Tombolist.__mro__中,所以Tombolist不会从Tombola继承任何方法。
这结束了我们的TombolaABC 案例研究。在下一节中,我们将讨论registerABC 函数在实际中的使用方式。
实践中的 register 用法
在示例 13-11 中,我们使用Tombola.register作为一个类装饰器。在 Python 3.3 之前,register 不能像那样使用——它必须在类定义之后作为一个普通函数调用,就像示例 13-11 末尾的注释建议的那样。然而,即使现在,它更广泛地被用作一个函数来注册在其他地方定义的类。例如,在collections.abc模块的源代码中,内置类型tuple、str、range和memoryview被注册为Sequence的虚拟子类,就像这样:
Sequence.register(tuple)
Sequence.register(str)
Sequence.register(range)
Sequence.register(memoryview)
其他几种内置类型在*_collections_abc.py*中被注册为 ABC。这些注册只会在导入该模块时发生,这是可以接受的,因为你无论如何都需要导入它来获取 ABC。例如,你需要从collections.abc导入MutableMapping来执行类似isinstance(my_dict, MutableMapping)的检查。
对 ABC 进行子类化或向 ABC 注册都是显式使我们的类通过issubclass检查的方法,以及依赖于issubclass的isinstance检查。但有些 ABC 也支持结构化类型。下一节将解释。
带有 ABCs 的结构化类型
ABC 主要与名义类型一起使用。当类Sub明确从AnABC继承,或者与AnABC注册时,AnABC的名称与Sub类关联起来—这就是在运行时,issubclass(AnABC, Sub)返回True的原因。
相比之下,结构类型是通过查看对象的公共接口结构来确定其类型的:如果一个对象实现了类型定义中定义的方法,则它与该类型一致。动态和静态鸭子类型是结构类型的两种方法。
事实证明,一些 ABC 也支持结构类型。在他的文章“水禽和 ABC”中,Alex 表明一个类即使没有注册也可以被识别为 ABC 的子类。以下是他的例子,增加了使用issubclass的测试:
>>> class Struggle:
... def __len__(self): return 23
...
>>> from collections import abc
>>> isinstance(Struggle(), abc.Sized)
True
>>> issubclass(Struggle, abc.Sized)
True
类Struggle被issubclass函数认为是abc.Sized的子类(因此,也被isinstance认为是)因为abc.Sized实现了一个名为__subclasshook__的特殊类方法。
Sized的__subclasshook__检查类参数是否有名为__len__的属性。如果有,那么它被视为Sized的虚拟子类。参见示例 13-12。
示例 13-12。来自Lib/_collections_abc.py源代码中Sized的定义
class Sized(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __len__(self):
return 0
@classmethod
def __subclasshook__(cls, C):
if cls is Sized:
if any("__len__" in B.__dict__ for B in C.__mro__): # ①
return True # ②
return NotImplemented # ③
①
如果在C.__mro__中列出的任何类(即C及其超类)的__dict__中有名为__len__的属性…
②
…返回True,表示C是Sized的虚拟子类。
③
否则返回NotImplemented以让子类检查继续进行。
注意
如果你对子类检查的细节感兴趣,请查看 Python 3.6 中ABCMeta.__subclasscheck__方法的源代码:Lib/abc.py。注意:它有很多的 if 语句和两次递归调用。在 Python 3.7 中,Ivan Levkivskyi 和 Inada Naoki 为了更好的性能,用 C 重写了abc模块的大部分逻辑。参见Python 问题 #31333。当前的ABCMeta.__subclasscheck__实现只是调用了_abc_subclasscheck。相关的 C 源代码在cpython/Modules/_abc.c#L605中。
这就是__subclasshook__如何使 ABC 支持结构类型。你可以用 ABC 规范化一个接口,可以对该 ABC 进行isinstance检查,而仍然可以让一个完全不相关的类通过issubclass检查,因为它实现了某个方法(或者因为它做了足够的事情来说服__subclasshook__为它背书)。
在我们自己的 ABC 中实现__subclasshook__是个好主意吗?可能不是。我在 Python 源代码中看到的所有__subclasshook__的实现都在像Sized这样声明了一个特殊方法的 ABC 中,它们只是检查那个特殊方法的名称。鉴于它们的“特殊”地位,你可以非常确定任何名为__len__的方法都会按照你的期望工作。但即使在特殊方法和基本 ABC 的领域,做出这样的假设也是有风险的。例如,映射实现了__len__、__getitem__和__iter__,但它们被正确地不认为是Sequence的子类型,因为你不能使用整数偏移或切片检索项目。这就是为什么abc.Sequence类不实现__subclasshook__。
对于你和我可能编写的 ABCs,__subclasshook__可能会更不可靠。我不准备相信任何实现或继承load、pick、inspect和loaded的Spam类都能保证像Tombola一样行为。最好让程序员通过将Spam从Tombola继承或使用Tombola.register(Spam)来确认。当然,你的__subclasshook__也可以检查方法签名和其他特性,但我认为这并不值得。
静态协议
注意
静态协议是在“静态协议”(第八章)中引入的。我考虑延迟对协议的所有覆盖,直到本章,但决定最初在函数中的类型提示的介绍中包括协议,因为鸭子类型是 Python 的一个重要部分,而没有协议的静态类型检查无法很好地处理 Pythonic API。
我们将通过两个简单示例和对数字 ABCs 和协议的讨论来结束本章。让我们首先展示静态协议如何使得我们可以对我们在“类型由支持的操作定义”中首次看到的double()函数进行注释和类型检查。
有类型的 double 函数
当向更习惯于静态类型语言的程序员介绍 Python 时,我最喜欢的一个例子就是这个简单的double函数:
>>> def double(x):
... return x * 2
...
>>> double(1.5)
3.0
>>> double('A')
'AA'
>>> double([10, 20, 30])
[10, 20, 30, 10, 20, 30]
>>> from fractions import Fraction
>>> double(Fraction(2, 5))
Fraction(4, 5)
在引入静态协议之前,没有实际的方法可以为double添加类型提示,而不限制其可能的用途。¹⁷
由于鸭子类型的存在,double甚至可以与未来的类型一起使用,比如我们将在“为标量乘法重载 *”(第十六章)中看到的增强Vector类:
>>> from vector_v7 import Vector
>>> double(Vector([11.0, 12.0, 13.0]))
Vector([22.0, 24.0, 26.0])
Python 中类型提示的初始实现是一种名义类型系统:注释中的类型名称必须与实际参数的类型名称或其超类的名称匹配。由于不可能命名所有支持所需操作的协议的类型,因此在 Python 3.8 之前无法通过类型提示描述鸭子类型。
现在,通过typing.Protocol,我们可以告诉 Mypy,double接受一个支持x * 2的参数x。示例 13-13 展示了如何实现。
示例 13-13. double_protocol.py: 使用Protocol定义double的定义
from typing import TypeVar, Protocol
T = TypeVar('T') # ①
class Repeatable(Protocol):
def __mul__(self: T, repeat_count: int) -> T: ... # ②
RT = TypeVar('RT', bound=Repeatable) # ③
def double(x: RT) -> RT: # ④
return x * 2
①
我们将在__mul__签名中使用这个T。
②
__mul__是Repeatable协议的本质。self参数通常不会被注释,其类型被假定为类。在这里,我们使用T来确保结果类型与self的类型相同。此外,请注意,此协议中的repeat_count限制为int。
③
RT类型变量受Repeatable协议的约束:类型检查器将要求实际类型实现Repeatable。
④
现在类型检查器能够验证x参数是一个可以乘以整数的对象,并且返回值与x的类型相同。
本示例说明了为什么PEP 544的标题是“协议:结构子类型(静态鸭子类型)”。给定给double的实际参数x的名义类型是无关紧要的,只要它呱呱叫,也就是说,只要它实现了__mul__。
可运行时检查的静态协议
在类型映射中(图 13-1),typing.Protocol出现在静态检查区域—图表的下半部分。然而,当定义typing.Protocol子类时,您可以使用@runtime_checkable装饰器使该协议支持运行时的isinstance/issubclass检查。这是因为typing.Protocol是一个 ABC,因此支持我们在“使用 ABC 进行结构化类型检查”中看到的__subclasshook__。
截至 Python 3.9,typing模块包含了七个可供直接使用的运行时可检查的协议。以下是其中两个,直接引用自typing文档:
class typing.SupportsComplex
一个具有一个抽象方法__complex__的 ABC。
class typing.SupportsFloat
一个具有一个抽象方法__float__的 ABC。
这些协议旨在检查数值类型的“可转换性”:如果一个对象o实现了__complex__,那么您应该能够通过调用complex(o)来获得一个complex——因为__complex__特殊方法存在是为了支持complex()内置函数。
示例 13-14 展示了typing.SupportsComplex协议的源代码。
示例 13-14. typing.SupportsComplex协议源代码
@runtime_checkable
class SupportsComplex(Protocol):
"""An ABC with one abstract method __complex__."""
__slots__ = ()
@abstractmethod
def __complex__(self) -> complex:
pass
关键在于__complex__抽象方法。¹⁸ 在静态类型检查期间,如果一个对象实现了只接受self并返回complex的__complex__方法,则该对象将被视为与SupportsComplex协议一致。
由于@runtime_checkable类装饰器应用于SupportsComplex,因此该协议也可以与isinstance检查一起在示例 13-15 中使用。
示例 13-15. 在运行时使用SupportsComplex
>>> from typing import SupportsComplex
>>> import numpy as np
>>> c64 = np.complex64(3+4j) # ①
>>> isinstance(c64, complex) # ②
False >>> isinstance(c64, SupportsComplex) # ③
True >>> c = complex(c64) # ④
>>> c
(3+4j) >>> isinstance(c, SupportsComplex) # ⑤
False >>> complex(c)
(3+4j)
①
complex64是 NumPy 提供的五种复数类型之一。
②
NumPy 的任何复数类型都不是内置的complex的子类。
③
但 NumPy 的复数类型实现了__complex__,因此它们符合SupportsComplex协议。
④
因此,您可以从中创建内置的complex对象。
⑤
遗憾的是,complex内置类型不实现__complex__,尽管如果c是complex,那么complex(c)可以正常工作。
由于上述最后一点,如果您想测试对象c是否为complex或SupportsComplex,您可以将类型元组作为isinstance的第二个参数提供,就像这样:
isinstance(c, (complex, SupportsComplex))
另一种方法是使用numbers模块中定义的Complex ABC。内置的complex类型和 NumPy 的complex64和complex128类型都注册为numbers.Complex的虚拟子类,因此这样可以工作:
>>> import numbers
>>> isinstance(c, numbers.Complex)
True
>>> isinstance(c64, numbers.Complex)
True
在第一版的流畅的 Python中,我推荐使用numbers ABCs,但现在这不再是一个好建议,因为这些 ABCs 不被静态类型检查器识别,正如我们将在“数字 ABC 和数值协议”中看到的那样。
在本节中,我想演示一个运行时可检查的协议如何与isinstance一起工作,但事实证明这个示例并不是isinstance的一个特别好的用例,因为侧边栏“鸭子类型是你的朋友”解释了这一点。
提示
如果您正在使用外部类型检查器,那么显式的isinstance检查有一个优点:当您编写一个条件为isinstance(o, MyType)的if语句时,那么 Mypy 可以推断在if块内,o对象的类型与MyType一致。
现在我们已经看到如何在运行时使用静态协议与预先存在的类型如complex和numpy.complex64,我们需要讨论运行时可检查协议的限制。
运行时协议检查的限制
我们已经看到类型提示通常在运行时被忽略,这也影响了对静态协议进行isinstance或issubclass检查。
例如,任何具有__float__方法的类在运行时被认为是SupportsFloat的虚拟子类,即使__float__方法不返回float。
查看这个控制台会话:
>>> import sys
>>> sys.version
'3.9.5 (v3.9.5:0a7dcbdb13, May 3 2021, 13:17:02) \n[Clang 6.0 (clang-600.0.57)]'
>>> c = 3+4j
>>> c.__float__
<method-wrapper '__float__' of complex object at 0x10a16c590>
>>> c.__float__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't convert complex to float
在 Python 3.9 中,complex类型确实有一个__float__方法,但它只是为了引发一个带有明确错误消息的TypeError。如果那个__float__方法有注释,返回类型将是NoReturn,我们在NoReturn中看到过。
但在typeshed上对complex.__float__进行类型提示不会解决这个问题,因为 Python 的运行时通常会忽略类型提示,并且无法访问typeshed存根文件。
继续前面的 Python 3.9 会话:
>>> from typing import SupportsFloat
>>> c = 3+4j
>>> isinstance(c, SupportsFloat)
True
>>> issubclass(complex, SupportsFloat)
True
因此我们有了误导性的结果:针对SupportsFloat的运行时检查表明你可以将complex转换为float,但实际上会引发类型错误。
警告
Python 3.10.0b4 中修复了complex类型的特定问题,移除了complex.__float__方法。
但总体问题仍然存在:isinstance/issubclass检查只关注方法的存在或不存在,而不检查它们的签名,更不用说它们的类型注释了。而且这不太可能改变,因为这样的运行时类型检查会带来无法接受的性能成本。¹⁹
现在让我们看看如何在用户定义的类中实现静态协议。
支持静态协议
回想一下我们在第十一章中构建的Vector2d类。考虑到complex数和Vector2d实例都由一对浮点数组成,支持从Vector2d到complex的转换是有意义的。
示例 13-16 展示了__complex__方法的实现,以增强我们在示例 11-11 中看到的Vector2d的最新版本。为了完整起见,我们可以通过一个fromcomplex类方法支持反向操作,从complex构建一个Vector2d。
示例 13-16. vector2d_v4.py: 转换为和从complex的方法
def __complex__(self):
return complex(self.x, self.y)
@classmethod
def fromcomplex(cls, datum):
return cls(datum.real, datum.imag) # ①
①
这假设datum有.real和.imag属性。我们将在示例 13-17 中看到一个更好的实现。
鉴于前面的代码,以及Vector2d在示例 11-11 中已经有的__abs__方法,我们得到了这些特性:
>>> from typing import SupportsComplex, SupportsAbs
>>> from vector2d_v4 import Vector2d
>>> v = Vector2d(3, 4)
>>> isinstance(v, SupportsComplex)
True
>>> isinstance(v, SupportsAbs)
True
>>> complex(v)
(3+4j)
>>> abs(v)
5.0
>>> Vector2d.fromcomplex(3+4j)
Vector2d(3.0, 4.0)
对于运行时类型检查,示例 13-16 是可以的,但为了更好的静态覆盖和使用 Mypy 进行错误报告,__abs__,__complex__ 和 fromcomplex 方法应该得到类型提示,如示例 13-17 所示。
示例 13-17. vector2d_v5.py: 为研究中的方法添加注释
def __abs__(self) -> float: # ①
return math.hypot(self.x, self.y)
def __complex__(self) -> complex: # ②
return complex(self.x, self.y)
@classmethod
def fromcomplex(cls, datum: SupportsComplex) -> Vector2d: # ③
c = complex(datum) # ④
return cls(c.real, c.imag)
①
需要float返回注释,否则 Mypy 推断为Any,并且不检查方法体。
②
即使没有注释,Mypy 也能推断出这返回一个complex。根据您的 Mypy 配置,注释可以避免警告。
③
这里SupportsComplex确保datum是可转换的。
④
这种显式转换是必要的,因为SupportsComplex类型没有声明.real和.imag属性,这在下一行中使用。例如,Vector2d没有这些属性,但实现了__complex__。
如果在模块顶部出现from __future__ import annotations,fromcomplex的返回类型可以是Vector2d。这个导入会导致类型提示被存储为字符串,而不会在导入时被评估,当函数定义被评估时。没有__future__导入annotations,此时Vector2d是一个无效的引用(类尚未完全定义),应该写成字符串:'Vector2d',就好像它是一个前向引用一样。这个__future__导入是在PEP 563—注解的延迟评估中引入的,实现在 Python 3.7 中。这种行为原计划在 3.10 中成为默认值,但该更改被推迟到以后的版本。²⁰ 当这种情况发生时,这个导入将是多余的,但无害的。
接下来,让我们看看如何创建——以及稍后扩展——一个新的静态协议。
设计一个静态协议
在学习鹅类型时,我们在“定义和使用 ABC”中看到了Tombola ABC。在这里,我们将看到如何使用静态协议定义一个类似的接口。
Tombola ABC 指定了两种方法:pick和load。我们也可以定义一个具有这两种方法的静态协议,但我从 Go 社区中学到,单方法协议使得静态鸭子类型更有用和灵活。Go 标准库有几个类似Reader的接口,这是一个仅需要read方法的 I/O 接口。过一段时间,如果你意识到需要一个更完整的协议,你可以将两个或更多的协议组合起来定义一个新的协议。
使用随机选择项目的容器可能需要重新加载容器,也可能不需要,但肯定需要一种方法来实际选择,因此这就是我选择最小RandomPicker协议的方法。该协议的代码在示例 13-18 中,其使用由示例 13-19 中的测试演示。
示例 13-18。randompick.py:RandomPicker的定义
from typing import Protocol, runtime_checkable, Any
@runtime_checkable
class RandomPicker(Protocol):
def pick(self) -> Any: ...
注意
pick方法返回Any。在“实现通用静态协议”中,我们将看到如何使RandomPicker成为一个带有参数的通用类型,让协议的使用者指定pick方法的返回类型。
示例 13-19。randompick_test.py:RandomPicker的使用
import random
from typing import Any, Iterable, TYPE_CHECKING
from randompick import RandomPicker # ①
class SimplePicker: # ②
def __init__(self, items: Iterable) -> None:
self._items = list(items)
random.shuffle(self._items)
def pick(self) -> Any: # ③
return self._items.pop()
def test_isinstance() -> None: # ④
popper: RandomPicker = SimplePicker([1]) # ⑤
assert isinstance(popper, RandomPicker) # ⑥
def test_item_type() -> None: # ⑦
items = [1, 2]
popper = SimplePicker(items)
item = popper.pick()
assert item in items
if TYPE_CHECKING:
reveal_type(item) # ⑧
assert isinstance(item, int)
①](#co_interfaces__protocols__and_abcs_CO14-1)
定义实现它的类时,不需要导入静态协议。这里我只导入RandomPicker是为了稍后在test_isinstance中使用它。
②](#co_interfaces__protocols__and_abcs_CO14-2)
SimplePicker实现了RandomPicker——但它并没有继承它。这就是静态鸭子类型的作用。
③](#co_interfaces__protocols__and_abcs_CO14-3)
Any是默认返回类型,因此此注释并不是严格必要的,但它确实使我们正在实现示例 13-18 中定义的RandomPicker协议更清晰。
④](#co_interfaces__protocols__and_abcs_CO14-4)
如果你希望 Mypy 查看测试,请不要忘记为你的测试添加-> None提示。
⑤](#co_interfaces__protocols__and_abcs_CO14-5)
我为popper变量添加了一个类型提示,以显示 Mypy 理解SimplePicker是与之一致的。
⑥](#co_interfaces__protocols__and_abcs_CO14-6)
这个测试证明了SimplePicker的一个实例也是RandomPicker的一个实例。这是因为@runtime_checkable装饰器应用于RandomPicker,并且SimplePicker有一个所需的pick方法。
⑦](#co_interfaces__protocols__and_abcs_CO14-7)
这个测试调用了SimplePicker的pick方法,验证它是否返回了给SimplePicker的项目之一,然后对返回的项目进行了静态和运行时检查。
⑧
这行代码会在 Mypy 输出中生成一个注释。
正如我们在示例 8-22 中看到的,reveal_type是 Mypy 识别的“魔术”函数。这就是为什么它不被导入,我们只能在typing.TYPE_CHECKING保护的if块内调用它,这个块只有在静态类型检查器的眼中才是True,但在运行时是False。
示例 13-19 中的两个测试都通过了。Mypy 在该代码中没有看到任何错误,并显示了pick返回的item上reveal_type的结果:
$ mypy randompick_test.py
randompick_test.py:24: note: Revealed type is 'Any'
创建了我们的第一个协议后,让我们研究一些相关建议。
协议设计的最佳实践
在使用 Go 中的静态鸭子类型 10 年后,很明显,窄协议更有用——通常这样的协议只有一个方法,很少有超过两个方法。Martin Fowler 撰写了一篇定义角色接口的文章,在设计协议时要记住这个有用的概念。
有时候你会看到一个协议在使用它的函数附近定义——也就是说,在“客户端代码”中定义,而不是在库中定义。这样做可以轻松创建新类型来调用该函数,这对于可扩展性和使用模拟进行测试是有益的。
窄协议和客户端代码协议的实践都避免了不必要的紧密耦合,符合接口隔离原则,我们可以总结为“客户端不应被迫依赖于他们不使用的接口”。
页面“贡献给 typeshed”推荐了这种静态协议的命名约定(以下三点引用原文):
-
对于代表清晰概念的协议,请使用简单名称(例如,
Iterator,Container)。 -
对于提供可调用方法的协议,请使用
SupportsX(例如,SupportsInt,SupportsRead,SupportsReadSeek)。²¹ -
对于具有可读和/或可写属性或 getter/setter 方法的协议,请使用
HasX(例如,HasItems,HasFileno)。
Go 标准库有一个我喜欢的命名约定:对于单方法协议,如果方法名是动词,可以添加“-er”或“-or”以使其成为名词。例如,不要使用SupportsRead,而是使用Reader。更多示例包括Formatter,Animator和Scanner。有关灵感,请参阅 Asuka Kenji 的“Go(Golang)标准库接口(精选)”。
创建简约协议的一个好理由是以后可以根据需要扩展它们。我们现在将看到创建一个带有额外方法的派生协议并不困难。
扩展协议
正如我在上一节开始时提到的,Go 开发人员在定义接口时倾向于保持最小主义——他们称之为静态协议。许多最广泛使用的 Go 接口只有一个方法。
当实践表明一个具有更多方法的协议是有用的时候,与其向原始协议添加方法,不如从中派生一个新协议。在 Python 中扩展静态协议有一些注意事项,正如示例 13-20 所示。
示例 13-20. randompickload.py: 扩展RandomPicker
from typing import Protocol, runtime_checkable
from randompick import RandomPicker
@runtime_checkable # ①
class LoadableRandomPicker(RandomPicker, Protocol): # ②
def load(self, Iterable) -> None: ... # ③
①
如果希望派生协议可以进行运行时检查,必须再次应用装饰器——其行为不会被继承。²²
②
每个协议必须明确将typing.Protocol命名为其基类之一,除了我们正在扩展的协议。这与 Python 中继承的方式不同。²³
③
回到“常规”面向对象编程:我们只需要声明这个派生协议中新增的方法。pick方法声明是从RandomPicker继承的。
这结束了本章中定义和使用静态协议的最终示例。
为了结束本章,我们将讨论数字 ABCs 及其可能被数字协议替代的情况。
数字 ABCs 和数字协议
正如我们在“数字塔的崩塌”中看到的,标准库中numbers包中的 ABCs 对于运行时类型检查效果很好。
如果需要检查整数,可以使用isinstance(x, numbers.Integral)来接受int、bool(它是int的子类)或其他由外部库提供并将其类型注册为numbers ABCs 虚拟子类的整数类型。例如,NumPy 有21 种整数类型——以及几种浮点类型注册为numbers.Real,以及以不同位宽注册为numbers.Complex的复数。
提示
令人惊讶的是,decimal.Decimal并未注册为numbers.Real的虚拟子类。原因是,如果您的程序需要Decimal的精度,那么您希望受到保护,以免将精度较低的浮点数与Decimal混合。
遗憾的是,数字塔并不适用于静态类型检查。根 ABC——numbers.Number——没有方法,因此如果声明x: Number,Mypy 将不允许您在x上进行算术运算或调用任何方法。
如果不支持numbers ABCs,那么还有哪些选项?
寻找类型解决方案的好地方是typeshed项目。作为 Python 标准库的一部分,statistics模块有一个对应的statistics.pyi存根文件,其中包含了对typeshed上几个函数进行类型提示的定义。在那里,您会找到以下定义,用于注释几个函数:
_Number = Union[float, Decimal, Fraction]
_NumberT = TypeVar('_NumberT', float, Decimal, Fraction)
这种方法是正确的,但有限。它不支持标准库之外的数字类型,而numbers ABCs 在运行时支持这些数字类型——当数字类型被注册为虚拟子类时。
当前的趋势是推荐typing模块提供的数字协议,我们在“可运行时检查的静态协议”中讨论过。
不幸的是,在运行时,数字协议可能会让您失望。正如在“运行时协议检查的限制”中提到的,Python 3.9 中的complex类型实现了__float__,但该方法仅存在于引发TypeError并附带明确消息“无法将复数转换为浮点数”:同样的原因,它也实现了__int__。这些方法的存在使得在 Python 3.9 中isinstance返回误导性的结果。在 Python 3.10 中,那些无条件引发TypeError的complex方法被移除了。²⁴
另一方面,NumPy 的复数类型实现了__float__和__int__方法,只有在第一次使用每个方法时才会发出警告:
>>> import numpy as np
>>> cd = np.cdouble(3+4j)
>>> cd
(3+4j)
>>> float(cd)
<stdin>:1: ComplexWarning: Casting complex values to real
discards the imaginary part
3.0
相反的问题也会发生:内置类complex、float和int,以及numpy.float16和numpy.uint8,都没有__complex__方法,因此对于它们,isinstance(x, SupportsComplex)返回False。²⁵ NumPy 的复数类型,如np.complex64,确实实现了__complex__以转换为内置的complex。
然而,在实践中,complex()内置构造函数处理所有这些类型的实例都没有错误或警告:
>>> import numpy as np
>>> from typing import SupportsComplex
>>> sample = [1+0j, np.complex64(1+0j), 1.0, np.float16(1.0), 1, np.uint8(1)]
>>> [isinstance(x, SupportsComplex) for x in sample]
[False, True, False, False, False, False]
>>> [complex(x) for x in sample]
[(1+0j), (1+0j), (1+0j), (1+0j), (1+0j), (1+0j)]
这表明isinstance检查对SupportsComplex的转换表明这些转换为complex将失败,但它们都成功了。在 typing-sig 邮件列表中,Guido van Rossum 指出,内置的complex接受一个参数,这就是为什么这些转换起作用的原因。
另一方面,Mypy 在定义如下的to_complex()函数时接受这六种类型的所有参数:
def to_complex(n: SupportsComplex) -> complex:
return complex(n)
在我写这篇文章时,NumPy 没有类型提示,因此其数值类型都是Any。²⁶ 另一方面,Mypy 在某种程度上“意识到”内置的int和float可以转换为complex,尽管在 typeshed 中只有内置的complex类有一个__complex__方法。²⁷
总之,尽管数值类型不应该难以进行类型检查,但目前的情况是:类型提示 PEP 484 避开了数值塔,并隐含地建议类型检查器硬编码内置complex、float和int之间的子类型关系。Mypy 这样做了,并且还实用地接受int和float与SupportsComplex一致,尽管它们没有实现__complex__。
提示
当我尝试将数值Supports*协议与complex进行转换时,使用isinstance检查时我只发现了意外结果。如果你不使用复数,你可以依赖这些协议而不是numbers ABCs。
本节的主要要点是:
-
numbersABCs 适用于运行时类型检查,但不适用于静态类型检查。 -
数值静态协议
SupportsComplex、SupportsFloat等在静态类型检查时效果很好,但在涉及复数时在运行时类型检查时不可靠。
现在我们准备快速回顾本章内容。
章节总结
键盘映射(图 13-1)是理解本章内容的关键。在简要介绍了四种类型方法后,我们对比了动态和静态协议,分别支持鸭子类型和静态鸭子类型。这两种类型的协议共享一个基本特征,即类永远不需要明确声明支持任何特定协议。一个类通过实现必要的方法来支持一个协议。
接下来的主要部分是“编程鸭子”,我们探讨了 Python 解释器为使序列和可迭代动态协议工作所做的努力,包括部分实现两者。然后我们看到一个类如何通过动态添加额外方法来在运行时实现一个协议,通过猴子补丁。鸭子类型部分以防御性编程的提示结束,包括使用try/except检测结构类型而无需显式的isinstance或hasattr检查,并快速失败。
在 Alex Martelli 介绍鹅类型之后“水禽和 ABCs”,我们看到如何对现有的 ABCs 进行子类化,调查了标准库中重要的 ABCs,并从头开始创建了一个 ABC,然后通过传统的子类化和注册来实现。为了结束这一部分,我们看到__subclasshook__特殊方法如何使 ABCs 能够通过识别提供符合 ABC 中定义接口的方法的不相关类来支持结构类型。
最后一个重要部分是“静态协议”,我们在这里恢复了静态鸭子类型的覆盖范围,这始于第八章,在“静态协议”中。我们看到@runtime_checkable装饰器如何利用__subclasshook__来支持运行时的结构化类型,尽管最佳使用静态协议的方式是与静态类型检查器一起使用,这样可以考虑类型提示以使结构化类型更可靠。接下来,我们讨论了静态协议的设计和编码以及如何扩展它。本章以“数字 ABCs 和数字协议”结束,讲述了数字塔的荒废状态以及提出的替代方案存在的一些缺陷:Python 3.8 中添加到typing模块的数字静态协议,如SupportsFloat等。
本章的主要信息是我们在现代 Python 中有四种互补的接口编程方式,每种方式都有不同的优势和缺点。在任何规模较大的现代 Python 代码库中,您可能会发现每种类型方案都有适用的用例。拒绝这些方法中的任何一种都会使您作为 Python 程序员的工作变得比必要的更加困难。
话虽如此,Python 在仅支持鸭子类型的情况下取得了广泛的流行。其他流行的语言,如 JavaScript、PHP 和 Ruby,以及 Lisp、Smalltalk、Erlang 和 Clojure 等不那么流行但非常有影响力的语言,都通过利用鸭子类型的力量和简单性产生了巨大影响。
进一步阅读
要快速了解类型的利弊,以及typing.Protocol对于静态检查代码库健康的重要性,我强烈推荐 Glyph Lefkowitz 的帖子“我想要一个新的鸭子:typing.Protocol和鸭子类型的未来”。我还从他的帖子“接口和协议”中学到了很多,比较了typing.Protocol和zope.interface——一种早期用于在松散耦合的插件系统中定义接口的机制,被Plone CMS、Pyramid web framework和Twisted异步编程框架等项目使用,这是 Glyph 创建的一个项目。²⁸
有关 Python 的优秀书籍几乎可以定义为对鸭子类型的广泛覆盖。我最喜欢的两本 Python 书籍在Fluent Python第一版之后发布了更新:Naomi Ceder 的The Quick Python Book第 3 版(Manning)和 Alex Martelli、Anna Ravenscroft 和 Steve Holden(O’Reilly)的Python in a Nutshell第 3 版。
有关动态类型的利弊讨论,请参阅 Guido van Rossum 与 Bill Venners 的访谈“Python 中的合同:与 Guido van Rossum 的对话,第四部分”。Martin Fowler 在他的帖子“动态类型”中对这场辩论进行了深入而平衡的探讨。他还写了“角色接口”,我在“最佳协议设计实践”中提到过。尽管这不是关于鸭子类型的,但这篇文章对 Python 协议设计非常相关,因为他对比了狭窄的角色接口与一般类的更广泛的公共接口。
Mypy 文档通常是与 Python 中静态类型相关的任何信息的最佳来源,包括他们在“协议和结构子类型”章节中讨论的静态鸭子类型。
剩下的参考资料都是关于鹅类型的。Beazley 和 Jones 的*Python Cookbook*,第 3 版(O’Reilly)有一节关于定义 ABC(Recipe 8.12)。这本书是在 Python 3.4 之前编写的,所以他们没有使用现在更受欢迎的通过从abc.ABC子类化来声明 ABC 的语法(相反,他们使用了metaclass关键字,我们只在第二十四章中真正需要它)。除了这个小细节,这个配方很好地涵盖了主要的 ABC 特性。
Doug Hellmann 的Python 标准库示例(Addison-Wesley)中有一章关于abc模块。它也可以在 Doug 出色的PyMOTW—Python 本周模块网站上找到。Hellmann 还使用了旧式的 ABC 声明方式:PluginBase(metaclass=abc.ABCMeta),而不是自 Python 3.4 起可用的更简单的PluginBase(abc.ABC)。
在使用 ABCs 时,多重继承不仅很常见,而且几乎是不可避免的,因为每个基本集合 ABCs—Sequence、Mapping和Set—都扩展了Collection,而Collection又扩展了多个 ABCs(参见图 13-4)。因此,第十四章是本章的一个重要后续。
PEP 3119—引入抽象基类 提供了 ABC 的理由。PEP 3141—数字类型的类型层次结构 展示了numbers模块的 ABC,但在 Mypy 问题#3186 “int is not a Number?”的讨论中包含了一些关于为什么数字塔不适合静态类型检查的论点。Alex Waygood 在 StackOverflow 上写了一个全面的答案,讨论了注释数字类型的方法。我将继续关注 Mypy 问题#3186,期待这个传奇的下一章有一个让静态类型和鹅类型兼容的美好结局——因为它们应该是兼容的。
¹ 设计模式:可复用面向对象软件的元素,“介绍”,p. 18。
² Wikipedia 上的“猴子补丁”文章中有一个有趣的 Python 示例。
³ 这就是为什么自动化测试是必要的。
⁴ Bjarne Stroustrup, C++的设计与演化, p. 278 (Addison-Wesley)。
⁵ 检索日期为 2020 年 10 月 18 日。
⁶ 当然,你也可以定义自己的 ABCs,但我会劝阻除了最高级的 Pythonista 之外的所有人这样做,就像我会劝阻他们定义自己的自定义元类一样……即使对于那些拥有对语言的每一个折叠和褶皱深度掌握的“最高级的 Pythonista”来说,这些都不是经常使用的工具。这种“深度元编程”,如果适用的话,是为了那些打算由大量独立开发团队扩展的广泛框架的作者而设计的……不到“最高级的 Pythonista”的 1%可能会需要这个! — A.M.
⁷ 多重继承被认为是有害的,并且在 Java 中被排除,除了接口:Java 接口可以扩展多个接口,Java 类可以实现多个接口。
⁸ 或许客户需要审计随机器;或者机构想提供一个作弊的随机器。你永远不知道……
⁹ “注册”和“虚拟子类”不是标准的 UML 术语。我使用它们来表示一个特定于 Python 的类关系。
¹⁰ 在抽象基类存在之前,抽象方法会引发NotImplementedError来表示子类负责实现它们。在 Smalltalk-80 中,抽象方法体会调用subclassResponsibility,这是从object继承的一个方法,它会产生一个带有消息“我的子类应该重写我的消息之一”的错误。
¹¹ 完整的树在《Python 标准库》文档的“5.4. 异常层次结构”部分中。
¹² @abc.abstractmethod在abc模块文档中的条目。
¹³ 第六章中的“使用可变参数进行防御性编程”专门讨论了我们刚刚避免的别名问题。
¹⁴ 我用load()的相同技巧无法用于loaded(),因为list类型没有实现__bool__,我必须绑定到loaded的方法。bool() 内置不需要__bool__就能工作,因为它也可以使用__len__。请参阅 Python 文档的“内置类型”章节中的“4.1. 真值测试”。
¹⁵ 在“多重继承和方法解析顺序”中有一个完整的解释__mro__类属性的部分。现在,这个简短的解释就够了。
¹⁶ 类型一致性的概念在“子类型与一致性”中有解释。
¹⁷ 好吧,double() 并不是很有用,除了作为一个例子。但是在 Python 3.8 添加静态协议之前,Python 标准库有许多函数无法正确注释。我通过使用协议添加类型提示来帮助修复了 typeshed 中的一些错误。例如,修复“Mypy 是否应该警告可能无效的 max 参数?”的拉取请求利用了一个 _SupportsLessThan 协议,我用它增强了 max、min、sorted 和 list.sort 的注释。
¹⁸ __slots__ 属性与当前讨论无关—这是我们在“使用 slots 节省内存”中讨论的优化。
¹⁹ 感谢 PEP 544(关于协议)的合著者伊万·列夫基夫斯基指出,类型检查不仅仅是检查x的类型是否为T:它是关于确定x的类型与T是一致的,这可能是昂贵的。难怪 Mypy 即使对短小的 Python 脚本进行类型检查也需要几秒钟的时间。
²⁰ 阅读 Python Steering Council 在 python-dev 上的决定。
²¹ 每个方法都是可调用的,所以这个准则并没有说太多。也许“提供一个或两个方法”?无论如何,这只是一个指导方针,不是一个严格的规则。
²² 有关详细信息和原理,请参阅 PEP 544 中关于@runtime_checkable的部分—协议:结构子类型(静态鸭子类型)。
²³ 再次,请阅读 PEP 544 中关于“合并和扩展协议”的详细信息和原理。
²⁴ 请参阅Issue #41974—删除 complex.__float__、complex.__floordiv__ 等。
²⁵ 我没有测试 NumPy 提供的所有其他浮点数和整数变体。
²⁶ NumPy 的数字类型都已注册到相应的numbers ABCs 中,但 Mypy 忽略了这一点。
²⁷ 这是 typeshed 的一种善意的谎言:截至 Python 3.9,内置的complex类型实际上并没有__complex__方法。
²⁸ 感谢技术审阅者 Jürgen Gmach 推荐“接口和协议”文章。
第十四章:继承:是好是坏
[…] 我们需要一个更好的关于继承的理论(现在仍然需要)。例如,继承和实例化(这是一种继承)混淆了实用性(例如为了节省空间而分解代码)和语义(用于太多任务,如:专门化、泛化、种类化等)。
Alan Kay,“Smalltalk 的早期历史”¹
本章讨论继承和子类化。我假设你对这些概念有基本的了解,你可能从阅读Python 教程或从其他主流面向对象语言(如 Java、C#或 C++)的经验中了解这些概念。在这里,我们将重点关注 Python 的四个特点:
-
super()函数
-
从内置类型继承的陷阱
-
多重继承和方法解析顺序
-
Mixin 类
多重继承是一个类具有多个基类的能力。C++支持它;Java 和 C#不支持。许多人认为多重继承带来的麻烦不值得。在早期 C++代码库中被滥用后,Java 故意将其排除在外。
本章介绍了多重继承,供那些从未使用过的人,并提供了一些关于如何应对单一或多重继承的指导,如果你必须使用它。
截至 2021 年,对继承的过度使用存在明显的反对意见,不仅仅是多重继承,因为超类和子类之间紧密耦合。紧密耦合意味着对程序的某一部分进行更改可能会在其他部分产生意想不到的深远影响,使系统变得脆弱且难以理解。
然而,我们必须维护设计有复杂类层次结构的现有系统,或者使用强制我们使用继承的框架——有时甚至是多重继承。
我将通过标准库、Django 网络框架和 Tkinter GUI 工具包展示多重继承的实际用途。
本章新内容
本章主题没有与 Python 相关的新功能,但我根据第二版技术审阅人员的反馈进行了大量编辑,特别是 Leonardo Rochael 和 Caleb Hattingh。
我写了一个新的开头部分,重点关注super()内置函数,并更改了“多重继承和方法解析顺序”中的示例,以更深入地探讨super()如何支持协作式 多重继承。
“Mixin 类”也是新内容。“现实世界中的多重继承”已重新组织,并涵盖了标准库中更简单的 mixin 示例,然后是复杂的 Django 和复杂的 Tkinter 层次结构。
正如章节标题所示,继承的注意事项一直是本章的主要主题之一。但越来越多的开发人员认为这是一个问题,我在“章节总结”和“进一步阅读”的末尾添加了几段关于避免继承的内容。
我们将从神秘的super()函数的概述开始。
super()函数
对于可维护的面向对象 Python 程序,一致使用super()内置函数至关重要。
当子类重写超类的方法时,通常需要调用超类的相应方法。以下是推荐的方法,来自collections模块文档中的一个示例,“OrderedDict 示例和配方”部分:²
class LastUpdatedOrderedDict(OrderedDict):
"""Store items in the order they were last updated"""
def __setitem__(self, key, value):
super().__setitem__(key, value)
self.move_to_end(key)
为了完成其工作,LastUpdatedOrderedDict重写了__setitem__以:
-
使用
super().__setitem__调用超类上的该方法,让其插入或更新键/值对。 -
调用
self.move_to_end以确保更新的key位于最后位置。
调用重写的__init__方法特别重要,以允许超类在初始化实例时发挥作用。
提示
如果你在 Java 中学习面向对象编程,可能会记得 Java 构造方法会自动调用超类的无参构造方法。Python 不会这样做。你必须习惯编写这种模式:
def __init__(self, a, b) :
super().__init__(a, b)
... # more initialization code
你可能见过不使用super()而是直接在超类上调用方法的代码,就像这样:
class NotRecommended(OrderedDict):
"""This is a counter example!"""
def __setitem__(self, key, value):
OrderedDict.__setitem__(self, key, value)
self.move_to_end(key)
这种替代方法在这种特定情况下有效,但出于两个原因不建议使用。首先,它将基类硬编码了。OrderedDict的名称出现在class语句中,也出现在__setitem__中。如果将来有人更改class语句以更改基类或添加另一个基类,他们可能会忘记更新__setitem__的内容,从而引入错误。
第二个原因是,super实现了处理具有多重继承的类层次结构的逻辑。我们将在“多重继承和方法解析顺序”中回顾这一点。为了总结这个关于super的复习,回顾一下在 Python 2 中我们如何调用它,因为旧的带有两个参数的签名是具有启发性的:
class LastUpdatedOrderedDict(OrderedDict):
"""This code works in Python 2 and Python 3"""
def __setitem__(self, key, value):
super(LastUpdatedOrderedDict, self).__setitem__(key, value)
self.move_to_end(key)
现在super的两个参数都是可选的。Python 3 字节码编译器在调用方法中的super()时会自动检查周围的上下文并提供这些参数。这些参数是:
type
实现所需方法的超类的搜索路径的起始位置。默认情况下,它是包含super()调用的方法所属的类。
object_or_type
对象(例如方法调用)或类(例如类方法调用)作为方法调用的接收者。默认情况下,如果super()调用发生在实例方法中,接收者就是self。
无论是你还是编译器提供这些参数,super()调用都会返回一个动态代理对象,该对象会在type参数的超类中找到一个方法(例如示例中的__setitem__),并将其绑定到object_or_type,这样在调用方法时就不需要显式传递接收者(self)了。
在 Python 3 中,你仍然可以显式提供super()的第一个和第二个参数。³ 但只有在特殊情况下才需要,例如跳过部分 MRO 进行测试或调试,或者解决超类中不希望的行为。
现在让我们讨论对内置类型进行子类化时的注意事项。
对内置类型进行子类化是棘手的
在 Python 的最早版本中,无法对list或dict等内置类型进行子类化。自 Python 2.2 起,虽然可以实现,但有一个重要的警告:内置类型的代码(用 C 编写)通常不会调用用户定义类中重写的方法。关于这个问题的一个简短描述可以在 PyPy 文档的“PyPy 和 CPython 之间的区别”部分中找到,“内置类型的子类”。
官方上,CPython 没有明确规定子类中重写的方法何时会被隐式调用或不会被调用。作为近似值,这些方法永远不会被同一对象的其他内置方法调用。例如,在
dict的子类中重写的__getitem__()不会被内置的get()方法调用。
示例 14-1 说明了这个问题。
示例 14-1. 我们对__setitem__的重写被内置dict的__init__和__update__方法所忽略。
>>> class DoppelDict(dict):
... def __setitem__(self, key, value):
... super().__setitem__(key, [value] * 2) # ①
...
>>> dd = DoppelDict(one=1) # ②
>>> dd
{'one': 1} >>> dd['two'] = 2 # ③
>>> dd
{'one': 1, 'two': [2, 2]} >>> dd.update(three=3) # ④
>>> dd
{'three': 3, 'one': 1, 'two': [2, 2]}
①
DoppelDict.__setitem__在存储时会复制值(没有好理由,只是为了有一个可见的效果)。它通过委托给超类来实现。
②
从dict继承的__init__方法明显忽略了__setitem__的重写:'one'的值没有复制。
③
[]操作符调用我们的__setitem__,并按预期工作:'two'映射到重复的值[2, 2]。
④
dict的update方法也没有使用我们的__setitem__版本:'three'的值没有被复制。
这种内置行为违反了面向对象编程的一个基本规则:方法的搜索应始终从接收者的类(self)开始,即使调用发生在一个由超类实现的方法内部。这就是所谓的“后期绑定”,Smalltalk 之父 Alan Kay 认为这是面向对象编程的一个关键特性:在任何形式为x.method()的调用中,要调用的确切方法必须在运行时确定,基于接收者x的类。⁴ 这种令人沮丧的情况导致了我们在“标准库中 missing 的不一致使用”中看到的问题。
问题不仅限于实例内的调用——无论self.get()是否调用self.__getitem__()——还会发生在其他类的覆盖方法被内置方法调用时。示例 14-2 改编自PyPy 文档。
示例 14-2. AnswerDict的__getitem__被dict.update绕过。
>>> class AnswerDict(dict):
... def __getitem__(self, key): # ①
... return 42
...
>>> ad = AnswerDict(a='foo') # ②
>>> ad['a'] # ③
42 >>> d = {}
>>> d.update(ad) # ④
>>> d['a'] # ⑤
'foo' >>> d
{'a': 'foo'}
①
AnswerDict.__getitem__总是返回42,无论键是什么。
②
ad是一个加载了键-值对('a', 'foo')的AnswerDict。
③
ad['a']返回42,如预期。
④
d是一个普通dict的实例,我们用ad来更新它。
⑤
dict.update方法忽略了我们的AnswerDict.__getitem__。
警告
直接对dict、list或str等内置类型进行子类化是容易出错的,因为内置方法大多忽略用户定义的覆盖。不要对内置类型进行子类化,而是从collections模块派生你的类,使用UserDict、UserList和UserString,这些类设计得易于扩展。
如果你继承collections.UserDict而不是dict,那么示例 14-1 和 14-2 中暴露的问题都会得到解决。请参见示例 14-3。
示例 14-3. DoppelDict2和AnswerDict2按预期工作,因为它们扩展了UserDict而不是dict。
>>> import collections
>>>
>>> class DoppelDict2(collections.UserDict):
... def __setitem__(self, key, value):
... super().__setitem__(key, [value] * 2)
...
>>> dd = DoppelDict2(one=1)
>>> dd
{'one': [1, 1]}
>>> dd['two'] = 2
>>> dd
{'two': [2, 2], 'one': [1, 1]}
>>> dd.update(three=3)
>>> dd
{'two': [2, 2], 'three': [3, 3], 'one': [1, 1]}
>>>
>>> class AnswerDict2(collections.UserDict):
... def __getitem__(self, key):
... return 42
...
>>> ad = AnswerDict2(a='foo')
>>> ad['a']
42
>>> d = {}
>>> d.update(ad)
>>> d['a']
42
>>> d
{'a': 42}
为了衡量子类化内置类型所需的额外工作,我将示例 3-9 中的StrKeyDict类重写为子类化dict而不是UserDict。为了使其通过相同的测试套件,我不得不实现__init__、get和update,因为从dict继承的版本拒绝与覆盖的__missing__、__contains__和__setitem__合作。UserDict子类从示例 3-9 开始有 16 行,而实验性的dict子类最终有 33 行。⁵
明确一点:本节只涉及内置类型的 C 语言代码中方法委托的问题,只影响直接从这些类型派生的类。如果你子类化了一个用 Python 编写的基类,比如UserDict或MutableMapping,你就不会受到这个问题的困扰。⁶
现在让我们关注一个在多重继承中出现的问题:如果一个类有两个超类,当我们调用super().attr时,Python 如何决定使用哪个属性,但两个超类都有同名属性?
多重继承和方法解析顺序
任何实现多重继承的语言都需要处理当超类实现同名方法时可能出现的命名冲突。这称为“菱形问题”,在图 14-1 和示例 14-4 中有所说明。
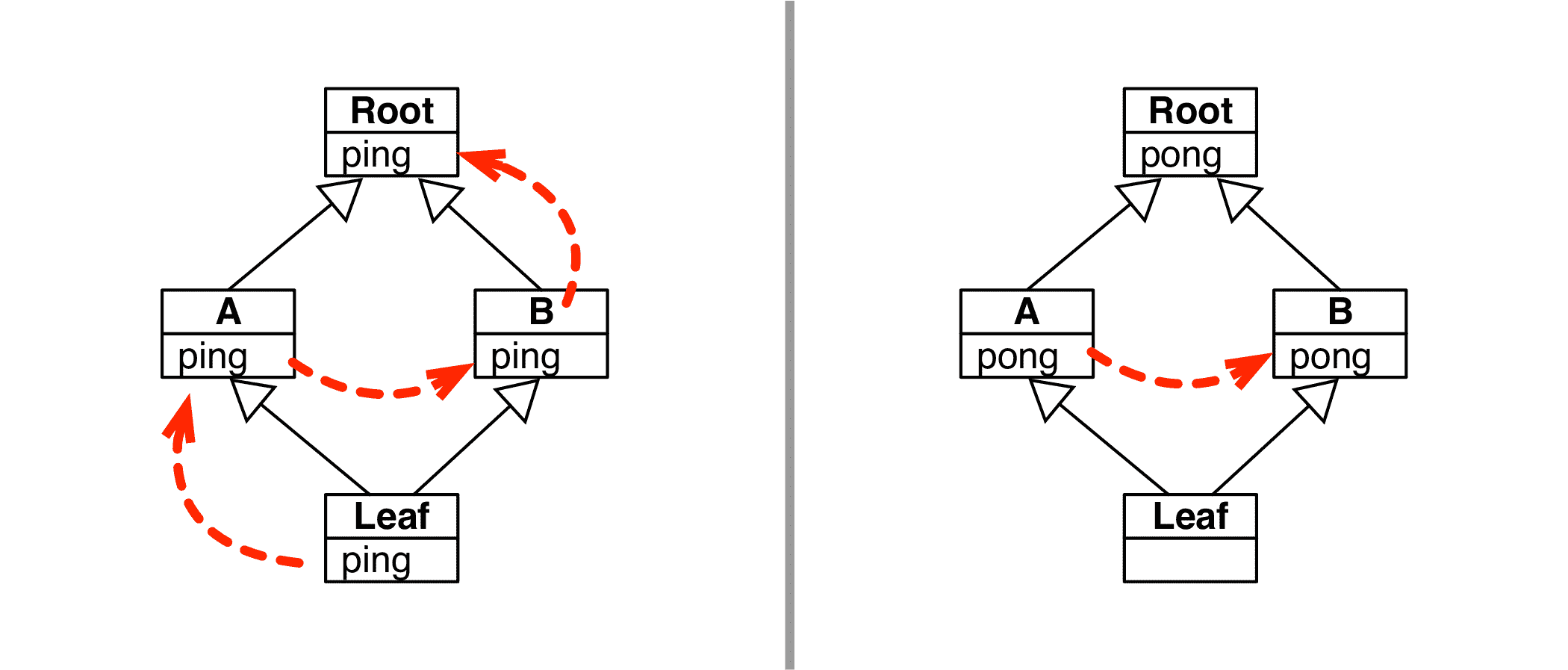
图 14-1. 左:leaf1.ping()调用的激活顺序。右:leaf1.pong()调用的激活顺序。
示例 14-4. diamond.py:类Leaf、A、B、Root形成了图 14-1 中的图形
class Root: # ①
def ping(self):
print(f'{self}.ping() in Root')
def pong(self):
print(f'{self}.pong() in Root')
def __repr__(self):
cls_name = type(self).__name__
return f'<instance of {cls_name}>'
class A(Root): # ②
def ping(self):
print(f'{self}.ping() in A')
super().ping()
def pong(self):
print(f'{self}.pong() in A')
super().pong()
class B(Root): # ③
def ping(self):
print(f'{self}.ping() in B')
super().ping()
def pong(self):
print(f'{self}.pong() in B')
class Leaf(A, B): # ④
def ping(self):
print(f'{self}.ping() in Leaf')
super().ping()
①
Root提供ping、pong和__repr__以使输出更易于阅读。
②
类A中的ping和pong方法都调用了super()。
③
类B中只有ping方法调用了super()。
④
类Leaf只实现了ping,并调用了super()。
现在让我们看看在Leaf的实例上调用ping和pong方法的效果(示例 14-5)。
示例 14-5. 在Leaf对象上调用ping和pong的文档测试
>>> leaf1 = Leaf() # ①
>>> leaf1.ping() # ②
<instance of Leaf>.ping() in Leaf
<instance of Leaf>.ping() in A
<instance of Leaf>.ping() in B
<instance of Leaf>.ping() in Root
>>> leaf1.pong() # ③
<instance of Leaf>.pong() in A
<instance of Leaf>.pong() in B
①
leaf1是Leaf的一个实例。
②
调用leaf1.ping()会激活Leaf、A、B和Root中的ping方法,因为前三个类中的ping方法都调用了super().ping()。
③
调用leaf1.pong()通过继承激活了A中的pong,然后调用super.pong(),激活了B.pong。
示例 14-5 和图 14-1 中显示的激活顺序由两个因素决定:
-
Leaf类的方法解析顺序。 -
每个方法中使用
super()
每个类都有一个名为__mro__的属性,其中包含一个指向超类的元组,按照方法解析顺序排列,从当前类一直到object类。⁷ 对于Leaf类,__mro__如下:
>>> Leaf.__mro__ # doctest:+NORMALIZE_WHITESPACE
(<class 'diamond1.Leaf'>, <class 'diamond1.A'>, <class 'diamond1.B'>,
<class 'diamond1.Root'>, <class 'object'>)
注意
查看图 14-1,您可能会认为 MRO 描述了一种广度优先搜索,但这只是对于特定类层次结构的一个巧合。 MRO 由一个名为 C3 的已发布算法计算。其在 Python 中的使用详细介绍在 Michele Simionato 的“Python 2.3 方法解析顺序”中。这是一篇具有挑战性的阅读,但 Simionato 写道:“除非您大量使用多重继承并且具有非平凡的层次结构,否则您不需要理解 C3 算法,您可以轻松跳过本文。”
MRO 仅确定激活顺序,但每个类中的特定方法是否激活取决于每个实现是否调用了super()。
考虑使用pong方法的实验。Leaf类没有对其进行覆盖,因此调用leaf1.pong()会通过继承激活Leaf.__mro__的下一个类中的实现:A类。方法A.pong调用super().pong()。接下来是 MRO 中的B类,因此激活B.pong。但是该方法不调用super().pong(),因此激活顺序到此结束。
MRO 不仅考虑继承图,还考虑超类在子类声明中列出的顺序。换句话说,如果在diamond.py(示例 14-4)中Leaf类声明为Leaf(B, A),那么类B会在Leaf.__mro__中出现在A之前。这会影响ping方法的激活顺序,并且会导致leaf1.pong()通过继承激活B.pong,但A.pong和Root.pong永远不会运行,因为B.pong不调用super()。
当一个方法调用super()时,它是一个合作方法。合作方法实现合作多重继承。这些术语是有意的:为了工作,Python 中的多重继承需要涉及方法的积极合作。在B类中,ping进行合作,但pong不进行合作。
警告
一个非合作方法可能导致微妙的错误。许多编码者阅读示例 14-4 时可能期望当方法A.pong调用super.pong()时,最终会激活Root.pong。但如果B.pong在之前激活,那就会出错。这就是为什么建议每个非根类的方法m都应该调用super().m()。
合作方法必须具有兼容的签名,因为你永远不知道A.ping是在B.ping之前还是之后调用的。激活顺序取决于每个同时继承两者的子类声明中A和B的顺序。
Python 是一种动态语言,因此super()与 MRO 的交互也是动态的。示例 14-6 展示了这种动态行为的一个令人惊讶的结果。
示例 14-6。diamond2.py:演示super()动态性质的类
from diamond import A # ①
class U(): # ②
def ping(self):
print(f'{self}.ping() in U')
super().ping() # ③
class LeafUA(U, A): # ④
def ping(self):
print(f'{self}.ping() in LeafUA')
super().ping()
①
类A来自diamond.py(示例 14-4)。
②
类U与diamond模块中的A或Root无关。
③
super().ping()做什么?答案:这取决于情况。继续阅读。
④
LeafUA按照这个顺序子类化U和A。
如果你创建一个U的实例并尝试调用ping,你会得到一个错误:
>>> u = U()
>>> u.ping()
Traceback (most recent call last):
...
AttributeError: 'super' object has no attribute 'ping'
super()返回的'super'对象没有属性'ping',因为U的 MRO 有两个类:U和object,而后者没有名为'ping'的属性。
然而,U.ping方法并非完全没有希望。看看这个:
>>> leaf2 = LeafUA()
>>> leaf2.ping()
<instance of LeafUA>.ping() in LeafUA
<instance of LeafUA>.ping() in U
<instance of LeafUA>.ping() in A
<instance of LeafUA>.ping() in Root
>>> LeafUA.__mro__ # doctest:+NORMALIZE_WHITESPACE
(<class 'diamond2.LeafUA'>, <class 'diamond2.U'>,
<class 'diamond.A'>, <class 'diamond.Root'>, <class 'object'>)
LeafUA中的super().ping()调用激活U.ping,后者通过调用super().ping()也进行合作,激活A.ping,最终激活Root.ping。
注意LeafUA的基类是(U, A),按照这个顺序。如果基类是(A, U),那么leaf2.ping()永远不会到达U.ping,因为A.ping中的super().ping()会激活Root.ping,而该方法不调用super()。
在一个真实的程序中,类似U的类可能是一个mixin 类:一个旨在与多重继承中的其他类一起使用,以提供额外功能的类。我们将很快学习这个,在“Mixin Classes”中。
总结一下关于 MRO 的讨论,图 14-2 展示了 Python 标准库中 Tkinter GUI 工具包复杂多重继承图的一部分。
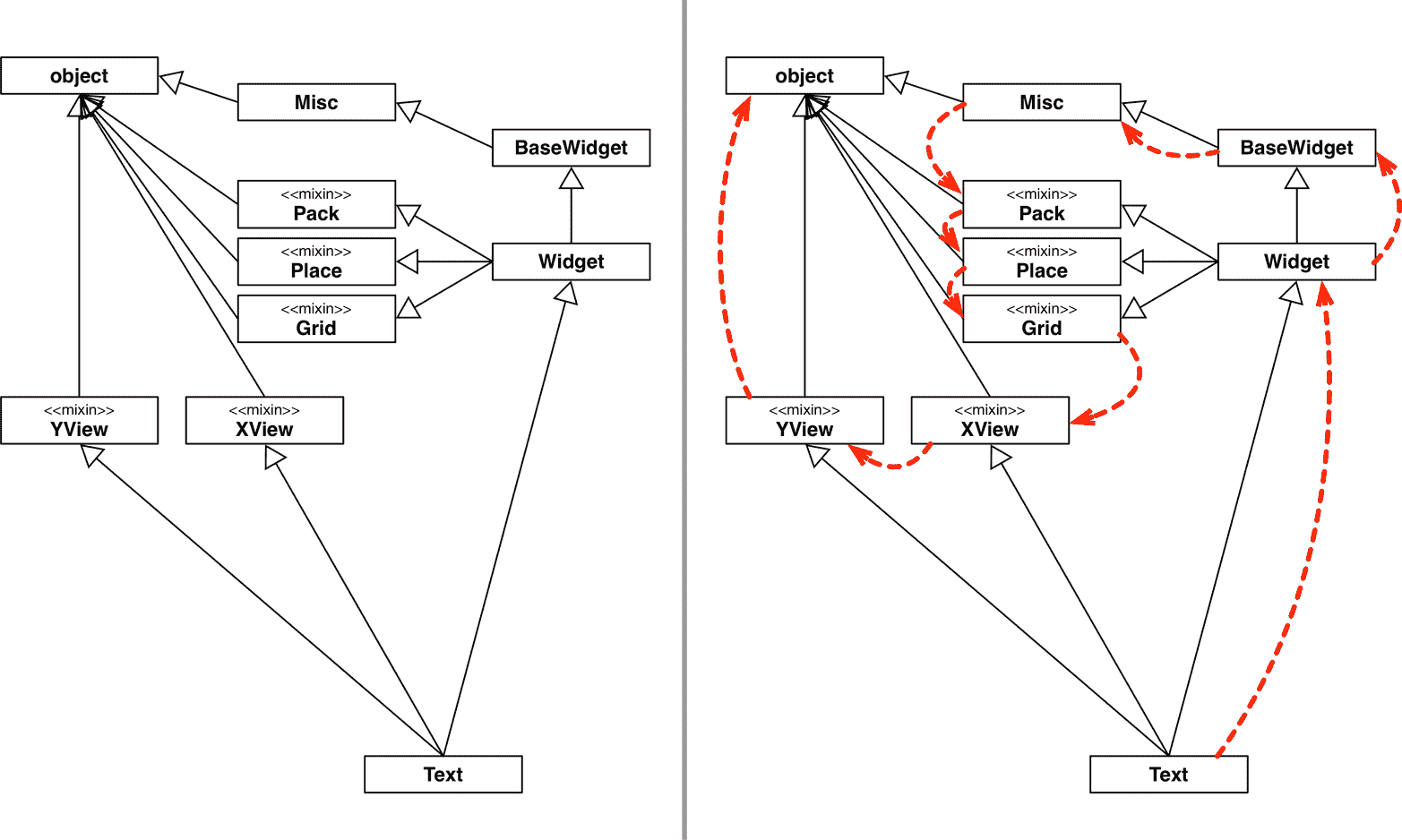
图 14-2。左:Tkinter Text小部件类及其超类的 UML 图。右:Text.__mro__的漫长曲折路径用虚线箭头绘制。
要研究图片,请从底部的Text类开始。Text类实现了一个功能齐全的、多行可编辑的文本小部件。它本身提供了丰富的功能,但也继承了许多其他类的方法。左侧显示了一个简单的 UML 类图。右侧用箭头装饰,显示了 MRO,如示例 14-7 中列出的,借助print_mro便利函数。
示例 14-7. tkinter.Text的 MRO
>>> def print_mro(cls):
... print(', '.join(c.__name__ for c in cls.__mro__))
>>> import tkinter
>>> print_mro(tkinter.Text)
Text, Widget, BaseWidget, Misc, Pack, Place, Grid, XView, YView, object
现在让我们谈谈混入。
混入类
混入类设计为与至少一个其他类一起在多重继承安排中被子类化。混入不应该是具体类的唯一基类,因为它不为具体对象提供所有功能,而只是添加或自定义子类或兄弟类的行为。
注意
混入类是 Python 和 C++中没有明确语言支持的约定。Ruby 允许明确定义和使用作为混入的模块——一组方法,可以包含以添加功能到类。C#、PHP 和 Rust 实现了特征,这也是混入的一种明确形式。
让我们看一个简单但方便的混入类的示例。
不区分大小写的映射
示例 14-8 展示了UpperCaseMixin,一个设计用于提供对具有字符串键的映射进行不区分大小写访问的类,通过在添加或查找这些键时将它们大写。
示例 14-8. uppermixin.py:UpperCaseMixin支持不区分大小写的映射
import collections
def _upper(key): # ①
try:
return key.upper()
except AttributeError:
return key
class UpperCaseMixin: # ②
def __setitem__(self, key, item):
super().__setitem__(_upper(key), item)
def __getitem__(self, key):
return super().__getitem__(_upper(key))
def get(self, key, default=None):
return super().get(_upper(key), default)
def __contains__(self, key):
return super().__contains__(_upper(key))
①
这个辅助函数接受任何类型的key,并尝试返回key.upper();如果失败,则返回未更改的key。
②
这个混入实现了映射的四个基本方法,总是调用super(),如果可能的话,将key大写。
由于UpperCaseMixin的每个方法都调用super(),这个混入取决于一个实现或继承具有相同签名方法的兄弟类。为了发挥其作用,混入通常需要出现在使用它的子类的 MRO 中的其他类之前。实际上,这意味着混入必须首先出现在类声明中基类元组中。示例 14-9 展示了两个示例。
示例 14-9. uppermixin.py:使用UpperCaseMixin的两个类
class UpperDict(UpperCaseMixin, collections.UserDict): # ①
pass
class UpperCounter(UpperCaseMixin, collections.Counter): # ②
"""Specialized 'Counter' that uppercases string keys""" # ③
①
UpperDict不需要自己的实现,但UpperCaseMixin必须是第一个基类,否则将调用UserDict的方法。
②
UpperCaseMixin也适用于Counter。
③
不要使用pass,最好提供一个文档字符串来满足class语句语法中需要主体的需求。
这里是uppermixin.py中的一些 doctests,用于UpperDict:
>>> d = UpperDict([('a', 'letter A'), (2, 'digit two')])
>>> list(d.keys())
['A', 2]
>>> d['b'] = 'letter B'
>>> 'b' in d
True
>>> d['a'], d.get('B')
('letter A', 'letter B')
>>> list(d.keys())
['A', 2, 'B']
还有一个关于UpperCounter的快速演示:
>>> c = UpperCounter('BaNanA')
>>> c.most_common()
[('A', 3), ('N', 2), ('B', 1)]
UpperDict和UpperCounter看起来几乎像是魔法,但我不得不仔细研究UserDict和Counter的代码,以使UpperCaseMixin与它们一起工作。
例如,我的第一个版本的UpperCaseMixin没有提供get方法。那个版本可以与UserDict一起工作,但不能与Counter一起工作。UserDict类继承了collections.abc.Mapping的get方法,而该get方法调用了我实现的__getitem__。但是,当UpperCounter加载到__init__时,键并没有大写。这是因为Counter.__init__使用了Counter.update,而Counter.update又依赖于从dict继承的get方法。然而,dict类中的get方法并不调用__getitem__。这是在“标准库中 missing 的不一致使用”中讨论的问题的核心。这也是对利用继承的程序的脆弱和令人困惑的本质的鲜明提醒,即使在小规模上也是如此。
下一节将涵盖多个多重继承的示例,通常包括 Mixin 类。
现实世界中的多重继承
在《设计模式》一书中,⁸几乎所有的代码都是用 C++ 编写的,但多重继承的唯一示例是适配器模式。在 Python 中,多重继承也不是常态,但有一些重要的例子我将在本节中评论。
ABCs 也是 Mixins
在 Python 标准库中,最明显的多重继承用法是collections.abc包。这并不具有争议性:毕竟,即使是 Java 也支持接口的多重继承,而 ABCs 是接口声明,可以选择性地提供具体方法实现。⁹
Python 官方文档中对collections.abc使用术语mixin 方法来表示许多集合 ABCs 中实现的具体方法。提供 mixin 方法的 ABCs 扮演两个角色:它们是接口定义,也是 mixin 类。例如,collections.UserDict的实现依赖于collections.abc.MutableMapping提供的几个 mixin 方法。
ThreadingMixIn 和 ForkingMixIn
http.server包提供了HTTPServer和ThreadingHTTPServer类。后者是在 Python 3.7 中添加的。其文档中说:
类http.server.ThreadingHTTPServer(server_address, RequestHandlerClass)
这个类与HTTPServer相同,但使用线程来处理请求,使用了ThreadingMixIn。这对于处理预先打开套接字的网络浏览器非常有用,对于这些套接字,HTTPServer将无限期等待。
这是 Python 3.10 中ThreadingHTTPServer类的完整源代码:
class ThreadingHTTPServer(socketserver.ThreadingMixIn, HTTPServer):
daemon_threads = True
socketserver.ThreadingMixIn的源代码有 38 行,包括注释和文档字符串。示例 14-10 展示了其实现的摘要。
示例 14-10. Python 3.10 中 Lib/socketserver.py 的一部分
class ThreadingMixIn:
"""Mixin class to handle each request in a new thread."""
# 8 lines omitted in book listing
def process_request_thread(self, request, client_address): # ①
... # 6 lines omitted in book listing
def process_request(self, request, client_address): # ②
... # 8 lines omitted in book listing
def server_close(self): # ③
super().server_close()
self._threads.join()
①
process_request_thread 不调用super(),因为它是一个新方法,而不是一个覆盖。它的实现调用了HTTPServer提供或继承的三个实例方法。
②
这覆盖了HTTPServer从socketserver.BaseServer继承的process_request方法,启动一个线程,并将实际工作委托给在该线程中运行的process_request_thread。它不调用super()。
③
server_close 调用super().server_close()停止接受请求,然后等待process_request启动的线程完成其工作。
ThreadingMixIn出现在socketserver模块文档中,旁边是ForkingMixin。后者旨在支持基于os.fork()的并发服务器,这是一种在符合POSIX的类 Unix 系统中启动子进程的 API。
Django 通用视图混合类
注意
您不需要了解 Django 才能阅读本节。我使用框架的一小部分作为多重继承的实际示例,并将尽力提供所有必要的背景知识,假设您在任何语言或框架中具有一些服务器端 Web 开发经验。
在 Django 中,视图是一个可调用对象,接受一个request参数——代表一个 HTTP 请求的对象,并返回一个代表 HTTP 响应的对象。我们在这里讨论的是不同的响应。它们可以是简单的重定向响应,没有内容主体,也可以是一个在线商店中的目录页面,从 HTML 模板渲染并列出多个商品,带有购买按钮和到详细页面的链接。
最初,Django 提供了一组称为通用视图的函数,实现了一些常见用例。例如,许多站点需要显示包含来自多个项目的信息的搜索结果,列表跨越多个页面,对于每个项目,都有一个链接到包含有关其详细信息的页面。在 Django 中,列表视图和详细视图被设计为一起解决这个问题:列表视图呈现搜索结果,详细视图为每个单独项目生成一个页面。
然而,最初的通用视图是函数,因此它们是不可扩展的。如果您需要做类似但不完全像通用列表视图的事情,您将不得不从头开始。
类视图的概念是在 Django 1.3 中引入的,连同一组通用视图类,组织为基类、混合类和可直接使用的具体类。在 Django 3.2 中,基类和混合类位于django.views.generic包的base模块中,如图 14-3 所示。在图表的顶部,我们看到两个负责非常不同职责的类:View和TemplateResponseMixin。
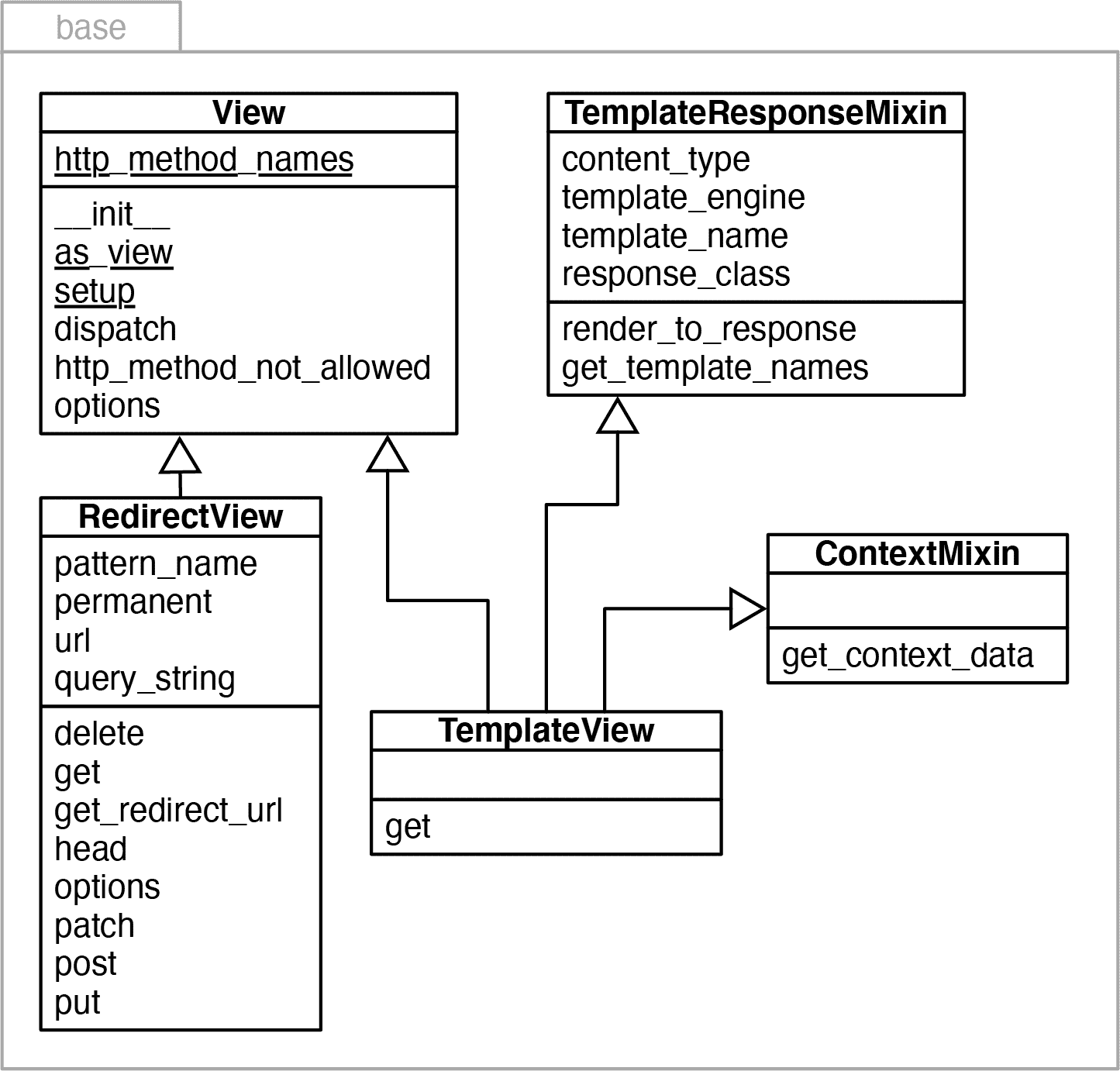
图 14-3. django.views.generic.base模块的 UML 类图。
提示
学习这些类的一个很好的资源是Classy Class-Based Views网站,您可以轻松浏览它们,查看每个类中的所有方法(继承的、重写的和添加的方法),查看图表,浏览它们的文档,并跳转到它们在 GitHub 上的源代码。
View是所有视图的基类(它可以是 ABC),它提供核心功能,如dispatch方法,该方法委托给具体子类实现的“处理程序”方法,如get、head、post等,以处理不同的 HTTP 动词。¹⁰ RedirectView类仅继承自View,您可以看到它实现了get、head、post等。
View的具体子类应该实现处理程序方法,那么为什么这些方法不是View接口的一部分呢?原因是:子类可以自由地实现它们想要支持的处理程序。TemplateView仅用于显示内容,因此它只实现get。如果向TemplateView发送 HTTP POST请求,继承的View.dispatch方法会检查是否存在post处理程序,并生成 HTTP 405 Method Not Allowed响应。¹¹
TemplateResponseMixin提供的功能只对需要使用模板的视图感兴趣。例如,RedirectView没有内容主体,因此不需要模板,也不继承自此混合类。TemplateResponseMixin为TemplateView和其他模板渲染视图提供行为,如ListView、DetailView等,定义在django.views.generic子包中。图 14-4 描述了django.views.generic.list模块和base模块的部分。
对于 Django 用户来说,图 14-4 中最重要的类是ListView,它是一个聚合类,没有任何代码(其主体只是一个文档字符串)。 当实例化时,ListView 通过object_list实例属性具有一个可迭代的对象,模板可以通过它来显示页面内容,通常是数据库查询返回多个对象的结果。 生成这些对象的可迭代对象的所有功能来自MultipleObjectMixin。 该混合类还提供了复杂的分页逻辑——在一个页面中显示部分结果和链接到更多页面。
假设您想创建一个不会呈现模板,但会以 JSON 格式生成对象列表的视图。 这就是BaseListView的存在。 它提供了一个易于使用的扩展点,将View和MultipleObjectMixin功能结合在一起,而不需要模板机制的开销。
Django 基于类的视图 API 是多重继承的一个更好的例子,比 Tkinter 更好。 特别是,很容易理解其混合类:每个混合类都有一个明确定义的目的,并且它们都以…Mixin后缀命名。
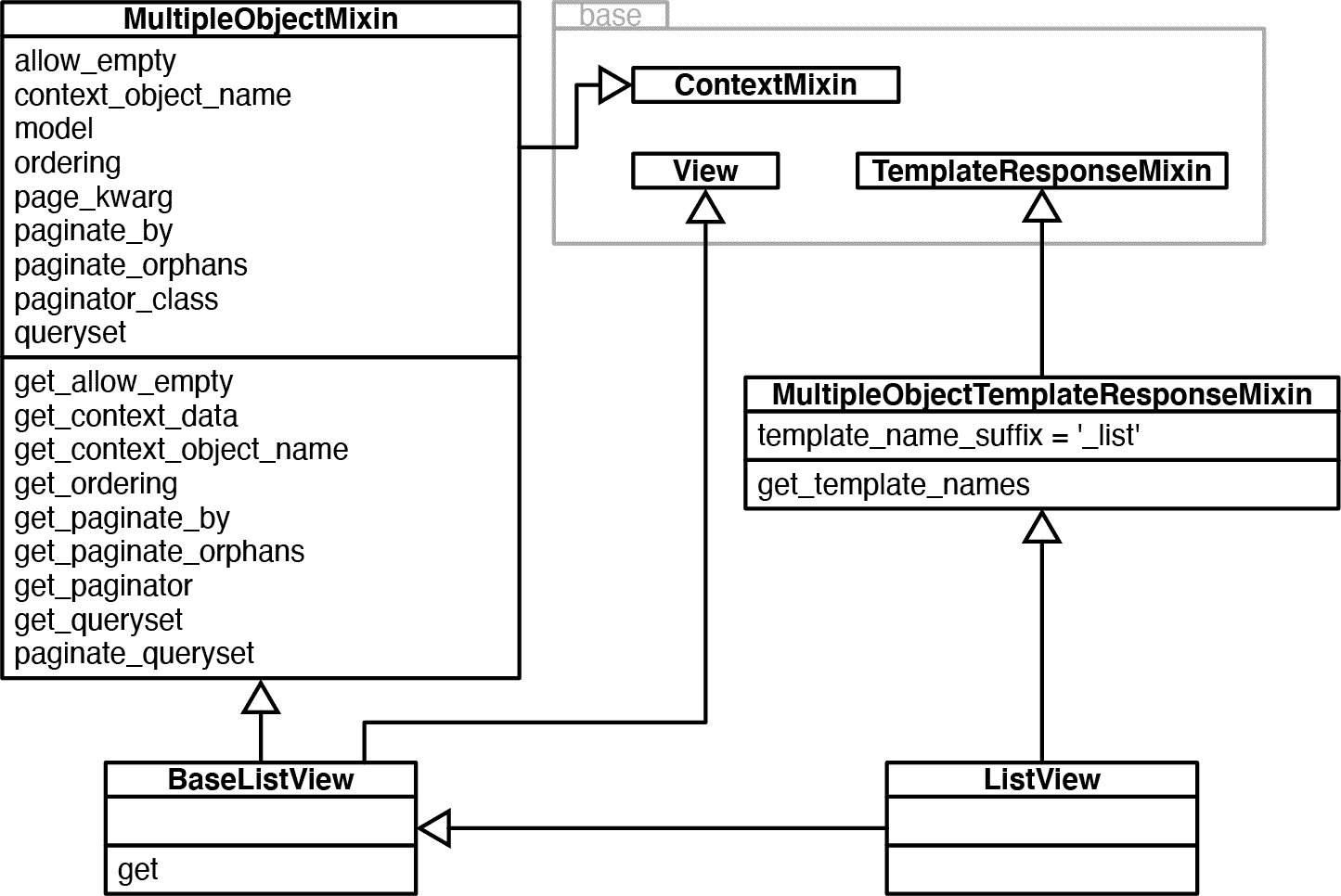
图 14-4. django.views.generic.list 模块的 UML 类图。 这里基本模块的三个类已经折叠(参见图 14-3)。 ListView 类没有方法或属性:它是一个聚合类。
基于类的视图并不被 Django 用户普遍接受。许多人以一种有限的方式使用它们,作为不透明的盒子,但当需要创建新东西时,许多 Django 程序员继续编写处理所有这些责任的单片视图函数,而不是尝试重用基本视图和混合类。
学习如何利用基于类的视图以及如何扩展它们以满足特定应用程序需求确实需要一些时间,但我发现研究它们是值得的。 它们消除了大量样板代码,使得重用解决方案更容易,甚至改善了团队沟通——例如,通过定义模板的标准名称,以及传递给模板上下文的变量。 基于类的视图是 Django 视图的“轨道”。
Tkinter 中的多重继承
Python 标准库中多重继承的一个极端例子是Tkinter GUI 工具包。 我使用了 Tkinter 小部件层次结构的一部分来说明图 14-2 中的 MRO。 图 14-5 显示了tkinter基础包中的所有小部件类(tkinter.ttk子包中有更多小部件)。
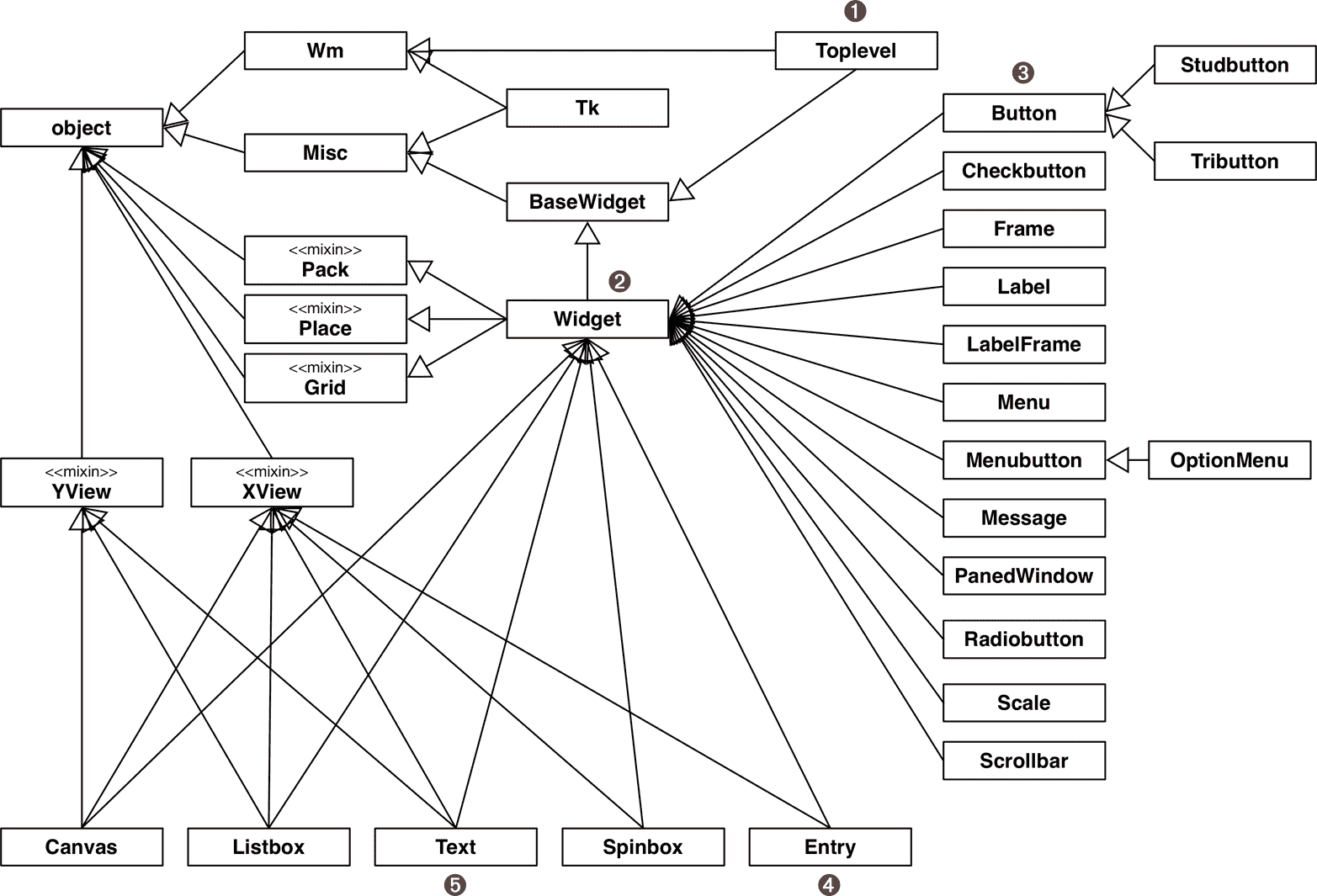
图 14-5. Tkinter GUI 类层次结构的摘要 UML 图;标记为«mixin»的类旨在通过多重继承为其他类提供具体方法。
当我写这篇文章时,Tkinter 已经有 25 年的历史了。 它并不是当前最佳实践的例子。 但它展示了当编码人员不欣赏其缺点时如何使用多重继承。 当我们在下一节讨论一些良好实践时,它将作为一个反例。
请考虑来自图 14-5 的这些类:
➊ Toplevel:Tkinter 应用程序中顶级窗口的类。
➋ Widget:可以放置在窗口上的每个可见对象的超类。
➌ Button:一个普通的按钮小部件。
➍ Entry:一个单行可编辑文本字段。
➎ Text:一个多行可编辑文本字段。
这些类的 MRO 是由print_mro函数显示的,该函数来自示例 14-7:
>>> import tkinter
>>> print_mro(tkinter.Toplevel)
Toplevel, BaseWidget, Misc, Wm, object
>>> print_mro(tkinter.Widget)
Widget, BaseWidget, Misc, Pack, Place, Grid, object
>>> print_mro(tkinter.Button)
Button, Widget, BaseWidget, Misc, Pack, Place, Grid, object
>>> print_mro(tkinter.Entry)
Entry, Widget, BaseWidget, Misc, Pack, Place, Grid, XView, object
>>> print_mro(tkinter.Text)
Text, Widget, BaseWidget, Misc, Pack, Place, Grid, XView, YView, object
注意
按照当前标准,Tkinter 的类层次结构非常深。Python 标准库的很少部分具有超过三到四级的具体类,Java 类库也是如此。然而,有趣的是,Java 类库中一些最深层次的层次结构恰好是与 GUI 编程相关的包:java.awt 和 javax.swing。现代、免费的 Smalltalk 版本 Squeak 包括功能强大且创新的 Morphic GUI 工具包,同样具有深层次的类层次结构。根据我的经验,GUI 工具包是继承最有用的地方。
注意这些类与其他类的关系:
-
Toplevel是唯一一个不从Widget继承的图形类,因为它是顶层窗口,不像一个 widget 那样行为;例如,它不能附加到窗口或框架。Toplevel从Wm继承,提供了主机窗口管理器的直接访问函数,如设置窗口标题和配置其边框。 -
Widget直接从BaseWidget和Pack、Place、Grid继承。这三个类是几何管理器:它们负责在窗口或框架内排列小部件。每个类封装了不同的布局策略和小部件放置 API。 -
Button,像大多数小部件一样,只从Widget继承,但间接从Misc继承,为每个小部件提供了数十种方法。 -
Entry从支持水平滚动的Widget和XView继承。 -
Text从Widget、XView和YView继承以支持垂直滚动。
现在我们将讨论一些多重继承的良好实践,并看看 Tkinter 是否符合这些实践。
处理继承
阿兰·凯在前言中写道:关于继承还没有能够指导实践程序员的一般理论。我们拥有的是经验法则、设计模式、“最佳实践”、巧妙的首字母缩写、禁忌等。其中一些提供了有用的指导方针,但没有一个是普遍接受的或总是适用的。
使用继承很容易创建难以理解和脆弱的设计,即使没有多重继承。由于我们没有一个全面的理论,这里有一些避免意大利面式类图的提示。
偏向对象组合而不是类继承
这个小节的标题是《设计模式》书中的面向对象设计的第二原则¹²,也是我在这里能提供的最好建议。一旦你熟悉了继承,就很容易过度使用它。将对象放在一个整洁的层次结构中符合我们的秩序感;程序员只是为了好玩而这样做。
偏向组合会导致更灵活的设计。例如,在tkinter.Widget类的情况下,widget 实例可以持有对几何管理器的引用,并调用其方法,而不是从所有几何管理器继承方法。毕竟,一个Widget不应该“是”一个几何管理器,但可以通过委托使用其服务。然后,您可以添加一个新的几何管理器,而不必触及 widget 类层次结构,也不必担心名称冲突。即使在单一继承的情况下,这个原则也增强了灵活性,因为子类化是一种紧密耦合的形式,而高继承树往往是脆弱的。
组合和委托可以替代使用 Mixin 使行为可用于不同类,但不能替代使用接口继承来定义类型层次结构。
理解每种情况下为何使用继承
处理多重继承时,有必要清楚地了解在每种特定情况下为何进行子类化。主要原因包括:
-
接口继承创建一个子类型,暗示一个“是一个”关系。这最好通过 ABCs 完成。
-
实现的继承避免了代码重复使用。Mixin 可以帮助实现这一点。
在实践中,这两种用法通常同时存在,但只要您能清楚地表达意图,就应该这样做。继承用于代码重用是一个实现细节,它经常可以被组合和委托替代。另一方面,接口继承是框架的支柱。接口继承应尽可能只使用 ABC 作为基类。
使用 ABC 明确接口
在现代 Python 中,如果一个类旨在定义一个接口,它应该是一个明确的 ABC 或typing.Protocol子类。ABC 应该仅从abc.ABC或其他 ABC 继承。多重继承 ABC 并不成问题。
使用明确的混合类进行代码重用
如果一个类旨在为多个不相关的子类提供方法实现以供重用,而不意味着“是一个”关系,则应该是一个明确的混合类。从概念上讲,混合类不定义新类型;它只是捆绑方法以供重用。混合类不应该被实例化,具体类不应该仅从混合类继承。每个混合类应提供一个特定的行为,实现少量且非常相关的方法。混合类应避免保留任何内部状态;即混合类不应具有实例属性。
在 Python 中没有正式的方法来声明一个类是混合类,因此强烈建议它们以Mixin后缀命名。
为用户提供聚合类
主要通过从混合项继承而构建的类,不添加自己的结构或行为,被称为聚合类。
Booch 等人¹³
如果某些 ABC 或混合类的组合对客户端代码特别有用,请提供一个以合理方式将它们组合在一起的类。
例如,这里是 Django ListView类的完整源代码,位于图 14-4 右下角:
class ListView(MultipleObjectTemplateResponseMixin, BaseListView):
"""
Render some list of objects, set by `self.model` or `self.queryset`.
`self.queryset` can actually be any iterable of items, not just a queryset.
"""
ListView的主体是空的,但该类提供了一个有用的服务:它将一个混合类和一个应该一起使用的基类组合在一起。
另一个例子是tkinter.Widget,它有四个基类,没有自己的方法或属性,只有一个文档字符串。由于Widget聚合类,我们可以创建一个新的小部件,其中包含所需的混合项,而无需弄清楚它们应该以何种顺序声明才能按预期工作。
请注意,聚合类不一定要完全为空,但它们通常是。
只对设计为可子类化的类进行子类化
在关于本章的一条评论中,技术审阅员 Leonardo Rochael 提出了以下警告。
警告
由于超类方法可能以意想不到的方式忽略子类覆盖,因此从任何复杂类继承并覆盖其方法是容易出错的。尽可能避免覆盖方法,或者至少限制自己只继承易于扩展的类,并且只以设计为可扩展的方式进行扩展。
这是一个很好的建议,但我们如何知道一个类是否被设计为可扩展?
第一个答案是文档(有时以文档字符串或甚至代码注释的形式)。例如,Python 的socketserver包被描述为“一个网络服务器框架”。它的BaseServer类被设计为可子类化,正如其名称所示。更重要的是,类的文档和源代码中的文档字符串明确指出了哪些方法是打算由子类重写的。
在 Python ≥ 3.8 中,通过PEP 591—为类型添加 final 修饰符提供了一种明确制定这些设计约束的新方法。该 PEP 引入了一个@final装饰器,可应用于类或单独的方法,以便 IDE 或类型检查器可以报告误用尝试对这些类进行子类化或覆盖这些方法的情况。¹⁴
避免从具体类继承
从具体类进行子类化比从 ABC 和 mixin 进行子类化更危险,因为具体类的实例通常具有内部状态,当您覆盖依赖于该状态的方法时,很容易破坏该状态。即使您的方法通过调用super()来合作,并且内部状态是使用__x语法保存在私有属性中,仍然有无数种方法可以通过方法覆盖引入错误。
在“水禽和 ABC”中,Alex Martelli 引用了 Scott Meyer 的More Effective C++,其中说:“所有非叶类都应该是抽象的。”换句话说,Meyer 建议只有抽象类应该被子类化。
如果必须使用子类化进行代码重用,则应将用于重用的代码放在 ABC 的 mixin 方法中或明确命名的 mixin 类中。
我们现在将从这些建议的角度分析 Tkinter。
Tkinter:优点、缺点和丑闻
先前部分中的大多数建议在 Tkinter 中并未遵循,特别例外是“向用户提供聚合类”。即使如此,这也不是一个很好的例子,因为像在“更青睐对象组合而非类继承”中讨论的那样,将几何管理器集成到Widget中可能效果更好。
请记住,Tkinter 自 1994 年发布的 Python 1.1 起就是标准库的一部分。Tkinter 是建立在 Tcl 语言的出色 Tk GUI 工具包之上的一层。Tcl/Tk 组合最初并非面向对象,因此 Tk API 基本上是一个庞大的函数目录。但是,该工具包在设计上是面向对象的,尽管在其原始的 Tcl 实现中不是。
tkinter.Widget的文档字符串以“内部类”开头。这表明Widget可能应该是一个 ABC。尽管Widget没有自己的方法,但它确实定义了一个接口。它的含义是:“您可以依赖于每个 Tkinter 小部件提供基本小部件方法(__init__、destroy和数十个 Tk API 函数),以及所有三个几何管理器的方法。”我们可以同意这不是一个很好的接口定义(它太宽泛了),但它是一个接口,而Widget将其“定义”为其超类接口的并集。
Tk类封装了 GUI 应用程序逻辑,继承自Wm和Misc的两者都不是抽象或 mixin(Wm不是一个适当的 mixin,因为TopLevel仅从它继承)。Misc类的名称本身就是一个非常明显的代码异味。Misc有 100 多个方法,所有小部件都继承自它。为什么每个小部件都需要处理剪贴板、文本选择、定时器管理等方法?您实际上无法将内容粘贴到按钮中或从滚动条中选择文本。Misc应该拆分为几个专门的 mixin 类,并且不是所有小部件都应该从每个 mixin 类继承。
公平地说,作为 Tkinter 用户,您根本不需要了解或使用多重继承。这是隐藏在您将在自己的代码中实例化或子类化的小部件类背后的实现细节。但是,当您键入dir(tkinter.Button)并尝试在列出的 214 个属性中找到所需的方法时,您将遭受过多多重继承的后果。如果您决定实现一个新的 Tk 小部件,您将需要面对这种复杂性。
提示
尽管存在问题,Tkinter 是稳定的、灵活的,并且如果使用tkinter.ttk包及其主题小部件,提供现代外观和感觉。此外,一些原始小部件,如Canvas和Text,功能强大。你可以在几小时内将Canvas对象转换为简单的拖放绘图应用程序。如果你对 GUI 编程感兴趣,Tkinter 和 Tcl/Tk 绝对值得一看。
这标志着我们对继承迷宫的探索结束了。
章节总结
本章从单一继承的情况下对super()函数进行了回顾。然后我们讨论了子类化内置类型的问题:它们在 C 中实现的原生方法不会调用子类中的重写方法,除了极少数特殊情况。这就是为什么当我们需要自定义list、dict或str类型时,更容易子类化UserList、UserDict或UserString——它们都定义在collections模块中,实际上包装了相应的内置类型并将操作委托给它们——这是标准库中偏向组合而非继承的三个例子。如果期望的行为与内置提供的行为非常不同,可能更容易子类化collections.abc中的适当 ABC,并编写自己的实现。
本章的其余部分致力于多重继承的双刃剑。首先,我们看到了方法解析顺序,编码在__mro__类属性中,解决了继承方法中潜在命名冲突的问题。我们还看到了super()内置函数在具有多重继承的层次结构中的行为,有时会出乎意料。super()的行为旨在支持混入类,然后我们通过UpperCaseMixin对不区分大小写映射的简单示例进行了研究。
我们看到了多重继承和混入方法在 Python 的 ABCs 中的使用,以及在socketserver线程和分叉混入中的使用。更复杂的多重继承用法由 Django 的基于类的视图和 Tkinter GUI 工具包示例。尽管 Tkinter 不是现代最佳实践的例子,但它是我们可能在遗留系统中找到的过于复杂的类层次结构的例子。
为了结束本章,我提出了七条应对继承的建议,并在对 Tkinter 类层次结构的评论中应用了其中一些建议。
拒绝继承——甚至是单一继承——是一个现代趋势。21 世纪创建的最成功的语言之一是 Go。它没有名为“类”的构造,但你可以构建作为封装字段结构的类型,并且可以将方法附加到这些结构上。Go 允许定义接口,编译器使用结构化类型检查这些接口,即静态鸭子类型,与 Python 3.8 之后的协议类型非常相似。Go 有特殊的语法用于通过组合构建类型和接口,但它不支持继承——甚至不支持接口之间的继承。
所以也许关于继承的最佳建议是:如果可以的话,尽量避免。但通常情况下,我们没有选择:我们使用的框架会强加它们自己的设计选择。
进一步阅读
在阅读清晰度方面,适当的组合优于继承。由于代码更多地被阅读而不是被编写,一般情况下应避免子类化,尤其不要混合各种类型的继承,并且不要使用子类化进行代码共享。
Hynek Schlawack,《Python 中的子类化再探》
在这本书的最终审阅期间,技术审阅员 Jürgen Gmach 推荐了 Hynek Schlawack 的帖子“Subclassing in Python Redux”—前述引用的来源。Schlawack 是流行的attrs包的作者,并且是 Twisted 异步编程框架的核心贡献者,这是 Glyph Lefkowitz 于 2002 年发起的项目。随着时间的推移,核心团队意识到他们在设计中过度使用了子类化,根据 Schlawack 的说法。他的帖子很长,引用了其他重要的帖子和演讲。强烈推荐。
在同样的结论中,Hynek Schlawack 写道:“不要忘记,更多时候,一个函数就是你所需要的。”我同意,这正是为什么在类和继承之前,《Fluent Python》深入讲解函数的原因。我的目标是展示在创建自己的类之前,利用标准库中现有类可以实现多少功能。
Guido van Rossum 的论文“Unifying types and classes in Python 2.2”介绍了内置函数的子类型、super函数以及描述符和元类等高级特性。这些特性自那时以来并没有发生重大变化。Python 2.2 是语言演进的一个了不起的成就,添加了几个强大的新特性,形成了一个连贯的整体,而不会破坏向后兼容性。这些新特性是 100%选择性的。要使用它们,我们只需显式地子类化object——直接或间接地创建所谓的“新样式类”。在 Python 3 中,每个类都是object的子类。
David Beazley 和 Brian K. Jones(O’Reilly)的《Python Cookbook》,第三版(https://fpy.li/pycook3)中有几个示例展示了super()和 mixin 类的使用。你可以从启发性的部分“8.7. Calling a Method on a Parent Class”开始,然后从那里跟随内部引用。
Raymond Hettinger 的帖子“Python’s super() considered super!”从积极的角度解释了 Python 中super和多重继承的工作原理。这篇文章是作为对 James Knight 的“Python’s Super is nifty, but you can’t use it (Previously: Python’s Super Considered Harmful)”的回应而撰写的。Martijn Pieters 对“How to use super() with one argument?”的回应包括对super的简明而深入的解释,包括它与描述符的关系,这是我们只会在第二十三章中学习的概念。这就是super的本质。在基本用例中使用起来很简单,但它是一个强大且复杂的工具,涉及一些 Python 中最先进的动态特性,很少在其他语言中找到。
尽管这些帖子的标题是关于super内置函数的,但问题实际上并不是 Python 3 中不像 Python 2 那样丑陋的super内置函数。真正的问题在于多重继承,这本质上是复杂且棘手的。Michele Simionato 在他的“Setting Multiple Inheritance Straight”中不仅仅是批评,实际上还提出了一个解决方案:他实现了 traits,这是一种源自 Self 语言的明确形式的 mixin。Simionato 在 Python 中有一系列关于多重继承的博客文章,包括“The wonders of cooperative inheritance, or using super in Python 3”;“Mixins considered harmful,” part 1和part 2;以及“Things to Know About Python Super,” part 1、part 2和part 3。最早的帖子使用了 Python 2 的super语法,但仍然具有相关性。
我阅读了 Grady Booch 等人的第三版《面向对象的分析与设计》,强烈推荐它作为独立于编程语言的面向对象思维的通用入门书籍。这是一本罕见的涵盖多重继承而没有偏见的书籍。
现在比以往任何时候都更时尚地避免继承,所以这里有两个关于如何做到这一点的参考资料。Brandon Rhodes 写了 “组合优于继承原则”,这是他出色的 Python 设计模式 指南的一部分。Augie Fackler 和 Nathaniel Manista 在 PyCon 2013 上提出了 “对象继承的终结与新模块化的开始”。Fackler 和 Manista 谈到围绕接口和处理实现这些接口的对象的函数来组织系统,避免类和继承的紧密耦合和失败模式。这让我很想起 Go 的方式,但他们为 Python 提倡这种方式。
¹ Alan Kay, “Smalltalk 的早期历史”,发表于 SIGPLAN Not. 28, 3 (1993 年 3 月), 69–95. 也可在线获取 链接。感谢我的朋友 Christano Anderson,在我撰写本章时分享了这个参考资料。
² 我只修改了示例中的文档字符串,因为原文有误导性。它说:“按照键最后添加的顺序存储项目”,但这并不是明确命名的 LastUpdatedOrderedDict 所做的。
³ 也可以只提供第一个参数,但这并不实用,可能很快就会被弃用,Guido van Rossum 创建 super() 时也表示支持。请参见 “是时候废弃未绑定的 super 方法了吗?” 中的讨论。
⁴ 有趣的是,C++ 中有虚方法和非虚方法的概念。虚方法是晚期绑定的,但非虚方法在编译时绑定。尽管我们在 Python 中编写的每个方法都像虚方法一样晚期绑定,但用 C 编写的内置对象似乎默认具有非虚方法,至少在 CPython 中是这样。
⁵ 如果你感兴趣,实验在 14-inheritance/strkeydict_dictsub.py 文件中的 fluentpython/example-code-2e 仓库中。
⁶ 顺便说一句,在这方面,PyPy 的行为比 CPython 更“正确”,但代价是引入了一点不兼容性。详细信息请参见 “PyPy 和 CPython 之间的差异”。
⁷ 类还有一个 .mro() 方法,但那是元类编程的高级特性,提到了 “类作为对象”。在类的正常使用过程中,__mro__ 属性的内容才是重要的。
⁸ Erich Gamma, Richard Helm, Ralph Johnson, 和 John Vlissides,设计模式:可复用面向对象软件的元素 (Addison-Wesley)。
⁹ 正如之前提到的,Java 8 允许接口提供方法实现。这一新特性在官方 Java 教程中称为 “默认方法”。
¹⁰ Django 程序员知道 as_view 类方法是 View 接口中最显著的部分,但在这里对我们并不重要。
¹¹ 如果你对设计模式感兴趣,你会注意到 Django 的调度机制是 模板方法模式 的动态变体。它是动态的,因为 View 类不强制子类实现所有处理程序,而是 dispatch 在运行时检查是否为特定请求提供了具体处理程序。
¹² 这个原则出现在该书的引言第 20 页。
¹³ Grady Booch 等人,面向对象的分析与设计及应用,第 3 版 (Addison-Wesley),第 109 页。
¹⁴ PEP 591 还引入了一个Final注释,用于标记不应重新赋值或覆盖的变量或属性。
¹⁵ Alan Kay 在 SIGPLAN Not. 28, 3(1993 年 3 月)中写道:“Smalltalk 的早期历史”,69-95 页。也可在线查看链接。感谢我的朋友 Christiano Anderson,在我撰写本章时分享了这个参考资料。
¹⁶ 我的朋友和技术审阅员 Leonardo Rochael 解释得比我更好:“Perl 6 的持续存在,但始终未到来,使 Perl 本身的发展失去了意志力。现在 Perl 继续作为一个独立的语言进行开发(截至目前为止已经到了版本 5.34),没有因为曾经被称为 Perl 6 的语言而被废弃的阴影。”