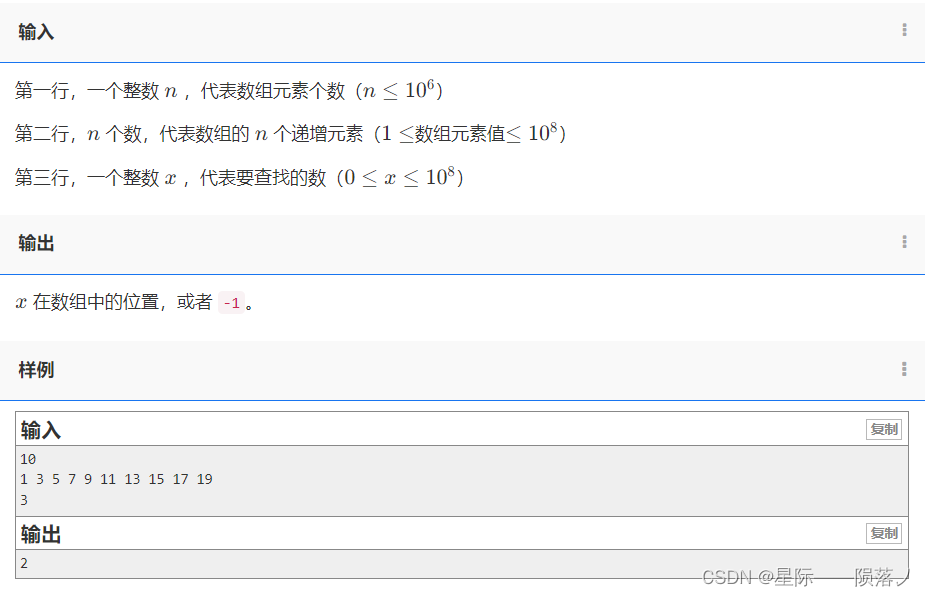
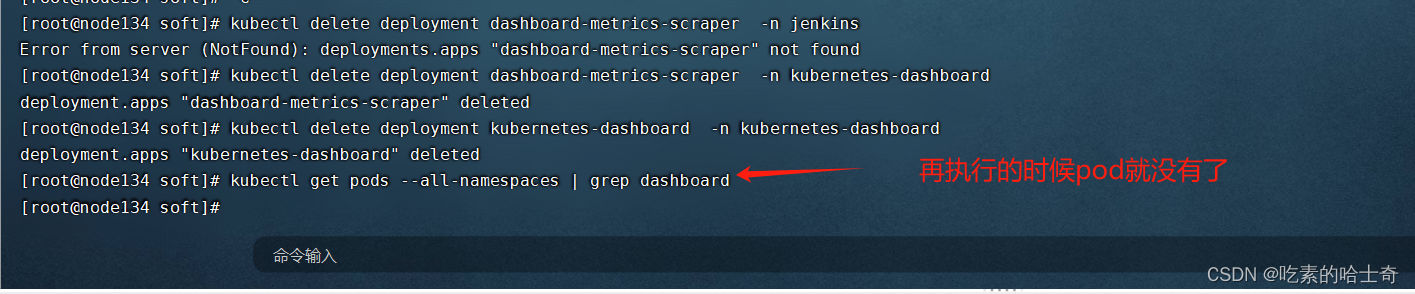
第二部分:从现实世界的图像中学习:肺癌的早期检测
第 2 部分的结构与第 1 部分不同;它几乎是一本书中的一本书。我们将以几章的篇幅深入探讨一个单一用例,从第 1 部分学到的基本构建模块开始,构建一个比我们迄今为止看到的更完整的项目。我们的第一次尝试将是不完整和不准确的,我们将探讨如何诊断这些问题,然后修复它们。我们还将确定我们解决方案的各种其他改进措施,实施它们,并衡量它们的影响。为了训练第 2 部分中将开发的模型,您将需要访问至少 8 GB RAM 的 GPU,以及数百 GB 的可用磁盘空间来存储训练数据。
第九章介绍了我们将要消耗的项目、环境和数据,以及我们将要实施的项目结构。第十章展示了我们如何将数据转换为 PyTorch 数据集,第十一章和第十二章介绍了我们的分类模型:我们需要衡量数据集训练效果的指标,并实施解决阻止模型良好训练的问题的解决方案。在第十三章,我们将转向端到端项目的开始,通过创建一个生成热图而不是单一分类的分割模型。该热图将用于生成位置进行分类。最后,在第十四章,我们将结合我们的分割和分类模型进行最终诊断。
九、使用 PyTorch 来对抗癌症
本章涵盖内容
-
将一个大问题分解为更小、更容易的问题
-
探索复杂深度学习问题的约束,并决定结构和方法
-
下载训练数据
本章有两个主要目标。我们将首先介绍本书第二部分的整体计划,以便我们对接下来的各个章节将要构建的更大范围有一个坚实的概念。在第十章中,我们将开始构建数据解析和数据操作例程,这些例程将在第十一章中训练我们的第一个模型时产生要消耗的数据。为了很好地完成即将到来的章节所需的工作,我们还将利用本章来介绍我们的项目将运行的一些背景:我们将讨论数据格式、数据来源,并探索我们问题领域对我们施加的约束。习惯执行这些任务,因为你将不得不为任何严肃的深度学习项目做这些任务!
9.1 用例简介
本书这一部分的目标是为您提供处理事情不顺利的工具,这种情况比第 1 部分可能让你相信的更常见。我们无法预测每种失败情况或涵盖每种调试技术,但希望我们能给你足够的东西,让你在遇到新的障碍时不感到困惑。同样,我们希望帮助您避免您自己的项目出现情况,即当您的项目表现不佳时,您不知道接下来该做什么。相反,我们希望您的想法列表会很长,挑战将是如何优先考虑!
为了呈现这些想法和技术,我们需要一个具有一些细微差别和相当重要性的背景。我们选择使用仅通过患者胸部的 CT 扫描作为输入来自动检测肺部恶性肿瘤。我们将专注于技术挑战而不是人类影响,但不要误解–即使从工程角度来看,第 2 部分也需要比第 1 部分更严肃、更有结构的方法才能使项目成功。
注意 CT 扫描本质上是 3D X 射线,表示为单通道数据的 3D 数组。我们很快会更详细地讨论它们。
正如你可能已经猜到的,本章的标题更多是引人注目的、暗示夸张,而不是严肃的声明意图。让我们准确一点:本书的这一部分的项目将以人体躯干的三维 CT 扫描作为输入,并输出怀疑的恶性肿瘤的位置,如果有的话。
早期检测肺癌对生存率有巨大影响,但手动进行这项工作很困难,特别是在任何全面、整体人口意义上。目前,审查数据的工作必须由经过高度训练的专家执行,需要极其细致的注意,而且主要是由不存在癌症的情况主导。
做好这项工作就像被放在 100 堆草垛前,并被告知:“确定这些中哪些,如果有的话,包含一根针。”这样搜索会导致潜在的警告信号被忽略,特别是在早期阶段,提示更加微妙。人类大脑并不适合做那种单调的工作。当然,这就是深度学习发挥作用的地方。
自动化这个过程将使我们在一个不合作的环境中获得经验,在那里我们必须从头开始做更多的工作,而且可能会遇到更少的问题容易解决。不过,我们一起努力,最终会成功的!一旦你读完第二部分,我们相信你就准备好开始解决你自己选择的一个真实且未解决的问题了。
我们选择了肺部肿瘤检测这个问题,有几个原因。主要原因是这个问题本身尚未解决!这很重要,因为我们想要明确表明你可以使用 PyTorch 有效地解决尖端项目。我们希望这能增加你对 PyTorch 作为框架以及作为开发者的信心。这个问题空间的另一个好处是,虽然它尚未解决,但最近许多团队一直在关注它,并且已经看到了有希望的结果。这意味着这个挑战可能正好处于我们集体解决能力的边缘;我们不会浪费时间在一个实际上离合理解决方案还有几十年的问题上。对这个问题的关注也导致了许多高质量的论文和开源项目,这些是灵感和想法的重要来源。如果你有兴趣继续改进我们创建的解决方案,这将在我们完成书的第二部分后非常有帮助。我们将在第十四章提供一些额外信息的链接。
本书的这一部分将继续专注于检测肺部肿瘤的问题,但我们将教授的技能是通用的。学习如何调查、预处理和呈现数据以进行训练对于你正在进行的任何项目都很重要。虽然我们将在肺部肿瘤的具体背景下涵盖预处理,但总体思路是这是你应该为你的项目做好准备的。同样,建立训练循环、获得正确的性能指标以及将项目的模型整合到最终应用程序中都是我们将在第 9 至 14 章中使用的通用技能。
注意 尽管第 2 部分的最终结果将有效,但输出不够准确以用于临床。我们专注于将其作为教授 PyTorch的激励示例,而不是利用每一个技巧来解决问题。
9.2 准备一个大型项目
这个项目将建立在第 1 部分学到的基础技能之上。特别是,从第八章开始的模型构建内容将直接相关。重复的卷积层后跟着一个分辨率降低的下采样层仍将构成我们模型的大部分。然而,我们将使用 3D 数据作为我们模型的输入。这在概念上类似于第 1 部分最后几章中使用的 2D 图像数据,但我们将无法依赖 PyTorch 生态系统中所有 2D 特定工具。
我们在第八章使用卷积模型的工作与第 2 部分中将要做的工作之间的主要区别与我们投入到模型之外的事情有关。在第八章,我们使用一个提供的现成数据集,并且在将数据馈送到模型进行分类之前几乎没有进行数据操作。我们几乎所有的时间和注意力都花在构建模型本身上,而现在我们甚至不会在第十一章开始设计我们的两个模型架构之一。这是由于有非标准数据,没有预先构建的库可以随时提供适合插入模型的训练样本。我们将不得不了解我们的数据并自己实现相当多的内容。
即使完成了这些工作,这也不会成为将 CT 转换为张量,将其馈送到神经网络中,并在另一侧得到答案的情况。对于这样的真实用例,一个可行的方法将更加复杂,以考虑到限制数据可用性、有限的计算资源以及我们设计有效模型的能力的限制因素。请记住这一点,因为我们将逐步解释我们项目架构的高级概述。
谈到有限的计算资源,第 2 部分将需要访问 GPU 才能实现合理的训练速度,最好是至少具有 8 GB 的 RAM。尝试在 CPU 上训练我们将构建的模型可能需要几周时间!¹ 如果你手头没有 GPU,我们在第十四章提供了预训练模型;那里的结节分析脚本可能可以在一夜之间运行。虽然我们不想将本书与专有服务绑定,但值得注意的是,目前,Colaboratory(colab.research.google.com)提供免费的 GPU 实例,可能会有用。PyTorch 甚至已经预安装!你还需要至少 220 GB 的可用磁盘空间来存储原始训练数据、缓存数据和训练模型。
注意 第 2 部分中呈现的许多代码示例省略了复杂的细节。与其用日志记录、错误处理和边缘情况来混淆示例,本书的文本只包含表达讨论中核心思想的代码。完整的可运行代码示例可以在本书的网站(www.manning.com/books/deep-learning-with-pytorch)和 GitHub(github.com/deep-learning-with-pytorch/dlwpt-code)上找到。
好的,我们已经确定了这是一个困难、多方面的问题,但我们要怎么解决呢?我们不是要查看整个 CT 扫描以寻找肿瘤或其潜在恶性,而是要解决一系列更简单的问题,这些问题将组合在一起提供我们感兴趣的端到端结果。就像工厂的装配线一样,每个步骤都会接收原材料(数据)和/或前一步骤的输出,进行一些处理,并将结果交给下一个站点。并不是每个问题都需要这样解决,但将问题分解成独立解决的部分通常是一个很好的开始。即使最终发现这种方法对于特定项目来说是错误的,但在处理各个部分时,我们可能已经学到足够多的知识,以便知道如何重新构建我们的方法以取得成功。
在我们深入了解如何分解问题的细节之前,我们需要了解一些关于医学领域的细节。虽然代码清单会告诉你我们在做什么,但了解放射肿瘤学将解释为什么我们这样做。无论是哪个领域,了解问题空间都是至关重要的。深度学习很强大,但它不是魔法,盲目地将其应用于非平凡问题可能会失败。相反,我们必须将对空间的洞察力与对神经网络行为的直觉相结合。从那里,有纪律的实验和改进应该为我们提供足够的信息,以便找到可行的解决方案。
9.3 什么是 CT 扫描,确切地说?
在我们深入项目之前,我们需要花点时间解释一下什么是 CT 扫描。我们将广泛使用 CT 扫描数据作为我们项目的主要数据格式,因此对数据格式的优势、劣势和基本特性有一个工作理解将对其有效利用至关重要。我们之前指出的关键点是:CT 扫描本质上是 3D X 射线,表示为单通道数据的 3D 数组。正如我们可能从第四章中记得的那样,这就像一组堆叠的灰度 PNG 图像。
体素
一个体素是熟悉的二维像素的三维等价物。它包围着空间的一个体积(因此,“体积像素”),而不是一个区域,并且通常排列在一个三维网格中以表示数据场。每个维度都将与之关联一个可测量的距离。通常,体素是立方体的,但在本章中,我们将处理的是长方体体素。
除了医学数据,我们还可以在流体模拟、从 2D 图像重建的 3D 场景、用于自动驾驶汽车的光探测与测距(LIDAR)数据等问题领域看到类似的体素数据。这些领域都有各自的特点和微妙之处,虽然我们将在这里介绍的 API 通常适用,但如果我们想要有效地使用这些 API,我们也必须了解我们使用的数据的性质。
每个 CT 扫描的体素都有一个数值,大致对应于内部物质的平均质量密度。大多数数据的可视化显示高密度材料如骨骼和金属植入物为白色,低密度的空气和肺组织为黑色,脂肪和组织为各种灰色。再次,这看起来与 X 射线有些相似,但也有一些关键区别。
CT 扫描和 X 射线之间的主要区别在于,X 射线是将 3D 强度(在本例中为组织和骨密度)投影到 2D 平面上,而 CT 扫描保留了数据的第三维。这使我们能够以各种方式呈现数据:例如,作为一个灰度实体,我们可以在图 9.1 中看到。
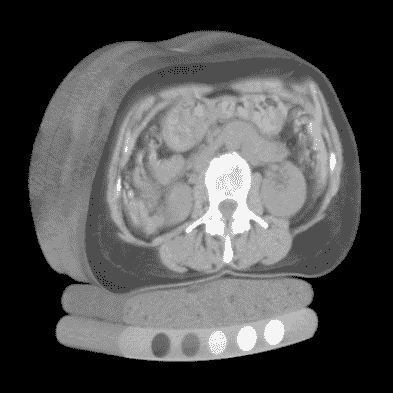
图 9.1 人体躯干的 CT 扫描,从上到下依次显示皮肤、器官、脊柱和患者支撑床。来源:mng.bz/04r6; Mindways CT Software / CC BY-SA 3.0 (creativecommons.org/licenses/by-sa/3.0/deed.en)。
注意 CT 扫描实际上测量的是辐射密度,这是受检材料的质量密度和原子序数的函数。在这里,区分并不相关,因为无论输入的确切单位是什么,模型都会处理和学习 CT 数据。
这种 3D 表示还允许我们通过隐藏我们不感兴趣的组织类型来“看到”主体内部。例如,我们可以将数据呈现为 3D,并将可见性限制在骨骼和肺组织,如图 9.2 所示。

图 9.2 显示了肋骨、脊柱和肺结构的 CT 扫描
与 X 射线相比,CT 扫描要难得多,因为这需要像图 9.3 中所示的那种机器,通常新机器的成本高达一百万美元,并且需要受过培训的工作人员来操作。大多数医院和一些设备齐全的诊所都有 CT 扫描仪,但它们远不及 X 射线机器普及。这与患者隐私规定结合在一起,可能会使得获取 CT 扫描有些困难,除非已经有人做好了收集和整理这些数据的工作。
图 9.3 还显示了 CT 扫描中包含区域的示例边界框。患者躺在的床来回移动,使扫描仪能够成像患者的多个切片,从而填充边界框。扫描仪较暗的中心环是实际成像设备的位置。

图 9.3 一个患者在 CT 扫描仪内,CT 扫描的边界框叠加显示。除了库存照片外,患者在机器内通常不穿着便装。
CT 扫描与 X 射线之间的最后一个区别是数据仅以数字格式存在。CT代表计算机断层扫描(en.wikipedia.org/wiki/CT_scan#Process)。扫描过程的原始输出对人眼来说并不特别有意义,必须由计算机正确重新解释为我们可以理解的内容。扫描时 CT 扫描仪的设置会对结果数据产生很大影响。
尽管这些信息可能看起来并不特别相关,但实际上我们学到了一些东西:从图 9.3 中,我们可以看到 CT 扫描仪测量头到脚轴向距离的方式与其他两个轴不同。患者实际上沿着这个轴移动!这解释了(或至少是一个强烈的暗示)为什么我们的体素可能不是立方体,并且也与我们在第十二章中如何处理数据有关。这是一个很好的例子,说明我们需要了解我们的问题领域,如果要有效地选择如何解决问题。在开始处理自己的项目时,确保您对数据的细节进行相同的调查。
9.4 项目:肺癌端到端检测器
现在我们已经掌握了 CT 扫描的基础知识,让我们讨论一下我们项目的结构。大部分磁盘上的字节将用于存储包含密度信息的 CT 扫描的 3D 数组,我们的模型将主要消耗这些 3D 数组的各种子切片。我们将使用五个主要步骤,从检查整个胸部 CT 扫描到给患者做出肺癌诊断。
我们在图 9.4 中展示的完整端到端解决方案将加载 CT 数据文件以生成包含完整 3D 扫描的Ct实例,将其与执行分割(标记感兴趣的体素)的模块结合,然后将有趣的体素分组成小块,以寻找候选结节。
结节
肺部由增殖细胞组成的组织块称为肿瘤。肿瘤可以是良性的,也可以是恶性的,此时也被称为癌症。肺部的小肿瘤(仅几毫米宽)称为结节。大约 40%的肺结节最终被证实是恶性的–小癌症。尽早发现这些对于医学影像非常重要,这取决于我们正在研究的这种类型的医学影像。

图 9.4 完整胸部 CT 扫描并确定患者是否患有恶性肿瘤的端到端过程
结节位置与 CT 体素数据结合,产生结节候选,然后可以由我们的结节分类模型检查它们是否实际上是结节,最终是否是恶性的。后一项任务特别困难,因为恶性可能仅从 CT 成像中无法明显看出,但我们将看看我们能走多远。最后,每个单独的结节分类可以组合成整体患者诊断。
更详细地说,我们将执行以下操作:
-
将我们的原始 CT 扫描数据加载到一个可以与 PyTorch 一起使用的形式中。将原始数据放入 PyTorch 可用的形式将是您面临的任何项目的第一步。对于 2D 图像数据,这个过程稍微复杂一些,对于非图像数据则更简单。
-
使用 PyTorch 识别肺部潜在肿瘤的体素,实现一种称为分割的技术。这大致相当于生成应该输入到我们第 3 步分类器中的区域的热图。这将使我们能够专注于肺部内部的潜在肿瘤,并忽略大片无趣的解剖结构(例如,一个人不能在胃部患肺癌)。
通常,在学习时能够专注于单一小任务是最好的。随着经验的积累,有些情况下更复杂的模型结构可以产生最优结果(例如,我们在第二章看到的 GAN 游戏),但是从头开始设计这些模型需要对基本构建模块有广泛的掌握。先学会走路,再跑步,等等。
-
将有趣的体素分组成块:也就是候选结节(有关结节的更多信息,请参见图 9.5)。在这里,我们将找到热图上每个热点的粗略中心。
每个结节可以通过其中心点的索引、行和列来定位。我们这样做是为了向最终分类器提供一个简单、受限的问题。将体素分组不会直接涉及 PyTorch,这就是为什么我们将其拆分为一个单独的步骤。通常,在处理多步解决方案时,会在项目的较大、由深度学习驱动的部分之间添加非深度学习的连接步骤。
-
使用 3D 卷积将候选结节分类为实际结节或非结节。
这将类似于我们在第八章中介绍的 2D 卷积。确定候选结构中肿瘤性质的特征是与问题中的肿瘤局部相关的,因此这种方法应该在限制输入数据大小和排除相关信息之间提供良好的平衡。做出这种限制范围的决定可以使每个单独的任务受限,这有助于在故障排除时限制要检查的事物数量。
-
使用组合的每个结节分类来诊断患者。
与上一步中的结节分类器类似,我们将尝试仅基于成像数据确定结节是良性还是恶性。我们将简单地取每个肿瘤恶性预测的最大值,因为只需要一个肿瘤是恶性,患者就会患癌症。其他项目可能希望使用不同的方式将每个实例的预测聚合成一个文件分数。在这里,我们问的是,“有什么可疑的吗?”所以最大值是一个很好的聚合方式。如果我们正在寻找定量信息,比如“A 型组织与 B 型组织的比例”,我们可能会选择适当的平均值。
肩上的巨人
当我们决定采用这种五步方法时,我们站在巨人的肩膀上。我们将在第十四章更详细地讨论这些巨人及其工作。我们事先并没有特别的理由认为这种项目结构对这个问题会很有效;相反,我们依赖于那些实际实施过类似事物并报告成功的人。在转向不同领域时,预计需要进行实验以找到可行的方法,但始终尝试从该领域的早期努力和那些在类似领域工作并发现可能转移的事物的人那里学习。走出去,寻找他人所做的事情,并将其作为一个基准。同时,避免盲目获取代码并运行,因为您需要完全理解您正在运行的代码,以便利用结果为自己取得进展。
图 9.4 仅描述了在构建和训练所有必要模型后通过系统的最终路径。训练相关模型所需的实际工作将在我们接近实施每个步骤时详细说明。
我们将用于训练的数据为步骤 3 和 4 提供了人工注释的输出。这使我们可以将步骤 2 和 3(识别体素并将其分组为结节候选)几乎视为与步骤 4(结节候选分类)分开的项目。人类专家已经用结节位置注释了数据,因此我们可以按照自己喜欢的顺序处理步骤 2 和 3 或步骤 4。
我们将首先处理步骤 1(数据加载),然后跳到步骤 4,然后再回来实现步骤 2 和 3,因为步骤 4(分类)需要一种类似于我们在第八章中使用的方法,即使用多个卷积和池化层来聚合空间信息,然后将其馈送到线性分类器中。一旦我们掌握了分类模型,我们就可以开始处理步骤 2(分割)。由于分割是更复杂的主题,我们希望在不必同时学习分割和 CT 扫描以及恶性肿瘤的基础知识的情况下解决它。相反,我们将在处理一个更熟悉的分类问题的同时探索癌症检测领域。
从问题中间开始并逐步解决问题的方法可能看起来很奇怪。从第 1 步开始逐步向前推进会更直观。然而,能够将问题分解并独立解决各个步骤是有用的,因为这样可以鼓励更模块化的解决方案;此外,将工作负载在小团队成员之间划分会更容易。此外,实际的临床用户可能更喜欢一个系统,可以标记可疑的结节供审查,而不是提供单一的二进制诊断。将我们的模块化解决方案适应不同的用例可能会比如果我们采用了单一的、自上而下的系统更容易。
当我们逐步实施每一步时,我们将详细介绍肺部肿瘤,以及展示大量关于 CT 扫描的细节。虽然这可能看起来与专注于 PyTorch 的书籍无关,但我们这样做是为了让你开始对问题空间产生直觉。这是至关重要的,因为所有可能的解决方案和方法的空间太大,无法有效地编码、训练和评估。
如果我们在做一个不同的项目(比如你在完成这本书后要处理的项目),我们仍然需要进行调查来了解数据和问题空间。也许你对卫星地图制作感兴趣,你的下一个项目需要处理从轨道拍摄的地球图片。你需要询问关于收集的波长的问题–你只得到正常的 RGB 吗,还是更奇特的东西?红外线或紫外线呢?此外,根据白天时间或者成像位置不直接在卫星正上方,可能会使图像倾斜。图像是否需要校正?
即使你假设的第三个项目的数据类型保持不变,你将要处理的领域可能会改变事情,可能会发生显著变化。处理自动驾驶汽车的相机输出仍然涉及 2D 图像,但复杂性和注意事项却大不相同。例如,映射卫星不太可能需要担心太阳照射到相机中,或者镜头上沾上泥巴!
我们必须能够运用直觉来引导我们对潜在优化和改进的调查。这对于深度学习项目来说是真实的,我们将在第 2 部分中练习使用我们的直觉。所以,让我们这样做。快速退后一步,做一个直觉检查。你的直觉对这种方法有什么看法?对你来说是否过于复杂?
9.4.1 为什么我们不能简单地将数据输入神经网络直到它工作?
在阅读最后一节之后,如果你认为,“这和第八章完全不同!”我们并不会责怪你。你可能会想知道为什么我们有两种不同的模型架构,或者为什么整体数据流如此复杂。嗯,我们之所以采取这种方法与第八章不同是有原因的。自动化这个任务很困难,人们还没有完全弄清楚。这种困难转化为复杂性;一旦我们作为一个社会彻底解决了这个问题,可能会有一个现成的库包,我们可以直接使用,但我们还没有达到那一步。
为什么会这么困难呢?
首先,大部分 CT 扫描基本上与回答“这个患者是否患有恶性肿瘤?”这个问题无关。这是很直观的,因为患者身体的绝大部分组织都是健康的细胞。在有恶性肿瘤的情况下,CT 中高达 99.9999%的体素仍然不是癌症。这个比例相当于高清电视上某处两个像素的颜色错误或者一本小说书架上一个拼错的单词。
你能够在图 9.5 的三个视图中识别被标记为结节的白点吗?²
如果你需要提示,索引、行和列值可以帮助找到相关的密集组织块。你认为只有这些图像(这意味着只有图像–没有索引、行和列信息!)你能找出肿瘤的相关特性吗?如果你被给予整个 3D 扫描,而不仅仅是与扫描的有趣部分相交的三个切片呢?
注意 如果你找不到肿瘤,不要担心!我们试图说明这些数据有多微妙–难以在视觉上识别是这个例子的全部意义。

图 9.5 一张 CT 扫描,大约有 1,000 个对于未经训练的眼睛看起来像肿瘤的结构。当由人类专家审查时,只有一个被确定为结节。其余的是正常的解剖结构,如血管、病变和其他无问题的肿块。
你可能在其他地方看到端到端方法在对象检测和分类中非常成功。TorchVision 包括像 Fast R-CNN/Mask R-CNN 这样的端到端模型,但这些模型通常在数十万张图像上进行训练,而这些数据集并不受稀有类别样本数量的限制。我们将使用的项目架构有利于在更适量的数据上表现良好。因此,虽然从理论上讲,可以向神经网络投入任意大量的数据,直到它学会寻找传说中的丢失的针,以及如何忽略干草,但实际上收集足够的数据并等待足够长的时间来正确训练网络是不现实的。这不会是最佳方法,因为结果很差,大多数读者根本无法获得计算资源来实现它。
要想得出最佳解决方案,我们可以研究已被证明能够更好地端到端集成数据的模型设计。这些复杂的设计能够产生高质量的结果,但它们并不是最佳,因为要理解它们背后的设计决策需要先掌握基本概念。这使得这些先进模型在教授这些基本概念时不是很好的选择!
这并不是说我们的多步设计是最佳方法,因为“最佳”只是相对于我们选择用来评估方法的标准而言。有许多“最佳”方法,就像我们在项目中工作时可能有许多目标一样。我们的自包含、多步方法也有一些缺点。
回想一下第二章的 GAN 游戏。在那里,我们有两个网络合作,制作出老大师艺术家的逼真赝品。艺术家会制作一个候选作品,学者会对其进行评论,给予艺术家如何改进的反馈。用技术术语来说,模型的结构允许梯度从最终分类器(假或真)传播到项目的最早部分(艺术家)。
我们解决问题的方法不会使用端到端梯度反向传播直接优化我们的最终目标。相反,我们将分别优化问题的离散块,因为我们的分割模型和分类模型不会同时训练。这可能会限制我们解决方案的最高效果,但我们认为这将带来更好的学习体验。
我们认为,能够一次专注于一个步骤使我们能够放大并集中精力学习的新技能数量更少。我们的两个模型将专注于执行一个任务。就像人类放射科医生在逐层查看 CT 切片时一样,如果范围被很好地限定,训练工作就会变得更容易。我们还希望提供能够对数据进行丰富操作的工具。能够放大并专注于特定位置的细节将对训练模型的整体生产率产生巨大影响,而不是一次查看整个图像。我们的分割模型被迫消耗整个图像,但我们将构建结构,使我们的分类模型获得感兴趣区域的放大视图。
第 3 步(分组)将生成数据,第 4 步(分类)将消耗类似于图 9.6 中包含肿瘤顺序横截面的图像。这幅图像是(潜在恶性,或至少不确定)肿瘤的近距离视图,我们将训练第 4 步模型识别,并训练第 5 步模型将其分类为良性或恶性。对于未经训练的眼睛(或未经训练的卷积网络)来说,这个肿块可能看起来毫无特征,但在这个样本中识别恶性的预警信号至少比消耗我们之前看到的整个 CT 要容易得多。我们下一章的代码将提供生成类似图 9.6 的放大结节图像的例程。

图 9.6 CT 扫描中肿瘤的近距离、多层切片裁剪
我们将在第十章中进行第 1 步数据加载工作,第十一章和第十二章将专注于解决分类这些结节的问题。之后,我们将回到第十三章工作于第 2 步(使用分割找到候选肿瘤),然后我们将在第十四章中结束本书的第 2 部分,通过实现第 3 步(分组)和第 5 步(结节分析和诊断)的端到端项目。
注意 CT 的标准呈现将上部放在图像的顶部(基本上,头向上),但 CT 按顺序排列其切片,使第一切片是下部(向脚)。因此,Matplotlib 会颠倒图像,除非我们注意翻转它们。由于这种翻转对我们的模型并不重要,我们不会在原始数据和模型之间增加代码路径的复杂性,但我们会在渲染代码中添加翻转以使图像正面朝上。有关 CT 坐标系统的更多信息,请参见第 10.4 节。
让我们在图 9.7 中重复我们的高层概述。

图 9.7 完成全胸 CT 扫描并确定患者是否患有恶性肿瘤的端到端过程
9.4.2 什么是结节?
正如我们所说的,为了充分了解我们的数据以有效使用它,我们需要学习一些关于癌症和放射肿瘤学的具体知识。我们需要了解的最后一件重要事情是什么是结节。简单来说,结节是可能出现在某人肺部内部的无数肿块和隆起之一。有些从患者健康角度来看是有问题的;有些则不是。精确的定义将结节的大小限制在 3 厘米以下,更大的肿块被称为肺块;但我们将使用结节来交替使用所有这样的解剖结构,因为这是一个相对任意的分界线,我们将使用相同的代码路径处理 3 厘米两侧的肿块。肺部的小肿块–结节–可能是良性或恶性肿瘤(也称为癌症)。从放射学的角度来看,结节与其他有各种原因的肿块非常相似:感染、炎症、血液供应问题、畸形血管以及除肿瘤外的其他疾病。
关键部分在于:我们试图检测的癌症将始终是结节,要么悬浮在肺部非密集组织中,要么附着在肺壁上。这意味着我们可以将我们的分类器限制在仅检查结节,而不是让它检查所有组织。能够限制预期输入范围将有助于我们的分类器学习手头的任务。
这是另一个例子,说明我们将使用的基础深度学习技术是通用的,但不能盲目应用。我们需要了解我们所从事的领域,以做出对我们有利的选择。
在图 9.8 中,我们可以看到一个恶性结节的典型例子。我们关注的最小结节直径仅几毫米,尽管图 9.8 中的结节较大。正如我们在本章前面讨论的那样,这使得最小结节大约比整个 CT 扫描小一百万倍。患者检测到的结节中超过一半不是恶性的。

图 9.8 一张显示恶性结节与其他结节视觉差异的 CT 扫描
9.4.3 我们的数据来源:LUNA 大挑战
我们刚刚查看的 CT 扫描来自 LUNA(LUng Nodule Analysis)大挑战。LUNA 大挑战是一个开放数据集与患者 CT 扫描(许多带有肺结节的)高质量标签的结合,以及对数据的分类器的公开排名。有一种公开分享医学数据集用于研究和分析的文化;对这些数据的开放访问使研究人员能够在不必在机构之间签订正式研究协议的情况下使用、结合和对这些数据进行新颖的工作(显然,某些数据也是保密的)。LUNA 大挑战的目标是通过让团队轻松竞争排名榜上的高位来鼓励结节检测的改进。项目团队可以根据标准化标准(提供的数据集)测试其检测方法的有效性。要包含在公开排名中,团队必须提供描述项目架构、训练方法等的科学论文。这为提供进一步的想法和启发项目改进提供了很好的资源。
注意 许多 CT 扫描“在野外”非常混乱,因为各种扫描仪和处理程序之间存在独特性。例如,一些扫描仪通过将那些超出扫描仪视野范围的 CT 扫描区域的密度设置为负值来指示这些体素。CT 扫描也可以使用各种设置在 CT 扫描仪上获取,这可能会以微妙或截然不同的方式改变结果图像。尽管 LUNA 数据通常很干净,但如果您整合其他数据源,请务必检查您的假设。
我们将使用 LUNA 2016 数据集。LUNA 网站(luna16.grand-challenge.org/Description)描述了挑战的两个轨道:第一轨道“结节检测(NDET)”大致对应于我们的第 1 步(分割);第二轨道“假阳性减少(FPRED)”类似于我们的第 3 步(分类)。当该网站讨论“可能结节的位置”时,它正在讨论一个类似于我们将在第十三章中介绍的过程。
9.4.4 下载 LUNA 数据
在我们进一步探讨项目的细节之前,我们将介绍如何获取我们将使用的数据。压缩后的数据约为 60 GB,因此根据您的互联网连接速度,可能需要一段时间才能下载。解压后,它占用约 120 GB 的空间;我们还需要另外约 100 GB 的缓存空间来存储较小的数据块,以便我们可以比读取整个 CT 更快地访问它。
导航至 luna16.grand-challenge.org/download 并注册使用电子邮件或使用 Google OAuth 登录。登录后,您应该看到两个指向 Zenodo 数据的下载链接,以及指向 Academic Torrents 的链接。无论哪个链接,数据应该是相同的。
提示 截至目前,luna.grand-challenge.org 域名没有链接到数据下载页面。如果您在查找下载页面时遇到问题,请仔细检查 luna16. 的域名,而不是 luna.,如果需要,请重新输入网址。
我们将使用的数据分为 10 个子集,分别命名为 subset0 到 subset9。解压缩每个子集,以便您有单独的子目录,如 code/data-unversioned/ part2/luna/subset0,依此类推。在 Linux 上,您将需要 7z 解压缩实用程序(Ubuntu 通过 p7zip-full 软件包提供此功能)。Windows 用户可以从 7-Zip 网站(www.7-zip.org)获取提取器。某些解压缩实用程序可能无法打开存档;如果出现错误,请确保您使用的是提取器的完整版本。
另外,您需要 candidates.csv 和 annotations.csv 文件。为了方便起见,我们已经在书的网站和 GitHub 仓库中包含了这些文件,因此它们应该已经存在于 code/data/part2/luna/*.csv 中。也可以从与数据子集相同的位置下载它们。
注意 如果您没有轻松获得约 220 GB 的免费磁盘空间,可以仅使用 1 或 2 个数据子集来运行示例。较小的训练集将导致模型表现得更差,但这总比完全无法运行示例要好。
一旦您拥有候选文件和至少一个已下载、解压缩并放置在正确位置的子集,您应该能够开始运行本章的示例。如果您想提前开始,可以使用 code/p2ch09_explore_data .ipynb Jupyter Notebook 来开始。否则,我们将在本章后面更深入地讨论笔记本。希望您的下载能在您开始阅读下一章之前完成!
9.5 结论
我们已经取得了完成项目的重大进展!您可能会觉得我们没有取得多少成就;毕竟,我们还没有实现一行代码。但请记住,当您独自处理项目时,您需要像我们在这里做的研究和准备一样。
在本章中,我们着手完成了两件事:
-
了解我们的肺癌检测项目周围的更大背景
-
勾勒出我们第二部分项目的方向和结构
如果您仍然觉得我们没有取得实质性进展,请意识到这种心态是一个陷阱–理解项目所处的领域至关重要,我们所做的设计工作将在我们继续前进时大大获益。一旦我们在第十章开始实现数据加载例程,我们将很快看到这些回报。
由于本章仅提供信息,没有任何代码,我们将暂时跳过练习。
9.6 总结
-
我们检测癌性结节的方法将包括五个大致步骤:数据加载、分割、分组、分类以及结节分析和诊断。
-
将我们的项目分解为更小、半独立的子项目,使得教授每个子项目变得更容易。对于未来具有不同目标的项目,可能会采用其他方法,而不同于本书的目标。
-
CT 扫描是一个包含大约 3200 万体素的强度数据的 3D 数组,大约比我们想要识别的结节大一百万倍。将模型集中在与手头任务相关的 CT 扫描裁剪部分上,将使训练得到合理结果变得更容易。
-
理解我们的数据将使编写处理数据的程序更容易,这些程序不会扭曲或破坏数据的重要方面。CT 扫描数据的数组通常不会具有立方体像素;将现实世界单位的位置信息映射到数组索引需要进行转换。CT 扫描的强度大致对应于质量密度,但使用独特的单位。
-
识别项目的关键概念,并确保它们在我们的设计中得到很好的体现是至关重要的。我们项目的大部分方面将围绕着结节展开,这些结节是肺部的小肿块,在 CT 上可以被发现,与许多其他具有类似外观的结构一起。
-
我们正在使用 LUNA Grand Challenge 数据来训练我们的模型。LUNA 数据包含 CT 扫描,以及用于分类和分组的人工注释输出。拥有高质量的数据对项目的成功有重大影响。
¹ 我们假设–我们还没有尝试过,更不用说计时了。
² 这个样本的series_uid是1.3.6.1.4.1.14519.5.2.1.6279.6001.12626457893177825889037 1755354,如果您以后想要详细查看它,这可能会很有用。
³ 例如,Retina U-Net (arxiv.org/pdf/1811.08661.pdf) 和 FishNet (mng.bz/K240)。
⁴Eric J. Olson,“肺结节:它们可能是癌症吗?”梅奥诊所,mng.bz/yyge。
⁵ 至少如果我们想要得到像样的结果的话,是不行的。
⁶ 根据国家癌症研究所癌症术语词典:mng.bz/jgBP。
⁷ 所需的缓存空间是按章节计算的,但一旦完成了一个章节,你可以删除缓存以释放空间。
十、将数据源合并为统一数据集
本章涵盖
-
加载和处理原始数据文件
-
实现一个表示我们数据的 Python 类
-
将我们的数据转换为 PyTorch 可用的格式
-
可视化训练和验证数据
现在我们已经讨论了第二部分的高层目标,以及概述了数据将如何在我们的系统中流动,让我们具体了解一下这一章我们将要做什么。现在是时候为我们的原始数据实现基本的数据加载和数据处理例程了。基本上,你在工作中涉及的每个重要项目都需要类似于我们在这里介绍的内容。¹ 图 10.1 展示了我们项目的高层地图,来自第九章。我们将在本章的其余部分专注于第 1 步,数据加载。

图 10.1 我们端到端的肺癌检测项目,重点关注本章的主题:第 1 步,数据加载
我们的目标是能够根据我们的原始 CT 扫描数据和这些 CT 的注释列表生成一个训练样本。这听起来可能很简单,但在我们加载、处理和提取我们感兴趣的数据之前,需要发生很多事情。图 10.2 展示了我们需要做的工作,将我们的原始数据转换为训练样本。幸运的是,在上一章中,我们已经对我们的数据有了一些理解,但在这方面我们还有更多工作要做。

图 10.2 制作样本元组所需的数据转换。这些样本元组将作为我们模型训练例程的输入。
这是一个关键时刻,当我们开始将沉重的原始数据转变,如果不是成为黄金,至少也是我们的神经网络将会将其转变为黄金的材料。我们在第四章中首次讨论了这种转变的机制。
10.1 原始 CT 数据文件
我们的 CT 数据分为两个文件:一个包含元数据头信息的.mhd 文件,以及一个包含组成 3D 数组的原始字节的.raw 文件。每个文件的名称都以称为系列 UID(名称来自数字影像和通信医学[DICOM]命名法)的唯一标识符开头,用于讨论的 CT 扫描。例如,对于系列 UID 1.2.3,将有两个文件:1.2.3.mhd 和 1.2.3.raw。
我们的Ct类将消耗这两个文件并生成 3D 数组,以及转换矩阵,将患者坐标系(我们将在第 10.6 节中更详细地讨论)转换为数组所需的索引、行、列坐标(这些坐标在图中显示为(I,R,C),在代码中用_irc变量后缀表示)。现在不要为所有这些细节担心;只需记住,在我们应用这些坐标到我们的 CT 数据之前,我们需要进行一些坐标系转换。我们将根据需要探讨细节。
我们还将加载 LUNA 提供的注释数据,这将为我们提供一个结节坐标列表,每个坐标都有一个恶性标志,以及相关 CT 扫描的系列 UID。通过将结节坐标与坐标系转换信息结合起来,我们得到了我们结节中心的体素的索引、行和列。
使用(I,R,C)坐标,我们可以裁剪我们的 CT 数据的一个小的 3D 切片作为我们模型的输入。除了这个 3D 样本数组,我们必须构建我们的训练样本元组的其余部分,其中将包括样本数组、结节状态标志、系列 UID 以及该样本在结节候选 CT 列表中的索引。这个样本元组正是 PyTorch 从我们的Dataset子类中期望的,并代表了我们从原始原始数据到 PyTorch 张量的标准结构的桥梁的最后部分。
限制或裁剪我们的数据以避免让模型淹没在噪音中是重要的,同样重要的是确保我们不要过于激进,以至于我们的信号被裁剪掉。我们希望确保我们的数据范围行为良好,尤其是在归一化之后。裁剪数据以去除异常值可能很有用,特别是如果我们的数据容易出现极端异常值。我们还可以创建手工制作的、算法转换的输入;这被称为特征工程;我们在第一章中简要讨论过。通常我们会让模型大部分工作;特征工程有其用处,但在第 2 部分中我们不会使用它。
10.2 解析 LUNA 的注释数据
我们需要做的第一件事是开始加载我们的数据。在着手新项目时,这通常是一个很好的起点。确保我们知道如何处理原始输入是必需的,无论如何,知道我们的数据加载后会是什么样子可以帮助我们制定早期实验的结构。我们可以尝试加载单个 CT 扫描,但我们认为解析 LUNA 提供的包含每个 CT 扫描中感兴趣点信息的 CSV 文件是有意义的。正如我们在图 10.3 中看到的,我们期望获得一些坐标信息、一个指示坐标是否为结节的标志以及 CT 扫描的唯一标识符。由于 CSV 文件中的信息类型较少,而且更容易解析,我们希望它们能给我们一些线索,告诉我们一旦开始加载 CT 扫描后要寻找什么。

图 10.3 candidates.csv 中的 LUNA 注释包含 CT 系列、结节候选位置以及指示候选是否实际为结节的标志。
candidates.csv 文件包含有关所有潜在看起来像结节的肿块的信息,无论这些肿块是恶性的、良性肿瘤还是完全不同的东西。我们将以此为基础构建一个完整的候选人列表,然后将其分成训练和验证数据集。以下是 Bash shell 会话显示文件包含的内容:
$ wc -l candidates.csv # ❶
551066 candidates.csv
$ head data/part2/luna/candidates.csv # ❷
seriesuid,coordX,coordY,coordZ,class # ❸
1.3...6860,-56.08,-67.85,-311.92,0
1.3...6860,53.21,-244.41,-245.17,0
1.3...6860,103.66,-121.8,-286.62,0
1.3...6860,-33.66,-72.75,-308.41,0
...
$ grep ',1$' candidates.csv | wc -l # ❹
1351
❶ 统计文件中的行数
❷ 打印文件的前几行
❸ .csv 文件的第一行定义了列标题。
❹ 统计以 1 结尾的行数,表示恶性
注意 seriesuid 列中的值已被省略以更好地适应打印页面。
因此,我们有 551,000 行,每行都有一个seriesuid(我们在代码中将其称为series_uid)、一些(X,Y,Z)坐标和一个class列,对应于结节状态(这是一个布尔值:0 表示不是实际结节的候选人,1 表示是结节的候选人,无论是恶性还是良性)。我们有 1,351 个标记为实际结节的候选人。
annotations.csv 文件包含有关被标记为结节的一些候选人的信息。我们特别关注diameter_mm信息:
$ wc -l annotations.csv
1187 annotations.csv # ❶
$ head data/part2/luna/annotations.csv
seriesuid,coordX,coordY,coordZ,diameter_mm # ❷
1.3.6...6860,-128.6994211,-175.3192718,-298.3875064,5.651470635
1.3.6...6860,103.7836509,-211.9251487,-227.12125,4.224708481
1.3.6...5208,69.63901724,-140.9445859,876.3744957,5.786347814
1.3.6...0405,-24.0138242,192.1024053,-391.0812764,8.143261683
...
❶ 这是与 candidates.csv 文件中不同的数字。
❷ 最后一列也不同。
我们有大约 1,200 个结节的大小信息。这很有用,因为我们可以使用它来确保我们的训练和验证数据包含了结节大小的代表性分布。如果没有这个,我们的验证集可能只包含极端值,使得看起来我们的模型表现不佳。
10.2.1 训练和验证集
对于任何标准的监督学习任务(分类是典型示例),我们将把数据分成训练集和验证集。我们希望确保两个集合都代表我们预期看到和正常处理的真实世界输入数据范围。如果任一集合与我们的真实用例有实质性不同,那么我们的模型行为很可能与我们的预期不同–我们收集的所有训练和统计数据在转移到生产使用时将不具有预测性!我们并不试图使这成为一门精确的科学,但您应该在未来的项目中留意,以确保您正在对不适合您操作环境的数据进行训练和测试。
让我们回到我们的结节。我们将按大小对它们进行排序,并取每第N个用于我们的验证集。这应该给我们所期望的代表性分布。不幸的是,annotations.csv 中提供的位置信息并不总是与 candidates.csv 中的坐标精确对齐:
$ grep 100225287222365663678666836860 annotations.csv
1.3.6...6860,-128.6994211,-175.3192718,-298.3875064,5.651470635 # ❶
1.3.6...6860,103.7836509,-211.9251487,-227.12125,4.224708481
$ grep '100225287222365663678666836860.*,1$' candidates.csv
1.3.6...6860,104.16480444,-211.685591018,-227.011363746,1
1.3.6...6860,-128.94,-175.04,-297.87,1 # ❶
❶ 这两个坐标非常接近。
如果我们从每个文件中截取相应的坐标,我们得到的是(-128.70, -175.32,-298.39)与(-128.94,-175.04,-297.87)。由于问题中的结节直径为 5 毫米,这两个点显然都是结节的“中心”,但它们并不完全对齐。决定处理这种数据不匹配是否值得并忽略该文件是完全合理的反应。然而,我们将努力使事情对齐,因为现实世界的数据集通常以这种方式不完美,并且这是您需要做的工作的一个很好的例子,以从不同的数据源中组装数据。
10.2.2 统一我们的注释和候选数据
现在我们知道我们的原始数据文件是什么样子的,让我们构建一个getCandidateInfoList函数,将所有内容串联起来。我们将使用文件顶部定义的命名元组来保存每个结节的信息。
列表 10.1 dsets.py:7
from collections import namedtuple
# ... line 27
CandidateInfoTuple = namedtuple(
'CandidateInfoTuple',
'isNodule_bool, diameter_mm, series_uid, center_xyz',
)
这些元组不是我们的训练样本,因为它们缺少我们需要的 CT 数据块。相反,这些代表了我们正在使用的人工注释数据的经过消毒、清洁、统一的接口。将必须处理混乱数据与模型训练隔离开非常重要。否则,你的训练循环会很快变得混乱,因为你必须在本应专注于训练的代码中不断处理特殊情况和其他干扰。
提示 明确地将负责数据消毒的代码与项目的其余部分分开。如果需要,不要害怕重写数据一次并将其保存到磁盘。
我们的候选信息列表将包括结节状态(我们将训练模型对其进行分类)、直径(有助于在训练中获得良好的分布,因为大和小结节不会具有相同的特征)、系列(用于定位正确的 CT 扫描)、候选中心(用于在较大的 CT 中找到候选)。构建这些NoduleInfoTuple实例列表的函数首先使用内存缓存装饰器,然后获取磁盘上存在的文件列表。
列表 10.2 dsets.py:32
@functools.lru_cache(1) # ❶
def getCandidateInfoList(requireOnDisk_bool=True): # ❷
mhd_list = glob.glob('data-unversioned/part2/luna/subset*/*.mhd')
presentOnDisk_set = {os.path.split(p)[-1][:-4] for p in mhd_list}
❶ 标准库内存缓存
❷ requireOnDisk_bool 默认筛选掉尚未就位的数据子集中的系列。
由于解析某些数据文件可能很慢,我们将在内存中缓存此函数调用的结果。这将在以后很有用,因为我们将在未来的章节中更频繁地调用此函数。通过仔细应用内存或磁盘缓存来加速我们的数据流水线,可以在训练速度上取得一些令人印象深刻的收益。在您的项目中工作时,请留意这些机会。
之前我们说过,我们将支持使用不完整的训练数据集运行我们的训练程序,因为下载时间长且磁盘空间要求高。requireOnDisk_bool 参数是实现这一承诺的关键;我们正在检测哪些 LUNA 系列 UID 实际上存在并准备从磁盘加载,并且我们将使用该信息来限制我们从即将解析的 CSV 文件中使用的条目。能够通过训练循环运行我们数据的子集对于验证代码是否按预期工作很有用。通常情况下,当这样做时,模型的训练结果很差,几乎无用,但是进行日志记录、指标、模型检查点等功能的练习是有益的。
在获取候选人信息后,我们希望合并注释.csv 中的直径信息。首先,我们需要按 series_uid 对我们的注释进行分组,因为这是我们将用来交叉参考两个文件中每一行的第一个关键字。
代码清单 10.3 dsets.py:40,def getCandidateInfoList
diameter_dict = {}
with open('data/part2/luna/annotations.csv', "r") as f:
for row in list(csv.reader(f))[1:]:
series_uid = row[0]
annotationCenter_xyz = tuple([float(x) for x in row[1:4]])
annotationDiameter_mm = float(row[4])
diameter_dict.setdefault(series_uid, []).append(
(annotationCenter_xyz, annotationDiameter_mm)
)
现在我们将使用 candidates.csv 文件中的信息构建候选人的完整列表。
代码清单 10.4 dsets.py:51,def getCandidateInfoList
candidateInfo_list = []
with open('data/part2/luna/candidates.csv', "r") as f:
for row in list(csv.reader(f))[1:]:
series_uid = row[0]
if series_uid not in presentOnDisk_set and requireOnDisk_bool: # ❶
continue
isNodule_bool = bool(int(row[4]))
candidateCenter_xyz = tuple([float(x) for x in row[1:4]])
candidateDiameter_mm = 0.0
for annotation_tup in diameter_dict.get(series_uid, []):
annotationCenter_xyz, annotationDiameter_mm = annotation_tup
for i in range(3):
delta_mm = abs(candidateCenter_xyz[i] - annotationCenter_xyz[i])
if delta_mm > annotationDiameter_mm / 4: # ❷
break
else:
candidateDiameter_mm = annotationDiameter_mm
break
candidateInfo_list.append(CandidateInfoTuple(
isNodule_bool,
candidateDiameter_mm,
series_uid,
candidateCenter_xyz,
))
❶ 如果系列 UID 不存在,则它在我们没有在磁盘上的子集中,因此我们应该跳过它。
❷ 将直径除以 2 得到半径,并将半径除以 2 要求两个结节中心点相对于结节大小不要相距太远。(这导致一个边界框检查,而不是真正的距离检查。)
对于给定 series_uid 的每个候选人条目,我们循环遍历我们之前收集的相同 series_uid 的注释,看看这两个坐标是否足够接近以将它们视为同一个结节。如果是,太好了!现在我们有了该结节的直径信息。如果我们找不到匹配项,那没关系;我们将只将该结节视为直径为 0.0。由于我们只是使用这些信息来在我们的训练和验证集中获得结节尺寸的良好分布,对于一些结节的直径尺寸不正确不应该是问题,但我们应该记住我们这样做是为了防止我们这里的假设是错误的情况。
这是为了合并我们的结节直径而进行的许多有些繁琐的代码。不幸的是,根据您的原始数据,必须进行这种操作和模糊匹配可能是相当常见的。然而,一旦我们到达这一点,我们只需要对数据进行排序并返回即可。
代码清单 10.5 dsets.py:80,def getCandidateInfoList
candidateInfo_list.sort(reverse=True) # ❶
return candidateInfo_list
❶ 这意味着我们所有实际结节样本都是从最大的开始,然后是所有非结节样本(这些样本没有结节大小信息)。
元组成员在 noduleInfo_list 中的排序是由此排序驱动的。我们使用这种排序方法来帮助确保当我们取数据的一个切片时,该切片获得一组具有良好结节直径分布的实际结节。我们将在第 10.5.3 节中进一步讨论这一点。
10.3 加载单个 CT 扫描
接下来,我们需要能够将我们的 CT 数据从磁盘上的一堆位转换为一个 Python 对象,从中我们可以提取 3D 结节密度数据。我们可以从图 10.4 中看到这条路径,从 .mhd 和 .raw 文件到 Ct 对象。我们的结节注释信息就像是我们原始数据中有趣部分的地图。在我们可以按照这张地图找到我们感兴趣的数据之前,我们需要将数据转换为可寻址的形式。

图 10.4 加载 CT 扫描产生一个体素数组和一个从患者坐标到数组索引的转换。
提示 拥有大量原始数据,其中大部分是无趣的,是一种常见情况;在处理自己的项目时,寻找方法限制范围仅限于相关数据是很重要的。
CT 扫描的本机文件格式是 DICOM(www.dicomstandard.org)。DICOM 标准的第一个版本是在 1984 年编写的,正如我们可能期望的那样,来自那个时期的任何与计算有关的东西都有点混乱(例如,现在已经废弃的整个部分专门用于选择要使用的数据链路层协议,因为当时以太网还没有胜出)。
注意 我们已经找到了正确的库来解析这些原始数据文件,但对于你从未听说过的其他格式,你将不得不自己找到一个解析器。我们建议花时间去做这件事!Python 生态系统几乎为太阳下的每种文件格式都提供了解析器,你的时间几乎肯定比写解析器来处理奇特数据格式的工作更值得花费在项目的新颖部分上。
令人高兴的是,LUNA 已经将我们将在本章中使用的数据转换为 MetaIO 格式,这样使用起来要容易得多(itk.org/Wiki/MetaIO/Documentation#Quick_Start)。如果你以前从未听说过这种格式,不用担心!我们可以将数据文件的格式视为黑匣子,并使用SimpleITK将其加载到更熟悉的 NumPy 数组中。
代码清单 10.6 dsets.py:9
import SimpleITK as sitk
# ... line 83
class Ct:
def __init__(self, series_uid):
mhd_path = glob.glob(
'data-unversioned/part2/luna/subset*/{}.mhd'.format(series_uid) # ❶
)[0]
ct_mhd = sitk.ReadImage(mhd_path) # ❷
ct_a = np.array(sitk.GetArrayFromImage(ct_mhd), dtype=np.float32) # ❸
❶ 我们不关心给定 series_uid 属于哪个子集,因此我们使用通配符来匹配子集。
❷ sitk.ReadImage隐式消耗了传入的.mhd文件以及.raw文件。
❸ 重新创建一个 np.array,因为我们想将值类型转换为 np.float3。
对于真实项目,你会想要了解原始数据中包含哪些类型的信息,但依赖像SimpleITK这样的第三方代码来解析磁盘上的位是完全可以的。找到了关于你的输入的一切与盲目接受你的数据加载库提供的一切之间的正确平衡可能需要一些经验。只需记住,我们主要关心的是数据,而不是位。重要的是信息,而不是它的表示方式。
能够唯一标识我们数据中的特定样本是很有用的。例如,清楚地传达哪个样本导致问题或得到较差的分类结果可以极大地提高我们隔离和调试问题的能力。根据我们样本的性质,有时这个唯一标识符是一个原子,比如一个数字或一个字符串,有时它更复杂,比如一个元组。
我们使用系列实例 UID(series_uid)来唯一标识特定的 CT 扫描,该 UID 是在创建 CT 扫描时分配的。DICOM 在个别 DICOM 文件、文件组、治疗过程等方面大量使用唯一标识符(UID),这些标识符在概念上类似于 UUIDs(docs.python.org/3.6/library/uuid.html),但它们具有不同的创建过程和不同的格式。对于我们的目的,我们可以将它们视为不透明的 ASCII 字符串,用作引用各种 CT 扫描的唯一键。官方上,DICOM UID 中只有字符 0 到 9 和句点(.)是有效字符,但一些野外的 DICOM 文件已经通过替换 UID 为十六进制(0-9 和 a-f)或其他技术上不符合规范的值进行了匿名化(这些不符合规范的值通常不会被 DICOM 解析器标记或清理;正如我们之前所说,这有点混乱)。
我们之前讨论的 10 个子集中,每个子集大约有 90 个 CT 扫描(总共 888 个),每个 CT 扫描表示为两个文件:一个带有.mhd扩展名的文件和一个带有.raw扩展名的文件。数据被分割到多个文件中是由sitk例程隐藏的,因此我们不需要直接关注这一点。
此时,ct_a 是一个三维数组。所有三个维度都是空间维度,单一的强度通道是隐含的。正如我们在第四章中看到的,在 PyTorch 张量中,通道信息被表示为一个大小为 1 的第四维。
10.3.1 豪斯菲尔德单位
回想一下,我们之前说过我们需要了解我们的数据,而不是存储数据的位。在这里,我们有一个完美的实例。如果不了解数据值和范围的微妙之处,我们将向模型输入值,这将妨碍其学习我们想要的内容。
继续__init__方法,我们需要对ct_a值进行一些清理。CT 扫描体素以豪斯菲尔德单位(HU;en.wikipedia.org/ wiki/Hounsfield_scale)表示,这是奇怪的单位;空气为-1,000 HU(对于我们的目的足够接近 0 克/立方厘米),水为 0 HU(1 克/立方厘米),骨骼至少为+1,000 HU(2-3 克/立方厘米)。
注意 HU 值通常以有符号的 12 位整数(塞入 16 位整数)的形式存储在磁盘上,这与 CT 扫描仪提供的精度水平相匹配。虽然这可能很有趣,但与项目无关。
一些 CT 扫描仪使用与负密度对应的 HU 值来指示那些体素位于 CT 扫描仪视野之外。对于我们的目的,患者之外的一切都应该是空气,因此我们通过将值的下限设置为-1,000 HU 来丢弃该视野信息。同样,骨骼、金属植入物等的确切密度与我们的用例无关,因此我们将密度限制在大约 2 克/立方厘米(1,000 HU),即使在大多数情况下这在生物学上并不准确。
列表 10.7 dsets.py:96,Ct.__init__
ct_a.clip(-1000, 1000, ct_a)
高于 0 HU 的值与密度并不完全匹配,但我们感兴趣的肿瘤通常在 1 克/立方厘米(0 HU)左右,因此我们将忽略 HU 与克/立方厘米等常见单位并不完全对应的事实。这没关系,因为我们的模型将被训练直接使用 HU。
我们希望从我们的数据中删除所有这些异常值:它们与我们的目标没有直接关联,而且这些异常值可能会使模型的工作变得更加困难。这种情况可能以多种方式发生,但一个常见的例子是当批量归一化被这些异常值输入时,关于如何最佳归一化数据的统计数据会被扭曲。始终注意清理数据的方法。
我们现在已经将所有构建的值分配给self。
列表 10.8 dsets.py:98,Ct.__init__
self.series_uid = series_uid
self.hu_a = ct_a
重要的是要知道我们的数据使用-1,000 到+1,000 的范围,因为在第十三章中,我们最终会向我们的样本添加信息通道。如果我们不考虑 HU 和我们额外数据之间的差异,那么这些新通道很容易被原始 HU 值所掩盖。对于我们项目的分类步骤,我们不会添加更多的数据通道,因此我们现在不需要实施特殊处理。
10.4 使用患者坐标系定位结节
深度学习模型通常需要固定大小的输入,²因为有固定数量的输入神经元。我们需要能够生成一个包含候选者的固定大小数组,以便我们可以将其用作分类器的输入。我们希望训练我们的模型时使用一个裁剪的 CT 扫描,其中候选者被很好地居中,因为这样我们的模型就不必学习如何注意藏在输入角落的结节。通过减少预期输入的变化,我们使模型的工作变得更容易。
10.4.1 患者坐标系
不幸的是,我们在第 10.2 节加载的所有候选中心数据都是以毫米为单位表示的,而不是体素!我们不能简单地将毫米位置插入数组索引中,然后期望一切按我们想要的方式进行。正如我们在图 10.5 中所看到的,我们需要将我们的坐标从以毫米表示的坐标系(X,Y,Z)转换为用于从 CT 扫描数据中获取数组切片的基于体素地址的坐标系(I,R,C)。这是一个重要的例子,说明了一致处理单位的重要性!

图 10.5 使用转换信息将病人坐标中的结节中心坐标(X,Y,Z)转换为数组索引(索引,行,列)。
正如我们之前提到的,处理 CT 扫描时,我们将数组维度称为索引、行和列,因为 X、Y 和 Z 有不同的含义,如图 10.6 所示。病人坐标系定义正 X 为病人左侧(左),正 Y 为病人后方(后方),正 Z 为朝向病人头部(上部)。左后上有时会缩写为LPS。

图 10.6 我们穿着不当的病人展示了病人坐标系的轴线
病人坐标系以毫米为单位测量,并且具有任意位置的原点,不与 CT 体素数组的原点对应,如图 10.7 所示。

图 10.7 数组坐标和病人坐标具有不同的原点和比例。
病人坐标系通常用于指定有趣解剖的位置,这种方式与任何特定扫描无关。定义 CT 数组与病人坐标系之间关系的元数据存储在 DICOM 文件的头部中,而该元图像格式也保留了头部中的数据。这些元数据允许我们构建从(X,Y,Z)到(I,R,C)的转换,如图 10.5 所示。原始数据包含许多其他类似的元数据字段,但由于我们现在不需要使用它们,这些不需要的字段将被忽略。
10.4.2 CT 扫描形状和体素大小
CT 扫描之间最常见的变化之一是体素的大小;通常它们不是立方体。相反,它们可以是 1.125 毫米×1.125 毫米×2.5 毫米或类似的。通常行和列维度的体素大小相同,而索引维度具有较大的值,但也可以存在其他比例。
当使用方形像素绘制时,非立方体体素可能看起来有些扭曲,类似于使用墨卡托投影地图时在北极和南极附近的扭曲。这是一个不完美的类比,因为在这种情况下,扭曲是均匀和线性的–在图 10.8 中,病人看起来比实际上更矮胖或胸部更宽。如果我们希望图像反映真实比例,我们将需要应用一个缩放因子。

图 10.8 沿索引轴具有非立方体体素的 CT 扫描。请注意从上到下肺部的压缩程度。
知道这些细节在试图通过视觉解释我们的结果时会有所帮助。没有这些信息,很容易会认为我们的数据加载出了问题:我们可能会认为数据看起来很矮胖是因为我们不小心跳过了一半的切片,或者类似的情况。很容易会浪费很多时间来调试一直正常运行的东西,熟悉你的数据可以帮助避免这种情况。
CT 通常是 512 行×512 列,索引维度从大约 100 个切片到可能达到 250 个切片(250 个切片乘以 2.5 毫米通常足以包含感兴趣的解剖区域)。这导致下限约为 225 个体素,或约 3200 万数据点。每个 CT 都会在文件元数据中指定体素大小;例如,在列表 10.10 中我们会调用ct_mhd .GetSpacing()。
10.4.3 毫米和体素地址之间的转换
我们将定义一些实用代码来帮助在病人坐标中的毫米和(I,R,C)数组坐标之间进行转换(我们将在代码中用变量和类似的后缀_xyz表示病人坐标中的变量,用_irc后缀表示(I,R,C)数组坐标)。
您可能想知道 SimpleITK 库是否带有实用函数来进行转换。确实,Image 实例具有两种方法–TransformIndexToPhysicalPoint 和 TransformPhysicalPointToIndex–可以做到这一点(除了从 CRI [列,行,索引] IRC 进行洗牌)。但是,我们希望能够在不保留 Image 对象的情况下进行此计算,因此我们将在这里手动执行数学运算。
轴翻转(以及可能的旋转或其他变换)被编码在从ct_mhd.GetDirections()返回的 3 × 3 矩阵中,以元组形式返回。为了从体素索引转换为坐标,我们需要按顺序执行以下四个步骤:
-
将坐标从 IRC 翻转到 CRI,以与 XYZ 对齐。
-
用体素大小来缩放指数。
-
使用 Python 中的
@矩阵乘以方向矩阵。 -
添加原点的偏移量。
要从 XYZ 转换为 IRC,我们需要按相反顺序执行每个步骤的逆操作。
我们将体素大小保留在命名元组中,因此我们将其转换为数组。
列表 10.9 util.py:16
IrcTuple = collections.namedtuple('IrcTuple', ['index', 'row', 'col'])
XyzTuple = collections.namedtuple('XyzTuple', ['x', 'y', 'z'])
def irc2xyz(coord_irc, origin_xyz, vxSize_xyz, direction_a):
cri_a = np.array(coord_irc)[::-1] # ❶
origin_a = np.array(origin_xyz)
vxSize_a = np.array(vxSize_xyz)
coords_xyz = (direction_a @ (cri_a * vxSize_a)) + origin_a # ❷
return XyzTuple(*coords_xyz)
def xyz2irc(coord_xyz, origin_xyz, vxSize_xyz, direction_a):
origin_a = np.array(origin_xyz)
vxSize_a = np.array(vxSize_xyz)
coord_a = np.array(coord_xyz)
cri_a = ((coord_a - origin_a) @ np.linalg.inv(direction_a)) / vxSize_a # ❸
cri_a = np.round(cri_a) # ❹
return IrcTuple(int(cri_a[2]), int(cri_a[1]), int(cri_a[0])) # ❺
❶ 在转换为 NumPy 数组时交换顺序
❷ 我们计划的最后三个步骤,一行搞定
❸ 最后三个步骤的逆操作
❹ 在转换为整数之前进行适当的四舍五入
❺ 洗牌并转换为整数
哦。如果这有点沉重,不要担心。只需记住我们需要将函数转换并使用为黑匣子。我们需要从患者坐标(_xyz)转换为数组坐标(_irc)的元数据包含在 MetaIO 文件中,与 CT 数据本身一起。我们从 .mhd 文件中提取体素大小和定位元数据的同时获取 ct_a。
列表 10.10 dsets.py:72, class Ct
class Ct:
def __init__(self, series_uid):
mhd_path = glob.glob('data-unversioned/part2/luna/subset*/{}.mhd'.format(series_uid))[0]
ct_mhd = sitk.ReadImage(mhd_path)
# ... line 91
self.origin_xyz = XyzTuple(*ct_mhd.GetOrigin())
self.vxSize_xyz = XyzTuple(*ct_mhd.GetSpacing())
self.direction_a = np.array(ct_mhd.GetDirection()).reshape(3, 3) # ❶
❶ 将方向转换为数组,并将九元素数组重塑为其正确的 3 × 3 矩阵形状
这些是我们需要传递给我们的 xyz2irc 转换函数的输入,除了要转换的单个点。有了这些属性,我们的 CT 对象实现现在具有将候选中心从患者坐标转换为数组坐标所需的所有数据。
10.4.4 从 CT 扫描中提取结节
正如我们在第九章中提到的,对于肺结节患者的 CT 扫描,高达 99.9999% 的体素不会是实际结节的一部分(或者癌症)。再次强调,这个比例相当于高清电视上某处不正确着色的两个像素斑点,或者一本小说书架上一个拼写错误的单词。强迫我们的模型检查如此庞大的数据范围,寻找我们希望其关注的结节的线索,将会像要求您从一堆用您不懂的语言写成的小说中找到一个拼写错误的单词一样有效!³
相反,正如我们在图 10.9 中所看到的,我们将提取每个候选者周围的区域,并让模型一次关注一个候选者。这类似于让您阅读外语中的单个段落:仍然不是一项容易的任务,但要少得多!寻找方法来减少我们模型的问题范围可以帮助,特别是在项目的早期阶段,当我们试图让我们的第一个工作实现运行起来时。

图 10.9 通过使用候选者中心的数组坐标信息(索引,行,列)从较大的 CT 体素数组中裁剪候选样本
getRawNodule函数接受以患者坐标系(X,Y,Z)表示的中心(正如在 LUNA CSV 数据中指定的那样),以及以体素为单位的宽度。它返回一个 CT 的立方块,以及将候选者中心转换为数组坐标的中心。
列表 10.11 dsets.py:105, Ct.getRawCandidate
def getRawCandidate(self, center_xyz, width_irc):
center_irc = xyz2irc(
center_xyz,
self.origin_xyz,
self.vxSize_xyz,
self.direction_a,
)
slice_list = []
for axis, center_val in enumerate(center_irc):
start_ndx = int(round(center_val - width_irc[axis]/2))
end_ndx = int(start_ndx + width_irc[axis])
slice_list.append(slice(start_ndx, end_ndx))
ct_chunk = self.hu_a[tuple(slice_list)]
return ct_chunk, center_irc
实际实现将需要处理中心和宽度的组合将裁剪区域的边缘放在数组外部的情况。但正如前面所述,我们将跳过使函数的更大意图变得模糊的复杂情况。完整的实现可以在书的网站上找到(www.manning.com/books/deep-learning-with-pytorch?query=pytorch)以及 GitHub 仓库中(github.com/deep-learning-with-pytorch/dlwpt-code)。
10.5 一个直接的数据集实现
我们在第七章首次看到了 PyTorch 的Dataset实例,但这将是我们第一次自己实现一个。通过子类化Dataset,我们将把我们的任意数据插入到 PyTorch 生态系统的其余部分中。每个Ct实例代表了数百个不同的样本,我们可以用它们来训练我们的模型或验证其有效性。我们的LunaDataset类将规范化这些样本,将每个 CT 的结节压缩成一个单一集合,可以从中检索样本,而不必考虑样本来自哪个Ct实例。这种压缩通常是我们处理数据的方式,尽管正如我们将在第十二章中看到的,有些情况下简单的数据压缩不足以很好地训练模型。
在实现方面,我们将从子类化Dataset所施加的要求开始,并向后工作。这与我们之前使用的数据集不同;在那里,我们使用的是外部库提供的类,而在这里,我们需要自己实现和实例化类。一旦我们这样做了,我们就可以像之前的例子那样使用它。幸运的是,我们自定义子类的实现不会太困难,因为 PyTorch API 只要求我们想要实现的任何Dataset子类必须提供这两个函数:
一个__len__的实现,在初始化后必须返回一个单一的常量值(在某些情况下该值会被缓存)
__getitem__方法接受一个索引并返回一个元组,其中包含用于训练(或验证,视情况而定)的样本数据
首先,让我们看看这些函数的函数签名和返回值是什么样的。
列表 10.12 dsets.py:176, LunaDataset.__len__
def __len__(self):
return len(self.candidateInfo_list)
def __getitem__(self, ndx):
# ... line 200
return (
candidate_t, 1((CO10-1))
pos_t, 1((CO10-2))
candidateInfo_tup.series_uid, # ❶
torch.tensor(center_irc), # ❶
)
这是我们的训练样本。
我们的__len__实现很简单:我们有一个候选列表,每个候选是一个样本,我们的数据集大小与我们拥有的样本数量一样大。我们不必使实现像这里这样简单;在后面的章节中,我们会看到这种变化!⁴唯一的规则是,如果__len__返回值为N,那么__getitem__需要对所有输入 0 到 N - 1 返回有效值。
对于__getitem__,我们取ndx(通常是一个整数,根据支持输入 0 到 N - 1 的规则)并返回如图 10.2 所示的四项样本元组。构建这个元组比获取数据集长度要复杂一些,因此让我们来看看。
这个方法的第一部分意味着我们需要构建self.candidateInfo _list以及提供getCtRawNodule函数。
列表 10.13 dsets.py:179, LunaDataset.__getitem__
def __getitem__(self, ndx):
candidateInfo_tup = self.candidateInfo_list[ndx]
width_irc = (32, 48, 48)
candidate_a, center_irc = getCtRawCandidate( # ❶
candidateInfo_tup.series_uid,
candidateInfo_tup.center_xyz,
width_irc,
)
返回值 candidate_a 的形状为 (32,48,48);轴是深度、高度和宽度。
我们将在 10.5.1 和 10.5.2 节中马上看到这些。
在__getitem__方法中,我们需要将数据转换为下游代码所期望的正确数据类型和所需的数组维度。
列表 10.14 dsets.py:189, LunaDataset.__getitem__
candidate_t = torch.from_numpy(candidate_a)
candidate_t = candidate_t.to(torch.float32)
candidate_t = candidate_t.unsqueeze(0) # ❶
.unsqueeze(0) 添加了‘Channel’维度。
目前不要太担心我们为什么要操纵维度;下一章将包含最终使用此输出并施加我们在此主动满足的约束的代码。这将是你应该期望为每个自定义Dataset实现的内容。这些转换是将您的“荒野数据”转换为整洁有序张量的关键部分。
最后,我们需要构建我们的分类张量。
列表 10.15 dsets.py:193,LunaDataset.__getitem__
pos_t = torch.tensor([
not candidateInfo_tup.isNodule_bool,
candidateInfo_tup.isNodule_bool
],
dtype=torch.long,
)
这有两个元素,分别用于我们可能的候选类别(结节或非结节;或正面或负面)。我们可以为结节状态设置单个输出,但nn.CrossEntropyLoss期望每个类别有一个输出值,这就是我们在这里提供的内容。您构建的张量的确切细节将根据您正在处理的项目类型而变化。
让我们看看我们最终的样本元组(较大的nodule_t输出并不特别可读,所以我们在列表中省略了大部分内容)。
列表 10.16 p2ch10_explore_data.ipynb
# In[10]:
LunaDataset()[0]
# Out[10]:
(tensor([[[[-899., -903., -825., ..., -901., -898., -893.], # ❶
..., # ❶
[ -92., -63., 4., ..., 63., 70., 52.]]]]), # ❶
tensor([0, 1]), # ❷
'1.3.6...287966244644280690737019247886', # ❸
tensor([ 91, 360, 341])) # ❹
❶ candidate_t
❷ cls_t
❸ candidate_tup.series_uid(省略)
❹ center_irc
这里我们看到了我们__getitem__返回语句的四个项目。
10.5.1 使用getCtRawCandidate函数缓存候选数组
为了使LunaDataset获得良好的性能,我们需要投资一些磁盘缓存。这将使我们避免为每个样本从磁盘中读取整个 CT 扫描。这样做将速度非常慢!确保您注意项目中的瓶颈,并在开始减慢速度时尽力优化它们。我们有点过早地进行了这一步,因为我们还没有证明我们在这里需要缓存。没有缓存,LunaDataset的速度会慢 50 倍!我们将在本章的练习中重新讨论这个问题。
函数本身很简单。它是我们之前看到的Ct.getRawCandidate方法的文件缓存包装器(pypi.python.org/pypi/ diskcache)。
列表 10.17 dsets.py:139
@functools.lru_cache(1, typed=True)
def getCt(series_uid):
return Ct(series_uid)
@raw_cache.memoize(typed=True)
def getCtRawCandidate(series_uid, center_xyz, width_irc):
ct = getCt(series_uid)
ct_chunk, center_irc = ct.getRawCandidate(center_xyz, width_irc)
return ct_chunk, center_irc
我们在这里使用了几种不同的缓存方法。首先,我们将getCt返回值缓存在内存中,这样我们就可以重复请求相同的Ct实例而不必重新从磁盘加载所有数据。在重复请求的情况下,这将极大地提高速度,但我们只保留一个 CT 在内存中,所以如果我们不注意访问顺序,缓存未命中会频繁发生。
调用getCt的getCtRawCandidate函数也具有其输出被缓存,因此在我们的缓存被填充后,getCt将不会被调用。这些值使用 Python 库diskcache缓存在磁盘上。我们将在第十一章讨论为什么有这种特定的缓存设置。目前,知道从磁盘中读取 215 个float32值要比读取 225 个int16值,转换为float32,然后选择 215 个子集要快得多。从第二次通过数据开始,输入的 I/O 时间应该降至可以忽略的程度。
注意 如果这些函数的定义发生实质性变化,我们将需要从磁盘中删除缓存的数值。如果不这样做,即使现在函数不再将给定的输入映射到旧的输出,缓存仍将继续返回它们。数据存储在 data-unversioned/cache 目录中。
10.5.2 在 LunaDataset.init 中构建我们的数据集
几乎每个项目都需要将样本分为训练集和验证集。我们将通过指定的val_stride参数将每个第十个样本指定为验证集的成员来实现这一点。我们还将接受一个isValSet_bool参数,并使用它来确定我们应该保留仅训练数据、验证数据还是所有数据。
列表 10.18 dsets.py:149,class LunaDataset
class LunaDataset(Dataset):
def __init__(self,
val_stride=0,
isValSet_bool=None,
series_uid=None,
):
self.candidateInfo_list = copy.copy(getCandidateInfoList()) # ❶
if series_uid:
self.candidateInfo_list = [
x for x in self.candidateInfo_list if x.series_uid == series_uid
]
❶ 复制返回值,以便通过更改 self.candidateInfo_list 不会影响缓存副本
如果我们传入一个真值series_uid,那么实例将只包含该系列的结节。这对于可视化或调试非常有用,因为这样可以更容易地查看单个有问题的 CT 扫描。
10.5.3 训练/验证分割
我们允许Dataset将数据的 1/N部分分割成一个用于验证模型的子集。我们将如何处理该子集取决于isValSet _bool参数的值。
列表 10.19 dsets.py:162, LunaDataset.__init__
if isValSet_bool:
assert val_stride > 0, val_stride
self.candidateInfo_list = self.candidateInfo_list[::val_stride]
assert self.candidateInfo_list
elif val_stride > 0:
del self.candidateInfo_list[::val_stride] # ❶
assert self.candidateInfo_list
❶ 从self.candidateInfo_list中删除验证图像(列表中每个val_stride个项目)。我们之前复制了一份,以便不改变原始列表。
这意味着我们可以创建两个Dataset实例,并确信我们的训练数据和验证数据之间有严格的分离。当然,这取决于self.candidateInfo_list具有一致的排序顺序,我们通过确保候选信息元组有一个稳定的排序顺序,并且getCandidateInfoList函数在返回列表之前对列表进行排序来实现这一点。
关于训练和验证数据的另一个注意事项是,根据手头的任务,我们可能需要确保来自单个患者的数据只出现在训练或测试中,而不是同时出现在两者中。在这里这不是问题;否则,我们需要在到达结节级别之前拆分患者和 CT 扫描列表。
让我们使用p2ch10_explore_data.ipynb来查看数据:
# In[2]:
from p2ch10.dsets import getCandidateInfoList, getCt, LunaDataset
candidateInfo_list = getCandidateInfoList(requireOnDisk_bool=False)
positiveInfo_list = [x for x in candidateInfo_list if x[0]]
diameter_list = [x[1] for x in positiveInfo_list]
# In[4]:
for i in range(0, len(diameter_list), 100):
print('{:4} {:4.1f} mm'.format(i, diameter_list[i]))
# Out[4]:
0 32.3 mm
100 17.7 mm
200 13.0 mm
300 10.0 mm
400 8.2 mm
500 7.0 mm
600 6.3 mm
700 5.7 mm
800 5.1 mm
900 4.7 mm
1000 4.0 mm
1100 0.0 mm
1200 0.0 mm
1300 0.0 mm
我们有一些非常大的候选项,从 32 毫米开始,但它们迅速减半。大部分候选项在 4 到 10 毫米的范围内,而且有几百个根本没有尺寸信息。这看起来正常;您可能还记得我们实际结节比直径注释多的情况。对数据进行快速的健全性检查非常有帮助;及早发现问题或错误的假设可能节省数小时的工作!
更重要的是,我们的训练和验证集应该具有一些属性,以便良好地工作:
两个集合都该包含所有预期输入变化的示例。
任何一个集合都不应该包含不代表预期输入的样本,除非它们有一个特定的目的,比如训练模型以对异常值具有鲁棒性。
训练集不应该提供关于验证集的不真实的提示,这些提示在真实世界的数据中不成立(例如,在两个集合中包含相同的样本;这被称为训练集中的泄漏)。
10.5.4 渲染数据
再次,要么直接使用p2ch10_explore_data.ipynb,要么启动 Jupyter Notebook 并输入
# In[7]:
%matplotlib inline # ❶
from p2ch10.vis import findNoduleSamples, showNodule
noduleSample_list = findNoduleSamples()
❶ 这个神奇的行设置了通过笔记本内联显示图像的能力。
提示 有关 Jupyter 的 matplotlib 内联魔术的更多信息,请参阅mng.bz/rrmD。
# In[8]:
series_uid = positiveSample_list[11][2]
showCandidate(series_uid)
这产生了类似于本章前面显示的 CT 和结节切片的图像。
如果您感兴趣,我们邀请您编辑p2ch10/vis.py中渲染代码的实现,以满足您的需求和口味。渲染代码大量使用 Matplotlib (matplotlib.org),这是一个对我们来说太复杂的库,我们无法在这里覆盖。
记住,渲染数据不仅仅是为了获得漂亮的图片。重点是直观地了解您的输入是什么样子的。一眼就能看出“这个有问题的样本与我的其他数据相比非常嘈杂”或“奇怪的是,这看起来非常正常”可能在调查问题时很有用。有效的渲染还有助于培养洞察力,比如“也许如果我修改这样的东西,我就能解决我遇到的问题。”随着您开始处理越来越困难的项目,这种熟悉程度将是必不可少的。
注意由于每个子集的划分方式,以及在构建LunaDataset.candidateInfo_list时使用的排序方式,noduleSample_list中条目的排序高度依赖于代码执行时存在的子集。请记住这一点,尤其是在解压更多子集后尝试第二次找到特定样本时。
10.6 结论
在第九章中,我们已经对我们的数据有了深入的了解。在这一章中,我们让PyTorch对我们的数据有了深入的了解!通过将我们的 DICOM-via-meta-image 原始数据转换为张量,我们已经为开始实现模型和训练循环做好了准备,这将在下一章中看到。
不要低估我们已经做出的设计决策的影响:我们的输入大小、缓存结构以及如何划分训练和验证集都会对整个项目的成功或失败产生影响。不要犹豫在以后重新审视这些决策,特别是当你在自己的项目上工作时。
10.7 练习
-
实现一个程序,遍历
LunaDataset实例,并计算完成此操作所需的时间。为了节省时间,可能有意义的是有一个选项将迭代限制在前N=1000个样本。-
第一次运行需要多长时间?
-
第二次运行需要多长时间?
-
清除缓存对运行时间有什么影响?
-
使用最后的
N=1000个样本对第一/第二次运行有什么影响?
-
-
将
LunaDataset的实现更改为在__init__期间对样本列表进行随机化。清除缓存,并运行修改后的版本。这对第一次和第二次运行的运行时间有什么影响? -
恢复随机化,并将
@functools.lru_cache(1, typed=True)装饰器注释掉getCt。清除缓存,并运行修改后的版本。现在运行时间如何变化?
摘要
-
通常,解析和加载原始数据所需的代码并不简单。对于这个项目,我们实现了一个
Ct类,它从磁盘加载数据并提供对感兴趣点周围裁剪区域的访问。 -
如果解析和加载例程很昂贵,缓存可能会很有用。请记住,一些缓存可以在内存中完成,而一些最好在磁盘上执行。每种缓存方式都有其在数据加载管道中的位置。
-
PyTorch 的
Dataset子类用于将数据从其原生形式转换为适合传递给模型的张量。我们可以使用这个功能将我们的真实世界数据与 PyTorch API 集成。 -
Dataset的子类需要为两个方法提供实现:__len__和__getitem__。其他辅助方法是允许的,但不是必需的。 -
将我们的数据分成合理的训练集和验证集需要确保没有样本同时出现在两个集合中。我们通过使用一致的排序顺序,并为验证集取每第十个样本来实现这一点。
-
数据可视化很重要;能够通过视觉调查数据可以提供有关错误或问题的重要线索。我们正在使用 Jupyter Notebooks 和 Matplotlib 来呈现我们的数据。
¹ 对于那些事先准备好所有数据的稀有研究人员:你真幸运!我们其他人将忙于编写加载和解析代码。
² 有例外情况,但现在并不相关。
³ 你在这本书中找到拼写错误了吗? 😉
⁴ 实际上更简单一些;但重点是,我们有选择。
⁵ 他们的术语,不是我们的!
十一、训练一个分类模型以检测可疑肿瘤
本章涵盖
-
使用 PyTorch 的
DataLoader加载数据 -
实现一个在我们的 CT 数据上执行分类的模型
-
设置我们应用程序的基本框架
-
记录和显示指标
在前几章中,我们为我们的癌症检测项目做好了准备。我们涵盖了肺癌的医学细节,查看了我们项目将使用的主要数据来源,并将原始 CT 扫描转换为 PyTorch Dataset实例。现在我们有了数据集,我们可以轻松地使用我们的训练数据。所以让我们开始吧!
11.1 一个基础模型和训练循环
在本章中,我们将做两件主要的事情。我们将首先构建结节分类模型和训练循环,这将是第 2 部分探索更大项目的基础。为此,我们将使用我们在第十章实现的Ct和LunaDataset类来提供DataLoader实例。这些实例将通过训练和验证循环向我们的分类模型提供数据。
我们将通过运行训练循环的结果来结束本章,引入本书这一部分中最困难的挑战之一:如何从混乱、有限的数据中获得高质量的结果。在后续章节中,我们将探讨我们的数据受限的具体方式,并减轻这些限制。
让我们回顾一下第九章的高层路线图,如图 11.1 所示。现在,我们将致力于生成一个能够执行第 4 步分类的模型。作为提醒,我们将候选者分类为结节或非结节(我们将在第十四章构建另一个分类器,试图区分恶性结节和良性结节)。这意味着我们将为呈现给模型的每个样本分配一个单一特定的标签。在这种情况下,这些标签是“结节”和“非结节”,因为每个样本代表一个候选者。

图 11.1 我们的端到端项目,用于检测肺癌,重点是本章的主题:第 4 步,分类
获得项目中一个有意义部分的早期端到端版本是一个重要的里程碑。拥有一个足够好使得结果可以进行分析评估的东西,让你可以有信心进行未来的改变,确信你正在通过每一次改变来改进你的结果,或者至少你能够搁置任何不起作用的改变和实验!在自己的项目中进行大量的实验是必须的。获得最佳结果通常需要进行大量的调试和微调。
但在我们进入实验阶段之前,我们必须打下基础。让我们看看我们第 2 部分训练循环的样子,如图 11.2 所示:鉴于我们在第五章看到了一组类似的核心步骤,这应该会让人感到熟悉。在这里,我们还将使用验证集来评估我们的训练进展,如第 5.5.3 节所讨论的那样。

图 11.2 我们将在本章实现的训练和验证脚本
我们将要实现的基本结构如下:
-
初始化我们的模型和数据加载。
-
循环遍历一个半随机选择的 epoch 数。
-
循环遍历
LunaDataset返回的每个训练数据批次。 -
数据加载器工作进程在后台加载相关批次的数据。
-
将批次传入我们的分类模型以获得结果。
-
根据我们预测结果与地面真实数据之间的差异来计算我们的损失。
-
记录关于我们模型性能的指标到一个临时数据结构中。
-
通过误差的反向传播更新模型权重。
-
循环遍历每个验证数据批次(与训练循环非常相似的方式)。
-
加载相关的验证数据批次(同样,在后台工作进程中)。
-
对批次进行分类,并计算损失。
-
记录模型在验证数据上的表现信息。
-
打印出本轮的进展和性能信息。
-
当我们阅读本章的代码时,请注意我们正在生成的代码与第一部分中用于训练循环的代码之间的两个主要区别。首先,我们将在程序周围放置更多结构,因为整个项目比我们在早期章节中做的要复杂得多。没有额外的结构,代码很快就会变得混乱。对于这个项目,我们将使我们的主要训练应用程序使用许多良好封装的函数,并进一步将像数据集这样的代码分离为独立的 Python 模块。
确保对于您自己的项目,您将结构和设计水平与项目的复杂性水平匹配。结构太少,将难以进行实验、排除问题,甚至描述您正在做的事情!相反,结构太多意味着您正在浪费时间编写您不需要的基础设施,并且在所有管道都就位后,您可能会因为不得不遵守它而减慢自己的速度。此外,花时间在基础设施上很容易成为一种拖延策略,而不是投入艰苦工作来实际推进项目。不要陷入这种陷阱!
本章代码与第一部分的另一个重大区别将是专注于收集有关训练进展的各种指标。如果没有良好的指标记录,准确确定变化对训练的影响是不可能的。在不透露下一章内容的情况下,我们还将看到收集不仅仅是指标,而是适合工作的正确指标是多么重要。我们将在本章中建立跟踪这些指标的基础设施,并通过收集和显示损失和正确分类的样本百分比来运用该基础设施,无论是总体还是每个类别。这足以让我们开始,但我们将在第十二章中涵盖一组更现实的指标。
11.2 我们应用程序的主要入口点
本书中与之前训练工作的一个重大结构性差异是,第二部分将我们的工作封装在一个完整的命令行应用程序中。它将解析命令行参数,具有完整功能的 --help 命令,并且可以在各种环境中轻松运行。所有这些都将使我们能够轻松地从 Jupyter 和 Bash shell 中调用训练例程。¹
我们的应用功能将通过一个类来实现,以便我们可以实例化应用程序并在需要时传递它。这可以使测试、调试或从其他 Python 程序调用更容易。我们可以调用应用程序而无需启动第二个 OS 级别的进程(在本书中我们不会进行显式单元测试,但我们创建的结构对于需要进行这种测试的真实项目可能会有所帮助)。
利用能够通过函数调用或 OS 级别进程调用我们的训练的方式之一是将函数调用封装到 Jupyter Notebook 中,以便代码可以轻松地从本机 CLI 或浏览器中调用。
代码清单 11.1 code/p2_run_everything.ipynb
# In[2]:w
def run(app, *argv):
argv = list(argv)
argv.insert(0, '--num-workers=4') # ❶
log.info("Running: {}({!r}).main()".format(app, argv))
app_cls = importstr(*app.rsplit('.', 1)) # ❷
app_cls(argv).main()
log.info("Finished: {}.{!r}).main()".format(app, argv))
# In[6]:
run('p2ch11.training.LunaTrainingApp', '--epochs=1')
❶ 我们假设您有一台四核八线程 CPU。如有需要,请更改 4。
❷ 这是一个稍微更干净的 import 调用。
注意 这里的训练假设您使用的是一台四核八线程 CPU、16 GB RAM 和一块具有 8 GB RAM 的 GPU 的工作站。如果您的 GPU RAM 较少,请减小 --batch-size,如果 CPU 核心较少或 CPU RAM 较少,请减小 --num-workers。
让我们先把一些半标准的样板代码搞定。我们将从文件末尾开始,使用一个相当标准的 if main 语句块,实例化应用对象并调用 main 方法。
代码清单 11.2 training.py:386
if __name__ == '__main__':
LunaTrainingApp().main()
从那里,我们可以跳回文件顶部,查看应用程序类和我们刚刚调用的两个函数,__init__和main。我们希望能够接受命令行参数,因此我们将在应用程序的__init__函数中使用标准的argparse库(docs.python.org/3/library/argparse.html)。请注意,如果需要,我们可以向初始化程序传递自定义参数。main方法将是应用程序核心逻辑的主要入口点。
列表 11.3 training.py:31,class LunaTrainingApp
class LunaTrainingApp:
def __init__(self, sys_argv=None):
if sys_argv is None: # ❶
sys_argv = sys.argv[1:]
parser = argparse.ArgumentParser()
parser.add_argument('--num-workers',
help='Number of worker processes for background data loading',
default=8,
type=int,
)
# ... line 63
self.cli_args = parser.parse_args(sys_argv)
self.time_str = datetime.datetime.now().strftime('%Y-%m-%d_%H.%M.%S') # ❷
# ... line 137
def main(self):
log.info("Starting {}, {}".format(type(self).__name__, self.cli_args))
❶ 如果调用者没有提供参数,我们会从命令行获取参数。
❷ 我们将使用时间戳来帮助识别训练运行。
这种结构非常通用,可以在未来的项目中重复使用。特别是在__init__中解析参数允许我们将应用程序的配置与调用分开。
如果您在本书网站或 GitHub 上检查本章的代码,您可能会注意到一些额外的提到TensorBoard的行。现在请忽略这些;我们将在本章后面的第 11.9 节中详细讨论它们。
11.3 预训练设置和初始化
在我们开始迭代每个 epoch 中的每个批次之前,需要进行一些初始化工作。毕竟,如果我们还没有实例化模型,我们就无法训练模型!正如我们在图 11.3 中所看到的,我们需要做两件主要的事情。第一,正如我们刚才提到的,是初始化我们的模型和优化器;第二是初始化我们的Dataset和DataLoader实例。LunaDataset将定义组成我们训练 epoch 的随机样本集,而我们的DataLoader实例将负责从我们的数据集中加载数据并将其提供给我们的应用程序。

图 11.3 我们将在本章实现的训练和验证脚本,重点放在预循环变量初始化上
11.3.1 初始化模型和优化器
对于这一部分,我们将LunaModel的细节视为黑匣子。在第 11.4 节中,我们将详细介绍内部工作原理。您可以探索对实现进行更改,以更好地满足我们对模型的目标,尽管最好是在至少完成第十二章之后再进行。
让我们看看我们的起点是什么样的。
列表 11.4 training.py:31,class LunaTrainingApp
class LunaTrainingApp:
def __init__(self, sys_argv=None):
# ... line 70
self.use_cuda = torch.cuda.is_available()
self.device = torch.device("cuda" if self.use_cuda else "cpu")
self.model = self.initModel()
self.optimizer = self.initOptimizer()
def initModel(self):
model = LunaModel()
if self.use_cuda:
log.info("Using CUDA; {} devices.".format(torch.cuda.device_count()))
if torch.cuda.device_count() > 1: # ❶
model = nn.DataParallel(model) # ❷
model = model.to(self.device) # ❸
return model
def initOptimizer(self):
return SGD(self.model.parameters(), lr=0.001, momentum=0.99)
❶ 检测多个 GPU
❷ 包装模型
❸ 将模型参数发送到 GPU。
如果用于训练的系统有多个 GPU,我们将使用nn.DataParallel类在系统中的所有 GPU 之间分发工作,然后收集和重新同步参数更新等。就模型实现和使用该模型的代码而言,这几乎是完全透明的。
DataParallel vs. DistributedDataParallel
在本书中,我们使用DataParallel来处理利用多个 GPU。我们选择DataParallel,因为它是我们现有模型的简单插入包装器。然而,它并不是使用多个 GPU 的性能最佳解决方案,并且它仅限于与单台机器上可用的硬件一起使用。
PyTorch 还提供DistributedDataParallel,这是在需要在多个 GPU 或机器之间分配工作时推荐使用的包装类。由于正确的设置和配置并不简单,而且我们怀疑绝大多数读者不会从复杂性中获益,因此我们不会在本书中涵盖DistributedDataParallel。如果您希望了解更多,请阅读官方文档:pytorch.org/tutorials/intermediate/ddp_tutorial.html。
假设self.use_cuda为真,则调用self.model.to(device)将模型参数移至 GPU,设置各种卷积和其他计算以使用 GPU 进行繁重的数值计算。在构建优化器之前这样做很重要,否则优化器将只查看基于 CPU 的参数对象,而不是复制到 GPU 的参数对象。
对于我们的优化器,我们将使用基本的随机梯度下降(SGD;pytorch.org/docs/stable/optim.html#torch.optim.SGD)与动量。我们在第五章中首次看到了这个优化器。回想第 1 部分,PyTorch 中提供了许多不同的优化器;虽然我们不会详细介绍大部分优化器,但官方文档(pytorch.org/docs/stable/optim.html#algorithms)很好地链接到相关论文。
当选择优化器时,使用 SGD 通常被认为是一个安全的起点;有一些问题可能不适合 SGD,但它们相对较少。同样,学习率为 0.001,动量为 0.9 是相当安全的选择。从经验上看,SGD 与这些值一起在各种项目中表现得相当不错,如果一开始效果不佳,可以尝试学习率为 0.01 或 0.0001。
这并不意味着这些值中的任何一个对我们的用例是最佳的,但试图找到更好的值是在超前。系统地尝试不同的学习率、动量、网络大小和其他类似配置设置的值被称为超参数搜索。在接下来的章节中,我们需要先解决其他更为突出的问题。一旦我们解决了这些问题,我们就可以开始微调这些值。正如我们在第五章的“测试其他优化器”部分中提到的,我们还可以选择其他更为奇特的优化器;但除了可能将torch.optim.SGD替换为torch.optim.Adam之外,理解所涉及的权衡是本书所讨论的范围之外的一个过于高级的主题。
11.3.2 数据加载器的照料和喂养
我们在上一章中构建的LunaDataset类充当着我们拥有的任何“荒野数据”与 PyTorch 构建模块期望的更加结构化的张量世界之间的桥梁。例如,torch.nn.Conv3d ( pytorch.org/docs/stable/nn.html#conv3d) 期望五维输入:(N, C, D, H, W):样本数量,每个样本的通道数,深度,高度和宽度。这与我们的 CT 提供的本机 3D 非常不同!
您可能还记得上一章中LunaDataset.__getitem__中的ct_t.unsqueeze(0)调用;它提供了第四维,即我们数据的“通道”。回想一下第四章,RGB 图像有三个通道,分别用于红色、绿色和蓝色。天文数据可能有几十个通道,每个通道代表电磁波谱的各个切片–伽马射线、X 射线、紫外线、可见光、红外线、微波和/或无线电波。由于 CT 扫描是单一强度的,我们的通道维度只有大小 1。
还要回顾第 1 部分,一次训练单个样本通常是对计算资源的低效利用,因为大多数处理平台能够进行更多的并行计算,而模型处理单个训练或验证样本所需的计算量要少。解决方案是将样本元组组合成批元组,如图 11.4 所示,允许同时处理多个样本。第五维度(N)区分了同一批中的多个样本。
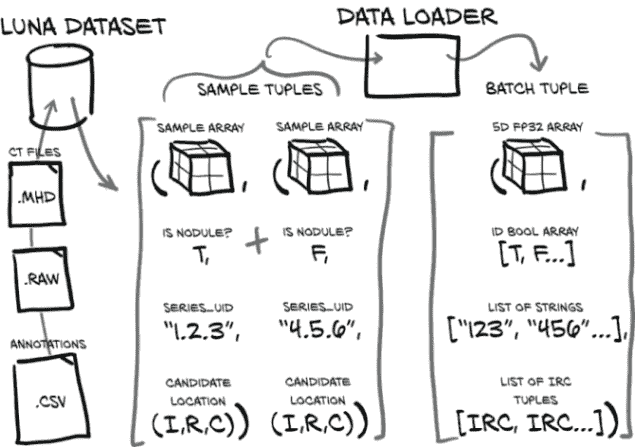
图 11.4 将样本元组整合到数据加载器中的单个批元组中
方便的是,我们不必实现任何批处理:PyTorch 的DataLoader类将处理所有的整理工作。我们已经通过LunaDataset类将 CT 扫描转换为 PyTorch 张量,所以唯一剩下的就是将我们的数据集插入数据加载器中。
列表 11.5 training.py:89,LunaTrainingApp.initTrainDl
def initTrainDl(self):
train_ds = LunaDataset( # ❶
val_stride=10,
isValSet_bool=False,
)
batch_size = self.cli_args.batch_size
if self.use_cuda:
batch_size *= torch.cuda.device_count()
train_dl = DataLoader( # ❷
train_ds,
batch_size=batch_size, # ❸
num_workers=self.cli_args.num_workers,
pin_memory=self.use_cuda, # ❹
)
return train_dl
# ... line 137
def main(self):
train_dl = self.initTrainDl()
val_dl = self.initValDl() # ❺
❶ 我们的自定义数据集
❷ 一个现成的类
❸ 批处理是自动完成的。
❹ 固定内存传输到 GPU 快速。
❺ 验证数据加载器与训练非常相似。
除了对单个样本进行分批处理外,数据加载器还可以通过使用单独的进程和共享内存提供数据的并行加载。我们只需在实例化数据加载器时指定num_workers=...,其余工作都在幕后处理。每个工作进程生成完整的批次,如图 11.4 所示。这有助于确保饥饿的 GPU 得到充分的数据供应。我们的validation_ds和validation_dl实例看起来很相似,除了明显的isValSet_bool=True。
当我们迭代时,比如for batch_tup in self.train_dl:,我们不必等待每个Ct被加载、样本被取出和分批处理等。相反,我们将立即获得已加载的batch_tup,并且后台的工作进程将被释放以开始加载另一个批次,以便在以后的迭代中使用。使用 PyTorch 的数据加载功能可以加快大多数项目的速度,因为我们可以将数据加载和处理与 GPU 计算重叠。
11.4 我们的第一次神经网络设计
能够检测肿瘤的卷积神经网络的设计空间实际上是无限的。幸运的是,在过去的十年左右,已经付出了相当大的努力来研究有效的图像识别模型。虽然这些模型主要集中在 2D 图像上,但一般的架构思想也很适用于 3D,因此有许多经过测试的设计可以作为起点。这有助于我们,因为尽管我们的第一个网络架构不太可能是最佳选择,但现在我们只是追求“足够好以让我们开始”。
我们将基于第八章中使用的内容设计网络。我们将不得不稍微更新模型,因为我们的输入数据是 3D 的,并且我们将添加一些复杂的细节,但图 11.5 中显示的整体结构应该感觉熟悉。同样,我们为这个项目所做的工作将是您未来项目的良好基础,尽管您离开分类或分割项目越远,就越需要调整这个基础以适应。让我们从组成网络大部分的四个重复块开始剖析这个架构。

图 11.5 LunaModel类的架构由批量归一化尾部、四个块的主干和由线性层后跟 softmax 组成的头部。
11.4.1 核心卷积
分类模型通常由尾部、主干(或身体)和头部组成。尾部是处理网络输入的前几层。这些早期层通常具有与网络其余部分不同的结构或组织,因为它们必须将输入调整为主干所期望的形式。在这里,我们使用简单的批量归一化层,尽管通常尾部也包含卷积层。这些卷积层通常用于大幅度降低图像的大小;由于我们的图像尺寸已经很小,所以这里不需要这样做。
接下来,网络的骨干通常包含大部分层,这些层通常按块的系列排列。每个块具有相同(或至少类似)的层集,尽管通常从一个块到另一个块,预期输入的大小和滤波器数量会发生变化。我们将使用一个由两个 3 × 3 卷积组成的块,每个卷积后跟一个激活函数,并在块末尾进行最大池化操作。我们可以在图 11.5 的扩展视图中看到标记为Block[block1]的块的实现。以下是代码中块的实现。
代码清单 11.6 model.py:67,class LunaBlock
class LunaBlock(nn.Module):
def __init__(self, in_channels, conv_channels):
super().__init__()
self.conv1 = nn.Conv3d(
in_channels, conv_channels, kernel_size=3, padding=1, bias=True,
)
self.relu1 = nn.ReLU(inplace=True) 1((CO5-1))
self.conv2 = nn.Conv3d(
conv_channels, conv_channels, kernel_size=3, padding=1, bias=True,
)
self.relu2 = nn.ReLU(inplace=True) # ❶
self.maxpool = nn.MaxPool3d(2, 2)
def forward(self, input_batch):
block_out = self.conv1(input_batch)
block_out = self.relu1(block_out) # ❶
block_out = self.conv2(block_out)
block_out = self.relu2(block_out) # ❶
return self.maxpool(block_out)
❶ 这些可以作为对功能 API 的调用来实现。
最后,网络的头部接收来自骨干的输出,并将其转换为所需的输出形式。对于卷积网络,这通常涉及将中间输出展平并传递给全连接层。对于一些网络,也可以考虑包括第二个全连接层,尽管这通常更适用于具有更多结构的分类问题(比如想想汽车与卡车有轮子、灯、格栅、门等)和具有大量类别的项目。由于我们只进行二元分类,并且似乎不需要额外的复杂性,我们只有一个展平层。
使用这样的结构可以作为卷积网络的良好第一构建块。虽然存在更复杂的设计,但对于许多项目来说,它们在实现复杂性和计算需求方面都过于复杂。最好从简单开始,只有在确实需要时才增加复杂性。
我们可以在图 11.6 中看到我们块的卷积在 2D 中表示。由于这是较大图像的一小部分,我们在这里忽略填充。(请注意,未显示 ReLU 激活函数,因为应用它不会改变图像大小。)
让我们详细了解输入体素和单个输出体素之间的信息流。当输入发生变化时,我们希望对输出如何响应有一个清晰的认识。最好回顾第八章,特别是第 8.1 至 8.3 节,以确保您对卷积的基本机制完全掌握。

图 11.6 LunaModel块的卷积架构由两个 3 × 3 卷积和一个最大池组成。最终像素具有 6 × 6 的感受野。
我们在我们的块中使用 3 × 3 × 3 卷积。单个 3 × 3 × 3 卷积具有 3 × 3 × 3 的感受野,这几乎是显而易见的。输入了 27 个体素,输出一个体素。
当我们使用两个连续的 3 × 3 × 3 卷积时,情况变得有趣。堆叠卷积层允许最终输出的体素(或像素)受到比卷积核大小所示的更远的输入的影响。如果将该输出体素作为边缘体素之一输入到另一个 3 × 3 × 3 卷积核中,则第一层的一些输入将位于第二层的输入 3 × 3 × 3 区域之外。这两个堆叠层的最终输出具有 5 × 5 × 5 的有效感受野。这意味着当两者一起考虑时,堆叠层的作用类似于具有更大尺寸的单个卷积层。
换句话说,每个 3 × 3 × 3 卷积层为感受野添加了额外的一像素边界。如果我们在图 11.6 中向后跟踪箭头,我们可以看到这一点;我们的 2 × 2 输出具有 4 × 4 的感受野,进而具有 6 × 6 的感受野。两个堆叠的 3 × 3 × 3 层比完整的 5 × 5 × 5 卷积使用更少的参数(因此计算速度更快)。
我们两个堆叠的卷积的输出被送入一个 2×2×2 的最大池,这意味着我们正在取一个 6×6×6 的有效区域,丢弃了七分之八的数据,并选择了产生最大值的一个 5×5×5 区域。现在,那些“被丢弃”的输入体素仍然有机会贡献,因为距离一个输出体素的最大池还有一个重叠的输入区域,所以它们可能以这种方式影响最终输出。
请注意,虽然我们展示了每个卷积层的感受野随着每个卷积层的缩小而缩小,但我们使用了填充卷积,它在图像周围添加了一个虚拟的一像素边框。这样做可以保持输入和输出图像的大小不变。
nn.ReLU 层与我们在第六章中看到的层相同。大于 0.0 的输出将保持不变,小于 0.0 的输出将被截断为零。
这个块将被多次重复以形成我们模型的主干。
11.4.2 完整模型
让我们看一下完整模型的实现。我们将跳过块的定义,因为我们刚刚在代码清单 11.6 中看到了。
代码清单 11.7 model.py:13,class LunaModel
class LunaModel(nn.Module):
def __init__(self, in_channels=1, conv_channels=8):
super().__init__()
self.tail_batchnorm = nn.BatchNorm3d(1) # ❶
self.block1 = LunaBlock(in_channels, conv_channels) # ❷
self.block2 = LunaBlock(conv_channels, conv_channels * 2) # ❷
self.block3 = LunaBlock(conv_channels * 2, conv_channels * 4) # ❷
self.block4 = LunaBlock(conv_channels * 4, conv_channels * 8) # ❷
self.head_linear = nn.Linear(1152, 2) # ❸
self.head_softmax = nn.Softmax(dim=1) # ❸
❶ 尾部
❷ 主干
❸ 头部
在这里,我们的尾部相对简单。我们将使用nn.BatchNorm3d对输入进行归一化,正如我们在第八章中看到的那样,它将移动和缩放我们的输入,使其具有均值为 0 和标准差为 1。因此,我们的输入单位处于的有点奇怪的汉斯菲尔德单位(HU)尺度对网络的其余部分来说并不明显。这是一个有点武断的选择;我们知道我们的输入单位是什么,我们知道相关组织的预期值,所以我们可能很容易地实现一个固定的归一化方案。目前尚不清楚哪种方法更好。
我们的主干是四个重复的块,块的实现被提取到我们之前在代码清单 11.6 中看到的单独的nn.Module子类中。由于每个块以 2×2×2 的最大池操作结束,经过 4 层后,我们将在每个维度上将图像的分辨率降低 16 倍。回想一下第十章,我们的数据以 32×48×48 的块返回,最终将变为 2×3×3。
最后,我们的尾部只是一个全连接层,然后调用nn.Softmax。Softmax 是用于单标签分类任务的有用函数,并具有一些不错的特性:它将输出限制在 0 到 1 之间,对输入的绝对范围相对不敏感(只有输入的相对值重要),并且允许我们的模型表达对答案的确定程度。
函数本身相对简单。输入的每个值都用于求幂e,然后得到的一系列值除以所有求幂结果的总和。以下是一个简单的非优化 softmax 实现的 Python 代码示例:
>>> logits = [1, -2, 3]
>>> exp = [e ** x for x in logits]
>>> exp
[2.718, 0.135, 20.086]
>>> softmax = [x / sum(exp) for x in exp]
>>> softmax
[0.118, 0.006, 0.876]
当然,我们在模型中使用 PyTorch 版本的nn.Softmax,因为它本身就能理解批处理和张量,并且会快速且如预期地执行自动梯度。
复杂性:从卷积转换为线性
继续我们的模型定义,我们遇到了一个复杂性。我们不能简单地将self.block4的输出馈送到全连接层,因为该输出是每个样本的 64 通道的 2×3×3 图像,而全连接层期望一个 1D 向量作为输入(技术上说,它们期望一个批量的 1D 向量,这是一个 2D 数组,但无论如何不匹配)。让我们看一下forward方法。
代码清单 11.8 model.py:50,LunaModel.forward
def forward(self, input_batch):
bn_output = self.tail_batchnorm(input_batch)
block_out = self.block1(bn_output)
block_out = self.block2(block_out)
block_out = self.block3(block_out)
block_out = self.block4(block_out)
conv_flat = block_out.view(
block_out.size(0), # ❶
-1,
)
linear_output = self.head_linear(conv_flat)
return linear_output, self.head_softmax(linear_output)
❶ 批处理大小
请注意,在将数据传递到全连接层之前,我们必须使用view函数对其进行展平。由于该操作是无状态的(没有控制其行为的参数),我们可以简单地在forward函数中执行该操作。这在某种程度上类似于我们在第八章讨论的功能接口。几乎每个使用卷积并产生分类、回归或其他非图像输出的模型都会在网络头部具有类似的组件。
对于forward方法的返回值,我们同时返回原始logits和 softmax 生成的概率。我们在第 7.2.6 节中首次提到了 logits:它们是网络在被 softmax 层归一化之前产生的数值。这可能听起来有点复杂,但 logits 实际上只是 softmax 层的原始输入。它们可以有任何实值输入,softmax 会将它们压缩到 0-1 的范围内。
在训练时,我们将使用 logits 来计算nn.CrossEntropyLoss,⁴而在实际对样本进行分类时,我们将使用概率。在训练和生产中使用的输出之间存在这种轻微差异是相当常见的,特别是当两个输出之间的差异是像 softmax 这样简单、无状态的函数时。
初始化
最后,让我们谈谈初始化网络参数。为了使我们的模型表现良好,网络的权重、偏置和其他参数需要表现出一定的特性。让我们想象一个退化的情况,即网络的所有权重都大于 1(且没有残差连接)。在这种情况下,重复乘以这些权重会导致数据通过网络层时层输出变得非常大。类似地,小于 1 的权重会导致所有层输出变得更小并消失。类似的考虑也适用于反向传播中的梯度。
许多规范化技术可以用来保持层输出的良好行为,但其中最简单的一种是确保网络的权重初始化得当,使得中间值和梯度既不过小也不过大。正如我们在第八章讨论的那样,PyTorch 在这里没有给予我们足够的帮助,因此我们需要自己进行一些初始化。我们可以将以下_init_weights函数视为样板,因为确切的细节并不特别重要。
列表 11.9 model.py:30,LunaModel._init_weights
def _init_weights(self):
for m in self.modules():
if type(m) in {
nn.Linear,
nn.Conv3d,
}:
nn.init.kaiming_normal_(
m.weight.data, a=0, mode='fan_out', nonlinearity='relu',
)
if m.bias is not None:
fan_in, fan_out = \
nn.init._calculate_fan_in_and_fan_out(m.weight.data)
bound = 1 / math.sqrt(fan_out)
nn.init.normal_(m.bias, -bound, bound)
11.5 训练和验证模型
现在是时候将我们一直在处理的各种部分组装起来,以便我们实际执行。这个训练循环应该很熟悉–我们在第五章看到了类似图 11.7 的循环。

图 11.7 我们将在本章实现的训练和验证脚本,重点是在每个时期和时期中的批次上进行嵌套循环
代码相对紧凑(doTraining函数仅有 12 个语句;由于行长限制,这里较长)。
列表 11.10 training.py:137,LunaTrainingApp.main
def main(self):
# ... line 143
for epoch_ndx in range(1, self.cli_args.epochs + 1):
trnMetrics_t = self.doTraining(epoch_ndx, train_dl)
self.logMetrics(epoch_ndx, 'trn', trnMetrics_t)
# ... line 165
def doTraining(self, epoch_ndx, train_dl):
self.model.train()
trnMetrics_g = torch.zeros( # ❶
METRICS_SIZE,
len(train_dl.dataset),
device=self.device,
)
batch_iter = enumerateWithEstimate( # ❷
train_dl,
"E{} Training".format(epoch_ndx),
start_ndx=train_dl.num_workers,
)
for batch_ndx, batch_tup in batch_iter:
self.optimizer.zero_grad() # ❸
loss_var = self.computeBatchLoss( # ❹
batch_ndx,
batch_tup,
train_dl.batch_size,
trnMetrics_g
)
loss_var.backward() # ❺
self.optimizer.step() # ❺
self.totalTrainingSamples_count += len(train_dl.dataset)
return trnMetrics_g.to('cpu')
❶ 初始化一个空的指标数组
❷ 设置我们的批次循环和时间估计
❸ 释放任何剩余的梯度张量
❹ 我们将在下一节详细讨论这种方法。
❺ 实际更新模型权重
我们从前几章的训练循环中看到的主要区别如下:
-
trnMetrics_g张量在训练过程中收集了详细的每类指标。对于像我们这样的大型项目,这种洞察力可能非常有用。 -
我们不直接遍历
train_dl数据加载器。我们使用enumerateWithEstimate来提供预计完成时间。这并不是必要的;这只是一种风格上的选择。 -
实际的损失计算被推入
computeBatchLoss方法中。再次强调,这并不是绝对必要的,但代码重用通常是一个优点。
我们将在第 11.7.2 节讨论为什么我们在enumerate周围包装了额外的功能;目前,假设它与enumerate(train_dl)相同。
trnMetrics_g张量的目的是将有关模型在每个样本基础上的行为信息从computeBatchLoss函数传输到logMetrics函数。让我们接下来看一下computeBatchLoss。在完成主要训练循环的其余部分后,我们将讨论logMetrics。
11.5.1 computeBatchLoss函数
computeBatchLoss函数被训练和验证循环调用。顾名思义,它计算一批样本的损失。此外,该函数还计算并记录模型产生的每个样本信息。这使我们能够计算每个类别的正确答案百分比,从而让我们专注于模型遇到困难的领域。
当然,函数的核心功能是将批次输入模型并计算每个批次的损失。我们使用CrossEntropyLoss ( pytorch.org/docs/stable/nn.html#torch.nn.CrossEntropyLoss),就像在第七章中一样。解包批次元组,将张量移动到 GPU,并调用模型应该在之前的训练工作后都感到熟悉。
列表 11.11 training.py:225,.computeBatchLoss
def computeBatchLoss(self, batch_ndx, batch_tup, batch_size, metrics_g):
input_t, label_t, _series_list, _center_list = batch_tup
input_g = input_t.to(self.device, non_blocking=True)
label_g = label_t.to(self.device, non_blocking=True)
logits_g, probability_g = self.model(input_g)
loss_func = nn.CrossEntropyLoss(reduction='none') # ❶
loss_g = loss_func(
logits_g,
label_g[:,1], # ❷
)
# ... line 238
return loss_g.mean() # ❸
❶ reduction=‘none’给出每个样本的损失。
❷ one-hot 编码类别的索引
❸ 将每个样本的损失重新组合为单个值
在这里,我们不使用默认行为来获得平均批次的损失值。相反,我们得到一个损失值的张量,每个样本一个。这使我们能够跟踪各个损失,这意味着我们可以按照自己的意愿进行聚合(例如,按类别)。我们马上就会看到这一点。目前,我们将返回这些每个样本损失的均值,这等同于批次损失。在不想保留每个样本统计信息的情况下,使用批次平均损失是完全可以的。是否这样取决于您的项目和目标。
一旦完成了这些,我们就完成了对调用函数的义务,就 backpropagation 和权重更新而言,需要做的事情。然而,在这之前,我们还想要记录我们每个样本的统计数据以供后人(和后续分析)使用。我们将使用传入的metrics_g参数来实现这一点。
列表 11.12 training.py:26
METRICS_LABEL_NDX=0 # ❶
METRICS_PRED_NDX=1
METRICS_LOSS_NDX=2
METRICS_SIZE = 3
# ... line 225
def computeBatchLoss(self, batch_ndx, batch_tup, batch_size, metrics_g):
# ... line 238
start_ndx = batch_ndx * batch_size
end_ndx = start_ndx + label_t.size(0)
metrics_g[METRICS_LABEL_NDX, start_ndx:end_ndx] = \ # ❷
label_g[:,1].detach() # ❷
metrics_g[METRICS_PRED_NDX, start_ndx:end_ndx] = \ # ❷
probability_g[:,1].detach() # ❷
metrics_g[METRICS_LOSS_NDX, start_ndx:end_ndx] = \ # ❷
loss_g.detach() # ❷
return loss_g.mean() # ❸
❶ 这些命名的数组索引在模块级别范围内声明
❷ 我们使用detach,因为我们的指标都不需要保留梯度。
❸ 再次,这是整个批次的损失。
通过记录每个训练(以及后续的验证)样本的标签、预测和损失,我们拥有大量详细信息,可以用来研究我们模型的行为。目前,我们将专注于编译每个类别的统计数据,但我们也可以轻松地使用这些信息找到被错误分类最多的样本,并开始调查原因。同样,对于一些项目,这种信息可能不那么有趣,但记住你有这些选项是很好的。
11.5.2 验证循环类似
图 11.8 中的验证循环看起来与训练很相似,但有些简化。关键区别在于验证是只读的。具体来说,返回的损失值不会被使用,权重也不会被更新。

图 11.8 我们将在本章实现的训练和验证脚本,重点放在每个 epoch 的验证循环上
在函数调用的开始和结束之间,模型的任何内容都不应该发生变化。此外,由于with torch.no_grad()上下文管理器明确告知 PyTorch 不需要计算梯度,因此速度要快得多。
在 LunaTrainingApp.main 中的 training.py:137,代码清单 11.13
def main(self):
for epoch_ndx in range(1, self.cli_args.epochs + 1):
# ... line 157
valMetrics_t = self.doValidation(epoch_ndx, val_dl)
self.logMetrics(epoch_ndx, 'val', valMetrics_t)
# ... line 203
def doValidation(self, epoch_ndx, val_dl):
with torch.no_grad():
self.model.eval() # ❶
valMetrics_g = torch.zeros(
METRICS_SIZE,
len(val_dl.dataset),
device=self.device,
)
batch_iter = enumerateWithEstimate(
val_dl,
"E{} Validation ".format(epoch_ndx),
start_ndx=val_dl.num_workers,
)
for batch_ndx, batch_tup in batch_iter:
self.computeBatchLoss(
batch_ndx, batch_tup, val_dl.batch_size, valMetrics_g)
return valMetrics_g.to('cpu')
❶ 关闭训练时的行为
在不需要更新网络权重的情况下(回想一下,这样做会违反验证集的整个前提;我们绝不希望这样做!),我们不需要使用computeBatchLoss返回的损失,也不需要引用优化器。 在循环内部剩下的只有对computeBatchLoss的调用。请注意,尽管我们不使用computeBatchLoss返回的每批损失来做任何事情,但我们仍然在valMetrics_g中收集指标作为调用的副作用。
11.6 输出性能指标
每个时期我们做的最后一件事是记录本时期的性能指标。如图 11.9 所示,一旦我们记录了指标,我们就会返回到下一个训练时期的训练循环中。在训练过程中随着进展记录结果是很重要的,因为如果训练出现问题(在深度学习术语中称为“不收敛”),我们希望能够注意到这一点,并停止花费时间训练一个不起作用的模型。在较小的情况下,能够监视模型行为是很有帮助的。

图 11.9 我们将在本章实现的训练和验证脚本,重点放在每个时期结束时的指标记录上
之前,我们在trnMetrics_g和valMetrics_g中收集结果以记录每个时期的进展。这两个张量现在包含了我们计算每个训练和验证运行的每类百分比正确和平均损失所需的一切。每个时期执行此操作是一个常见选择,尽管有些是任意的。在未来的章节中,我们将看到如何调整我们的时期大小,以便以合理的速率获得有关训练进度的反馈。
11.6.1 logMetrics 函数
让我们谈谈logMetrics函数的高级结构。签名看起来像这样。
在 LunaTrainingApp.logMetrics 中的 training.py:251,代码清单 11.14
def logMetrics(
self,
epoch_ndx,
mode_str,
metrics_t,
classificationThreshold=0.5,
):
我们仅使用epoch_ndx来在记录结果时显示。mode_str参数告诉我们指标是用于训练还是验证。
我们要么使用传入的metrics_t参数中的trnMetrics_t或valMetrics_t。回想一下,这两个输入都是浮点值的张量,在computeBatchLoss期间我们填充了数据,然后在我们从doTraining和doValidation返回它们之前将它们转移到 CPU。这两个张量都有三行,以及我们有样本数(训练样本或验证样本,取决于)的列数。作为提醒,这三行对应以下常量。
在 training.py:26,代码清单 11.15
METRICS_LABEL_NDX=0 # ❶
METRICS_PRED_NDX=1
METRICS_LOSS_NDX=2
METRICS_SIZE = 3
❶ 这些在模块级别范围内声明。
张量掩码和布尔索引
掩码张量是一种常见的使用模式,如果您以前没有遇到过,可能会感到不透明。您可能熟悉 NumPy 概念称为掩码数组;张量和数组掩码的行为方式相同。
如果您对掩码数组不熟悉,NumPy 文档中的一个优秀页面(mng.bz/XPra)很好地描述了其行为。 PyTorch 故意使用与 NumPy 相同的语法和语义。
构建掩码
接下来,我们将构建掩码,以便仅将指标限制为结节或非结节(也称为阳性或阴性)样本。我们还将计算每个类别的总样本数,以及我们正确分类的样本数。
在 LunaTrainingApp.logMetrics 中的 training.py:264,代码清单 11.16
negLabel_mask = metrics_t[METRICS_LABEL_NDX] <= classificationThreshold
negPred_mask = metrics_t[METRICS_PRED_NDX] <= classificationThreshold
posLabel_mask = ~negLabel_mask
posPred_mask = ~negPred_mask
虽然我们在这里没有assert,但我们知道存储在metrics _t[METRICS_LABEL_NDX]中的所有值属于集合{0.0, 1.0},因为我们知道我们的结节状态标签只是True或False。通过与默认值为 0.5 的classificationThreshold进行比较,我们得到一个二进制值数组,其中True值对应于所讨论样本的非结节(也称为负)标签。
我们进行类似的比较以创建negPred_mask,但我们必须记住METRICS_PRED_NDX值是我们模型产生的正预测,可以是介于 0.0 和 1.0 之间的任意浮点值。这并不改变我们的比较,但这意味着实际值可能接近 0.5。正掩模只是负掩模的反向。
注意 虽然其他项目可以利用类似的方法,但重要的是要意识到,我们正在采取一些捷径,这是因为这是一个二元分类问题。如果您的下一个项目有超过两个类别或样本同时属于多个类别,您将需要使用更复杂的逻辑来构建类似的掩模。
接下来,我们使用这些掩模计算一些每个标签的统计数据,并将其存储在字典metrics_dict中。
代码清单 11.17 training.py:270,LunaTrainingApp.logMetrics
neg_count = int(negLabel_mask.sum()) # ❶
pos_count = int(posLabel_mask.sum())
neg_correct = int((negLabel_mask & negPred_mask).sum())
pos_correct = int((posLabel_mask & posPred_mask).sum())
metrics_dict = {}
metrics_dict['loss/all'] = \
metrics_t[METRICS_LOSS_NDX].mean()
metrics_dict['loss/neg'] = \
metrics_t[METRICS_LOSS_NDX, negLabel_mask].mean()
metrics_dict['loss/pos'] = \
metrics_t[METRICS_LOSS_NDX, posLabel_mask].mean()
metrics_dict['correct/all'] = (pos_correct + neg_correct) \
/ np.float32(metrics_t.shape[1]) * 100 # ❷
metrics_dict['correct/neg'] = neg_correct / np.float32(neg_count) * 100
metrics_dict['correct/pos'] = pos_correct / np.float32(pos_count) * 100
❶ 转换为普通的 Python 整数
❷ 避免整数除法,转换为 np.float32
首先,我们计算整个时期的平均损失。由于损失是训练过程中要最小化的单一指标,我们始终希望能够跟踪它。然后,我们将损失平均限制为仅使用我们刚刚制作的negLabel_mask的那些带有负标签的样本。我们对正损失也是一样的。像这样计算每类损失在某种情况下是有用的,如果一个类别比另一个类别更难分类,那么这种知识可以帮助推动调查和改进。
我们将通过确定我们正确分类的样本比例以及每个标签的正确比例来结束计算,因为我们将在稍后将这些数字显示为百分比,所以我们还将这些值乘以 100。与损失类似,我们可以使用这些数字来帮助指导我们在进行改进时的努力。计算完成后,我们通过三次调用log.info记录我们的结果。
代码清单 11.18 training.py:289,LunaTrainingApp.logMetrics
log.info(
("E{} {:8} {loss/all:.4f} loss, "
+ "{correct/all:-5.1f}% correct, "
).format(
epoch_ndx,
mode_str,
**metrics_dict,
)
)
log.info(
("E{} {:8} {loss/neg:.4f} loss, "
+ "{correct/neg:-5.1f}% correct ({neg_correct:} of {neg_count:})"
).format(
epoch_ndx,
mode_str + '_neg',
neg_correct=neg_correct,
neg_count=neg_count,
**metrics_dict,
)
)
log.info( # ❶
# ... line 319
)
❶ “pos”日志与之前的“neg”日志类似。
第一个日志包含从所有样本计算得出的值,并标记为/all,而负(非结节)和正(结节)值分别标记为/neg和/pos。我们这里不显示正值的第三个日志声明;它与第二个相同,只是在所有情况下将neg替换为pos。
11.7 运行训练脚本
现在我们已经完成了 training.py 脚本的核心部分,我们将开始实际运行它。这将初始化和训练我们的模型,并打印关于训练进展情况的统计信息。我们的想法是在我们详细介绍模型实现的同时,将其启动在后台运行。希望我们完成后能够查看结果。
我们从主代码目录运行此脚本;它应该有名为 p2ch11、util 等的子目录。所使用的python环境应该安装了 requirements.txt 中列出的所有库。一旦这些库准备就绪,我们就可以运行:
$ python -m p2ch11.training # ❶
Starting LunaTrainingApp,
Namespace(batch_size=256, channels=8, epochs=20, layers=3, num_workers=8)
<p2ch11.dsets.LunaDataset object at 0x7fa53a128710>: 495958 training samples
<p2ch11.dsets.LunaDataset object at 0x7fa537325198>: 55107 validation samples
Epoch 1 of 20, 1938/216 batches of size 256
E1 Training ----/1938, starting
E1 Training 16/1938, done at 2018-02-28 20:52:54, 0:02:57
...
❶ 这是 Linux/Bash 的命令行。Windows 用户可能需要根据所使用的安装方法以不同方式调用 Python。
作为提醒,我们还提供了一个包含训练应用程序调用的 Jupyter 笔记本。
代码清单 11.19 code/p2_run_everything.ipynb
# In[5]:
run('p2ch11.prepcache.LunaPrepCacheApp')
# In[6]:
run('p2ch11.training.LunaTrainingApp', '--epochs=1')
如果第一个时代似乎需要很长时间(超过 10 或 20 分钟),这可能与需要准备 LunaDataset 需要的缓存数据有关。有关缓存的详细信息,请参阅第 10.5.1 节。第十章的练习包括编写一个脚本以有效地预先填充缓存。我们还提供了 prepcache.py 文件来执行相同的操作;可以使用 python -m p2ch11 .prepcache 调用它。由于我们每章都重复我们的 dsets.py 文件,因此缓存需要为每一章重复。这在一定程度上是空间和时间上的低效,但这意味着我们可以更好地保持每一章的代码更加完整。对于您未来的项目,我们建议更多地重用您的缓存。
一旦训练开始,我们要确保我们正在按照预期使用手头的计算资源。判断瓶颈是数据加载还是计算的一个简单方法是在脚本开始训练后等待几分钟(查看类似 E1 Training 16/7750, done at... 的输出),然后同时检查 top 和 nvidia-smi:
如果八个 Python 工作进程消耗了 >80% 的 CPU,那么缓存可能需要准备(我们知道这一点是因为作者已经确保在这个项目的实现中没有 CPU 瓶颈;这不会是普遍的情况)。
如果 nvidia-smi 报告 GPU-Util >80%,那么你的 GPU 已经饱和了。我们将在第 11.7.2 节讨论一些有效等待的策略。
我们的意图是 GPU 饱和;我们希望尽可能多地利用计算能力来快速完成时代。一块 NVIDIA GTX 1080 Ti 应该在 15 分钟内完成一个时代。由于我们的模型相对简单,CPU 不需要太多的预处理才能成为瓶颈。当处理更深的模型(或者总体需要更多计算的模型)时,处理每个批次将需要更长的时间,这将增加 CPU 处理的数量,以便在 GPU 在下一批输入准备好之前耗尽工作之前。
11.7.1 训练所需的数据
如果训练样本数量少于 495,958 个,验证样本数量少于 55,107 个,可能有必要进行一些合理性检查,以确保完整的数据已经准备就绪。对于您未来的项目,请确保您的数据集返回您期望的样本数量。
首先,让我们看一下我们的 data-unversioned/ part2/luna 目录的基本目录结构:
$ ls -1p data-unversioned/part2/luna/
subset0/
subset1/
...
subset9/
接下来,让我们确保每个系列 UID 都有一个 .mhd 文件和一个 .raw 文件
$ ls -1p data-unversioned/part2/luna/subset0/
1.3.6.1.4.1.14519.5.2.1.6279.6001.105756658031515062000744821260.mhd
1.3.6.1.4.1.14519.5.2.1.6279.6001.105756658031515062000744821260.raw
1.3.6.1.4.1.14519.5.2.1.6279.6001.108197895896446896160048741492.mhd
1.3.6.1.4.1.14519.5.2.1.6279.6001.108197895896446896160048741492.raw
...
以及我们是否有正确数量的文件:
$ ls -1 data-unversioned/part2/luna/subset?/* | wc -l
1776
$ ls -1 data-unversioned/part2/luna/subset0/* | wc -l
178
...
$ ls -1 data-unversioned/part2/luna/subset9/* | wc -l
176
如果所有这些看起来都正确,但事情仍然不顺利,请在 Manning LiveBook 上提问(livebook.manning.com/book/deep-learning-with-pytorch/chapter-11),希望有人可以帮助解决问题。
11.7.2 插曲:enumerateWithEstimate 函数
使用深度学习涉及大量的等待。我们谈论的是现实世界中坐在那里,看着墙上的时钟,一个看着的壶永远不会煮开(但你可以在 GPU 上煎蛋),纯粹的 无聊。
唯一比坐在那里盯着一个一个小时都没有移动的闪烁光标更糟糕的是,让您的屏幕充斥着这些:
2020-01-01 10:00:00,056 INFO training batch 1234
2020-01-01 10:00:00,067 INFO training batch 1235
2020-01-01 10:00:00,077 INFO training batch 1236
2020-01-01 10:00:00,087 INFO training batch 1237
...etc...
至少安静闪烁的光标不会让你的滚动缓冲区溢出!
从根本上说,在所有这些等待的过程中,我们想要回答“我有时间去倒满水杯吗?”这个问题,以及关于是否有时间的后续问题
冲一杯咖啡
准备晚餐
在巴黎吃晚餐⁵
要回答这些紧迫的问题,我们将使用我们的 enumerateWithEstimate 函数。使用方法如下:
>>> for i, _ in enumerateWithEstimate(list(range(234)), "sleeping"):
... time.sleep(random.random())
...
11:12:41,892 WARNING sleeping ----/234, starting
11:12:44,542 WARNING sleeping 4/234, done at 2020-01-01 11:15:16, 0:02:35
11:12:46,599 WARNING sleeping 8/234, done at 2020-01-01 11:14:59, 0:02:17
11:12:49,534 WARNING sleeping 16/234, done at 2020-01-01 11:14:33, 0:01:51
11:12:58,219 WARNING sleeping 32/234, done at 2020-01-01 11:14:41, 0:01:59
11:13:15,216 WARNING sleeping 64/234, done at 2020-01-01 11:14:43, 0:02:01
11:13:44,233 WARNING sleeping 128/234, done at 2020-01-01 11:14:35, 0:01:53
11:14:40,083 WARNING sleeping ----/234, done at 2020-01-01 11:14:40
>>>
这是超过 200 次迭代的 8 行输出。即使考虑到random.random()的广泛变化,该函数在 16 次迭代后(不到 10 秒)就有了相当不错的估计。对于具有更稳定时间的循环体,估计会更快地稳定下来。
就行为而言,enumerateWithEstimate与标准的enumerate几乎完全相同(差异在于我们的函数返回一个生成器,而enumerate返回一个专门的<enumerate object at 0x...>)。
列表 11.20 util.py:143,def enumerateWithEstimate
def enumerateWithEstimate(
iter,
desc_str,
start_ndx=0,
print_ndx=4,
backoff=None,
iter_len=None,
):
for (current_ndx, item) in enumerate(iter):
yield (current_ndx, item)
然而,副作用(特别是日志记录)才是使函数变得有趣的地方。与其陷入细节中试图覆盖实现的每个细节,如果您感兴趣,可以查阅函数文档字符串(github .com/deep-learning-with-pytorch/dlwpt-code/blob/master/util/util.py#L143)以获取有关函数参数的信息并对实现进行桌面检查。
深度学习项目可能非常耗时。知道何时预计完成意味着您可以明智地利用这段时间,它还可以提示您某些地方出了问题(或者某种方法行不通),如果预计完成时间远远超出预期。
11.8 评估模型:达到 99.7%的正确率意味着我们完成了,对吧?
让我们来看一下我们训练脚本的一些(缩减的)输出。作为提醒,我们使用命令行python -m p2ch11.training运行了这个脚本:
E1 Training ----/969, starting
...
E1 LunaTrainingApp
E1 trn 2.4576 loss, 99.7% correct
...
E1 val 0.0172 loss, 99.8% correct
...
经过一轮训练,训练集和验证集都显示至少 99.7%的正确结果。这是 A+!是时候来一轮高五,或者至少满意地点点头微笑了。我们刚刚解决了癌症!…对吧?
嗯,不是。
让我们更仔细地(不那么缩减地)看一下第 1 个时代的输出:
E1 LunaTrainingApp
E1 trn 2.4576 loss, 99.7% correct,
E1 trn_neg 0.1936 loss, 99.9% correct (494289 of 494743)
E1 trn_pos 924.34 loss, 0.2% correct (3 of 1215)
...
E1 val 0.0172 loss, 99.8% correct,
E1 val_neg 0.0025 loss, 100.0% correct (494743 of 494743)
E1 val_pos 5.9768 loss, 0.0% correct (0 of 1215)
在验证集上,我们对非结节的分类 100%正确,但实际结节却 100%错误。网络只是将所有东西都分类为非结节!数值 99.7%只意味着大约 0.3%的样本是结节。
经过 10 个时代,情况只是稍微好转:
E10 LunaTrainingApp
E10 trn 0.0024 loss, 99.8% correct
E10 trn_neg 0.0000 loss, 100.0% correct
E10 trn_pos 0.9915 loss, 0.0% correct
E10 val 0.0025 loss, 99.7% correct
E10 val_neg 0.0000 loss, 100.0% correct
E10 val_pos 0.9929 loss, 0.0% correct
分类输出保持不变–没有一个结节(也称为阳性)样本被正确识别。有趣的是,我们开始看到val_pos损失有所减少,然而,val_neg损失并没有相应增加。这意味着网络正在学习。不幸的是,它学习得非常,非常慢。
更糟糕的是,这种特定的失败模式在现实世界中是最危险的!我们希望避免将肿瘤误分类为无害的结构,因为这不会促使患者接受可能需要的评估和最终治疗。了解所有项目的误分类后果很重要,因为这可能会对您设计、训练和评估模型的方式产生很大影响。我们将在下一章中更详细地讨论这个问题。
然而,在此之前,我们需要升级我们的工具,使结果更易于理解。我们相信您和任何人一样喜欢盯着数字列,但图片价值千言。让我们绘制一些这些指标的图表。
11.9 使用 TensorBoard 绘制训练指标图表
我们将使用一个名为 TensorBoard 的工具,作为一种快速简便的方式,将我们的训练指标从训练循环中提取出来,并呈现为一些漂亮的图表。这将使我们能够跟踪这些指标的趋势,而不仅仅查看每个时代的瞬时值。当您查看可视化表示时,要知道一个值是异常值还是趋势的最新值就容易得多。
“嘿,等等”,您可能会想,“TensorBoard 不是 TensorFlow 项目的一部分吗?它在我的 PyTorch 书中做什么?”
嗯,是的,它是另一个深度学习框架的一部分,但我们的理念是“使用有效的工具”。没有理由限制自己不使用一个工具,只因为它捆绑在我们不使用的另一个项目中。PyTorch 和 TensorBoard 的开发人员都同意,因为他们合作将 TensorBoard 的官方支持添加到 PyTorch 中。TensorBoard 很棒,它有一些易于使用的 PyTorch API,让我们可以将数据从几乎任何地方连接到其中进行快速简单的显示。如果您坚持深度学习,您可能会看到(并使用)很多 TensorBoard。
实际上,如果您一直在运行本章的示例,您应该已经有一些准备好并等待显示的数据在磁盘上。让我们看看如何运行 TensorBoard,并查看它可以向我们展示什么。
11.9.1 运行 TensorBoard
默认情况下,我们的训练脚本将指标数据写入 runs/ 子目录。如果在 Bash shell 会话期间列出目录内容,您可能会看到类似于以下内容:
$ ls -lA runs/p2ch11/
total 24
drwxrwxr-x 2 elis elis 4096 Sep 15 13:22 2020-01-01_12.55.27-trn-dlwpt/ # ❶
drwxrwxr-x 2 elis elis 4096 Sep 15 13:22 2020-01-01_12.55.27-val-dlwpt/ # ❶
drwxrwxr-x 2 elis elis 4096 Sep 15 15:14 2020-01-01_13.31.23-trn-dwlpt/ # ❷
drwxrwxr-x 2 elis elis 4096 Sep 15 15:14 2020-01-01_13.31.23-val-dwlpt/ # ❷
❶ 之前的单次运行
❷ 最近的 10 次训练运行
要获取 tensorboard 程序,请安装 tensorflow (pypi.org/project/tensorflow) Python 包。由于我们实际上不会使用 TensorFlow 本身,所以如果您安装默认的仅 CPU 包也是可以的。如果您已经安装了另一个版本的 TensorBoard,那也没问题。确保适当的目录在您的路径上,或者使用 ../path/to/tensorboard --logdir runs/ 来调用它。从哪里调用它并不重要,只要您使用 --logdir 参数将其指向存储数据的位置即可。最好将数据分隔到单独的文件夹中,因为一旦进行了 10 或 20 次实验,TensorBoard 可能会变得有些难以管理。您将不得不在每个项目中决定最佳的做法。如果需要,随时移动数据也是个好主意。
现在让我们开始 TensorBoard 吧:
$ tensorboard --logdir runs/
2020-01-01 12:13:16.163044: I tensorflow/core/platform/cpu_feature_guard.cc:140]# ❶
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA 1((CO17-2))
TensorBoard 1.14.0 at http://localhost:6006/ (Press CTRL+C to quit)
❶ 这些消息可能对您来说是不同的或不存在的;这没关系。
完成后,您应该能够将浏览器指向 http://localhost:6006 并查看主仪表板。图 11.10 展示了这是什么样子。

图 11.10 主要的 TensorBoard 用户界面,显示了一对训练和验证运行
在浏览器窗口的顶部,您应该看到橙色的标题。标题的右侧有用于设置的典型小部件,一个指向 GitHub 存储库的链接等。我们现在可以忽略这些。标题的左侧有我们提供的数据类型的项目。您至少应该有以下内容:
-
标量(默认选项卡)
-
直方图
-
精确-召回曲线(显示为 PR 曲线)
您可能还会看到分布,以及图 11.10 中标量右侧的第二个 UI 选项卡。我们这里不会使用或讨论这些。确保您已经通过单击选择了标量。
左侧是一组用于显示选项的控件,以及当前存在的运行列表。如果您的数据特别嘈杂,平滑选项可能会很有用;它会使事情变得平静,这样您就可以找出整体趋势。原始的非平滑数据仍然以相同颜色的淡线的形式显示在背景中。图 11.11 展示了这一点,尽管在黑白打印时可能难以辨认。

图 11.11 带有平滑设置为 0.6 和选择了两个运行以显示的 TensorBoard 侧边栏
根据您运行训练脚本的次数,您可能有多个运行可供选择。如果呈现的运行太多,图表可能会变得过于嘈杂,所以不要犹豫在目前不感兴趣的情况下取消选择运行。
如果你想永久删除一个运行,可以在 TensorBoard 运行时从磁盘中删除数据。您可以这样做来摆脱崩溃、有错误、不收敛或太旧不再有趣的实验。运行的数量可能会增长得相当快,因此经常修剪并重命名运行或将特别有趣的运行移动到更永久的目录以避免意外删除是有帮助的。要删除train和validation运行,执行以下操作(在更改章节、日期和时间以匹配要删除的运行之后):
$ rm -rf runs/p2ch11/2020-01-01_12.02.15_*
请记住,删除运行将导致列表中后面的运行向上移动,这将导致它们被分配新的颜色。
好的,让我们来谈谈 TensorBoard 的要点:漂亮的图表!屏幕的主要部分应该填满了从收集训练和验证指标中得到的数据,如图 11.12 所示。

图 11.12 主要的 TensorBoard 数据显示区域向我们展示了我们在实际结节上的结果非常糟糕
比起E1 trn_pos 924.34 loss, 0.2% correct (3 of 1215),这样解析和吸收起来要容易得多!虽然我们将把讨论这些图表告诉我们的内容保存到第 11.10 节,现在是一个好时机确保清楚这些数字对应我们的训练程序中的内容。花点时间交叉参考你通过鼠标悬停在线条上得到的数字和训练.py 在同一训练运行期间输出的数字。你应该看到工具提示的值列和训练期间打印的值之间有直接对应关系。一旦你对 TensorBoard 显示的内容感到舒适和自信,让我们继续讨论如何让这些数字首次出现。
11.9.2 将 TensorBoard 支持添加到度量记录函数
我们将使用torch.utils.tensorboard模块以 TensorBoard 可消费的格式编写数据。这将使我们能够快速轻松地为此项目和任何其他项目编写指标。TensorBoard 支持 NumPy 数组和 PyTorch 张量的混合使用,但由于我们没有将数据放入 NumPy 数组的理由,我们将专门使用 PyTorch 张量。
我们需要做的第一件事是创建我们的SummaryWriter对象(我们从torch.utils.tensorboard导入)。我们将传入的唯一参数初始化为类似runs/p2ch11/2020-01-01_12 .55.27-trn-dlwpt的内容。我们可以在我们的训练脚本中添加一个注释参数,将dlwpt更改为更具信息性的内容;使用python -m p2ch11.training --help获取更多信息。
我们创建两个写入器,一个用于训练运行,一个用于验证运行。这些写入器将在每个时代重复使用。当SummaryWriter类被初始化时,它还会作为副作用创建log_dir目录。如果训练脚本在写入任何数据之前崩溃,这些目录将显示在 TensorBoard 中,并且可能会用空运行杂乱 UI,这在你尝试某些东西时很常见。为了避免写入太多空的垃圾运行,我们等到准备好第一次写入数据时才实例化SummaryWriter对象。这个函数从logMetrics()中调用。
列表 11.21 training.py:127,.initTensorboardWriters
def initTensorboardWriters(self):
if self.trn_writer is None:
log_dir = os.path.join('runs', self.cli_args.tb_prefix, self.time_str)
self.trn_writer = SummaryWriter(
log_dir=log_dir + '-trn_cls-' + self.cli_args.comment)
self.val_writer = SummaryWriter(
log_dir=log_dir + '-val_cls-' + self.cli_args.comment)
如果你回忆起来,第一个时代有点混乱,训练循环中的早期输出基本上是随机的。当我们保存来自第一批次的指标时,这些随机结果最终会使事情有点偏斜。从图 11.11 中可以看出,TensorBoard 具有平滑功能,可以消除趋势线上的噪音,这在一定程度上有所帮助。
另一种方法可能是在第一个 epoch 的训练数据中完全跳过指标,尽管我们的模型训练速度足够快,仍然有必要查看第一个 epoch 的结果。随意根据需要更改此行为;第 2 部分的其余部分将继续采用包括第一个嘈杂训练 epoch 的模式。
提示 如果你最终进行了许多实验,导致异常或相对快速终止训练脚本,你可能会留下许多垃圾运行,混乱了你的 runs/目录。不要害怕清理它们!
向 TensorBoard 写入标量
写入标量很简单。我们可以取出已经构建的metrics_dict,并将每个键值对传递给writer.add_scalar方法。torch.utils.tensorboard.SummaryWriter类具有add_scalar方法( mng.bz/RAqj),具有以下签名。
代码清单 11.22 PyTorch torch/utils/tensorboard/writer.py:267
def add_scalar(self, tag, scalar_value, global_step=None, walltime=None):
# ...
tag参数告诉 TensorBoard 我们要向哪个图形添加值,scalar_value参数是我们数据点的 Y 轴值。global_step参数充当 X 轴值。
请记住,我们在doTraining函数内更新了totalTrainingSamples_count变量。我们将通过将其作为global_step参数传入来将totalTrainingSamples_count用作我们 TensorBoard 图表的 X 轴。以下是我们代码中的示例。
代码清单 11.23 training.py:323,LunaTrainingApp.logMetrics
for key, value in metrics_dict.items():
writer.add_scalar(key, value, self.totalTrainingSamples_count)
请注意,我们键名中的斜杠(例如'loss/all')导致 TensorBoard 通过斜杠前的子字符串对图表进行分组。
文档建议我们应该将 epoch 数作为global_step参数传入,但这会导致一些复杂性。通过使用向网络呈现的训练样本数,我们可以做一些事情,比如改变每个 epoch 的样本数,仍然能够将未来的图形与我们现在创建的图形进行比较。如果每个 epoch 花费的时间是四倍长,那么说一个模型在一半的 epoch 中训练是没有意义的!请记住,这可能不是标准做法;然而,预计会看到各种值用于全局步骤。
11.10 为什么模型无法学习检测结节?
我们的模型显然在学习某些东西–随着 epoch 增加,损失趋势线是一致的,结果是可重复的。然而,模型正在学习的内容与我们希望它学习的内容之间存在分歧。发生了什么?让我们用一个简单的比喻来说明问题。
想象一下,一位教授给学生一份包含 100 个真/假问题的期末考试。学生可以查阅这位教授过去 30 年的考试版本,每次只有一个或两个问题的答案是 True。其他 98 或 99 个问题每次都是 False。
假设分数不是按曲线划分的,而是有一个典型的 90%正确或更高为 A 的等级刻度,便很容易获得 A+:只需将每个问题标记为 False!让我们想象今年只有一个 True 答案。像图 11.13 中左侧的学生那样毫无头绪地将每个答案标记为 False 的学生会在期末考试中得到 99%的分数,但实际上并没有证明他们学到了什么(除了如何从旧测试中临时抱佛脚)。这基本上就是我们的模型目前正在做的事情。
图 11.13 一位教授给予两名学生相同的分数,尽管知识水平不同。问题 9 是唯一一个答案为 True 的问题。
将其与右侧学生进行对比,右侧学生也回答了 99%的问题,但是通过回答两个问题为 True 来实现。直觉告诉我们,图 11.13 中右侧的学生可能比所有回答为 False 的学生更好地掌握了材料。在只有一个错误答案的情况下找到一个正确答案是相当困难的!不幸的是,我们的学生分数和我们模型的评分方案都没有反映这种直觉。
我们有一个类似的情况,99.7%的“这个候选人是结节吗?”的答案是“不是”。我们的模型正在采取简单的方式,对每个问题都回答 False。
然而,如果我们更仔细地查看模型的数字,训练集和验证集上的损失是在减少!我们在癌症检测问题上取得任何进展都应该给我们带来希望。下一章的工作将是实现这一潜力。我们将在第十二章开始时介绍一些新的相关术语,然后我们将提出一个更好的评分方案,不像我们迄今为止所做的那样容易被操纵。
11.11 结论
本章我们走了很长的路–我们现在有了一个模型和一个训练循环,并且能够使用我们在上一章中生成的数据。我们的指标不仅被记录在控制台上,还以图形方式呈现。
虽然我们的结果还不能使用,但实际上我们比看起来更接近。在第十二章中,我们将改进用于跟踪进度的指标,并利用它们来指导我们需要做出的改变,以使我们的模型产生合理的结果。
11.12 练习
-
实现一个程序,通过将
LunaDataset实例包装在DataLoader实例中来迭代,同时计时完成此操作所需的时间。将这些时间与第十章练习中的时间进行比较。在运行脚本时要注意缓存的状态。-
将
num_workers=...设置为 0、1 和 2 会产生什么影响? -
在给定
batch_size=...和num_workers=...组合下,您的机器支持的最高值是多少,而不会耗尽内存?
-
-
颠倒
noduleInfo_list的排序顺序。在训练一个周期后,模型的行为会如何改变? -
将
logMetrics更改为修改在 TensorBoard 中使用的运行和键的命名方案。-
尝试不同的斜杠放置方式,将键传递给
writer.add_scalar。 -
让训练和验证运行使用相同的写入器,并在键的名称中添加
trn或val字符串。 -
自定义日志目录和键的命名以适应您的口味。
-
11.13 总结
-
数据加载器可以在多个进程中从任意数据集加载数据。这使得否则空闲的 CPU 资源可以用于准备数据以供 GPU 使用。
-
数据加载器从数据集中加载多个样本并将它们整理成一个批次。PyTorch 模型期望处理数据批次,而不是单个样本。
-
数据加载器可以通过改变个别样本的相对频率来操作任意数据集。这允许对数据集进行“售后”调整,尽管直接更改数据集实现可能更合理。
-
我们将在第二部分中使用 PyTorch 的
torch.optim.SGD(随机梯度下降)优化器,学习率为 0.001,动量为 0.99。这些值也是许多深度学习项目的合理默认值。 -
我们用于分类的初始模型将与第八章中使用的模型非常相似。这让我们可以开始使用一个我们有理由相信会有效的模型。如果我们认为模型设计是阻止项目表现更好的原因,我们可以重新审视模型设计。
-
训练过程中监控的指标选择很重要。很容易不小心选择那些对模型表现误导性的指标。使用样本分类正确的整体百分比对我们的数据没有用处。第十二章将详细介绍如何评估和选择更好的指标。
-
TensorBoard 可以用来直观显示各种指标。这使得消化某些形式的信息(特别是趋势数据)在每个训练周期中发生变化时更容易。
¹ 任何 shell 都可以,但如果你使用的是非 Bash shell,你已经知道这一点。
² 请记住,尽管是 2D 图,但我们实际上是在 3D 中工作。
³ 这就是为什么下一章有一个练习来尝试两者的原因!
⁴ 这样做有数值稳定性的好处。通过使用 32 位浮点数计算的指数来准确传播梯度可能会有问题。
⁵ 如果在法国吃晚餐不涉及机场,可以随意用“Texas 的巴黎”来制造笑话;en.wikipedia.org/wiki/Paris_(disambiguation)。
⁶ 如果你在不同的计算机上运行训练,你需要用适当的主机名或 IP 地址替换localhost。