go 语言中 map 比较的说,和 slice 有什么区别?如果 map 是从 int 到 int 类型的话,差别还真不大。map 的 key 退化为 slice 的下标,而 value 退化为 slice 的值。
但这样也存在很大的弊端:空间浪费严重。假设 map 中只有 2 个元素,key 值分别是0、1000,用 slice 表示的话,[1, 999] 的空间都被浪费掉了。
按照 slice 的思维,继续把 map 推广到 string 到 string 的类型,将 map 中 key 表示的 string 进行 hash 函数处理为数值类型,作为 slice 的下标。但运行 hash 将 string 转换为 int 的方式,引入了另一个问题:hash 冲突。
map 的 key 是可以唯一表示的任意值,但 key 经过 hash 函数处理之后的数值却不是 1:1 的唯一关系,不同的 key 经过 hash 处理之后可能会得到相同的结果。
带着这些问题,我们来思考 go 语言中 map 的源码实现。对 go 有一点了解的,都应该知道 map 底层使用 bucket 做实际数据存储。这算的上一个 sharding 策略,通过对 key 做 hash 运算、和 bucket 做取余,来确定 key 应该属于哪一个 bucket。
这个比较好理解,假设我们提前创建了 5 个 bucket,最终所有的值都应该被分配到这 5 个 bucket 上,取余是常规的操作策略。
通过下图 473 行的变量 b 可以得出,map 初始分配的 bucket 是一整块连续的内存。 h.buckets 作为内存的首地址,加上间隔的内存空间,得出 b 的首地址。这种通过加减法来计算内存地址的方式,在底层会比较常见。

用来记录 sharding 信息的结构体是 hmap,包含了 sharding 相关的信息,从上面的角度来看,主要包含 hash 的散列函数以及底层 bucket 的数量。对应的 bmap 实际存储 bucket 的元信息。从 hmap 和 bmap 的命名上可以推断出 header 和 body 的关系。如果工作上需要设置一种 sharding 的存储,可能是为了降低加锁的开销,也同样需要 2 个数据结构来组合使用。
每个 bucket 最多可容纳 8 组键值对,而 hmap 中确定的 bucket 数量是固定的,或者说在一段时间内,bucket 的数量是固定的。我们对 key 做 hash 之后,如果发现大于 8 个以上的不同 key 同时命中其中的一个 bucket 怎么处理呢?
这里主要在于 hash 冲突的解决方案,go 中采用链表法来解决冲突。按照我们传统的 map 策略,会在表示键值对元素的结构体上存储链表的指针。大概就是下面图示的意思,键值 2008 和 2001 经过 hash 运算之后值都为 1,所以接了一个链表节点。
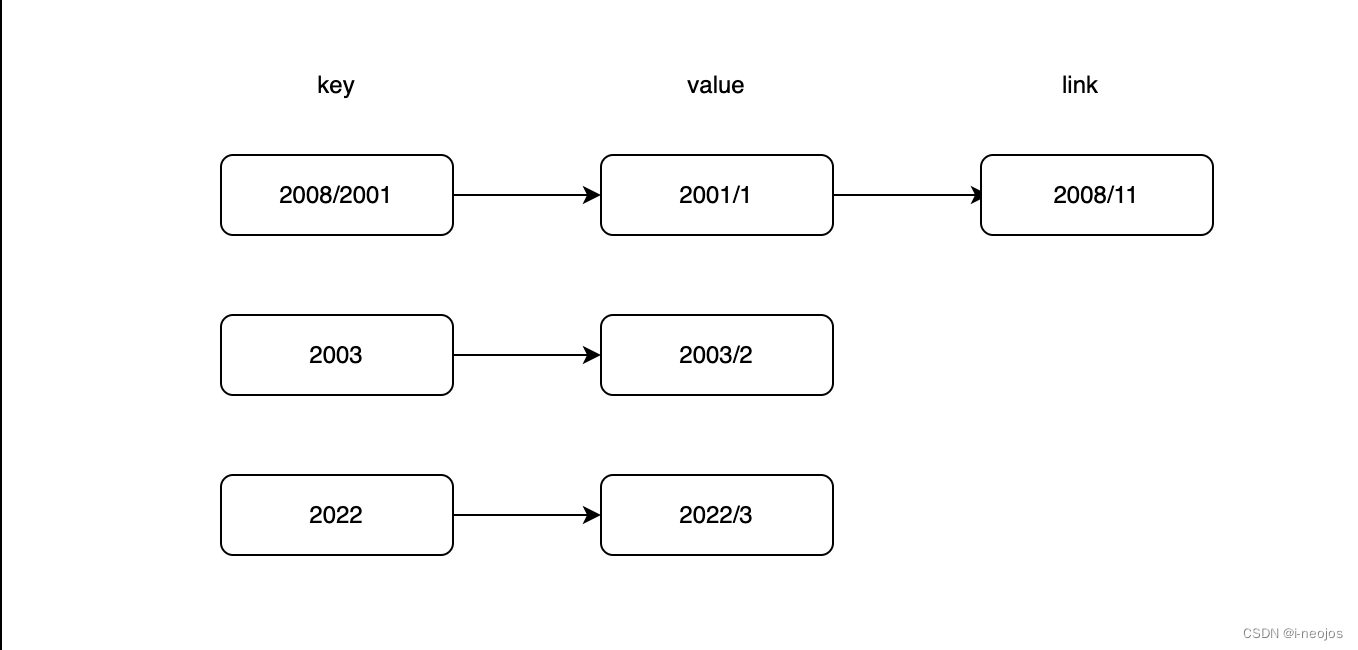
通过拉链的方式,其实还支持了数据可以无限插入的能力。hmap 中关联到的 bucket 数量是有限的,假设 hmap 中包含有 7 个 bucket,那最多也就容纳 56(7*8)个元素。如果再继续加入新的键值对,就需要通过拉链的方式,扩展 bmap 中的链表。
源码 go1.16.6/src/runtime/map.go:426 中 mapaccess1 给了我们一些启示,我们是如何联合 hmap 和 bmap 查询到键值的。既然是 2 层结构,那肯定是首先通过 hmap 计算出 key 所在的 bucket,然后再通过 bmap 查询具体的 key。
上面的描述,针对 bucket 和 bmap 在连贯性上可能会产生些误会,但其实这两个名字值得其实是同一个类型。所以,bmap 中的首字母 b 到底应该是 body 的含义,还是 bucket 的含义,有待商榷。
第一步,计算 key 所在的 bucket ,代码中的局部变量 b 是通过指针运算计算出来的,表达式 hash&m 确定 key 所在第几个块位置(内存块的尺寸等于 t.bucketsize)。
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
在表达式 if 中有变量 b 的覆写逻辑,条件是 h.oldbuckets 存在
第二步,在 bucket 中查找元素