概述
通过本文,您将学会如何利用 Streamlit 框架快速搭建前端交互界面。该界面将集成图像上传功能,让用户可以方便地提交待处理图片。在后端,我们将借助 Amazon Bedrock 的 Message API,调用 Claude 3 家族中的 Sonnet 模型对图像进行理解和分析。
界面设计还将包含一个聊天窗口,实现人机对话交互。用户可以在此窗口中,基于上传图像提出连续性问题,例如询问图像中元素的性质、场景等详情。值得一提的是,我们将记录历史对话上下文,作为后续问答的参考依据。这一机制确保了对话的连贯性和一致性。
本文将为您一步步讲解实现过程,包括 Streamlit 界面设计、Amazon Bedrock API 集成,以及 Sonnet 模型调用等关键环节。我们还将分享一些实践中的经验和技巧,帮助您进一步提升应用质量和交互体验。
关于 Claude 3
Claude 3 是由 Anthropic 公司开发的一套大型人工智能语言模型。作为 Claude 家族的最新成员,它在自然语言处理、推理和生成等多个领域具有卓越能力。

Claude 3 的核心优势包括:
强大的多模态能力 – 可同时处理文本、图像、视频等不同模态的输入,在多模态任务上表现出色。
高质量的输出 – 生成的文本内容通顺流畅,语义准确,减少了幻觉性错误。
稳健的推理能力 – 能够有效理解和推理复杂的逻辑关系,完成多步推理任务。
广泛的知识涵盖范围 – 涉及科学、历史、艺术、法律等多个领域的知识。
集成了视觉模型 Sonnet – 赋予了出色的图像理解、分析和生成能力。
强调 AI 伦理和安全 – Claude 3 在设计时注重 AI 系统的安全性和道德操守。
总的来说,Claude 3 凭借强大的自然语言处理、推理和多模态能力,可广泛应用于问答系统、智能写作、内容创作、视觉辅助等多个领域,为人类带来高效智能的 AI 助手体验。

Let’s build
前置条件:开通服务
在进入 Amazon Bedrock 服务后,需要以下几个步骤:
在侧边栏点击“模型访问权限”
在右上角点击“管理模型访问权限”
点击“提交应用场景详细信息”
在 Anthropic 下找到 Claude 3 Sonnet 模型,并在前面打勾
最后在右下角点击“保存更改”
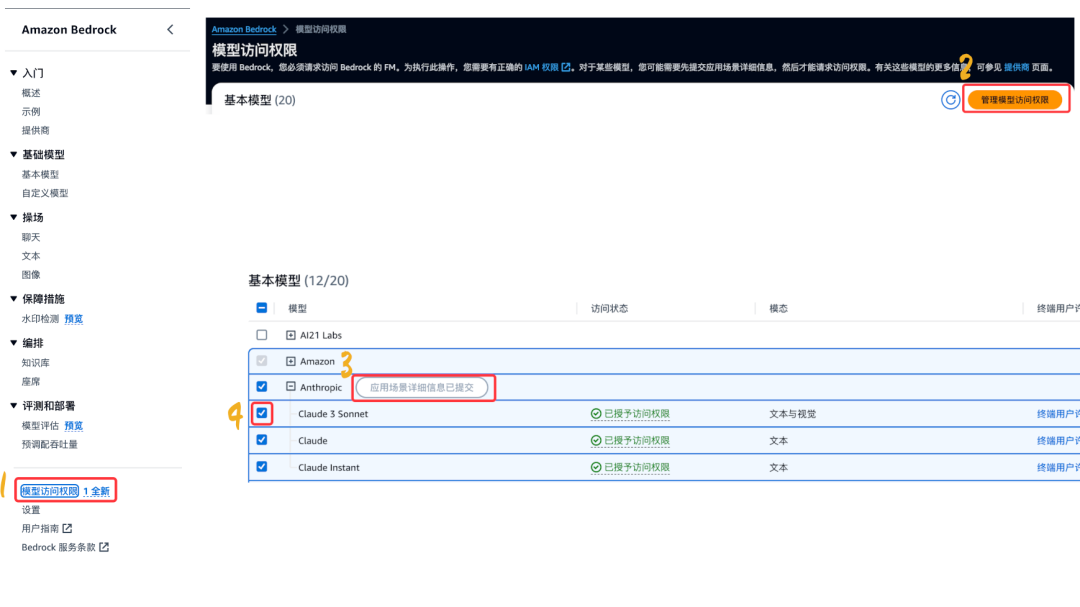
开通后,我们可以看到模型后面的访问状态,已经是处于“已授予访问权限”。
在本地配置访问权限
通过 IAM User 的 AK/SK 获取后,使用 aws-cli 命令行工具配置,您在本地程序访问亚马逊云科技服务的权限。
aws configure由于访问权限的配置不是本文的重点,因此可以直接参考此文档:
使用 IAM 用户凭证进行身份验证
https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/cli-authentication-user.html
Show Me The Code
在我们接下来的项目开发过程中,需要用到的主要框架包括亚马逊云科技提供的 Python SDK boto3,以及用于构建数据应用的流行开源框架 Streamlit。
boto3
boto3 是亚马逊云科技官方推出的 Python SDK,它提供了一组友好的面向对象的 API,使 Python 开发人员能够轻松地与亚马逊云科技的各种服务进行交互和操作。无论是启动 Amazon EC2 实例、部署 Amazon Lambda 函数,还是操作 Amazon S3 存储桶、Amazon DynamoDB 数据库等,boto3 都提供了相应的接口。它极大地简化了亚马逊云科技资源的管理和开发,是进行亚马逊云科技云端开发的利器。
Streamlit
Streamlit 则是一个用 Python 构建的开源框架,旨在让数据科学家以最简单、最高效的方式创建丰富的数据应用程序和交互式数据产品。它支持多种数据类型和数据源的渲染,如 DataFrame、图像、视频等,并允许用户以 Python 脚本的形式编写界面逻辑。Streamlit 的响应式布局、缓存机制等特性使其构建可视化分析和数据产品的体验非常流畅。
总的来说,boto3 帮助我们高效操作亚马逊云科技资源,而 Streamlit 则为构建数据应用提供了极佳的支持。两者结合将大大加快我们的开发效率。
关键代码解析
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name=REGION,
)
model_id = 'anthropic.claude-3-sonnet-20240229-v1:0'
response = bedrock_runtime.invoke_model(
body=body, modelId=model_id)
response_body = json.loads(response.get('body').read())通过 boto3 我们可以轻松创建 bedrock-runtime 的客户端,然后通过这个客户端的 invoke_model 来调用 Claude 模型。其中 modelId 就是 Claude 3 的模型。
接下来对 request 中需要传入的 body 进行代码展示:
message = {"role": "user",
"content": [
{"type": "text", "text": input_text}
]}
if not has_history():
message["content"].append({"type": "image",
"source": {"type": "base64",
"media_type": "image/jpeg",
"data": content_image}})
messages = []
# Get History Messages
if has_history():
messages.extend(get_chat_history())
messages.append(message)
system_input = """
You are Claude, an AI assistant created by Anthropic to be helpful,harmless, and honest.
Your goal is to provide informative and substantive responses to queries while avoiding potential harms.
You should answer the questions in the same language with user input text.
"""
body = json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"system": system_input,
"messages": messages
}
)body 中有 4 个关键参数:
anthropic_version 目前只能填写 bedrock-2023-05-31 ,未来随着模型的迭代应该会有更多可选参数。
max_tokens 是 tokens 最大值的限制,这里是指 input 和 output 的累加值。在新的 Message API 中,每次消耗的 input tokens 和 output tokens 都会在返回值中明确给出。
system 是用来设定 Claude 的“人设”,我们在这里需要设置一些符合我们输出预期的风格,告诉模型即将处理的任务目标,这样可以提高模型针对特定领域问题回答的精度。
messages 是一个包含了角色(role)、信息类型(type)和值(source 或 text)的一个 json 字段。在这个 json 字段中,我们可以提交多个图片和一段文本信息。图片由 base 编码的字符串作为数据传入,目前支持 jpg、png、gif 和 webp 四种格式。历史的聊天记录也会存储在这个字段里面。
在这个样例代码中,我使用了 st.session 来存储会话的上下文信息。
def save_chat_history_message(history: list):
st.session_state['history'] = history
def has_history():
return 'history' in st.session_state
def show_chat_history():
if 'history' not in st.session_state:
return
for msg in st.session_state['history']:
if 'content' not in msg:
continue
if type(msg['content']) is list:
for item in msg['content']:
if item['type'] == "text":
st.chat_message(name=msg['role']).write(item['text'])
elif item['type'] == "image":
continue
else:
st.chat_message(name=msg['role']).write(msg['content'])
def get_chat_history():
if not has_history():
return []
return st.session_state['history']
def clear_chat_history_message():
if 'history' in st.session_state:
del st.session_state['history']而历史的聊天记录,我们则需要插入到用户的输入信息中。历史记录将插入到 messages 中。
# Get History Messages
if has_history():
messages.extend(get_chat_history())由于 streamlit 每次都是根据代码的顺序去重新渲染界面的,所以我们还需要每次问答的文本记录起来,并且在下一次渲染界面的时候全部重绘。所以 show_chat_history() 这个函数会在每次获得文本输出后,先调用一次。
def show_chat_history():
if 'history' not in st.session_state:
return
for msg in st.session_state['history']:
if 'input' in msg:
st.chat_message(name='user').write(msg['input'])
if 'output' in msg:
st.chat_message(name='ai').write(msg['output'])运行测试
运行代码前准备好 python 环境,我测试的是 python3.11 版本,理论上其他版本应该也能运行。
安装依赖包
pip install boto3 streamlit完整代码
以下是完整代码,新建一个 app.py 的文件。复制粘贴全部代码到 app.py 中。其中 region 字段可以根据实际情况进行配置,这里选择的是 us-west-2 ,需要配置成您在 Amazon Bedrock 中实际开通模型访问的区域。
import base64
import json
import logging
import boto3
import streamlit as st
from botocore.exceptions import ClientError
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.DEBUG)
st.sidebar.title("Building with Bedrock") # Title of the application
st.sidebar.subheader("Q&A for the uploaded image")
REGION = "us-west-2"
def save_chat_history_message(history: list):
st.session_state['history'] = history
def has_history():
return 'history' in st.session_state
def show_chat_history():
if 'history' not in st.session_state:
return
for msg in st.session_state['history']:
if 'content' not in msg:
continue
if type(msg['content']) is list:
for item in msg['content']:
if item['type'] == "text":
st.chat_message(name=msg['role']).write(item['text'])
elif item['type'] == "image":
continue
else:
st.chat_message(name=msg['role']).write(msg['content'])
def get_chat_history():
if not has_history():
return []
return st.session_state['history']
def clear_chat_history_message():
if 'history' in st.session_state:
del st.session_state['history']
def run_multi_modal_prompt(bedrock_runtime, model_id, messages, max_tokens):
"""
Invokes a model with a multimodal prompt.
Args:
bedrock_runtime: The Amazon Bedrock boto3 client.
model_id (str): The model ID to use.
messages (JSON): The messages to send to the model.
max_tokens (int): The maximum number of tokens to generate.
Returns:
None.
"""
system_input = """
You are Claude, an AI assistant created by Anthropic to be helpful,harmless, and honest.
Your goal is to provide informative and substantive responses to queries while avoiding potential harms.
You should answer the questions in the same language with user input text.
"""
body = json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"system": system_input,
"messages": messages
}
)
response = bedrock_runtime.invoke_model(
body=body, modelId=model_id)
response_body = json.loads(response.get('body').read())
return response_body
def main():
"""
Entrypoint for Anthropic Claude multimodal prompt example.
"""
try:
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name=REGION,
)
model_id = 'anthropic.claude-3-sonnet-20240229-v1:0'
max_tokens = 4096
st.sidebar.header("What image would you like to analyst?")
uploaded_file = st.sidebar.file_uploader("Upload an image",
type=['jpg', 'jpeg', 'png', 'gif', 'webp'],
on_change=clear_chat_history_message)
content_image = None
if uploaded_file:
st.sidebar.image(uploaded_file)
content_image = base64.b64encode(uploaded_file.read()).decode('utf8')
# Read reference image from file and encode as base64 strings.
input_text = st.chat_input(placeholder="What do you want to know?")
if content_image:
if input_text:
show_chat_history()
st.chat_message(name='user').write(input_text)
message = {"role": "user",
"content": [
{"type": "text", "text": input_text}
]}
if not has_history():
message["content"].append({"type": "image",
"source": {"type": "base64",
"media_type": "image/jpeg",
"data": content_image}})
messages = []
# Get History Messages
if has_history():
messages.extend(get_chat_history())
messages.append(message)
with st.spinner('I am thinking about this...'):
response = run_multi_modal_prompt(bedrock_runtime, model_id, messages, max_tokens)
st.chat_message(name='assistant').write(response.get("content")[0].get("text"))
messages.append({
"role": "assistant",
"content": response.get("content")[0].get("text")
})
save_chat_history_message(messages)
logger.debug(json.dumps(response, indent=4))
except ClientError as err:
message = err.response["Error"]["Message"]
logger.error("A client error occurred: %s", message)
if __name__ == "__main__":
main()运行
在命令行模式下,使用 streamlit run app.py 来运行。
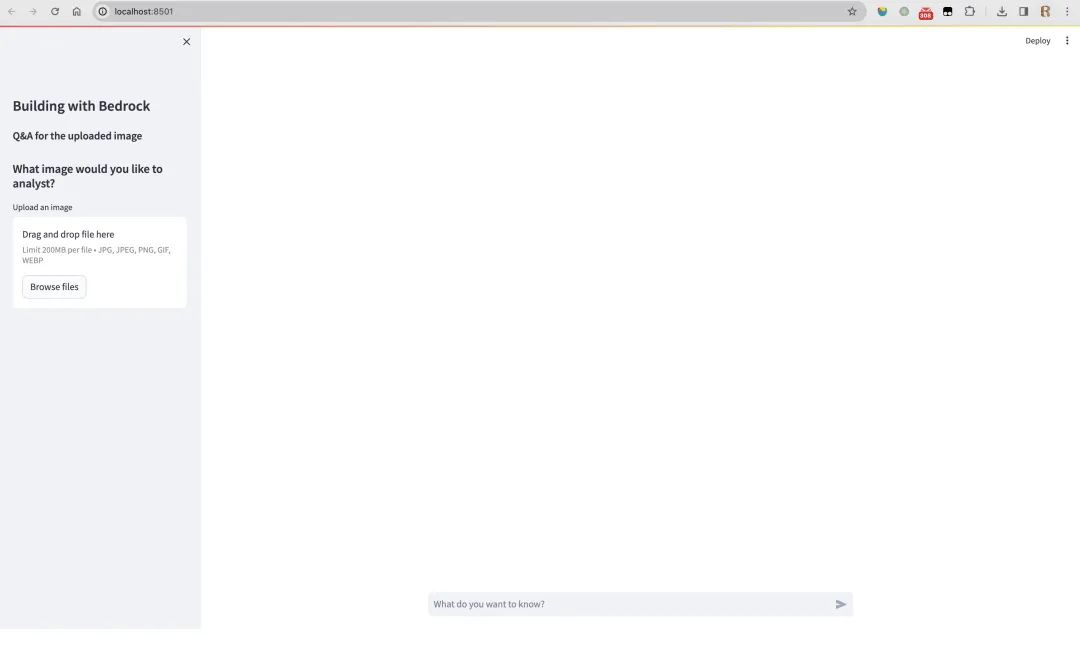
应用会在本地启动一个 8501 端口,并且自动在浏览器中打开应用。
界面中,侧边栏包含一个可以上传图片的组件,右边则是一个聊天窗口。
测试
初体验——看图计算
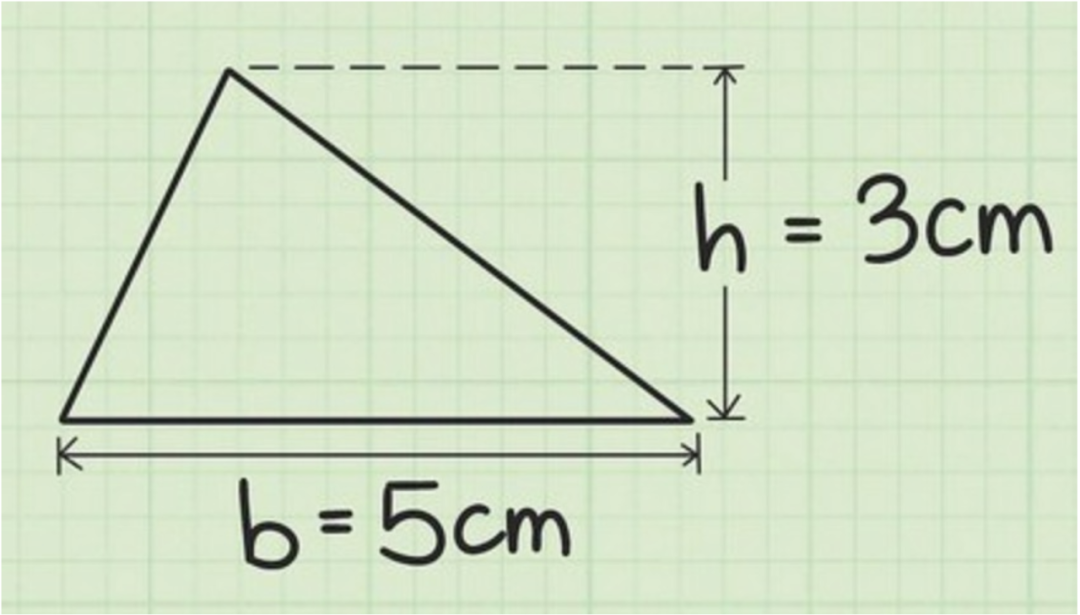
我们上传一张描述三角形的图片,并输入 计算它的面积 ,让大语言模型计算它的面积。
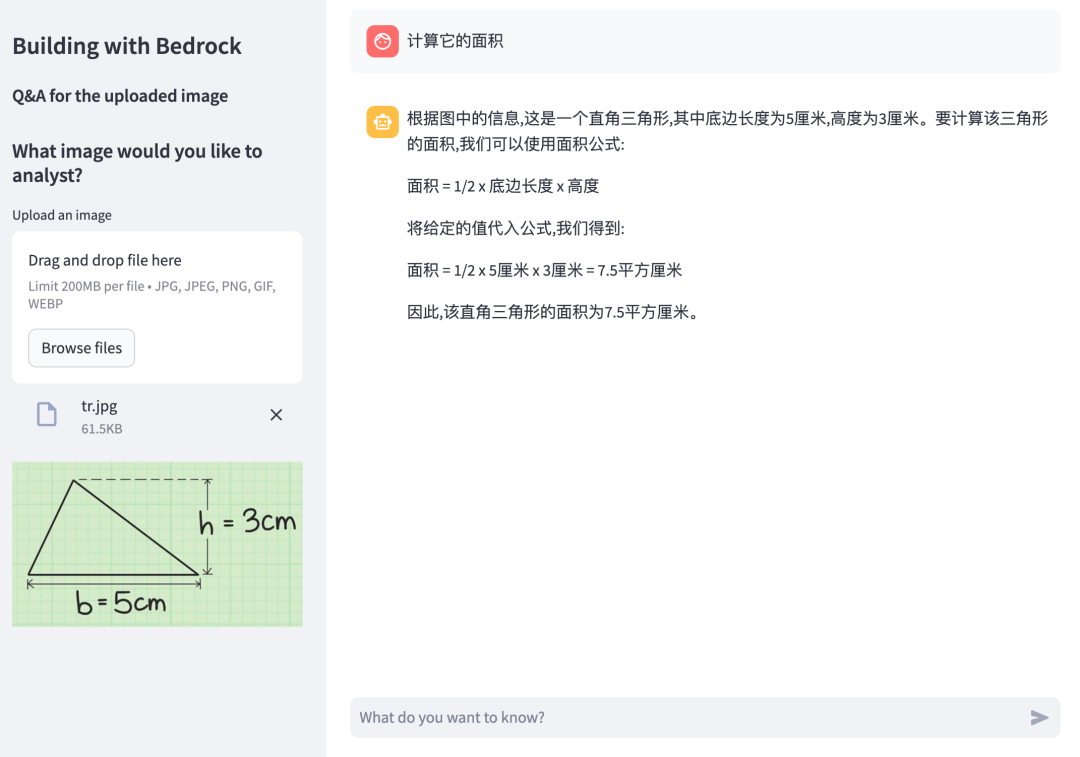
我们可以看到 Claude 3 已经识别到这是一个三角形,并且准确的获取来三角形的“底”和“高”,并通过面积公式来计算出了这个三角形的面积。
再体验——上下文记忆
我们输入 假设它的高是 4cm 呢? ,看看应用是否能够获取上下文并理解当前设定。依然能正确给出答案。
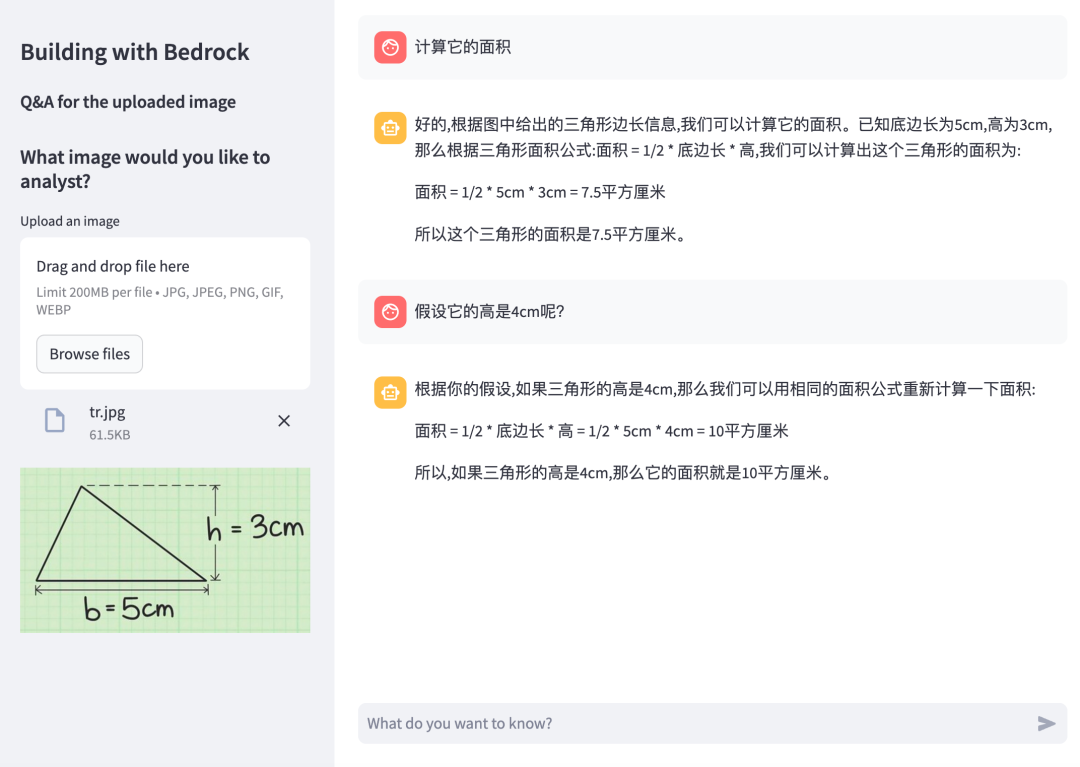
我们看到了答案,结果依然计算正确,说明这个应用能够正确理解上下文。虽然在第二个问题中,我们并没有明确说是计算面积,但是通过上图的回答,依然可以获得我们想要的答案。
总结
在 Claude 3 支持的多模态场景下,我们尝试了让模型去理解一个数学问题,并根据图片内容计算相关结果。除此之外,Claude 3 在归因、文本理解、多语言等方面相对 Claude 2 都有大幅度的性能提升。您可以根据本文提供的样例代码,构建您自己专属的 AI Bot。甚至您还可以尝试使用 Agents for Amazon Bedrock 来整合工作流,以构建更加专注于某个领域的智能体。
参考链接
Anthropic Claude Messages API – Amazon Bedrock
https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-anthropic-claude-messages.html
streamlit.io
https://streamlit.io/
AgentsforBedrockRuntime – Boto3 1.34.58 documentation
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/bedrock-agent-runtime.html
使用 IAM 用户凭证进行身份验证
https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/cli-authentication-user.html
您仍然可以继续领略 Amazon Bedrock 上包括 Mistral, llama2 等领先的基础模型的魅力,对于 Amazon Bedrock 上的 Claude 3 模型,如果您的业务有出海需求,可以由您的海外关联公司在海外访问亚马逊云科技海外区域提供的相关模型,感受先进技术带来的无限可能,感谢您的支持与理解!
本篇作者

林业
亚马逊云科技资深解决方案架构师,负责基于亚马逊云科技的云计算方案的咨询与架构设计。拥有超过 14 年研发经验,曾打造千万级用户 APP,多项 Github 开源项目贡献者。在游戏、IoT、智慧城市、汽车、电商等多个领域都拥有丰富的实践经验。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!




![[C++]20:unorderedset和unorderedmap结构和封装。](https://img-blog.csdnimg.cn/direct/81314f944e3a4c28b50041b67fb0ce8d.gif)

![[STM32] Keil MDK 新建工程编译不通过(warning: #2803-D和Error: L6218E)解决方法备忘](https://img-blog.csdnimg.cn/direct/bd42bb115f0746bf82a1372db0c3bd76.png#pic_center)