Python 文件处理是一个核心编程概念,涉及到文件的读取、写入、创建、删除以及管理文件路径等操作,让我们循序渐进的一起探究吧
目录
一、open()函数
1、打开文件
2、读取文件
使用 .read() 方法
使用 .readline() 方法
使用 .readlines() 方法
3、写入文件
4、文件关闭
5、使用with语句自动关闭文件
总结:
二、os模块和pathlib模块
理解文件路径
1. 文件读写
2. 路径创建与管理
3. 遍历目录树
4. 获取路径信息
5. 组合与解析路径
6. 存在性检查
7. 其他应用场景举例
总结:
一、open()函数
在Python中,使用内置的open()函数打开一个文件,并返回文件对象。在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。该函数接受两个主要参数:文件名包括路径(file)和模式(mode)。
1、打开文件
完整的语法格式如下
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode 参数可以是以下几种:
'r':读取模式,用于打开现有文件以读取数据。
'w':写入模式,用于打开文件进行写入,如果文件已存在则会被覆盖。
'a':追加模式,在文件末尾添加内容,不会覆盖原有内容。
'x':创建模式,只在文件不存在时创建新文件并打开。
't'(默认):文本模式,适用于普通文本文件。
'b':二进制模式,适用于非文本文件如图片、音频或视频文件。基于这几个字母组成的多重结果wb wt rb rt rt wb+ wt+ rb+ rt+
没有+号只能读取或写入,有+可以同时读取写入
简单示例
# 打开文本文件以读取
file_read = open('example.txt', 'r')
# 打开文本文件以写入(会清空原文件内容)
file_write = open('output.txt', 'w')
# 在文本文件末尾追加内容
file_append = open('log.txt', 'a')2、读取文件
使用 .read() 方法
一次性读取整个文件内容到字符串中:
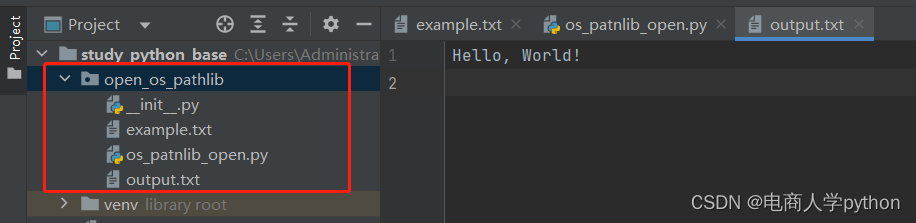
当被读取文件跟代码.py文件在同一文件夹目录下,可以直接写file参数为文件名(全称包含文件类型)
file = open('output.txt', 'r+' , encoding='utf-8')
read_content=file.read()
print(read_content)#输出文件内容: Hello World!使用 .readline() 方法
逐行读取: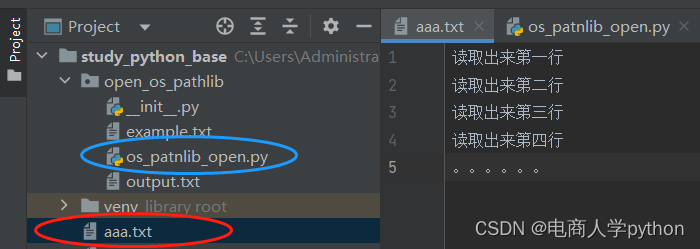
如果是跨目录读取则需写file参数为 路径+文件名。
file1=open(r'C:\Users\Administrator\PycharmProjects\study_python_base\aaa.txt', 'r+' , encoding='utf-8')
read_line1=file1.readline() # 每次调用获取一行
print(read_line1)
read_line2=file1.readline()
print(read_line2)
'''控制台输出:
读取出来第一行
读取出来第二行
'''使用 .readlines() 方法
返回包含所有行的列表:
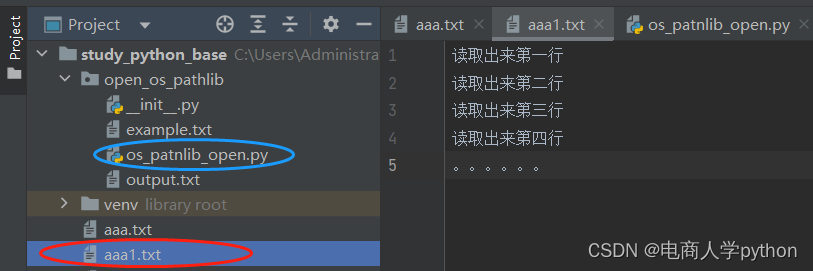
也可以用绝对路径
file2=open(r'..\aaa1.txt', 'r+' , encoding='utf-8')
read_lines=file2.readlines()
print(read_lines)
#输出:['读取出来第一行\n', '读取出来第二行\n', '读取出来第三行\n', '读取出来第四行\n', '。。。。。。']3、写入文件
使用 .write() 方法将字符串内容写入文件:
file=open('output.txt','w+', encoding='utf-8')
file.write('Hello World!\n')
file.write('写入字符串')
print(file.read())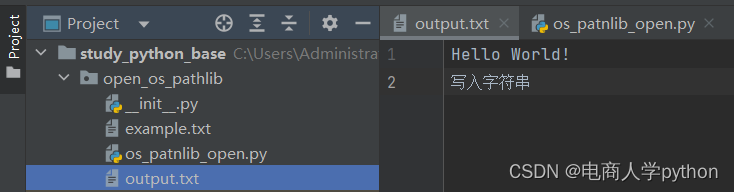
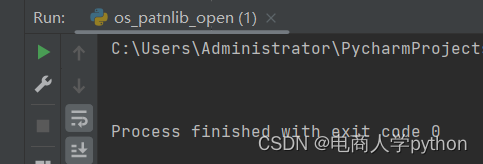
我们会发现output.txt文件里已经写入了内容,但是读取时控制台没有输出内容,我们继续往下走。
4、文件关闭
操作完文件后,务必使用 .close() 方法关闭文件以释放系统资源,并确保数据被正确保存:
file=open('output.txt','w+', encoding='utf-8')
file.write('Hello World!\n')
file.write('写入字符串')
file.close()
print('写入成功!\n\n')
file=open('output.txt','r+', encoding='utf-8')
print(file.read())
使用.close()方法将文件关闭后,再重新打开文件读取,我们发现这时写入的数据才真正得以保存,能够被读取出来。
5、使用with语句自动关闭文件
推荐使用 with 语句来处理文件,这样当离开 with 块时,Python会自动关闭文件,即使发生异常也能保证文件最终会被关闭:
with open('output.txt','w+',encoding='utf-8') as file:
for i in ['Hello World!\n','yes or no']:
file.write(i)
file_r=open('output.txt','r+',encoding='utf-8')
print(file_r.read())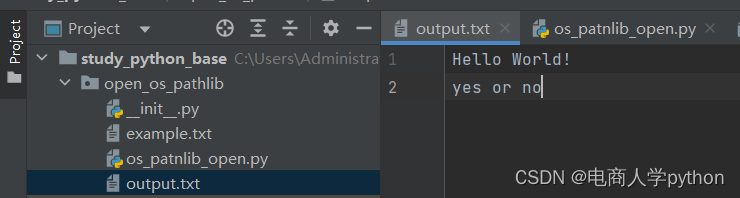
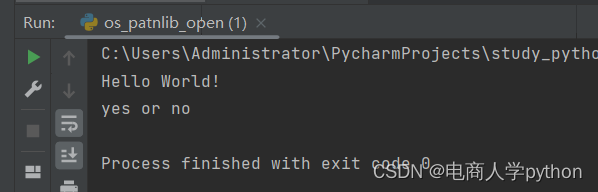
总结:
Python 的 open() 函数可以打开各种类型的文件,包括但不限于以下几种:
- 1、文本文件(.txt, .csv, .json, .ini, .py 等):这些文件通常以文本形式存储数据,可以用 'r' 读取模式、 'w' 写入模式、 'a' 追加模式等进行操作。
- 2、二进制文件(.jpg, .png, .mp3, .exe, .dll 等):对于非文本格式的文件,比如图片、音频、视频或可执行程序,需要使用 'rb' 读取模式或 'wb' 写入模式来处理二进制数据。
- 3、数据库文件(如SQLite数据库.db文件):虽然不直接打开为文本或二进制流,但可以通过 'rb' 或 'wb' 模式对它们进行读写,并结合特定的数据库API(如sqlite3模块)来进行操作。
- 4、配置文件(.conf, .xml, .yml, .toml 等):这些特殊格式的文本文件也可以通过 open() 函数读取,然后用适当的解析器处理其内容。
- 5、ZIP压缩包、日志文件、XML/HTML文件等各种特殊格式的文件,只要在合适的上下文中使用适当的方式,都可以通过 open() 函数配合其他库进行读取或写入。
需要注意的是,尽管 open() 函数可以用于打开任何文件,针对某些复杂或特定格式的文件(如数据库、压缩包、XML/HTML等),可能需要配合额外的库或函数来正确地解析或写入数据、实现更深入的操作。例如,读取CSV文件时,可以搭配 csv 模块;读取JSON文件时,则可以使用 json 模块等。对于数据库操作,我们会使用
sqlite3库来与SQLite数据库交互;对于ZIP压缩包,会用zipfile模块进行读写;而对于XML/HTML文件,可能要借助xml.etree.ElementTree或BeautifulSoup等库进行解析。所以,可以说在处理不同类型的文件时,
open()方法是一个起点,而具体如何有效利用这些数据,则取决于所使用的其他相关库的功能。
二、os模块和pathlib模块
Python 中的 os 模块和 pathlib 模块在处理文件路径和进行文件系统操作时有着不同的设计思路与使用方法。下面是一个对比表格,展示了两者在主要功能上的异同:
| 功能/模块 | os模块 | pathlib模块 |
|---|---|---|
| 初始化路径 | 使用字符串表示路径 | 使用 Path 类实例表示路径 |
| 创建路径对象 | 无直接创建路径类的对象 | Path('path/to/file') 或 Path.cwd()(当前工作目录) |
| 路径拼接 | 需要使用 os.path.join() 函数 | 可以通过 / 运算符组合路径:Path('dir') / 'file.txt' |
| 获取绝对路径 | os.path.abspath(path) | Path(path).resolve() |
| 检查路径存在性 | os.path.exists(path)、os.path.isfile()、os.path.isdir() | Path(path).exists(), Path(path).is_file(), Path(path).is_dir() |
| 读取文件内容 | 打开文件并调用 .read() 方法 | Path(path).read_text() (文本) 或 Path(path).read_bytes() (二进制) |
| 写入文件内容 | 打开文件并调用 .write() 方法 | Path(path).write_text(text) (文本) 或 Path(path).write_bytes(data) (二进制) |
| 遍历目录 | 使用 os.listdir(directory),进一步处理需要循环 | 使用 Path(directory).iterdir() 迭代器 |
| 递归遍历 | 自己实现递归或结合 os.walk() 函数 | 使用 Path(directory).rglob(pattern) 根据 glob 模式递归查找 |
| 创建/删除文件/目录 | os.mkdir(path, mode=0o777)、os.remove(path)、os.rmdir(path) | Path(path).mkdir(mode=0o777, parents=True, exist_ok=True)、Path(path).unlink()、Path(path).rmdir() |
| 重命名或移动文件 | os.rename(old_path, new_path) | Path(old_path).rename(new_path) |
| 查询路径信息 | os.path.basename(), os.path.dirname(), os.path.splitext() 等函数 | Path(path).name, Path(path).stem, Path(path).suffix, Path(path).parent 等属性 |
总结:
os 模块提供了底层的操作系统接口,其函数基于字符串操作,对于熟悉Unix/Linux命令行的人来说可能更为直观。
pathlib 模块是面向对象的,它提供了一个名为 Path 的类,使路径操作更具有可读性和便捷性,尤其适合编写跨平台代码且对类型安全性要求较高的场景。
因此,在现代Python编程实践中,除非有特殊需求或兼容旧版Python版本,一般推荐使用 pathlib 来进行文件路径和文件系统的操作。
在这篇文章我们就主要来聊一聊pathlib:
pathlib 模块是一个内置的标准库,自 Python 3.4 版本起引入,它为文件系统路径提供了面向对象的处理方式。相比于传统的 os 和 os.path 模块中的字符串操作,pathlib.Path 类提供了一种更安全、易用且跨平台的方法来创建、操作和遍历文件系统路径。
理解文件路径
我们先理解一下什么是文件路径
路径=文件的位置+文件的名字
1、绝对路径:
操作系统中获取,以盘符开头,带有文件夹名字、文件的名字(包含文件类型,如a.txt、xxx.py等),完整的路径。
pycharm右键->copy path->absolute path
2、相对路径:
相对谁:当前工作目录(cwd),cwd是一个变量
相对路径下,文件的路径=变量+文件名(包含文件类型,如a.txt、xxx.py等)
路径中某些符号,有特殊含义
./本级目录
../上级目录
./ 和 ../可以无限循环使用
path_1 = Path("../aaa.py")
path_2 = Path("../../../aaa.py")
path_3 = Path("../../.././aaa.py")
接下来直接来看看关于pathlib模块的场景应用
1. 文件读写
在读取或写入文本文件时,可以直接通过 .read_text() 和 .write_text() 方法来完成
from pathlib import Path
# 写入文本文件
file_path = Path("newfile.txt") #如果该文件不存在,会在当前目录创建newfile.txt文件
file_path.write_text("Hello, World!")
# 读取文本文件
content = file_path.read_text()
print(content) # 输出:Hello, World!2. 路径创建与管理
创建、删除、重命名文件或目录
from pathlib import Path
path = Path("new_directory")
path.mkdir() # 创建目录,当文件已存在时,无法创建该文件。
# 安全创建目录(即使已存在也不会报错)
safe_create_path = Path("existing_or_not")
safe_create_path.mkdir(exist_ok=True)
(path / "file.txt").touch() # 创建文件
(path / "file.txt").unlink() # 删除文件
path.rmdir() if path.is_dir() else path.unlink() # 删除空目录或文件
path.rename(Path("renamed_directory")) # 重命名目录3. 遍历目录树
递归遍历目录下的所有文件:
from pathlib import Path
for child in Path(".").rglob("*"):
print(child)
a=Path('.').iterdir()
for i in a:
print(i)4. 获取路径信息
查询路径属性(如文件名、扩展名、父目录等):
from pathlib import Path
file_path = Path("newfile.txt")
print(f'''
.name:获取路径的最后一部分,即文件名或目录名:---{file_path.name}
.stem:获取不包括扩展名的文件名部分:---{file_path.stem}
.suffix:获取文件扩展名,包括点(如.txt):---{file_path.suffix}
.parent:返回父目录路径对象:---{file_path.parent}
.absolute():返回绝对路径对象:---{file_path.absolute()}
.resolve():解析所有符号链接并返回绝对路径:---{file_path.resolve()}
''')5. 组合与解析路径
使用 / 运算符组合路径,可以像操作字符串一样来组合路径,这使得代码更加简洁和易读:
from pathlib import Path
# 创建一个基本的路径对象
base_path = Path("/home/user")
# 使用 / 运算符添加子路径或文件名
project_dir = base_path / "projects"
file_path = project_dir / "my_project" / "main.py"
print(file_path) # 输出: /home/user/projects/my_project/main.py解析绝对路径和处理符号链接,resolve() 方法用于解析符号链接(如果存在),并确保得到的是一个绝对路径:
#符号链接(Symbolic Link),又称为软链接,是Unix/Linux系统中的一种特殊类型的文件,它指向另一个文件或目录。
symlink_path = Path("/home/user/link_to_projects")
absolute_path = symlink_path.resolve()
print(absolute_path) # 输出:/home/user/projects (假设link_to_projects是一个指向"/home/user/projects"的符号链接)
#符号链接就像一个快捷方式,当你通过符号链接访问文件或目录时,系统实际上会转向并访问其指向的原始文件或目录。
# 在上述场景中,symlink_path 就像是通往 /home/user/projects 目录的一个快捷入口。当需要创建一个多级目录结构时,可以直接通过连续组合路径并调用 mkdir(parents=True) 来实现:
new_str = Path("/mnt/data/archive/year=2023/month=04/day=15")
# 如果该路径不存在,parents=True 参数将自动创建所有必要的父级目录
new_str.mkdir(parents=True, exist_ok=True)
# 此时 "/mnt/data/archive/year=2023/month=04/day=15" 目录及其所有上级目录都将被创建解析路径的同时也可以提取出路径的不同部分:
complex_path = Path("/mnt/data/archive/year=2023/month=04/day=15/report.txt")
# 获取目录部分
directory_part = complex_path.parent
print(directory_part) # 输出: /mnt/data/archive/year=2023/month=04/day=15
# 获取文件名(包括扩展名)
filename_with_extension = complex_path.name
print(filename_with_extension) # 输出: report.txt
# 获取文件名不带扩展名的部分
stem_without_extension = complex_path.stem
print(stem_without_extension) # 输出: report
# 获取扩展名
extension = complex_path.suffix
print(extension) # 输出: .txt6. 存在性检查
检查文件或目录是否存在,以及它们的类型:
from pathlib import Path
file_path = Path("newfile.txt")
print(f'''
.is_file():判断路径是否是一个文件:---{file_path.is_file()}
.is_dir():判断路径是否是一个目录:---{file_path.is_dir()}
.is_symlink():判断路径是否是一个符号链接:---{file_path.is_symlink()}
.exists():判断路径是否存在:---{file_path.exists()}''')7. 其他应用场景举例
1、日志文件的管理,如按日期创建日志目录并写入内容。
2、数据抓取时,根据路径结构组织保存的数据文件。
3、构建工具中,根据项目结构生成文件列表或者执行批量文件操作。
4、开发过程中,根据模块结构查找源代码文件。
总结:
在实际开发过程中,
pathlib和os通常是互补的工具集,根据具体需求选择合适的模块。对于简单的路径管理和基本的文件操作,pathlib可能足够用;而对于更加复杂或者与操作系统紧密相关的任务,则可能需要结合os模块来完成。当然,在现代Python编程中,大多数日常的文件和目录操作可以通过
pathlib来简化代码,并且保持良好的可读性。其面向对象的设计使得路径操作更易于理解和维护,并且由于它是内置模块,无需额外安装,方便开发者在各种Python项目中直接使用。
希望文章能帮助大家有效理解如何操作Python文件,以及对文件路径进行高效管理!









![[蓝桥杯 2015 省 B] 生命之树](https://img-blog.csdnimg.cn/direct/7bd7daa8c9504bcbaf2b9794db0e8d9d.png)