目录
- 1 概念
- 2 快速入门
- 2.1 启动xxl-job-admin
- 2.2 创建一个新的定时任务
- 2.3 在调度中心新增定时任务
- 3 详细介绍
- 3.1 新建执行器
- 3.2 创建任务
- 3.3 其他概念
- 3.3.1 路由策略
- 3.3.2 任务运行模式(BEAN、GLUE)
- 3.3.3 阻塞处理策略
- 3.3.4 子任务
- 3.3.5 任务超时时间
- 3.4 高级任务用法
- 3.4.1 分片任务
- 3.4.2 命令任务
- 4 总结
- 4.1 概念
- 4.2 步骤
- 4.2.1 导入xxl-job-core包
- 4.2.2 继承 IJobHandle(可省略)
- 4.2.3 创建 XxlJobConfig 获取地址
- 4.2.4 配置文件
- 4.2.5 启动调度中心和执行器
XXL-Job快速入门+详细教程
xxl-job官网中文文档地址
项目代码:GitHub
1 概念
XXL-JOB是一个轻量级分布式任务调度平台
详细说明:XXL-JOB是一个任务调度框架,通过引入XXL-JOB相关的依赖,按照相关格式撰写代码后,可在其可视化界面进行任务的启动,执行,中止以及包含了日志记录与查询和任务状态监控
如果将XXL-JOB形容为一个人的话,每一个引入xxl-job的微服务就相当于一个独立的人(执行器),而按照相关约定格式撰写的Handler为餐桌上的食物,可视化界面则可以决定哪个执行器(人),吃东西或者不吃某个东西(定时任务),在什么时间吃(Corn表达式控制或者执行或终止或者;立即开始);
每一个xxl-job微服务 = 独立的人(执行器)
每一个Handler = 餐桌上的食物
"可视化界面可以决定哪个人(执行器)吃或者不吃某个食物(定时任务)"
Quartz的不足:Quartz作为开源任务调度中的佼佼者,是任务调度的首选。但是在集群环境中,Quartz采用API的方式对任务进行管理,这样存在以下问题:
- 通过调用API的方式操作任务,不人性化。
- 需要持久化业务的QuartzJobBean到底层数据表中,系统侵入性相当严重。
- 调度逻辑和QuartzJobBean耦合在同一个项目中,这将导致一个问题,在调度
- 任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况下,此时调度系统的性能将大大受限于业务。
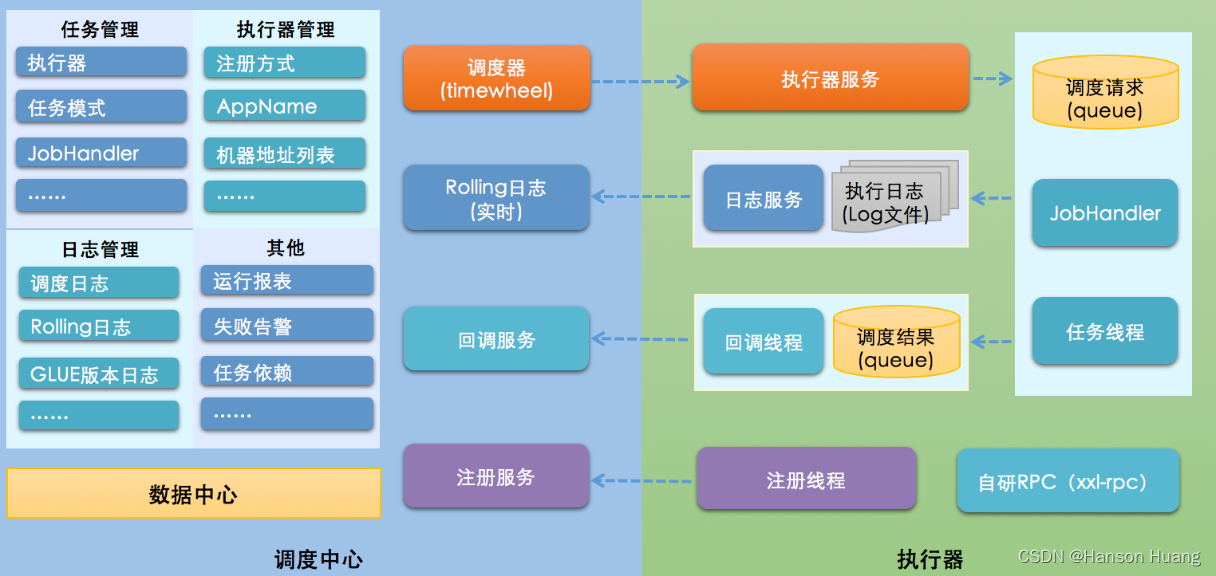
XXL-Job架构图:
2 快速入门
首先从GitHub上面将项目clone下来,如果网络问题导致速度慢也可以从Gitee上面拉取
GitHub地址:https://github.com/xuxueli/xxl-job
Gitee地址:https://gitee.com/xuxueli0323/xxl-job
2.1 启动xxl-job-admin
1)新建idea项目
clone后项目使用idea打开,得到如下目录结构
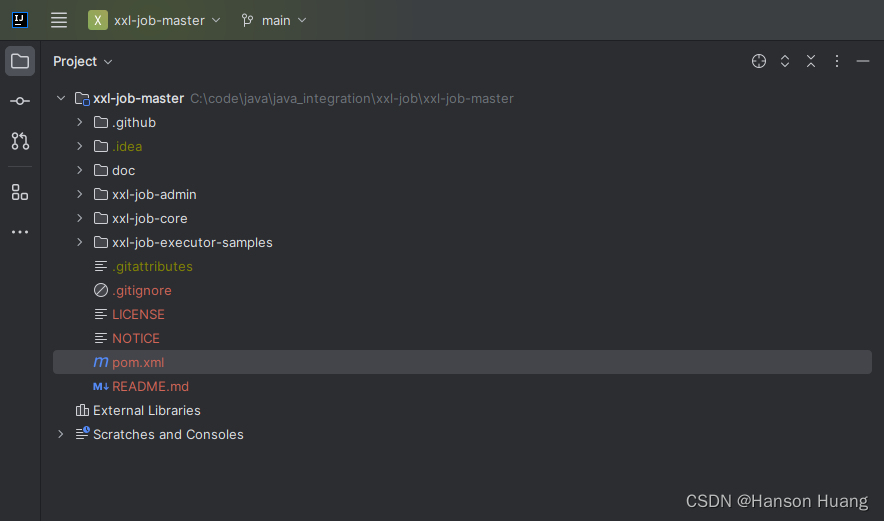
doc:文档资料,包括"调度数据库"建表脚本
xxl-job-core:公共 Jar 依赖
xxl-job-admin:调度中心,项目源码,spring boot 项目,可以直接启动
xxl-job-executor-samples:执行器,sample 示例项目,其中的 spring boot 工程,可以直接启动。可以在该项目上进行开发,也可以将现有项目改造生成执行器项目。
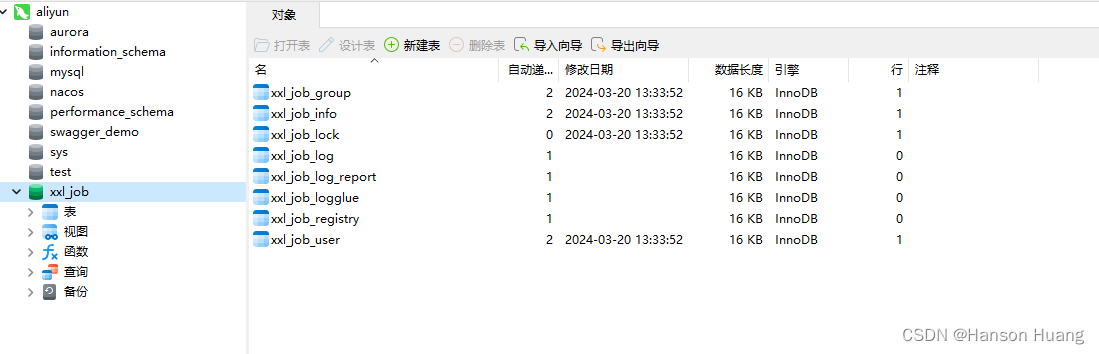
2)配置好数据源,执行sql
执行后:
3)打开xxl-job-admin模块,在application.properties中进行后台的配置
数据库的url需要设置时区
jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai

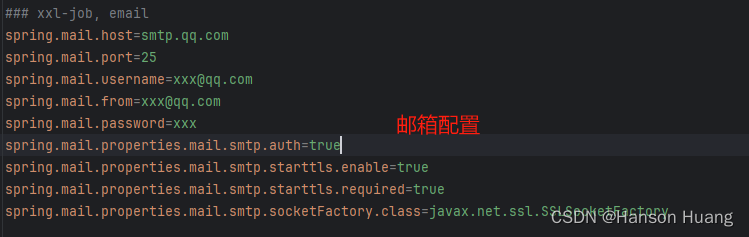
注意:其中的spring.mail.password不是邮箱登录密码,而是有限的授权码。
这里我以qq邮箱为例,登录邮箱点击设置,然后点账号

在账户项中下滑至POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务。

4)启动XxlJobAdminApplication类,访问http://localhost:8080/xxl-job-admin 默认账户admn,密码123456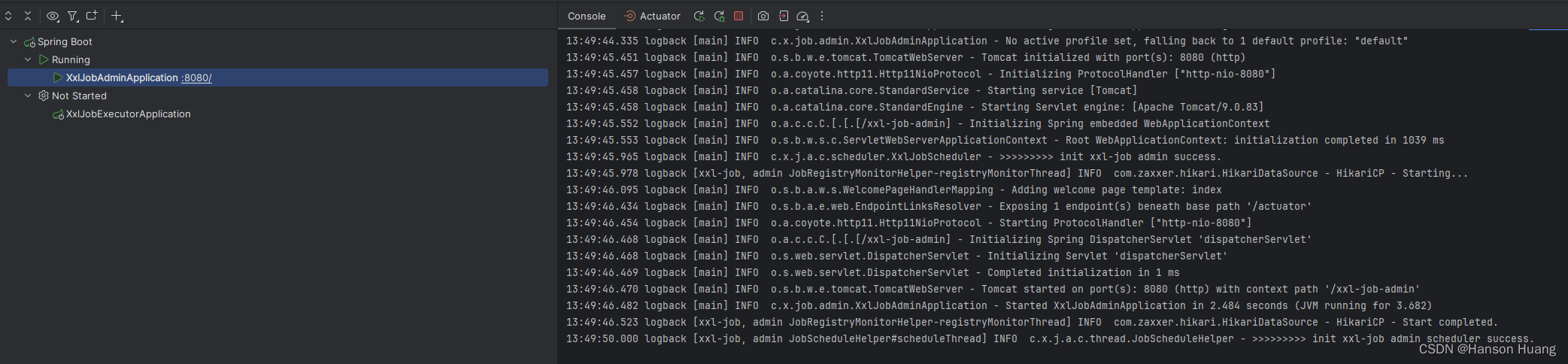
主页面:
2.2 创建一个新的定时任务
定位到jobhandler下,新增定时任务
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.springframework.stereotype.Component;
/**
* @author hanson
* @date 2024/3/20 14:39
*/
@Component
public class MyJobHandler {
/**
* 简单的任务示例
*
* @param param
* @return
* @throws InterruptedException
*/
@XxlJob(value = "myJobHandler", init = "", destroy = "")
public ReturnT<String> demoJobHandler(String param) throws InterruptedException {
// 模拟业务的执行
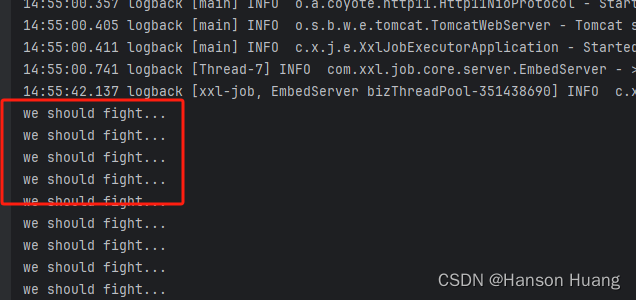
System.out.println("we should fight...");
// 返回执行结果
return ReturnT.SUCCESS;
}
}
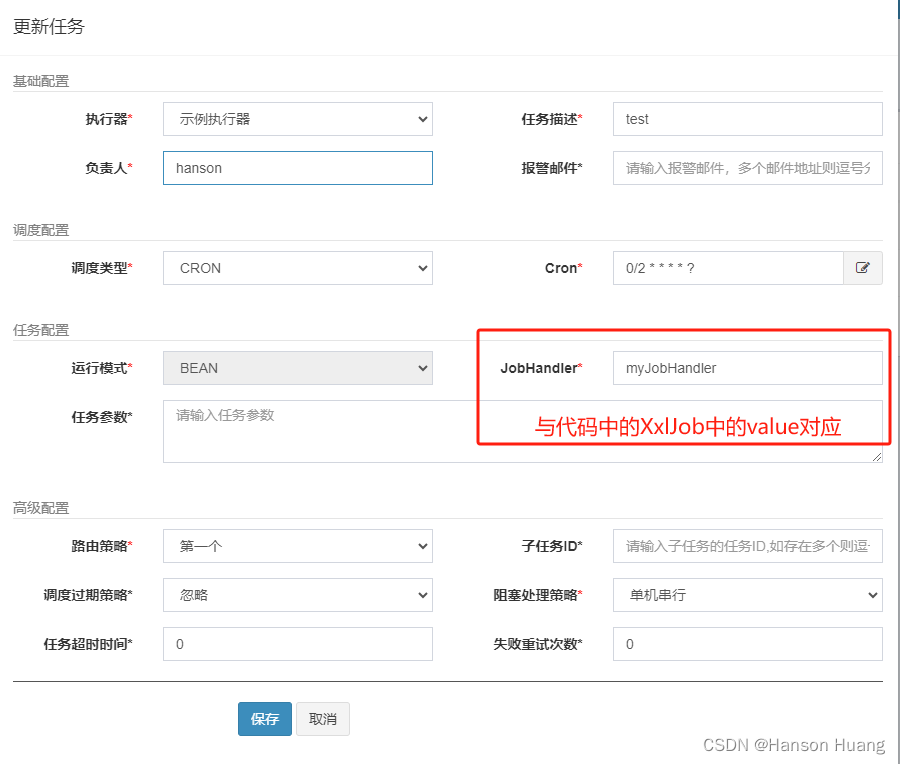
2.3 在调度中心新增定时任务
1)选中右侧任务管理-新增
2)启动XxlJobExecutorApplication执行器
3)在调度中心,启动定时任务
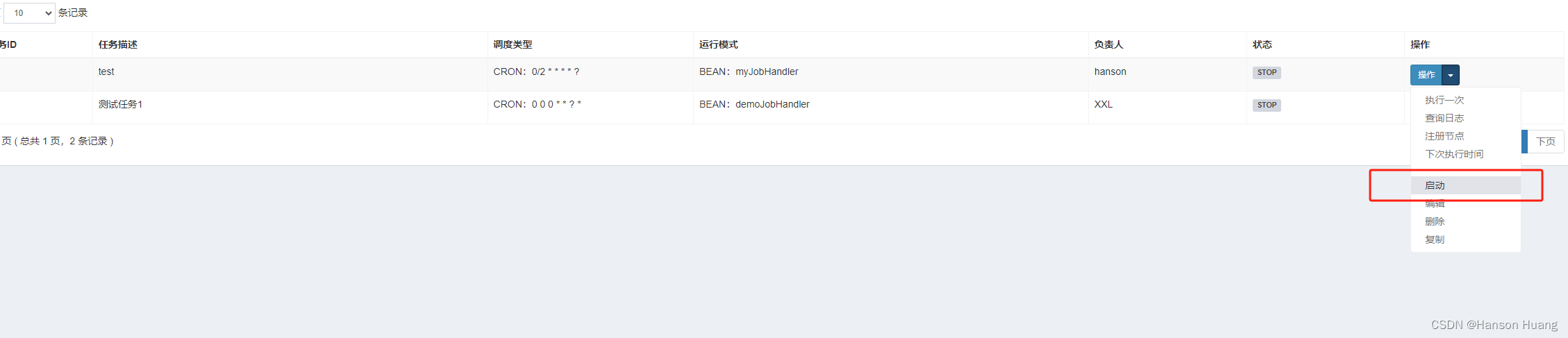
4)查看结果
3 详细介绍
自己的项目想要引用xxl-job,导入以下依赖即可
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.0.1</version>
</dependency>
3.1 新建执行器
执行器相当于是小组组长,负责任务的具体执行,由它分配线程(组员)执行任务。执行器需要注册到调度中心,这样调度中心才知道怎样选择执行器,或者说做路由。执行器的执行结果,也需要通过回调的方式告诉调度中心。
这里选择 spring boot 项目用来举例子,从源码中单独拷一个项目出来,如果你是在业务项目里集成的话,也是参考这个 sample,在项目里加上 xxl-job-core 的依赖,添加配置就可以创建执行器了。
1)在xxl-job-executor-samples下新建自己的执行器模块,例如:xxl-job-executor-hz【直接复制xxl-job-executor-sample-springboot】,修改下文件名和模块名
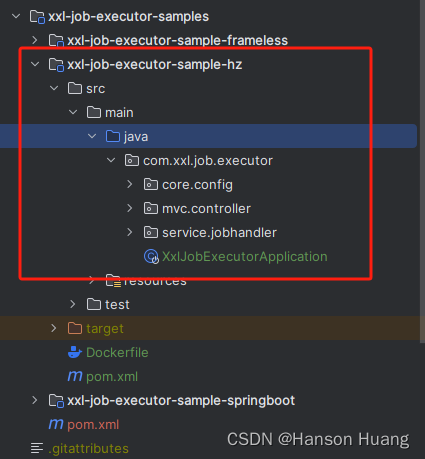
同时修改执行器的名字,否则后面会报命名冲突,修改@XxlJob的value即可
2)修改sample-hz模块的配置,将其修改为集群模式
在E盘下,创建xxl-log文件夹
### xxl-job executor log-path 日志存放路径
xxl.job.executor.logpath=C:\\code\\java\\java_integration\\xxl-job\\xxl-log
### 因为我们要模拟执行器集群部署,打包后单击运行多次,为服务设置随机端口
server.port=${random.int[10000,19999]}
### 执行器的端口
xxl.job.executor.port=${random.int[9000,10000]}
### 集群部署,这两项配置要一致
xxl.job.executor.appname=xxl-job-executor-zi
xxl.job.executor.address=
可以直接将我的直接复制到配置文件中,然后看哪块重复了,直接删除即可
最终效果:
# no web
#spring.main.web-environment=false
# log config
logging.config=classpath:logback.xml
### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### xxl-job, access token
xxl.job.accessToken=default_token
### xxl-job executor appname
### xxl-job executor server-info
xxl.job.executor.ip=
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30
### xxl-job executor log-path 日志存放路径
xxl.job.executor.logpath=E:\\xxl-log
### 因为我们要模拟执行器集群部署,打包后单击运行多次,为服务设置随机端口
server.port=${random.int[10000,19999]}
### 执行器的端口
xxl.job.executor.port=${random.int[9000,10000]}
### 集群部署,这两项配置要一致
xxl.job.executor.appname=xxl-job-executor-zi
xxl.job.executor.address=
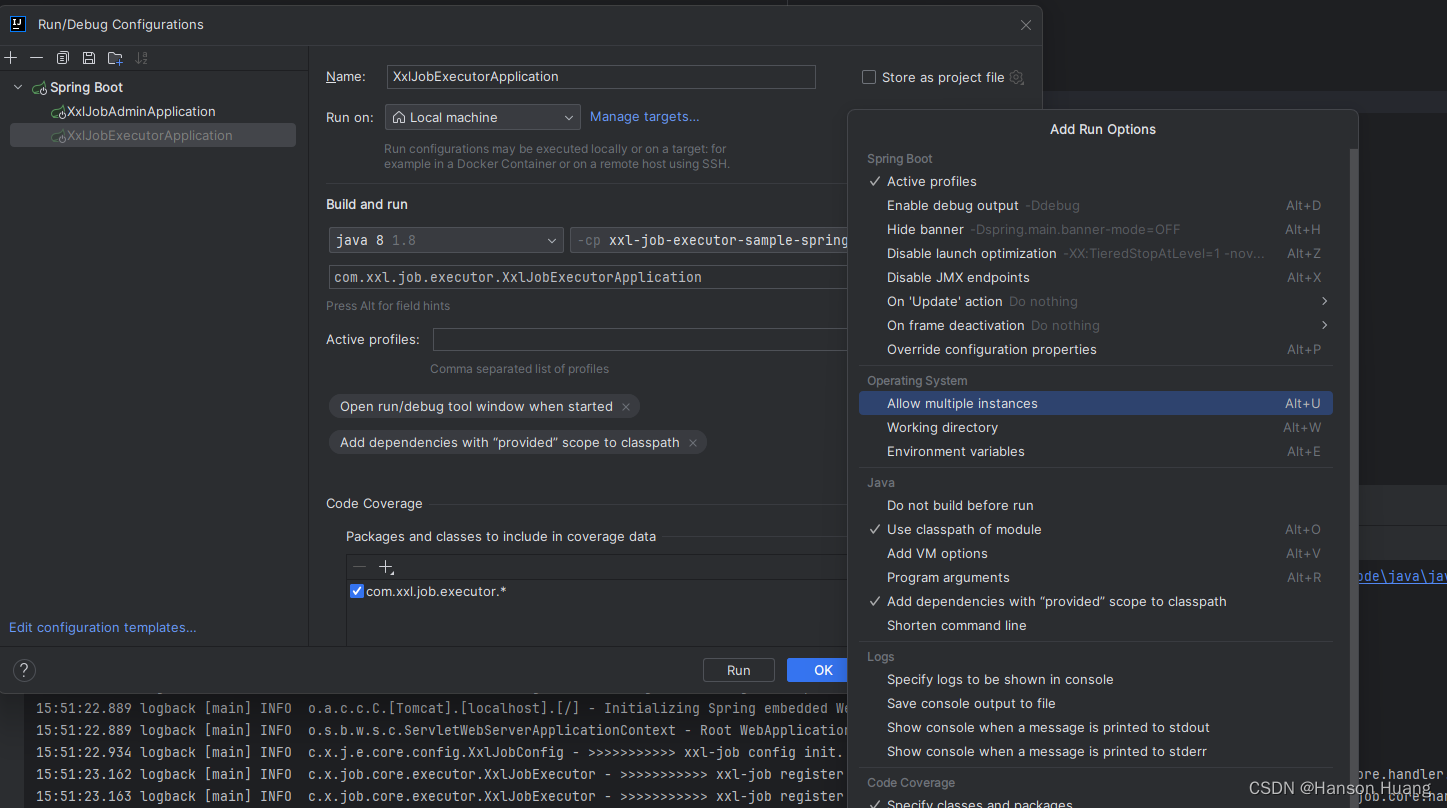
3)修改idea配置
启动项目,在本地启动多个执行器集群的时候这里要打上勾(或者直接
alt+U),因为我们配置了随机端口,所以是不会报错的。
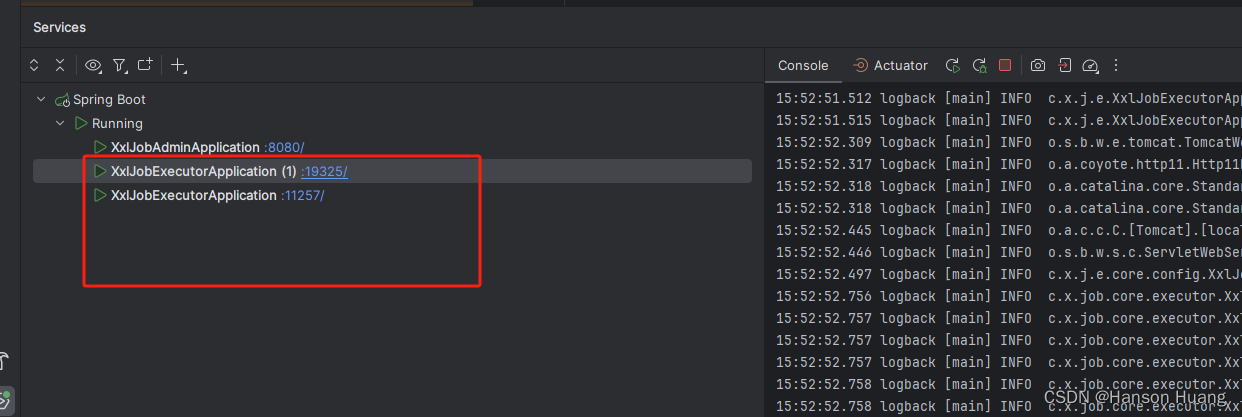
4)启动执行器
启动两个(XxlJobExecutorApplication)
5)新增执行器
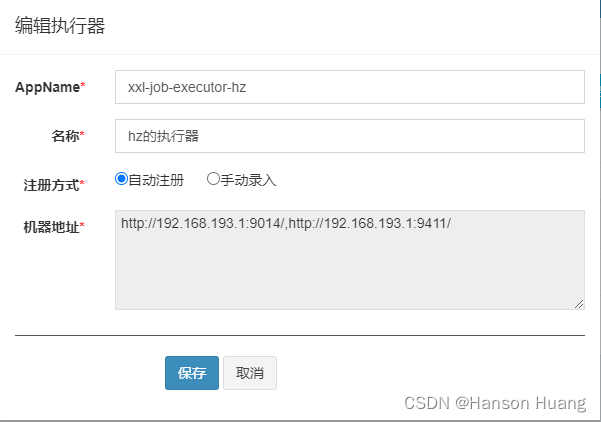
6)刷新,查看效果
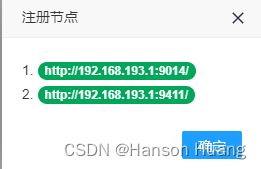
注册成功
3.2 创建任务
注意点:
新建任务有几个注意点:
- 在Spring Bean 实例中(@Component 注解),开发 Job 方法。方法格式要求为"public ReturnT < String > demoJobHandler(String param)",返回值和参数格式是固定的,这个是不能动的,唯一能动的是方法名。
- 在方法名上打上 @XxlJob 注解,这里面有几个属性,第一个 value 值对应的是调度中心新建任务的JobHandler属性的值。另外的 init 对应 JobHandler 初始化方法,destory 对应
JobHandler 销毁方法。这两个方法要在任务类里面创建。- 执行日志:需要通过"XxlJobLogger.log"打印执行日志,会写到指定的日志文件中。
3.3 其他概念
3.3.1 路由策略
路由策略是指一个任务可以由多个执行器完成,那具体由哪一个完成呢,这就要看我们指定的路由策略了,
这个参数当执行器做集群部署的时候才有意义。
Quartz中只能随机负载。
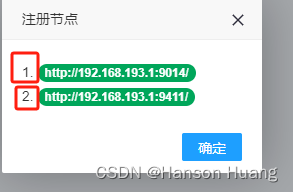
那么这里的第一个,最后一个是按什么顺序来的呢,就是点击查看-注册节点中的1,2,3,4,第一个指的就是1,最后一个指的就是4。
3.3.2 任务运行模式(BEAN、GLUE)
运行模式分为两种,一种是BEAN,一种是GLUE
- BEAN模式:这个是在项目中写 Java 类,然后在 JobHandler 里填上 @XxlJob 里面的名字,是在执行器端编写的
- GLUE模式:支持Java、Shell、Python、PHP、Nodejs、PowerShell,这个时候代码是直接维护在调度中心这边的
1)新增一个任务,模式选择为GLUE
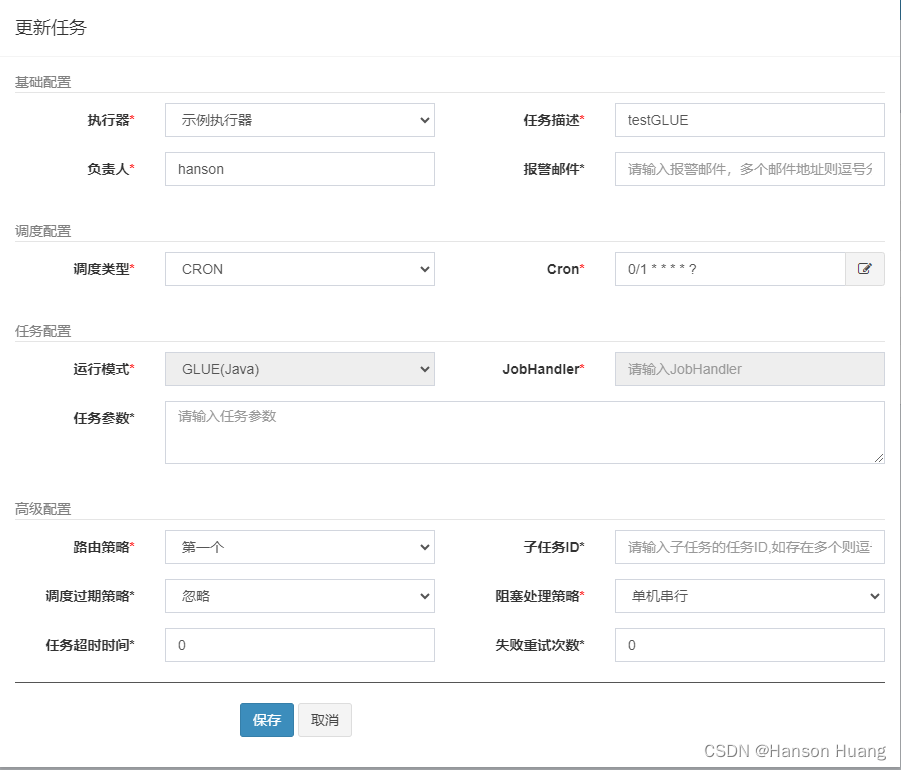
2)编写任务
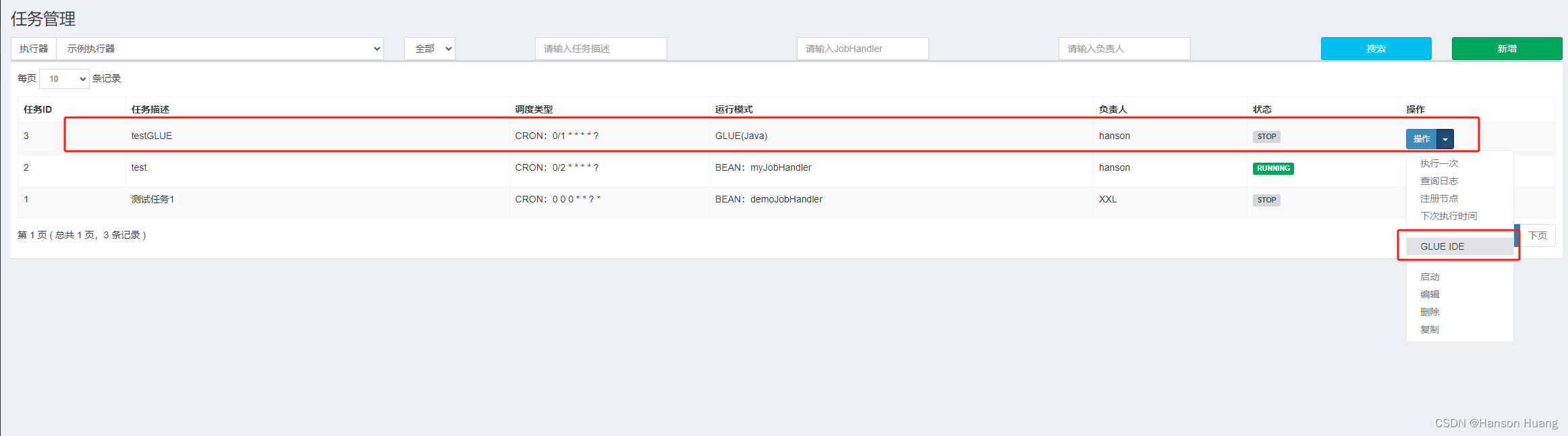
但是这样会存在一个安全隐患的问题,没有做鉴权。解决方法也很简单,只需要在调度中心和执行器的application.properties 里加上相同的 token 即可。
xxl.job.accessToken=
3.3.3 阻塞处理策略
阻塞处理策略指的是任务的一次运行还没有结束,下一次调度的时间又到了,比如一个任务执行的时间是三分钟,但是设置的频率是每两分钟执行一次,这时候第一次还没执行完,第二次怎么办?
3.3.4 子任务
当我们要写一个 Job 的时候,任务是相互依赖的。比如下面我要干这么多事情,A干完了干B,B干完了干C,C干完了干D。
解决这种问题的时候思路有两种。
- 第一种是把这么多逻辑写成一个大 job,串行化。
- 第二种就是用子任务,在一个任务末尾触发另一个任务。
如果我们需要在本任务执行结束并且执行成功的时候触发另外一个任务,那么就可以把另外的任务作为本任务的子任务执行,因为每个 Job 都有自己的唯一 id,所以只需在子任务一栏填上任务 id 即可。
3.3.5 任务超时时间
超时的意思就是如果在指定时间内没有返回结果,就不再等待结果。
3.4 高级任务用法
3.4.1 分片任务
假设我们有个任务需要处理20万条数据,每条数据的业务逻辑处理要0.1秒,对于普通任务单线程来讲,需要处理5.5个小时才能处理完。这时候你想要提高速度,你的第一反应就是开多线程跑嘛,我开3个,差不多就是一个多小时就能搞定了,你的思路完全正确!
这时候将会是下面这种情况,在执行器0上有三个线程在拼命的工作,但是这样大家觉得好不好?不好吧,我执行器0在这累的要死,你执行器1和执行器2在那休息,旱的旱死,涝的涝死,首先这是一个分配不均匀的问题。其次当执行器0三个线程都在工作的时候会浪费它的资源,使之这台服务器的性能也会下降,所以这是一种不好的方式。
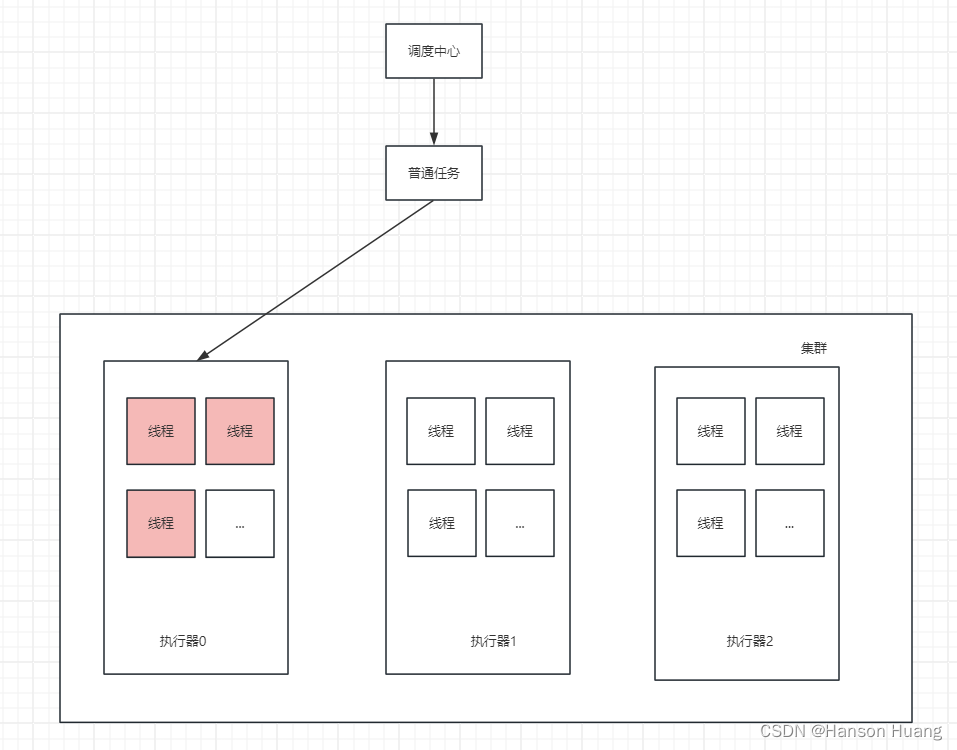
这时候就要用到我们的分片任务了,真正好的方案如下,这是一个既科学又合理的方案。三台执行器各自起一个线程来共同把这个任务完成!
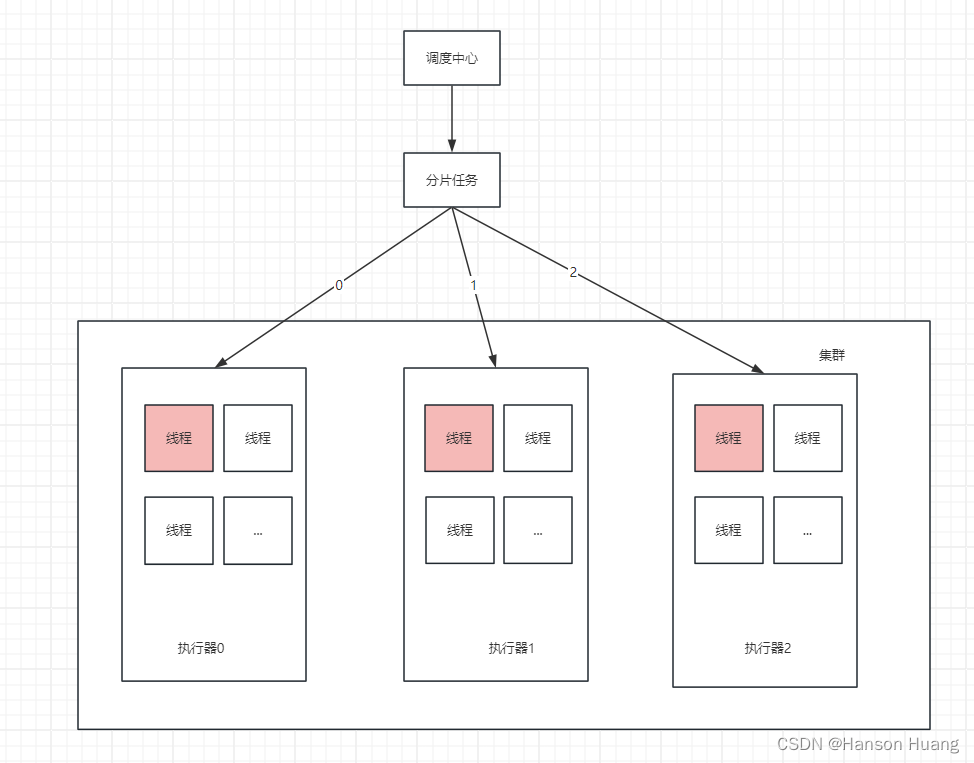
这时候有个问题,三台机器大家都执行同一段代码,那岂不是乱套了,这个数据你也执行一遍,我也执行一遍,它也执行一遍。 解决的思路很简单,一台执行器处理总数的1/3,大家把需要干的活平均分了嘛,我干1/3,你干1/3,它干1/3,这样也不会产生冲突。
分片任务在运行的时候,调度器会给每个执行器发送一个不同的分片序号,分片的最大序号跟执行器的总数量是一样的,确保每个执行器都会执行到这个任务,比如上图中第一个执行器拿到分片序号0,第二台执行器拿到分片序号1,第三台执行器拿到分片序号2。那现在就好办了,我们只需要把处理的数据进行模3取余,余数为0的数据就由执行器0干,余数为1的数据就由执行器1干,余数为2的数据就由执行器2干。
我们获取数据的sql可以这样写:
//count分片总数,index当前分片数
select id,name,password from student where status=0 and mod(id,#{count})=#{index} order by id desc limit 1000;
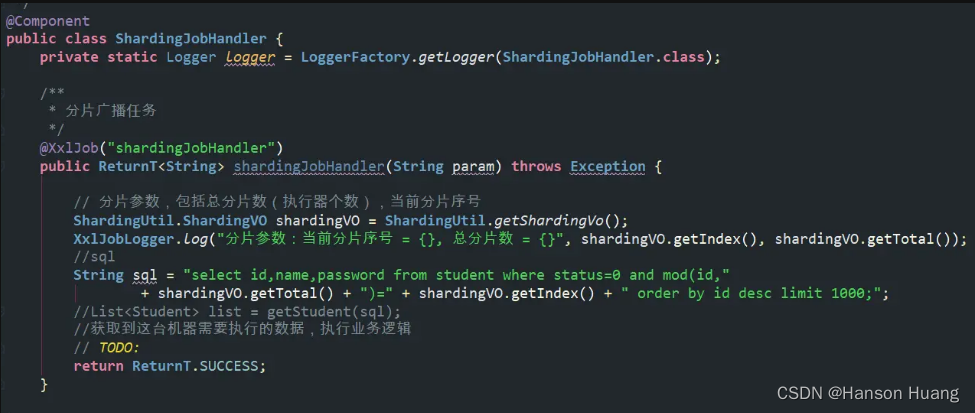
新建任务的时候选择分片广播,填上对应的JobHandler即可
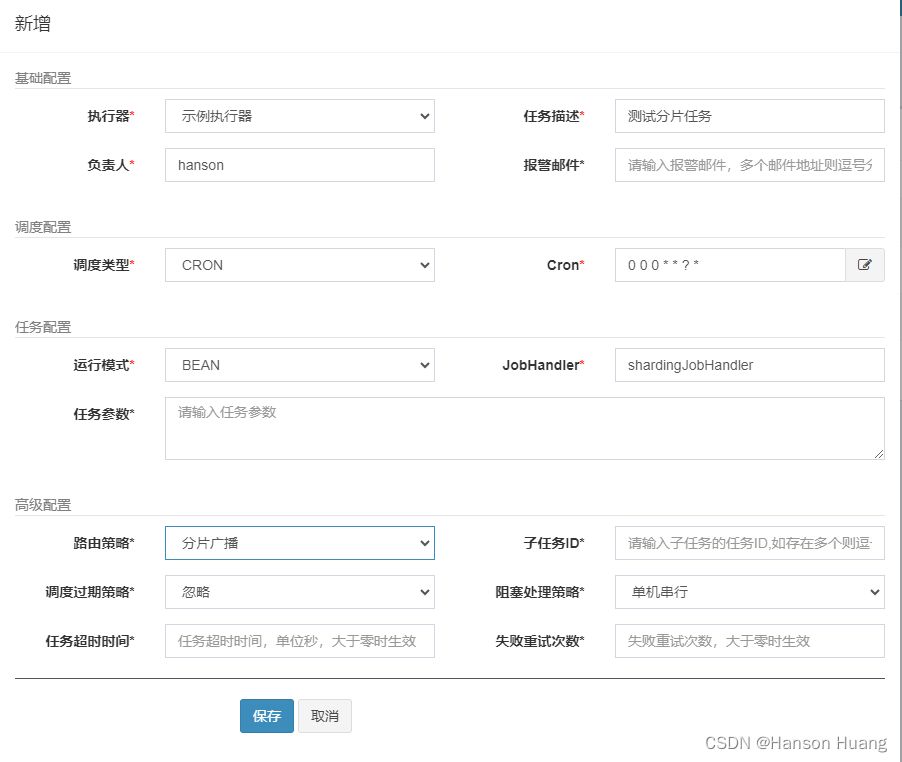
最后需要说明一下,分片的数据量不一定是完全均等的数据量,上面的取模只是一个举例,一个思路。我们也可以把0、1、2替换成其他条件去从所有数据中获取部分数据,比如分片序号0的机器我查2018年的数据,分片序号1的机器我查2019年的数据,分片序号2的机器我查2020年的数据。具体怎么分全靠我们的业务来选择。
如果增加或者减少了节点,总分片数和最大分片序号会实时发生变化。
3.4.2 命令任务
命令任务比较有用,比如我们需要定时重启数据库(service restart),定时备份数据文件(cp tar rm),定时清理日志(rm)。
命令行的使用也很简单,只需要把执行的命令作为参数传递进来即可
@Component
public class CommandJobHandler2 {
/**
* 命令行任务
* @param
* @return
*/
@XxlJob(value = "commandJobHandler2")
public ReturnT<String> commandJobHandlerTest() throws IOException {
//用于获取动态传入进来的参数
String jobParam = XxlJobHelper.getJobParam();
Process exec = Runtime.getRuntime().exec(jobParam);
System.out.println("command run success...");
return ReturnT.SUCCESS;
}
}
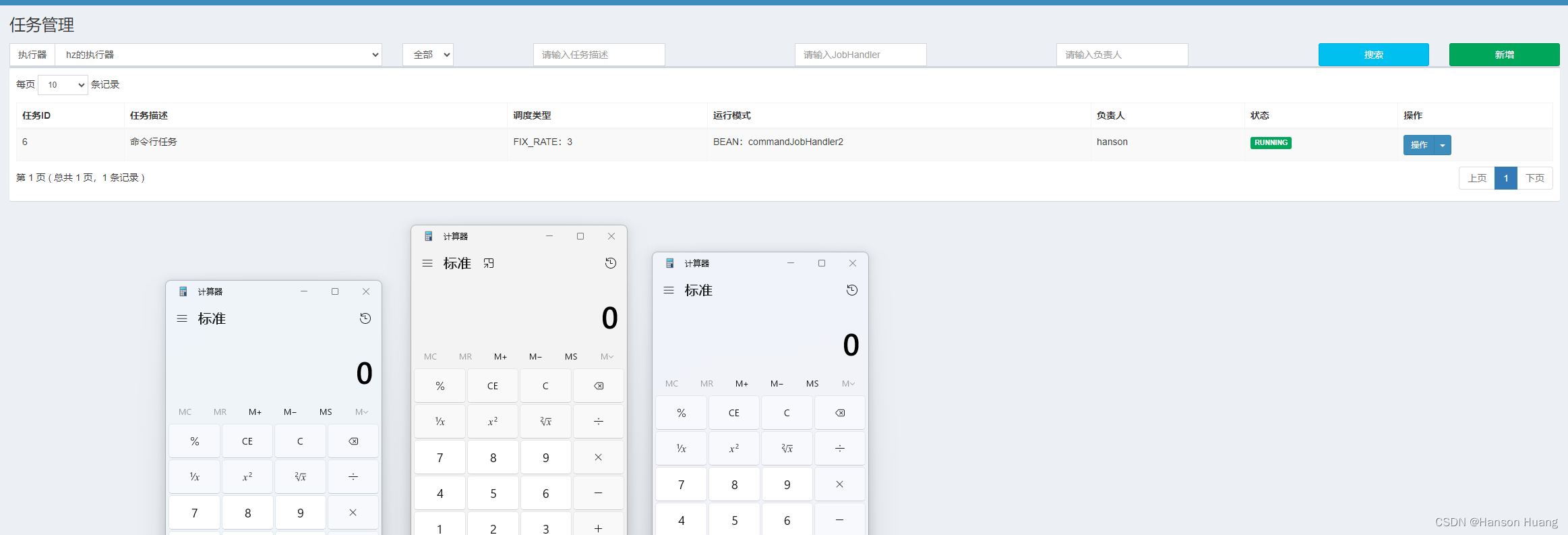
启动一下任务,每过3秒,这个计算器就自动弹出来了
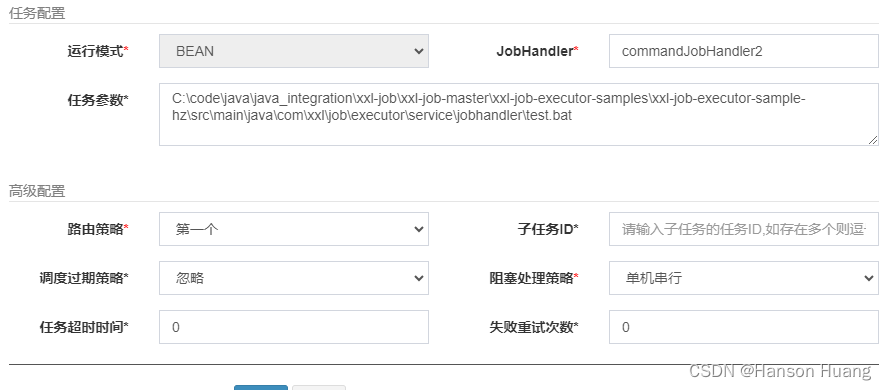
拓展:执行bat文件
随便写一个test.bat
start https://www.baidu.com/s?wd=ChatGPT
@Component
public class CommandJobHandler2 {
/**
* 命令行任务
* @param
* @return
*/
@XxlJob(value = "commandJobHandler2")
public ReturnT<String> commandJobHandlerTest() throws IOException {
//用于获取动态传入进来的参数
String jobParam = XxlJobHelper.getJobParam();
File file = new File(jobParam);
System.out.println(String.valueOf(file));
System.out.println(file.getAbsolutePath());
System.out.println(file.getCanonicalFile());
// Process exec = Runtime.getRuntime().exec("cmd /k start " + "www.baidu.com");
Process exec2 = Runtime.getRuntime().exec("cmd /k start " + file.getCanonicalFile());
System.out.println("command run success...");
// System.out.println(exec.getInputStream());
//D:\系统默认\桌面\test.bat
return ReturnT.SUCCESS;
}
}
效果:弹出页面
cmd命令执行窗口开闭指令
cmd /c dir 是执行完dir命令后关闭命令窗口。
cmd /k dir 是执行完dir命令后不关闭命令窗口。
cmd /c start dir 会打开一个新窗口后执行dir指令,原窗口会关闭。
cmd /k start dir 会打开一个新窗口后执行dir指令,原窗口不会关闭。
4 总结
4.1 概念
- 调度中心
- 负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
- 调度中心支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
- 调度中心会把调度请求放进一个异步调度队列,理论上默认配置下的调度中心单机能够支撑5000任务并发并且稳定运行,但是由于受网络延迟、DB读写耗时不同、任务调度密集程度不同,会导致任务量上限会上下波动。如果需要支撑更多的任务量,可以通过调大调度线程数、降低调度中心与执行器ping延迟、提升机器配置等。
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
- 执行器
- 负责接收调度请求并执行任务逻辑,任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
- 接收调度中心的执行请求、终止请求和日志请求等。
4.2 步骤
4.2.1 导入xxl-job-core包
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.0.1</version>
</dependency>
4.2.2 继承 IJobHandle(可省略)
继承IJobHandle+@JobHandler可以通过@XxlJob代替
@JobHandler("testJobHandler")
@Component
public class TestJobHandler extends IJobHandler {
private final Logger logger = LoggerFactory.getLogger(getClass());
@Override
public ReturnT<String> execute(String param) {
// 分片参数
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
int index = shardingVO.getIndex();
int total = shardingVO.getTotal();
// xxl 日志
XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}, 任务参数 = {}", index, total, param);
// spring 日志
logger.info("分片参数:当前分片序号 = {}, 总分片数 = {}, 任务参数 = {}", index, total, param);
// TODO 自己的业务
logger.info("【定时任务】开始,ing...");
// return new ReturnT<>(500, "参数不符合要求");
// return new ReturnT<>(200, "成功处理 " + count + " 条数据!");
return SUCCESS;
}
}
4.2.3 创建 XxlJobConfig 获取地址
package com.example.job.task.handler;
import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan(basePackages = "com.example.job.task")
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.executor.appname}")
private String appName;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean(initMethod = "start", destroyMethod = "destroy")
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppName(appName);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
4.2.4 配置文件
#redis 不配置就报错,在main类排除配置也没用(不配置也可以)
spring.redis.host: 10.16.88.34
spring.redis.port: 6380
spring.redis.database: 0
spring.redis.timeout: 5000
spring.redis.password: 123456
spring.redis.pool.max-idle: 0
spring.redis.pool.max-wait: -1
#任务调度
#任务调度服务地址以及端口
xxl.job.admin.addresses=http://10.16.87.104:9001
#执行名称
xxl.job.executor.appname=logistics-appName-job
#自动获取
xxl.job.executor.ip=
#默认端口9999
xxl.job.executor.port=9999
xxl.job.accessToken=
#日志输出地址
xxl.job.executor.logpath=./xxl-job-log
#日志保存天数:值大于3时生效,启用执行器Log文件定期清理功能,否则不生效
xxl.job.executor.logretentiondays=-1