缓冲区
首先, 我们对缓冲区最基本的理解, 是一块内存, 用户提供的缓冲区就是用户缓冲区, C标准库提供的就是C标准库提供的缓冲区, 操作系统提供的就是操作系统缓冲区, 它们都是一块内存.
为什么要有缓冲区?
先举个生活中的例子, 我们寄快递的时候往往是去驿站寄快递, 而不是直接自己去送, 自己送效率太低, 不如直接把快递交给驿站. 驿站方便了用户, 虽然最终快递还是要被快递员送过去, 但是它给使用者提供了方便, 谁要寄快递就方便了谁.
驿站就相当于缓冲区:
1. 缓冲区的主要作用是提高效率, 提高使用者的效率, 谁使用缓冲区就提高谁的效率. 冯诺依曼体系中, 数据不用从一个设备拷贝到另一个设备, 而是把数据直接写入内存中, 让操作系统定期去刷新即可.
2. 因为有缓冲区的存在, 我们可以把数据积累一部分再统一发送, 提高了发送的效率.
缓冲区刷新方式
缓冲区因为能够暂存数据, 所以必定要有对应的刷新方式:
一般策略:
1. 无缓冲(立即刷新)
2. 行缓冲(行刷新)
3. 全缓冲(缓冲区满刷新)
特殊情况 :
1. 强制刷新
2. 进程退出的时候, 一般要进行刷新缓冲区
一般情况, 对于显示器文件, 行缓冲; 磁盘上的文件, 全缓冲.
现在看一个样例, 调用三个C语言接口往显示器打印, 再调用一个系统调用接口往显示器打印, 最后创建了一个子进程:
1 #include <stdio.h>
2 #include <string.h>
3 #include <unistd.h>
4 int main()
5 {
6 fprintf(stdout, "C: hello fprintf\n");
7 printf("C: hello printf\n");
8 fputs("C: hello fputs\n",stdout);
9 const char* str = "system call: hello write\n";
10 write(1,str,strlen(str));
11
12 fork();
13 return 0;
14 }
运行后发现结果和我们预想的一样, 打印了四条语句.

当我们向显示器打印的时候, 显示器的刷新方式是行刷新, 而代码中输出的语句都带有\n, fork之前, 数据全部被刷新, 包括系统调用.
现在把内容重定向到 log.txt 磁盘文件中 , 发现除了系统调用以外, 每一个C语句都被打印了两次:

重定向到 log.txt, 本质是向磁盘文件中写入, 系统对于数据的刷新方式变成了全刷新, 全刷新意味着缓冲区变大, 实际写入的几条简单数据不足以把缓冲区填满, 也就是说fork执行的时候, 数据依然在缓冲区中.
由于C语言printf等接口底层是封装了系统调用的, 而系统调用却没有打印两次, 说明目前我们谈的缓冲区和操作系统无关, 是C语言提供的缓冲区. C/C++提供的缓冲区, 里面保存的是用户的数据, 仍然属于当前进程在运行时自己的数据, 而进程退出的时候, 一般要刷新缓冲区, 即使数据没有满足刷新条件, 此例中不管是fork创建的子进程还是父进程, 总有一个进程要退出, 也就是会发生一次缓冲区刷新, 而刷新缓冲区是数据清空的操作, 就会发生写时拷贝! 另一个进程退出时数据还会被刷新一次, 数据就被刷新了两次.
再来解释一下为什么write的内容只显示了一次, 因为write是系统调用, 没有使用C缓冲区, 而是直接把数据写入到了操作系统, 如果我们把数据交给了操作系统, 数据就属于操作系统, 不属于当前进程了, 也就不会被写时拷贝.
什么叫做刷新?
我们printf将数据输入到C语言缓冲区中, 缓冲区满足刷新方式时就会调用write进行刷新, 刷新其实就是将数据从C缓冲区写入OS!
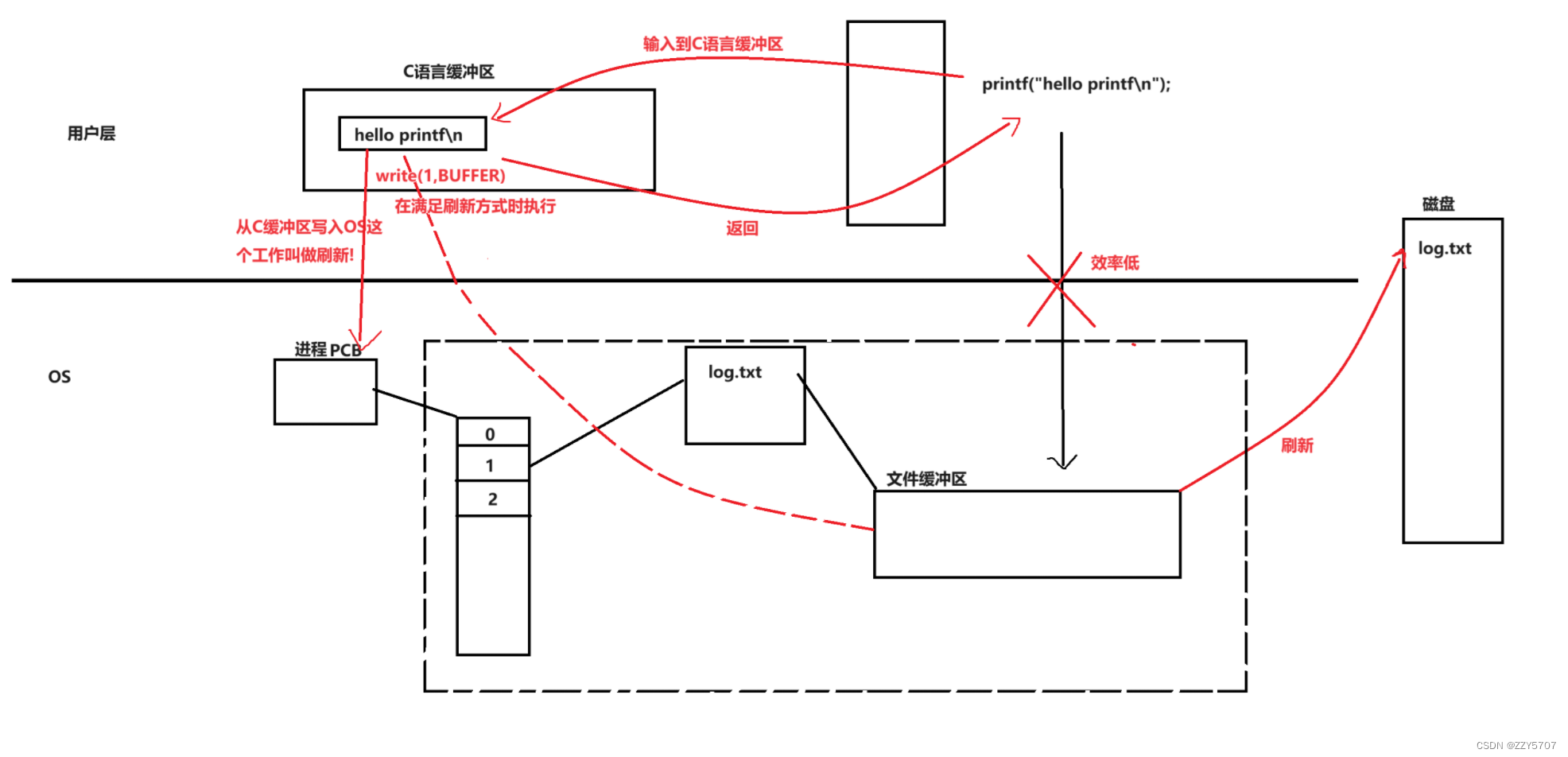
printf只在用户层与C缓冲区交互, 是用户级别的交互, 而不是直接将数据写入操作系统管理的文件缓存区中, 等C语言缓冲区存放了一定的数据后再统一刷新到文件缓冲区, 文件缓冲区再刷新到磁盘中, 提高了printf的效率, 从而间接提高了程序其它代码执行的效率. 另外, 其实printf在拷贝字符串数据的同时也把格式化%d等操作拷贝到目标字符串中, 顺便也把格式化输出的工作也做了.
操作系统管理的文件缓冲区也有自己的刷新方式, write系统调用只管把C缓冲区的数据写到文件缓冲区即可, 不关心它什么时候刷新到磁盘, 这样能提高系统调用的效率.
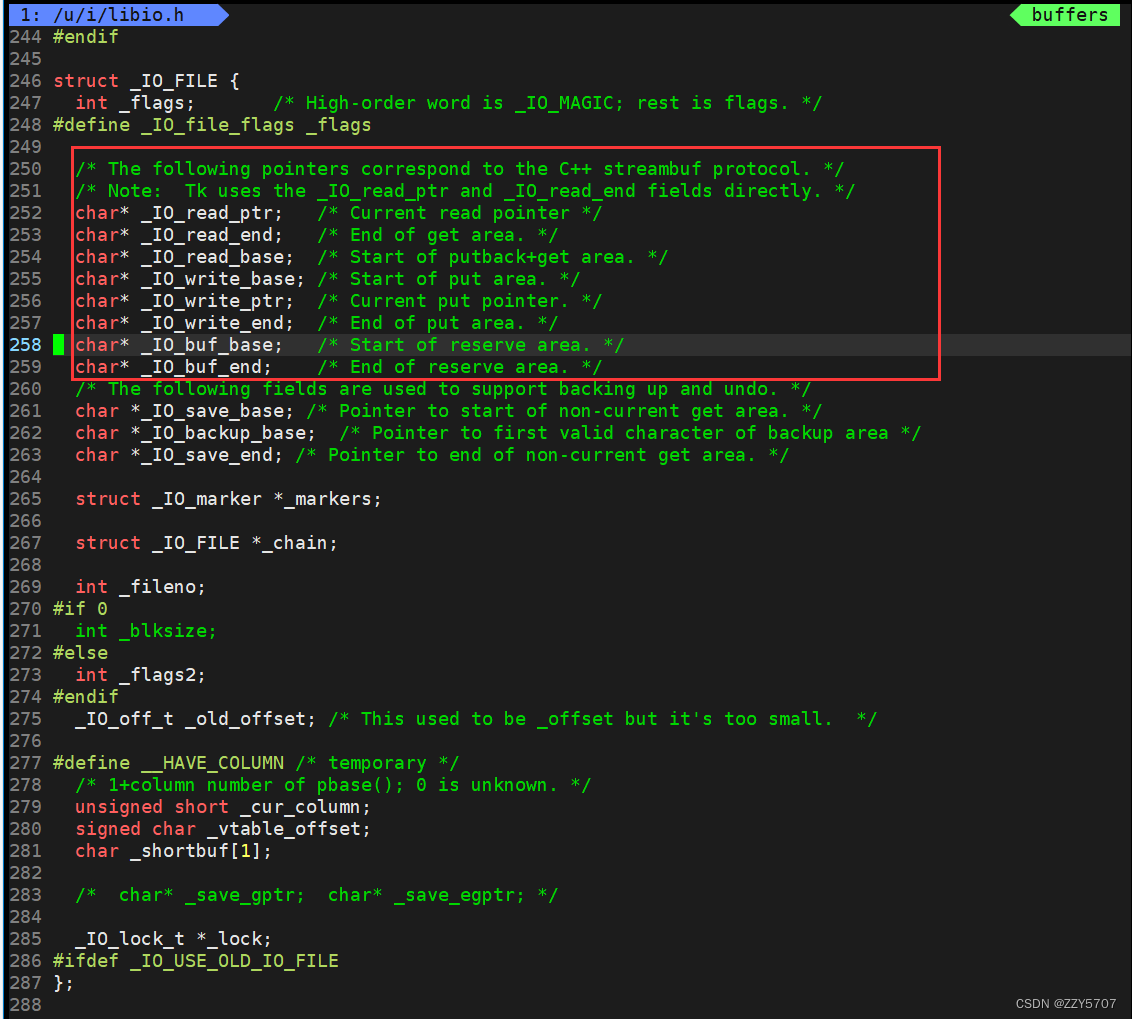
C语言缓冲区在哪里?
C语言缓冲区存在FILE结构体里, FILE结构体里不仅封装了fd, 而且包含了该文件fd对应的语言层的缓冲区结构_IO_FILE, 在/usr/include/libio.h中:
模拟实现C标准库的函数
这里目的是代码说明, 不是复刻
mystdio.h
#pragma once
#define SIZE 4096
#define FLUSH_NONE 1
#define FLUSH_LINE (1<<1)
#define FLUSH_ALL (1<<2)
typedef struct _FILE
{
int fileno;//文件标识符
int flag;//刷新策略
char buffer[SIZE];//缓冲区
int end;//缓冲区大小
} my_FILE;
extern my_FILE* my_fopen(const char* path, const char* mode);
extern int my_fclose(my_FILE* stream);
extern int my_fflush(my_FILE* stream);
extern unsigned my_fwrite(const void* ptr, unsigned num, my_FILE* stream);//fwrite中间两个参数简化为1个
mystdio.c
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include <errno.h>
#define DEFAULT_MODE 0666
my_FILE* my_fopen(const char*path, const char* mode)
{
int fd = 0;//文件描述符
int flag = 0;//确定打开方式
if(strcmp(mode,"r") == 0)
{
flag |= O_RDONLY;
}
else if(strcmp(mode,"w") == 0)
{
flag |= O_CREAT | O_TRUNC | O_WRONLY;
}
else if(strcmp(mode,"a") == 0)
{
flag |= O_CREAT | O_APPEND | O_WRONLY;
}
if(flag & O_CREAT)
fd = open(path, flag,DEFAULT_MODE);
else
fd = open(path, flag);
if(fd < 0)
{
errno = 2;
return NULL;
}
//创建一个my_FILE结构体
my_FILE* stream = (my_FILE*)malloc(sizeof(my_FILE));
if(!stream)
{
errno = 3;
return NULL;
}
stream->fileno = fd;
stream->end = 0;
return stream;
}
int my_fflush(my_FILE* stream)
{
if(stream->end > 0)
{
write(stream->fileno, stream->buffer, stream->end);
stream->end = 0;
}
return 0;
}
int my_fclose(my_FILE* stream)
{
my_fflush(stream);//文件关闭前刷新缓冲区
int ret = close(stream->fileno);
if(ret)
errno = 2;
return ret;
}
unsigned my_fwrite(const void*ptr, unsigned num, my_FILE* stream)
{
memcpy(stream->buffer+stream->end,ptr,num);
unsigned i = 0;
for(i = 0; i < num; i++)
{
if(*(stream->buffer+stream->end+i) == '\n')
{
stream->end += num;
my_fflush(stream);
return 0;
}
}
stream->end += num;
return stream->end;
}
main.c , 用于测试:
#include "mystdio.h"
#include <string.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
my_FILE* fp = my_fopen("log.txt","w");
if(fp == NULL)
{
perror("fopen");
return 1;
}
const char* msg = "hello, mystdio\n";
int cnt = 20;
while(cnt--)
{
my_fwrite(msg,strlen(msg),fp);
sleep(1);
}
my_fclose(fp);
return 0;
}
编译:

运行结果:
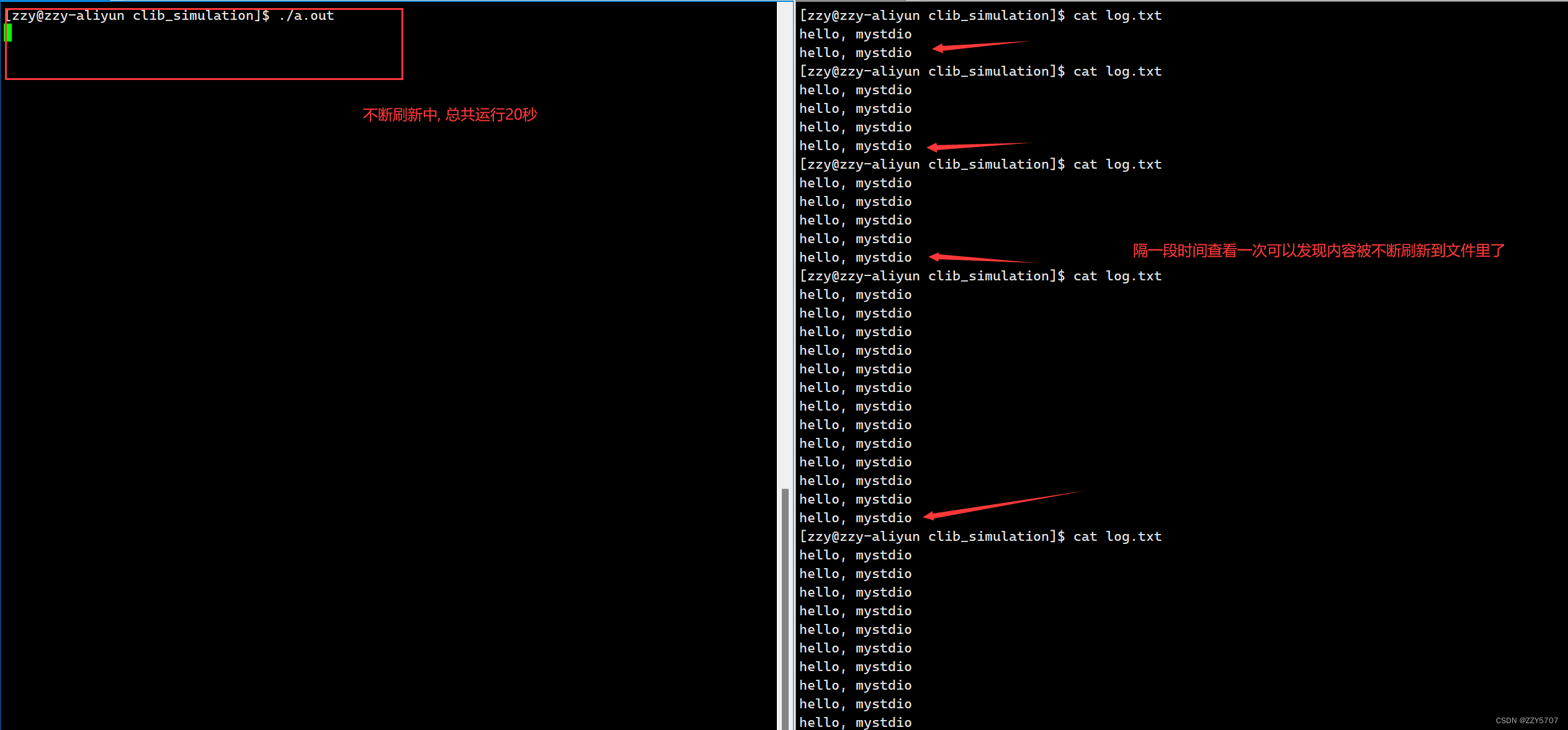
总结:
不管是什么语言Java, python, C, C++等, 它们的IO函数上层的接口使用起来都不一样, 但是它们的底层都是一样的, 操作系统决定了它们的底层必须一样, 不管上层的接口如何封装如何设计, 底层都是一样的.