大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径及一点个人思考
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
文章目录
- 大模型相关目录
- 一、LLaMA-Factory简介
- 二、使用准备
- 二、单卡微调
- 测试集对微调模型性能评估
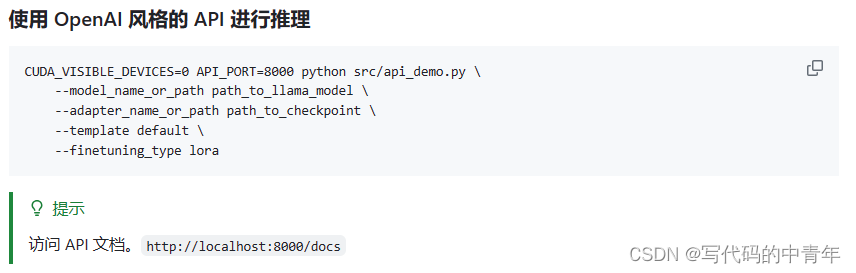
- 微调模型问答使用
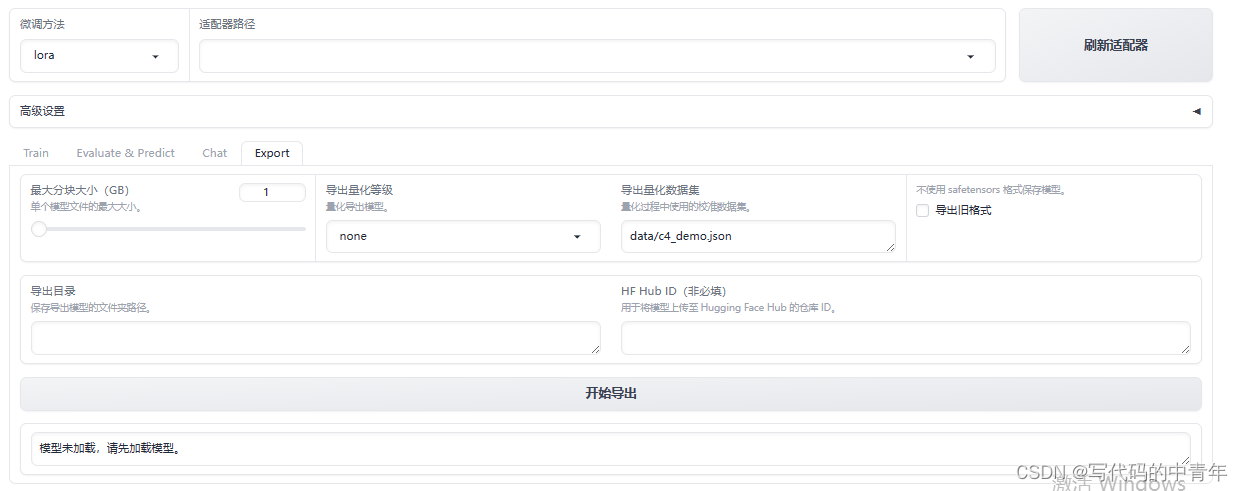
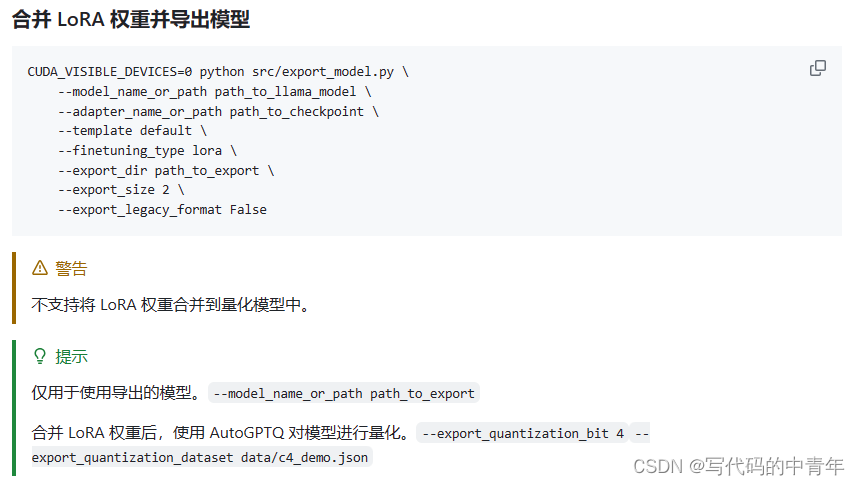
- 微调模型增量模型导出
- 三、多卡微调
- 四、其他
一、LLaMA-Factory简介
LLaMA-Factory是开源的大模型微调框架,在模型微调方式、参数配置、数据集设置、模型保存、模型合并、模型测试以及模型试用上,提供了非常完备的开发接口。其框架使用形式分为指令与界面两种。
二、使用准备
1.拉取项目并部署相应环境(微调chatGLM3 6B很流畅,微调Qwen系列可能需要按错误提示对环境进行补包),并激活。
conda activate zwllama_factory
2.下载模型到本地

3.自行准备数据集
包括:
- 自我认知数据集(微调后可能效果也比较一般,需要多次微调,或者配合prompt。)
- 通用数据集(微调时用不用均可,可保持模型通用能力。且LLaMA-Factory的data文件夹下有alpaca_gpt4_data_zh等已经备好的数据集,不需要刻意定制。)
- 特定领域数据集
基本格式如下(alpaca,一种指令微调的格式。当然还有其他格式):
[
{
"instruction": "你好",
"input": "",
"output": "您好,我是XX大模型,一个由XXX开发的 AI 助手,很高兴认识您。请问我能为您做些什么?"
},
{
"instruction": "你好",
"input": "",
"output": "您好,我是XX大模型,一个由XXX打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
其中,instruction和input可以都填充进内容,如把问题作为input,把“回答问题这一要求”作为instruction。据说这种指令微调数据集的格式效果比较好。
准备数据及后,应上传所用到的数据集至项目路径下data文件夹
data文件夹下的数据集要想使用,还需在dataset_info.json下进行登记注册。
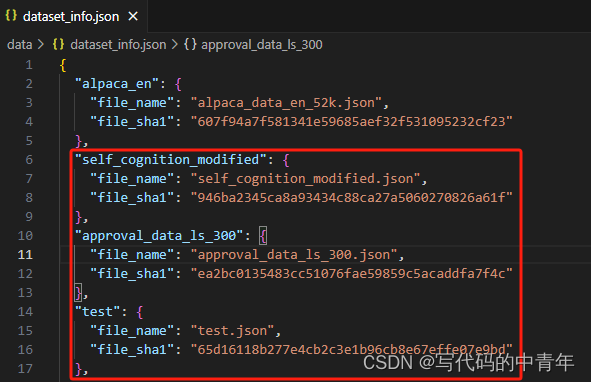
其中,file_sha1可通过如下代码计算获得,该字段要求并不严格,有即可,主要为了区分重复文件,作uuid使用。
import hashlib
def calculate_sha1(file_path):
sha1 = hashlib.sha1()
try:
with open(file_path, 'rb') as file:
while True:
data = file.read(8192) # Read in chunks to handle large files
if not data:
break
sha1.update(data)
return sha1.hexdigest()
except FileNotFoundError:
return "File not found."
# 使用示例
file_path = r'C:\Users\12258\Desktop\xxx.json' # 替换为您的文件路径
sha1_hash = calculate_sha1(file_path)
print("SHA-1 Hash:", sha1_hash)
二、单卡微调
单卡微调往往针对6B、7B等规模不大的大模型,因此界面化操作完全狗满足需求。
下述指令启动界面:
CUDA_VISIBLE_DEVICES=0 python src/train_web.py
如下图所示配置页面信息


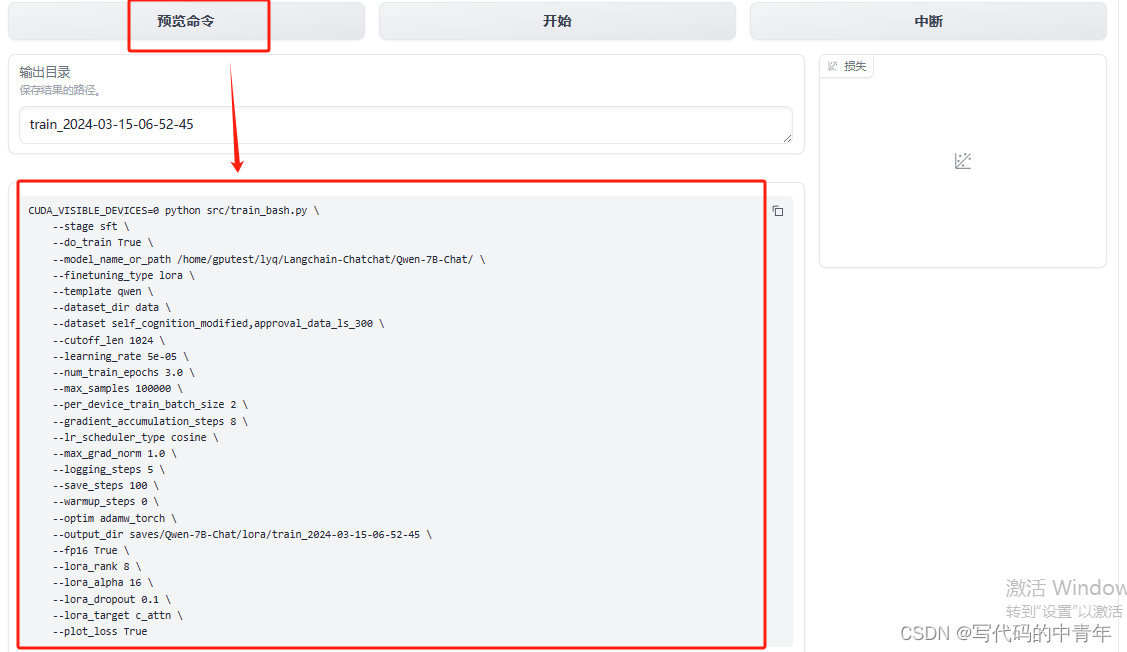
可见界面微调的本质依旧是后端的指令。
点击开始,开始微调,界面无反应,后端开始加载

加载完毕后,前端界面出现训练所需时间和损失曲线。
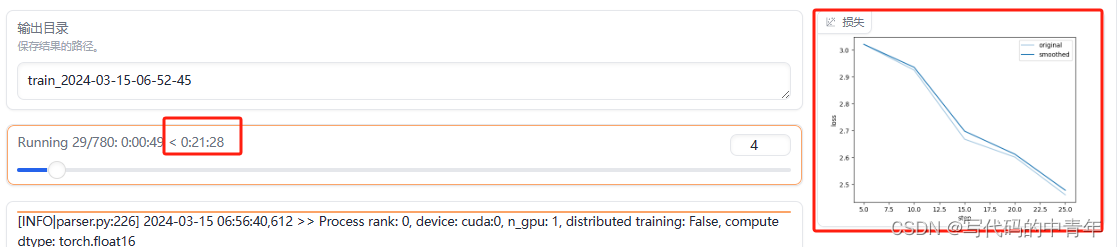
注意,训练随时可以中断。
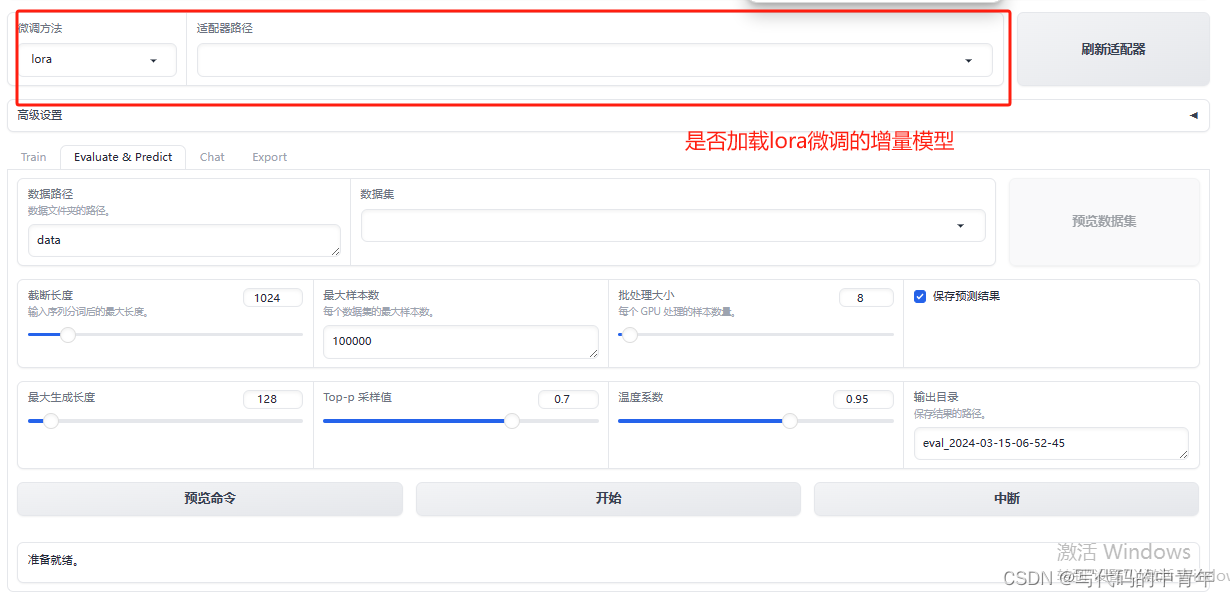
测试集对微调模型性能评估
微调模型问答使用
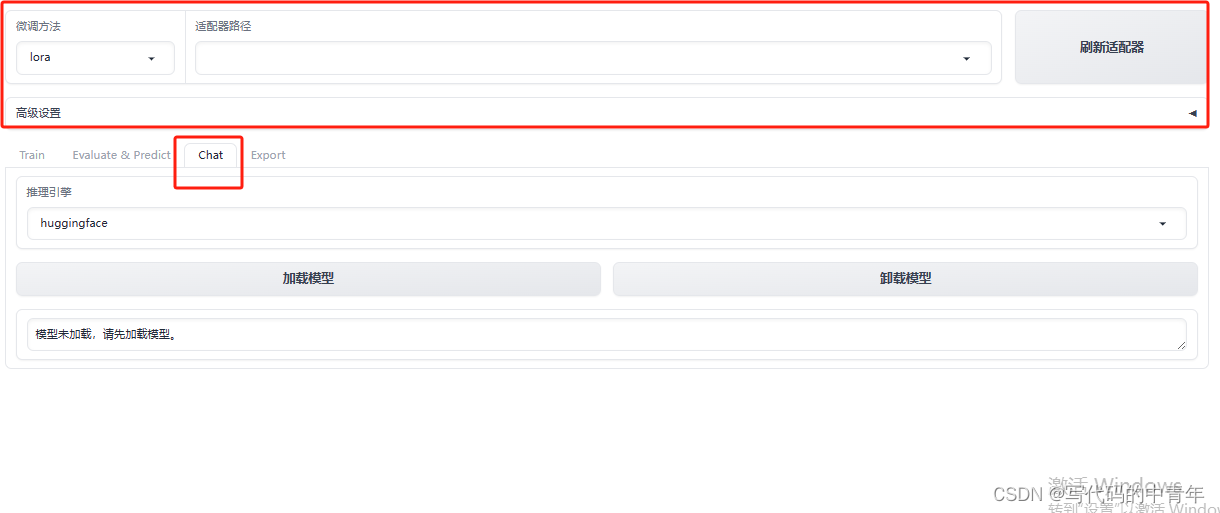
微调模型增量模型导出
三、多卡微调

四、其他
更多信息可以访问开源项目进行了解。