1.两阶段提交,要是在binlog写入磁盘后,redolog还没处于commit状态,这时事务会回滚吗?
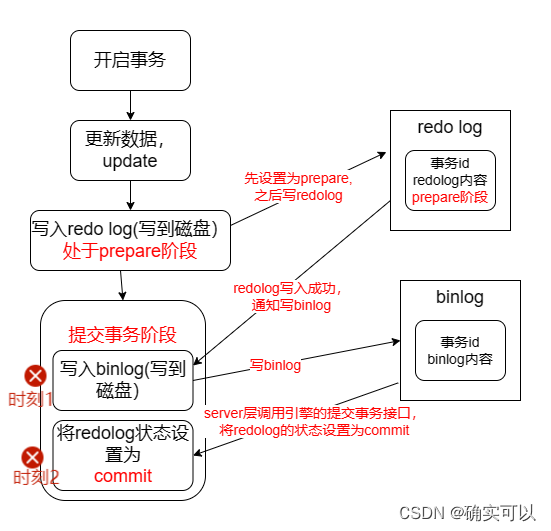
我们先来看一下崩溃恢复时的判断规则。
- 如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
- 如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整: a. 如果是,则提交事务; b. 否则,回滚事务。
时刻1:写入binlog时发生异常。MySQL根据redo log日志恢复数据,发现redo log还处于prepare阶段,并且没有对应binlog日志,这就是对应情况2(b),就会回滚该事务。
时刻2:redo log和binlog都写入成功,只是redolog还是处于prepare。这时并不会回滚事务,虽然redo log是处于prepare阶段,但是能通过redolog的数据找到对应的binlog日志,这就是对应q情况2(a),MySQL认为对应的事务binlog是完整的,就会提交事务恢复数据。
可以看到,对于处于 prepare 阶段的 redo log,可以提交事务,也可以回滚事务,这取决于是否查找到与与该redo log对应的完整binlog。如果有就提交事务,如果没有就回滚事务。这样就可以保证 redo log 和 binlog 这两份日志的一致性了。
所以说,两阶段提交是以 binlog 写成功为事务提交成功的标识。
2.redo log和binlog是如何关联起来的
它们有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:
- 如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
- 如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。
3.怎样才是完整的binlog
只找到对应的XID还不行,还需要判断该binlog是否完整的。
一个事务的 binlog 是有完整格式的:
- statement 格式,最后会有 COMMIT;
- row 格式,最后会有一个 XID event。
另外,在 MySQL 5.6.2 版本以后,还引入了 binlog-checksum 参数,用来验证 binlog 内容的正确性。对于 binlog 日志由于磁盘原因,可能会在日志中间出错的情况,MySQL 可以通过校验 checksum 的结果来发现。所以,MySQL 还是有办法验证事务 binlog 的完整性的。
4.为什么 redo log 具有 crash-safe 的能力,而 binlog 没有?
redo log 和 binlog 有一个很大的区别就是,一个是循环写,一个是追加写。也就是说 redo log 只会记录未刷盘的日志,已经刷入磁盘的数据都会从 redo log 这个有限大小的日志文件里删除。binlog 是追加日志,保存的是全量的日志。
重启后,只通过 binlog 数据库没有标志无法判断有哪些记录还没写入磁盘,只能全盘恢复,那就会出问题。
但 redo log 不一样,只要刷入磁盘的数据,都会从 redo log 中抹掉,数据库重启后,直接把 redo log 中的数据都恢复至内存就可以了。这就是为什么 redo log 具有 crash-safe 的能力,而 binlog 不具备。
5.redo log的WAL 之后如果读数据,是不是一定要读盘,是不是一定要从 redo log 里面把数据更新以后才可以返回?
这个其实是不一定的。写了redolog后,会更新内存中的数据,要是这时进行查询,而数据还在内存中,就直接访问内存即可,不需要去读取磁盘,也不需要把redo log里的数据更新到数据磁盘中。
6.MySQL是如何判断是否是脏页?
这里需要用到LSN的知识。LSN (log sequence number)是日志的逻辑序列号,在InnoDB存储引擎中,LSN的值会随着日志的写入而逐渐增大。新的日志LSN等于旧的LSN加上新增日志的大小。
内存数据页中有LSN,redo log日志文件中checkpoint也有LSN。对比这个LSN跟checkpoint 的LSN,比checkpoint小的一定是干净页,即是大于checkpoint的LSN的内存数据页就是脏页。
7.MySQL基于Checkpoint如何从crash中恢复?
使用show语句
show engine innodb status\G;
---省略部分内容
---
LOG
---
Log sequence number 21926177
Log buffer assigned up to 21926177
Log buffer completed up to 21926177
Log written up to 21926177
Log flushed up to 21926177
Added dirty pages up to 21926177
Pages flushed up to 21926177
Last checkpoint at 21926177可以看到多种LSN,主要是查看以下4种:
- log sequence number: 代表当前的重做日志redo log(in buffer)在内存中的LSN
- log flushed up to: 代表刷到redo log file on disk中的LSN
- pages flushed up to: 代表已经刷到磁盘数据页上的LSN
- last checkpoint at: 代表上一次检查点所在位置的LSN
redo log中的checkpoint的LSN是开始往前推进的位置(即是last checkpoint at),即是从该位置开始是还没有写入到磁盘数据页的。就是从该位置开始开始扫描redo-log,并将其应用到buffer-pool中,直到last Checkpoint对应的LSN等于 log flushed up to 对应的 LSN (也就是redo-log磁盘上存储的LSN值),则恢复完成 。
8.刷脏页过程中,redo log会有什么操作吗?数据写入后的最终落盘,是从redo log更新过来的还是从buffer pool更新过来的呢?
首先要知道,磁盘数据页中的也是有LSN的。
举个例子:
buffer pool里是维护着一个脏页列表,假设现在redo log 的 checkpoint 记录的 LSN 为 1100,现在内存中的某一干净页有修改,修改后该页的LSN为1200,大于 checkpoint 的LSN,则在写redo log的同时该页也会被标记为脏页记录到脏页列表中。现在内存不足,该页需要被淘汰掉,该页会被刷到磁盘,磁盘中该页的LSN为1200(刷脏页后,磁盘中的LSN和内存中的就一致),该页也从脏页列表中移除。
若是redo log 需要往前推进checkpoint,到LSN为1200的这条log时,发现内存中的脏页列表里没有该页,且磁盘上该页的LSN也已经为1200,则该页已刷脏,已为干净页,跳过。
所以,刷脏页过程中,redo log是不会有操作的。在奔溃恢复时候,会对比磁盘数据页的LSN和checkpoint的LSN,要是其是相等的,就会跳过该页。
另外,redo log并没有记录数据页的完整数据,所以它并没有能力自己去更新磁盘数据页,也就不存在“数据最终落盘,是由redo log更新过去”的情况。
-
如果是正常运行的实例的话,数据页被修改以后,跟磁盘的数据页不一致,称为脏页。最终数据落盘,就是把内存中的数据页写盘。这个过程,甚至与redo log毫无关系。
-
在崩溃恢复场景中,InnoDB如果判断到一个数据页可能在崩溃恢复的时候丢失了更新,就会将它读到内存,然后让redo log更新内存内容。更新完成后,内存页变成脏页,就回到了第一种情况的状态。









![[ C++ ] STL---list的使用指南](https://img-blog.csdnimg.cn/direct/fc5935a424eb4072b6a7d771058b604e.gif)