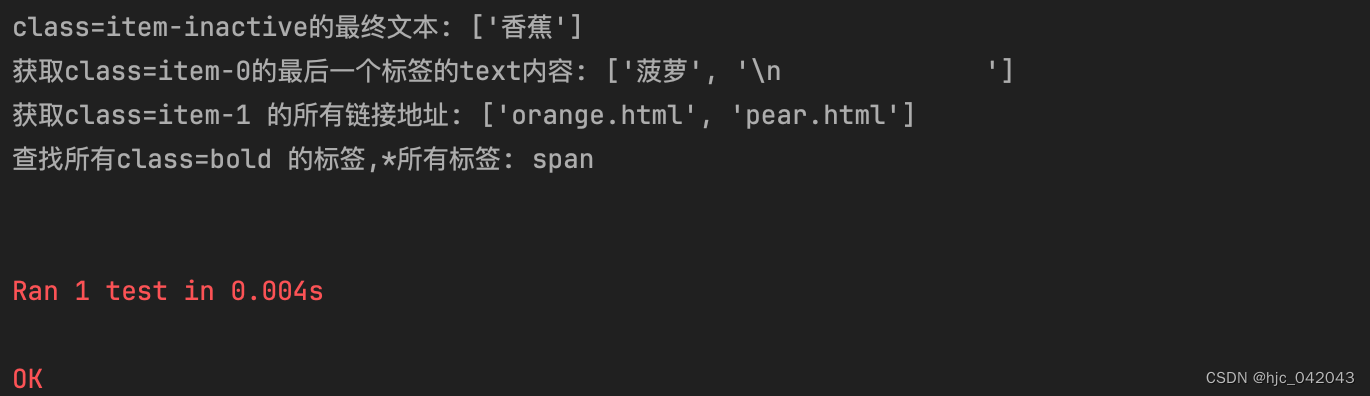
Scrapy
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。
一、安装scrapy
安装Twisted
-
Twisted:为 Python 提供的基于事件驱动的网络引擎包。
-
在下面网址安装Twisted
url:https://www.lfd.uci.edu/~gohlke/pythonlibs/

安装scrapy
-
cmd输入
pip install scrapy -
安装完毕,cmd里输入scrapy出现安装成功。

二、了解scrapy

Scrapy的组件
-
引擎,用来处理整个系统的数据流处理,触发事务。
-
调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
-
下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
-
蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
-
项目管道,负责处理有蜘蛛从网页中抽取的项目,主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
-
下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
-
蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
-
调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
其处理流程为:
-
引擎打开一个域名时,蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL。
-
引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
-
引擎从调度那获取接下来进行爬取的页面。
-
调度将下一个爬取的URL返回给引擎,引擎将他们通过下载中间件发送到下载器。
-
当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
-
引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
-
蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
-
引擎将抓取到的项目项目管道,并向调度发送请求。
-
系统重复第二部后面的操作,直到调度中没有请求。
三、项目分析
爬取天气网城市的信息
url : https://www.aqistudy.cn/historydata/

爬取主要的信息: 热门城市每一天的空气质量信息

点击月份还有爬取每天的空气质量信息

四、新建项目
-
新建文件夹命令为天气网爬虫
-
cd到根目录,打开cmd,运行
scrapy startproject weather_spider

- 创建spider
cd到根目录,运行scrapy genspider weather www.aqistudy.cn/historydata

这里的weather是spider的名字
- 创建的路径如下:

五、代码编写
对于scrapy,第一步,必须编写item.py,明确爬取的对象
- item.py

对于爬取必须伪装好UA,在setting.py中定义MY_USER_AGENT来存放UA,注意在settings中命名必须大写
- settings.py
MY_USER_AGENT = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",]
在定义好UA后,在middlewares.py中创建RandomUserAgentMiddleware类
- middlewares.py

注意要在settings.py中激活,必须是900,来去掉scrapy本身的UA
- setting.py

开始编写最重要的spider.py,推荐使用scrapy.shell来一步一步调试
- 先拿到所有的城市

在scrapy中xpath方法和lxml中的xpath语法一样

我们可以看出url中缺少前面的部分,follow方法可以自动拼接url,通过meta方法来传递需要保存的city名字,通过callback方法来调度将下一个爬取的URL
- weather.py
def parse(self, response): city_urls = response.xpath('//div[@class="all"]/div[@class="bottom"]//li/a/@href').extract()[16:17] city_names = response.xpath('//div[@class="all"]/div[@class="bottom"]//li/a/text()').extract()[16:17] self.logger.info('正在爬去{}城市url'.format(city_names[0])) for city_url, city_name in zip(city_urls, city_names): # 用的follow快捷方式,可以自动拼接url yield response.follow(url=city_url, meta={'city': city_name}, callback=self.parse_month)
这时就是定义parse_month函数,首先分析月份的详情页,拿到月份的url

还是在scrapy.shell 中一步一步调试

通过follow方法拼接url,meta来传递city_name要保存的城市名字,selenium:True先不管
然后通过callback方法来调度将下一个爬取的URL,即就是天的爬取详细页
- weather.py
def parse_month(self, response): """ 解析月份的url :param response: :return: """ city_name = response.meta['city'] self.logger.info('正在爬取{}城市的月份url'.format(city_name[0])) # 由于爬取的信息太大了,所有先爬取前5个 month_urls = response.xpath('//ul[@class="unstyled1"]/li/a/@href').extract()[0:5] for month_url in month_urls: yield response.follow(url=month_url, meta={'city': city_name, 'selenium': True}, callback=self.parse_day_data)
在将日的详细页的信息通过xpah来取出

发现竟然为空

同时发现了源代码没有该信息

说明了是通过js生成的数据,scrapy只能爬静态的信息,所以引出的scrapy对接selenium的知识点,所以上面meta传递的参数就是告诉scrapy使用selenium来爬取。
复写WeatherSpiderDownloaderMiddleware下载中间件中的process_request函数方法
middlewares.py
import time
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
class WeatherSpiderDownloaderMiddleware(object):
def process_request(self, request, spider):
if request.meta.get('selenium'):
# 为了让浏览器能够无界面的工作
chrome_options = Options()
# 设置chrome浏览器无界面模式
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=chrome_options)
# 用浏览器去访问这个地址
driver.get(request.url)
time.sleep(1.5) # 因为浏览器需要加载渲染
html = driver.page_source
driver.quit()
return scrapy.http.HtmlResponse(url=request.url, body=html, encoding='utf-8', request=request)
return None
激活WeatherSpiderDownloaderMiddleware

最后编写weather.py中的剩下代码

六、运行项目
一定要注意项目的根目录执行命令,可以通过scrapy list查看是否存在项目

scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,命令如下:
默认json
- scrapy crawl weather -o spider.json
json lines格式,默认为Unicode编码
- scrapy crawl weather -o spider…jl
csv 逗号表达式,可用Excel打开
- scrapy crawl weather -o spider…csv
xml格式
- scrapy crawl weather -o spider…xml
但是保存的编码不对,必须在settings中加入FEED_EXPORT_ENCODING = 'utf-8'
七、入库操作
这里入的库是Mongodb,在settings.py中配置

对于入门主要处理的是pipelines中
-
pipelines.py

-
在settings中激活pipelines

效果如下

八、结语
我们本次通过爬取天气网站的来作为学习 Scrapy 的,这里展示的关于 Scrapy 大部分的知识点。如果改写列表,就可以爬取北京所有的天气信息,当然还可以爬取全部城市的天气信息,即这个天气网的全部内容基本都爬取。
如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

Python兼职渠道推荐
学的同时助你创收,每天花1-2小时兼职,轻松稿定生活费.
2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


上述所有资料 ⚡️ ,朋友们如果有需要的,可以扫描下方👇👇👇二维码免费领取🆓





![[C语言]一维数组二维数组的大小](https://img-blog.csdnimg.cn/direct/8456245efec84329909bc73c5ac9225c.png)