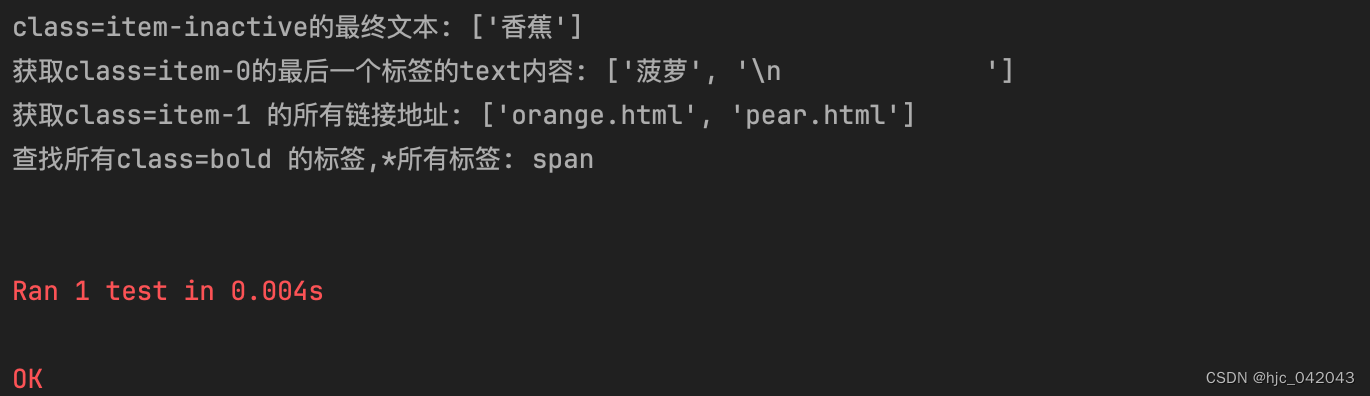
读取数据
代码
import numpy as np
# 文件的路径
us_file_path="./youtube_video_data/US_video_data_numbers.csv"
uk_file_path="./youtube_video_data/GB_video_data_numbers.csv"
# 读取文件
t1=np.loadtxt(us_file_path,delimiter=',',dtype='int')
t2=np.loadtxt(uk_file_path,delimiter=',',dtype='int')
print(t1)
print("-"*50)
print(t2)说明
`csv`格式:`Comma-Seperated value`逗号分隔值文件。通过换行逗号分隔行列的格式化文本,每一行的数据表示一条记录。由于csv方便展示,读入和写入,所以很多地方的也是用csv的格式存储和传输中小型的数据。`np.loadtxt(fname,dtype,delimiter,skiprows,usecol,unpack):`
| 参数 | 解释 |
|
| 文件路径 |
|
| 数据类型,默认是 |
|
| 分隔符,默认是空格 |
|
| 跳过前 |
|
| 读取指定列 |
|
| 默认是 |
读取指定行/列数据
读取某行
# 取某一行
print(t1[1])读取连续的多行
# 取连续的多行
print(t1[:3])
print("-"*50)
print(t2[1:4])读取不连续的多行
# 取不连续的多行
# 注意是两个[]
print(t1[[0,2,3]])
print("-"*50)
print(t2[[1,3,5]])读取某列
# 取列
print(t1[:,0])读取连续/不连续的多列
# 取连续/不连续的多列
print(t1[:,:3])
print("-"*50)
print(t2[:,[0,2,3]])读取某一行某一列,取某几行和某几列交叉
# 取某一行某一列,取某几行和某几列交叉
print(t1[1,2])
print("-"*50)
print(t2[1:4,2:4])取某几个坐标点
# 取某几个点
# 这里要注意一下,取点的坐标的(1,0),(2,1),(4,3).原则是取第一个[]里第i个数和第二个[]里第i个数组成坐标。有更多的维度依次类推
print(t1[[1,2,4],[0,1,3]])布尔索引
代码
# bool索引
a=np.arange(24).reshape(4,6)
a<10效果

三元操作符(where)
代码
import numpy as np
a=np.arange(24).reshape(4,6)
# 使用三元操作符
np.where(a<10,0,12)说明
这个`where`有点像C语言中的 : : 这个操作符。`np.where(a,b,c)`表示如果a为真,则执行`b`,否则执行`c`数组则是数组元素满足a的赋值为b,否则赋值为c)
cilp方法
代码
import numpy as np
a=np.arange(24).reshape(4,6)
# 使用clip方法
a.clip(11,13)说明
`t.clip(a,b)`:把数组t中小于a的赋值为a,大于b的赋值为b
nan
简介
`nan`:`not a number`,不是一个数字,数据类型是`float`
当我们读取本地文件,数据类型为float时,如果有缺失,则会出现nan,或者当做了一个不合适的计算的时候(比如无穷大减去无穷大)
注意点
- 两个`
nan`是不相等的。利用这个特性,判断数组中的`nan`的数量。 `nan`和任何值计算都为`nan`
代码演示
import numpy as np
a=np.nan
print(a)
print(type(a))
print(a==a)import numpy as np
t=np.arange(100,112).reshape(3,4).astype(float)
print(t)
t[1,2]=np.nan
print(t)
print([t==t])
print(t[t==t])
# 小技巧
# 我们可以用t[t==t]来提取出数组中非nan的数据
inf
简介
`inf`:`infinity`,表示正无穷大,`-inf`表示负无穷大。数据类型也是`float`
当一个数字除以0会出现`inf`



![[C语言]一维数组二维数组的大小](https://img-blog.csdnimg.cn/direct/8456245efec84329909bc73c5ac9225c.png)