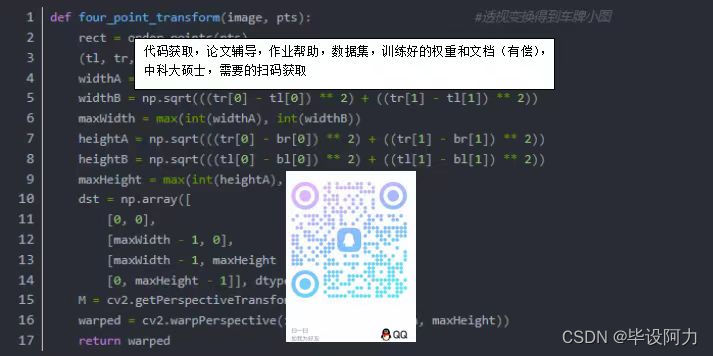
YOLOv7 GUI 是一款用户友好型图形界面应用程序,专为简化基于YOLOv7(You Only Look Once version 7)的目标检测流程而设计。该工具允许用户无需深入掌握命令行操作和复杂编程细节,即可方便快捷地运行YOLOv7模型来检测图像或视频中的物体。
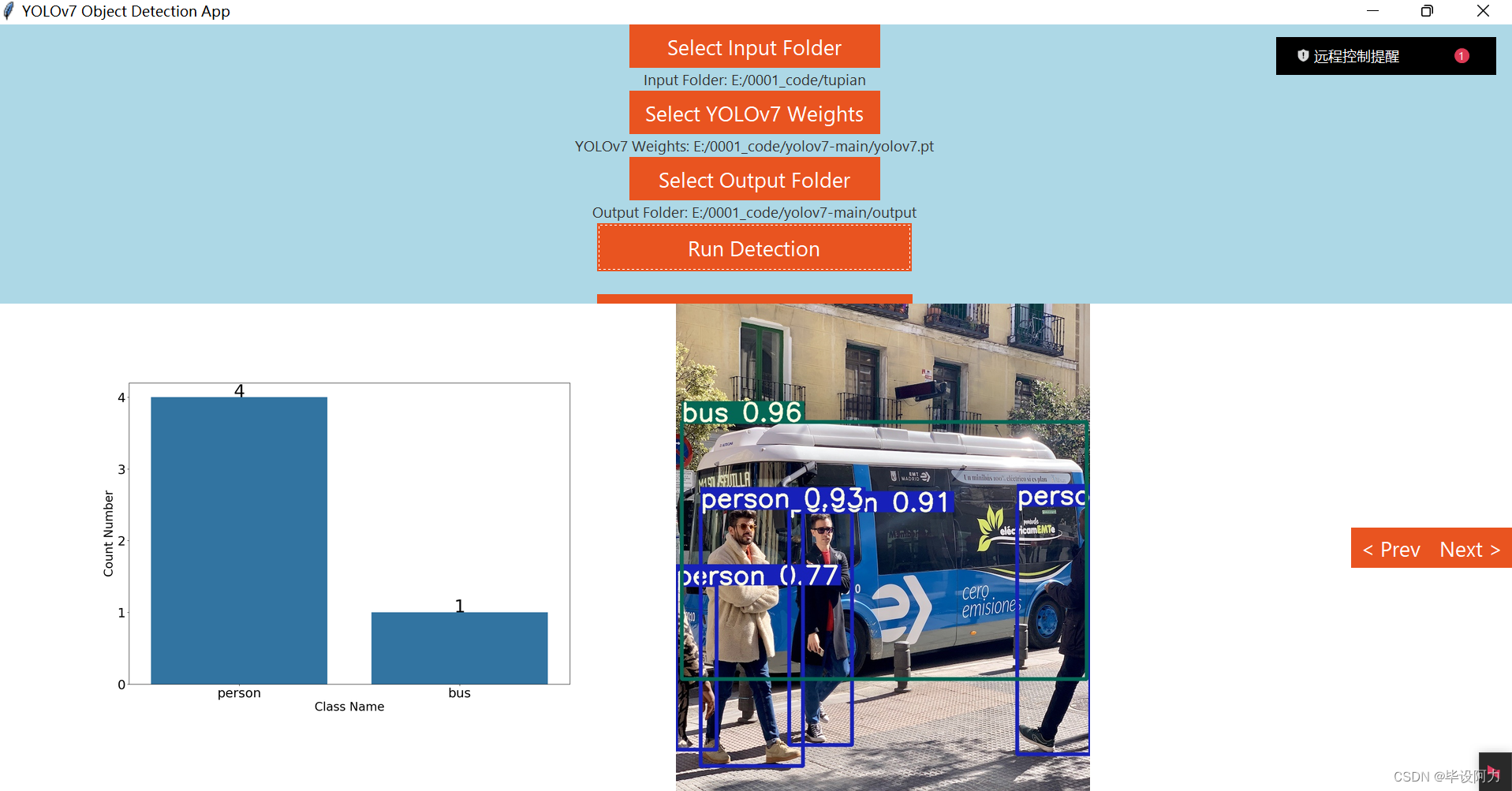
通过直观的图形用户界面,用户可以轻松上传图片或视频文件,然后直接应用预训练的YOLOv7模型进行实时或批量检测。YOLOv7 GUI 还可能提供可视化功能,将检测结果以高亮框的形式叠加在原始图像上,同时支持统计和显示检测到的不同类别物体的数量,并可能以图表形式呈现检测结果的概览。
此外,该GUI应用还可能整合了一些高级特性,如调整检测阈值、选择不同大小的输入以及输出选项等,使得非专业开发人员也能便捷高效地利用YOLOv7的强大性能进行各种场景下的目标检测任务。总的来说,YOLOv7 GUI 将原本复杂的深度学习模型应用过程变得更为简易和直观,极大地提升了用户体验并拓宽了YOLOv7模型的应用范围。

不仅如此,它还能以图表形式展示检测到的对象数量。借助此应用,您无需繁琐的选项或额外代码,即可直接在YOLOv7中分析您的图像数据。
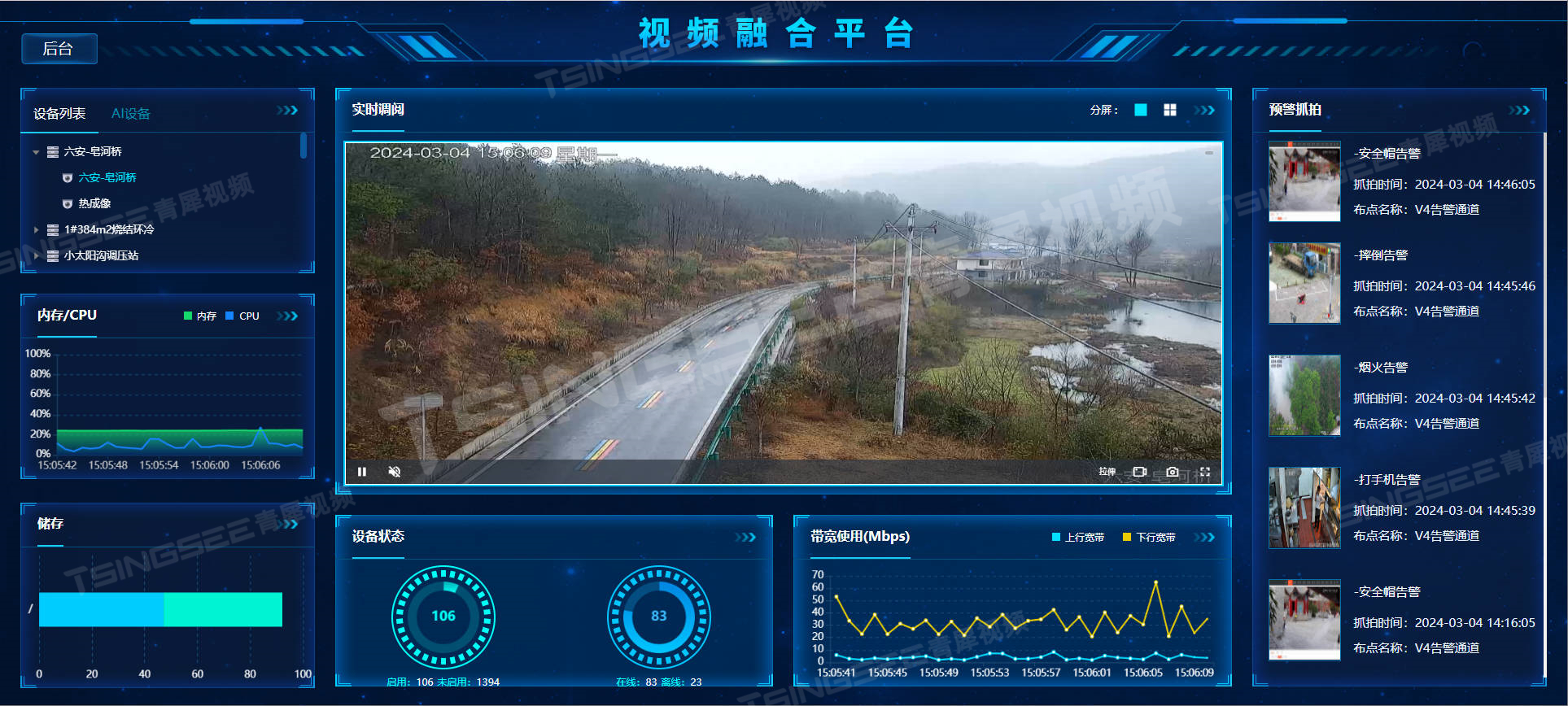
行人车辆计数统计图如下,会在gui界面显示:

准备阶段: 下载仓库并创建虚拟环境
conda create -n yolov7 python=3.10
conda activate yolov7
pip install -r requirements.txt下载yolov7的模型:
使用传统的yolov7的模型。
准备你的素材图片:
应用到你想检测的图片。
运行你的yolov7 gui 应用:
python run_yolov7.py如何操作GUI
1. 点击“选择输入文件夹”:资源管理器将会启动,让你选择已经准备好的图片目录。
2. 点击“选择YOLOv7权重文件”:从资源管理器中选择用于物体检测所用的YOLOv7模型。
3. 点击“选择输出文件夹”:选择一个目录用于输出已检测到物体的图片、注解文件(.txt格式)、汇总物体检测结果的图表以及csv文件。如果尚未创建目录,你可以在资源管理器中新建一个。
4. 点击“运行检测”:物体检测开始执行。同时,进度条会向右移动。当物体检测完成后,GUI会显示出汇总检测数量结果的柱状图以及物体检测后的图片。
5. 物体检测完成后,你可以再次更改输入文件夹或YOLOv7模型以检测新的物体。
6. 结束物体检测:点击GUI屏幕右上角的×按钮退出应用。
* 注意:在GUI中第二次显示物体检测结果时,界面可能会出现一些bug。但物体检测的结果会无误地输出至输出文件夹。我们会在未来修复这个问题。

有问题可咨询: