本次分享论文为:Enhancing Static Analysis for Practical Bug Detection: An LLM-Integrated Approach
基本信息
原文作者:Haonan Li, Yu Hao, Yizhuo Zhai, Zhiyun Qian
作者单位:加州大学河滨分校
关键词:静态分析、错误检测、大语言模型
原文链接:
https://www.cs.ucr.edu/~zhiyunq/pub/oospla24_llift.pdf
开源代码:暂无
论文要点
论文简介:本文提出了一种名为LLift的框架,这是一个先进的自动化工具,旨在通过集成大语言模型(LLMs)来增强静态分析在错误检测中的能力。特别是,研究聚焦于识别Linux内核中的使用前初始化(UBI)错误。通过在路径敏感分析中引入后约束引导的路径分析优化,并结合精心设计的过程,LLift能够高效处理特定错误建模、大规模代码库的挑战以及LLMs的不可预测性。实际评估表明,LLift在主流Linux内核中成功识别了四个之前未被发现的UBI错误,这些错误已得到Linux社区的认可。
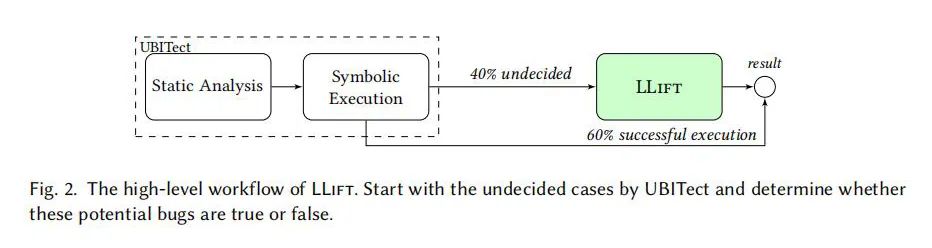
研究背景:尽管静态分析在发现软件错误方面起着重要作用,但在分析大型且复杂的代码库时,其精确性面临挑战。现有的静态分析工具在处理如Linux内核这样的大型软件项目时,往往会因为缺乏路径敏感性而产生大量误报。此外,传统静态分析方法在分析复杂函数和循环结构时也会遇到困难。
研究贡献:
1.新的机遇:首次展示了利用LLMs克服静态分析限制、增强其查找错误能力的方法。
2.后约束引导路径分析:在大规模代码库的实际错误检测中利用后约束引导的路径剪枝,有效增强了静态分析在路径敏感分析中的能力。
3.利用LLMs的方法论:开发了LLift,这是一个创新且完全自动化的框架。LLift采用多种策略与LLMs交互,获得准确可靠的响应。
4.结果:通过对近300个UBITect未定案例的严格调查,LLift展现了合理的精确率(50%)并且没有发现遗漏的错误。此外,LLift从UBITect中发现了13个未被发现的错误,其中四个已被Linux社区确认为真实错误。
引言
静态分析一直是理解程序行为、提高代码质量、可靠性和安全性的重要工具。在错误发现领域,它提供了一种主动机制,能在代码投入生产前发现错误。然而,现代软件的复杂性,如Linux内核等大型代码库,挑战了静态分析的极限。本文提出的LLift框架,通过将静态分析和大语言模型(LLMs)的能力结合起来,为静态分析在错误检测中的应用开辟了新的方向。
背景知识
本文详细介绍了静态分析在实践中面临的一般挑战,包括知识边界的固有问题和穷尽路径探索的问题。此外,还探讨了大语言模型(LLMs)的能力,如何“绕过”这些挑战,提供了一种灵活的方式总结代码行为,这为解决静态分析的固有挑战提供了新的思路。
论文方法
理论背景:通过引入后约束引导的路径分析来优化路径敏感分析,聚焦于触发错误的约束,可以减少探索路径,使复杂漏洞分析更加精确。
方法实现:解决集成LLMs到静态分析中,用于错误识别的挑战和潜在的解决方案。LLift框架展示了静态分析和LLMs能力的无缝集成。
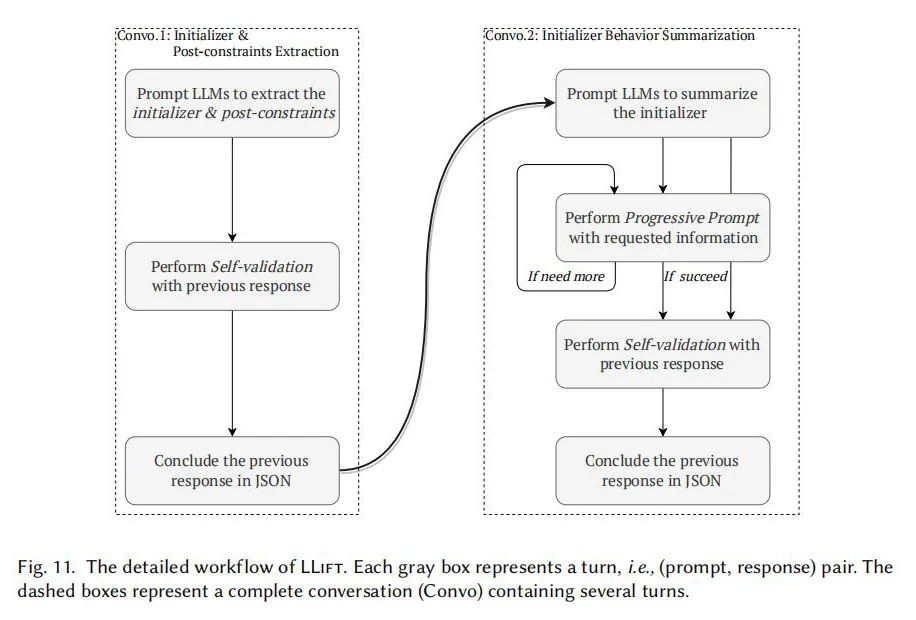
实验
实验设置:LLift主要在Linux内核上进行评估。利用UBITect在Linux内核中标识的未决UBI警告(对Linux内核来说是40%),识别了四个新的错误。
实验结果:通过融合优化的路径分析和LLMs的判别能力,LLift在新时代的错误识别领域推动了静态分析的发展。本文记录了这一探索过程,详细介绍了我们的策略和从实践中获得的见解。
论文结论
在这项研究中,研究人员引入了 LLift,这是一个突破性的框架,它通过集成大语言模型 (LLM) 来增强静态分析,以有效且高效地检测通用缓冲区溢出 (UBI) 漏洞。通过采用后约束引导分析,LLift 改进了路径验证能力,解决了复杂的漏洞挑战。通过一系列及时的策略,LLift 有效地利用法学硕士来确保其输出的可靠性和一致性。测试证明了LLift的效率,识别出Linux内核中的13个新的UBI漏洞,准确率达到50%。这项研究凸显了法学硕士与静态分析相结合的潜力,为该领域的未来探索奠定了基础。
原作者:论文解读智能体
润色:Fancy
校对:小椰风