:::info
💡 在sora笔记(一):sora前世今生与技术梗概 一文中介绍了目前未开源的sora模型可能涉及到的技术点,包括介绍了Vision Transformer,作为transformer正式用于图像的一种范式,为本文中将提到的内容打下基础,同时sora笔记(二):diffusion model推导 一文对diffusion model的数学原理推导,也为后来模型的演化提供更加完整的认识。而本文将要介绍的是后来的ViViT与DiT两种模型架构,并对其进行了更进一步的源码分析。
:::
Vision Transformer(ViT)
| 📒** 论文名** | 《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》 |
|---|---|
| 🔍** 地址** | https://arxiv.org/abs/2010.11929 |
| ⛳** Official repo** | https://github.com/google-research/vision_transformer |
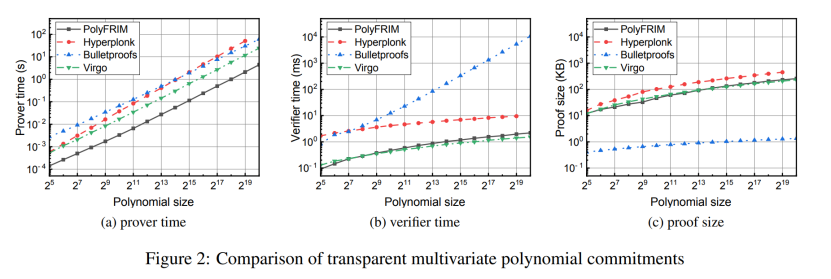
Vision Transformer (ViT) 模型由 Alexey Dosovitskiy 等人在 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 中提出。这是第一篇在 ImageNet 上成功训练 Transformer 编码器的论文,与熟悉的卷积架构相比,取得了非常好的结果。论文提出,虽然 Transformer 架构已成为自然语言处理任务事实上的标准,但其在计算机视觉中的应用仍然有限。 在视觉中,attention 要么与卷积网络结合应用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。 ViT 证明这种对 CNN 的依赖是不必要的,直接应用于图像块序列(patches)的纯 Transformer 可以在图像分类任务上表现良好。 当对大量数据进行预训练并转移到多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,Vision Transformer (ViT) 与 SOTA 的 CNN 相比取得了优异的结果,同时需要更少的计算资源来训练,Vision Transformer (ViT) 基本上是 Transformers,但应用于图像。
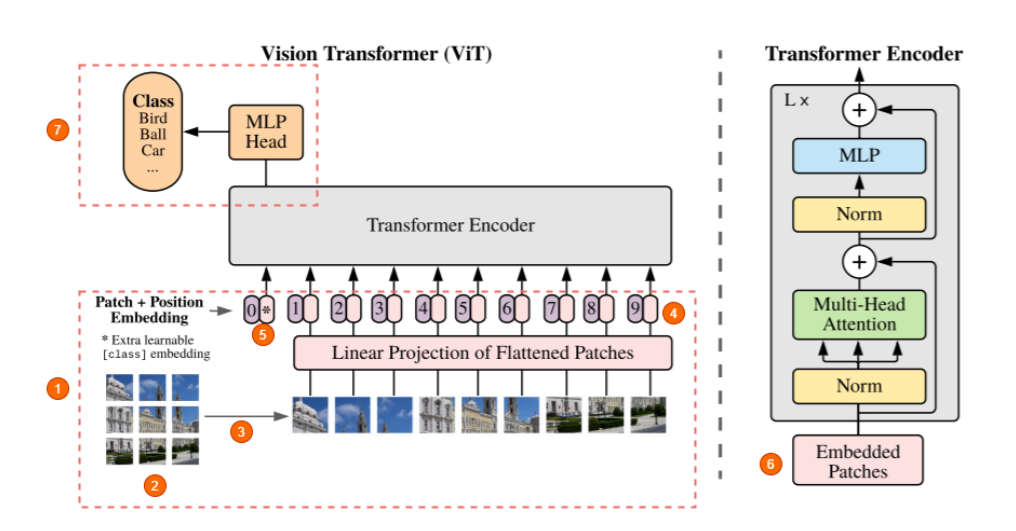
- 只使用transformer的编码器部分,但区别在于如何将图像输入网络
- 将图像分解成固定大小的patches。可以是16x16或32x32,或者更大,但更多的patches意味着随着patches本身变得更小,训练这些网络变得更简单。
- 将patches展开(压平,即将二维转化为一维向量)并发送到网络中进行进一步处理。
- 与神经网络不同,这里的模型对样本在序列中的位置一无所知,这里的每个样本都是来自输入图像的一个patches。因此,图像被连同positional embedding vector一起提供到encoder中。这里需要注意的一点是位置嵌入也是可学习的,所以实际上不需要将硬编码的向量 w.r.t 提供给它们的位置。
- 在开始时还有一个特殊的标记,就像 BERT 一样。
- 将一维(压平)的patches组成一个大矢量,并得到乘以一个embedding矩阵,这也是可学习的,创建embedding patches。将这些与位置向量相结合,输入到transformer中。
- 前馈神经网络MLP Header,并获取到分类输出。
这里内容为第一篇中sora笔记(一):sora前世今生与技术梗概 内容,作为后续展开的引用,就不再此过多介绍,可回看之前的代码。
ViViT: 视频ViT
| 📒** 论文名** | 《Arnab, Anurag, et al. “Vivit: A video vision transformer.” ICCV2021》 |
|---|---|
| 🔍** 地址** | https://arxiv.org/pdf/2103.15691.pdf |
| ⛳** Official repo** | https://github.com/google-research/scenic/tree/main/scenic/projects/vivit |
作者使用了基于transfomer的方法做视频分类。模型从视频中提取时间和空间的token。为了解决视频中的长序列问题,作者提出了一些有效的方法在模型中。Transformer通常需要大规模的数据集。作者通过有效的正则方法,让模型在相对小的数据集上也能训练。模型在Kinetics-400,600, Epic Kitchens, Something-Somethingv2和 Moments in Time上都取得了SOTA。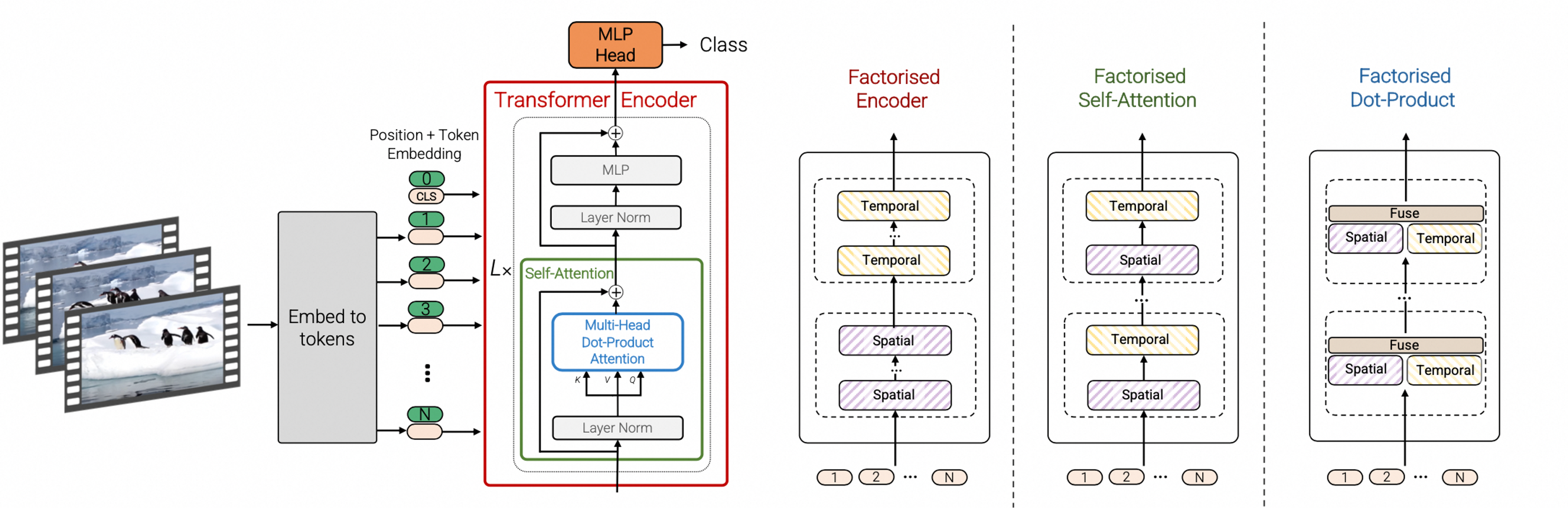
ViViT(Vision Vision Transformer)是对传统的ViT(Vision Transformer)模型的改进和扩展。它在以下几个方面进行了创新:
-
**Tubelet Embedding:**ViViT引入了Tubelet Embedding的概念,将图像分成多个连续的子图像块(称为tubelets),并对每个tubelet进行嵌入。这样做的好处是可以捕捉到图像中更多的局部信息,从而提高模型对细节和空间关系的感知能力。
-
**Positional Encoding:**ViViT使用了Positional Encoding来引入图像的位置信息。除了原始的绝对位置编码,ViViT还引入了相对位置编码,以便模型能够更好地理解不同图像区域之间的相对位置关系。
-
**分级注意力机制:**ViViT引入了分级注意力机制,即将注意力机制应用于不同层级的图像表示。这样做的好处是可以同时关注全局和局部特征,使模型能够更好地处理不同尺度的信息。
Tubelet Embedding 和 Positional Encoding
一个视频V有4个维度
T
∗
H
∗
W
∗
C
T * H * W * C
T∗H∗W∗C。 变成一个序列token就是
N
t
∗
N
h
∗
N
w
∗
d
Nt * Nh * Nw * d
Nt∗Nh∗Nw∗d。加上位置编码, 变成transformer的输入
N
∗
d
N * d
N∗d。从视频中用统一的采样频率,抽取n帧。所有的帧都是用和Vit一样的embedding方法,拼接所有的tokens。将会有个token输入到transformer encoder。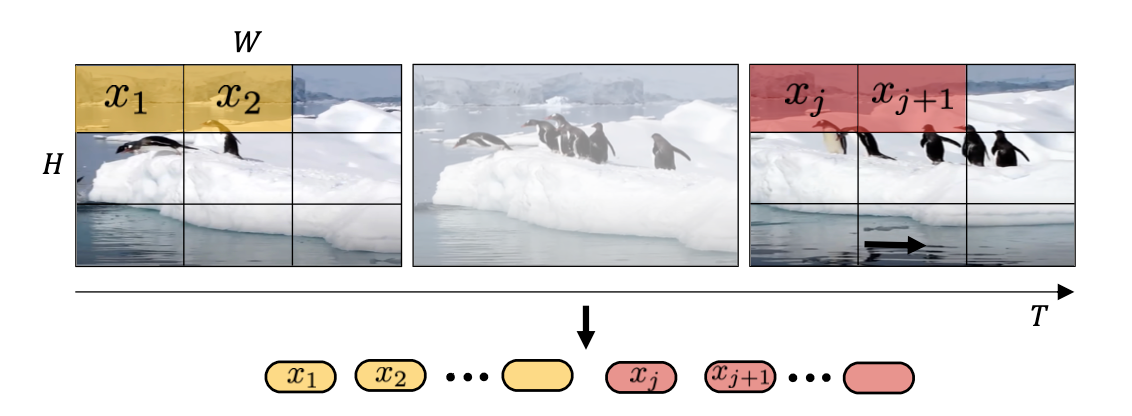
代码为:
class PatchEncoder(L.Layer):
def __init__(self, num_patches, projection_dim):
super(PatchEncoder, self).__init__()
self.num_patches = num_patches
self.projection = L.Dense(units = projection_dim)
self.position_embedding = L.Embedding(
input_dim = num_patches, output_dim = projection_dim
)
def call(self, patch):
positions = tf.range(start = 0, limit = self.num_patches, delta = 1)
encoded = self.projection(patch) + self.position_embedding(positions)
return encoded
而ViViT采取的embedding的方式如下图所示: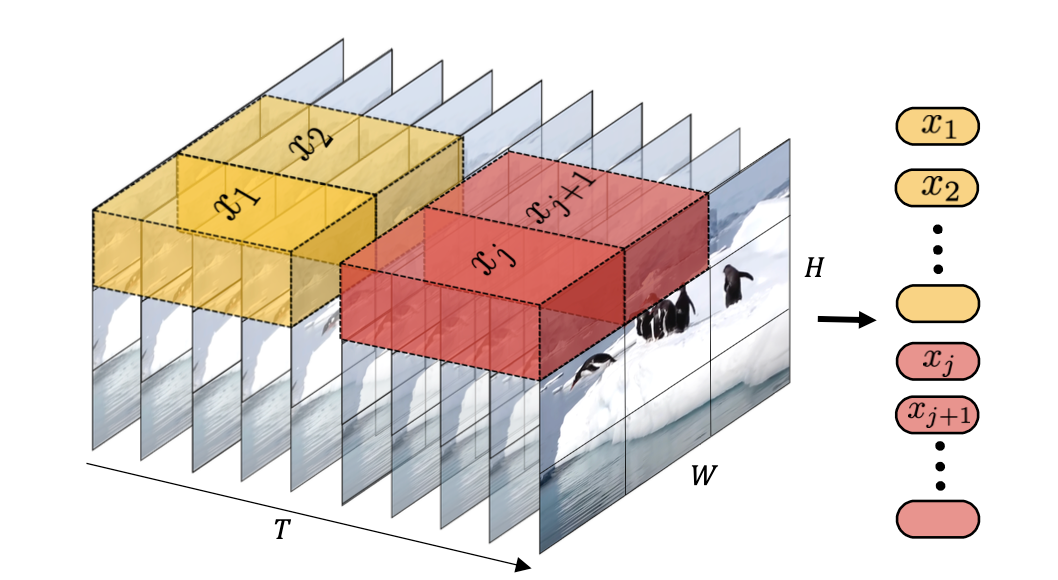
Tubelet Embedding在捕获视频中的时间信息方面与传统方法不同的地方。它首先从视频中提取出体积(tubelet),这些体积包含帧的补丁和时间信息,然后将这些体积展平以构建视频令牌。代码为:
class TubeletEmbedding(layers.Layer):
def __init__(self, embed_dim, patch_size, **kwargs):
super().__init__(**kwargs)
self.projection = layers.Conv3D(
filters=embed_dim,
kernel_size=patch_size,
strides=patch_size,
padding="VALID",
)
self.flatten = layers.Reshape(target_shape=(-1, embed_dim))
def call(self, videos):
projected_patches = self.projection(videos)
flattened_patches = self.flatten(projected_patches)
return flattened_patches
class PositionalEncoder(layers.Layer):
def __init__(self, embed_dim, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
def build(self, input_shape):
_, num_tokens, _ = input_shape
self.position_embedding = layers.Embedding(
input_dim=num_tokens, output_dim=self.embed_dim
)
self.positions = tf.range(start=0, limit=num_tokens, delta=1)
def call(self, encoded_tokens):
# Encode the positions and add it to the encoded tokens
encoded_positions = self.position_embedding(self.positions)
encoded_tokens = encoded_tokens + encoded_positions
return encoded_tokens
分级注意力机制
该篇作者提出了 Vision Transformer 的 4 种变体。
- 时空注意力(Spatio-Temporal Attention):
- 传统的自注意力机制只考虑了一维序列的上下文关系,但在视频处理任务中,时空关系也是非常重要的。时空注意力引入了时间维度的关注,使得模型能够同时捕捉到时间和空间上的关系。
- 在时空注意力中,输入是一个三维的特征张量,表示为(时间步长,空间高度,空间宽度)。通过将时间步长看作序列长度,空间高度和宽度看作特征维度,可以将自注意力机制应用于时空领域。
- 因式分解编码器(Factorized Encoder):
- 传统的Transformer编码器需要对输入序列进行全连接操作,这会导致计算复杂度较高。因此,VIVIT模型提出了因式分解编码器,通过将全连接操作分解为多个较小的矩阵乘法操作来降低计算复杂度。
- 因式分解编码器使用了一个低秩的近似矩阵,将输入特征映射到一个较低维度的空间中,然后再进行多个小规模的矩阵乘法操作。这样可以在一定程度上减少计算量,同时保持较好的性能。
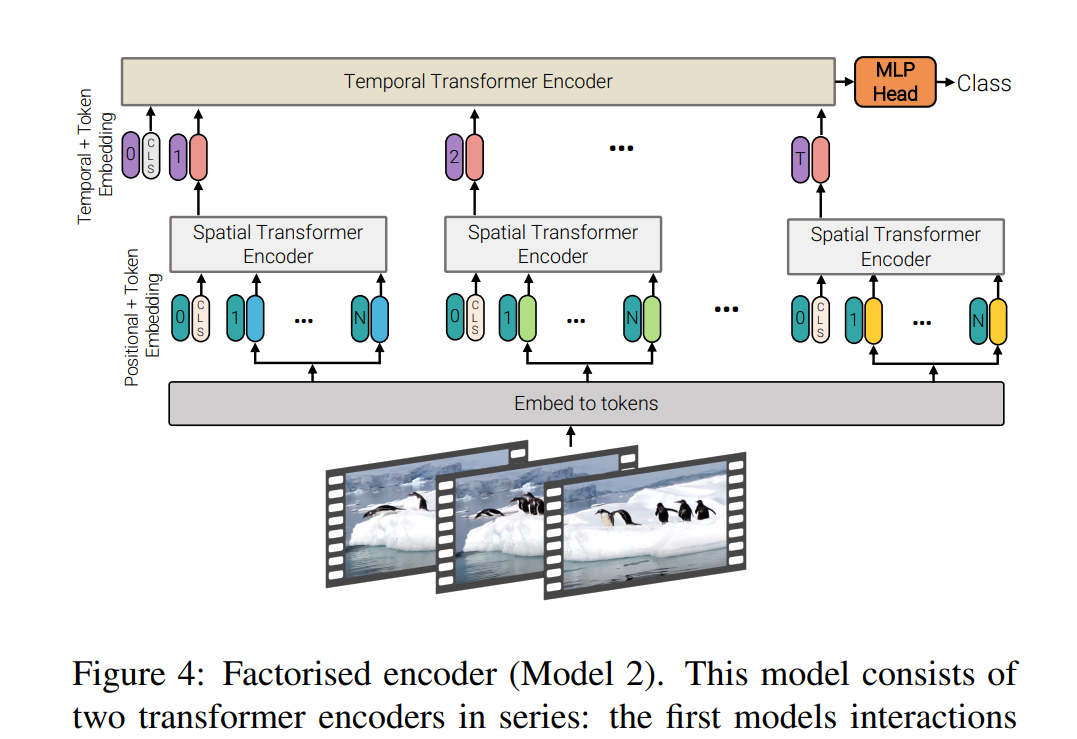
- 因式分解的自注意力(Factorized Self-Attention):
- 自注意力机制是Transformer中的核心组件,但在长序列处理中,计算复杂度较高。为了降低计算复杂度,VIVIT模型引入了因式分解的自注意力。
- 因式分解的自注意力将自注意力机制分解为两个步骤:局部自注意力和全局自注意力。首先,在每个时间步长上,只计算局部的自注意力权重,以捕捉局部的依赖关系。然后,使用全局自注意力将这些局部信息整合起来,以获取全局的上下文表示。
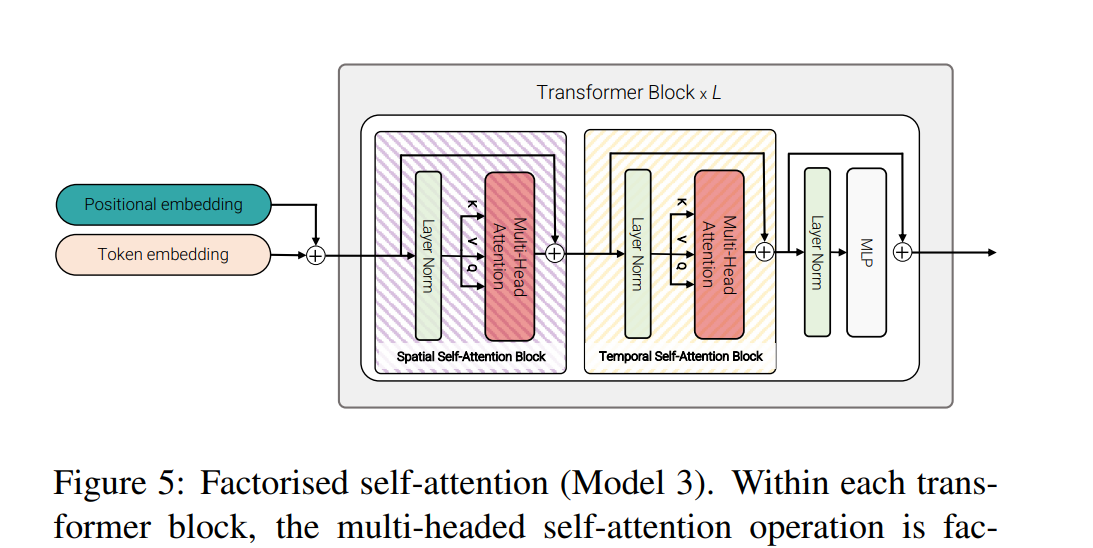
- 因式分解点积注意力(Factorized Dot-Product Attention):
- 点积注意力是自注意力机制中常用的计算方式,但在长序列处理中,计算复杂度较高。为了降低计算复杂度,VIVIT模型提出了因式分解点积注意力。
- 因式分解点积注意力将点积操作分解为两个步骤:投影和点积。首先,通过将输入特征映射到较低维度的空间中,实现了计算量的减少。然后,在较低维度空间上进行点积操作来计算注意力权重。
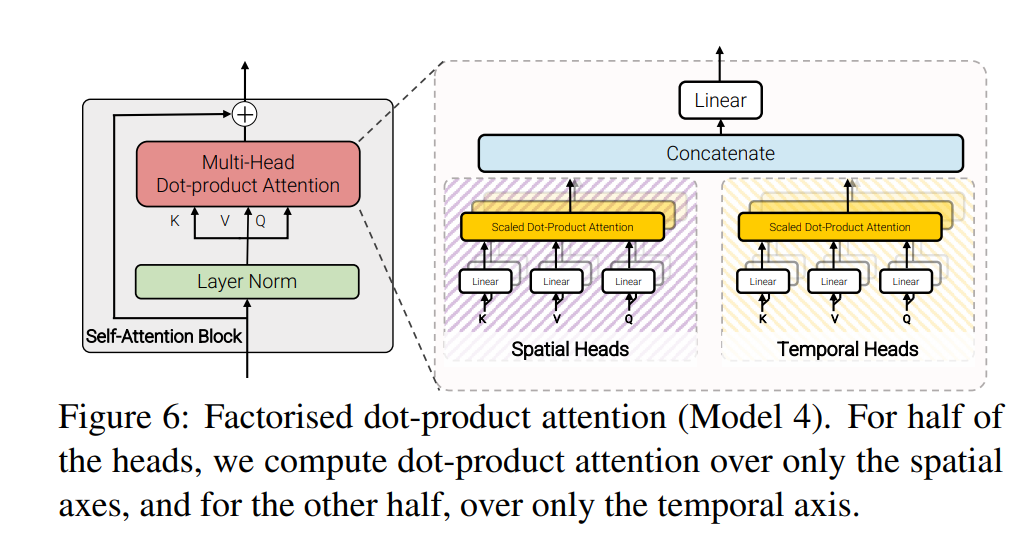
以上transformer四种变体代码理解可参考ViViT: A Video Vision Transformer阅读和代码 ,Mark一下,jax的代码与pytorch还是很相似的。
模型实践
本节做了一个小实验,取fight-detection-surv-dataset和movies-fight-detection-dataset两份视频数据集(reference给出)总共500份样本,将其都resize到(128,128,3)的比例,其中正负样本即fight非fight的都为250份,分割成330份(训练)、37份(验证)和93份(测试),为简单起见,考虑时空注意力机制,代码为:
def create_vivit_classifier(
tubelet_embedder,
positional_encoder,
input_shape=INPUT_SHAPE,
transformer_layers=NUM_LAYERS,
num_heads=NUM_HEADS,
embed_dim=PROJECTION_DIM,
layer_norm_eps=LAYER_NORM_EPS,
num_classes=NUM_CLASSES,
):
# Get the input layer
inputs = layers.Input(shape=input_shape)
# Create patches.
patches = tubelet_embedder(inputs)
# Encode patches.
encoded_patches = positional_encoder(patches)
# Create multiple layers of the Transformer block.
for _ in range(transformer_layers):
# Layer normalization and MHSA
x1 = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
attention_output = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim // num_heads, dropout=0.1
)(x1, x1)
# Skip connection
x2 = layers.Add()([attention_output, encoded_patches])
# Layer Normalization and MLP
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
x3 = keras.Sequential(
[
layers.Dense(units=embed_dim * 4, activation=tf.nn.gelu),
layers.Dense(units=embed_dim, activation=tf.nn.gelu),
]
)(x3)
# Skip connection
encoded_patches = layers.Add()([x3, x2])
# Layer normalization and Global average pooling.
representation = layers.LayerNormalization(epsilon=layer_norm_eps)(encoded_patches)
representation = layers.GlobalAvgPool1D()(representation)
# Classify outputs.
outputs = layers.Dense(units=num_classes, activation="softmax")(representation)
# Create the Keras model.
model = keras.Model(inputs=inputs, outputs=outputs)
return model
训练日志与history可视化为:
Epoch 1/60
83/83 [==============================] - 6s 34ms/step - loss: 0.6797 - accuracy: 0.6254 - recall_m: 0.9398 - precision_m: 0.4920 - f1_m: 0.6192 - val_loss: 0.5349 - val_accuracy: 0.7568 - val_recall_m: 0.9000 - val_precision_m: 0.4750 - val_f1_m: 0.6038
Epoch 2/60
83/83 [==============================] - 2s 29ms/step - loss: 0.6815 - accuracy: 0.5891 - recall_m: 0.8916 - precision_m: 0.4940 - f1_m: 0.6091 - val_loss: 0.5532 - val_accuracy: 0.7027 - val_recall_m: 0.9000 - val_precision_m: 0.4750 - val_f1_m: 0.6038
......
Epoch 59/60
83/83 [==============================] - 2s 29ms/step - loss: 0.0682 - accuracy: 0.9668 - recall_m: 0.9639 - precision_m: 0.4930 - f1_m: 0.6273 - val_loss: 1.1690 - val_accuracy: 0.7297 - val_recall_m: 0.9000 - val_precision_m: 0.4750 - val_f1_m: 0.6038
Epoch 60/60
83/83 [==============================] - 2s 27ms/step - loss: 0.0858 - accuracy: 0.9668 - recall_m: 0.9277 - precision_m: 0.4940 - f1_m: 0.6162 - val_loss: 0.9938 - val_accuracy: 0.7297 - val_recall_m: 0.9000 - val_precision_m: 0.4750 - val_f1_m: 0.6038
24/24 [==============================] - 1s 13ms/step - loss: 1.1741 - accuracy: 0.7312 - recall_m: 0.9583 - precision_m: 0.6146 - f1_m: 0.7310
Test accuracy: 73.12%
Test recall: 95.83%
Test precision: 61.46%
Test F1: 73.1%
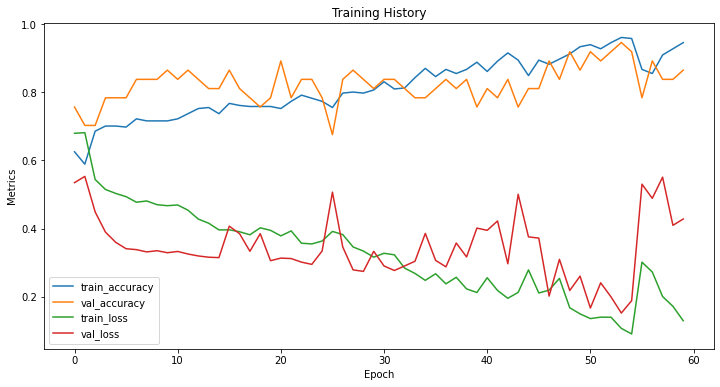
这里选用了60个epoch,其余都是常规参数,但看起来波动范围较大,考虑还是样本较小,分布一般,但还说得过去,根据keras的文档介绍,与另一种CNN-RNN的模型结构分类做对比,画出相应的混淆矩阵热力图,结果如下: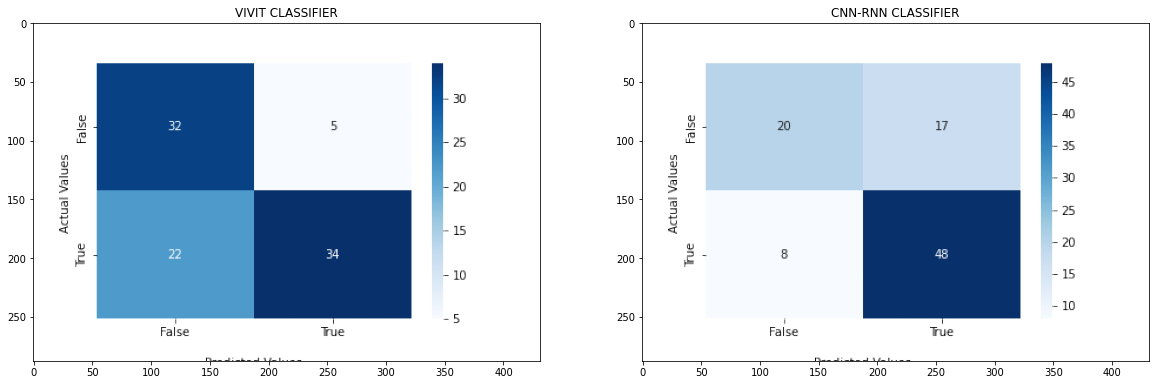
同为60个epoch,感觉半斤八两,emmm,大概率是数据集一般了。可以做测试样本的图像以及它们对应的真实标签和模型预测标签的网格展示为:
DiT:Scalable Diffusion Models with Transformers
| 📒** 论文名** | 《Scalable Diffusion Models with Transformers》 |
|---|---|
| 🔍** 地址** | https://arxiv.org/abs/2212.09748 |
| ⛳** Official repo** | https://github.com/facebookresearch/DiT |
机器学习正在经历一场由基于 self-attention 的 Transformer 的革命。 在过去的五年中,用于自然语言处理的神经架构、基础视觉模型和其他几个重要的领域在很大程度上都被 transformers 纳入了统一的大框架中。在统一大模型上,ViT 似乎已经逐渐取代了 CNN 原有的江湖地位,开始成为主流视觉架构的基本模型,但 U-Net 在扩散模型领域仍然一枝独秀,无论是带领 text-to-image 出圈的 DALL·E2,还是真正引发人们对图像生成文本模型讨论的 Stable Diffusion,都采用了 U-Net 的结构进行编码,而没有使用 Transformer 作为图像生成架构。但是 self-attention 的思想显然能带给模型选择更多的灵活性,那么能否将 Transformer 与 diffusion 的生成过程进行结合呢?kaiming 在 Meta 重要的合作者 Saining Xie 大神(但现在应该跳槽去了 New York University)给出了肯定的回答。
架构为: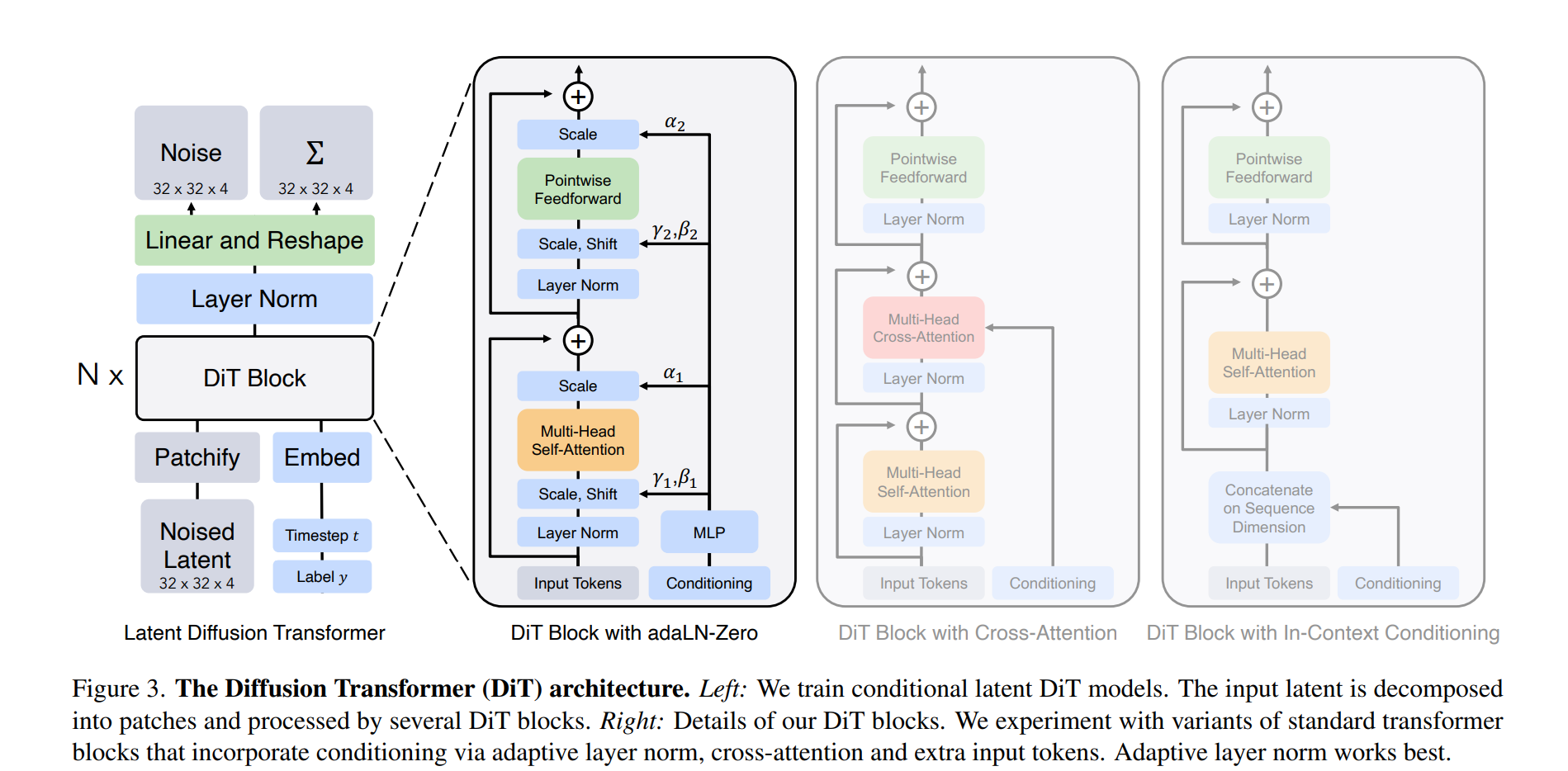
模型设计和创新
DiT主要的创新点同样提出了四种transformer block变体。具体为:
- In-context conditioning:
- 将条件信息 t t t和 c c c的向量嵌入为输入序列中的附加标记,与图像标记一起处理。
- 通过在最后一个块之后从序列中删除条件标记,实现了对条件信息的处理,增加的计算量可以忽略。
- Cross-attention block:
- 将条件信息 t t t和 c c c的embedding与图像的token序列分开处理,形成长度为2的序列。
- 在多头自注意块之后引入额外的多头交叉注意层,类似于LDM用于调节类标签。
- 带来的计算量增加约15%,提高了模型的表达能力和适应性。
- Adaptive layer norm (adaLN) block:
- 探索使用Adaptive layer norm替换transformer块中的标准正则化方式。
- 通过从 t t t和 c c c的嵌入向量的总和中,回归参数 r r r和 β \beta β,提高了正则化效果,同时添加的计算量最少,计算效率最高。
- adaLN-Zero block:
- 引入维度缩放参数 r r r,并初始化MLP以输出所有 a a a的零向量,将整个DiT块初始化为恒等函数。
- 除了回归 r r r和 β \beta β,还有回归参数 a a a,增强了对模型内部结构的控制。
- 类似于ResNets和基于U-Net的模型的初始化策略,使得模型更容易训练和收敛。
作者针对其提出的四种变体在FID-50K 数据集上进行了测试,如下图所示: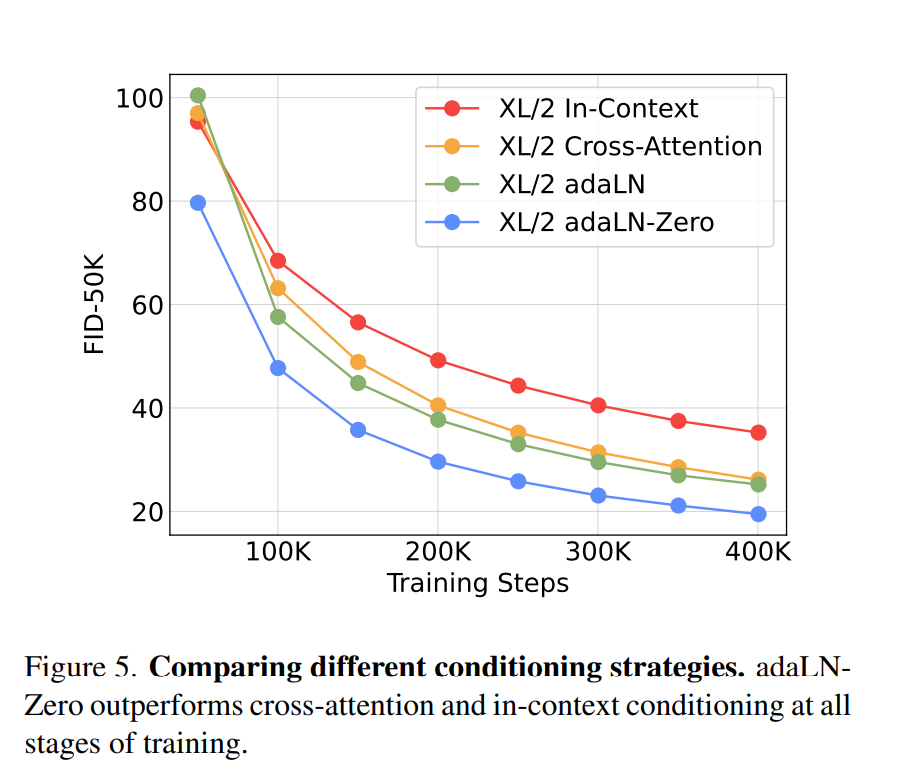
从图中可以很明显看出,第四种变体效果更好。而作者所采用的也是该种方案,整个dit代码为:
# https://github.com/facebookresearch/DiT/blob/main/models.py
class DiT(nn.Module):
"""
Diffusion model with a Transformer backbone.
"""
def __init__(
self, input_size=32,patch_size=2, in_channels=4, hidden_size=1152,depth=28,num_heads=16, mlp_ratio=4.0,
class_dropout_prob=0.1,num_classes=1000,learn_sigma=True,
):
super().__init__()
self.learn_sigma = learn_sigma
self.in_channels = in_channels
self.out_channels = in_channels * 2 if learn_sigma else in_channels
self.patch_size = patch_size
self.num_heads = num_heads
self.x_embedder = PatchEmbed(input_size, patch_size, in_channels, hidden_size, bias=True)
self.t_embedder = TimestepEmbedder(hidden_size)
self.y_embedder = LabelEmbedder(num_classes, hidden_size, class_dropout_prob)
num_patches = self.x_embedder.num_patches
# Will use fixed sin-cos embedding:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, hidden_size), requires_grad=False)
self.blocks = nn.ModuleList([
DiTBlock(hidden_size, num_heads, mlp_ratio=mlp_ratio) for _ in range(depth)
])
self.final_layer = FinalLayer(hidden_size, patch_size, self.out_channels)
self.initialize_weights() # 初始化模型的权重和其他参数。
def initialize_weights(self):
# Initialize transformer layers:
def _basic_init(module):
if isinstance(module, nn.Linear):
torch.nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.constant_(module.bias, 0) # 用于初始化线性层 (nn.Linear) 的权重。Xavier 初始化方法初始化权重,并将偏置(如果存在的话)初始化为零。
self.apply(_basic_init) # _basic_init 函数应用到模型的所有子模块上。这意味着该函数将被递归地应用到模型的所有子模块(包括嵌套的子模块)的权重初始化过程中。
# Initialize (and freeze) pos_embed by sin-cos embedding:
pos_embed = get_2d_sincos_pos_embed(self.pos_embed.shape[-1], int(self.x_embedder.num_patches ** 0.5)) # 生成 sin-cos 编码的位置嵌入
self.pos_embed.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0)) # 将生成的位置嵌入复制到模型的 pos_embed 参数中。
# Initialize patch_embed like nn.Linear (instead of nn.Conv2d):
w = self.x_embedder.proj.weight.data # patch_embed 模块的权重参数
nn.init.xavier_uniform_(w.view([w.shape[0], -1])) # 使用 Xavier 初始化方法对 patch_embed 模块的权重参数进行初始化。
nn.init.constant_(self.x_embedder.proj.bias, 0) # 将 patch_embed 模块的偏置参数 bias 初始化为常数 0。确保模型的初始输出为零。
# Initialize label embedding table:
nn.init.normal_(self.y_embedder.embedding_table.weight, std=0.02) # 初始化标签嵌入表 embedding_table 的权重。对其权重进行正态分布初始化,标准差为 0.02,来随机初始化这些权重。
# Initialize timestep embedding MLP:
nn.init.normal_(self.t_embedder.mlp[0].weight, std=0.02) # 初始化时间步嵌入的多层感知机(MLP)的权重。
nn.init.normal_(self.t_embedder.mlp[2].weight, std=0.02) # 对权重进行正态分布初始化,标准差为 0.02,来随机初始化这些权重。
# Zero-out adaLN modulation layers in DiT blocks:
for block in self.blocks:
nn.init.constant_(block.adaLN_modulation[-1].weight, 0)
nn.init.constant_(block.adaLN_modulation[-1].bias, 0) # 将 DiTBlock 中最后一个自适应层归一化(adaLN)模块的权重和偏置初始化为常数 0。
# Zero-out output layers:
nn.init.constant_(self.final_layer.adaLN_modulation[-1].weight, 0)
nn.init.constant_(self.final_layer.adaLN_modulation[-1].bias, 0)
nn.init.constant_(self.final_layer.linear.weight, 0)
nn.init.constant_(self.final_layer.linear.bias, 0)
def unpatchify(self, x): # 将输入的张量 x 转换为图像。
"""
x: (N, T, patch_size**2 * C)
imgs: (N, H, W, C)
"""
c = self.out_channels
p = self.x_embedder.patch_size[0]
h = w = int(x.shape[1] ** 0.5)
assert h * w == x.shape[1]
x = x.reshape(shape=(x.shape[0], h, w, p, p, c))
x = torch.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape(shape=(x.shape[0], c, h * p, h * p))
return imgs # 该方法返回了一个形状为 (N, C, H * P, W * P) 的张量,表示由输入张量 x 重构的图像。
def forward(self, x, t, y):
"""
Forward pass of DiT.
x: (N, C, H, W) tensor of spatial inputs (images or latent representations of images)
t: (N,) tensor of diffusion timesteps
y: (N,) tensor of class labels
"""
x = self.x_embedder(x) + self.pos_embed # (N, T, D), where T = H * W / patch_size ** 2 # 将输入图像转换为序列形式,并加入位置信息。
t = self.t_embedder(t) # (N, D) # 与输入张量相同形状的时间步嵌入
y = self.y_embedder(y, self.training) # (N, D) # 类别标签 y 输入到 y_embedder 模块中
c = t + y # (N, D) # 时间步嵌入和类别嵌入相加,得到条件信息 c
for block in self.blocks:
x = block(x, c) # (N, T, D) # 将输入张量 x 和条件信息 c 传递给每个模块,以获取转换后的张量 x。这一步通过模型的多个块,对输入序列进行处理和转换,以捕获图像的特征。
x = self.final_layer(x, c) # (N, T, patch_size ** 2 * out_channels) # 转换后的张量 x 和条件信息 c 输入
x = self.unpatchify(x) # (N, out_channels, H, W) # 将张量 x 转换回图像的形式。
return x
def forward_with_cfg(self, x, t, y, cfg_scale):
"""
Forward pass of DiT, but also batches the unconditional forward pass for classifier-free guidance.
"""
# https://github.com/openai/glide-text2im/blob/main/notebooks/text2im.ipynb
half = x[: len(x) // 2]
combined = torch.cat([half, half], dim=0) # 将 half 两次拼接起来,形成一个与原始输入大小相同的张量 combined。这是为了复制一份输入,以便同时进行无条件的前向传播和有条件的分类器自由指导。
model_out = self.forward(combined, t, y)
# For exact reproducibility reasons, we apply classifier-free guidance on only
# three channels by default. The standard approach to cfg applies it to all channels.
# This can be done by uncommenting the following line and commenting-out the line following that.
# eps, rest = model_out[:, :self.in_channels], model_out[:, self.in_channels:]
eps, rest = model_out[:, :3], model_out[:, 3:]
cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0) # 将 eps 分成两半,分别表示有条件的部分 cond_eps 和无条件的部分 uncond_eps。这是为了实现分类器自由指导。
half_eps = uncond_eps + cfg_scale * (cond_eps - uncond_eps) # 进行混合,通过调整 cfg_scale 参数来控制有条件部分对最终结果的影响程度。这一步是分类器自由指导的关键部分。
eps = torch.cat([half_eps, half_eps], dim=0) # 混合后的结果重新拼接成完整的张量 eps,以便与 rest 进行合并。
return torch.cat([eps, rest], dim=1)
class TimestepEmbedder(nn.Module):
"""
Embeds scalar timesteps into vector representations.
"""
def __init__(self, hidden_size, frequency_embedding_size=256):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(frequency_embedding_size, hidden_size, bias=True),
nn.SiLU(),
nn.Linear(hidden_size, hidden_size, bias=True),
)
self.frequency_embedding_size = frequency_embedding_size
@staticmethod
def timestep_embedding(t, dim, max_period=10000): # 生成时间步骤的嵌入向量,采用了一种基于正弦和余弦函数的方法。
"""
Create sinusoidal timestep embeddings.
:param t: a 1-D Tensor of N indices, one per batch element. # t 是一个一维张量,包含了批次中每个元素对应的时间步骤。
These may be fractional.
:param dim: the dimension of the output.
:param max_period: controls the minimum frequency of the embeddings.
:return: an (N, D) Tensor of positional embeddings.
"""
# https://github.com/openai/glide-text2im/blob/main/glide_text2im/nn.py
half = dim // 2
freqs = torch.exp(
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
).to(device=t.device) # freqs 频率向量
args = t[:, None].float() * freqs[None]
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1) # 根据输入的时间步骤和频率向量生成嵌入向量 embedding。
if dim % 2:
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
return embedding
def forward(self, t):
t_freq = self.timestep_embedding(t, self.frequency_embedding_size) # 生成时间步骤的频率嵌入。
t_emb = self.mlp(t_freq) # 通过 MLP 模型将频率嵌入映射到隐藏层维度大小,得到最终的嵌入向量。
return t_emb
class LabelEmbedder(nn.Module):
"""
Embeds class labels into vector representations. Also handles label dropout for classifier-free guidance.
将类标签嵌入到向量表示
"""
def __init__(self, num_classes, hidden_size, dropout_prob):
super().__init__()
use_cfg_embedding = dropout_prob > 0
self.embedding_table = nn.Embedding(num_classes + use_cfg_embedding, hidden_size) # 创建了一个嵌入表,用于将类标签映射到向量表示。
self.num_classes = num_classes
self.dropout_prob = dropout_prob
def token_drop(self, labels, force_drop_ids=None):
"""
Drops labels to enable classifier-free guidance. 将标签进行丢弃,以便进行无分类器指导。
"""
if force_drop_ids is None: # 指定哪些标签需要强制丢弃。
drop_ids = torch.rand(labels.shape[0], device=labels.device) < self.dropout_prob
else:
drop_ids = force_drop_ids == 1
labels = torch.where(drop_ids, self.num_classes, labels)
return labels
def forward(self, labels, train, force_drop_ids=None):
use_dropout = self.dropout_prob > 0
if (train and use_dropout) or (force_drop_ids is not None):
labels = self.token_drop(labels, force_drop_ids) # 对标签进行丢弃处理。
embeddings = self.embedding_table(labels) # 通过嵌入表将处理后的标签映射为嵌入向量。
return embeddings
class DiTBlock(nn.Module):
"""
A DiT block with adaptive layer norm zero (adaLN-Zero) conditioning.
"""
def __init__(self, hidden_size, num_heads, mlp_ratio=4.0, **block_kwargs):
super().__init__()
self.norm1 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.attn = Attention(hidden_size, num_heads=num_heads, qkv_bias=True, **block_kwargs)
self.norm2 = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
mlp_hidden_dim = int(hidden_size * mlp_ratio)
approx_gelu = lambda: nn.GELU(approximate="tanh")
self.mlp = Mlp(in_features=hidden_size, hidden_features=mlp_hidden_dim, act_layer=approx_gelu, drop=0)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 6 * hidden_size, bias=True)
)
def forward(self, x, c):
shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(c).chunk(6, dim=1) # 对条件向量 c 进行调节,生成了六个调节因子,分别用于自注意力机制和 MLP 模块的门控。
# 对输入向量 x 进行多层次的处理。
x = x + gate_msa.unsqueeze(1) * self.attn(modulate(self.norm1(x), shift_msa, scale_msa)) #
# 通过 self.norm1 对 x 进行层归一化,并将调节因子应用到归一化后的向量中,以调节自注意力机制的影响。
# 通过自注意力机制 self.attn 处理调节后的向量,得到注意力加权的输出。
#
x = x + gate_mlp.unsqueeze(1) * self.mlp(modulate(self.norm2(x), shift_mlp, scale_mlp))
#
return x
class FinalLayer(nn.Module):
"""
The final layer of DiT.
"""
def __init__(self, hidden_size, patch_size, out_channels):
super().__init__()
self.norm_final = nn.LayerNorm(hidden_size, elementwise_affine=False, eps=1e-6)
self.linear = nn.Linear(hidden_size, patch_size * patch_size * out_channels, bias=True)
self.adaLN_modulation = nn.Sequential(
nn.SiLU(),
nn.Linear(hidden_size, 2 * hidden_size, bias=True)
)
def forward(self, x, c):
shift, scale = self.adaLN_modulation(c).chunk(2, dim=1) # 对条件向量 c 进行调节,生成了两个调节因子,分别用于归一化层的偏移和缩放。
x = modulate(self.norm_final(x), shift, scale)
x = self.linear(x)
return x
def modulate(x, shift, scale): # x 输入向量 shift: 偏移向量 scale: 缩放向量
return x * (1 + scale.unsqueeze(1)) + shift.unsqueeze(1) # 函数返回调节后的输入向量
# scale中将每个值增加1,是为了确保在应用缩放时不会消除输入向量的重要信息。
摘自Scalable Diffusion Models with Transformers,我就不跑了,因为没钱,emmm。当然huggingface或modelscope已经上传了预训练权重,modelscope地址为:DiT-XL-2-256x256
模型实践
测试代码为:https://github.com/facebookresearch/DiT/blob/main/run_DiT.ipynb
即首先导包:
# DiT imports:
import torch
from torchvision.utils import save_image
from diffusion import create_diffusion
from diffusers.models import AutoencoderKL
from download import find_model
from models import DiT_XL_2
from PIL import Image
from IPython.display import display
torch.set_grad_enabled(False)
device = "cuda" if torch.cuda.is_available() else "cpu"
if device == "cpu":
print("GPU not found. Using CPU instead.")
下载已经通过modelscope下载到指定文件夹了,不走huggingface,所以设置指定目录并读取:
image_size = 256 #@param [256, 512]
vae_model = "my folder" #@param ["stabilityai/sd-vae-ft-mse", "stabilityai/sd-vae-ft-ema"]
latent_size = int(image_size) // 8
# Load model:
model = DiT_XL_2(input_size=latent_size).to(device)
state_dict = find_model(f"DiT-XL-2-{image_size}x{image_size}.pt")
model.load_state_dict(state_dict)
model.eval() # important!
vae = AutoencoderKL.from_pretrained(vae_model).to(device)
最后进行调用,并推理:
# Set user inputs:
seed = 0 #@param {type:"number"}
torch.manual_seed(seed)
num_sampling_steps = 250 #@param {type:"slider", min:0, max:1000, step:1}
cfg_scale = 4 #@param {type:"slider", min:1, max:10, step:0.1}
class_labels = 207, 360, 387, 974, 88, 979, 417, 279 #@param {type:"raw"}
samples_per_row = 4 #@param {type:"number"}
# Create diffusion object:
diffusion = create_diffusion(str(num_sampling_steps))
# Create sampling noise:
n = len(class_labels)
z = torch.randn(n, 4, latent_size, latent_size, device=device)
y = torch.tensor(class_labels, device=device)
# Setup classifier-free guidance:
z = torch.cat([z, z], 0)
y_null = torch.tensor([1000] * n, device=device)
y = torch.cat([y, y_null], 0)
model_kwargs = dict(y=y, cfg_scale=cfg_scale)
# Sample images:
samples = diffusion.p_sample_loop(
model.forward_with_cfg, z.shape, z, clip_denoised=False,
model_kwargs=model_kwargs, progress=True, device=device
)
samples, _ = samples.chunk(2, dim=0) # Remove null class samples
samples = vae.decode(samples / 0.18215).sample
# Save and display images:
save_image(samples, "sample.png", nrow=int(samples_per_row),
normalize=True, value_range=(-1, 1))
samples = Image.open("sample.png")
display(samples)
因为我没有机器,那么本节到此为止。
Latte:用于视频生成的潜在扩散变压器
| 📒** 论文名** | 《Latte: Latent Diffusion Transformer for Video Generation》 |
|---|---|
| 🔍** 地址** | https://arxiv.org/abs/2401.03048 |
| ⛳** Official repo** | https://github.com/Vchitect/Latte |
Latte 提出了一种新颖的潜在扩散变压器,用于视频生成。Latte 首先从输入视频中提取时空标记,然后采用一系列 Transformer 块对潜在空间中的视频分布进行建模。为了对从视频中提取的大量标记进行建模,从分解输入视频的空间和时间维度的角度引入了四种有效的变体。为了提高生成视频的质量,我们通过严格的实验分析确定了 Latte 的最佳实践,包括视频剪辑补丁嵌入、模型变体、时间步级信息注入、时间位置嵌入和学习策略。我们的综合评估表明,Latte 在四个标准视频生成数据集(即 FaceForensics、SkyTimelapse、UCF101 和 Taichi-HD)上实现了最先进的性能。此外, Latte 也 扩展到文本到视频生成 (T2V) 任务,其中 Latte 取得了与最新 T2V 模型相当的结果。我们坚信,Latte 为未来将 Transformer 纳入视频生成扩散模型的研究提供了宝贵的见解。

UViT:扩散模型的 ViT 骨干
| 📒** 论文名** | 《All are Worth Words: A ViT Backbone for Diffusion Models》 |
|---|---|
| 🔍** 地址** | https://arxiv.org/abs/2209.12152 |
| ⛳** Official repo** | https://github.com/baofff/U-ViT |
reference
- https://github.com/seymanurakti/fight-detection-surv-dataset
- https://keras.io/examples/vision/video_classification/
- https://keras.io/examples/vision/vivit/
- https://huggingface.co/Qwen/Qwen-VL-Chat
- https://github.com/facebookresearch/DiT/blob/main/models.py
- https://github.com/datawhalechina/sora-tutorial/blob/main/docs/chapter2/chapter2_3/chapter2_3.md
- ViViT: A Video Vision Transformer阅读和代码
- 十分钟读懂Diffusion:图解Diffusion扩散模型
以上内容来源于本人语雀公开笔记,如果有些排版问题可移步:sora笔记(三):diffusion transformer模型的发展历程 这里是搬运至csdn