目录
一.环境要求
虚拟机环境
1.linux操作系统
2.jdk
3.Hadoop环境
4.spark
5.scala
Windows环境
1.jdk
2.Hadoop(同上)
3.Scala
4. 安装winutils
二.IDEA的安装
idea下载
1、网站
2、下载
3、 安装
idea的配置
1.汉化
2.下载scala插件
3.下载Maven
4.新建Maven项目
5.配置Maven
6.添加框架
三.编写文件
1.配置pom.xml文件
2.下载spark,导jar包
3.新建object文件
四.实验测试
1.新建object
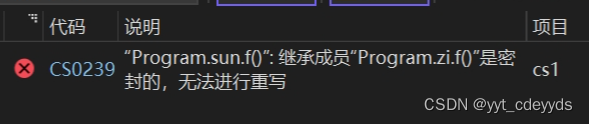
控制台结果
hadoop文件查看结果
2.新建object
一.环境要求
虚拟机环境
1.linux操作系统
2.jdk
3.Hadoop环境
如果没有安装的话,请看这篇文章:
https://blog.csdn.net/2202_75334392/article/details/132863607?spm=1001.2014.3001.5501
4.spark
5.scala
如果没有安装的话,请看这篇文章:
https://blog.csdn.net/2202_75334392/article/details/136355422?spm=1001.2014.3001.5501
Windows环境
1.jdk
如果没有安装的话,请看这篇文章:
https://blog.csdn.net/2202_75334392/article/details/132345373?spm=1001.2014.3001.5501
2.Hadoop(同上)
(windows和linux的hadoop版本要相同,jdk也是一样)
3.Scala
下载地址:
http://distfiles.macports.org/scala2.11/
两个相同的安装方式,下载安装包,配置环境变量
点击系统变量的path
添加路径

win+R 打开控制窗 输入下面的命令查看是否安装成功
scala
hadoop version

4. 安装winutils
下载地址:(这个适合3.1.x的版本)
https://pan.baidu.com/s/12_CDLyq3s8pgQ2JNAnw_SA?pwd=8888
提取码:8888其他版本
http:// https://github.com/steveloughran/winutils
存放路径:/hadoop/bin路径下

二.IDEA的安装
idea下载
1、网站
打开浏览器输入,进入 Jetbrains官网,点击 Developer Tools,再点击 Intellij IDEA
2、下载
选择左边的 Ultimate 版本进行下载安装。Ultimate 版本为旗舰版,需要付费,包括完整的功能Community 版本为社区版,免费,只支持部分功能。这里我们选择左边 Ultimate 版本进行下载,然后进行激活

3、 安装
下载完后在本地找到该文件,双击运行 idea 安装程序
按照安装程序进行安装。

idea的配置
1.汉化
打开setting(设置)
找到plug(插件)
在搜索Chinese。下载,重启

2.下载scala插件

3.下载Maven
下载地址
https://archive.apache.org/dist/maven/maven-3/3.9.5/binaries/

4.新建Maven项目

5.配置Maven
点击右边框的m键
再点击齿轮

然后修改成下载的Maven路径

6.添加框架
双击shift键

勾选scala

三.编写文件
1.配置pom.xml文件
第一次加载可能会有点久
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>test_spark_1</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<encoding>UTF-8</encoding>
<!-- 声明scala的版本 -->
<scala.version>2.11.12</scala.version>
<!-- 声明linux集群搭建的spark版本,如果没有搭建则不用写 -->
<spark.version>2.4.0</spark.version>
<!-- 声明linux集群搭建的Hadoop版本 ,如果没有搭建则不用写-->
<hadoop.version>3.1.3</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<!-- 2.11是我的Scala的版本,2.4.0是我的spark的版本 ,要根据你们自己的版本修改 -->
<artifactId>spark-mllib_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.12</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<!-- 3.1.3是我的hadoop的版本 ,要根据你们自己的版本修改 -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<!--mapreduce-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>2.下载spark,导jar包
(和虚拟机spark的版本一致)
下载地址:
Index of /apache/spark
把spark的jar文件夹一整个导入

3.新建object文件


四.实验测试
1.新建object
名称为GeneratePeopleInfoHDFS
import org.apache.spark.{SparkConf, SparkContext}
import scala.util.Random
object GeneratePeopleInfoHDFS {
//用于随机生成性别,返回字符串 "M" 或 "F"
def getRandomGender():String={
val rand = new Random()
val randNum = rand.nextInt(2)+1
if (randNum % 2 == 0) {"M"} else {"F"}
}
// 主函数
def main(args: Array[String]): Unit = {
System.setProperty("HADOOP_USER_NAME","root")
// 指定输出文件路径
val outputFile = "hdfs://192.168.200.80:8020/user/root/peopleinfo2.txt"
// 创建 SparkConf 对象,设置应用名称和运行模式
val conf = new SparkConf().setAppName("GeneratePeopleAgeHDFS").setMaster("local[1]")
// 创建 SparkContext 对象
val sc = new SparkContext(conf)
// 生成随机人员信息并存储到数组中
val rand = new Random()
val array = new Array[String](1000)
for (i<-1 to 1000){
var height = rand.nextInt(230)
if (height<50) {height = height + 50}
var gender = getRandomGender()
if (height <100 && gender == "M") {height = height+100}
if (height <100 && gender == "F") {height = height+50}
array(i-1)=i+" "+gender+" "+height
}
// 将数组转换为 RDD 并打印每个元素,然后将 RDD 保存到指定的 HDFS 文件路径
val rdd = sc.parallelize(array)
rdd.foreach(println)
rdd.saveAsTextFile(outputFile)
}
}
控制台结果

hadoop文件查看结果

2.新建object
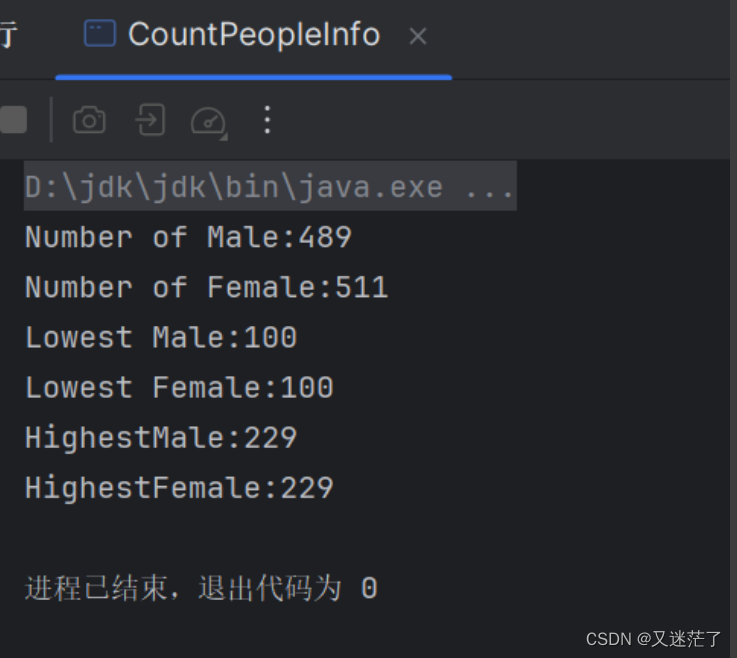
编写Spark应用程序,该程序对HDFS文件中的数据文件peopleinfo.txt进行统计,计算得到男性总数、女性总数、男性最高身高、女性最高身高、男性最低身高、女性最低身高
package TEST2
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
// 定义 CountPeopleInfo 对象
object CountPeopleInfo {
def main(args: Array[String]): Unit = {
// 设置 Spark 应用程序的配置,并指定应用名称为 "CountPeopleInfo",运行模式为本地模式
val conf = new SparkConf().setAppName("CountPeopleInfo").setMaster("local")
// 创建 SparkContext 对象
val sc = new SparkContext(conf)
// 指定输入文件路径
val inputFile = "hdfs://192.168.200.80:8020/user/root/peopleinfo2.txt"
// 读取文件中的每一行
val lines = sc.textFile(inputFile)
// 提取男性信息和女性信息,并生成格式为 "性别 身高" 的元组
val maleInfo = lines.filter(line => line.contains("M")).map(line => line.split(" ")).map(t => (t(1) + " " + t(2)))
val femaleInfo = lines.filter(line => line.contains("F")).map(line => line.split(" ")).map(t => (t(1) + " " + t(2)))
// 提取男性和女性的身高信息
val maleHeightInfo = maleInfo.map(t => t.split(" ")(1).toInt)
val femaleHeightInfo = femaleInfo.map(t => t.split(" ")(1).toInt)
// 计算男性和女性的最低和最高身高
val lowestMale = maleHeightInfo.sortBy(x => x, true).first()
val lowestFemale = femaleHeightInfo.sortBy(p => p, true).first()
val highestMale = maleHeightInfo.sortBy(p => p, false).first()
val highestFemale = femaleHeightInfo.sortBy(p => p, false).first()
// 输出统计结果
println("Number of Male: " + maleInfo.count())
println("Number of Female: " + femaleInfo.count())
println("Lowest Male: " + lowestMale)
println("Lowest Female: " + lowestFemale)
println("Highest Male: " + highestMale)
println("Highest Female: " + highestFemale)
}
}
结束了!!
感谢大家的观看!!