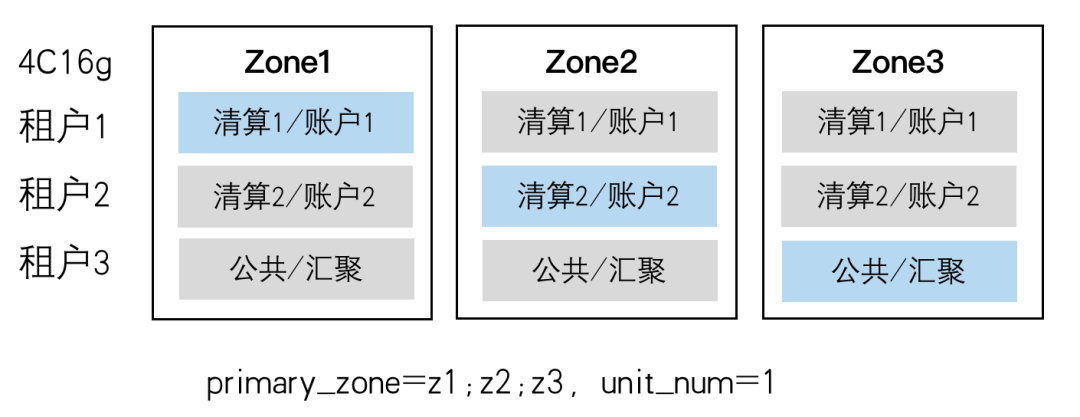
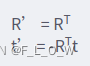1.信息抽取概述
信息抽取是构建知识图谱的必要条件。知识图谱中以(subject,relation,object)三元组的形式表示数据。信息抽取分为两大部分,一部分是命名实体识别,识别出文本中的实体,另外就是关系抽取,对识别出来的实体构建对应的关系,两者便是构建三元组的基本组成。
2.关系抽取概述
实体关系抽取(关系抽取)是构建知识图谱非常重要的一环,旨在识别实体之间的语义关系。关系抽取就是从非结构化文本(纯文本)中抽取实体关系三元组(SRO)。这里S代表头实体,R代表关系,O代表尾实体。如下图所示:第一句文本中,“刘翔”和“上海”两个实体之间的语义关系是“出生地”。 第二句文本中,“张艺谋”与“菊豆”两个实体之间的语义关系是“导演”

3.关系抽取方法
当前关系抽取主要分为两大类,分别是传统的限定域关系抽取(传统关系抽取)和开放领域关系抽取。
3-1 开放域关系抽取(open domain)
不再局限于一小部分提前已知的关系,关系类型不需要提前固定,而是去抽取文本当中各种各样的关系。
3-2 限定域关系抽取(fixed domain)
从非结构化文本中识别出一对实体概念和联系,这对实体以及关系构成的相关三元组。其schema确定后关系类型是固定的,有的关系不在提前定义好的schema中时,将无法抽取,不能抽取出新的关系。 限定域关系抽取方法分为两种,分别是:流水线学习方法(pipeline) 和联合学习方法
3-2-1 流水线学习方法(pipeline)
通常先抽取句子中的实体,然后在对实体对进行关系分类,从而找出SRO三元组。
3-2-2 联合学习方法(joint)
联合学习方法(joint) 联合学习方法同时进行实体识别和实体对的关系分类两个任务。联合学习方法由于考虑了两个子任务之间的信息交互,大大提升了实体关系抽取的效果,所以目前针对实体关系抽取任务的研究大多采用联合学习方法。


参数共享模型: 1.主体、客体和关系抽取不是同步的。 2.整个过程可以得到三个Loss值。整个模型的Loss是各个过程的Loss值和 。
联合解码模型: 1.主体、客体和关系抽取同步进行,通过一个模型直接得出SRO三元组。
4.关系抽取难点
4-1 语言表述难点
由于自然语言表达的多样性、灵活性,不同词汇可表达同一关系。 在文本中找不到明确的关系表示。同一词汇会有不同的关系。

4-2 关系三元组重叠

1.Normal
没有重叠的部分
2.EPO(EntityPairOverlap)
关系两端的实体都是一致的 。(《少林足球》,导演,周星驰) (《少林足球》,编剧,周星驰)
3.SEO(SingleEntityOverlap)
关系两端有单个实体共享。 (刘翔,出生地,上海) (刘翔,出生时间,1983年7月13日) (阿尔弗雷德.阿德勒,出生地,奥地利) (阿尔弗雷德.阿德勒,出生地,维也纳)
5. 相关论文介绍
5-1 基于流水线模式关系抽取
流水线学习方法是指在实体识别已经完成的基础上直接进行实体之间关系的抽取 。
5-1-1 《A frustratingly easy approach for entity and relation extraction》
论文来源: 普林斯顿 NAACL 2021
论文引用 :Zhong Z, Chen D. A frustratingly easy approach for entity and relation extraction[J]. arXiv preprint arXiv:2010.12812, 2020.
模型结构图

方法解读
两个编码器
1.实体模型: Span-level NER,提取所有可能的片段排列,通过SoftMax对每一个Span进行实体类型判断。
2.关系模型: 对所有的实体pair进行关系分类。将实体边界和类型作为标识符(typed marker)加入到实体Span前后,然后作为关系模型的input。对每个sub和obj的组合进行分类,预测各实体之间的关系。
巧妙改进:学习实体对之间的依赖关系
S:Md和/S:Md:代表实体类型为Method的Subject,S是实体span的第一个token,/S是最后一个token; O:Md和/O:Md:代表实体类型为Method的Object,O是实体span的第一个token,/O是最后一个token;
5-2-2 《Packed Levitated Marker for Entity and Relation Extraction》
论文来源: 清华大学&微信团队ACL 2022
论文引用 :Ye D, Lin Y, Li P, et al. Packed Levitated Marker for Entity and Relation Extraction[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022: 4904-4917.
额外知识:Span表征方式
 1.Solid Marker(固定标记) 显式的在句子中的span前后插入两个marker。如果是关系抽取,就在subject span和object span前后分别插入。 2.Levitated Marker(悬浮标记) 悬浮标记全部置于句子外面。有利于嵌套实体表示;同时有利于计算加速。 3.Packed Levitated Marker subject和object分别存在于句子内部和句子外部。subject存在于句子内部,object全部统一存放在句子外部。有利于凸显object的span之间的内在联系。
1.Solid Marker(固定标记) 显式的在句子中的span前后插入两个marker。如果是关系抽取,就在subject span和object span前后分别插入。 2.Levitated Marker(悬浮标记) 悬浮标记全部置于句子外面。有利于嵌套实体表示;同时有利于计算加速。 3.Packed Levitated Marker subject和object分别存在于句子内部和句子外部。subject存在于句子内部,object全部统一存放在句子外部。有利于凸显object的span之间的内在联系。
模型架构图
Step1: Entity

方法解读:
通过枚举,列出所有的span 。1.设置span的最大长度 ; 2.设置pack的最大长度。将相邻的span的悬浮标记拼接在同一个样本里面
优点:
1.面向邻居span的打包策略,以更好地建模实体边界信息,借用span之间的关系。
Step2:Relation

方法解读:
对于一个句子,以及其中的subject span和它对应的object spans,构成一条训练样本,其中subject span采用固定标记,也就是在句子中span单词的前后直接插入[S]和[/S]两个标记,然后将它对应的候选Object span用悬浮标记的方式拼接在文本后面。
优点:
1.建模具有相同subject的跨度对之间的相互关系。
5-2 联合解码模式关系抽取
5-2-1 《Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme》
论文来源: 中国科学研究院 ACL 2021
论文引用 :Zheng S, Wang F, Bao H, et al. Joint extraction of entities and relations based on a novel tagging scheme[J]. arXiv preprint arXiv:1706.05075, 2017.
模型架构图
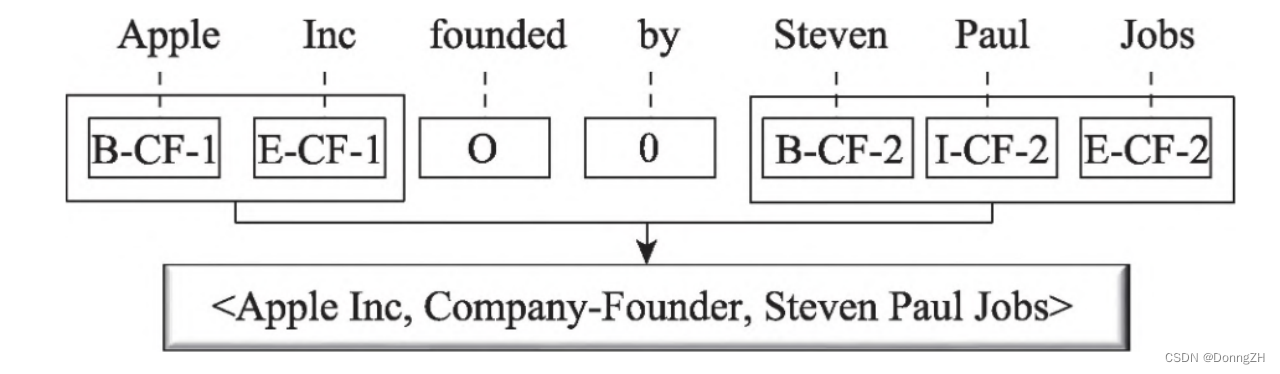
CF 表示关系类型Company-Founder “1”和“2”分别表示被标注的单词属于当前关系类型的头实体和尾实体。
方法解读
创新点:采用新的标注方案
1.首次采用序列标注的方法实现联合抽取,将联合提取任务转化为标记问题 。
2. 在原有BIES(begin、inside、end、single)标注方案上进行了扩展,新的标注中融入了关系类型和实体在关系中的角色信息。
5-3 基于联合模式关系抽取
本质上本质上是多任务学习,实体识别和关系抽取共享encoder,使用不同的decoder, 并构建联合loss训练优化。
5-3-1 《End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures》
论文来源: ACL 2016
论文引用 :Miwa M , Bansal M . End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures:, 10.18653/v1/P16-1105[P]. 2016.
模型架构图
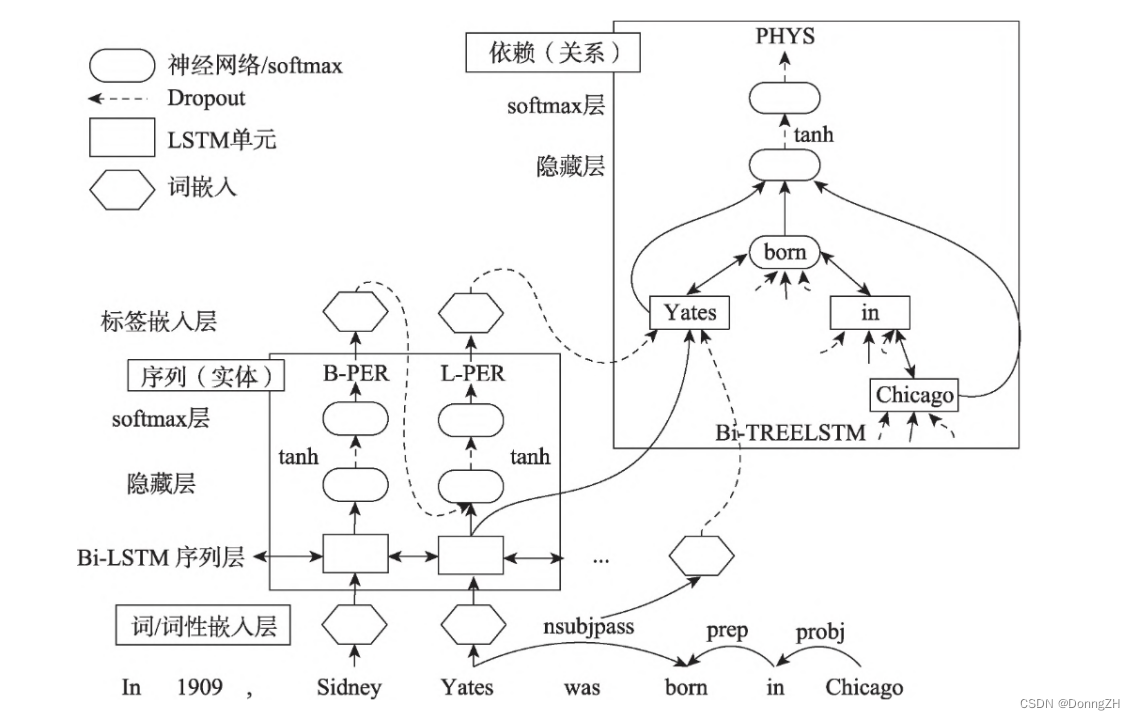
方法解读
属于联合关系抽取的开山之作,一共分为三个部分。
1.Embedding layer (word embeddings layer) ;
2.Sequence layer (word sequence based LSTM-RNN layer):用于实体检测;
3.Dependency layer (dependency subtreebased LSTM-RNN layer ):用于关系抽取。
两个双向LSTM-RNN结构分别用于检测实体和分类关系,它们是单独训练的,但是loss是加在一起同时进行反向传播和更新。
5-3-2 《Span-based joint entity and relation extraction with transformer pre-training》
论文来源: ECAI 2020
论文引用 :Eberts M, Ulges A. Span-based joint entity and relation extraction with transformer pre-training[J]. arXiv preprint arXiv:1909.07755, 2019.
模型架构图

方法解读
模型共分为三个部分 1.span classification 2.Span Filtering 3.relation classification,共享Encoder span classification 和 Span Filtering层对实体进行筛选和识别,relation classification 进行关系抽取。
(1)实体分类,这里对实体进行分类,是一个softmax,但是考虑了实体的头尾,实体分类模型得到的是实体的类别和实体span,也就是文本中的那些字段是实体,模型的输入文本tokenizer, 实体span,实体mask,实体size 。
(2)对实体进行过滤span filter,对实体模型的结果进行过滤,保留有实体,根据保留的实体构建关系负样本。
(3)关系分类,输入是实体,实体间连续文本特征max-pooling,实体宽度矩阵,经过一个线性层,得到关系分类的结果。
5-3-3 《A Novel Cascade Binary Tagging Framework for Relational Triple Extraction》
论文来源: 吉林大学 ACL 2020
论文引用 : Wei Z , Su J , Wang Y , et al. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.
模型架构图

方法解读
Casrel共分为两个步骤:
1.识别出句子中的subject
2.根据subject识别出所有可能的relation和object
模型分为三个部分:
1.BERT-based encoder module
这部分的就是对句子编码,获取每个词的隐层表示,可以采用 BERT 的任意一层。另外这部分是可以替换的,例如用 LSTM 替换 BERT。
2.subject tagging module
目的是识别出句子中的 subject。这部分的主要作用是对 BERT Encoder 获取到的词的隐层表示解码。构建两个二分类分类器预测 subject 的 start 和 end 索引位置,对每一个词计算其作为 start 和 end 的一个概率,并根据某个阈值,大于则标记为1,否则标记为0
(1)利用一个线性层➕一个sigmoid激活函数判断每个token是不是头实体的开始token或结束token;
(2)利用最近匹配原则将识别到的start和end配对获得候选头实体集合。

3.relation-specific object tagging module
根据 subject,寻找可能的 relation 和 object。这部分会同时识别出 subject 的 relation 和相关的 object。 解码的时候比 Subject Tagger 不仅仅考虑了 BERT 编码的隐层向量, 还考虑了识别出来的 subject 特征。vsub 代表 subject 特征向量,若存在多个词,将其取向量平均,hn 代表 BERT 编码向量。 对于识别出来的每一个 subject, 对应的每一种关系会解码出其 object 的 start 和 end 索引位置,与 Subject Tagger 类似。

对于第一个subject ,Jackie R. Brown,在关系 Birth_place 中识别出了两个 object,即 Washington 和 United States Of America,而在其他的关系中未曾识别出相应的 object。 对第二个subject, Washington 这个 subject 解码时,仅仅在 Capital_of 的关系中识别出 对应的 object: United States Of America。
公式解读



6 总结
| 基本方法 | 先抽取实体、再抽取关系 | 联合抽取 |
| 优点 | 1.两个模型,灵活度高 2.实体模型和关系模型可以使用独立的数据集 | 1.统一使用给一个模型编码 2.两个任务的表征有交互 |
| 缺点 | 1.误差积累:实体抽取的错误会影响下一步关系抽取性能 2.交互缺失:忽略两个任务之间的联系和依赖关系 | 2.同一个模型需要更为复杂的结构或者是标注语料 2.统一编码器提取特征可能会使得模型学习混乱 |