前言
最近有这样的一个需求, 我们存在一张 很大的 mysql 数据表, 数据量大概是在 六百万左右
然后 需要获取所有的记录, 将数据传输到 es 中
然后 当时 我就写了一个脚本来读取 这张大表, 然后 分页获取数据, 然后 按页进行数据处理 转换到 es
但是存在的问题是, 前面 还效率还可以, 但是 约到后面, 大概是到 三百多页, 的时候 从 mysql 读取数据 已经快不行了
十分耗时, 这里就是 记录这个问题的 另外的处理方式
我这里的处理是基于 消息中间件, 从 mysql 通过 datax/spoon 传输数据到 kafka 很快
然后 java 程序从 kafka 中消费队列的数据 也很快, 最终 六百万的数据 读取 + 处理 合计差不多是 一个多小时完成, 其中处理 有一部分地方 业务上面比较耗时
待处理的数据表
待处理的数据表如下, 里面合计 600w 的数据
CREATE TABLE `student_all` (
`id` int NOT NULL AUTO_INCREMENT,
`field0` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field1` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field2` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field3` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field4` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field5` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field6` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field7` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field8` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field9` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field10` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field11` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field12` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field13` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field14` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field15` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field16` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field17` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field18` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field19` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field20` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field21` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field22` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field23` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field24` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field25` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field26` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field27` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field28` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`field29` varchar(128) COLLATE utf8mb4_general_ci NOT NULL,
`CREATED_AT` bigint NOT NULL,
`UPDATED_AT` bigint NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4379001 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
基于 mysql 的数据分页处理
基于 mysql 的处理程序如下, 就是一个简单的 mysql 分页
然后将需要提取的数据封装, 然后 批量提交给 es
总的情况来说是 前面的一部分页是可以 很快的响应数据, 但是 越到后面, mysql 服务器越慢
/**
* Test05PostQy2Es
*
* @author Jerry.X.He
* @version 1.0
* @date 2022/11/21 16:00
*/
public class Test05PostEsFromMysql {
private static String mysqlUrl = "jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&autoReconnectForPools=true";
private static String mysqlUsername = "postgres";
private static String mysqlPassword = "postgres";
private static JdbcTemplate mysqlJdbcTemplate = JdbcTemplateUtils.getJdbcTemplate(mysqlUrl, mysqlUsername, mysqlPassword);
private static RestHighLevelClient esClient = getEsClient();
private static IndicesClient indicesClient = esClient.indices();
// Test05PostQy2Es
public static void main(String[] args) throws Exception {
String esIndexName = "student_all_20221211";
bulkEsData(esIndexName);
}
private static void bulkEsData(String esIndexName) throws Exception {
String queryDbTableName = "student_all";
List<String> fieldList = Arrays.asList("id", "field0", "field1", "field2", "field3", "field4", "field5", "field6", "field7", "field8", "field9", "field10", "field11", "field12", "field13", "field14", "field15", "field16", "field17", "field18", "field19", "field20", "field21", "field22", "field23", "field24", "field25", "field26", "field27", "field28", "field29", "CREATED_AT", "UPDATED_AT");
String idKey = "id";
String whereCond = "";
// String orderBy = "order by id asc";
String orderBy = "";
AtomicInteger counter = new AtomicInteger(0);
int pageSize = 1000;
int startPage = 0;
pageDo(queryDbTableName, whereCond, orderBy, pageSize, startPage, (pageNo, list) -> {
BulkRequest bulkRequest = new BulkRequest();
for (Map<String, Object> entity : list) {
IndexRequest indexRequest = new IndexRequest(esIndexName);
Map<String, Object> sourceMap = new LinkedHashMap<>();
List<String> allFieldsListed = new ArrayList<>();
for (String fieldName : fieldList) {
String fieldValue = String.valueOf(entity.get(fieldName));
sourceMap.put(fieldName, fieldValue);
allFieldsListed.add(Objects.toString(fieldValue, ""));
}
String id = String.valueOf(entity.get(idKey));
indexRequest.id(id);
sourceMap.put("_allFields", StringUtils.join(allFieldsListed, "$$"));
indexRequest.source(sourceMap);
bulkRequest.add(indexRequest);
}
try {
BulkResponse bulkResponse = esClient.bulk(bulkRequest, RequestOptions.DEFAULT);
counter.addAndGet(list.size());
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(" page : " + pageNo + ", flushed " + counter.get() + " records ");
});
}
private static void pageDo(String tableName, String whereCond, String orderBy, int pageSize, int startPage,
BiConsumer<Integer, List<Map<String, Object>>> func) {
if (StringUtils.isNotBlank(whereCond) && (!whereCond.trim().toLowerCase().startsWith("where"))) {
whereCond = " where " + whereCond;
}
if (StringUtils.isNotBlank(orderBy) && (!orderBy.trim().toLowerCase().startsWith("order"))) {
orderBy = " order by " + orderBy;
}
String queryCountSql = String.format(" select count(*) from %s %s %s", tableName, whereCond, orderBy);
Integer totalCount = mysqlJdbcTemplate.queryForObject(queryCountSql, Integer.class);
Integer totalPage = (totalCount == null || totalCount == 0) ? 0 : (totalCount - 1) / pageSize + 1;
for (int i = startPage; i < totalPage; i++) {
int offset = i * pageSize;
String queryPageSql = String.format(" select * from %s %s %s limit %s,%s ", tableName, whereCond, orderBy, offset, pageSize);
List<Map<String, Object>> list = mysqlJdbcTemplate.queryForList(queryPageSql);
func.accept(i, list);
}
}
}
基于中间件 kafka 的处理
首先通过 spoon/datax 将数据从 mysql 转换到 kafka
然后 再由脚本从 kafka 消费数据, 处理 传输到 es 中
入了一次 消息队列之后, 然后程序 再来消费, 就会快很多了, 消息队列本身功能比较单纯 比较适合于做做顺序遍历 就会有优势一些
这里以 spoon 将数据从 mysql 转换到 kafka
我这里 本地环境 内存等什么的都不足, 因此是 一分钟 入库三万条, 但是 实际生产环境 会很快
在生产环境 五百多w 的数据, 基于 datax 传输 mysql 到 kafka, 差不多是 五六分钟 就可以了
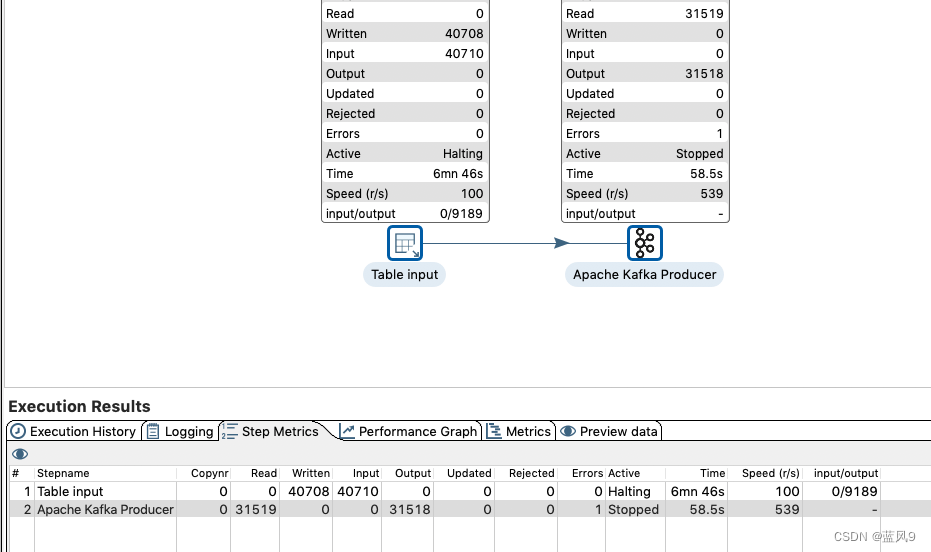
基于 kafka 将数据传输到 es
如下程序 仅仅是将 kafka 中的数据 原样照搬过去了, 但是 实际的场景 中会做一些 额外的业务处理, 这里仅仅是为了 演示
/**
* Test05PostQy2Es
*
* @author Jerry.X.He
* @version 1.0
* @date 2022/11/21 16:00
*/
public class Test05PostEsFromKafka {
private static RestHighLevelClient esClient = getEsClient();
private static IndicesClient indicesClient = esClient.indices();
private static String esIndexName = "student_all_20221211";
private static String groupId = "group-01";
// Test05PostQy2Es
public static void main(String[] args) throws Exception {
bulkKafka2EsData(esIndexName, groupId);
}
private static void bulkKafka2EsData(String esIndexName, String groupId) throws Exception {
List<Pair<String, String>> hjk2StdFieldMap = hjk2StdFieldMap();
Properties properties = kafkaProperties(groupId);
String idKey = "ID";
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
kafkaConsumer.subscribe(Arrays.asList("STUDENT_ALL_20221211"));
AtomicInteger counter = new AtomicInteger(0);
long start = System.currentTimeMillis();
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
if (records.isEmpty()) {
Thread.sleep(10 * 1000);
long spent = System.currentTimeMillis() - start;
System.out.println(" spent : " + (spent / 1000) + " s ");
continue;
}
BulkRequest bulkRequest = new BulkRequest();
boolean isEmpty = true;
for (ConsumerRecord<String, String> record : records) {
IndexRequest indexRequest = new IndexRequest(esIndexName);
String value = record.value();
JSONObject entity = JSON.parseObject(value);
// 获取 id
String id = StringUtils.defaultIfBlank(entity.getString(idKey), "");
if (isFilterByQy(id)) {
continue;
}
Map<String, Object> sourceMap = new LinkedHashMap<>();
List<String> allFieldsListed = new ArrayList<>();
for (Pair<String, String> entry : hjk2StdFieldMap) {
String hjkKey = entry.getKey(), stdKey = entry.getValue();
String fieldValue = StringUtils.defaultIfBlank(entity.getString(hjkKey), "");
sourceMap.put(stdKey, fieldValue);
allFieldsListed.add(Objects.toString(fieldValue, ""));
}
indexRequest.id(id);
sourceMap.put("_allFields", StringUtils.join(allFieldsListed, "$$"));
isEmpty = false;
indexRequest.source(sourceMap);
bulkRequest.add(indexRequest);
}
if (isEmpty) {
continue;
}
try {
BulkResponse bulkResponse = esClient.bulk(bulkRequest, RequestOptions.DEFAULT);
counter.addAndGet(bulkRequest.requests().size());
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(" flushed " + counter.get() + " records ");
}
}
private static List<Pair<String, String>> hjk2StdFieldMap() {
List<Pair<String, String>> hjk2StdFieldMap = new ArrayList<>();
hjk2StdFieldMap.add(new ImmutablePair<>("id", "id"));
hjk2StdFieldMap.add(new ImmutablePair<>("CREATED_AT", "CREATED_AT"));
hjk2StdFieldMap.add(new ImmutablePair<>("UPDATED_AT", "UPDATED_AT"));
for (int i = 0; i < Test05CreateMysqlBigTable.maxFieldIdx; i++) {
String fieldName = String.format("field%s", i);
hjk2StdFieldMap.add(new ImmutablePair<>(fieldName, fieldName));
}
return hjk2StdFieldMap;
}
private static Properties kafkaProperties(String groupId) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.0.190:9092");
properties.put("group.id", groupId);
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "1000");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "30000");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return properties;
}
private static boolean isFilterByQy(String qy) {
if (StringUtils.isBlank(qy)) {
return true;
}
return false;
}
}
spoon 安装 kakfa 插件
来自 Kettle安装Kafka Consumer和Kafka Producer插件
1.从github上下载kettle的kafka插件,地址如下
Kafka Consumer地址:
https://github.com/RuckusWirelessIL/pentaho-kafka-consumer/releases/tag/v1.7
Kafka Producer地址:
https://github.com/RuckusWirelessIL/pentaho-kafka-producer/releases/tag/v1.9
2.进入 kettle 安装目录:在plugin目录下创建steps目录
3.把下载的插件解压后放到 steps 目录下
5.重启 spoon.bat 即可
完
参考
Kettle安装Kafka Consumer和Kafka Producer插件