目录
1. 基础题
1.1 基础题1
1.2 基础题2
1.3 基础题3
2. turtle画图题
3. 大题
3.1 大题1
3.2 大题2
1. 基础题
1.1 基础题1
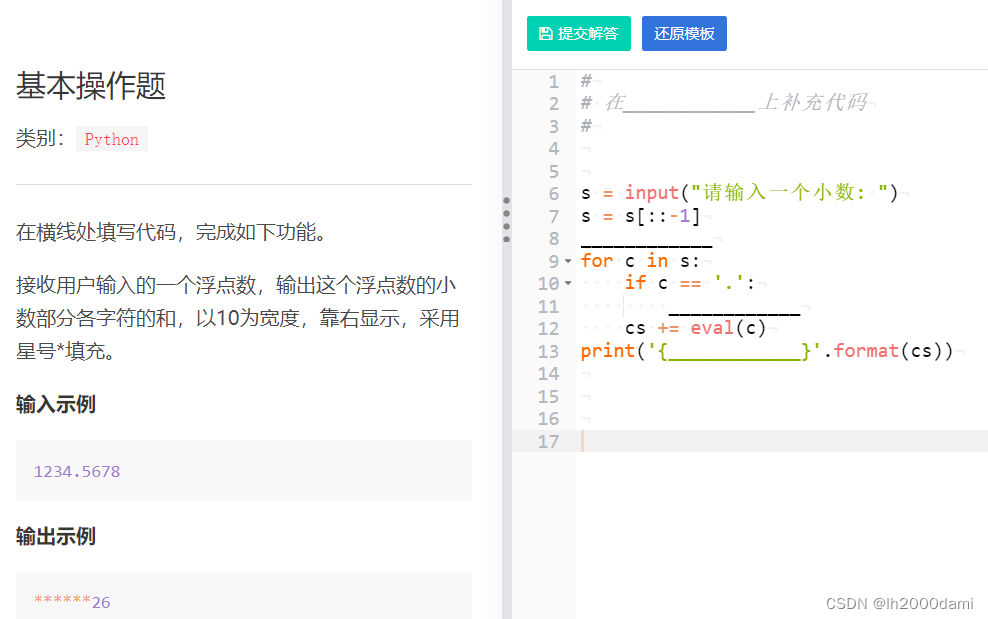
s=input("请输入一个小数:")
s=s[::-1]
cs=0
for c in s:
if c=='.':
break
cs+=eval(c)
print('{:*>10}'.format(cs))1.2 基础题2
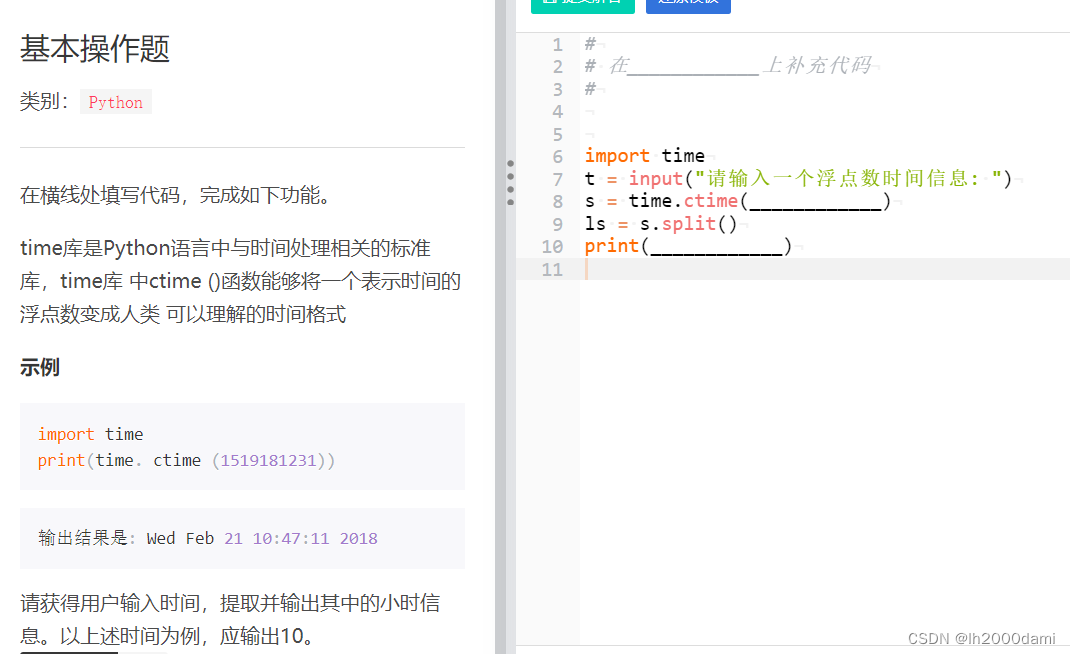
import time
t=input("请输入一个浮点数时间信息:")
s=time.ctime(float(t))
ls=s.split()
print(ls[3].split(':')[0])
#答案 print(ls[3][0:2])1.3 基础题3
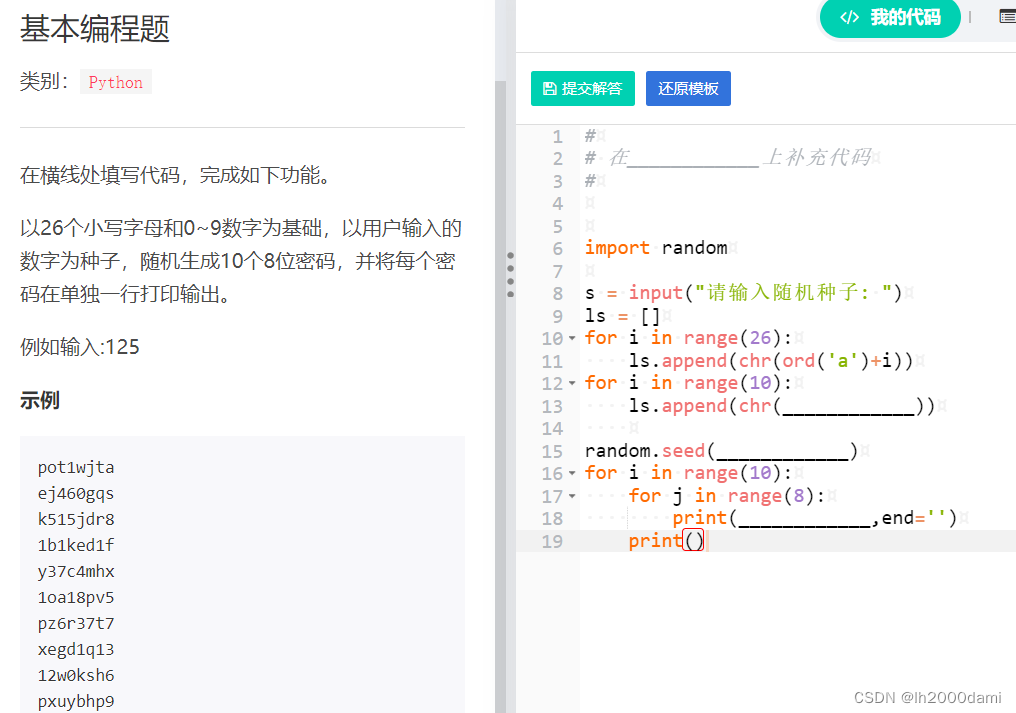
import random
s=input("请输入随机种子:")
ls=[]
for i in range(26):
ls.append(chr(ord('a')+i))
for i in range(10):
ls.append(chr(ord('0')+i))
random.seed(eval(s))
for i in range(10):
for j in range(8):
print(random.choice(ls),end='')
#或者print(ls[random.randint(0,35)],end='')
print()在Python中,print() 函数默认是自带换行符的,也就是说,每次调用print() 函数输出内容后会自动换行。
random.choice()是Python标准库中的一个函数,用于从给定的可迭代对象中随机选择一个元素并返回。
2. turtle画图题
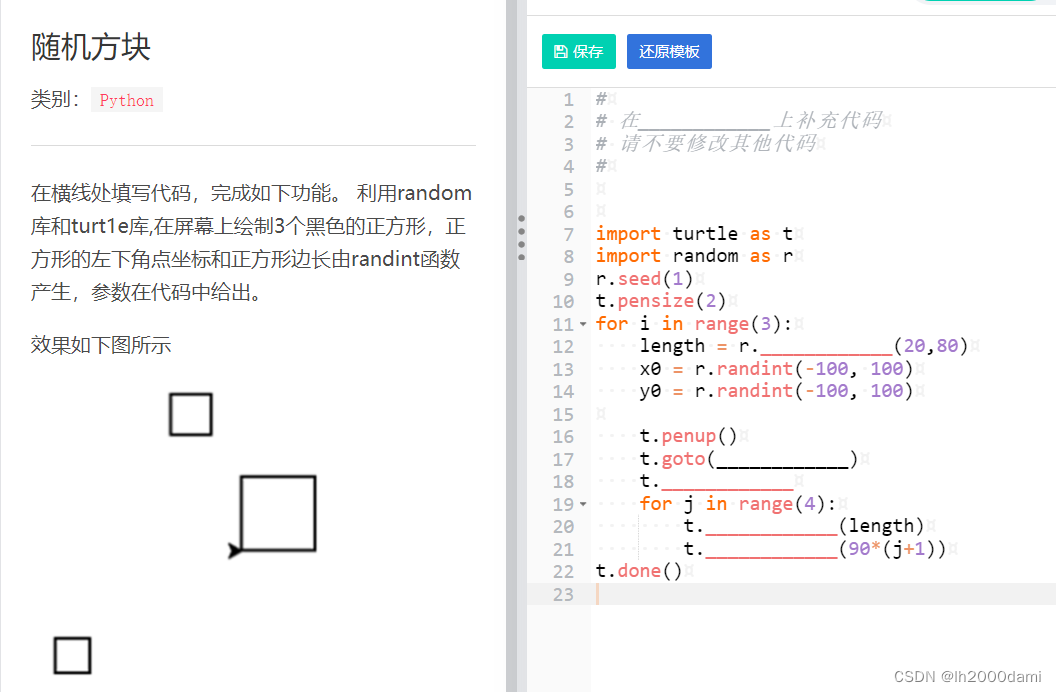
import turtle as t
import random as r
r.seed(1)
t.pensize(2)
for i in range(3):
length=r.randint(20,80)
x0=r.randint(-100,100)
y0=r.randint(-100,100)
t.penup()
t.goto(x0,y0)
t.pendown()
for j in range(4):
t.fd(length)
t.seth(90*(j+1))
t.done()turtle.seth() 设置海龟朝向,以逆时针为正方向
turtle.fd()前进
3. 大题
3.1 大题1
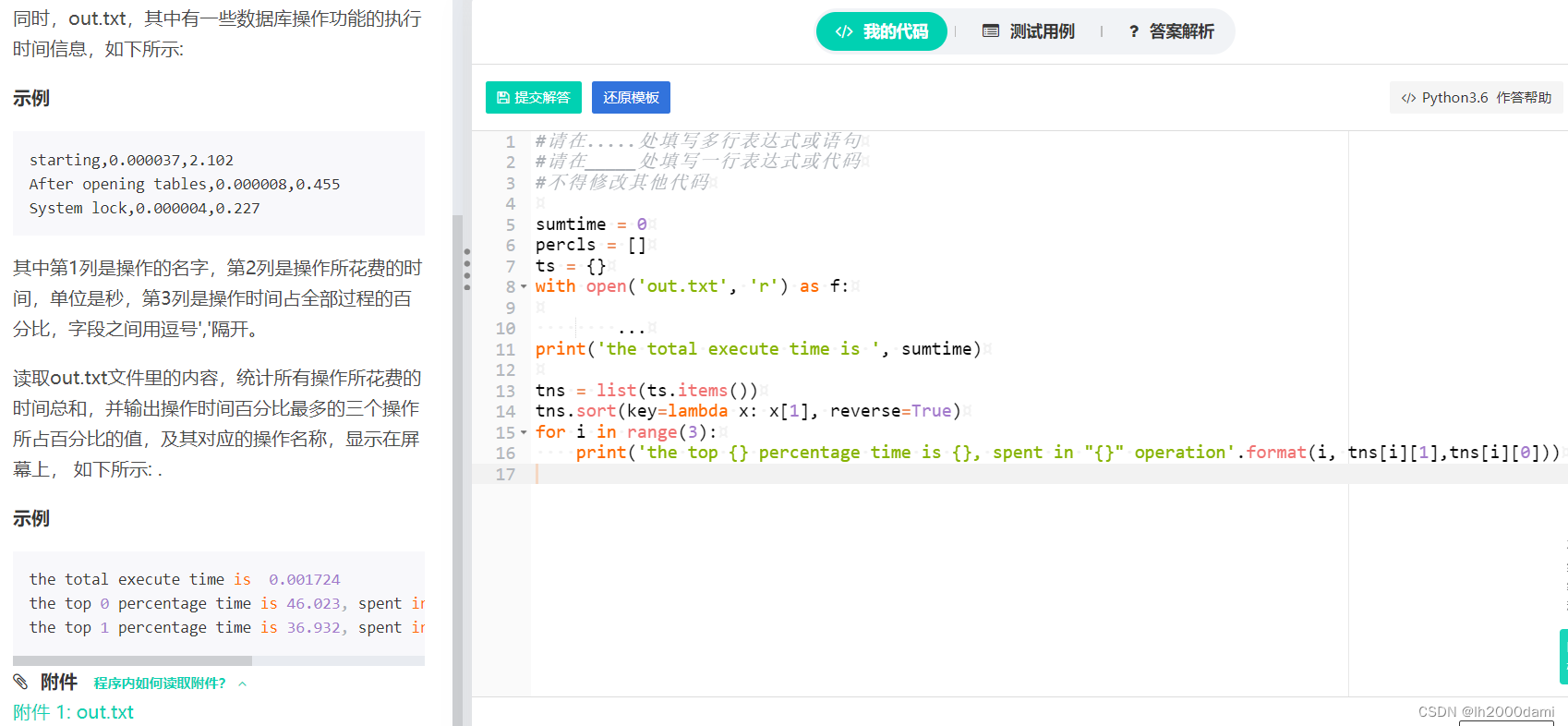
自己写的:
sumtime=0
percls=[]
ts={}
with open('out.txt','r') as f:
ls=f.readlines()
for i in range(len(ls)):
name=ls[i].split(',')[0]
time=eval(ls[i].split(',')[1])
p=eval(ls[i].split(',')[2])
sumtime+=time
ts[name]=p
print('the total execute time is', sumtime)
tns=list(ts.items())
tns.sort(key=lambda x:x[1],reverse=True)
for i in range(3):
print('the top {} percentage time is {}, spent in "{}" operation'. format(i,tns[i][1],tns[i][0]))
自己写的并未用到题目中给的percls=[]
注意文档中的记录数目不是3,需要用len(ls)
答案:
sumtime=0
percls=[]
ts={}
with open('out.txt','r') as f:
for line in f:
percls.append(line.strip("\n").split(","))
n=[x[1] for x in percls]
for i in range(len(n)):
sumtime+=eval(n[i])
ts={x[0]:x[2] for x in percls}
print('the total execute time is', sumtime)
tns=list(ts.items())
tns.sort(key=lambda x:x[1],reverse=True)
for i in range(3):
print('the top {} percentage time is {}, spent in "{}" operation'. format(i,tns[i][1],tns[i][0]))
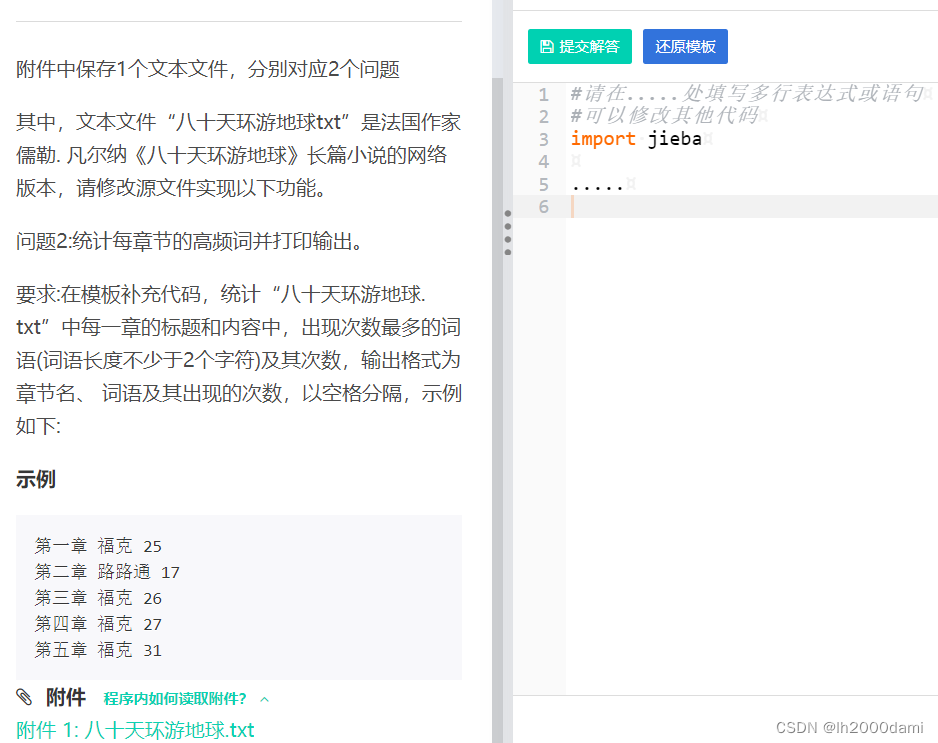
3.2 大题2
第一问:

#提取章节题目
f=open("八十天环游地球.txt",encoding="utf-8")
fo=open("八十天环游地球-章节.txt",'w',encoding="utf-8")
for i in f:
text=i.split()[0]
if text[0]=="第" and text[-1]=="章":
fo.write("{}\n".format(i.replace('\n','')))
f.close()
fo.close()第二问:
#第二问
import jieba
import re
strf='八十天环游地球.txt'
with open(strf,encoding="utf-8") as f:
lines=f.read()
t=re.findall('(第.{1,3}章.*)',lines)
with open(strf,encoding="utf-8") as f:
lines=f.read()
s=re.sub('(第.{1,3}章.*)','$',lines)
x=s.split('$')
x=x[1:]
for i,j in zip(t,x):
counts={}
txt=jieba.lcut(i+j)
for word in txt:
if len(word)>=2:
counts[word]=counts.get(word,0)+1
li=list(counts.items())
li.sort(key=lambda x:x[1],reverse=True)
word_max,count_max=li[0]
chapter=re.findall('(第.*章)',i)[0]
print(chapter+' '+word_max+' '+str(count_max))