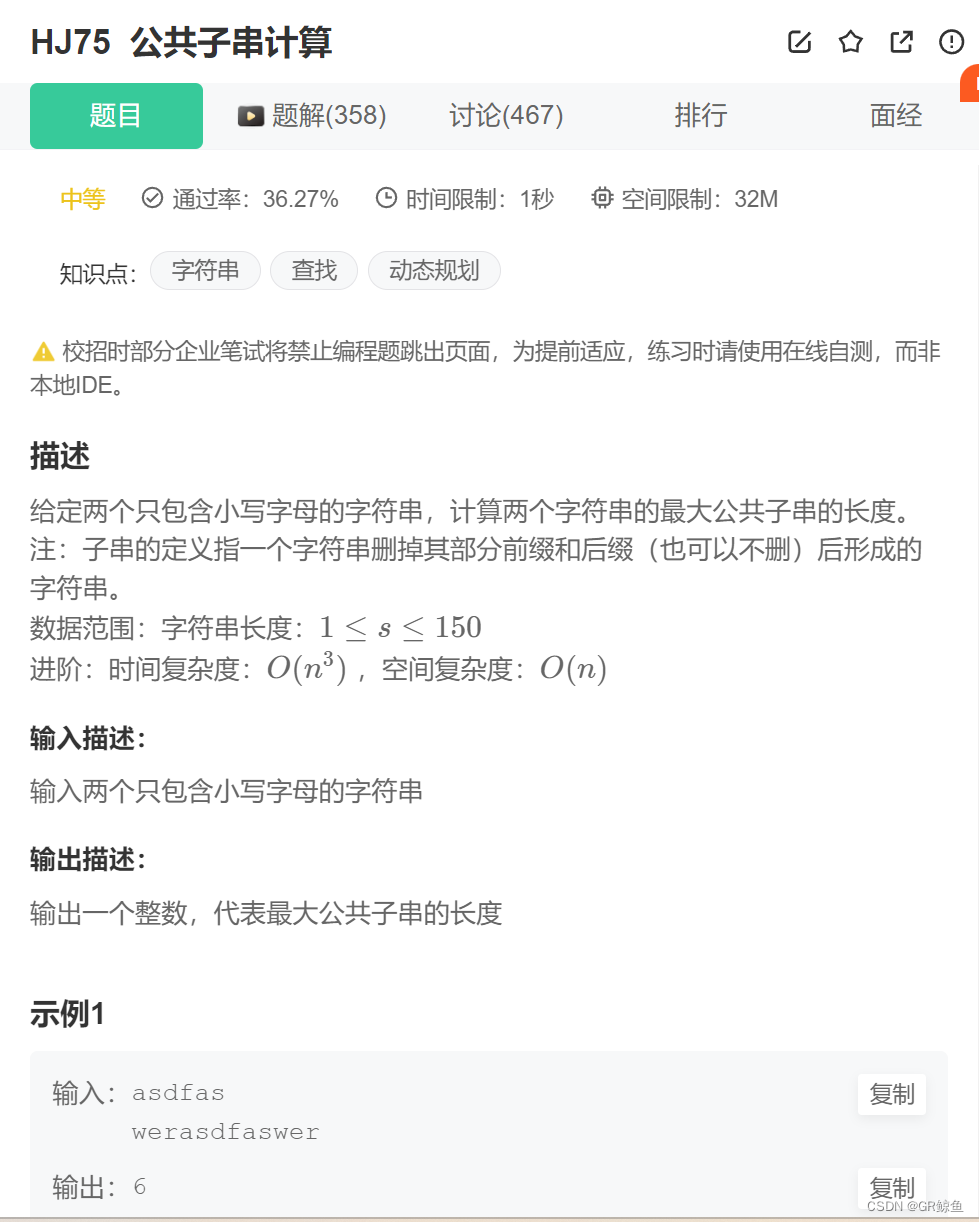
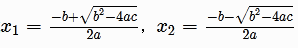关键要点
- 深度学习模型可能非常复杂,理解其内部原理可能具有挑战性
- 在机器学习中,提供可解释性的方法有多种
- 为了确保这些自动化系统的可靠性,可以使用可解释性工具来深入了解模型的决策过程
- 模型不可知的可解释性工具在不同模型之间是模块化的,可用于与他人共享模型结果,提供透明度,并使用户对其模型有信心
- 解释深度学习模型没有单一的“正确”方式
深度学习模型可能非常复杂,理解其内部原理可能具有挑战性。如果用户理解模型是如何做出决策的,他们会更信任这些模型。可解释性是一个旨在理解深度学习模型工作原理的不断发展的研究领域。在本文中,我将讨论当前深度学习中解释方法的状态。我还将讨论不同方法的优势和局限性,并展示如何利用可解释性来提高深度学习模型的可靠性。
未来,机器学习可以用于自动执行人类执行的日常任务,包括回答客户服务查询或处理数据。为了确保这些自动化系统的可靠性,可以使用可解释性工具来深入了解模型的决策过程。模型不可知的可解释性工具在不同模型之间是模块化的,可用于与他人共享模型结果,提供透明度,并使用户对其模型有信心。
解释方法
机器学习的可解释性指的是用户解释机器学习系统决策的能力。这包括理解输入、模型和输出之间的关系。可解释性提高了对模型的信心,减少了偏见,并确保了模型的合规性和道德性。在机器学习中提供可解释性的方法有几种,包括:
- 特征可解释性:这种方法涉及可视化模型所学习的特征,以了解其学习内容。特征可解释性可以帮助识别深度学习模型中最重要的特征,但如果不基于底层模型,它可能并不总是可靠的。
- 激活最大化:这种方法涉及最大化某个神经元或层的激活,以了解模型学习的内容。这种方法在某些情况下可用于可视化网络组件的贡献,但结果可能不总是对人类来说容易理解,这取决于使用案例。
- 显著性图:这种方法涉及创建模型输出的热图,以了解输入的哪些部分最重要。显著性图的一个缺点可能是它们并不总能提供有关不同特征之间关系的信息。
- 模型蒸馏:这种方法将复杂模型简化为一个更简单的模型(例如,决策树),同时尝试保持原始模型的准确性。因为较小的模型可能被认为是一个代理模型,它可能没有与原始模型完全相同的底层结构。
- 局部可解释模型不可知解释(LIME):局部可解释模型不可知解释(LIME)的目标是通过创建一个忠实于原始模型的可解释模型来解释复杂模型。为此,LIME通过在预测附近的训练数据上拟合一个线性模型来创建一个可解释模型。然后使用线性模型来解释原始模型的预测。LIME可能只为单个实例提供解释,而不是模型的整体行为。
- Shapley值:Shapley值可用于确定每个输入变量的重要性,以及哪些输入变量对模型输出的影响最大。这在选择包含在模型中的输入变量和调整模型参数以优化性能方面非常有用。Shapley值可能需要大量计算时间,这意味着在现实世界问题中通常确定近似解决方案。
为了更好地理解深度学习模型是如何做出决策的,接下来我们将更详细地探讨其中的一些方法。Shapley值和局部可解释模型不可知解释(LIME)是两种强大的深度学习可解释性工具。我们将研究这些示例,因为观看视觉表示可能有助于我们和未来的受众更容易理解这些概念。这也可能帮助您了解在您自己的实践中的潜在应用。
案例 1:局部可解释模型不可知解释(LIME)
局部可解释模型不可知解释(LIME),首次发布于2016年,使用局部线性近似来帮助理解黑盒模型的内部运作机制。该算法通过为给定预测学习一个稀疏线性模型来工作。这为用户提供了关于模型如何运作以及为何做出特定预测的洞见。LIME还可用于检测和纠正模型偏见,识别模型表现不佳的领域。通过理解您的深度学习模型的行为,LIME可以帮助您提高模型的准确性和鲁棒性。
利用一个可理解的代理模型是LIME的主要原则。例如,文本分类器可能使用词嵌入,而可解释表示可能是一个二进制向量,表示一个词是否出现。该算法包括从一组潜在的可解释模型中选择一个理想的解释模型,使该模型尽可能简单,同时保持与原始模型的相似性。通过对实例X的扰动来找到最佳解决方案。该技术使用采样和模型不可知方法来减少局部感知损失。
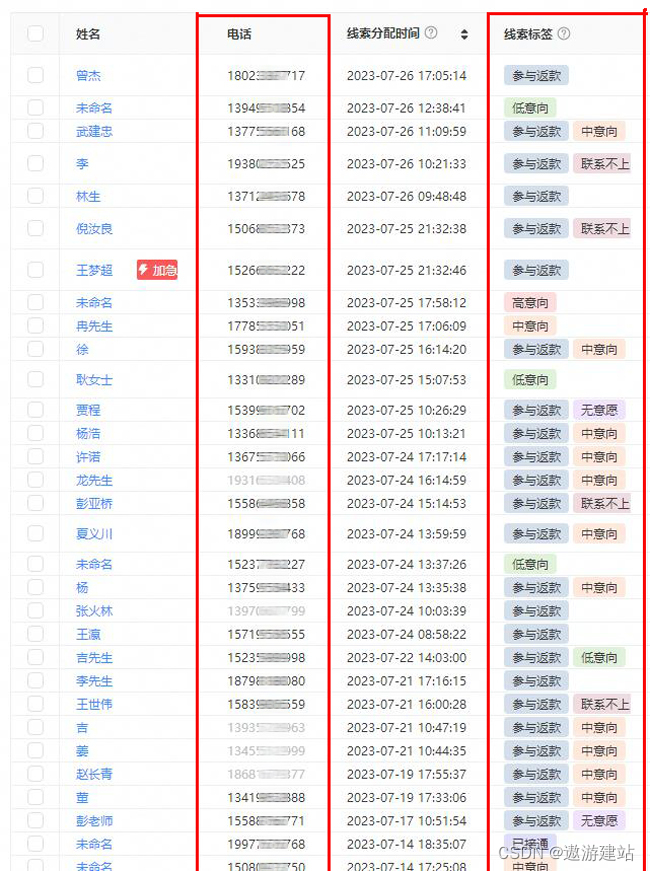
让我们看一个将LIME应用于Inception模型的例子,图片中有一只猫和一只狗。使用以下示例图片:

我们可以检索图像的前 5 个预测:
images = transform_img_fn(['dogs.jpg'])
plt.imshow(images[0] / 2 + 0.5)
preds = predict_fn(images)
for x in preds.argsort()[0][-5:]:
print x, names[x], preds[0,x]
286 Egyptian cat 0.000892741
242 EntleBucher 0.0163564
239 Greater Swiss Mountain dog 0.0171362
241 Appenzeller 0.0393639
240 Bernese mountain dog 0.829222
观察对预测伯恩山犬有贡献的特征(在这个例子中,是像素)可能会很有趣。在这种情况下,我们可以看到狗的脸部对其预测有很大的贡献。
from skimage.segmentation import mark_boundaries
temp, mask = explanation.get_image_and_mask(240, positive_only=True, num_features=5, hide_rest=True)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))
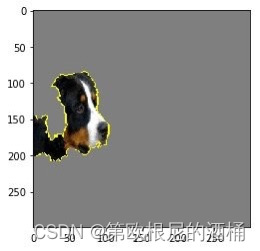
还可以看到产生负面影响的特征或像素:
temp, mask = explanation.get_image_and_mask(240, positive_only=False, num_features=10, hide_rest=False)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))

对狗的正(绿色)和负(红色)贡献
正如我们所看到的,猫的脸对伯恩山犬的预测有负面影响。现在让我们来看看哪些特征对埃及猫的特征有积极的贡献。
temp, mask = explanation.get_image_and_mask(286, positive_only=True, num_features=5, hide_rest=True)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))
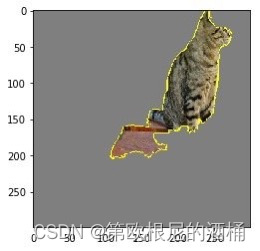
此外,我们可以看到伯恩山犬的脸对埃及猫的预测有负面影响。
temp, mask = explanation.get_image_and_mask(286, positive_only=False, num_features=10, hide_rest=False)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))

正如之前提到的,像其他方法一样,LIME也有其局限性和缺点。底层模型的“黑盒”特性使得使用可解释表示来解释某些行为变得困难。决定使用稀疏线性模型也固有地意味着所提供的解释可能无法准确反映非线性模型(例如,高度非线性模型)所做的预测。解决这一问题的一种方法是使用忠诚度估计来从多个选项中选择适合特定问题上下文的可解释模型类。
案例 2:Shapley值
Shapley值是一种模型独立的方法,用于用户描述模型中特征的重要性。它们解释了单个特征对整个模型预测的影响。深度学习(DL)模型通常包含多层神经元,使用这种方法可能无法有效描述深度学习模型中神经元之间的复杂相互作用。这种方法的另一个权衡是它需要大量样本来计算精确的Shapley值。对于某些深度学习模型来说,这可能非常难以实现。
通过测量训练模型中每个特征的重要性,Shapley值提供了一种解释机器学习中非线性模型预测的方法。计算Shapley值时,会进行模拟,模拟中从输入数据中移除了该特征,并为每个模拟做出预测。然后,该特征的Shapley值计算为带有和不带该特征的预测之间的平均差异。Shapley值可用于提供洞察计算特征贡献和每个特征对模型性能的影响。
让我们看一个关于卷积神经网络上Shapley值的例子。我们可以使用SHAP库来生成Shapley值:
# 为shap选择背景
background = x_train[np.random.choice(x_train.shape[0], 1000, replace=False)] # 使用DeepExplainer来解释模型的预测
explainer = shap.DeepExplainer(model, background) # 计算shap值
shap_values = explainer.shap_values(x_test_each_class)
# 可视化SHAP值
plot_actual_predicted(images_dict, predicted_class)
print()
shap.image_plot(shap_values, x_test_each_class * 255)
底层图像上 Shapley 值的可视化看起来类似于底层图像上 Shapley 值的可视化看起来类似于
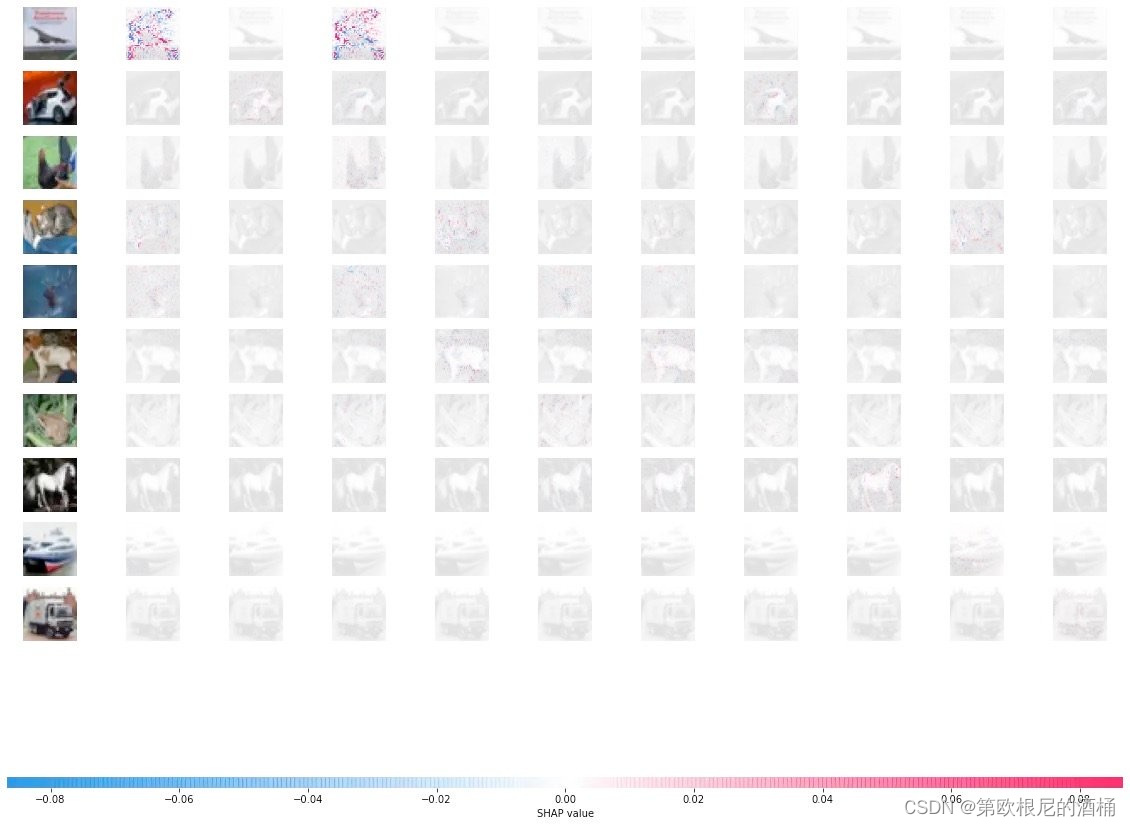
在这里,红色像素表示较高的值。Shapley值在将图像归类为特定类别时做出正面贡献,而蓝色像素代表较低的值,Shapley值在将图像归类时做出负面贡献。这种类型的可视化允许我们看到像素群是如何对单个解决方案做出贡献的,并允许我们寻找模型中的偏见,并调整训练过程以解决任何潜在问题。
如前所述,Shapley值与其他方法一样有局限性。它们可能需要大量的计算时间,这意味着在现实世界问题中通常需要确定近似解决方案。像其他基于排列的解释方法一样,Shapley值忽略了特征依赖性,并且有时也可能提供非故意的解释。因此,Shapley值可能会被误解,确保隐藏的偏见不被掩盖是很重要的。
结论
未来,机器学习可以用来自动执行人类的日常任务,包括回答客户服务查询或处理数据。为了确保这些自动化系统的可靠性,可解释性工具可以用来洞察模型的决策过程。模型不可知的可解释性工具在不同模型间是模块化的,可用于与他人共享模型结果,提供透明度,并使用户对其模型有信心。
LIME和Shapley值是解释深度学习模型结果的两种方法。这两种方法都提供了关于模型如何得出其结果的信息。LIME(局部可解释模型不可知解释)和Shapley值(以数学家劳埃德·沙普利命名)是两种用于描述深度学习模型决策过程的方法。这两种方法都旨在通过分析每个输入特征的贡献来解释深度学习模型的预测。这两种方法的主要区别在于LIME是一种模型不可知的方法。也就是说,它可以与任何类型的模型一起使用,但当应用于复杂或非线性模型时,Shapley值可能会增加计算成本和解释的复杂性。
正如我们所见,可解释性是一个不断发展的研究领域,